基于改进候鸟迁徙优化的多目标批量流混合流水车间调度
2022-03-07汤洪涛王丹南邵益平赵文彬江伟光陈青丰
汤洪涛, 王丹南, 邵益平, 赵文彬, 江伟光, 陈青丰
(浙江工业大学 机械工程学院, 杭州 310023)
批量流混合流水车间调度问题(LS-HFSP)是批量流问题与混合流水车间调度问题(HFSP)的结合,广泛存在于炼钢、食品加工、制药等工业领域,近年来得到了学者的广泛关注[1-4].根据给定拆分子批大小是否相同,可以将批量流问题分为相等批量流问题与不相等批量流问题.相等批量流混合流水车间调度问题是目前研究较多的LS-HFSP问题,相等批量拆分是解决批量流问题的最简单、最直接的方法,一旦确定了子批数量,就可以确定每个子批的大小.但相等批量拆分只能优化子批的数量,无法优化每个子批的大小,并且在生产实际中大多为不相等批量流问题.对于不相等批量流混合流水车间调度问题,不仅要优化加工顺序,还要优化子批的数量和大小,从而大大增加了计算的复杂度.
近年来,国内外已经有学者在ILS-HFSP领域做了大量研究,但这些工作具有一定的局限性,现有研究以单目标优化[5-10]为主.文献[7]以最小化最大完工时间为目标,研究了柔性作业车间不相等批量拆分调度问题.文献[8]以最小化总延迟时间为目标,研究了K阶段不可混流的 ILS-HFSP问题.文献[9]以最小化最大完工时间为目标,研究了只在最后阶段具有多台并行机的K阶段不可混流的ILS-HFSP问题.文献[10]以最小化最大完工时间为目标,研究了考虑批量流与换模时间的柔性生产线调度问题.
目前关于多目标ILS-HFSP问题研究较少.文献[11]针对存在随机扰动的相等批量流混合流水车间调度问题,提出了多目标候鸟迁徙算法,解决了最小化总加工时间与子批开工时间偏差的多目标优化问题.文献[12]以减少平均停滞时间、能源消耗及提前和延迟造成损失为目标,研究了可变批次的批量流混合流水车间调度问题.文献[13]以最小化最大完工时间与最小延期为目标,研究了多目标批量流水车间问题.关于在制品的流水车间调度问题,研究也较少.文献[14]提出使用过滤算法,研究了卷烟生产中的在制品堆积及有限产能的动态调度问题.文献[15]以最优缓存区容量为目标优化生产排程,提高了瓶颈资源的利用率.文献[16]研究生产机组的订单序列,建立了数学模型优化生产速率、在制品数量和生产周期3个目标.
ILS-HFSP是个NP难问题,通常采用启发式算法来解决.候鸟迁徙优化(MBO)算法是一种最新发展的启发式算法,由文献[17]在2012年首次提出.该算法模拟以V形编队飞行的鸟类迁徙行为,每一只鸟都代表一种可行解.在该算法中,鸟群中个体的数量、要考虑的邻域解数、跟随解共享的邻域解数以及领导解更换后鸟群的迭代次数是影响其性能的4个重要参数,具有较强的局部搜索能力和简单的结构,已成功应用于二次分配、流水车间调度、信用卡欺诈等不同的研究领域[6-7,18-20].
上述研究表明,对于以最小化在制品数量为目标的多目标ILS-HFSP的研究尚处空白,而减少在制品数量对于降低企业成本、提高企业的管理能力有着重要意义,也是实现精益生产的必由之路.此外,目前研究以批量流混合流水车间调度理论研究为主,其机器阶段数和各阶段机器数量不固定,结合实际研究背景及固定形式的混合流水车间研究较少.因此,本文以最小化完工时间与最小平均在制品数量为目标,结合工程实际研究了三阶段混合流水车间的多目标ILS-HFSP,针对MBO算法各算子在算法运行不同阶段改进概率具有差异的特点,提出了一种基于变邻域搜索的自适应候鸟迁徙优化(AMBO)算法,并提出时间窗算子以加快算法的收敛速度.本文研究可为以最小化在制品数量与最大化生产速率的多目标ILS-HFSP问题提供理论依据.
1 问题描述
1.1 问题背景
某铝锅制造企业A现有一条混合流水线,如图1所示.其中:该生产线由拉伸段、内喷涂段与包装段组成,M11、M12为拉伸段内的两台相同拉伸机,M21为内喷涂段内的一台内喷涂机,M31为包装段内的一台包装机,B1、B2为缓存区.两台拉伸机的产能均为450个/h,内喷涂段的产能为900个/h,包装段的产能为800个/h.由于铝锅的型号规格众多,机器切换生产不同型号规格的产品时需要换模,每种型号规格的产品只配备一套模具以降低模具成本.此外, 产品的订单数量变化较大,排程方案需考虑将大订单拆分成若干个小订单以防止产线堵塞.订单经排程后形成包含产线可执行信息的工单,产线依据工单顺序依次生产.

