结合双流网络和双向五元组损失的跨人脸语音匹配
2022-03-09钟必能王楠楠
柳 欣 王 锐 钟必能 王楠楠
1(华侨大学计算机科学与技术学院 福建厦门 361021)
2(综合业务网理论及关键技术国家重点实验室(西安电子科技大学) 西安 710071)
3(厦门市计算机视觉与模式识别重点实验室(华侨大学) 福建厦门 361021)
4(广西师范大学计算机科学与信息工程学院 广西桂林 541004)
语音和视觉信息是人们相互交流的重要载体,也是人机交互过程中最为直接和灵活的方式.心理学中著名的“麦格克效应”(McGurk effect)[1]表明,大脑在感知语音的过程中,人脸信息和语音信息会相互作用.同时,大量神经认知科学的研究表明,人脸信息和语音信息有着相同的神经认知通路[2].在日常生活中,当人们在给好友打语音电话时,虽然只接收到了对方的语音信息,但脑海中会不自觉地浮现出对方的人脸信息,即我们的大脑可以自动地将接收到的语音信息与之前已经存储好的人脸信息进行语义关联.
上述现象和研究表明,个体人脸信息和语音信息之间是存在明显关联特性的.受此启发,人们已逐渐认识到语音特征与视觉特征之间关联的重要性,并进行了多方面的跨模态匹配研究,如跨人脸-语音生物特征匹配、说话人标注以及跨人脸-语音检索等[3-5].因此,有效的人脸-语音相关性挖掘和跨模态匹配研究能够促进认知科学和人工智能技术创新实践的发展,具有重要的现实意义,有着广阔的应用前景.近年来,基于文本和图像的跨媒体检索,受到了国内外研究学者的广泛关注,但基于面部信息与语音信息的跨模态匹配和语义关联挖掘研究较为匮乏.
据文献研究,现有的挖掘人脸信息和语音信息之间关联的方法大致可以概括为2类:1)基于浅层特征相关性学习的方法;2)基于深度兼容性特征学习的方法.具体地,浅层匹配学习方法一般使用子空间相关性学习的方法进行人脸和语音的语义相似性映射挖掘,从而达到缩小面部特征与语音特征间的语义鸿沟的目的.深度特征学习方法旨在通过多层非线性网络结构来实现复杂特征表达能力的逼近,进而实现人脸和语音特征的跨模态语义关联.然而,人脸和语音信息的复杂多样性和非静态性加大了不同模态间潜层语义关联的抽取难度.为满足实际应用需求,现有人脸-语音语义关联方法在相关跨模态匹配方面的效果还需进一步提升.
基于人脸-语音的相关性挖掘和跨模态匹配问题的研究尚为一项新颖的课题,其智能语义关联研究仍处于早期发展阶段[6],并且现有方法或多或少存在一些挑战,包括3方面:1)面部和语音底层特征因维数不同、性质和属性不同,使得彼此之间无法直接参与计算,进而带来了语义表征的差异性和不可比性;2)针对人脸和语音特征的异构性,目前仍缺乏有效方法解决低层特征和高层语义之间存在的语义鸿沟问题;3)现有的异构特征学习和关联性学习结合的不够紧密,从而导致高层一致性语义挖掘的表征学习不够充分.此外,本文通过文献调研发现,大多数跨人脸-语音匹配方法工作只呈现了部分匹配任务评测结果,而其他多样性匹配评测任务还有待挖掘.
针对上述挑战,本文提出了一种基于双向五元组损失的跨人脸-语音特征学习框架,生成的跨模态表示在所有跨模态匹配任务上进行全面了评估测试.首先,本文采用双流架构的网络学习跨人脸-语音特征表示.传统的双流网络采用2条并行且独立的分支处理多模态数据,不同模态之间缺少交互,因而很难学习出高质量的语义特征.为解决特征异构问题,本文在双流网络的顶端引入了一种新的多模态加权残差网络,并采用权重共享策略,以挖掘模态间关联,生成模态不变的跨模态表示;其次,现有的基于距离度量损失的方法中采用的样本对构造策略往往没有挑选出合适样本对,也没有充分利用batch中的数据,使得很多有益于训练的样本未能参与训练,极大地限制了模型的泛化性能.为解决训练样本不足问题,本文提出了多种有效的样本对构造策略,并基于这些策略提出了多种表现形式的三元组损失,这些三元组损失一起构成一种新的双向五元组损失(bi-quintuple loss, Bi-Q loss).通过优化该损失,可以促使更多有益于训练的人脸样本及语音样本参与训练,进而学到更好的跨模态表示;最后,为了保证人脸特征和语音特征在共享语义空间的可分性,本文在特征层后面引入了一个全连接层进行身份(identity, ID)分类学习,实验表明结合ID损失与双向五元组损失可以促进模型的有效收敛,鲁棒性较好.本文工作的贡献主要包括3个方面:
1) 提出了一个端到端的跨人脸-语音特征学习框架,该框架在双流网络的顶端引入了一种新的权重共享多模态加权残差网络,可以有效挖掘模态间关联;
2) 设计多种样本对构造策略并提出双向五元组损失,极大地提高了数据利用率和模型泛化性能;
3)本文方法具有较强的扩展性和一般性.相比现有方法,本文学习框架在4个不同的跨人脸-语音关联任务上,其跨模态匹配各项指标上几乎取得了全面提升,某些指标上的提升近5%.
1 相关工作
人类面部视觉信息和语音信息是人机交互过程中最为直接和灵活的方式,从而基于人脸和语音的关联性挖掘及其跨模态协同感知吸引了国内外研究学者的广泛关注.早期针对人脸和语音的相关性挖掘主要是基于浅层特征相关性学习的方法.例如,Hasan等人[7]通过认知学的角度利用功能性磁共振成像分析了人脸和语音在身份鉴别上的潜在关联特性;类似地,针对人脸和语音2种不同模态特征之间存在的“语义鸿沟”问题,Li等人[8]通过跨模态因子分析(cross-modal factor analysis)来缩小人脸与语音特征间的语义鸿沟,接着利用典型相关分析法(canonical correlation analysis, CCA)进一步关联2种模态特征集,从而实现说话人的跨视听媒体数据互标注;Chetty等人[9]通过潜在语义分析和CCA方法对人脸和语音生物特征进行跨模态关联,从而使得身份验证系统达到了较好的预防反欺骗性(anti-spoofing)攻击的目的;Chakravarty等人[10]利用跨模态监督学习方法(cross-modal supervision)对语音信息进行当前说话人检测,取得了鲁棒性的结果.研究发现,这些浅层特征相关性学习方法缺乏从非线性异构特征中提取有意义跨模态关联的本质特征能力,从而导致其相应跨模态关联匹配效果有所欠缺.
