基于移动端轻量模型的杂草分类方法研究*
2022-03-08陈启陈慈发邓向武袁单飞
陈启,陈慈发,邓向武,袁单飞
(1. 三峡大学计算机与信息学院,湖北宜昌,443000;2. 广东石油化工学院电子信息工程学院,广东茂名,525000)
0 引言
预计到2050年,世界人口将达到90亿人左右,粮食需求将大幅增加[1],粮食增产问题日益迫切。然而据资料显示,杂草每年给全球粮食生产造成的损失高达950亿美元,相当于损失了3.8×108t小麦,杂草问题给粮食增产带来巨大的挑战。目前机器除草因其有效性,在农业生产中得到越来越多的应用,其中智能除草有望进一步提高现代农业生产力[2]。智能除草不仅能够降低劳动力成本,而且可以做到精准施药,最大限度地减少除草剂的使用、降低农药残留。杂草的精准识别可为智能除草的实施奠定理论基础并提供技术方法,因此研究快速、准确的杂草识别方法是有很大的现实意义。
当前,杂草和作物的识别方法主要分为3种:基于机器视觉的方法、基于光谱图像的方法、综合光谱图像与航空摄影图像的方法。后两种基于光谱图像的方法适合于高度控制的、特定地点的环境,例如较好地理条件的可耕地。但这两种方法对个体小、密度低的杂草识别率低。随着近年来计算机技术的迅猛发展,快速准确的机器视觉识别技术在杂草识别任务上得到了越来越广泛的应用,国内外学者也开展了大量相关研究[3-4]。何东健等[3]开展了基于多特征提取杂草识别方法的研究,但存在特定特征需要人工进行处理、特征提取难度大、抗干扰能力差、耗费人力多等不足,这导致了传统机器视觉方法在杂草识别任务上普适性差的问题。
杂草的识别问题归根到底是图像分类的问题。由于深度学习模型能够自动提取图像的深层特征,具有更强大的表征能力,深度学习主导了与机器视觉相关的很多领域的发展,也有力地推动了杂草识别的发展[5-11]。Razavi等[12]提出了基于卷积神经网络(Convolutional Neural Networks,CNN)的结构,从植物图像中识别类型,并与采用SVM分类器等传统机器视觉方法进行对比,证明了CNN深度学习模型的性能更优。Olsen等[13]于2018年在SCIENTIFIC REPORTS上提供一个标准数据集DeepWeeds,并采用Inception-v3和ResNet50深度学习模型训练,选择五倍交叉验证的方法进行测试,平均准确率达到95%以上,其中ResNet50模型性能更优。
上述研究表明,深度学习模型能够克服传统机器视觉识别方法在特征提取方面的不足,同时这些研究也为深度学习模型应用于杂草识别提供了可行性依据。这些研究大多集中在服务器端模型,而部署服务器端模型的设备普遍存在较笨重、占用较大的计算资源、运行速度较慢的问题。这些给杂草识别深度学习模型的落地应用带来了诸多困难。轻型化、小型化是未来除草设备的发展趋势[14]。特别是近年来植保无人机等设备的迅猛发展[15],对占用计算资源少的轻量模型的需求更加迫切。
基于以上问题,本文提出了一个轻量深度学习模型来实现对杂草图像的自动识别分类。该模型主要是基于迁移学习策略和知识蒸馏方法,并依据杂草数据集特点对移动端MobileNetV3_large网络模型进行改进。
1 材料与方法
1.1 数据集
本文采用DeepWeeds数据集。该数据集是Olsen等[13]于2018年12月提供的一个标准杂草数据集,包含17 509张8类杂草物种和负类目标。该数据集的图像大小是256像素×256像素,所有图片格式为JPG,其中Chinee apple 1 125张、Lantana 1 064张、Parkinsonia 1 031张、Parthenium 1 031张、Prickly acacia 1 062张、Rubber vine 1 009张、Siam weed 1 074 张、Snake weed 1 074张 、不包含目标杂草的负类照片 9 106张。该数据集的样本图像,如图1所示。本文对DeepWeeds数据集按照4∶1的比例划分为训练集和验证集。为确保模型对未知数据的泛化能力,把增强后的训练集和验证集分为两个独立的数据集,互不交叉。