图1 A公司铝锅产线构型图Fig.1 Configuration diagram of the aluminum pot production line of A Company
该混合流水线的每台拉伸机与内喷涂机同一时刻只能生产一种产品,拉伸机与内喷涂机需加工完当前工单后才能切换生产下一个工单.内喷涂机M21一次只能生产一种产品,拉伸机M11与拉伸机M12生产的不同产品需要根据加工顺序依次进入内喷涂机M21,尚未进行内喷涂的产品需在缓存区B1中等待.内喷涂段生产速率大于包装段,缓存区B2用以暂存未能及时包装的产品.
通过分析各机器生产速率可知,产线的生产瓶颈在于包装段,其最大生产速率总计为800个/h,而产线其他机器的产能有剩余.此外订单的产品数量差别较大,生产小批量订单加上换模时间将使产线的生产速率达不到包装线的速率引起产能损失;若一直生产大批量订单又可能导致在制品堆积问题.如何在最小化完工时间与在制品数量的两个目标下得到最优调度结果是本研究的主要内容.本研究的基本假设如下:
(1) 原材料不存在缺料情况;
(2) 每台机器的处理时间为固定值,机器不会出现故障;
(3) 数量较大的订单会拆分成若干个数量不等的工单;
(4) 拉伸机与内喷涂机的换模时间为固定值;
(5) 包装线的设置时间非常短,可认定为无换模时间;
(6) 任何两个订单的产品规格型号都不相同,无法共用一套模具;
(7) 缓存区为无限容量缓存区.
1.2 问题建模
本文研究一个有4台机器的三阶段不相等批量流混合流水车间调度问题,该三阶段不相等批量流混合流水车间调度问题具体描述如下:
(1) 本文的研究对象是一个2+1+1型三阶段混合流水车间,由第1阶段的两台并行(相同)机器和第2、3阶段各一台机器组成.在此混合流水车间中,机器换线生产不同订单的产品时需换模.第1阶段与第2阶段、第2阶段与第3阶段之间各设有一个缓存区.流水线形式及加工路线均满足1.1节所提出的背景要求.

由问题背景可知,除包装段外其余机器换线时需要进行换模设置,产线的拉伸段生产速率与内喷涂段的生产速率相同且都大于包装段的生产速率.为使两者产能匹配,存在一个最佳批量Q,每个产品以这个批量进行加工能使拉伸机、内喷涂段加工时间加上换模时间与包装段的加工时间相匹配.

根据上述问题描述以及定义的数学符号,建立如下数学模型:
(9)
目标函数:
(10)
(11)