近年来,多模深度学习可以有效对多模态数据逐级提取从低层到高层的语义特征,展现出了强大本质特征学习的能力.据文献研究,现有挖掘人脸信息和语音信息之间关联的深度学习方法大致可以分为2类:1)基于分类损失的学习方法;2)基于距离度量损失学习的方法.基于分类损失的学习方法通常把跨人脸-语音跨模态匹配问题定义为分类问题.典型代表为Nagrani等人[3]提出的多分支卷积神经网络(convolutional neural network, CNN)结构方法,该方法首先采用多分支CNN分别提取人脸图片和语音数据的特征,接着将提取好的人脸特征和语音特征拼接起来,输入到softmax层以获得分类概率.该模型然在1∶2 匹配任务上的表现可以媲美人类,但由于是针对特定匹配任务设计的,需要调整子网络数目才能应用于其他任务,模型灵活性欠佳;近期,Wen等人[5]采用不相交映射网络(disjoint mapping network, DIMNet)来监督跨模态表示的学习,在1∶2的跨模态匹配任务上获得了较好的准确率,超过了人类主观水平,但在一些挑战性较高的匹配任务上,如1∶N匹配及跨模态检索,该模型的表现有待提高.
基于距离度量损失的学习方法通常利用多模态神经网络将人脸样本和语音样本映射到欧氏空间,并通过优化网络距离度量损失,使得同一个体的人脸样本和语音样本对应的特征表达在欧氏空间中的距离足够近,不同人的人脸样本和语音样本对应的特征表达在欧氏空间中的距离足够远[11].Nagrani等人[12]通过刻画个人身份节点方式(person identity nodes, PINs)来描述身份,并采用对比损失来约束正负样本对之间的距离,该方法提出了一种基于Curriculum的策略构造样本对,但这种策略构造的负样本对中可能存在噪声数据;Xiong等人[13]采用了三元组损失来引导人脸-语音跨模态表示的学习,然而该方法只构造了跨模态三元组样本,忽略了许多其他类型有益于训练的三元组样本,其跨模态关联效果还有所欠缺.
2 跨人脸-语音特征学习框架
如图1所示,本文提出的结合双流深度网络和双向五元组损失的跨人脸-语音特征学习框架采用了常见的双流网络架构,包含人脸和语音2个分支网络.其中,人脸子网络和语音子网络的权重是各自独立的,用来提取模态特有的特征;双流网络顶端的多模态加权残差网络的权重由2个模态共享,用来挖掘模态间语义关联,生成模态不变的跨模态表示;双向五元组损失用于进一步挖掘模态间关联,提高数据利用率和模型泛化性能;ID损失用于保证跨模态表示的可分性,促进模型收敛.
2.1 形式化定义
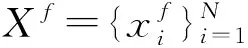
2.2 多模态加权残差网络
针对2种模态的关联性挖掘,双流深度网络能够有效地进行异构特征的兼容性学习.在跨模态特征表示学习中,文献[14]为了挖掘文本模态和图像模态之间的关联并生成模态不变的跨模态表示,选择在双流网络的顶端引入了权重共享的单层全连接.然而,一方面,单层全连接拟合能力有限,同时没办法解决非线性映射问题,因而挖掘到的模态间关联可能极为有限.另一方面,单纯地增加全连接层数有时会使得网络训练和优化起来越来越复杂和困难.
