DMFUCP:大规模轨迹数据通用伴随模式分布式挖掘框架
2022-03-09张敬伟刘绍建
张敬伟 刘绍建 杨 青 周 娅
1(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)
2(广西自动检测技术与仪器重点实验室(桂林电子科技大学) 广西桂林 541004)
具有定位功能的移动设备的普及使用,轨迹数据呈现爆炸式增长,例如日本大阪的ATC购物中心[1]在2012年10月28日的1天内能记录下4 000万以上的轨迹点;T-Drive[2]中超过33 000辆出租车在3个月内生成了7.9亿以上的轨迹点,平均采样时间为3.1分钟/点.轨迹数据多为时空序列,被携带有定位装置的移动对象不断以固定的频率产生,蕴含着丰富的价值.在大规模的轨迹中提取出通用伴随模式具有重要的意义,为上层的服务提供了诸多可能.通用伴随模式挖掘可用于改善城市交通状况,通过发现通用伴随模式可以预测某一时间段内某段道路是否会发生交通拥堵,从而提前疏导交通以避免交通拥堵;处于相同通用伴随模式的一组群体往往具有某些相似的特征,通过对这些相似的特征进行挖掘可以提高社会推荐服务;通用伴随模式挖掘在事件调查方面也具有广泛运用场景,通过挖掘的通用伴随模式为寻找事件发生的可能原因提供支持.
伴随模式是指在某一范围内一定数量的运动对象在某一时间段内伴随运动,它具有时间性和空间性.轨迹数据中挖掘伴随模式的方法从实现方案上可分为分布式与单机2类.分布式方案分为数据处理、数据分区和轨迹挖掘3个阶段,单机方案可分为数据处理和轨迹挖掘2个阶段.
现有的研究大多关注于如何在轨迹数据中快速地挖掘出伴随模式,将整个挖掘任务的重点放在轨迹挖掘阶段,对数据处理阶段则采用基于欧氏距离的密度聚类或圆盘聚类.但在现实生活与实践运用中,挖掘出对象间运动方向相似的比运动方向差异大的轨迹更具有实际意义,对基于欧氏距离的聚类方法形成了挑战.如图1所示,采用欧氏距离的聚类方法会将(o1,t3),(o2,t3)聚为一类,但在现实生活中将(o2,t3),(o3,t3)聚为一类更具有意义,因为很可能对象o1与对象o2在岔路口处选择了不同的路,而o3与o2选择了相同的路.亟需一种新的距离度量方式,能实现在扩大对象运动方向上的横向聚类半径的同时缩小纵向聚类半径.
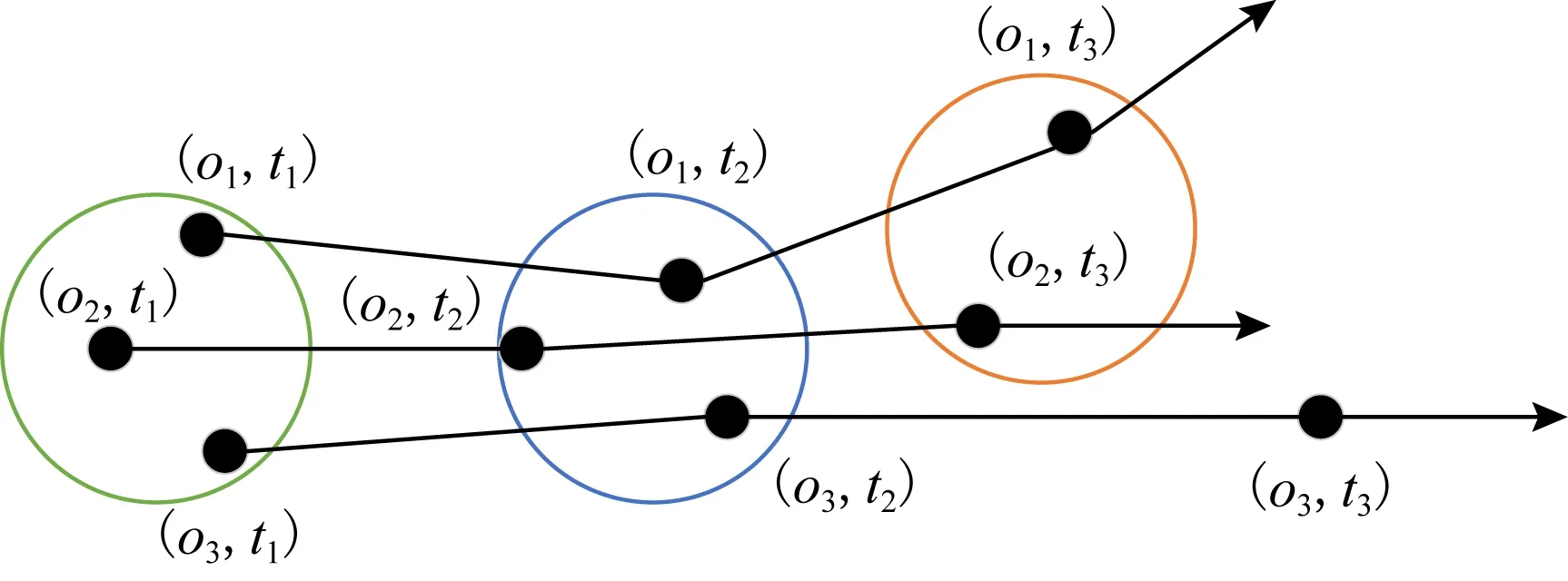
Fig. 1 Unreasonable clustering图1 不合理聚类
伴随模式挖掘中的聚类具有时间相关性,对象在某一时刻的聚类情况与它的上一时刻和下一时刻的聚类情况会对挖掘结果产生影响.由于聚类起始点是随机选取的,每个轨迹点也只能被归为一个簇,所以在聚类过程中会产生一定数量可同时归为不同簇的边界点,现有的工作单纯地按照对象被访问的顺序进行划分,影响了伴随模式挖掘的质量.怎样合理地划分边界点对聚类算法形成了挑战.如图2所示,对象o2和对象o3为核心点,对象o1为边界点,对象o1可同时处于对象o2与o3所属的簇,怎样合理地划分o1对于伴随模式挖掘具有重要意义.
