基于强化学习的合作频谱分配算法
2022-03-09李冠雄李桂林
李冠雄 李桂林
(1. 天津大学微电子学院,天津 300072;2. 大连交通大学电气信息工程学院,大连 116021)
引 言
随着5G时代的到来,人们对于互联网接入的服务质量要求越来越高,频谱资源短缺的问题日益凸显,传统的固定频谱分配方式无法满足飞速增长的通信需求[1-2],为了解决频谱资源短缺和利用效率低下等问题,认知无线电(cognitive radio, CR)技术应运而生[3]. 这是一种智能化的无线通信系统,系统中的次用户(secondary users, SU)能够检测出无线频谱中的空闲信道,并在不干扰主用户(primary users, PU)正常通信的条件下动态接入空闲信道资源,为提高频谱利用效率提供了一种新的方法.
在CR系统中,频谱分配是认知网络循环的一个重要环节,将强化学习算法融入到频谱分配过程中,使用户能独立进行环境感知,学习信道选择策略,可以有效提升认知网络系统性能. 文献[4]将多信道传输下的动态频谱接入问题建模为部分可观测的Markov决策过程,并利用Whittle指数激励法辅助决策,用户在授权信道上以最小的Whittle指数进行传输. 文献[5]研究了大规模多输入多输出(multi-input multi-output, MIMO) CR系统中底层用户的信道选择策略,针对次基站提出了一种深度强化学习算法,可以智能地选择合适的用户,以满足系统的体验质量要求. 文献[6]提出一种基于强化学习的功率控制信道切换策略,SU通过强化学习掌握最优的信道切换方案,并根据PU通信行为在不同信道间进行切换,有效地利用了数据的延迟容量,降低了信道切换时的功率消耗. 文献[7]通过强化学习和Bayes算法预测信道保持空闲状态的时间,减少了用于信道感知监测的功率消耗,实现了更高的吞吐量. 文献[8]融合了Q-learning和SARSA算法,提出一种多智能体无模型的强化学习资源分配方案,可以减轻认知网络中基站聚集干扰问题,有效提升了网络容量.
上述基于强化学习的频谱分配方案主要集中在对分配算法的研究,在信道选择过程中缺乏对频谱价格的考量,且对性能结果的分析主要集中在吞吐量、阻塞率和传输速率等维度,缺少可以直观反映用户体验的综合评价指标. 本文提出一种基于用户体验质量(quality of experience, QoE)的合作强化学习频谱分配算法,在信道选择过程中新用户通过合作学习其他用户的选择策略,有效提升了吞吐量和系统性能,将平均意见得分(mean opinion score, MOS)作为QoE的综合评价指标,并且在信道接入过程中引入PU的频谱定价因素,从市场博弈的角度研究了频谱价格对SU收益的影响.
1 系统建模与分析
1.1 CR网络通信场景
本文中的通信场景由两部分组成,如图1所示,一是由主基站(primary base station, PBS)和PU构成的授权服务系统,二是由次基站(secondary base station, SBS)和SU构成的认识服务系统. 在授权服务系统中PBS通过单一链路为PU提供通信服务,并在干扰可控的条件下与认知服务系统共享信道资源. 在认知服务系统中包含N个随机分布在次基站周围的SU,SU依托SBS动态接入主服务系统中的频谱空洞,实现频谱资源的高效复用.

图1 CR通信场景Fig. 1 Cognitive radio communication scenarios
在次服务系统中PU和SU均采用自适应调制编码技术进行信息传输,SU动态接入PU的授权频谱资源对不同信干噪比(signal to interference noise ratio,SINR)的信道做出选择. 从图1可以看出SU会受到来自PU、CR系统内其他SU以及环境噪声三部分干扰,第i个SU接入信道的SINR如下[9]:


式中:x、y为用户坐标;d0为参考距离常数;n为信道衰落因子. 由式(1)和式(2)可知SU接入信道的SINR与其到基站的距离有关,所以SU在实际频谱分配过程中是通过调整与SBS间的相对物理位置来进行信道选择,最终达到使CR系统整体性能最优的目标.
