基于逐级信息恢复网络的实时目标检测算法
2022-03-09庞彦伟孙汉卿曹家乐
庞彦伟,余 珂,孙汉卿,曹家乐
基于逐级信息恢复网络的实时目标检测算法
庞彦伟,余 珂,孙汉卿,曹家乐
(天津大学电气自动化与信息工程学院,天津 300072)
随着卷积神经网络的发展,目标检测算法成为计算机视觉领域的研究热点,基于深度学习的实时目标检测算法需要同时兼顾检测精度和检测速度两项指标. 不基于先验框的实时目标检测算法CenterNet大幅提高了检测速度,但是由于其直接对低分辨率高层特征进行连续上采样,没有充分补充特征在下采样过程中丢失的空间细节信息,导致算法对目标定位不够准确,影响了检测精度. 为解决这一问题,提出了一种基于逐级信息恢复网络(hierarchical information recovery network,HIRNet)的实时目标检测算法. 该算法中,为对信息进行逐级恢复,设计了相邻层信息增强模块(adjacent layer information strength module,ALISM)和残差注意力特征融合(residual attentional feature fusion,RAFF)模块. 通过构建ALISM模块,将中间层特征进行处理,分别为相邻层特征提供更多的空间细节信息和语义信息,提高低层特征的表达能力,输出更适宜进行信息恢复的特征. 为进一步精确恢复损失的空间细节信息,HIRNet在上采样过程中逐级使用构建的RAFF模块,这一模块综合利用全局和局部注意力调整低层特征和高层特征的残差权重,再对两级特征进行加权融合,恢复高层特征在下采样过程中丢失的空间细节信息. 在PASCAL VOC数据集和MS COCO数据集上的实验证明了所提算法的有效性. 在MS COCO验证集上,HIRNet保证了检测的实时性,提升了算法检测性能,检测精度比CenterNet算法提高了3.9%.
目标检测;深度学习;卷积神经网络;不基于先验框;逐级信息恢复
近年来,基于深度学习[1]的目标检测算法逐渐成为计算机视觉领域的研究热点[2-19].目标检测算法可以根据是否使用先验框分为基于先验框的方法[5-7]和不基于先验框的方法[8-19]两类.基于先验框的方法使用预定义的先验框对目标进行定位,而不基于先验框的方法摒弃了这种方式,避免了手工设计先验框参数对算法效果的影响,本文聚焦于不基于先验框的实时目标检测算法.
不基于先验框的目标检测算法可以大致分为使用关键点检测[10-16]和使用先验点检测[17-19]两类.使用关键点检测的方法先检测目标的关键点,再对检测结果进行后处理.使用先验点的检测方法将原有的先验框转化为先验点后进行回归.在使用关键点检测的方法中,CornerNet对目标左上和右下的角点进行检测[11].CenterNet只检测目标中心点,简化了后处理过程,大幅提高检测速度[12].ExtremeNet对目标的4个极点和1个中心点进行检测[13].TTF提出了一种新的采样方式,缩短了训练时间[14]. CentripetalNet使用带有向心偏移的角点进行检测,帮助算法达到更好的定位效果[15].CPN使用双阶段的方式先利用角点提取候选区,再进行分类[16].使用先验点检测的方法中,FCOS对目标中心区域的先验点进行回归,并使用Center-ness分支对可靠性进行评价[17]. FoveaBox引入可形变卷积,使用位置信息引导分类信息的预测[18].ATSS通过对比使用先验框和先验 点算法间的区别,提出了一种新的选择正负样本的方法[19].
使用关键点检测的CenterNet方法,大幅提高了检测速度,得到了广泛使用,但是由于其直接对低分辨率高层特征进行上采样,未有效利用低层特征补充下采样过程中丢失的空间细节,导致预测时对目标定位不够准确.