如图3所示,不同的颜色灰度表示不同的伴随模式,在现实生活中会存在这样一种现象,大量的轨迹会集中式地经过一些公共场所,如超市、加油站等,需要伴随模式挖掘算法去积极地识别它.GCMP(general co-movement pattern)将这种现象定义为松散连接,通过设置参数G来避免它,处理效果不好.现实生活中它很可能是一种正常现象,因为伴随模式具有时间性,所以对象o2与对象o3很可能处于2种不同的伴随状态.现有的方法并不能去挖掘和区分它们,同时挖掘具有松散连接现象的伴随模式需要扫描整个轨迹,对伴随模式挖掘算法的性能提出了挑战.
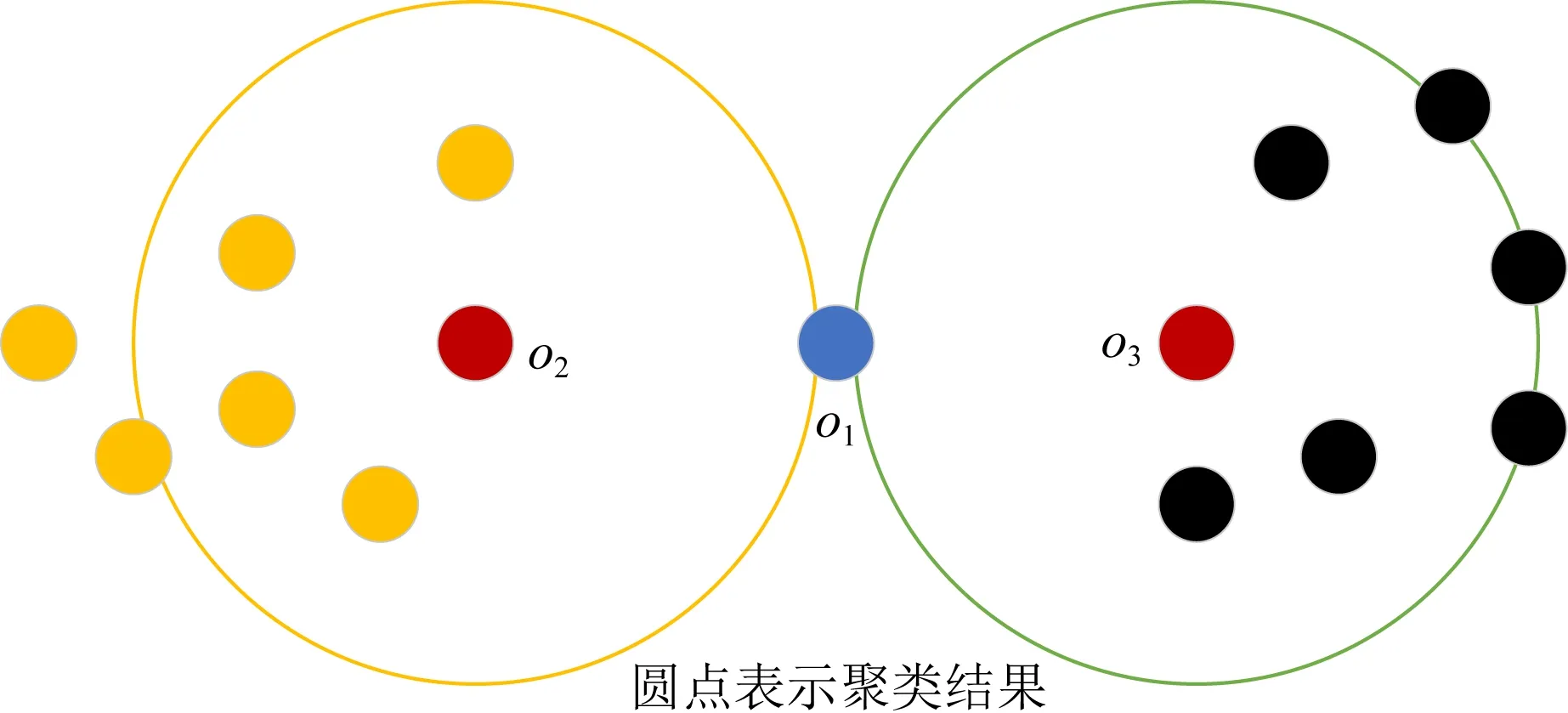
Fig. 2 Cluster boundary points图2 聚类边界点
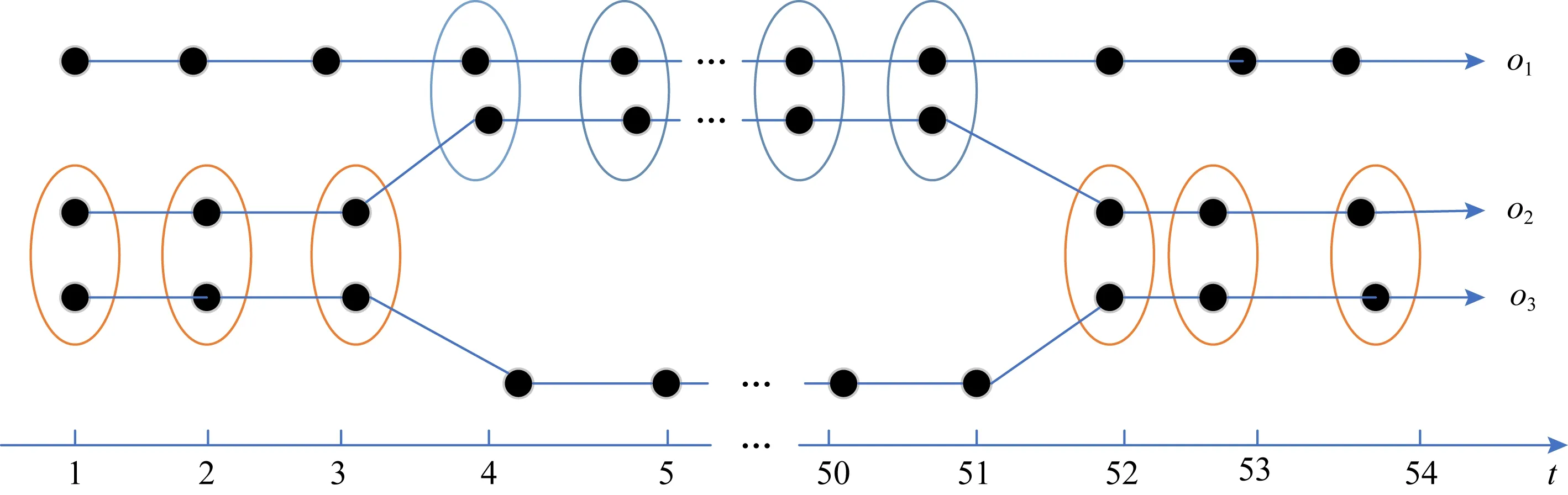
Fig. 3 Loose connections图3 松散连接
针对挑战,本文工作的主要贡献分为3个方面:
1) 在数据处理阶段基于DBSCAN(density-based spatial clustering of applications with noise)提出了DBSCANCD(DBSCAN based on cosine distance between two points)算法和TCB(time-dependent clustering balance)算法,DBSCANCD算法通过使用CDAP(cosine distance of the angle between two points)对轨迹点进行密度聚类,可以有效地扩大相似于对象运动方向上的轨迹点发现,同时减少与对象运动方向差异大的轨迹点发现.TCB算法以密度聚类结果作为输入,根据每一快照下的每个边界点形成一个边界点划分集合,通过计算集合成员间的相似度,对边界点进行合理划分.聚类平衡算法采用贪心策略的思想,每次计算尽最大可能划分更多边界点,以取得局部最优解.