(a) Chinee apple
1.2 数据增强、迁移学习
深度卷积神经网络有强大的表达能力。大规模的训练数据可以驱动模型训练,防止过拟合,提升深度神经网络的分类精度。本文所采用的数据集有9个类别17 509张标记的图片,为避免过拟合,提高分类准确率,本文采用了两种解决方案:数据增强和迁移学习。
1.2.1 数据增强
数据增强是常用在图像分类任务中的一种正则化方法。为了提高分类模型的适应性和增加样本的多样性,防止过拟合,训练集和验证集图像采取旋转、缩放等数据增强操作。图像分类中常用的数据增强方法有:图像解码、图像随机裁剪、水平方向随机翻转、图像数据的归一化、图像数据的重排、多幅图像数据组成batch数据。本文在训练过程中对图像进行随机裁剪、水平翻转、归一化的处理,这样使模型更具有泛化能力。
1.2.2 迁移学习
迁移学习是指把已训练好的模型参数迁移到新的模型上来帮助新模型的训练。考虑到大部分数据和任务存在一定的相关性,通过迁移学习可以使用已学到的模型参数来克服新模型收敛速度慢的问题,提升新模型训练效率,提高模型的分类准确率和泛化能力。本文把ImageNet数据集(1 000种类别,约1.28×106幅图像)上的ResNet50、MobileNetV3_large预训练模型,迁移到本文数据集上进行调试训练,并更改最后一层的输出类别数,本文的类别数设置为9。
1.3 卷积神经网络
卷积神经网络是由卷积层、池化层和全连接层等组成的多层网络神经结构。卷积神经网络可以从图像中学习到局部特征,比如线条、纹理等信息,而这些局部特征可以构成更加复杂的局部或者整体特征从而展现出对象特征,以便对图像进行分类和识别。目前,卷积神经网络已被广泛应用到杂草图像分类领域。

(1)
式中:k——网络第k层;
Mk-1——k-1层的特征图的数量;

2 移动端轻量模型
2.1 ResNet模型
ResNet[16]模型是由微软团队开发的深度卷积神经网络模型,并获得了2015年ILSVRC竞赛冠军,该竞赛是从5×105张图像中识别出1 000个不同类别的图像分类比赛。在牧场杂草分类工作中,Olsen等利用ResNet50模型和Inception-V3模型,在DeepWeeds数据集上进行了试验和比对,发现ResNet50模型的分类准确率更高。深度学习存在梯度消失和梯度爆炸等问题,越深的网络训练难度越大。为了解决这一难题,ResNet模型使用了瓶颈连接(或称捷径)。它将某一层的参数直接传递给更深的网络层,利用瓶颈连接能够搭建并有效训练网络结构。
ResNet模型由批归一化层(batch norm layers)、卷积层(Conv layers)、池化层(pool layers)、全连接层(FC)组成,最后由Softmax分类器预测分类结果。模型的主要结构由卷积块(Conv block)和恒等块(Identity block)两种残差块交替堆叠而成。卷积块在直连路径(捷径)上添加了卷积层和批归一化层。全连接层采用Dropout正则化的方法来减少过拟合,提高泛化能力。该方法会在训练过程中按预先设置的放弃比例随机删除神经元,从而减少过拟合。ResNet50模型结构如图2所示。

图2 ResNet50网络结构
在残差块结构中,R代表ReLU激活函数,B代表批归一化操作。在连接三层的卷积层中,将输入x直接连接至后三层的输出。假设原本连续三层的卷积层的输出为F(x),加上直接连接的跳层x,卷积层单元的输出变为F(x)+x。跳层x只传递数据,通过直接连接,反向传播时参数可以无损失地传递,有效地改善了网络层增加带来的梯度消失的问题。堆叠残差块结构有助于构建深层网络模型,并使深层网络模型可以有效训练。结合本文研究对象,对初始的图像训练网络架构进行改动,把最后一个包含1 000个神经元的完全连接层替换为具有9个神经元的完全连接层来实现杂草分类。ResNet50_vd网络模型是在残差块的跳层连接中加入一个平均池化层。该模型在训练速度和预测精度上都有很好的表现。
2.2 MobileNetV3_large模型
MobileNetV3[17]是Google在2019年3月提出的网络架构,是移动端的基准模型,涵盖两个子版本,即MobileNetV3_large和MobileNetV3_small。与MobileNetV2相比,MobileNetV3_large在ImageNet数据集上的分类准确率提高了4.6%,时间减少了5%。MobileNetV3_large模型网络结构如表1所示。

表1 MobileNetV3_large模型主要结构
2.3 加权Softmax损失函数改进

(2)

θ——模型的参数。
Softmax分类器的损失函数为
(3)
式中:i——第i个样本;