本文针对这一问题,在CenterNet的基础上进行改进,提出逐级信息恢复网络(hierarchical information recovery network,HIRNet),通过逐级信息恢复的方式有效利用低层特征补充空间细节,提高算法定位的准确性.首先,HIRNet构建相邻层信息增强模块(adjacent layer information strength module,ALISM),将中间层特征进行处理,为相邻两层特征分别提供语义信息和空间细节,输出更有效的特征用于信息恢复.其次,HIRNet应用了注意力机制[20]提升特征的融合效果,对注意力机制模块AFF[21]进行改进,提出残差注意力特征融合(residual attentional feature fusion,RAFF)模块,使用残差注意力融合低层特征和高层特征,进一步恢复高层特征中的空间细节.本文在PASCAL VOC[22]和MS COCO[23]数据集上进行了全面的实验,与现有的不基于先验框方法相比,HIRNet在这两个数据集上均能获得有效提升,并且保证了算法的实时性.
1 CenterNet存在的问题
本文提出的方法针对CenterNet面临的预测时使用的特征缺少空间细节信息导致定位不够精确的问题.图1为CenterNet和HIRNet使用ResNet-18[24]为骨干网在PASCAL VOC数据集上的可视化检测结果,由图1(a)可知,CenterNet的检测结果中存在对目标定位不够准确的问题,例如对图中大部分瓶子的定位不够准确.这是由于CenterNet在使用较高分辨率的高层特征图进行预测时,无法依靠简单的可形变卷积和上采样的堆叠恢复出之前在下采样过程中丢失的空间细节信息,进而导致预测时使用的特征图缺乏足够的空间信息,使得检测效果不佳.针对这一问题本文提出了逐级信息恢复网络HIRNet,构建了相邻层信息增强模块(ALISM)产生更适宜进行信息恢复的特征,并构建残差注意力特征融合(RAFF)模块使用全局和局部注意力机制加权融合两级特征的残差进行逐级信息恢复.

图1 CenterNet和HIRNet使用ResNet-18检测结果对比
2 逐级信息恢复网络及其目标检测方法
2.1 逐级信息恢复网络
本文提出的HIRNet是基于CenterNet的改进方法,HIRNet结构如图2所示,包括骨干网、ALISM、RAFF和检测头4部分.本文以骨干网使用ResNet-18的HIRNet为例对整体网络结构进行说明.依照CenterNet的设计,首先使输入图像经过一个卷积核大小为7×7、步长为2的卷积层以及批正则化(batch-norm)层、线性整流函数(ReLu)激活层和一个步长为2的最大值池化(maxpooling)层.通过对输入图像的粗处理,滤除了冗余信息,便于网络进行特征提取.此时将步长为4的特征图输入ResNet-18网络的第1~4层(layer),进行特征提取.然后在骨干网后依次使用3个上采样模块,提高特征图的分辨率,便于进行关键点检测.该上采样模块依次包括一个卷积核为3×3的可形变卷积层、一个批正则化层、一个ReLu激活层、一个转置上采样层以及一个批正则化层.同CenterNet一样,为了减少计算量,HIRNet未将3个上采样层的通道数均设为256,而是按处理顺序依次设为256、128、64.