为解决上述问题,受残差网络[15]思想的启发,本文在双层全连接网络的输入层与输出层之间引入了一种新的加权残差连接,并采用权重共享策略保证生成的跨模态表示形式在同一个特征表示子空间中.本文提出的这种网络结构简称为多模态加权残差网络(multi-modal weighted residual network, MWRN).实验结果表明,该网络可以有效地加强模态共享信息、挖掘模态间关联,促使模型生成更好的跨模态表示.
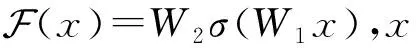
(1)
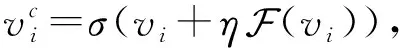
(2)
其中,η为缩放因子,在网络中是一个可学习的参数.根据文献[16]中的设计,在网络训练中缩放因子初始值设为0,用来避免训练初始阶段出现过分的梯度波动造成的不稳定,从而使得模型在训练初期更加的稳定,促进整个网络的训练平稳性和鲁棒性.
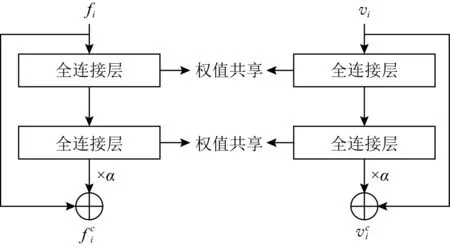
Fig. 2 Multi-modal weighted residual network图2 多模态加权残差网络
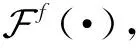
2.3 双向五元组损失
本文提出了一种双向五元组损失函数进行人脸-语音的语义关联性学习约束,该损失由多个改进的三元组损失构成.具体地,三元组损失是一种常见的距离度量损失,其形式化定义为
(3)
其中,a表示固定(anchor)样本,p表示与a属于同一类别的正(positive)样本,n表示与a属于不同类别的负(negative)样本,da,p表示固定样本a与正样本p对应的特征表达之间的距离,da,n表示固定样本a与负样本n对应的特征表达之间的距离,m表示最小间隔(margin).针对每个三元组a,p,n,三元组损失的优化目标是让da,p尽可能小,da,n尽可能大,并且要让da,p与da,n之间有一个最小的间隔m,T表示三元组样本集合,形式化描述为
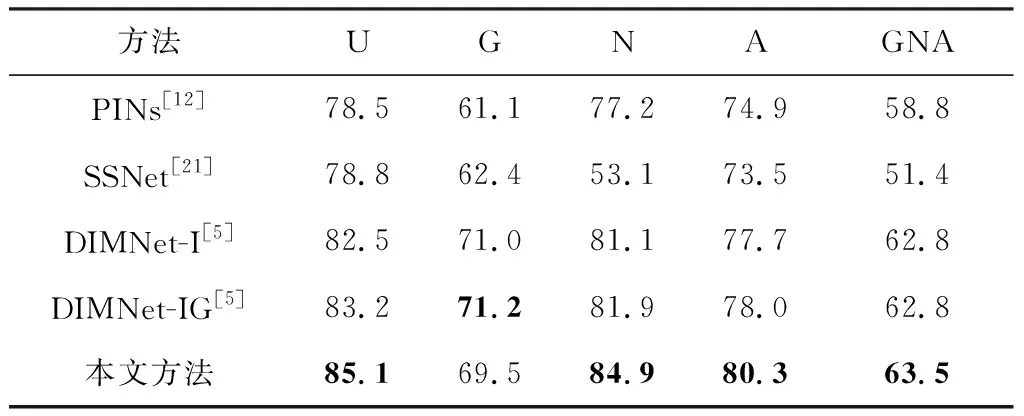
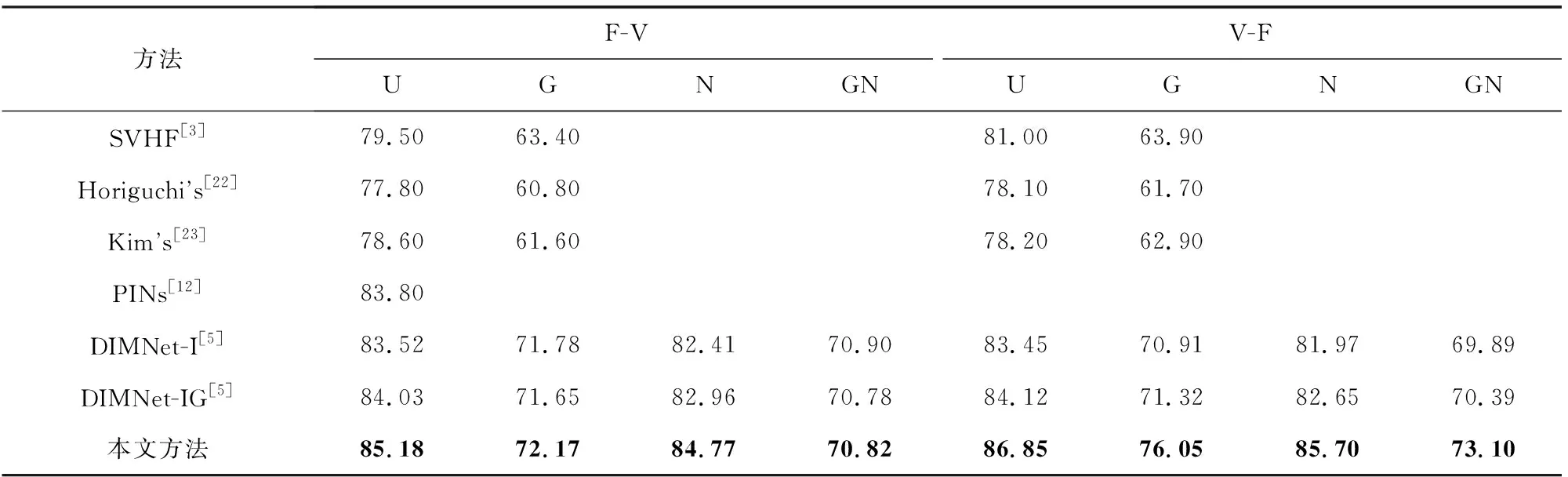
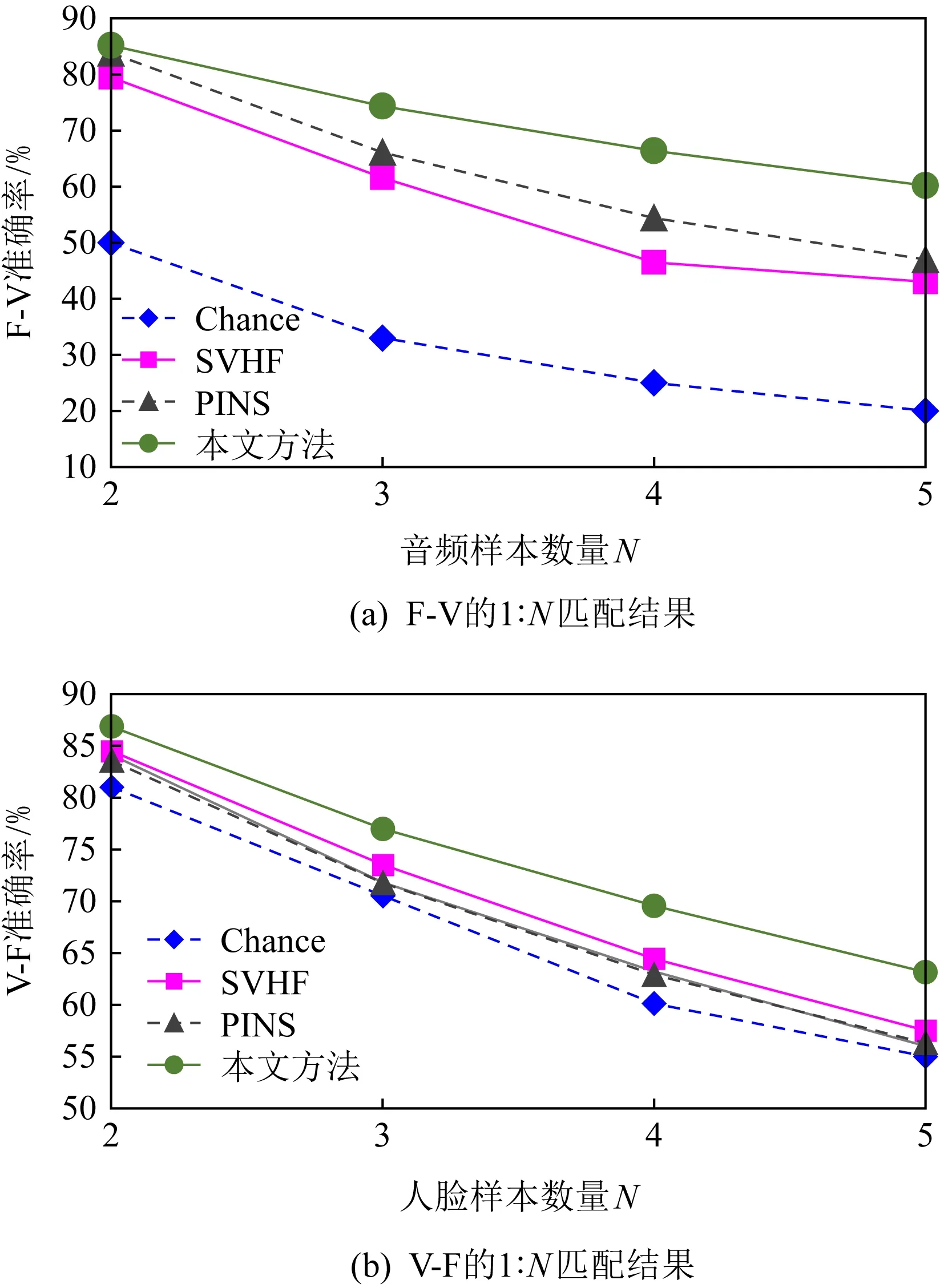
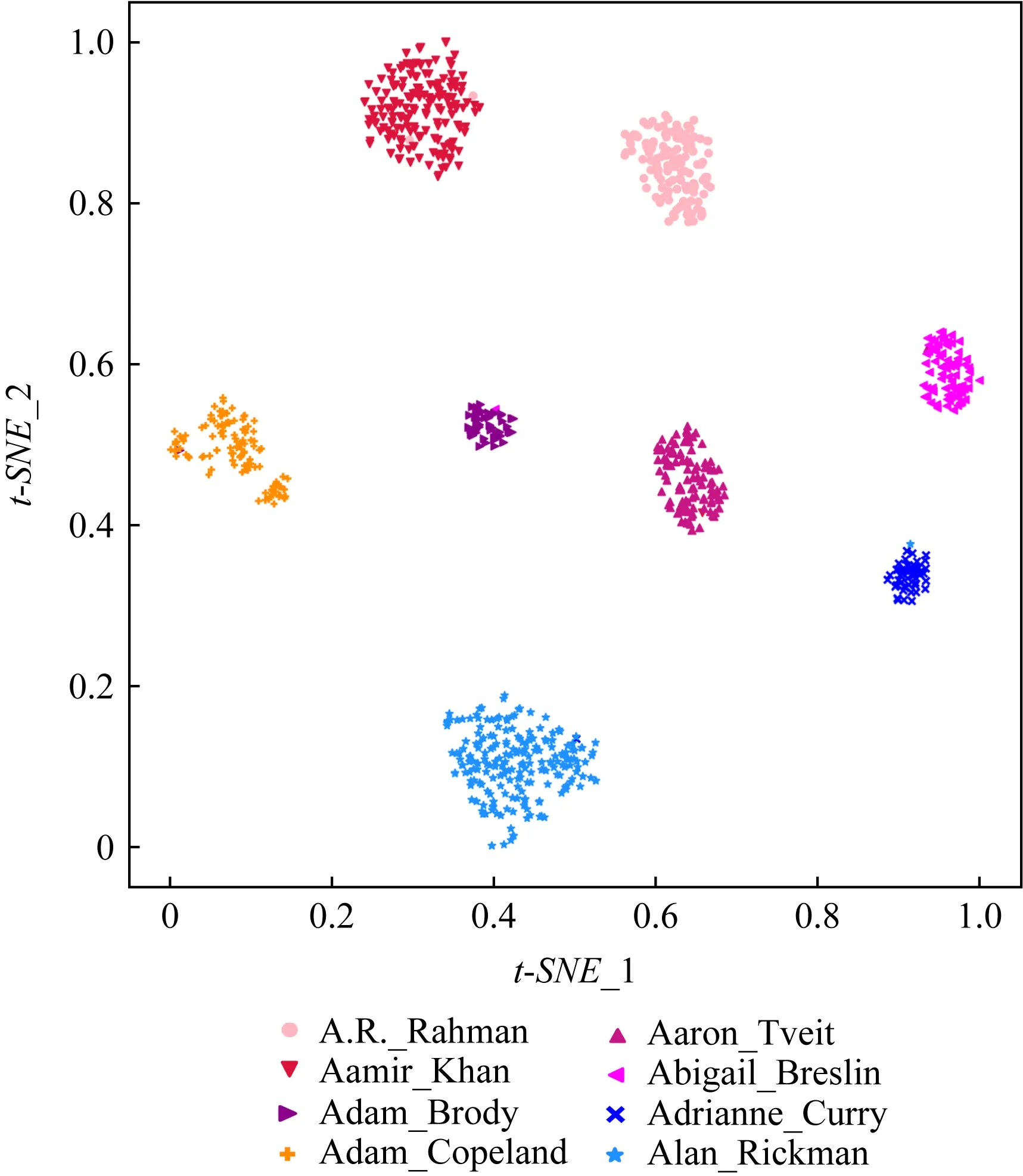
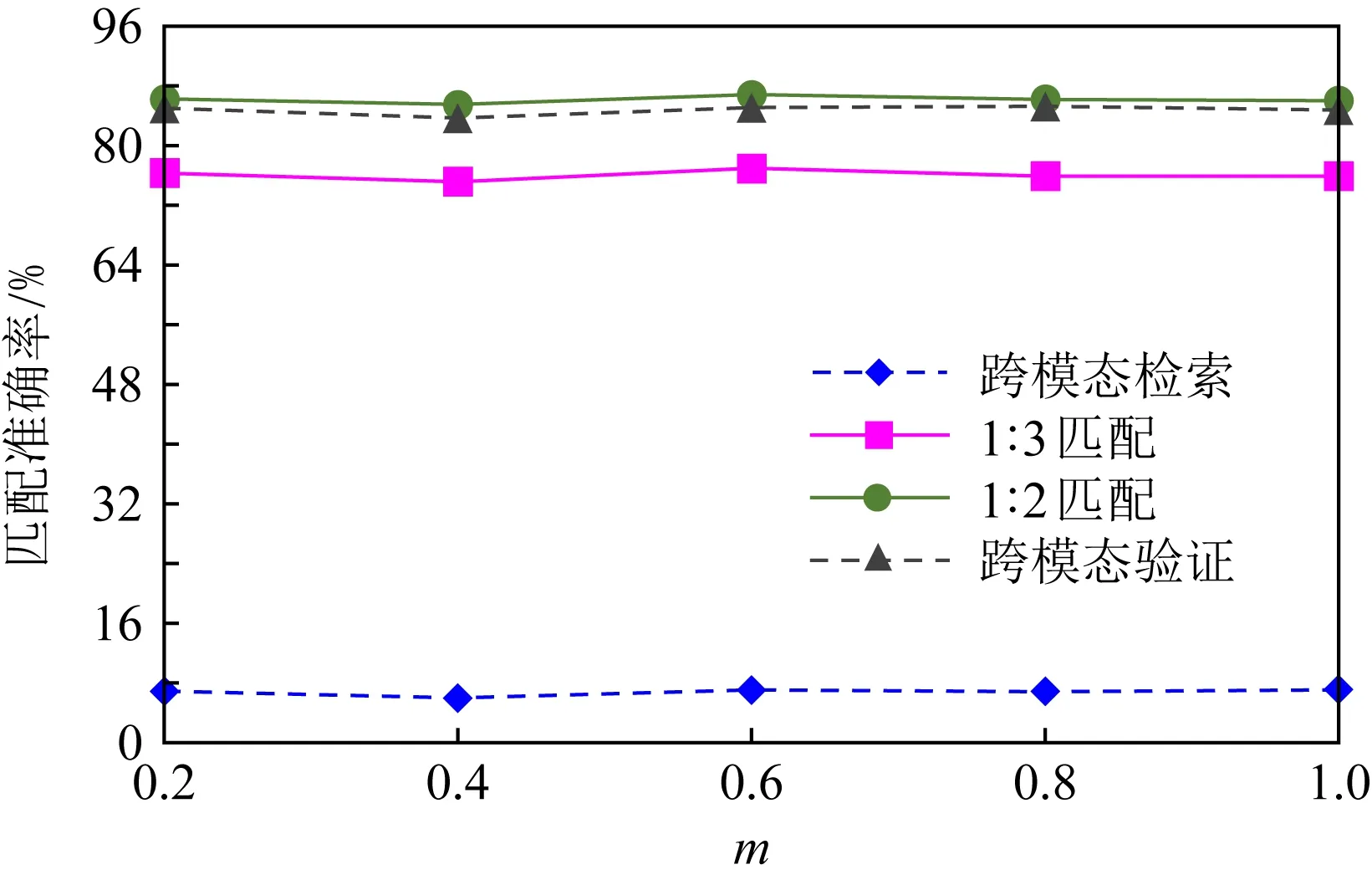
da,p+m (4) 然而,若要在整个训练集上构造三元组,随着训练集样本数目增多,可能的三元组数量将呈立方级增长.因此,当训练集非常大时,训练将会非常耗时.同时,随着训练的深入,大量的简单的三元组不具有判别性,并对模型表现的提升毫无贡献.为解决此问题,文献[17]提出了TriHard损失,它是一种采用基于批量(batch)的在线难样本采样策略的三元组损失.对于每个训练batch,随机挑选B个ID,每个ID随机挑选K个样本,则每个batch中有B×K个样本,其样本集合记为Xbatch.