2) 在挖掘阶段提出了GSPR(Gsegment pruning and repartitioning)算法和SAE(segmented apriori enumerator)算法,通过对分区数据进行G分段剪枝和重划分来有效地挖掘具有松散连接现象的通用伴随模式,同时保证SAE算法的性能.
3) 基于DBSCANCD,TCB,GSPR,SAE这4个算法提出了DMFUCP.DMFUCP利用负载均衡及合适的Map和Reduce方式降低了Spark进行分布式调度的压力.使用2个真实的轨迹数据集对部署在Spark上的DMFUCP进行了大量实验,本文所提出的DMFUCP在保证性能的同时,具有更强的通用伴随模式发现能力.
1 相关工作
近年来,轨迹数据的伴随模式挖掘已被广泛研究.随着轨迹数据的规模不断增长,如何快速、有效地从大规模轨迹数据中挖掘伴随模式为科学研究提供了动力.本节将主要围绕伴随模式的时间戳约束展开总结分析.
1.1 Flock和Convoy
Flock模式起初是被Laube等人[3-4]提出,只考虑单一时刻移动对象的行为特征,要求在某时刻至少有m个移动对象在同一区域内,并且移动方向相同,该定义不能很好地适应实际应用;Gudmundsson等人[5-6]对Flock模式提出了新的定义,即Flock模型,并形式化为flock(m,k,r);Jeung等人[7]发现已有的方法不能准确地检索出Convoy模式,在现有的基础上采用著名的过滤-细化框架开发了3种有效的Convoy发现算法,并使用线性简化方法[8]近似模拟原始轨迹,在数据库查询中发现Convoy模式;Orakzai等人[9]发现传统的Convoy挖掘方法需要对每个快照进行DBSCAN聚类,在大数据集上消耗的时间成本过大,于是提出了k/2-hop算法来高效地挖掘Convoy模式;Calders等人[10]提出了一种分布式挖掘算法DCM(distributed convoy mining)来发现Convoy模式,DCM算法基于分而治之策略且独立于任何数据处理框架,Calders等人还在Hadoop上实现了基于DCM算法的DCMMR框架.
Flock模型预先定义了区域形状和群体大小,不能很好地适应实际.为了解决在伴随模式挖掘中对移动对象群体大小和形状的限制,Convoy模型采用密度聚类来挖掘任意形状的轨迹,从而避免受预先定义的空间阈值限定.Flock和Convoy模式要求每个检测到的聚类组的所有快照都连续.
1.2 Group,Platoon,GCMP
Wang等人[11]提出了AGP(apriori-like algorithm for mining valid group patterns)和VG-growth(a valid group graph)算法来挖掘由距离阈值和最小持续时间确定的Group模式,并发现AGP和VG-growth[12]算法的性能较低,后研究发现在伴随模式挖掘前对原始轨迹数据进行摘要可以大幅度地提升AGP和VG-growth算法的性能;Bailey等人[13]提出了一种Platoon挖掘算法PlatoonMiner,使用频繁连续剪枝、对象剪枝、子集剪枝和通用前缀剪枝方法来减少搜索空间;由于现有的工作对伴随模式的定义种类繁多,Fan等人[14]提出了GCMP模式,并给出了TRPM(temporal replication and parallel mining)和SPARE(star partitioning and apriori enumerator)两个算法来挖掘GCMP模式,GCMP模式包含了4个可调参数M,K,L,G.通过对4个参数的调节可以将GCMP变换为Flock,Convoy,Group,Platoon等不同模式.同时,TRPM和SPARE这2个算法被部署在基于内存计算的Spark分布式平台上.Group,Platoon,GCMP模式使用了折中的时间戳约束方案,即局部连续.
1.3 Swarm和Traveling companion
Li等人[15]设计了ObjectGrowth算法来有效地检索封闭的Swarm模式,ObjectGrowth算法中使用了2种有效的剪枝策略减少搜索空间,并提出了一种新的闭包检查规则,用于动态检索封闭的Swarm.相对于Flock和Convoy模式,Swarm允许在一定时间内,移动对象在任意形状区域内一起移动而时间不要求连续.由于在Convoy和Swarm模式挖掘过程中需要将整个轨迹加载到内存中,Zheng等人[16-17]提出了Traveling companion模式,使用一种traveling buddy的数据结构来不断地从进入系统的轨迹中找到Convoy和Swarm模式.Traveling companion更像是一种在线的Convoy和Swarm模式检测方式.Swarm和Traveling companion模式不要求时间戳连续.