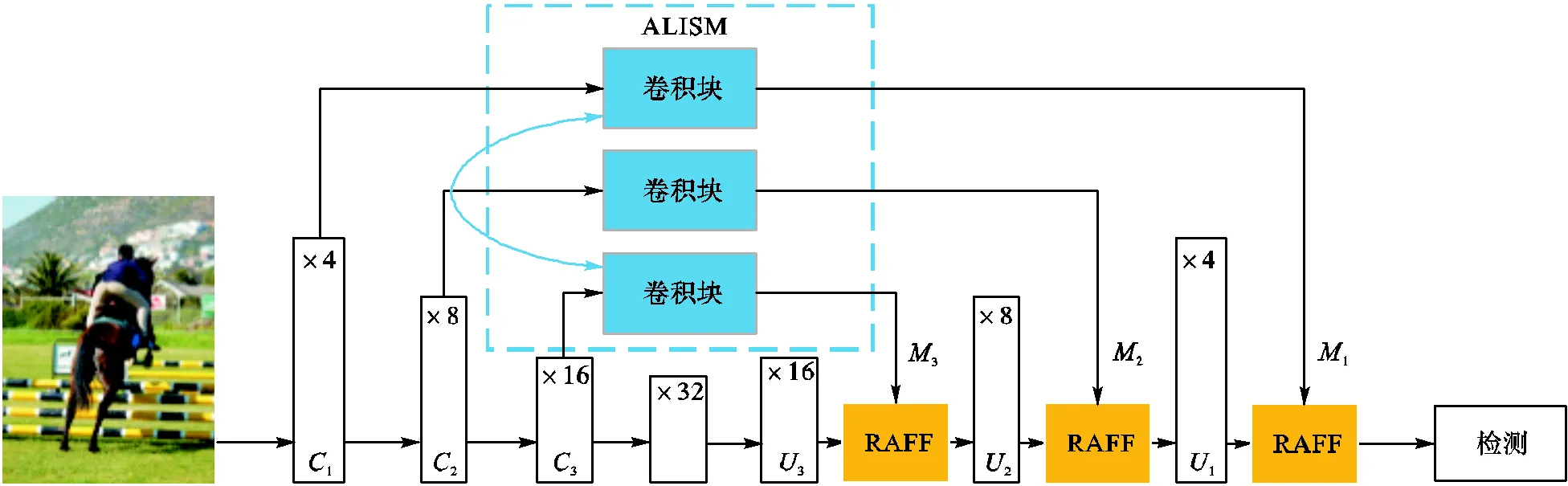
图2 HIRNet网络结构
由于特征图在下采样过程中损失了空间细节并且低层特征又相对包含较多空间细节,所以HIRNet使用骨干网第1~3层后提取到的特征作为ALISM的输入,并通过ALISM获得更适合进行信息恢复的特征图.为了进行逐级地信息恢复,ALISM配合输出的特征图与3次上采样后所得特征图分辨率相同.ALISM输出的特征图直接用于信息恢复过程.
为了更好地自适应强调重要信息,达到信息恢复的目的,HIRNet引入注意力机制,提出RAFF模块用于信息恢复时的特征融合操作.RAFF模块使用相同分辨率的ALISM对应输出特征和上采样后的特征图,融合产生恢复了具有一定信息和更强表达能力的特征图.为了更精确地进行恢复,RAFF模块使用全局注意力和局部注意力对两个特征的残差进行加权调整.
经过3个上采样模块和逐级信息恢复后,HIRNet按照CenterNet中的设计方案,将步长为4的特征图输入3个不同的检测头,分别进行目标中心点存在性、边界框大小和目标中心点偏移预测.
2.2 相邻层信息增强模块
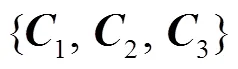

图3 ALISM结构

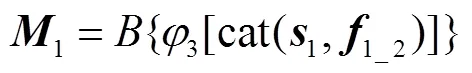
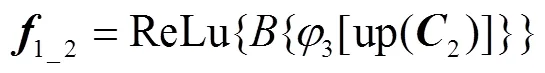




2.3 残差注意力特征融合模块
特征在神经网络的下采样过程中不断丢失其中所包含的信息,而简单的上采样堆叠无法准确地恢复出丢失的信息,甚至会引入错误,针对这一问题HIRNet使用ALISM的输出特征和上采样后的特征对信息进行恢复.为了避免由于采样倍数过大和同时使用多级特征而引入噪声,HIRNet使用对信息进行逐级恢复的方案.与FPN[25]直接相加的方式不同,HIRNet提出的残差注意力特征融合(RAFF)模块使用注意力机制来生成两个不同级别特征残差的权重,然后对两级特征进行加权融合.这种加权融合的RAFF模块可以更好地自适应强调需要补充的信息.