1.2 Q-learning强化学习算法
Q-learning是一种用于机器学习的value-based强化学习算法,其优势为能通过时间差分法进行离线学习. 算法由三部分要素构成[10]:环境状态;动作策略;奖励函数. 其中:状态代表算法当前所处的执行阶段;动作策略代表智能体可选择的策略集合;奖励函数则代表了策略选择后的直接奖励反馈,其最终目标为求得当前状态下按照策略π进行动作选择所能获得的最大奖励期望,通过式(3)表示.

式中:s表示环境状态;γ为折损因子,代表了智能体对长期收益的重视程度;R为奖励值大小.
算法的核心路径是利用状态s和动作策略a构建Q表来储存代表即时收益的Q值Q(s,a),每一轮强化学习可抽象为一次有限马尔科夫决策过程,智能体按照最大化奖励函数的策略进行动作选择,选择完成后状态由s转变为s′,同时按照式(4)Bellman公式进行Q值的更新并等待下一步动作选择[11].
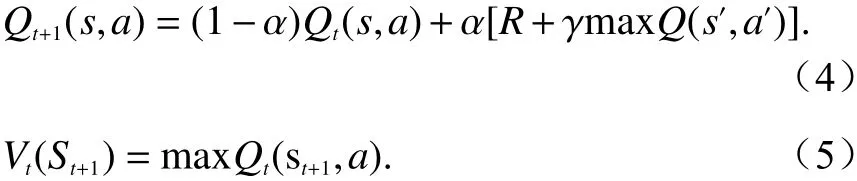
式中,α为学习因子.
式(5)为状态值函数,代表智能体总是选择使Q值最大化的动作策略. 经过多次迭代策略选择过程,当完成Q表全域更新且Q值保持稳定收敛时,即完成了强化学习过程.
2 改进的Q-learning频谱分配方案
2.1 基于Q-learning的合作信道选择策略
在认知无线网络中PBS作为频谱提供者在保证自身干扰阈值的情况下向SBS出租授权频谱资源,SU需要对SBS分发的频谱资源的不同信道做出选择,由于不同的信道具有不同的增益,根据式(2),距离基站越近的位置信道增益越大,单个SU出于自利性总是会向基站靠拢以接入增益较高的信道,这样的结果会造成SU间的干扰大幅增加,从而降低信道的SINR值使系统的整体通信性能下降.
为了纠正单个SU的选择盲目性,本文将Q-learning强化学习算法应用到SU的信道选择过程中,将SU模拟为算法中的智能体,将SU干扰r与PU通信阈值β0的大小关系定义为算法的状态s并通过式(6)表示. 当干扰大于阈值时状态s为0,否则状态s为1. 不同信道的SINR值a={β1,···,βn}构成算法的动作策略集合,奖励值R通过式(7)表示,M为小于奖励函数的固定常数.
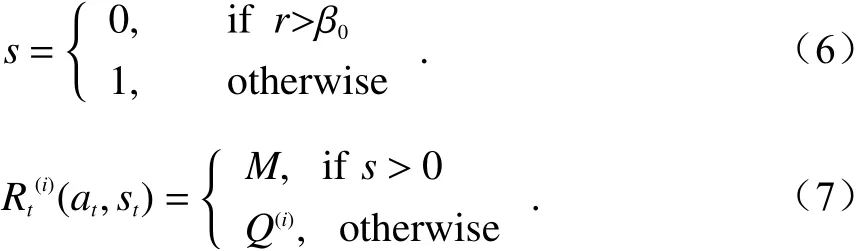
算法通过Q表来储存不同信道选择对应的奖励值结果,根据式(5),作为智能体的SU会按照最大化Q值的原则选择信道,接着根据收到的即时奖励,按照式(4)对Q表进行更新,通过多次迭代“选择信道-计算奖励值-更新Q表”的循环完成强化学习. 最后,我们针对新用户引入docitive合作学习机制,当新用户加入到认知系统中时,可通过式(8)将系统内存量老用户信道选择经验也就是Q值通过求和平均的方式赋给新用户,作为新用户的初始Q值,扩充到原Q表中作为第n+1维数据,形成新的n+1维Q表,以减少新加入节点对系统稳定性的影响,缩短重复学习的时间. 与独立学习算法相比合作学习机制更突出了“教学”的概念,已完成策略学习的节点将信道选择经验传递给新加入节点,以合作分配的方式提升算法的整体性能.