式(1)表示同一工单在内喷涂机上的开始加工时间与该工单在拉伸机上开始加工时间的约束;式(2)表示每个工单的开始加工时间必须大于等于0;式(3)为机器k上的工单Sij的开始加工时间与完工时间之间的关系;式(4)~(7)分别表示在拉伸机1、拉伸机2、内喷涂机、包装线上,下一个工单的开始时间与上一个工单完工时间的约束;式(8)表示不同订单子批次(工单)在拉伸机1、拉伸机2和内喷涂机上是不可混流生产的;式(9)表示拆分后的每个工单的最小产品数;式(10)表示完成所有订单生产的最小化完工时间;式(11)表示产线的平均在制品数量最小化.
2 自适应候鸟迁徙优化算法
基本的MBO算法是针对二次分配这种连续函数优化问题提出的,不能直接用于处理HFSP这类离散的组合优化问题,需要转换成离散形式.本文基于候鸟迁徙优化算法,结合ILS-HFSP问题,提出一种AMBO算法,包括批量拆分规则、编码与解码机制、邻域搜索策略、种群初始化、领导解优化、跟随解优化、领导解替换与算子权重自适应调整等,可有效求解ILS-HFSP问题.
2.1 算法具体定义
2.1.1批量拆分规则 对于批量流问题,需要明确订单的拆分规则.常见的订单拆分方式为给定一个随机数,对需要拆分的订单随机拆分成该数量个子订单[5],随机数的选取范围需根据订单大小与问题特征具体问题具体分析.本研究的批量大小不完全相同,拆分批量的上下限应根据每个订单的大小进行调整.

CJi2Qmin

CJiQmin


CJi2Qmin, CJiQminéëêêùûúú
2.1.2编码与解码机制 ILS-HFSP问题需同时优化订单拆分问题和作业调度问题,因此编码应同时考虑这两个方面,本文采用两阶段编码方案.用自然数序列代表所有可能的工单排列,编码分为两段:第1段表示加工顺序;第2段表示待分配的工单编码,每个工单编码对应一个加工顺序编号.每个工单编码由一个工单编号与其对应工单的数量组成,工单编号数为4位整数,工单数量为5位整数.例如,工单编号为101,数量为 3 000 的工单的工单编码为010103000.编码示例如图2所示.

图2 编码示例Fig.2 Code sample
每个编码都代表订单拆分后的工单在内喷涂机上的排程结果,为了进一步得到每个工单在各机器上的加工时间序列,计算每个解的适应度值,需对编码进行解码.由于拉伸机1与拉伸机2并行工作,每个工单只能在其中一台机器上加工,解码时需要考虑两个问题:① 所有工单在机器上的开始加工时间与完工时间;② 系统平均在制品数量.其具体过程如下.
假设有b个工单,其在内喷涂机上的加工序列为∂=(∂1, ∂2, …, ∂b),即依次将工单∂q从∂中取出并执行如下步骤.
步骤1选取具有最先空闲时间的拉伸机,将工单∂q分配到该机器上,确定其在该拉伸机上的开始加工时间与完工时间;
步骤2重复步骤1,直到完成所有工单的拉伸机分配;
步骤3根据加工序列与各工单在拉伸机上完工时间依次计算每个工单在内喷涂机上的开始加工时间与完工时间;
步骤4根据每个工单在内喷涂机上的完工时间,计算每个工单在包装线的开始加工时间与完工时间,得到加工完所有工单的最终完工时间;
步骤5根据解码所得到的各工单在其对应加工机器上的开始加工时间、结束加工时间、各机器的节拍与换模时间,计算流水车间开始加工到结束加工的平均在制品数量.
2.1.3适应度函数值 在得到解在各机器上的加工时间后,需要评估解的适应度值来完成领导解、跟随解的排序选择.本文采用权重和法处理多目标优化问题,由于研究的两个目标具有不同量纲,需先进行目标归一化处理,具体过程如下所示:
(12)