1.4 Gathering
为了检测某些事件,如庆祝和游行这类运动对象会频繁地加入和离开的事件,Zheng等人[18-19]提出了Gathering模型.Gathering模型用于检测事件时还要求检测到的事件的几何属性相对稳定,如位置和形状.
2 问题定义
本节给出一些参数和基本术语,如表1所示:

Table 1 Symbol Definition List表1 符号定义列表
本文主要研究的是怎样有效地在大规模轨迹数据中挖掘伴随模式,伴随模式具体定义:
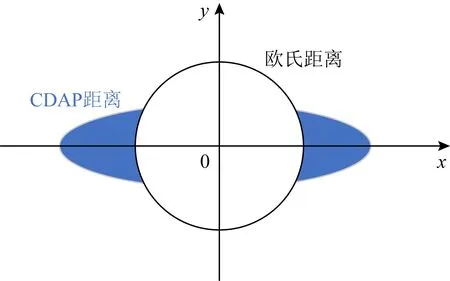
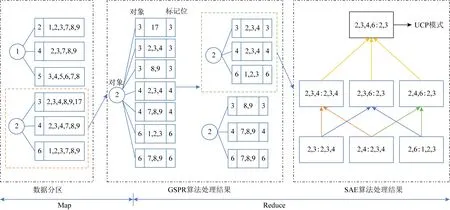
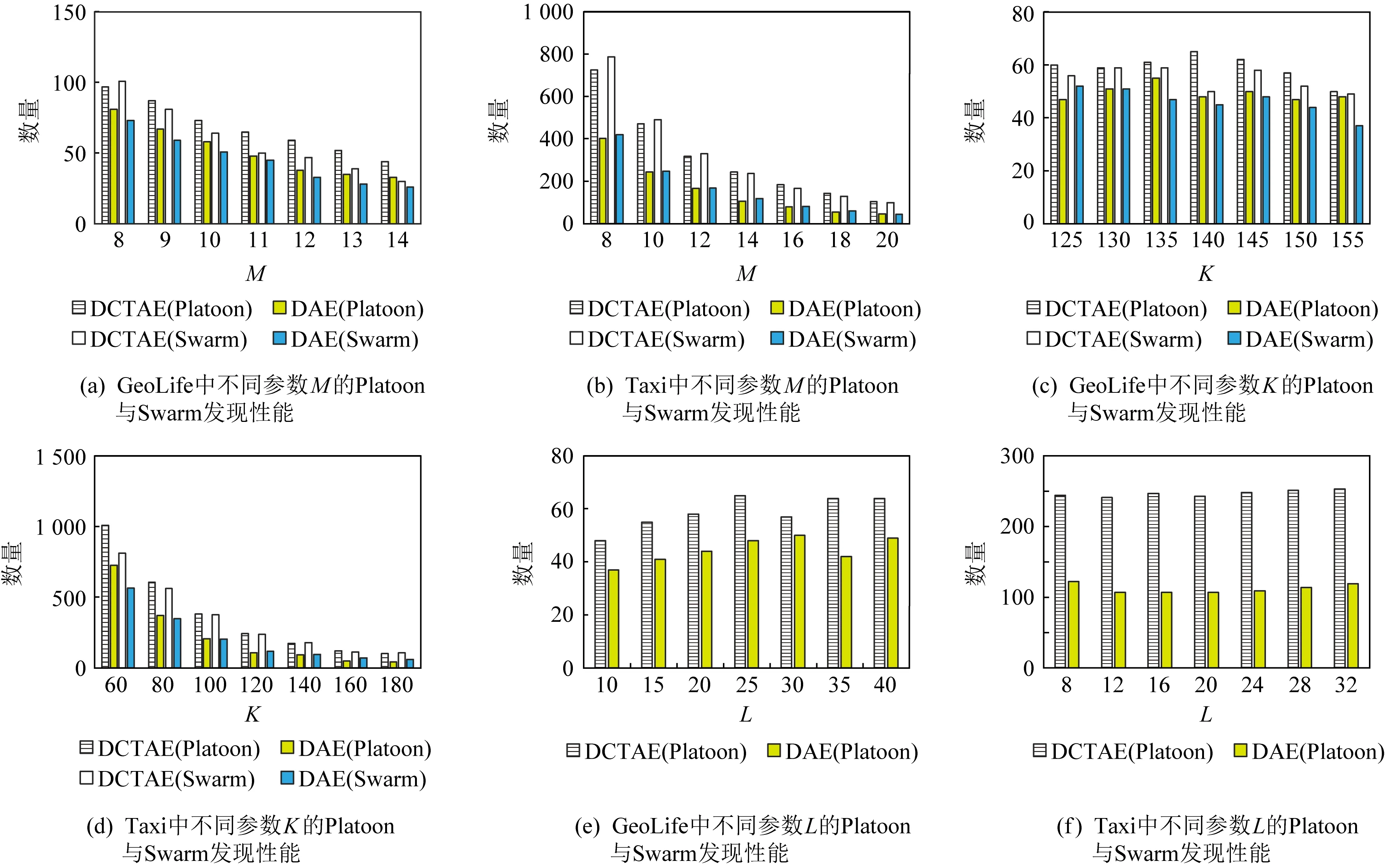
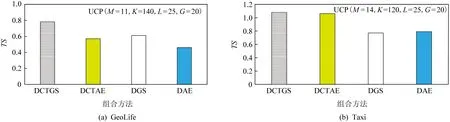
定义1.通用伴随模式(universal companion pattern, UCP).给定对象集O={o1,o2,…,on},聚类簇集C={c1,c2,…,cn},(oi,ti,i)∈ci,通用伴随模式UC={Os,TUs},其中Os⊆O,TUs=ti,tj,…,tn,i UCP具有5个约束,其中第1个约束包含距离和方向2个基本约束,即需要在方向参与计算得出的距离满足要求的1组轨迹才具有构成通用伴随模式的基本条件,第2~5个约束通过参数的形式进行调节以适应不同条件下的伴随模式.例如G=1时UCP转变为Convoy和Flock,这使得UCP能更好地适应现实生活.与已有的研究不同,本文的参数G还将用于GSPR算法中的长轨迹分割. Fig. 4 Distributed clustering and cluster balance framework图4 分布式聚类及聚类平衡框架 下面给出一个实例来理解UCP.当G=2,K=3,M=3,L=2时,给定一个UCP为UC={Os,TUs},TUs=(1,2,4,5,9,10,11,18),Os=(1,2,4,5),聚类簇集C={(Os,1,1),(Os,2,3),(Os,4,7),(Os,5,10),(Os,9,2),(Os,10,4),(Os,11,6),(Os,18,8)},根据定义1及参数G可以得到2个符合条件的UCP,分别为UC1={Os,(1,2,4,5)},UC2={Os,(9,10,11)}. 定义2.相邻轨迹点线段(adjacent trajectory point line segment, ATPS).给定轨迹P=p1,p2,…,pn,其中pn=(xn,yn,tn),xn为pn的经度,yn为pn的纬度,tn为pn的时间戳,ATPS表示为pS(i)=T[pi:pi+1],当且仅当pi+1-pi≤Δt. 定义3.ATPS方向向量,即pVector.给定轨迹T=p1,p2,…,pn,则pVector表示在以0经度线和0纬度线构成的二维坐标中运动对象在相邻时刻的运动向量,轨迹T在时刻i的pVector表示为 pV(Ti)=(xi+1-xi,yi+1-yi). (1) (2) 聚类操作对于轨迹数据的模式挖掘具有十分重要的作用,但聚类操作也占据了模式挖掘整个过程的大量时间.随着轨迹数据规模的快速增长,基于单机模式的挖掘框架很难直接扩展.现有的解决方式通常采用分布式方案,分布式可以将互不影响的各个任务并行执行,从而达到成倍的速度提升.轨迹数据的UCP挖掘具有时间相关性,分布式挖掘UCP,首先需要对每个快照下的所有对象进行聚类操作,在现实生活中,整个轨迹数据集往往具有成千上万的快照数,甚至更多,并且快照数和数据量随时间在不断地增长,对这些数据进行聚类所需要的时间十分庞大.分析发现,每个快照下的轨迹聚类操作互不影响,采用分布式聚类可以为整个模式挖掘任务节省大量时间.图4显示了本文提出的轨迹数据分布式聚类及聚类平衡的基本框架,整个框架包含Map和Reduce这2个阶段.图4显示了输入的原始轨迹、DBSCANCD算法聚类后的结果、TCB重划分边界点后的结果. 