融合和的残差所使用的权重可以通过对使用全局注意力和局部注意力机制得
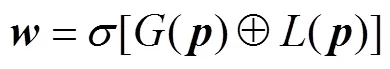

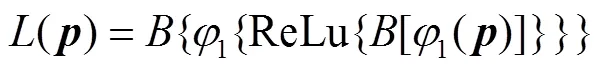
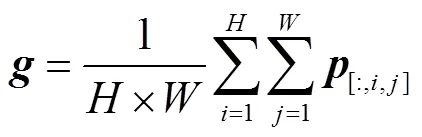

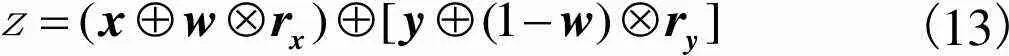
(13)
3 实验结果与分析
3.1 实验数据集
为验证本文所提方法的有效性,本文在PASCAL VOC数据集[22]和MS COCO数据集[23]上进行了目标检测实验.PASCAL VOC数据集包含20个目标类别,其中PASCAL VOC2007数据集包含5011张训练图像和4952张测试图像,PASCAL VOC2012数据集包含11540张训练图像和10991张测试图像.本文使用PASCAL VOC2007训练集和PASCAL VOC2012训练集的组合集进行训练,使用PASCAL VOC2007测试集进行评估.在PASCAL VOC数据集中,使用交并比(intersection over union,IoU)阈值为0.5计算平均精度均值(mean average precision,mAP).MS COCO数据集包含80个目标类别,它包含约115000张训练图像、5000张验证图像和40000张测试图像.本文使用训练集(trainval)训练,使用验证集(minival)进行评估.在MS COCO数据集中,平均精度(average precision,AP)通过对多个IoU阈值(取值范围从0.50~0.95)求平均值计算.
3.2 训练细节
本文在实验中使用在ImageNet数据集[26]上经过预训练的ResNet网络作为骨干网.为了节省计算量,当骨干网为ResNet-50时,ALISM采样部分的通道数从512减少到256.本文使用CenterNet[12]中所使用的损失函数、权重初始化和数据增强方法.实验采用Adam方法进行训练.对于PASCAL VOC数据集,批大小(batch size)为32,总迭代数(epoch)为70,学习率设置为1.25×10-4,在第45次和60次迭代后学习率均下降10倍.本文方法使用PASCAL VOC数据集时,训练和测试的输入尺寸均为384×384.对于MS COCO数据集,batch size为16,总迭代数为140,学习率为6.25×10-5,在第90次和120次迭代后均下降10倍.对于MS COCO中使用ResNet-50的情况,batch size为12,学习率遵循线性学习率规则[27].本文方法使用MS COCO数据集时,训练输入尺寸为512×512,测试时保持原图大小.本文实验模型的训练均使用两块NVIDIA GTX 1070显卡,测试除特别说明外均使用一块NVIDIA GTX 1070显卡.本文在Python中基于Pytorch深度学习框架构建算法模型.