对于每个样本a,挑选一个最难正样本p和最难负样本n,最难正样本p是Xbatch中与样本a属于同一ID的样本中距离样本a最远(语义最不相关)的样本,最难的负样本n是Xbatch中与样本a属于不同ID的样本中距离样本a最近(语义最相关)的样本.TriHard损失的形式化定义为 (5) 其中,P表示Xbatch中与a的ID相同的样本集合,Q表示Xbatch中与a的ID不同的样本集合,m表示最小间隔.可以看到,由于TriHard损失是在每个batch上构造三元组,而不是在整个训练集上,因而大大提高了模型的采样效率与训练效率,同时,借助难样本的重点性采样策略,简单的样本将被过滤掉,因而提高了模型的鲁棒性.为了提高模型训练效率,同时促使足够多的有益于训练的三元组样本参与训练,本文提出了多种样本对构造策略,进而提出了跨模态TriHard损失以及混合模态TriHard损失.采用双向训练策略的跨模态TriHard损失和混合模态TriHard损失一起构成一种新的双向五元组损失. (6) 2.3.1 跨模态TriHard损失 (7) (8) (9) 跨模态TriHard损失定义为 (10) 跨模态TriHard损失可以有效缩减人脸模态和语音模态数据之间的“异构鸿沟”,从而使得同一个ID的人脸样本和语音样本对应的特征表达之间的距离足够近,不同ID的人脸样本和语音样本对应的特征表达之间的距离足够远. 2.3.2 混合模态TriHard损失 (11) (12) 值得注意的是,由于正负样本是在2个模态数据集上采样得到的,因而xpos和xneg可能来自人脸模态,也可能来自语音模态,因而称之为混合模态三元组.以这种方式构建的三元组称之为有效的混合模态TriHard三元组,满足条件: (13) 有效的混合模态TriHard三元组有4种表现形式,如图3所示.其中,方形表示人脸样本,圆形表示语音样本,不同的颜色深浅代表不同的ID.从图3中可以看出:第1种三元组是2.3.1节提到的跨模态TriHard三元组,固定样本来自人脸模态,正负样本均来自语音模态;第2种三元组中固定样本与负样本来自同一模态,与正样本来自不同模态;第3种三元组中固定样本与正样本模态相同,与负样本模态不同;第4种三元组中固定样本及正负样本均来自同一模态,是一种模态内TriHard三元组.综合这些不同形式的三元组,混合模态TriHard损失的形式化定义为 MTH(,xpos,xneg)= (14) 混合模态TriHard损失综合考虑了模态间和模态内的多种距离约束,极大地提高了模型的泛化能力. Fig. 3 Mixed-modal triplets with different forms图3 不同表现形式的混合模态三元组 2.3.3 双向训练策略 前面2.3.1节和2.3.2节在构建TriHard三元组的过程中,默认采用人脸样本作为固定样本,但实际上人脸样本和语音样本并没有角色上的区别,同时,很多跨模态任务都是双向的,为了学习更适合于最终任务的跨模态表示,同时为了更多的有效的三元组样本得以参与训练,本文基于双向训练策略提出了双向五元组损失. (15) (16) 整个batch的双向五元组损失定义为 (17) 双向五元组损失可以同时优化2个方向的五元组距离度量损失,从而可以极大地提高人脸-语音跨模态表示的鲁棒性和模型的泛化能力. 