现有的大部分研究均采用基于欧氏距离的DBSCAN算法,DBSCAN算法并不考虑对象的运动方向,只考虑距离这一单一维度,使大量无实际意义的轨迹点被聚类.DBSCANCD是一种基于密度聚类的算法,它同时考虑了对象运动方向和距离2个维度,并且引入了可调参数σ,参数σ主要受城市道路的弯曲角度和城市道路岔路口角度2个因素影响. DBSCANCD使用了考虑运动方向和距离2个维度的CDAP度量方式,下面给出了CDAP距离的定义及计算方式: (3) (4) Fig. 5 The relationship between CDAP and Euclidean distance图5 CDAP距离与欧氏距离的关系 DBSCANCD算法可以发现任意形状的聚类区域,与DBSCAN算法不同,DBSCANCD算法的单一聚类区域不再是圆形,而是一个近似椭圆的扁平状区域.当σ=0.5时,图6显示了欧氏距离与CDAP距离在单一聚类区域上的差异,可以发现,CDAP距离所形成的聚类区域更为扁平,单一聚类区域更加偏向于对象的运动方向. Fig. 6 Comparison between Euclidean distance and CDAP single cluster area图6 欧氏距离与CDAP距离单一聚类区域对比 定义6.聚类边界点(boundary point).给定对象集O=o1,o2,…,on,聚类簇集C=c1,c2,…,cn,其中(oi,ti,i)∈ci,∃ok∈ci,∃ok∈ck,则ok为聚类边界点. 算法1.DBSCANCD算法. 输入:轨迹数据集合Si、聚类半径ePs、最小簇基数minPts、向量夹角阈值angle; 输出:聚类结果集cluster、边界点集BPSet. ①cluster←0,BPSet←∅,CI←1; ②CrDis←ePs/angle; ③ forsjinSi ④ ifsj没被访问 ⑤sj←Visited; ⑥C←DCDAP(sj,Si); ⑦C′←C.filter(0≤distance≤ePs); ⑧ if |C′|≥minPts ⑨C′←C′-sj; ⑩cluster(j)←CI; ePs); 算法1中,步骤①②对聚类结果集、边界点集、CDAP的临界值和簇号进行了初始化;步骤⑥⑦根据定义5进行了2点间的CDAP距离计算,并根据ePs参数对计算结果进行筛选;步骤~对C′进行了广度优先遍历,找出与sj属于同一簇的所有对象;步骤将满足|W′|≥minPts的所有W′成员添加到C′,以更新C′;步骤~得到了边界点e,并添加到BPSet集中. 在对轨迹数据进行密度聚类时,聚类算法通常会从所有对象集中随意挑选一个对象作为聚类的起始点,不断地遍历对象集中没有被访问过的对象.现有的聚类算法遵照先后顺序对每一个符合要求的轨迹点进行聚类,并将其归入某一簇中,然后将被归入簇中的点从对象集中删除.但对象集中往往存在一些这样的对象,它们可以同时满足超过2个簇的聚类条件,即定义6中的聚类边界点.轨迹数据的UCP挖掘具有时间相关性,对象在相邻时刻的聚类情况与它当前的聚类情况存在联系.单纯的按照先后顺序对边界点进行划分存在合理性问题. 定义7.边界点生成集(boundary point generating set).给定边界点i,边界点i同时满足聚类条件的聚类簇集C,|C|≥2,ck,cn∈C,i的边界点生成集BPC(i)可表示为 (5) 定义8.集合间相似度集(similarity set between sets).给定边界点i的边界点生成集BPC(i),BPC(i)的集合间相似度集SBS(BPC(i))为 (6) (7) 定义9.最大集合间相似度(maximum similarity between sets).给定边界点i的边界点生成集BPC(i),BPC(i)的集合间相似度集SBS(BPC(i)),BPC(i)的最大集合间相似度MSBS(BPC(i))为 MSBS(BPC(i))=max(SBS(BPC(i))). (8) TCB算法很好地改善了边界点合理划分问题,与现有的单纯按照对象访问顺序划分聚类边界点相比,TCB算法通过计算边界点i的BPC(i)的MSBS(BPC(i))值来确定i被划分到哪个簇更为合理.为了防止当前时刻和相邻时刻边界点i所属的簇中包含其他边界点而导致BPC(i)被递归计算,同时考虑到边界点i在相邻时刻均为边界点的情况,TCB算法采用贪心策略的思想,在处理边界点i的划分问题时,如果边界点i在相邻时刻同为边界点,则将相邻时刻边界点i同时满足的簇的所有成员添加到BPC(i),如果边界点i的当前时刻和相邻时刻存在其他边界点,则将它们仅在当前计算中视为非边界点.