基于DRAM牺牲Cache的异构内存页迁移机制
2022-03-09裴颂文钱艺幻叶笑春刘海坤孔令和
裴颂文 钱艺幻 叶笑春 刘海坤 孔令和
1(上海理工大学光电信息与计算机工程学院 上海 200093)
2(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
3(华中科技大学计算机科学与技术学院 武汉 430074)
4(上海交通大学计算机科学与工程系 上海 200240)
在大数据技术快速发展的当下,传统的随机动态存取存储器(dynamic random access memory, DRAM)逐渐暴露出其局限性,如存储密度小、带宽有限、能耗大等[1-3],揭示了传统DRAM无法满足越来越大的内存需求.因此,为了解决这一问题,近年来涌现的非易失性存储器(non-volatile memory, NVM)[4-7]被广泛关注,并与DRAM组成异构内存系统[8-11],大量研究围绕非易失性内存和异构内存展开[12-15].NVM拥有比DRAM更大的存储密度,无静态能耗,即不需要反复刷新保存数据,从而成为构建主存的理想存储设备.
然而,与传统DRAM相比,NVM同样具有写操作时延高、耐久性差、写操作能耗高等缺点.以相位存储器(phase change memory, PCM)为例,相比简单的电荷移动,PCM需要更多的能量来改变相变材料(基硫族化合物)内部的原子结构.另外,PCM的写入时延大约是DRAM写入时延的10倍.更详细的DRAM与部分NVM的特性对比如表1所示.因此,当DRAM和NVM构成异构内存时,应将访问频率更高的“热”内存页存放在DRAM中,而将“冷”内存页存放在NVM中,如此,系统便可以同时兼备NVM和DRAM两者的性能优势.但这同时又衍生出了新的问题,即如何进行内存页面的放置迁移操作.
近年来,许多相关研究都试图解决在NVM和DRAM之间进行内存页迁移的问题,如多级队列替换算法(multi-queue replacement algorithm, MQRA)[16]、CLOCK-DWF[17]、基于双向散列链表的页面迁移机制(THMigrator)[18]等.虽然它们在一定程度上优化了异构内存系统带来的问题,但也造成了冗余的页面迁移操作,从而降低系统的性能.由于不准确的迁移执行参数与预测机制,进行迁移的页面实际上可能不够“热”,而有些页面则可能会过早地被迁回NVM,这将导致2种设备之间频繁地往返迁移.同时页面迁移造成的不可避免的操作和资源消耗,例如页面的重新分配、页表的更新、带宽消耗等,都将带来巨大的系统开销.因此,不必要的迁移所产生的代价可能反而超过了页面迁移带来的收益.此外,NVM的大量数据写入操作也缩短了设备的使用寿命,并增加了访问时延.
我们通过实验观察到,当应用程序对海量数据进行处理时,主存DRAM中被逐出的“冷”页,可能会在短时间内再次变“热”.在这种情况下,页面将进行重复的迁移操作,这将会增加NVM的写入次数且消耗不必要的系统资源.
定义1.重复迁移.对任意内存页面x和迁移操作序列M=(M1,M2,…,Mi,…,Mn),若当前执行的迁移操作Mi使得x的迁移总次数n≥2,则迁移操作Mi为x执行了一次重复迁移.
定义2.冗余迁移.对任意内存页面x和迁移操作序列M=(M1,M2,…,Mi,…,Mn),若当前执行的迁移操作Mi使得x的迁移总次数n≥2,且对页面x的第i次迁移与第i-1次迁移之间的时间间隔t≤σ,则迁移操作Mi为x执行了冗余迁移.
其中σ是较小的时间阈值,由不同的内存器件和内存层次结构的差异而定.
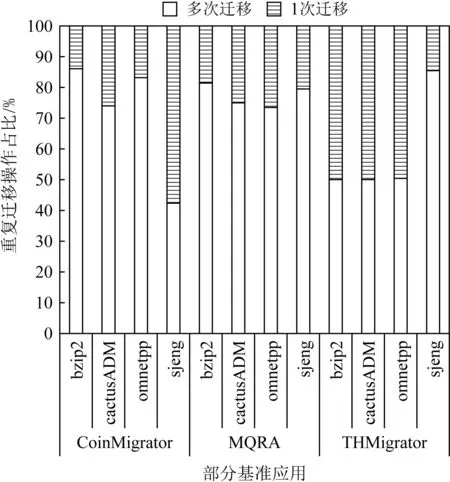
Fig. 1 The percentage of re-migration of CoinMigrator, MQRA and THMigrator图1 CoinMigrator/MQRA/THMigrator的重复 迁移操作占比
如图1所示,以CoinMigrator,MQRA,THMigrator为例,对于基准测试bzip2,cactusADM,omnetpp,sjeng,与总的迁移次数相比,平均有72.50%,66.33%,69.050%,69.11%的迁移操作为重复迁移.此外,由于迁移参数的主观人为设定,一些研究中的页面“冷”“热”程度判断机制可能无法准确判断并预测一个页面是否真的“热”.同时,被判定为“热”页的页面可能不会立即执行迁移,由于前一个页面未完成迁移操作而导致当前页面需要等待,在这种情况下,在当前页面完成迁移时,它可能不会再与之前一样“热”,并且由于“冷”“热”判断标准的不同被对应迁回NVM的页面可能比迁移到DRAM的页面更“热”.这样的页面迁移是不必要的,它们不仅会降低系统性能,同时也增加了系统资源的消耗.
为了解决这些问题,本文提出了一种基于DRAM的牺牲Cache(DRAM-based victim Cache, DVC)的异构内存页迁移机制(victim Cache for page migration on hybrid main memory system, VC-HMM).当执行页面迁回时,主存DRAM中的“冷”页将迁移到DVC中,而不是立即写回PCM.在“冷”页再次变“冷”之后,迁移控制器将判断该页是否为脏页.由于PCM仍保留原始页面数据,故若页面不脏,则不需要写回.VC-HMM还可以根据迁移收益情况自主地调整迁移参数,从而自适应不同的工作负载.本文工作的主要贡献有3个方面:
1) 提出了一种基于DRAM牺牲Cache的异构存储系统结构来消除冗余迁移.
2) 提出了适用于VC-HMM的基于双向散列链表的页面迁移机制进行更有效的迁移操作.
3) 提出了在不同工作负载下自适应更新迁移执行参数的方案,实现合理的迁移阈值控制.