为确保人脸样本和语音样本在嵌入到公共表示空间之后的模态内判别性得以保留,即保持良好的可分性,本文提出了基于ID损失的约束.每一个个体的身份ID可以看作一个类别,通过在特征层后面附上一个全连接层φC(·)来实现对语义特征所属的身份类别的预测.具体地,ID损失的定义为 (18) 本文提出方法的整体损失函数形式为 (19) 本文采用mini-batch的训练方式,mini-batch可以在训练过程中引入随机性,同时可以提升模型训练速度,每个batch会随机挑选16个ID,接着每个ID随机挑选4张人脸图片和4条语音数据.同时,本文采用结合权重衰减和动量技术的随机梯度下降(stochastic gradient descent, SGD)方法来优化模型,其中,一方面,权重衰减(weight_decay=0.000 5)用来调节模型复杂度对损失函数的影响,以防止过拟合;另一方面,动量(momentum=0.9)用来加速模型收敛过程.本文采用了一种动态的学习率调整策略,学习率会随着训练轮数的增加而衰减,训练共需50轮,训练过程中学习率将从初始学习率10-3衰减到10-8. 为了充分评估本文所提出方法的有效性和鲁棒性,本文在公开的Voxceleb1音视频数据集上进行实验测试,下面具体介绍实验详情. Voxceleb1[18]是公开的大规模音视频数据集,由上传到YouTube的采访视频中提取的1 251个名人的音视频短片组成.该数据集总计包含10万多条音频、2万多条视频.文献[12]采用SyncNet[19]方法从该数据集中提取出超过10万条说话人人脸轨迹片段.在本文实验中,实验所选取的数据集是由该文献作者处理好并在其官网公开发布的Voxceleb1数据集,其数据集划分方式也与作者在文献[12]中的描述相同. 本文方法依据Pytorch深度学习框架进行配置和实现,其中双向五元组损失中的间隔设置为m=0.6,人脸子网络采用Inception-ResNet-v1模型,并用标准的VGGFace2[20]数据集上的预训练权重进行初始化,输入的人脸图片采用了与PINs[12]方法和SSNet[21]相同的预处理技术;语音子网络采用与DIMNet-Voice[5]方法相同的结构,并使用在Voxceleb1上的预训练权重进行初始化.人脸特征和语音特征输出维度为256. 为了全面验证本文方法的有效性,本文设计了4种不同的跨人脸-语音匹配任务,分别为跨模态验证、1∶2 匹配、1∶N匹配以及跨模态检索任务. 1) 跨模态验证 跨模态验证是指给出1张人脸图片和1条语音数据,判断该数据对是否属于同一个人,其评价标准采用AUC值作为量化指标. 2) 1∶2 匹配 跨模态1∶2 匹配是指给出1张人脸图片和2条语音数据,2条语音数据中只有1条与给定的人脸图片属于同一个人,模型的任务是预测与给定的人脸图片匹配的那条语音数据的位置编号,本文称之为人脸到语音(face to voice, F-V)下1∶2 匹配;类似地,可以定义语音到人脸(voice to face, V-F)下1∶2 匹配.F-V下1∶2 跨模态匹配和V-F下1∶2 跨模态匹配均采用百分制匹配准确率作为评价指标,匹配准确率计算方式与文献[2]相同. 3) 1∶N匹配 跨模态1∶N匹配是1∶2 匹配任务的扩展版本,它将不匹配的样本数量扩增至N个.