3.3 所提模块有效性验证

表1 PASCALVOC数据集所提各模块消融实验结果
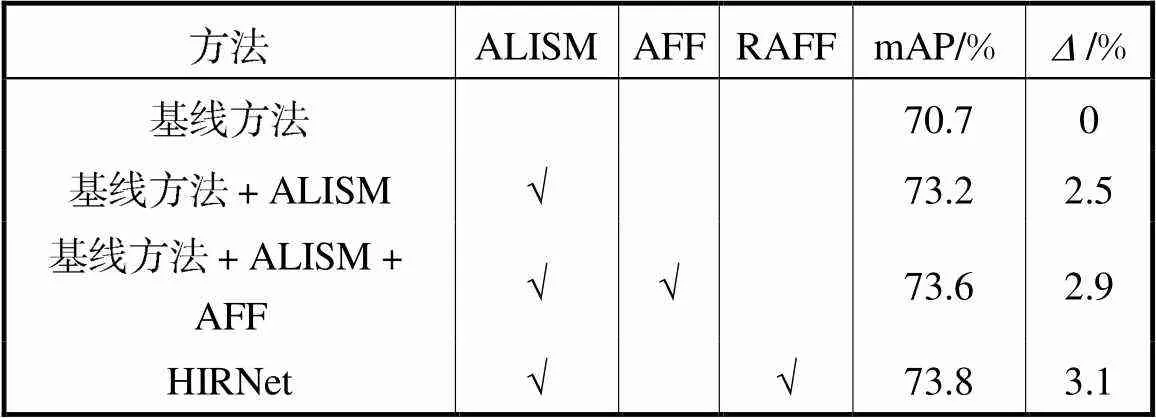
Tab.1 Ablation experiment results of the proposed mod-ules on the PASCAL VOC dataset
为确定ALISM的结构,本文尝试了跨层信息增强方案,该方案在本文中使用ALISMv0表示,ALISMv0使用第1层特征经过连续两个卷积核为 3×3、步长为2的卷积层为第3层特征提供空间细节,同时使用第3层特征经过4倍的双线性插值后再经过一个卷积核为3×3、步长为1的卷积层为第1层特征提供语义信息.ALISMv0其余部分设置与ALISM保持相同.PASCAL VOC数据集上ALISM结构对比实验结果如表2所示,为保证实验结果不受其他因素影响,表2中的网络没有使用RAFF模块.由表2可知,跨层提供信息的方案虽然使用了包含更多信息的特征,但是效果比相邻层方案差,本文认为这是由于上、下采样过程中引入了过多噪声导致的.
表2 PASCALVOC数据集上ALISM结构对比实验结果

Tab.2 Comparison experiment results of ALISM struc-ture on the PASCAL VOC dataset
为了证明HIRNet的有效性,本文进一步将所提方法与应用FPN[25]、PANet[28]的基线方法在PASCAL VOC数据集上进行了对比,实验结果如表3所示.为了公平比较,FPN和PANet均只使用了第1~3层的横向链接,通道数与HIRNet对应保持一致,且均只使用步长为4的特征图进行预测.实验结果表明,HIRNet的效果优于应用FPN、PANet的基线方法.这是由于,HIRNet中ALISM使用了相邻层的特征进行信息增强,缩小了FPN结构中直接使用横向连接的方式中存在的语义鸿沟,由ALISM模块产生的特征更容易提供更多有用信息.同时RAFF模块使用的特征残差注意力融合方式与直接相加的方式相比调整了两个特征各个像素的权重,更容易恢复出在下采样过程中丢失的信息.
表3 PASCALVOC数据集HIRNet与现有特征金字塔结构对比

Tab.3 Comparison of HIRNet with the existing feature pyramid structure on the PASCAL VOC dataset
HIRNet使用较少参数量的同时保证了检测效果,本文对比了表现接近的使用ResNet-34为骨干网的CenterNet与使用ResNet-18为骨干网的HIRNet的检测结果,如表4所示,HIRNet在参数量比CenterNet少5.4×106时,mAP比CenterNet高0.1%,证明了HIRNet能够使用较少的参数量有效提升检测效果.
表4 PASCALVOC数据集HIRNet与CenterNet参数量对比
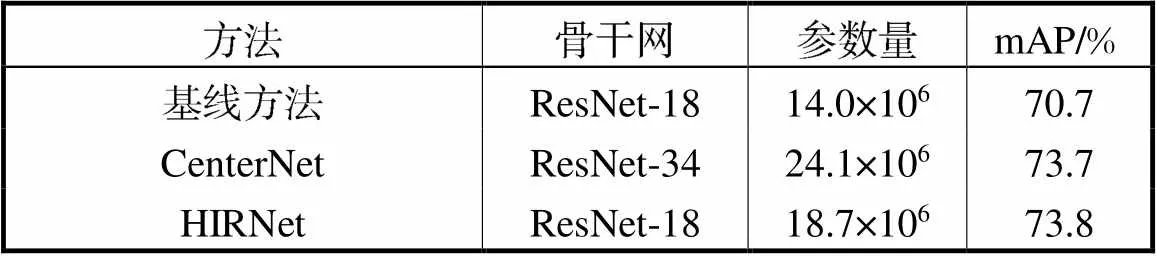
Tab.4 Comparison of parameters between HIRNet and CenterNet on the PASCAL VOC dataset
3.4 实验结果对比
为了验证本文方法在目标检测任务上的优越性,将本文方法在MS COCO数据集的验证集上进行测试,并与其他先进方法进行比较,实验结果如表5所示.使用一块NVIDIA GTX 1080Ti显卡对检测速度进行测试.通常认为检测速度大于30帧/s的方法满足实时性的要求,考虑到数据预处理、结果存储等因素,实践中取60帧/s为分界线划分算法的实时性,所以本文中以60帧/s为分界线进行对比.