实验结果表明:与其他迁移策略(CoinMigrator,MQRA,THMigrator)相比,VC-HMM平均减少了至少62.97%的PCM写操作次数,22.72%的平均访问时延,38.37%的重复迁移操作,以及3.40%的系统能耗.
1 相关工作
由于NVM难以作为DRAM的直接代替,异构内存系统的提出给内存问题提供了解决的方案.而为了兼具NVM与DRAM两者的性能优势,基于异构存储系统的页面迁移机制研究显得尤为重要.本节将首先介绍一些以往有关异构内存页面迁移机制研究的相关工作,并分析它们的优点与不足.
由于NVM在进行写操作时具有远大于DRAM的访问时延和能量消耗,许多研究着眼于如何减少NVM的写入操作来提升系统性能.Lee等人[17]提出了Clock-DWF算法将写请求频繁的页面迁移到DRAM中.对于一个进入内存的新页面,当访问为写操作时,该页面将直接载入DRAM中,反之放置于NVM中.对于在NVM中的页面,一旦被写请求命中则该页面将迁移到DRAM中.如果DRAM容量已满,Clock-DWF则会选择写请求命中次数最少或最长时间没有被访问的页面作为“冷”页逐出DRAM.该机制考虑到了写操作对NVM的影响,但迁移的评判标准过于简单,不能正确地判断“冷”“热”度从而增加迁移的次数.Kim等人[19]提出了基于自适应分类(adaptive-classification clock)的迁移机制.通过历史的访问模式,每个页面将被设定为不同的状态来判断页面是否为读/写密集以及是否执行迁移操作,减少了不必要的迁移.
除了以上通过监控页面访问来执行迁移的机制外,使用队列结构存储页面信息的策略也在以往的研究中广泛使用.Seok等人[20]提出了以4个LRU队列为基础的迁移模型.所有的页面被分为4个类别:NVM写频繁页面、NVM读频繁页面、DRAM写频繁页面以及DRAM读频繁页面,并且根据最近的访问时间进行有序排列.根据过去的访问信息,模型能够预测未来访问的类型,更加准确地进行页面的迁移,以减少NVM的写操作.Zhou等人[16]提出了多级队列迁移机制(MQMigrator)来提高迁移页面判断的准确性.多级队列迁移机制的实现基于3个页面属性,即最小生存周期、基于访问频率的优先级以及访问时间.每一个页面都将基于“冷”“热”度与生存周期来更新节点信息并移动到对应的队列中.通过多个LRU队列的维护,系统能够更加准确地选择最“热”和最“冷”的页面并且监控所有的页面状态,但维护成本和时间复杂度较高.Tan等人[21]提出了一种基于历史访问信息的统一“冷”“热”度计算方式,相较于大部分研究中使用访问次数作为“冷”“热”度度量标准的方法,统一的计算方式能更加公平地表现页面的访问状态.同时,迁移的阈值也能够根据每次迁移的收益来进行更新.随后,Tan等人[22]又进一步提出减少NVM写入操作的机制.当一个脏页写回NVM时,只需要写回以行大小为单位的数据而不用写回整个页面.该机制减少了冗余写回操作的同时延长了部分NVM存储单元的使用寿命.
除了减少NVM的写入操作和提高“热”页的选择准确性之外,一些研究也提供了其他的迁移思路.Ryoo等人[23]提出了一种基于粒度感知的迁移机制,迁移页面的粒度大小将根据不同工作负载的不同访问模式进行更新,减少不必要的迁移.为了解决迁移能耗的问题,Zhan等人[24]提出了一种基于能耗感知的迁移机制.该机制将权衡页面继续留存在NVM中和迁移到DRAM中2种情况的能量代价,为系统节约不必要的迁移能耗.
在内存系统结构的研究中,Guo等人[25]提出了新的内存系统结构DR-HBM,减少对NVM的写入.在该结构中,DRAM被分为2个部分:容量较小的DRAM Cache与容量较大的DRAM主存.Cache仅仅缓存源于NVM的页面并且按照页面状态的不同,在迁回时不用写回NVM而暂时保存在DRAM中以便再次访问.在Cache中第1次未命中的页面不会立刻执行缓存直到再一次被请求.这样的结构设计减少了NVM的写入并且节约了迁移所占用的带宽.Islam等人[26]提出了一种即时迁移的策略,通过在内存系统中添加新的硬件设备实现实时的页面迁移而不需要中断访问,为系统减少了访问的时延.
以上所有的迁移策略都对异构内存的页面迁移进行了逐步的优化升级,但同时也具有一定的局限性.大多数的迁移策略只关注迁移的页面,很少关注仍留存在DRAM或在迁移队列中的页面.通常在一个迁移过程中,一对“冷”“热”页面将会交替迁移,从DRAM中选中的“冷”页将被NVM中的“热”页代替以节约DRAM的存储空间,但是由于不公平的“冷”“热”度评价机制,可能会存在“冷”页面比“热”页面更“热”的情况,或“冷”页面被逐出后在短时间内再次变“热”.另外,由于页面达到迁移条件后可能不会立即执行迁移,所以当完成迁移时,当前页面可能不会与之前一样“热”,甚至比在它之后执行迁移的页面更加“冷”.在进行页面逐出迁回时,从DRAM迁移回NVM的页面都需要进行写回操作,但是对于读频繁页面来说,页面中的数据可能并没有经过修改,重新写回NVM将增加NVM的写操作且缩短NVM设备的使用寿命.此外,目前存在的大部分迁移策略没有关注分析算法的时间复杂度,这也将产生额外的系统消耗.
为了进一步消除海量大数据处理带来的冗余页面迁移操作,减少PCM写入次数,降低访问时延并提高系统性能,本文进而通过增加新的设备并改进以往基于双向散列链表的迁移算法,提出了基于DRAM牺牲Cache的异构内存页迁移机制.
2 基于牺牲Cache的异构内存页迁移机制
在异构内存系统中,由于NVM写入操作表现出的低性能问题,在访问速度较慢的NVM和访问速度较快的DRAM之间进行内存页面迁移显得尤为重要.针对访问时延较大的PCM,为了消除不必要的迁移操作,减少PCM的写入并缩短访问的时延,本文提出了VC-HMM,其中包括3个部分:基于DVC(DRAM-based victim Cache)的异构内存系统结构、适用于VC-HMM的页面迁移策略以及迁移条件在不同工作负载下的自适应算法.