由于不同类别的训练样本数量之间的偏差所带来的数据不平衡,是图像分类中普遍遇到的问题。不平衡的训练样本会导致训练模型侧重样本数量较多的类别,而“轻视”样本数量较少的类别。这会对模型在测试阶段时的泛化能力产生影响。
他是中国最早一批为公众所知的侍酒师,从参加第一个侍酒师认证开始,他就坚定地选择了一直走向MS的路径,这样清晰的目标,至少我在圈内是很少见的,十年坚定不移的坚持,更是少之又少。
本文通过在Softmax损失函数中设置合适的权重系数,给小类样本乘以较大的权重,大类样本乘以较小的权重,来缓解本文数据集中存在的类别不平衡问题,实现提高模型准确率的目的。加权Softmax损失函数
(4)
式中:wj——损失函数的权重,wj=M/Mj;
M——训练样本的总数量;
Mj——某类别样本数量。
算法流程如图3所示。
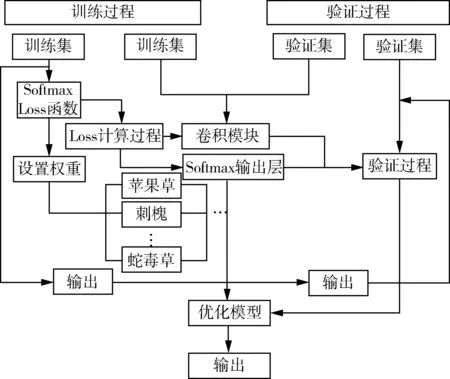
图3 模型流程图
2.4 知识蒸馏
在深度学习中一直存在着一个问题,那就是大模型预测效果好,却预测速度慢;而小模型预测速度快,但预测效果差。知识蒸馏[19-22]给该问题的解决提供了方法。知识蒸馏是通过一个模型较大的教师网络(精度更高)去指导一个模型较小的学生网络,来提升小模型网络的精度。针对杂草的识别,本文采用PaddlePaddle深度学习框架中基于包含1.4×107张图片的ImageNet-22k数据集的半监督知识蒸馏方案。知识蒸馏过程如图4所示。
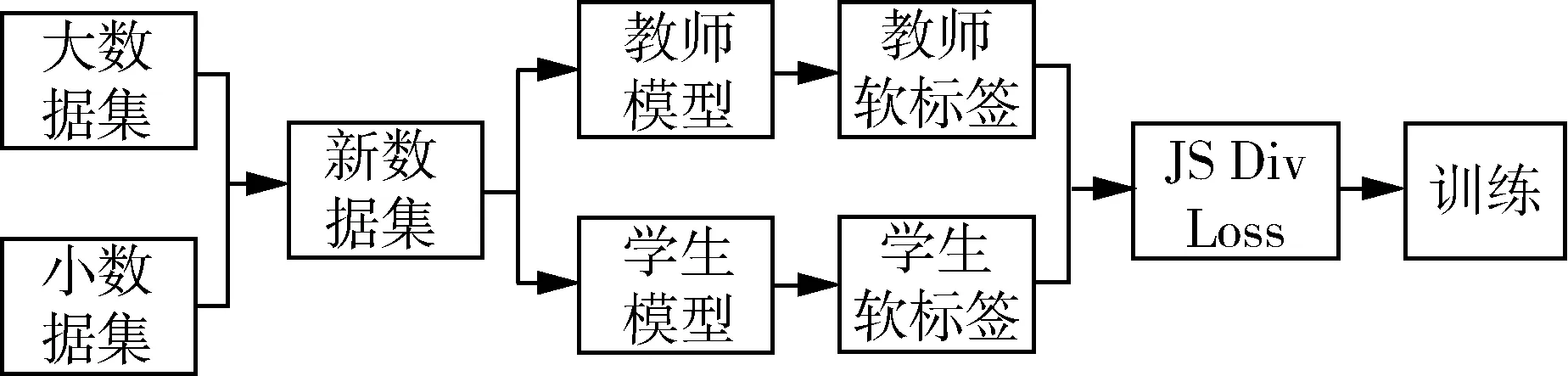
图4 从教师模型到学生模型的知识蒸馏过程
本文知识蒸馏方法如下。
1) 利用一个较大数据集,把学生模型和教师模型整合为一个新的网路,该网路分别输出学生模型和教师模型的预测分布,同时进行的是把教师模型的网路梯度固定,而学生模型可以做反向传播来更新参数。最后使用教师模型和学生模型的软标签输出来计算JS散度,并作为损失函数,用于蒸馏模型训练。
2) 对于大数据集上训练的模型,其学习的特征可能与小数据集上的数据特征有偏差,因此再利用小数据集对模型进行微调,得到优化后的模型。
3) 本文最后用得到的精度高的服务器端模型去指导训练速度快的移动端模型,得到新的知识蒸馏模型。
3 试验结果与分析
为了使选择的图像分类模型更具有效性和代表性,本文分别选取了服务器端和移动端的典型分类模型:服务器端模型选择ResNet系列模型,移动端模型选择MobileNetV3系列模型。在这两个系列模型中,选择性能更优的模型,然后采用半监督知识蒸馏方案预训练模型、设置加权Softmax权重等方法来进行试验对比,最后用得到的最优服务器端模型对移动端模型进行知识蒸馏,从而得到兼顾性能和规模的轻量模型。
3.1 试验设置
本文整个试验过程的操作系统为Windows10,服务器的配置为Intel(R) Xeon(R) Gold 6271C CPU @ 2.60 GHz×24、16 G的NVIDIA V100 GPU和32 G的运行内存。在此基础上搭建PaddlePaddle2.0.2深度学习框架,并用python3.7语言编程实现网络的训练和测试。
所有CNN模型默认参数设置如下:训练批处理BatchSize参数为32,测试批处理BatchSize参数为20,初始学习速率为0.012 5,动量因子设置为0.9,使用L2正则化,正则化参数λ=0.000 01。
3.2 两个基准系列模型的对比试验
ResNet系列和MobileNetV3系列模型作为基准模型被广泛应用,取得了很好的效果,具有很好的参照性。这两个系列的经典模型在DeepWeeds数据集上的识别准确率对比结果如图5所示,其中ResNet50_vd模型是对ResNet50模型进行了微调。从图5可以发现ResNet50_vd和MobileNetV3_large模型的性能表现相对更优。