2.2 引入频谱定价的用户收益测算
为了使频谱分配模型更加贴合实际通信场景,对影响频谱分配算法性能的因素做进一步探究,我们引入了频谱定价机制,允许主服务系统根据自身通信情况对频谱资源进行定价,PU处于闲时状态时可将频谱价格设置为较低水平,相反在通信高峰期可将频谱价格提高,以此来调节认知系统的频谱资源供需关系. 用户效用收益Us[12]为

式中:ts为吞吐量;Ps为SU的发射功率;μ为主服务系统对授权频谱的单位定价.
用户的吞吐量与传输速率和接入信道的SINR有关,计算公式如下[13]:

式中:ri为传输速率;βi为信道SINR值;L代表单个数据包的位宽,此处设置为20. SU在进行信道选择时需要对自身收益进行评估,对不同频谱价格条件下的用户收益进行模拟测算,通过求出SU收益Us达到峰值点时对应的频谱价格μ,确定主次用户价格博弈过程中能使系统收益最大的频谱定价.
2.3 不同流量需求用户的MOS评分
传统的通信系统评价维度多集中在拥塞率、通信速率、吞吐量等性能指标,而随着5G时代到来,用户对于通信服务的主观感受变得尤为重要,MOS被广泛应用于主观评测结果,且在QoE管理方面发挥着重要作用,因此本文选择MOS评分作为网络性能的评价维度,以评估频谱分配方案的整体性能,系统MOS分值与QoE的映射关系如表1所示[14].

表1 MOS分值和QoE映射关系Tab. 1 Relationship between MOS and user experience quality
根据SU不同通信需求,将其链路承载的流量划分为实时视频流量和静态数据流量两类. 视频流量属于实时通信,对低时延要求较高;数据流量则对实时性要求较低,在信道接入时的优先级低于前者. 本文使用基于比特率、丢包率等参数的MOS估计模型来进行QoE的主观评价,实时视频流量的MOS计算公式如下[15]:
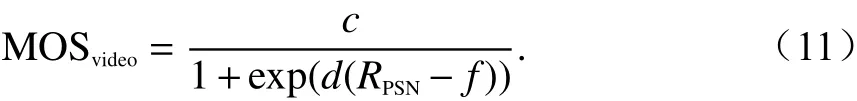
式中:RPSN为峰值信噪比;c、d、f均为函数参数,在本次实验中分别设置为c=6.643 1、d=−0.134 4、f=30.426 4.
静态数据流量的MOS计算公式为
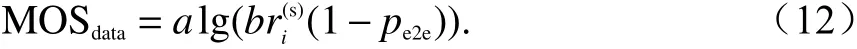
式中:a和b为两个系统常数;r为信道传输速率,可通过香农公式进行计算;pe2e为端到端数据丢包率.最后针对系统内不同用户的通信流量需求,通过下式计算系统整体MOS得分:
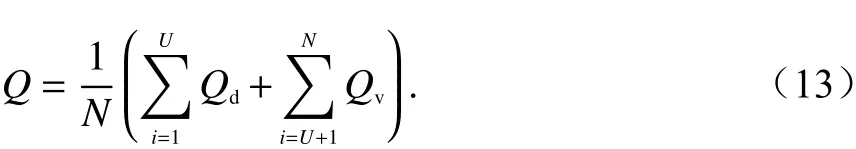
式中:U为数据流量通信用户数;N为视频流量通信用户数;Qd为数据型MOS分值;Qv为视频型MOS分值. 通过平均求解的集成方式整合不同链路类型的MOS分值,作为基于QoE的频谱分配方案综合评价维度.