2.1 基于DRAM牺牲Cache的异构内存系统结构
图2展示了VC-HMM的整体结构.与传统的内存结构不同的是在DRAM与PCM之间添加了一个小容量的Cache作为DRAM主存部分的牺牲Cache,牺牲Cache由随机动态存储器DRAM构成,并用来存储从主存DRAM中被逐出的“冷”页.DVC使用访问速度较快且页面替换便利的直接映射.与垂直结构的异构内存系统中使用的DRAM Cache类似,DVC中的每一页都有一个1 b的脏页标志来标记页面是否被修改.当DRAM逐出页面时,将根据页面的物理地址存储在Cache对应的块中.如果存储时产生冲突,则原本在块中的页面将被迁回PCM.由于在Cache中的页面原本就是从DRAM中淘汰的“冷”页,所以就算冲突后被直接写回也能一定程度上降低再次被迁移的概率.
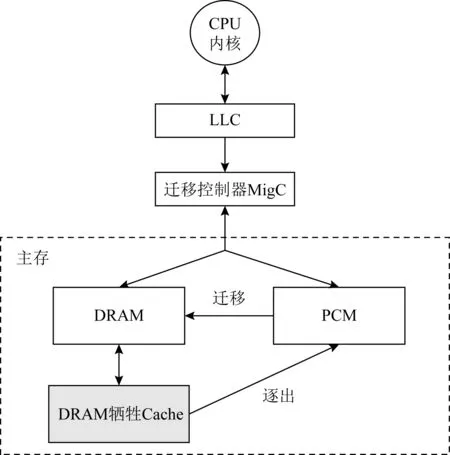
Fig. 2 DRAM-based victim Cache on hybrid main memory architecture图2 基于DRAM牺牲Cache的异构内存系统结构
当一个页面被判断为“热”页时,迁移控制器(migration controller, MigC)将执行迁移操作,从PCM迁移的页面将被拷贝到DRAM的空页框中,而PCM将继续保留此页的数据以便将来的迁回写入.通过这种方法,读操作密集的页面即使经历了迁移和迁回也不必写回PCM,减少了PCM的写操作.为了实现PCM中原数据的保留,在MigC中添加了用来监视迁移页面状态的迁移页面列表(migrated page list, MPL)用于判断所请求的页面的位置.如果所请求的页面已经迁移到DRAM中,则MigC将重映射目的地址使请求进行正确访问;而如果所请求页面经过二次迁移存在于DVC中,请求将通过原本的目的地址在牺牲Cache中查找.MPL会同时通过记录迁移的页面是否进行过写操作,从而在最后逐出DVC时进行写回判断,只有脏页面需要进行写回,对于其余的页面只需要删除相关的节点信息即可.
迁移控制器MigC基于THMigrator进行了改进.在THMigrator迁移机制中,页面节点的记录排序通过双向散列链表来完成.双向散列链表的结构能够直接快速的访问每个节点并完成增删改查的工作,这大大降低了算法的复杂度,加快了迁移的速度.每当有页面被访问时,该页的相关信息将被记录为节点插入对应表的表头,当表中页面再一次被访问时,该节点将重新被插入表头,即按照最近最少使用递减排序.通过这种排列方式进行页面搜索时能够把搜索范围控制在较小的区域内.另外,双向散列链表的结构能够使使用更加频繁的页面更早的执行迁移,而不是以达到迁移标准的时间来作为迁移准则,这将减少不必要的迁移次数.例如,页面A比页面B先达到迁移阈值进入候选迁移列表(migration candidate list, MCL),但是页面A此后再也没有被访问到,这时页面B被频繁使用,则MCL将把页面B的记录节点放在表头,从而比页面A更快地进行迁移.
在VC-HMM中双向散列链表结构依旧被使用在页面排列中.为了更好地适应DVC的结构,在迁移控制器中设置了3个双向散列链表:PCM页面列表(PCM page list, PPL)、候选迁移列表(MCL)以及迁移页面列表(MPL).PPL记录在PCM中的页面访问情况,PPL与MCL中的节点结构如表2所示.PPL记录PCM中页面的“冷”“热”程度、页面编号以及生存周期.内存中所有的页面将根据其物理地址计算得出一个唯一的页号作为在表中的索引,MigC能够根据页号直接访问页面的信息而不需要遍历查找.当一个在PCM中的页面首次被访问时,MigC将该页面的信息初始化并插入PPL的表头,且每次访问都会将之重新插入表头.“冷”“热”程度将根据访问的次数逐次递增,生存周期也将随着每一次的访问被重置.生存周期用于控制一个页面存在于列表中的时间,如果一个页面长时间不被访问,则当生存周期用尽,该页面节点将被删除.当PPL中的页面达到迁移阈值时,该页面节点将被插入迁移候选列表MCL的表头,MCL将在页面下一次被访问时执行迁移.当有迁移还未完成时,MCL也能够将页面按照“冷”“热”程度排序使更“热”的页面优先迁移.和PPL相同,在MCL中的页面也将根据访问情况更新节点信息,并且按顺序执行迁移.每次有请求进入内存时,MigC都将检查是否有页面达到迁移阈值或超过生命周期,超过生命周期的页面将被作为“冷”页从列表中删除以减少冗余的迁移操作.