由表5中结果可得,虽然HIRNet由于增加了一定的参数量,其速度相较于CenterNet稍有下降,但是在骨干网为ResNet-18时,HIRNet比CenterNet精度高3.9%.在速度与使用ResNet-34为骨干网的TTF相当的情况下,骨干网为ResNet-18的HIRNet比TTF精度高0.7%.HIRNet在精度与速度之间进行了较好的平衡.在骨干网为ResNet-50时,HIRNet速度是RetinaNet的3倍,且精度比RetinaNet高0.2%,虽然由于输入尺寸图像较小导致的检测困难使得HIRNet在IOU阈值为0.50时的AP值和衡量小物体的检测精度的APS比RetinaNet低,但是HIRNet在IoU阈值为0.75时的AP值更高,表明HIRNet的定位更准确.HIRNet在满足实时性的要求下,精度比一些使用ResNet-101、VGG等大型网络为骨干网的方法更高,体现了其在精度与速度之间进行了较好的平衡.
图5展示了CenterNet方法与HIRNet使用ResNet-18为骨干网在MS COCO验证集上的可视化结果,图5(a)为CenterNet结果,图5(b)为HIRNet结果.为了适应实际应用需要,图5中展示的可视化结果已滤除置信度低于0.3的检测结果.由两种方法的可视化结果对比可以看出,HIRNet比CenterNet定位更精确,如CenterNet在图5(a)的第1张图中检测结果的边界框只包含了船体的一部分,第2张图中的边界框只包含了冲浪板的一部分,而HIRNet对应边界框包含的物体更完整,对物体边界的定位更准确.同时HIRNet可以减轻CenterNet存在的虚检情况,如CenterNet在第3张图中将固定钟表的底座错检为交通灯、第4张图中对一个冲浪板产生多个检测结果,这种虚检现象未在HIRNet的对应结果中发生.
表5 不同方法在MSCOCO验证集上的比较结果

Tab.5 Comparison results of different methods on the MS COCO minival data set
注:*表示该结果未在原文中给出;AP50表示IoU为0.50时的AP值;AP75表示IoU为0.75时的AP值;APS表示小尺寸目标的AP值;APM表示中尺寸目标的AP值;APL表示大尺寸目标的AP值.

图5 CenterNet与HIRNet使用ResNet-18为骨干网在MS COCO验证集上可视化结果
4 结 语
本文提出了一种不基于先验框的目标检测方法HIRNet,构建ALISM和RAFF模块在上采样阶段对信息进行逐级恢复,解决了CenterNet中简单的上采样无法恢复神经网络在下采样阶段丢失的空间细节信息而导致的检测效果不佳的问题.ALISM利用中间层特征对相邻层特征进行信息增强,使得输出的低层特征同时具有更丰富的语义信息和空间细节信息,为后续信息恢复提供了更强有力的特征表达方式.RAFF模块引入全局注意力和局部注意力机制,自适应调整进行融合的两个特征的残差变化,提供了更有效的信息恢复手段.基于PASCAL VOC数据集和MS COCO 数据集的相关实验表明,本文所提出的HIRNet方法能在保证实时性的同时,明显提升目标检测精度,在MS COCO数据集上,骨干网使用ResNet-18时AP相对于基线方法CenterNet可提升3.9%达到32.0%,当使用ResNet-50为骨干网时AP为36.0%,验证了本文所提方法的有效性.