图5 不同模型下平均识别准确率的比较
3.3 半监督知识蒸馏方法和加权Softmax权重方法的对比试验
DeepWeeds数据集存在一定的数据不平衡问题,针对这一问题,对模型应用加权Softmax损失函数方法。为得到更好的训练结果,采用PaddlePaddle深度学习框架中的半监督知识蒸馏方案,试验结果如图6所示。
其中加权表示在训练中设置不同类别的权重,ssld表示在训练中采用半监督知识蒸馏的方法。由图6可知,对于服务器端模型和移动端模型,使用半监督知识蒸馏的方法均可以提高平均识别准确率;对比每类模型设置权重和不设置权重的结果可知,设置权重均可以提高识别准确率。使用半监督知识蒸馏的方法,模型分类准确率可以增加0.5%以上。对采用半监督知识蒸馏方法的模型进行加权处理,分类准确率可以增加0.11%以上。对未采用半监督知识蒸馏方法的模型进行加权处理,分类准确率可以增加0.6%以上。半监督知识蒸馏方法和设置权重方法具有有效性,能够促进精度的提升。

图6 不同方法下平均识别准确率的比较
图7展示了两个服务器模型ResNet50和ResNet50_vd_ssld_w(_w表示进行了加权处理)在DeepWeeds数据集上的平均识别准确率的变化。从图7中可以看到当迭代次数在130以后,2个模型的平均识别准确率变化趋于稳定,同时ResNet50_vd_ssld_w模型的平均识别准确率更高,最高达到了97.97%。这主要是该模型使用了半监督知识蒸馏和加权Softmax权重的方法提升了训练精度。该模型比ResNet50基准模型的精度提升了0.7%左右。在NVIDIA V100(GPU)图形处理单元上训练每个模型的平均时间是4 h左右。
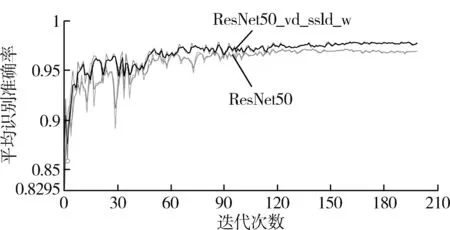
图7 ResNet50_vd_ssld_w与ResNet50模型的可视化对比
3.4 知识蒸馏方法的对比试验
服务器端模型的精度较高,但也存在着一些问题,比如:占用较多的计算资源,伴随较慢的计算速度以及带来较大的功耗。而移动端模型的优势:小模型,小计算量和高速度。为平衡精度和速度,本文采用知识蒸馏的办法,用高精度的教师模型ResNet50_vd_ssld_w(加权模型)来指导高速的学生模型MobileNetV3_large进行训练,从而得到ResNet_Mobile_ssld_w模型。经试验,学生模型选择的学习率为原学习率的1/10时,可以获得更好的学习精度,伴随着的是训练代数和时间变为原来的2倍,在NVIDIA V100(GPU)图形处理单元上的训练时间是8 h左右。知识蒸馏得到的ResNet_Mobile_ssld_w模型与ResNet50模型的平均识别准确率的可视化对比如图8所示。