Table 2 Page Node Structure of PPL and MCL表2 PCM页面列表与候选迁移列表的页面节点结构
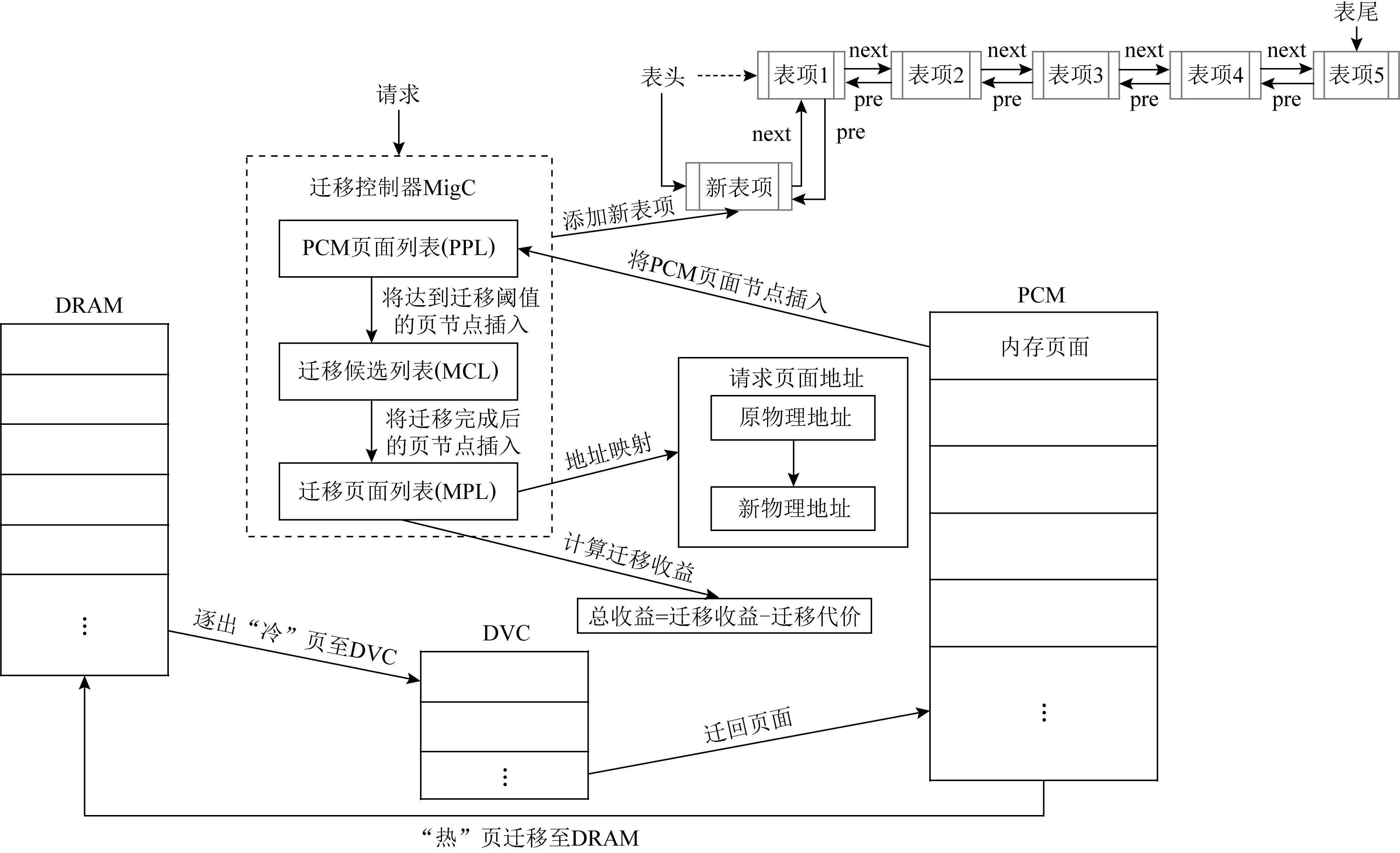
Fig. 3 Migration framework for VC-HMM图3 VC-HMM迁移框架
执行了迁移而进入DRAM的页面将被作为新的节点插入迁移页面列表(MPL)的表头,并删除在MCL中的旧节点,MPL中的节点结构如表3所示.MPL在PPL和MCL的基础上记录更多的页面信息帮助迁移机制的实现,1b标签参数IsInDRAM记录了页面存在的位置,页面地址的映射被记录用于请求的正确访问,另外MPL将记录页面在DRAM中的读写操作次数来帮助迁移参数的动态自适应.MPL也将随着页面的访问更新节点从而进行排序.当进行“冷”页判断时,MigC将逆序遍历MPL从而查找需要进行迁移的“冷”页.

Table 3 Page Node Structure of MPL表3 迁移页面列表的页面节点结构
2.2 页面迁移与访问
VC-HMM的迁移框架如图3所示,具体迁移步骤为:
① MigC判断所访问内存页是否存在于某个表中.如果在表中,则更新节点信息并将该节点置于表头;如果不在表中,将页面节点初始化并插入PCM页面列表PPL的表头.
② 如果所访问页面节点在迁移页面列表MPL中,则根据标志位判断该页在DRAM还是DVC中,并执行地址重映射.如果所访问页面节点在候选迁移列表MCL中,则检查是否有迁移正在进行,若有迁徙正在执行则等待当前迁移完成否则进行迁移操作.如果所访问页面节点在PPL中,则判断是否达到迁移阈值,若达到迁移阈值则将节点插入MCL表头.
③ 在MCL中按顺序进行迁移,将该页复制到DRAM的空页框中,将该页在MCL中的节点信息更新到MPL中并删除原节点,初始化新节点信息并置为表头.
④ 在MPL中从后往前检索是否有满足迁出条件的DRAM页面,若有满足迁出条件的DRAM页面,检查是否有DRAM到DVC的迁出操作正在进行,若没有正在进行的迁出操作,则进行迁移操作并更新MPL中对应节点信息,将对应DRAM页面重新置为空.若当前有迁移操作正在进行,则等待当前迁移操作结束.
⑤ 在MPL中从后往前检索是否有满足迁出条件的DVC页面,若有满足迁出条件的DVC页面,检查是否有DVC到PCM的页面逐出正在进行,若当前有迁移操作正在进行,则等待当前逐出结束.若没有正在进行的迁移操作,则通过MPL中该节点记录的读写情况判断是否需要写回PCM中,若不需要写回PCM中,则直接删除节点.最后根据该页面在DRAM中的读写情况计算迁移收益,若收益为正,则更新迁移参数使页面更容易迁入DRAM且页面的生命周期变长;若收益为负,则更新迁移条件使页面更难迁入DRAM且页面的生命周期变短.
⑥ 检查PPL和MCL是否有超过生命周期的页面节点,将之逐出.
迁移流程框图如图4所示:
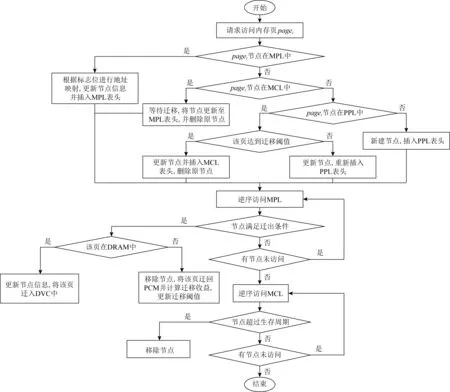
Fig. 4 Process of migration图4 迁移流程
页面的“冷”“热”程度根据访问次数递增.迁移时,MigC将为迁移的页面寻找DRAM中的空页框,如果没有可用的空页框,MigC将在MPL中逆序查找并逐出最“冷”的页面到DVC中.基于DRAM牺牲Cache的内存页迁移机制的伪代码实现方法如算法1所示:
算法1.内存页面迁移算法.