在未来的方法中,希望在本文的基础上进一步缓解参数量增加对检测速度的影响,并且更有效地利用低层特征的空间信息达到更好的检测效果.
[1] LeCun Y,Bengio Y,Hinton G. Deep learning[J]. Nature,2015,521(7553):436-444.
[2] 张 为,魏晶晶. 嵌入DenseNet结构和空洞卷积模块的改进YOLO v3火灾检测算法[J]. 天津大学学报(自然科学与工程技术版),2020,53(9):976-983.
Zhang Wei,Wei Jingjing. Improved YOLOv3 fire detection algorithm embedded in denseNet structure and dilated convolution module[J]. Journal of Tianjin University(Science and Technology),2020,53(9):976-983(in Chinese).
[3] 杨爱萍,鲁立宇,冀 中. 多层特征图堆叠网络及其目标检测方法[J]. 天津大学学报(自然科学与工程技术版),2020,53(6):647-652.
Yang Aiping,Lu Liyu,Ji Zhong. Multi-feature concatenation network for object detection[J]. Journal of Tianjin University(Science and Technology),2020,53(6):647-652(in Chinese).
[4] 高春艳,赵文辉,张明路,等. 一种基于YOLOv3 的汽车底部危险目标检测算法[J]. 天津大学学报(自然科学与工程技术版),2020,53(4):358-365.
Gao Chunyan,Zhao Wenhui,Zhang Minglu,et al. A vehicle bottom dangerous object detection algorithm based on YOLOv3[J]. Journal of Tianjin University (Science and Technology),2020,53(4):358-365(in Chinese).
[5] Ren S Q,He K M,Girshick R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[6] Liu W,Anguelov D,Erhan D,et al. SSD:Single shot multibox detector[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam,Netherlands,2016:21-37.
[7] Li Y Z,Pang Y W,Shen J B,et al. NetNet:Neighbor erasing and transferring network for better single shot object detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:13346-13355.
[8] Redmon J,Divvala S,Girshick R,et al. You only look once:Unified,real-time object detection[C]// Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:779-788.
[9] Yu J H,Jiang Y N,Wang Z Y,et al. et al. UnitBox:An advanced object detection network[C]//Proceedings of the 24th ACM Multimedia Conference. Amsterdam,Netherlands,2016:516-520.
[10] Duan K W,Bai S,Xie L X,et al. CenterNet:Keypoint triplets for object detection[C]//Proceedings of the 17th IEEE/CVF International Conference on Computer Vision. Seoul,South Korea,2019:6568-6577.
[11] Law H,Deng J. Cornernet:Detecting objects as paired keypoints[C]//Proceedings of the 15th European Conference on Computer Vision. Munich,Germany,2018:765-781.
[12] Zhou X Y,Wang D Q,Krähenbühl P. Objects as points[EB/OL]. http://arxiv.org/abs/1904. 07850,2019-04-25.
[13] Zhou X Y,Zhuo J C,Krähenbühl P. Bottom-up object detection by grouping extreme and center points[C]// Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:850-859.
[14] Liu Z L,Zheng T,Xu G D,et al. Training-time-friendly network for real-time object detection[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York,USA,2020:11685-11692.
[15] Dong Z W,Li G X,Liao Y,et al. CentripetalNet:Pursuing high-quality keypoint pairs for object detection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:10516-10525.
[16] Duan K,Xie L,Qi H,et al. Corner proposal network for anchor-free,two-stage object detection[C]// Proceedings of the 6th European Conference on Computer Vision. Glasgow,UK,2020:399-416.
[17] Tian Z,Shen C,Chen H,et al. FCOS:Fully convolutional one-stage object detection[C]//Proceedings of the 17th IEEE/CVF International Conference on Computer Vision. Seoul,South Korea,2019:9626-9635.