(13)
式中:λ1、λ2为2个目标函数的权重.
最小化总加时间与最小化平均在制品数量是本研究的两个目标,产线优化的首要目标是最大化生产速率使得企业效益最大化,而最小化平均在制品数量是为减少成本,属于次要目标,取权重λ1=0.6,λ2=0.4.
2.2 改进策略
2.2.1邻域搜索算子 MBO算法是一种基于邻域搜索的元启发式算法,因此有必要为其确定高效的邻域搜索算子.基于本文所采用的两阶段编码机制,从文献[21]中引入4种常见的邻域算子,分别为插入算子、贪婪插入算子、交换算子、贪婪交换算子.交换算子计算量小但局部搜索能力有限;贪婪算子虽然能提高局部搜索的结果,但会极大增加计算量.为平衡计算量与局部搜索结果,基于最佳批量原则本文提出一种时间窗算子,使其以较短的时间得到较优的解.以上算子都是针对调度子问题,针对批量拆分子问题,本文采用批量调整算子,使各订单的工单数与工单的产品数随算法迭代调整.
(1) 时间窗算子.
由于工单产品数量各不相同,首先定义一个推进时间窗W=[tes,tlf],tes为在内喷涂机处任务的开始时间,tlf为在内喷涂机处任务的结束时间,其是预测时域内包含一定数量工单的时间窗口,而其平均宽度取2Qt3.时间窗为2Q的匹配度较小,因此增加一个宽放系数γ,使时间窗的宽度取为
(2-2γ)Qt3≤tlf-tes≤(2+2γ)Qt3
(14)
式中:γ为时间窗的宽放系数,常见的宽放系数为0.05、0.1、0.2等,为尽可能匹配较多的订单,取宽放系数为0.2.
每次搜索的目标是从当前解中随机寻找拉伸机编号不相同的两个未被匹配时间窗的工单,对其进行时间窗匹配,形成一个新的邻域解,且满足如下订单关系式:
(2+2γ)Qt3
(15)


图3 时间窗算子Fig.3 Time window operation
步骤1将当前鸟中的所有工单输入到一个搜索集中;
步骤2判断搜索集是否为空,若为空则采用随机交换操作形成邻域解并结束邻域搜索;
步骤3寻找搜索集中产品数量最大的工单;
步骤4判断该工单与其后一工单是否能满足时间窗约束,若满足时间窗约束则将找到的订单2加工序号与订单1后的加工序号交换,若不能则跳到步骤5;
步骤5寻找个体中能与其满足时间窗约束的工单,若无法找到,则将该工单从搜索集中剔除并重复步骤1~5,若找到则将找到的工单与其后一工单位置进行交换形成新的解.
(2) 批量调整算子.
在工单编码段任选一个具有两个以上工单的订单,选择其中两个相邻的工单对其重新分配:随机选取其中一工单中随机数量的产品分配到另一工单中.若重新分配后的工单数量低于最小批量Qmin,则以50%概率将该工单全部分配到另一工单中,并将该工单所属订单的工单数减1;以50%的概率使该工单产品数量等于最小批量Qmin,并将其余数量的产品分配给另一工单.例如,一个 1 300 与 4 400 的工单组合,随机调整成 1 600 与 4 100 的组合.批量调整算子示意图如图4所示.
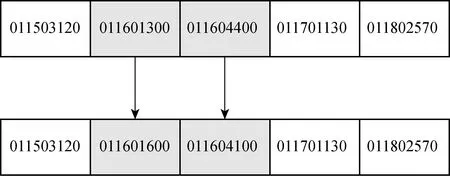
图4 批量调整算子示意图Fig.4 Diagram of batch adjustment operation
上述邻域搜索算子分别针对不同的子问题,如果只采用其中一种很难找到全局最优解.为了有效地联合两个子问题,提出了以下混合结构.
(1) 混合结构1:首先执行插入算子,然后执行批量调整算子.
(2) 混合结构2:首先执行贪婪插入算子,然后执行批量调整算子.
(3) 混合结构3:首先执行交换算子,然后执行批量调整算子.
(4) 混合结构4:首先执行贪婪交换算子,然后执行批量调整算子.
(5) 混合结构5:首先执行时间窗算子,然后执行批量调整算子.
2.2.2邻域算子权重自适应调整 本文采用了4种常见的邻域算子、时间窗算子、批量调整算子以及5种混合结构共计11种算子.为有效利用所采用的11种不同邻域算子,采用变邻域搜索策略使各算子的邻域得到充分探索.本文采用轮盘赌的方法,给每个算子以一个权重,在每次进行邻域搜索操作时根据每个算子权重随机选择邻域搜索算子得到邻域解.
邻域搜索的每个算子在算法的不同阶段对解的改进效果各不相同,例如在算法求解的初始阶段应优先选择全局搜索能力强的算子,在后期调整阶段应优先选择局部搜索能力强的算子.因此本文引入自适应调整策略[22],使每个邻域算子权重随算法迭代自动调整,其具体计算如下.
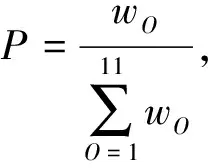
(16)
式中:πO为算子O经过m次迭代后的得分累计情况,其初始值为0,若表现比最优解好,则取πO=πO+1,对其余算子取原值;θO为算子O经过一个权重调整周期时算子O使用的次数;r为反应因子,控制权重调整规则对启发式方法的效率变化作出反应的速度与权重调整幅度.如果r为0,那么将完全不使用分数,而是保持初始权重.如果r设置为1,则在最后一代中获得的分数决定权重.本文取r为0.5,在反应速度与调整幅度之间保持平衡.设每个算子的初始权重为1,当算法完成一个迭代周期m后更新每个算子被选择的概率P,并重新将算子的权重设为1.
2.2.3扰动机制 MBO算法的邻域搜索机制过度关注了算法的局部搜索能力,为平衡算法的全局搜索和局部搜索能力,将扰动机制引入到MBO算法中.记g为扰动机制触发周期,如果领导解连续g次迭代没有更新,则扰动机制触发.在基本的扰动机制中,防止解陷入局部搜索的方法是用随机产生的新解将其替换.完全随机的方法会影响到算法的执行效率,为提高算法的执行效率,在连续第g次领导解没有更新时,以领导解为种子,引入Glover操作产生两个解分别替换领导解的左右跟随解.Glover操作将解序列拆分成z个子解序列,每个子序列以z为步长依次从原解序列中挑选组成,然后将z个子序列重新组合成扰动后的解序列.Glover操作的优势在于可以从种子解进行发散产生新解,并且新解继承旧解的序列信息,有利于提高算法的执行效率,已被文献[5,23-24]等用于防止算法陷入局部最优解中,取得了良好的效果,并根据文献[5]采用z=3作为Glover操作的参数.
2.3 AMBO算法实现
AMBO算法包含以下几个步骤:种群初始化、领导解改进、跟随解改进、领导解替换与算子权重更新、循环迭代与扰动机制.具体流程如图5所示.