图8 ResNet_Mobile_ssld_w与ResNet50模型的可视化对比
为更好地全面衡量模型的实际应用效果,本文不仅采用平均识别准确率AP(Average Precision)这一常用评价指标,同时考虑分类模型大小和推理速度以利于后期模型的应用和推广。具体试验结果如表2所示。
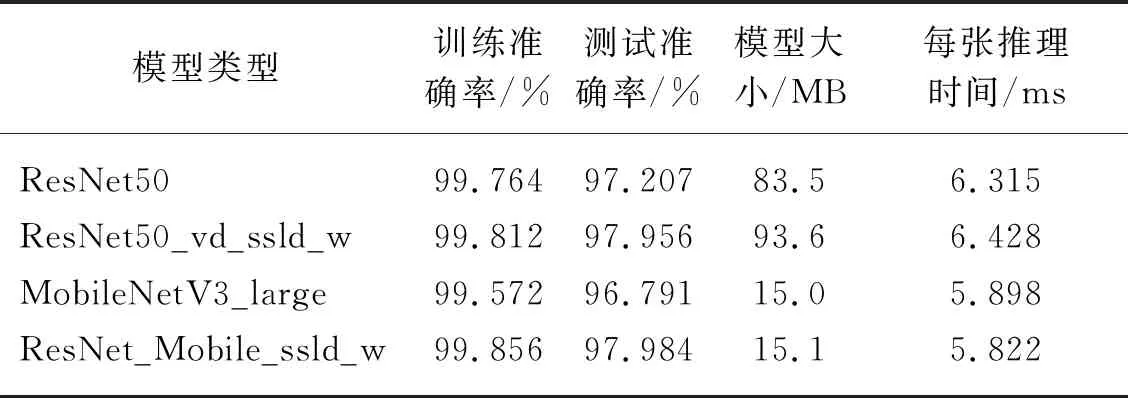
表2 模型参数对比
从表2中可以看出,蒸馏后的移动端模型ResNet_Mobile_ssld_w的AP值超过教师模型,达到97.984%。相比MobileNetV3_large模型,ResNet_Mobile_ssld_w在模型大小变化不大的情况下,识别准确率提升了将近1.2%。相比ResNet50基准模型,ResNet_Mobile_ssld_w模型的识别准确率提升0.78%,每张推理时间减少了7.8%,模型大小减少了近80%。该轻量模型保持较高识别准确率的情况下能够大幅降低计算资源和提高检测速度,这有利于推动后期杂草分类模型的落地实现。
4 结论
本文提出了一种基于MobileNetV3_large的杂草检测模型,试验表明该模型分类准确率高,检测速度快,模型规模小。经过训练后的模型在验证集上的AP值为97.984%,在NVIDIA V100图形处理单元上进行推理,平均每张图片的推理时间为5.822 ms,推理模型大小为15.1 MB。
1) 对比了ResNet系列和MobileNetV3系列的5种模型,其中的ResNet50_vd_ssld模型表现最好,对该模型采用加权处理,进一步提升ResNet50_vd_ssld模型精度,并选作教师模型。
2) 本文采用分类准确率最高的教师模型ResNet50_vd_ssld_w,通过知识蒸馏的方法指导MobileNetV3_large学生模型训练,得到ResNet_Mobile_ssld_w模型。该模型与未优化的MobileNetV3_large相比,AP值提高了1.2%,同时与ResNet50相比AP值提升了0.78%,平均每张推理时间减少了7.8%,模型大小减小80%,优势明显。
3) ResNet_Mobile_ssld_w模型检测精度高,在NVIDIA V100上的速度满足杂草实时检测的要求,但由于现实中便携设备(如机器人和物联网边缘设备)功率和计算资源有限,往往无法拥有这样的硬件资源,所以今后还需要结合便携设备的硬件资源,在不降低检测精度的情况下,提高模型的运行速度和减小模型的规模。