输入:当前访问页面的页号pagei、页面所在内存设备通道编号ChannelNumber.
① 初始化PPL,MCL,MPL,Threshold,currentTime;
②Request(pagei);
③ ifIsLocatedInPPL(pagei) then
④UpdatePPL(pagei);/*更新页面的“冷”“热”程度值并重置生命周期*/
⑤MoveToHead(pagei);/*将该页节点置为表头*/
⑥ ifpagei→value>Thresholdthen
/*“冷”“热”程度值达到阈值则插入候选迁移列表表头*/
⑦InsertMCL(pagei);
⑧RemovePPL(pagei);
⑨ end if
⑩ end if
/*在候选迁移列表中且没有超过生命周期则进行迁移*/
/*被访问页面位于DRAM中*/
&&!IsLocatedInMPL(pagei) then
与迁移操作仅针对当前所访问的页面不同,迁回和逐出操作针对每一个完成迁移的页面,可能在每一个时钟周期中发生.MigC将在迁移判断操作结束之后分别查看MPL和MCL列表.在MCL中通过从后往前逆序遍历查看各页面节点是否已超过生命周期,超过生命周期的节点将被直接删除.类似地,在MPL中逆序查找需要迁移的DRAM和DVC“冷”页,并进行迁移和迁回操作,随后针对迁回PCM的页面进行迁移收益核算.内存页面逐出的伪代码实现方法如算法2所示.通过MPL执行的逐出判断将在分别寻找到满足要求的一个DRAM和DVC页面后结束本次遍历.由于逐出操作面向的对象为“冷”页,故本算法中仅将生命周期作为判断“冷”“热”程度的标准以简化算法的执行.
当所访问的页面已经完成迁移时,MigC将通过MPL中保存的1 b标志位判断该页是在DRAM中还是在DVC中.如果IsInDRAM为true则该页在DRAM中,MigC将通过MPL记录的页面地址映射重新映射请求的目标地址;如果IsInDRAM为false则该页在DVC中,请求将通过原始目的地址与DVC中的地址进行比对从而执行访问.
算法2.内存页面逐出算法.
输入:当前访问页面的页号pagej.
① forpagej=rbeginMPL();
pagej≠rendMPL();
++pagejdo /*检查已迁移页面是否要逐出*/
② ifpagej→expirationTime>currentTime
then
③ ifpagej→IsInDRAM==true then
④VicfromDRAM(pagej);
⑤ else
⑥Revenue(pagej);
⑦VicfromCache(pagej);
⑧AdjustThreshold();
⑨ end if
⑩ end if
pagej≠rendMCL();
++pagejdo /*检查候选迁移列表中是否有页面超出生命周期*/
then
2.3 迁移参数的自适应调整
为了使迁移机制能够自适应不同的工作负载,提高迁移的合理性,MigC将通过迁移收益自主地更新迁移参数.当一个页面最终被逐出DVC时,MigC将计算这一次迁移的收益.迁移收益:
Rw=Writecount×(Timew_in_pcm-Timew_in_DRAM),
(1)
Rr=Readcount×(Timer_in_pcm-Timer_in_DRAM),
(2)
C=TimeP_D+TimeD_DVC+TimeDVC_P×dirty,
(3)
R=Rw+Rr-C.
(4)
式(1)和式(2)通过MPL记录的读写操作次数计算页面迁移到DRAM中和留存在PCM中的读写时延收益,Writecount表示迁移后该页面所收到的写操作次数,Timew_in_pcm和Timew_in_DRAM分别表示在PCM和DRAM中进行写操作所需的时间.同理Readcount,Timer_in_PCM,Timer_in_DRAM表示迁移后该页面所进行的读操作次数以及在PCM和DRAM中进行读操作所需的时间.
式(3)计算了迁移所需的时间代价,如果页面最终被逐出时为脏,则dirty=1,反之dirty=0.最终的收益通过式(4)计算,如果R>0则表示迁移收益为正,迁移阈值将自动降低使页面更容易迁移到DRAM中,在DRAM和DVC中的页面的生存周期也将被延长;如果R<0则表示迁移收益为负,迁移阈值将自动增加使页面更不容易达到迁移阈值,在DRAM和DVC中的页面的生存周期也将被缩短.
本文通过线性增值的方式自适应地调整迁移参数,设置以步长为1进行线性增长.生存周期的增减将应用于下一个周期执行迁移页面节点信息的初始化中,而不是更新目前迁移表中所有内存页的生存周期.实验中参数的初始数值与THMigrator的模型参数一致.
例如,当页面x被认定为“冷”页面,从而从DVC迁移回PCM时,MigC通过计算得出该页面x迁移的收益.若收益R为正,则表示当前迁移参数合理有效,留存于DRAM中的页面将被大概率访问.然后,MigC降低迁移阈值,增加其他页面迁移的机会.在下一次迁移时,提升页面初始生命周期,增加页面驻留在DRAM中的时间.
3 实验与分析
本文采用GEM5[27]和NVMain[28-29]构建基于异构内存的多核处理器模型系统,GEM5模拟器是一个用于计算机系统架构研究的模块化平台.NVMain是一个架构级的主存储器模拟器.本文通过GEM5与NVMain的结合,设计了具有DRAM牺牲Cache的水平型结构的异构内存系统,其中DRAM通道与PCM通道的比例为1∶3,DVC的大小为DRAM的1/16,采用时钟频率为2 GHz的TimingSimpleCPU,一级缓存设置为32 KB,二级缓存设置为256 KB.详细配置如表4所示,内存结构中的1∶1/16∶3为DRAM容量、DVC容量以及PCM容量的比例.