图5 AMBO算法流程图Fig.5 Flowchart of AMBO algorithm
步骤1初始化种群.首先,设置AMBO算法的6个控制参数,包括鸟(解)群中个体的数量(α),要考虑的邻域解数(β),跟随解共享的邻域解数(χ),领导解更换后鸟群的迭代次数(ω),算子权重自适应调整周期(m)、扰动机制触发周期(g).然后根据批量拆分规则对所需排程的订单任务拆分后对每个工单赋以随机加工顺序生成一个可行解,重复此过程生成α个解,选取适应度最优的解作为领导解,并将其余解随机安置在V形种群结构上形成初始种群.
步骤2领导解改进.根据各算子的初始权重得到相应被选择概率,采用轮盘赌方法围绕领导解生成β个邻域解.首先,对所得到的邻域解根据解码结果评估其适应度值,如果邻域解中最优解的适应度值优于领导解,那么领导解将被替换;否则,领导解保持不变.然后,将未使用的邻域根据其适应度值选取最优的2χ个解,分别形成包含χ个邻域解的左、右共享邻域集.
步骤3跟随解改进.改进过程是沿着尾巴进行的.对于左(右)队列中的跟随解(例如X),根据各邻域算子权重以轮盘赌方式产生β个邻域解.所产生的β个邻域解和左(右)共享邻域集中的解被视为X的邻域集,对所得的邻域集根据解码结果评估其适应度值.如果最佳邻域解比X具有更好的适应性,则替换X;否则将保持跟随解不变.随后,在未使用的邻域中选择最优的χ个解,用来重建左(右)共享邻域集.重复上述过程,直到遍历完左队列和右队列中的所有跟随解为止.
步骤4领导解替换与算子权重更新.在执行第3步ω次后,若追随解中的最优解比领导解适应值更优,则将最优追随解与当前最优解相互交换以更新领导解,否则解将保持不变.根据不同算子对解的改进情况更新其算子权重,并判断是否达到邻域搜索算子权重更新周期,若达到邻域搜索算子权重更新周期,依据邻域算子权重自适应调整式(16)分别更新每个算子的权重,并依据权重更新每个算子被选择的概率.
步骤5循环迭代与扰动机制.为了防止算法陷入局部最优,采用Glover 操作对g次迭代后未更新的领导解进行扰动,取两个新解分别替换领导解后的左、右跟随解.算法在若干次迭代后如果达到最大迭代次数,则算法终止;否则,重复步骤2~5直到满足算法终止条件.
3 仿真实验研究
3.1 算例产生规则
A企业的订单统计分析后具有以下特征,产品数量在3×103以下、3×103~1×104与1×104~2×104的订单分别占据其所有订单数的80%、15%与5%,产品总数量分别占所有订单的产品数总和的50%、30%与20%.出于A企业接单能力、成本、效率等因素的考虑,最大订单数量不超过2×104,最小订单数量不小于103,即Qmin=103.设定所有订单的产品数量都能被10整除,订单的数量特征如表1所示.