采用贪心策略的TCB算法可以减少边界点处理的次数,同时获得一个边界点合理划分的局部最优解. 算法2.TCB算法. 输入:所有快照下的聚类结果集CR、边界点集CP、最小簇的基数minPt; 输出:平衡聚类结果集CB. ①S←0; ②CB←CR; ③ if |CP|<1 ④ 输出CB; ⑤ end if ⑥ whileCP≠0 ⑦q←CP的第1个元素; ⑧CP←CP-q; ⑨M←SBS(BPC(q)); ⑩ ifM中的成员不相等 在大规模轨迹数据中挖掘满足要求的UCP是一项十分耗时的任务,轨迹数据中往往具有成千上万的运动对象,为了挖掘UCP就不得不遍历所有的对象.在成都Taxi数据集中,包含120 000以上条长轨迹和19 000多个快照,如果通过直接遍历它们挖掘UCP,即使采用各种剪枝技术,挖掘UCP所花费的时间也是十分庞大的.随着信息时代的不断发展,计算资源也取得了快速增长.分析发现,对每个运动对象进行UCP挖掘可以同时进行而不产生干扰,只需为挖掘任务分配更多的计算资源便可实现性能的成倍增长.将UCP进行分布式挖掘可以实现挖掘任务的并行执行,如图7所示,本文设计了一种高效的分布式UCP挖掘框架,实现了挖掘性能的提升,框架包含Map和Reduce这2阶段.图7显示了已分区的数据、GSPR算法的切分、剪枝和重划分的过程、SAE算法的挖掘过程. Fig. 7 Distributed companion pattern mining framework图7 分布式伴随模式挖掘框架 轨迹数据中存在大量的松散连接现象,表现为对象在2次形成聚类现象之间相隔了相当长的一段时间.为了高效地挖掘处于松散连接状态下不同的UCP,本文设计了GSPR算法,GSPR算法使用自定义参数G实现对存在松散连接现象的长轨迹的切分,并为属于同一条长轨迹的每个分段添加一个相同的标记以避免重划分过程的重复计算.GSPR算法使用自定义参数K对每一个分段进行初步剪枝,在完成初步剪枝后,使用自定义参数L和K同时对分段进行剪枝,在剪枝完成后将对每个分段进行重划分.最终,大量的长轨迹将被划分成一个包含相互独立的子轨迹群,下面给出子轨迹群的具体定义. 算法3.GSPR算法. 输入:星型分区数据Star,G,M,K,L; 输出:相互独立的STG集STGS. ① forSrinStar ② if |Sr中的所有时间点|≥K ③S←使用G划分Sr中的时间点; ④ forsiinS ⑤ if |si|≥K ⑥N←(Sr.O,si,label); ⑦ end if ⑧ end for ⑨ end if ⑩S←∅; nj.label 算法3中,步骤②使用K对星型分区的每条长轨迹进行首次过滤;步骤④~⑨首先使用参数G对长轨迹进行分割,并对分割后的各个分段使用K进行二次过滤,最后给每条长轨迹的每个分段添加相同的标记;步骤~使用参数L和K进行剪枝,并得到了候选的子轨迹群W;步骤~使用参数M对候选的子轨迹群W进行过滤,最终得到有效的子轨迹群并添加进STGS. SAE算法将GSPR算法输出的STGS作为输入,STGS中的每一个STG都相互独立,为了充分利用计算机的多线程特性,本文将SAE算法中加入多线程特性,以提高从STGS中挖掘UCP的效率.一条长轨迹往往携带着诸多的运动信息,它可能与不同的或相同的长轨迹集合在不同的时刻形成伴随状态,虽然现有的方法采用前向闭包检测能有效地提高挖掘任务的时间效率,但也导致了长轨迹的部分伴随信息丢失.SAE算法与现有挖掘算法一样,对每一个线程中的挖掘任务进行前向闭包检测,从而提前结束挖掘任务.但与现有方法不同的是,SAE算法不会错过长轨迹的伴随信息,SAE算法的输入STGS能保证伴随信息的不流失,同时提高SAE算法对UCP的挖掘效率. 算法4.SAE算法. 输入:星型分区数据Star,G,M,K,L; 输出:通用伴随模式UP. ①STGS←FGSPR(Star,G,M,K); ②UP←STGSMap(C′→UCPMinning(C′)); ③ 输出UP. 