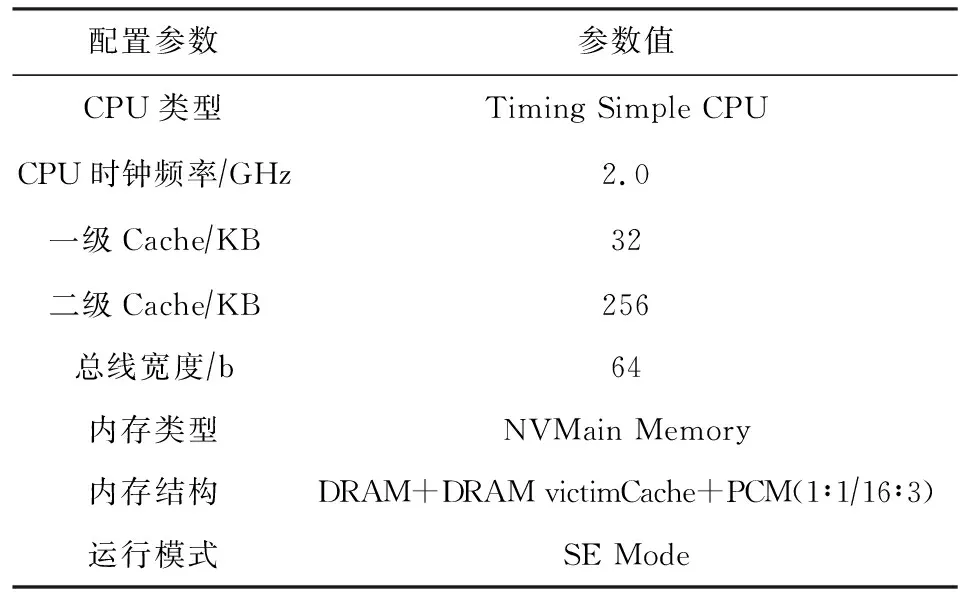
Table 4 Main Configurations of GEM5 and NVMain表4 GEM5和NVMain模拟器的主要配置
为了对VC-HMM进行全面分析,本文选择了CoinMigrator、多级队列替换算法(MQRA)和基于双向散列链表迁移机制(THMigrator)作为参考.CoinMigrator迁移策略为NVMain模拟器自带的随机迁移策略,每一次的迁移决策由随机数决定.MQMigrator迁移策略为Zhou等人[16]提出的页面替换算法,迁移使用多个队列来维护页面的访问信息,通过队列优先级进行“冷”“热”页面的排序和选择,但由于队列数量多,且不能随机访问每个页面节点.因此,本文提出的VC-HMM采用双向散列链表结构维护页面信息的数据结构,能实现页面节点的随机访问而不需要遍历链表,降低了页面信息维护的复杂度.本文采用了SPECCPU2006[30]中的10个不同的基准应用程序,并将CoinMigrator的数据作为对应的标准化数据.
针对一个内存页的读写配置与能耗配置如表5所示,参数来源于文献[18],内存页大小设置为4 KB.
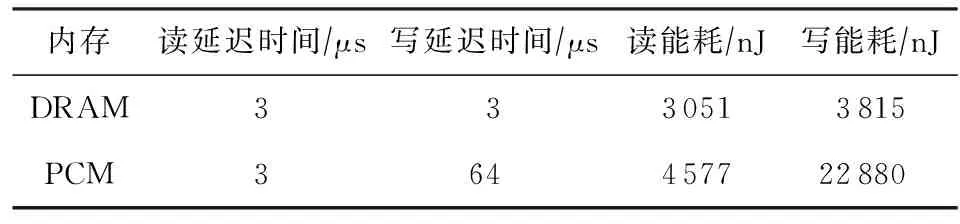
Table 5 Configuration of the Memory for a 4 KB Memory Page
实验数据通过GEM5和NVMain模拟器自身集成的Trace工具来产生,Trace工具可以以文本的形式输出程序运行时的日志信息,在程序代码中通过添加一些关键数据的打印操作,使用AddStat方法可以将运行时的数据输出到日志信息中,通过这种输出日志的跟踪方法可以获得读写操作的数量和分布以及迁移内存页的数量等信息.实验中用于测试的基准应用均使用了1 000万条指令的运行.其他迁移参数的设置与前期研究[18]的配置一致.
3.1 访问时延

Fig. 5 Normalized average access latency图5 归一化的平均访问时延
实验数据显示,通常情况下使用VC-HMM的系统的平均访问延迟比使用CoinMigrator,MQRA,THMigrator的系统的平均访问延迟分别低22.72%,31.56%,23.63%,如图5所示.基准中的每个应用在VC-HMM的使用中都有较好的效果.其中,与Coin-Migrator,MQRA,THMigrator相比,应用sjeng在使用VC-HMM时访问时延的降低最明显,分别为53.45%,60.58%,60.47%.图5中应用omnetpp的访问时延高于CoinMigrator,这是由于CoinMigrator的随机概率判断策略使得迁移不稳定,每一次的迁移并不完全一样.本文经过多次的实验,使数据尽可能趋于稳定.目前VC-HMM的总体访问时延相比其他的迁移策略基本上都有明显降低.即使对于所产生的访问时延高于CoinMigrator策略,VC-HMM策略的访问时延也仅高于1.5%.
VC-HMM的主要性能提升源于DRAM牺牲Cache,DVC将更多的页面保留在读写速度较快的DRAM部分.即使一个页面在迁移参数不精准的情况下进行迁移,该页面仍然可以在访问较快的DRAM中停留更长的时间,而不会由于“冷”“热”度的快速动态变化而在PCM和DRAM之间频繁迁移.这使得更多的请求通过访问时延较短的DRAM进行访问,而不是访问读写时延长的PCM.不必要迁移操作的减少也避免了带宽和其他系统资源的占用.实际上VC-HMM通过使已经执行的迁移变得更有效而不是单纯调整迁移阈值来消除无效迁移.
3.2 PCM写操作频次
通过使用添加了DVC的异构内存系统,PCM访问的次数也有了相应的减少.如图6所示,使用VC-HMM的系统中,PCM的访问次数相比使用CoinMigrator,MQRA,THMigrator的系统平均减少了67.38%,73.26%,62.97%.同时,对PCM的写操作数也明显减少.如图7所示,相比使用CoinMigrator,MQRA,THMigrator的系统,使用VC-HMM的系统平均减少了81.28%,84.99%,75.89%的PCM写入次数.