随着N的增大,任务的难度也将不断增大.同样地,1∶N匹配也有2个实验场景,均采用匹配准确率作为评价指标. 4) 跨模态检索 跨模态检索任务中可以有一个或多个样本与给定的查询样本匹配,因而匹配任务难度更大.本文采用随机结果(Chance)作为参照依据,并利用标准的百分制平均准确度(mAP)作为该任务的评价指标. 为了验证本文方法生成的跨模态表示的有效性,本文将其应用于3.3节中提到的4种任务. 1) 跨模态验证 在跨模态验证任务上,本文方法与现有方法的实验结果对比如表1所示.其中,“U”分组中是没有分层的测试数据,“G”分组中每个测试对中的人脸图片和语音数据来自性别相同的2个人,“N”分组中每个测试样本对中的人脸图片和语音数据来自国籍相同的2个人,“A”分组中每个测试对中的人脸图片和语音数据来自年龄相同的2个人,“GNA”分组中每个测试对中的人脸图片和语音数据来自性别、国籍、年龄均相同的2个人. Table 1 Comparison with Other Methods on Verification Task 从实验结果可以得到,本文方法在各个分组上的各项指标几乎全面超越了现有方法,取得了较好的跨模态验证结果.例如,本文提出方法在“U”“N”“A”上取得了优于现有方法的跨模态验证结果.同时也注意到,相比其他分组,本文方法和其他方法在“G”分组中的表现都稍弱,这说明性别信息对模型执行跨模态验证任务有较大影响. 2) 1∶2 匹配任务 在1∶2 匹配任务上,本文方法与现有方法的实验结果对比如表2所示.实验结果中1∶2 匹配任务包含“F-V”和“V-F”2个跨模态匹配场景,并且“U”“G”“N”和“GN”代表的含义与本节跨模态验证部分描述一致.本文方法在这2个场景中的表现均优于现有方法,表明本文方法具有较好的鲁棒性. Table 2 Comparisons on 1∶2 Cross-Modal Matching Task表2 跨模态1∶2 匹配任务上的实验对比结果 % 3) 1∶N匹配 图 4 展示了本文方法与现有方法在1∶N匹配任务上的实验结果对比.从实验结果可以看到,本文方法无论是在“F-V”匹配任务上还是在“V-F”匹配任务上均轻松超越现有方法.当N取较大值时,本文方法表现仍然比其他方法好,表明本文方法相比其他方法可以更好地解决一些比较困难的任务. Fig. 4 Comparisons with other methods on 1∶N matching task图4 不同方法在1∶N匹配任务上的实验结果对比 4) 跨模态检索 表3展示了本文方法与现有方法在跨模态检索任务上的实验结果对比.从实验结果中可以看出本文方法在模态检索任务上的表现远远超过随机水平,并优于现有的对比方法.因此,实验结果充分表明本文提出模型能够有效学习人脸-语音间的语义关联.