函数UCPMinning(C′): ① whileC′≠∅ ②Ou←C′.O的并集; ③Ti←C′.T的交集; ④ if ∃|Ti[m:n]|≥L并且∑(|Ti[m:n]|)≥K并且|Ou|≥M ⑤UP′←(Ou,Ti); ⑥ break; ⑦ end if ⑧ forciinC′ ⑨ forcjinC′ ⑩temp←ci.T∩cj.T; |temp|≥K 算法4中,步骤①调用了GSPR算法获得了子轨迹群集STGS;步骤②SAE算法对STGS结果进行了Map,即SAE开启了多线程;步骤④定义了一个UCPMinning函数,输入为子轨迹群集,输出为UCP;步骤⑥~对UCP的候选集进行前向闭包检测,如果(Ou,Ti)为UCP,则提前终止当前线程并输出结果;步骤~是SAE算法通过遍历子轨迹群来持续更新候选集CA. 5.1.1 环境设置 实验采用4台Dell服务器,每台服务器拥有128 GB RAM、56个CPU内核(Intel®Xeon®Gold 5117 CPU @2.00 GHz). 4台服务器上一共部署了26个节点,其中包括25个子节点和1个主节点.主节点拥有32 GB RAM、16个CPU内核和1.5 TB ROM,每个子节点拥有18 GB RAM、8个CPU内核和0.5 TB ROM.集群系统采用Centos7,Java虚拟机版本为JDK 1.8,分布式平台采用Spark2.3.0,以Yarn的方式搭建在Hadoop 3.1上,集群的统一部署和可视化采用Apache ambari 2.7,整个UCP挖掘方案使用Scala语言在IDEA 2019.1中实现,并通过Maven3.6.0进行打包上传到Spark集群. 5.1.2 数据集 本文使用了2个真实的轨迹数据集. 1) GeoLife[20-22].该数据集保存了182名用户在2008-04—2012-08的旅行记录.对于每个用户,定期收集GPS信息. 2) Taxi.该数据集是成都市14 795辆出租车超过3亿条GPS记录,时间从2014-08-03—2014-08-12,其中忽略了00∶00∶00—05∶59∶59这一时间段的数据. 5.1.3 预处理 预处理中,本文将运动对象的原始编号进行了重新编号,使编号连续并由1开始.同时本文使用了固定频率(GeoLife数据集为5 s,Taxi数据集为30 s)对2个真实数据集进行了处理,使用线性插值对缺失数据进行填充,同时剔除了小于固定频率的多余数据.在使用DBSCANCD与DBSCAN聚类算法时,本文根据数据集的不同设置了不同的ePs(聚类半径)和minPts(最小簇基数)值,GeoLife采用ePs=30,minPts=8,angle=0.5,Taxi采用ePs=25,minPts=8,angle=0.5.表2显示了本文对2个真实数据集预处理后的结果. Table 2 Data Preprocessing表2 数据预处理 5.1.4 参数设置 为了全面评估DMFUCP挖掘框架对UCP的发现能力及挖掘框架的性能,本文对设置的各个参数进行了实验.表3列出了所有需要评估的参数. Table 3 Parameters and Default Values表3 参数及默认值 由于DMFUCP挖掘框架涉及多个算法,为了便于观察,本文在以下实验对比与分析中为挖掘框架所使用到的算法进行了简化表示,具体如表4所示. 为了更好地比较表4中挖掘框架在挖掘阶段的性能,本文给出了挖掘性能的计算: (9) Table 4 Simplified Representation表4 方案简化表示 Fig. 8 Evaluation of UCP discovery capability by DMFUCP图8 DMFUCP对UCP发现能力评估 5.2.1 DMFUCP的UCP发现能力评估 图8显示了DMFUCP的UCP发现能力在2个数据集上的评估结果. 图8(a)(b)表示随着M的变化UCP发现能力的变化.GeoLife中不同的M对方案的发现能力改变相较于Taxi并不明显,那是因为GeoLife的数据比较稀疏,M的变化并不会对发现能力产生大的变化. 图8(c)(d)表示随着K的变化UCP发现能力的变化.GeoLife中发现能力在不同的K值下表现稳定,而Taxi则对不同K值表现的十分敏感,因为Taxi中的长轨迹包含的快照数要普遍低于GeoLife中长轨迹的快照数. 