2.4 算法执行步骤
整个频谱分配算法可以概括为:系统根据可选信道范围和参与资源分配的用户数量建立Q表;按照最大化奖励值的原则逐次迭代强化学习过程,寻找使系统性能最优的信道选择路径;新用户加入后通过合作学习掌握先前用户的信道选择经验;最后根据PU频谱定价计算SU的效用收益,如图2所示.以下为算法的流程图及核心步骤.

图2 核心算法流程图Fig. 2 Flowchart of the core algorithm
Step1 模型初始化
①按照图1中的CR通信场景,初始化认知模型参数,接着根据预先设置的SBS覆盖半径的大小,确定用户坐标范围;
②根据用户坐标范围按照式(2)计算出不同基站距离场景所对应的信道增益,从而确定可选信道SINR策略集合;
③将认知系统中的SU按照通信需求的不同,划分为不同数量的视频流量用户和数据流量用户.
Step2 执行强化学习
①按照认知系统内SU的数量N和可选信道数量M,构建一个M×N维的Q表并将Q值全部初始化为0;
②SU按照最大化奖励期望的原则进行信道选择,而后将所选信道的SINR、传输速率等参数上传至SBS判断SU干扰是否超出PU设定阈值以更新环境状态;
③每个SU根据当前所选信道的SINR值以及自身流量需求类型,计算出当期信道选择后所得到的即时奖励值;
④将SU信道选择后获得的即时奖励值代入到Bellman公式(4),结合上一周期的Q值和学习因子对Q表进行更新;
⑤单次Q-learning的迭代次数设置为100,学习完成后如状态函数小于PU干扰阈值且Q表处于收敛状态,则完成了一次有效的强化学习.
Step3 新用户合作学习
当第N+1个SU加入到认知系统时,系统需要建立新的强化学习循环过程,为了提升频谱分配效率,降低算法执行的复杂度,我们将上一步中前N个用户已收敛的Q表数值进行复用,并通过式(8)将新用户的Q值设置为前N个用户Q值的平均值,完成新Q表的初始化,接着使用新的Q表执行step2中的学习过程.
Step4 SU收益测算
完成强化学习过程获得信道选择方案后,根据SINR值计算不同信道用户的吞吐量,同时引入PU对频谱资源的单位带宽定价,本实验中频谱定价因子范围设置为[0,0.3],最后按照式(9)计算SU在不同带宽定价下效用收益的变化情况.
Step5 系统结果评估
执行完全部SU学习过程后,对认知系统的MOS分值、通信传输速率、系统吞吐量等数值进行整合,计算出全周期的频谱分配方案性能结果.
3 仿真结果与分析
本节在MATLAB平台环境下,对基于QoE驱动的频谱分配算法进行仿真测试. 主服务系统中用户数量为1,授权频谱带宽设置为10 MHz,高斯噪声功率和PU发射功率分别设置为1 nW和10 mW,PBS的蜂窝区域半径为20~1 000 m,SBS的蜂窝区域半径为5~200 m,PU和SU在各自基站的蜂窝区域内进行通信,信道增益遵循长距离路径损耗模型,路径衰减系数n=2.8,SU可选信道SINR范围为−45~40 dB.算法模型中的SU学习因子α=0.1,衰变因子γ=0.4,SU的最大数量设置为22.
图3为三种不同频谱分配方案的MOS. 方案一为合作学习算法,新用户加入系统后,可通过式(8)学习其他用户的信道选择经验;方案二为独立学习算法,新加入的用户独立执行Q-learning算法,而不考虑其他用户的学习经验;方案三为随机分配方案,SU不执行强化学习过程,而是根据随机生成的坐标位置直接接入授权信道. 可以看出三种算法的MOS均会随着SU数量的增加而降低,其原因是,随着用户数的增加用户间的干扰相应增大,为了满足授权系统干扰约束,每个SU趋向于选择较小SINR值的信道,从而总体上导致MOS分值下降. 该结果还表明,合作学习算法相较于独立学习算法能够获得更高的MOS分值,并且前两种执行了强化学习的方案MOS分值远高于方案三随机分配算法.