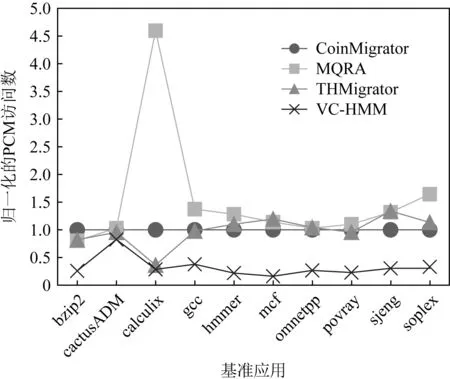
Fig. 6 Normalized PCM access times图6 归一化的PCM访问数
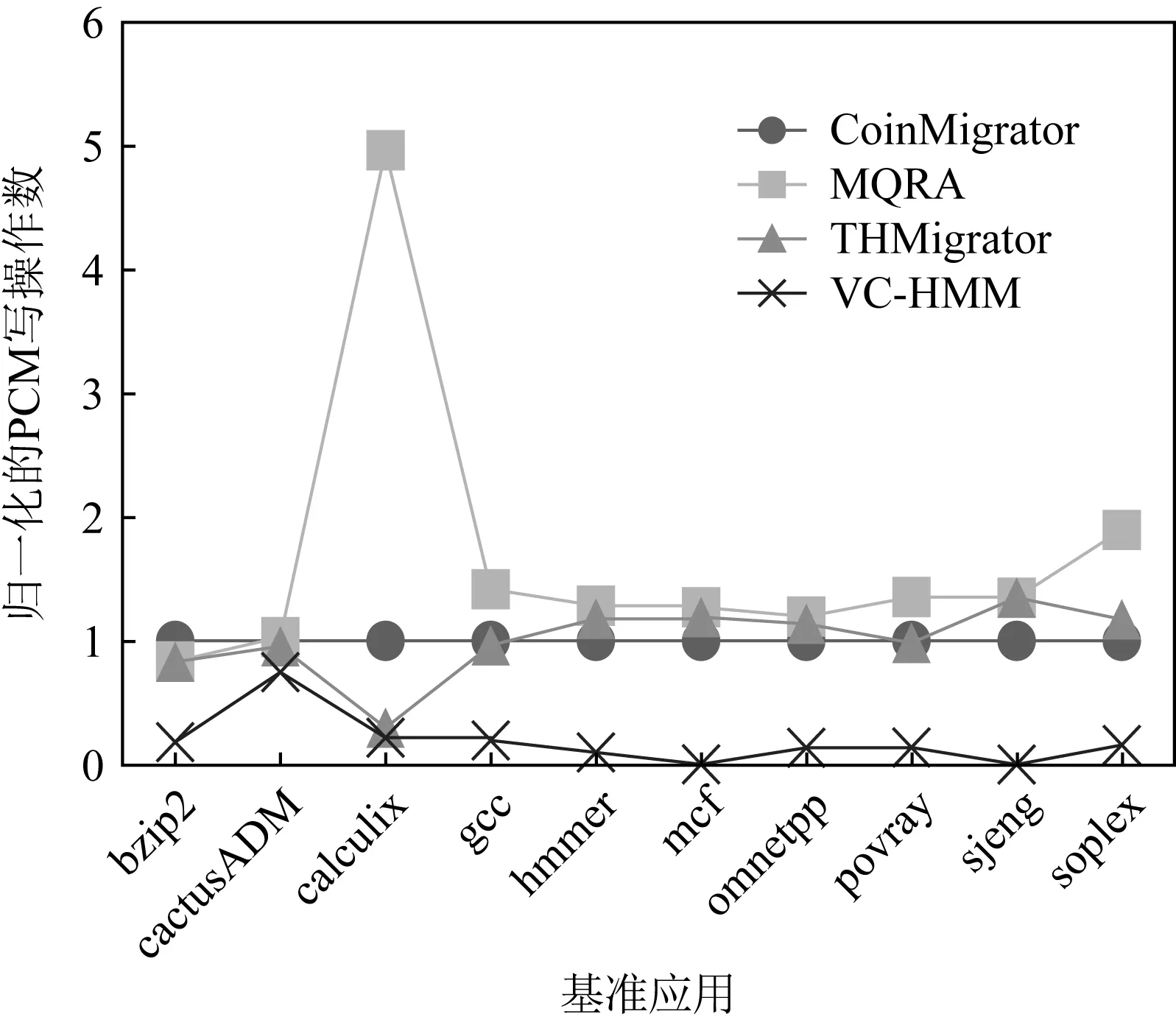
Fig. 7 Normalized PCM write times图7 归一化的PCM写操作数
尽管迁移阈值可能不够精确,且由于迁移参数的人为制定无法选择和预测真正最“热”的页面进行迁移,但VC-HMM增加了迁移页留在DRAM部分的时间,使大部分的请求通过DRAM进行访问,冗余迁移的减少也降低了对PCM的读写操作次数,延长了PCM的使用寿命.原页面的保留也使得读频繁的“冷”页面在迁移时不需要写回,进一步降低了PCM被访问的次数.
3.3 IPC
图8比较了使用VC-HMM和其他3种算法的系统IPC(平均每个周期完成的指令数).这4种不同算法所产生的系统IPC差异不显著,但VC-HMM仍能在一定程度上提高IPC.使用VC-HMM系统的IPC平均比使用CoinMigrator,MQRA,THMigrator的系统的IPC高2.36%,2.88%,4.03%.在所有基准应用中,sjeng的增长率最高,分别为11.36%,12.72%,24.32%,说明sjeng应用的存储访问的局部性较高.在这种情况下,所请求的页面大部分被迁移到DRAM中,大大减少了请求的时间.
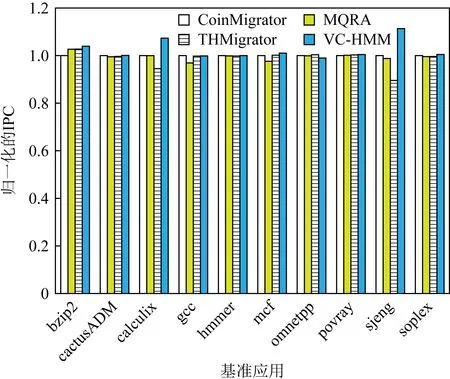
Fig. 8 Normalized IPC图8 归一化的IPC
然而,即使VC-HMM减少了大量的PCM写入,使用VC-HMM的系统的IPC也没有得到显著的改善.本文分析其中一个原因是由于VC-HMM需要在每次迁移中进行二次迁移.迁移的页面需要从DRAM到DRAM牺牲Cache进行额外迁移,即使MigC可以自主地调整迁移参数,但二次迁移依旧需要额外的时钟周期来完成.