同时,本文方法在“F-V”和“V-F”检索场景中的表现均优于现有方法,表明了本文方法的优越性. Table 3 Comparison with Other Methods on Cross-modal Retrieval Task 跨模态检索任务是1∶N匹配任务的拓展,旨在将候选样本规模从N个(本文实验中N≤5)扩展到整个测试集,同时候选样本中匹配样本数量Nm也从一个增加到若干个(1 在测试集上执行的4个基于人脸-语音的跨模态匹配任务中,本文方法几乎全面超越现有方法,表明本文方法拥有很好的泛化性能.为了进一步验证采用本文方法得到的跨模态表示的有效性,首先,本文从测试集中随机挑选了8个人,每人挑选40条语音数据;接着,使用训练好的模型提取它们的特征;最后,采用t-SNE[24]技术对提取的特征进行可视化,可视化结果如图5所示.可以看到,同一个人的语音样本对应的语音特征聚到了一起,不同人的语音样本对应的语音特征相距较远,表明采用本文方法提取到的跨模态表示具有较好的判别性和可分性. Fig. 5 Visualization of the deep voice embeddings图5 语音深度特征可视化结果图 为了探究本文提出的多模态加权残差网络、双向五元组损失以及其中的超参数对模型最终表现的影响,本文针对跨模态验证、1∶2 匹配、1∶3匹配以及跨模态检索任务设计了一系列消融分析实验. 为探究多模态加权残差网络(MWRN)对模型表现的影响,本文分别用单层全连接(SFC)、双层全连接(DFC)以及引入残差连接的双层全连接网络(DFC-R)替换MWRN进行实验,在4个不同任务上的实验结果如表4所示.可以发现,当把全连接层数由1层增加到2层时,模型表现有所下降,表明更深的网络可能更难训练和优化;引入残差连接后模型的表现有大幅提升,表明残差连接可以很好地解决上述问题;接着在残差连接中引入可学习的缩放因子后,模型表现又有一定幅度的提升,表明可学习的缩放因子可以进一步地减轻网络训练的难度,建立更有效的跨模态关联,进而促使网络收敛到更优的值. 表4 Cross-modal Matching Performance Performance Under Different Network Settings 本节将探讨本文提出的双向五元组损失(Bi-Q损失)和ID损失对模型表现的影响.图6展示了本文模型采用不同损失函数训练时在验证集上的1∶2 匹配任务准确率在前15轮的变化曲线. Fig. 6 Performance of our method with different loss图6 采用不同损失函数时本文模型的表现 可以看到,单独采用ID损失时,随着训练轮数的增加,模型表现虽然总体呈稳定上升趋势,但最终表现并不是特别好;单独采用双向五元组损失时模型并不收敛;当把ID损失与双向五元组损失结合起来使用时,模型很快就收敛了,并取得了不错表现,表明在模型训练过程中嵌入身份ID信息可以保证模型训练过程的稳定性,促进模型收敛. 本节探讨五元组损失中间隔m的取值对模型表现的影响.