图8(e)(f)表示随着L的变化UCP发现能力的变化.在2个数据集中不同的L值并未对UCP发现能力产生太大变化,因为在2个数据集中长轨迹的完整度都很高,线性插值补全也起到了作用. 图8(g)(h)表示随着G的变化UCP发现能力的变化.在GeoLife中采用GSPR算法比Taxi表现更好,GeoLife中会对UCP发现能力有2~3倍的提升,而Taxi中会有1~2倍的提升,因为GeoLife中长轨迹更长且存在大量的松散连接现象. 5.2.2 DMFUCP的Platoon与Swarm发现能力评估 图9表示随着M,K,L的变化Platoon与Swarm发现能力的变化.采用DCTAE比DAE的Platoon与Swarm发现能力更好,因为DCTAE扩大了对象运动方向上的对象发现.不同的M,K,L的变化在Taxi上表现得更加明显,且DCTAE相对于DAE对Platoon与Swarm发现能力保持在1.7倍左右,因为Taxi中存在的边界点多于GeoLife. 5.2.3 DMFUCP性能评估 图10(a)(b)显示了DAE,DCTAE,DGS,DCTGS Fig. 9 The evaluation of Platoon and Swarm’s discovery capability by DMFUCP图9 DMFUCP对Platoon和Swarm发现能力评估 Fig. 10 TS evaluation of DMFUCP图10 DMFUCP的TS评估 在默认取值的状态下对GeoLife与Taxi中的UCP发现性能.DCTGS和DCTAE的TS均高于基准框架DAE,因为它们发现UCP数量的提升要大于时间消耗的提升.Taxi中DGS的TS略低于DAE,因为Taxi中存在的松散连接现象并不多,这导致DGS发现UCP数量的提升要小于时间消耗的提升. 本文主要围绕在保证挖掘框架性能的同时提高对UCP的发现能力,因此,基于DBSCANCD,TCB,GSPR,SAE这4个算法提出了DMFUCP挖掘框架来达到本文的目标,DBSCANCD与TCB分别通过扩大有意义点的发现和合理划分聚类边界点来提高通用伴随模式挖掘输入数据的质量,GSPR算法通过G对通用伴随模式挖掘的输入进行分割和重划分,在过滤无用信息的同时提高挖掘算法对UCP的发现能力,SAE算法则使用多线程和前向闭包使挖掘过程的时间消耗大大降低.实验结果证明DMFUCP挖掘框架在UCP的发现能力和TS上均得到了提升.下一步工作将应用DMFUCP挖掘框架处理轨迹数据流,提升从轨迹数据流中发现UCP的能力和性能. 作者贡献声明:张敬伟负责提出研究选题、组织建议模型论证分析、优化论文;刘绍建负责细化算法、设计实验并开展实验分析;杨青负责调研整理文献、模型验证优化和设计论文框架;周娅负责修订和完善论文.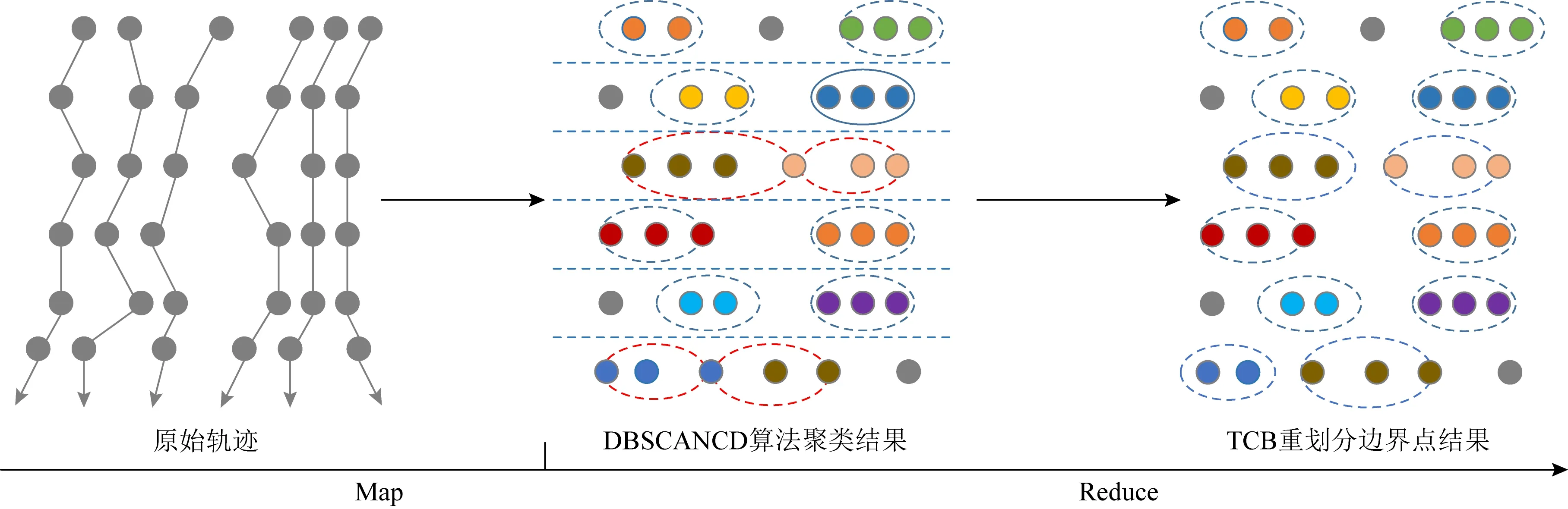
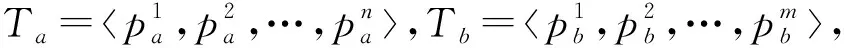
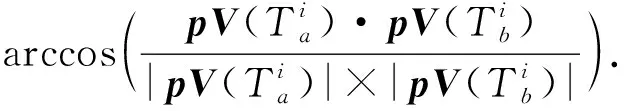
3 分布式聚类及聚类平衡框架
3.1 DBSCANCD算法
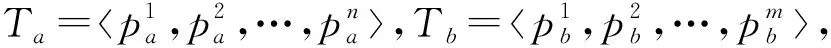
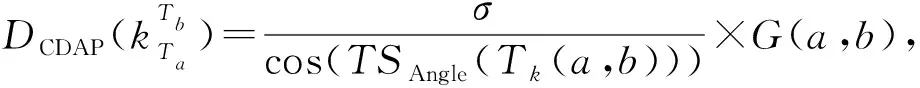
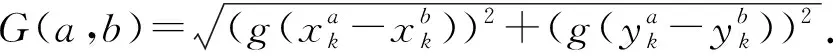
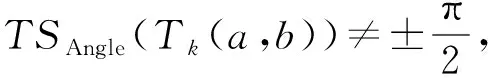

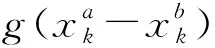
3.2 TCB算法
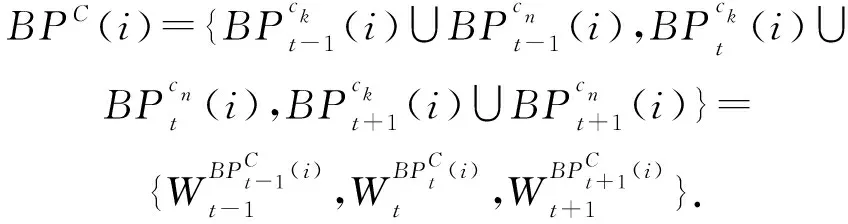
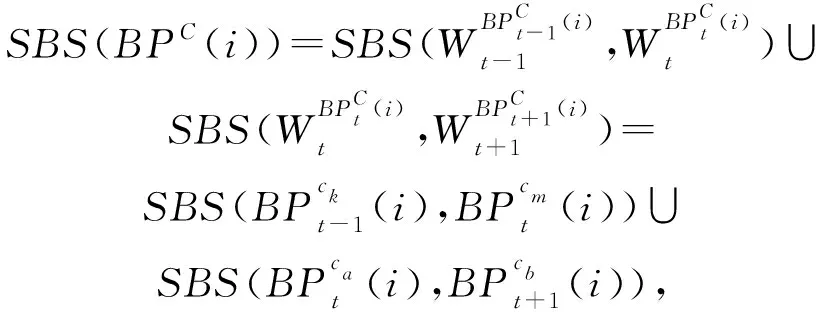
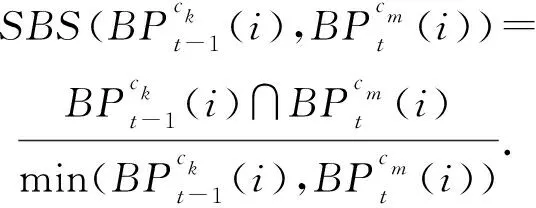
4 分布式UCP挖掘框架
4.1 GSPR算法
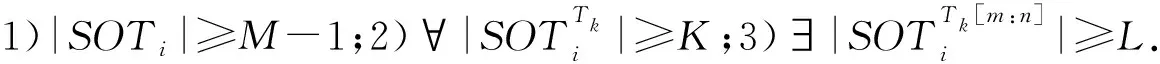
4.2 SAE算法
5 实验及分析
5.1 实验信息

5.2 实验对比及分析



6 总 结