[18] Kong T,Sun F C,Liu H P,et al. FoveaBox:Beyound anchor-based object detection[J]. IEEE Transactions on Image Processing,2020,29:7389-7398.
[19] Zhang S F,Chi C,Yao Y Q,et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:9756-9765.
[20] Fan D P,Wang W,Cheng M,et al. Shifting more attention to video salient object detection[C]// Proceed-ings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:8546-8556.
[21] Dai Y M,Gieseke F,Oehmcke S,et al. Attentional feature fusion[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Waikoloa,USA,2021:3559-3568.
[22] Everingham M,Van Gool L,Williams C K I,et al. The pascal visual object classes(VOC)challenge[J]. International Journal of Computer Vision,2010,88(2):303-338.
[23] Lin T Y,Maire M,Belongie S,et al. Microsoft COCO:Common objects in context[C]//Proceedings of the 13th European Conference on Computer Vision. Zurich,Switzerland,2014:740-755.
[24] He K M,Zhang X Y,Ren S Q,et al. Deep residual learning for image recognition[C]//Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:770-778.
[25] Lin T Y,Dollár P,Girshick R,et al. Feature pyramid networks for object detection[C]//Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:936-944.
[26] Russakovsky O,Deng J,Su H,et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision,2015,115(3):211-252.
[27] Goyal P,Dollár P,Girshick R,et al. Accurate,large minibatch SGD:Training ImageNet in 1 hour[EB/OL]. http://arxiv.org/abs/1706.02677,2018-04-30.
[28] Liu S,Qi L,Qin H F,et al. Path aggregation network for instance segmentation[C]//Proceedings of the 31st meeting of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:8759-8768.
[29] Lin T Y,Goyal P,Girshick R,et al. Focal loss for dense object detection[C]//Proceedings of the 16th IEEE International Conference on Computer Vision. Venice,Italy,2017:2999-3007.
[30] Redmon J,Farhadi A. YOLOv3:An incremental improvement[EB/OL]. http://arxiv.org/abs/1804.02767,2018-04-08.
Hierarchical Information Recovery Network for Real-Time Object Detection
Pang Yanwei,Yu Ke,Sun Hanqing,Cao Jiale
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
With the development of convolutional neural networks,object detection has become a focused research area in computer vision. Real-time object detection algorithms based on deep learning need to consider detection accuracy and speed. The real-time anchor-free object detection algorithm called CenterNet greatly improves the detection speed. However,it directly performs continuous upsampling of high-level features which are low-resolution. It does not fully recover the spatial details lost in the downsampling process,resulting in inaccurate positioning and low detection accuracy. To address this problem,a hierarchical information recovery network(HIRNet)is proposed. Here,the information is hierarchically recovered by developing an adjacent layer information strength module(ALISM) and residual attention feature fusion(RAFF)module. ALISM was designed to use the middle-layer features to provide more spatial details and semantic information for the adjacent layer features and improve the low-level features’ discriminative power. Thus,its outputs were more suitable for information recovery. RAFF was hierarchically used in the upsampling process to further recover the lost spatial details. It used the global and local attention to adjust the residual weights of the low-level and high-level features,then fused the two-level features to recover the spatial details of the high-level features,which were lost in the downsampling. Experiments on PASCAL VOC and MS COCO datasets showed the effectiveness of the proposed algorithm. HIRNet guarantees real-time detection with an accuracy of 3.9% higher than that of the CenterNet on the MS COCO minival dataset,improving the detection performance.
object detection;deep learning;convolutional neural network;anchor-free;hierarchical information recovery
10.11784/tdxbz202103031
TP391.4
A
0493-2137(2022)05-0471-09
2021-03-17;
2021-06-16.
庞彦伟(1976— ),男,博士,教授.
庞彦伟,pyw@tju.edu.cn.
国家自然科学基金资助项目(61906131).
Supported by the National Natural Science Foundation of China(No. 61906131).
(责任编辑:孙立华)