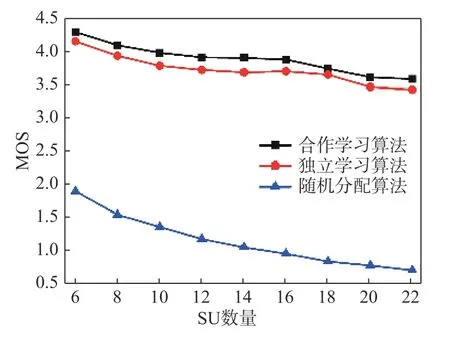
图3 不同分配算法MOS分值曲线Fig. 3 MOS score curve for different allocation algorithms
图4比较了三种不同频谱分配方案的系统吞吐量. 可以看到:当用户数在10个以下时,合作学习算法的吞吐量性能具有一定优势;但随着用户数量继续增加,三种算法的吞吐量迅速下降并趋于一致. 原因是随着用户数增加用户间干扰加剧,使SU的通信速率大幅降低,系统产生了严重的拥塞.
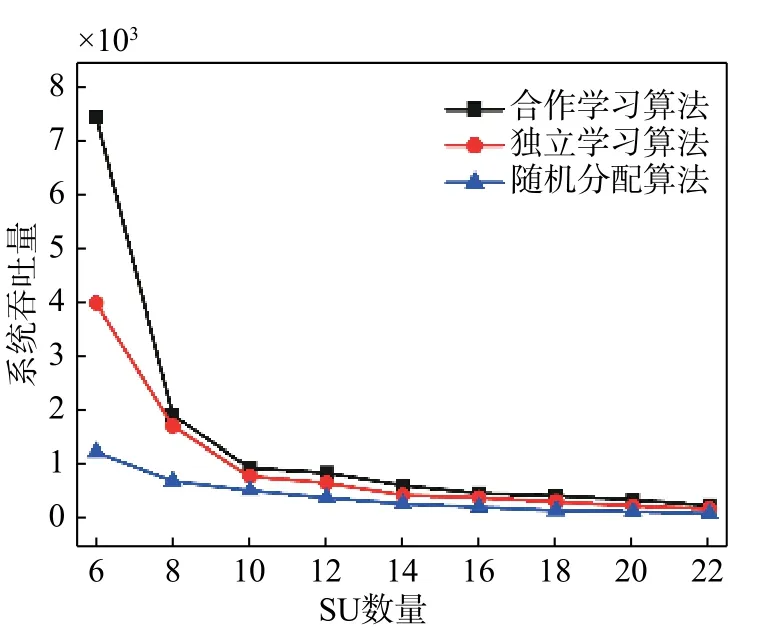
图4 不同分配算法的吞吐量曲线Fig. 4 Throughput curve of different allocation algorithms
图5对合作学习算法做了进一步延伸,对新加入用户和原有用户的流量需求类型进行划分,探讨了两种新的合作学习频谱分配算法:同类用户合作学习算法,异类用户合作学习算法. 第一种是新加入用户只学习具有相同流量类型用户的信道选择经验,第二种是新加入用户只学习具有不同流量类型用户的信道选择经验. 从仿真结果可以看出:融合全量用户学习经验的算法仍是MOS分值最高的方案;只学习同流量类型用户经验的算法MOS分值略高于其余两种分配算法;完全独立学习的算法仍是MOS分值最低的方案.
图5 四种频谱分配算法的MOS分值曲线Fig. 5 MOS score curve of 4 spectrum allocation algorithms
图6反映了SU数量对算法性能的影响. 可以看到:随着SU数量大幅增加,合作频谱分配算法所获得的MOS分值和收敛速度会随之下降,但仍处于可接受的范围内;当用户数量达到120个时,系统MOS分值为2.41,根据表1可知对应“一般”的QoE,依然可以满足正常通信需求. 收敛速度的下降,虽然会增加算法的执行时间,但不会影响对用户的服务质量.