图7展示了当m取不同值时模型在4个不同跨模态匹配任务上的表现. Fig. 7 Performance of our method with different m图7 间隔m取不同值时模型表现 从实验中可以看到,当m=0.6时本文提出的模型的表现最佳,同时,对于每个跨模态匹配任务,当m取不同的值时模型表现的波动范围很小,表明本文方法受m取值的影响并不大,具有较好的稳定性. 针对跨人脸-语音匹配挑战性问题,本文提出了一种结合双流网络和双向五元组损失的跨人脸-语音特征学习框架,使用该框架学到的跨模态特征可直接应用于多种人脸-语音的跨模态匹配任务.在公开名人多模态数据集上的实验结果表明:本文提出的网络模型能够对不同场景下名人影像数据进行跨模态标注,效果显著,取得了对面部姿态变化和样本多样性的鲁棒性,并在这些任务上的表现几乎全面超越了现有方法,实验验证了本文提出方法的有效性.另外,除了人脸和语音2种模态外,本文方法预期也同样适用于其他类型的视听媒体样本进行跨模态匹配. 作者贡献声明:柳欣负责算法设计与实验;王锐负责模型优化和编码;钟必能负责模型可行性分析;王楠楠负责实验的多样性分析.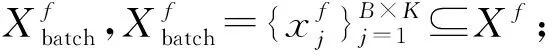
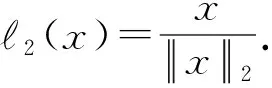
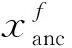
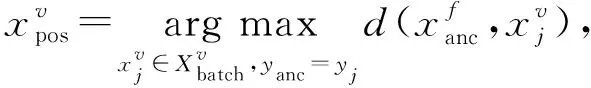
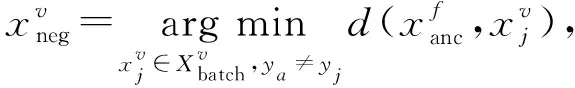
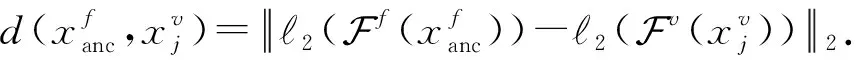
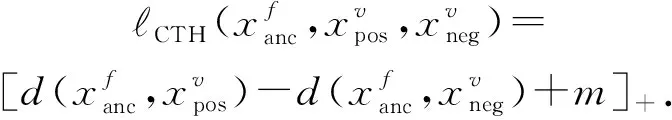
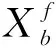
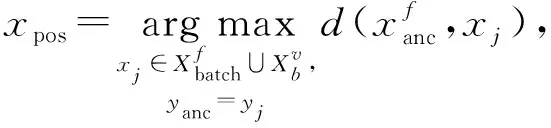
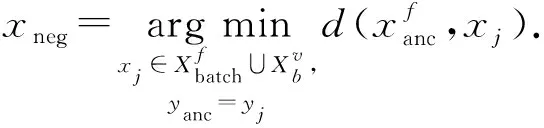

[d(,xpos)-d(,xneg)+m]+.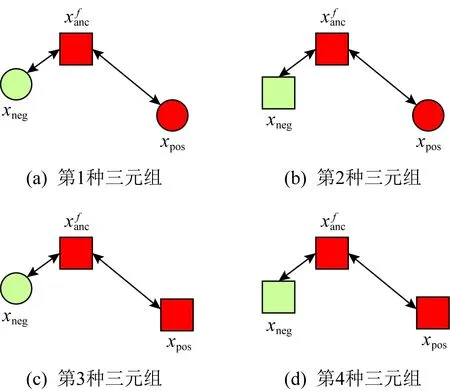
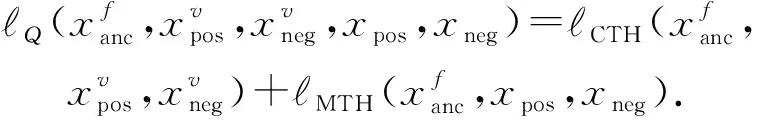
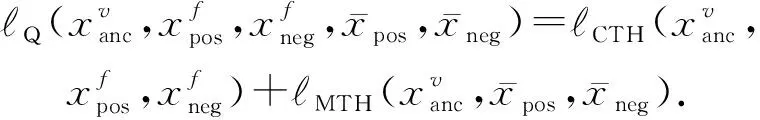
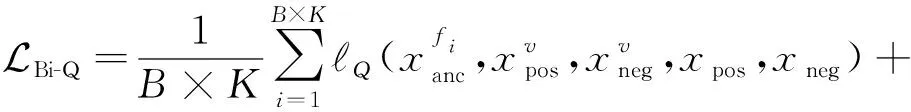
2.4 ID损失
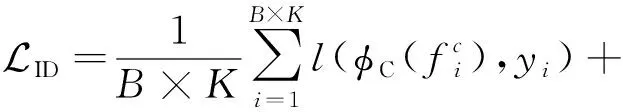

2.5 模型训练
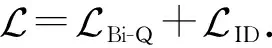
3 实验与结果
3.1 数据集介绍
3.2 实现细节
3.3 实验场景及评价指标
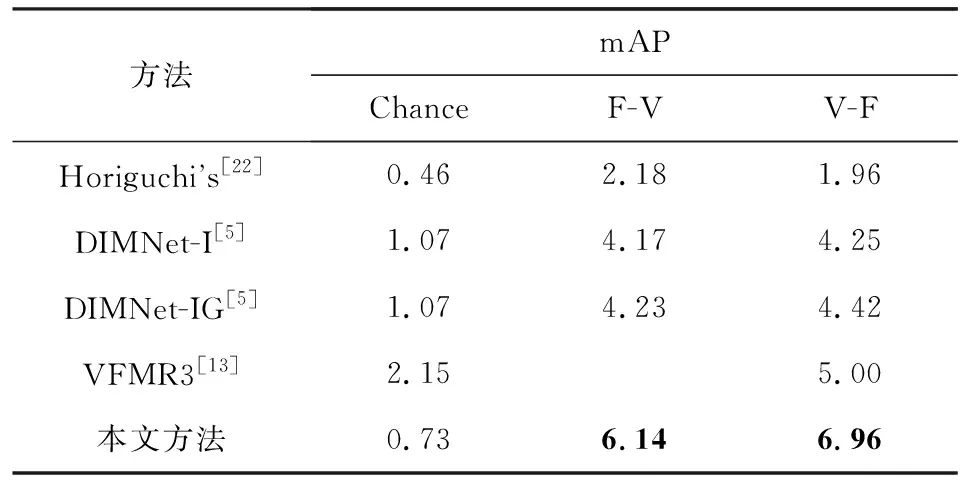
3.4 实验对比结果
4 消融分析
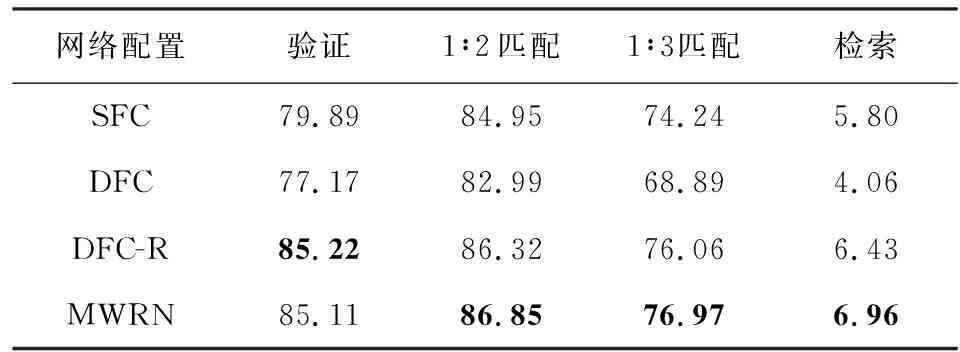
4.1 多模态加权残差网络的影响
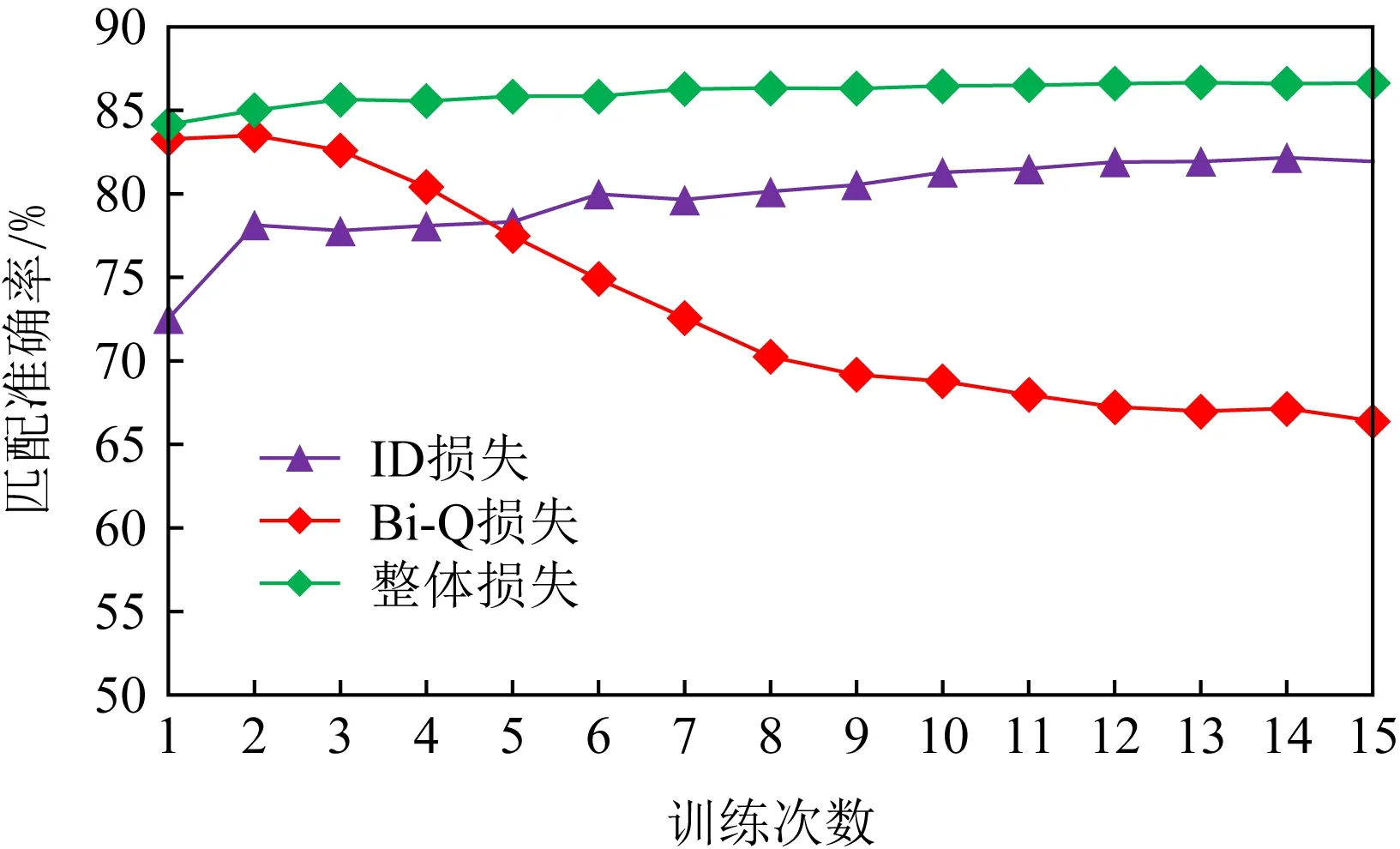
4.2 各项损失函数的影响
4.3 间隔m取值的影响
5 结 论