此外,不同应用程序的写请求频次多少、访存地址的局部性强弱会使得VC-HMM机制下的IPC值发生变化.写访问量较少且局部性较好的应用在使用VC-HMM时能够得到更好的性能提升.
3.4 冗余迁移操作
图9比较了使用VC-HMM的系统与使用另外3种算法的系统的重复迁移操作次数,与使用CoinMigrator,MQRA,THMigrator的系统相比,VC-HMM平均减少了58.80%,52.40%,38.37%的重复迁移操作.其中在基准测试应用calculix和sjeng中,均未检测到重复的内存页迁移操作.
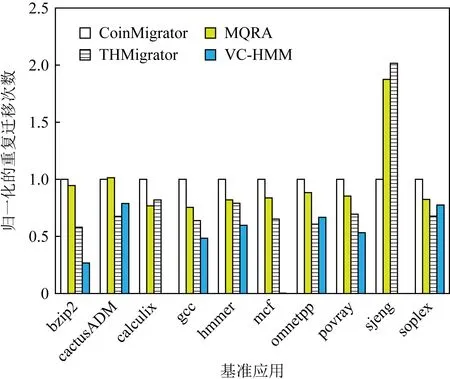
Fig. 9 Normalized re-migration times图9 归一化的重复迁移次数
由于当前实验阶段难以计算冗余操作中的σ值,本文实验采用统计重复迁移操作的次数来量化冗余迁移操作的次数.在cactusADM及omnetpp应用中,VC-HMM的重复迁移次数高于THMingrator,这是由于VC-HMM拥有迁移阈值和页面生存周期的自适应策略,对于局部性较差的应用来说,由于VC-HMM相比没有DVC设备的策略需要额外的从DRAM到DVC设备的迁移,这将会导致动态自适应算法减少页面在DRAM中的生存周期,从而使得页面过早迁出,增加了冗余迁移的可能性.同时,DVC的直接映射策略也使得冲突页面过早地迁回NVM,也增加了冗余迁移的次数.
DVC使得完成迁移的“热”页更久地保存在访问速度较快的DRAM设备中,且“冷”“热”页并不成对进行迁移操作,这阻止了“冷”页的误迁回,从而减少了页面再次变“热”而导致的冗余迁移问题.在构建DVC时,本文使用直接映射策略作为DVC的映射规则,虽然直接映射策略下的访问速度较快,但也更加容易引起冲突而加快页面的迁回,导致部分冗余的迁移操作.由于迁移到DVC的页面为从主存DRAM中逐出的“冷”页.因此,虽然存在由于冲突而过早迁回的页面,但并没有对系统产生过大的影响.
3.5 系统能耗
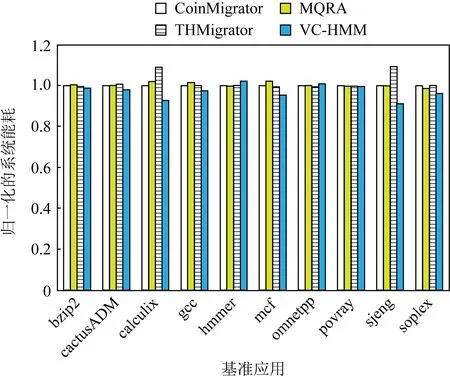
Fig. 10 Normalized energy consumption where the capacity of DVC is 1/16 of DRAM图10 DVC容量为DRAM容量1/16时归一化的 系统能耗

Fig. 11 Normalized energy consumption where the capacity of DVC is 1/8 of DRAM图11 DVC容量为DRAM容量1/8时归一化的 系统能耗
图10比较了使用VC-HMM的系统与使用另外3种算法的系统的能耗情况.与使用CoinMigrator,MQRA,THMigrator的系统相比,VC-HMM平均减少了2.74%,3.16%,4.29%的系统能耗.由于系统性能的提升,VC-HMM在降低运行时间、提高系统效率的同时减少了能耗.但同时,能耗将根据使用的DVC的容量大小而改变.图11对比了DVC容量为DRAM容量的1/8时所产生的能耗.与使用CoinMigrator,MQRA,THMigrator的系统相比,使用比先前增加1倍容量的DVC时,VC-HMM平均增加了24.92%,24.35%,22.97%的系统能耗.VC-HMM在应用hmmer与omnetpp上的能耗大于其他的迁移策略.对于局部性较差的应用来说,迁移的页面也会较多,从而导致内存访问和静态维持数据所需的能耗增加,且额外的DRAM到DVC的迁移操作和DVC冲突问题也将增加能耗.此外,DVC容量的增大将减少数据冲突的发生,导致所需保持的数据增加,这些数据的访问以及达到生存周期之前的数据刷新都将产生大量能耗.
由于DRAM利用电容内存储电荷的多少来存储数据的特性,晶体管漏电使得DRAM需要周期性地充电,且访问前需要对区块进行预充,这将产生不小的系统能耗来维持DRAM的运行.过大的DVC将使得静态能耗增加,且得不到合理的使用.另外,由于异构内存的迁移使得大量的内存访问集中于DRAM,所以DVC的容量大小将不同程度上影响系统能耗.
4 总 结
本文提出了一种基于DRAM牺牲Cache的异构内存页迁移机制VC-HMM,该机制实现了比THMigrator模型更低的访问延迟,消除了部分无效的迁移操作.此外,VC-HMM在局部性较强的应用中取得了较高的访存性能.
实验结果表明:与使用CoinMigrator、多队列算法MQRA和基于双向散列链表的迁移机制THMigrator的系统相比,使用VC-HMM的系统的平均访问延迟降低了22.72%,31.56%,23.63%.同时,VC-HMM相比CoinMigrator,MQRA,THMigrator减少了81.28%,84.99%,75.89%的PCM写操作,并在一定程度上提升了系统IPC.另外,在减少重复迁移操作方面,VC-HMM平均减少了相比另外3种机制58.80%,52.40%,38.37%的重复迁移操作.在能耗方面,与使用CoinMigrator,MQRA和THMigrator的系统相比,VC-HMM平均减少了2.74%,3.16%,4.29%的系统能耗.未来,我们计划利用机器学习算法识别和监测“热”页面,并着力于研究更智能的页迁移决策,以获得更高的异构内存综合性能.
作者贡献声明:裴颂文提出了算法思路和实验方案;钱艺幻负责完成实验并撰写论文;叶笑春提出指导意见并修改论文;刘海坤与孔令和提出指导意见.