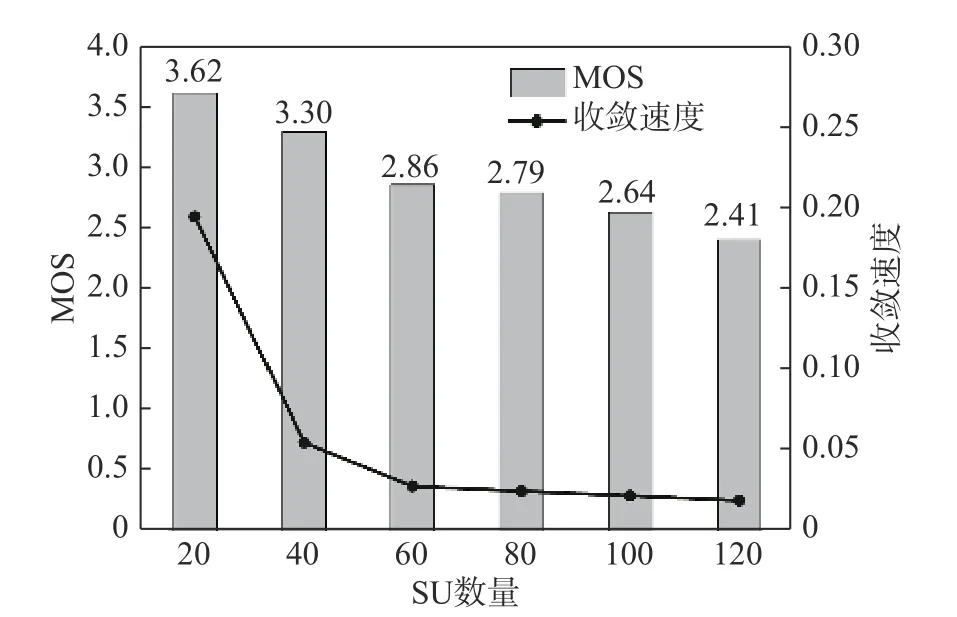
图6 SU数量对算法性能的影响Fig. 6 The impact of the SU on the algorithm
图7反映了不同频谱价格条件下的SU收益,频谱价格因子μ范围设置为[0,0.3]. 可以看出:起初随着单位频谱价格的提高SU的效用收益随之增大,效用收益达到峰值时对应的频谱价格因子为0.16;之后用户收益开始缓慢下降,当μ增加到0.26时,用户收益迅速下降,原因是PU频谱定价过高,导致频谱博弈市场崩溃,SU接入授权频谱的意愿大幅下降.
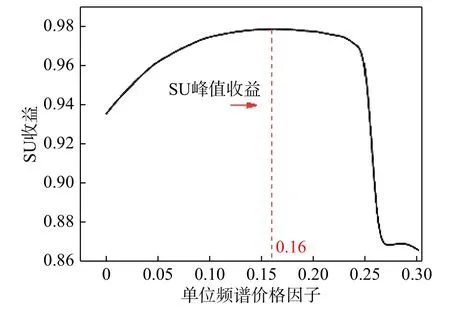
图7 不同频谱定价的SU收益Fig. 7 SU utility under different spectrum pricing
4 结 论
本文针对认知用户自利性和相互干扰而导致的频谱资源分配不合理问题,提出了一种基于QoE的合作强化学习分配算法,通过SU的强化学习找到使不同流量特性用户通信效用最大化的频谱分配方案,同时引入了用户间的合作机制,新加入用户可以学习其他用户的信道选择策略,从而有效优化了算法执行过程,提升了系统通信性能. 此外,本文将MOS用作系统性能评价度量,为不同流量类型用户提供统一的评价标准,实现了异类流量的无缝集成. 仿真结果表明所提出的合作频谱分配算法可以有效提升用户的服务质量和认知系统通信性能,在新用户与不同流量类型用户合作所做的对比中也可以看出,全流量类型的合作分配算法仍具有明显优势. 最后本文在PU和SU间融合了市场价格博弈因素,允许PU根据自身通信情况对授权频谱进行定价,研究了不同频谱价格对SU效用收益的影响,对强化学习和市场博弈理论相融合的频谱分配算法做了初步探索.但是目前所提出的算法只在单个PU和SU间进行了价格博弈,如何在多个SU强化学习过程中融入价格博弈的因素,建立多维度的频谱分配约束机制,是未来的研究方向.