表1 订单产品的数量特征Tab.1 Quantity characteristics of product orders
文献[5]指出,目前关于批量流水车间调度问题没有基准算例,为此本文根据表1的订单产品数量特征,随机产生不同规模的订单任务作为算例来评估算法性能.各机器的生产速率以及问题背景保持一致:拉伸机1与拉伸机2的生产速率为4.5×102个/h,内喷涂机的生产速率为9×102个/h,包装段的生产速率为8×102个/h.拉伸机1、拉伸机2与内喷涂机的换模时间都为30 min,可以得到最佳加工批量Q=3.6×103.
3.2 参数设置
参数设置通常在元启发式算法的有效性中起到重要作用.为了得到AMBO算法的最优参数,采用实验设计(DOE)方法设计了田口实验.AMBO算法中有6个控制因素,包括了α、β、χ、ω、m、g.由于β≥2χ+1,所以参数β、χ不满足实验设计要求.本文采用文献[17]建议的参数β=3、χ=1,将α、ω、m、g这4个参数作为实验因子,以一组订单数量为20的30个随机案例的平均值来测试在算法运行100 s时的平均最优结果值,通过Minitab17设计并运行分析最佳参数配置.
参考文献[5-6]中的因子水平,设计了4因子3水平的L9型正交田口实验,其各因子的3个水平取值分别为α{α1=25,α2=51,α3=81}、ω{ω1=5,ω2=10,ω3=15}、m{m1=5,m2=10,m3=15}、g{g1=10,g2=20,g3=30},表2为所设计的L9正交实验及相应的实验平均值.在Minitab17中分析后得到均值的主效应图如图6所示,其中:μ为每种参数的平均响应值.均值响应表如表3所示,其中:Δ为每个因子最大平均值减去最小平均值.从图6中可以得到,α=51、ω=10、m=10、g=10的参数组合下,AMBO算法将具有更好的性能.因此,将α=51、β=3、χ=1、ω=10、m=10、g=10作为AMBO算法的初始化参数.

表2 正交矩阵及响应值Tab.2 Orthogonal matrices and response values

图6 均值主效应图Fig.6 Mean main effects plot

表3 均值响应表Tab.3 Mean response table
3.3 算法测试
为验证AMBO算法求解问题的有效性,将其与基本MBO、遗传(GA)算法对比.因为问题的NP难特性,不能保证得到问题的最优解.因此,以多次重复实验所得到的最优解的平均值作为衡量算法求解精度,采用最优解的标准偏差评价算法的稳定性.因为订单随机性的影响,为了能够得到更多可靠的数据,算法在不同订单规模下随机生成30个订单任务,再对每个订单任务重复运行30次,得到每个任务的最优解平均值与标准偏差,分别对所得到的30个订单任务的最优解平均值与标准偏差取平均值,即得到所评价算法在该规模下的最优解平均值与标准偏差.
3种算法编码规则完全一致,其中遗传算法参数为种群规模为500,交叉概率Pc=0.8,交叉算子选用顺序交叉,变异概率Pm=0.1,变异算子选用插入算子与批量调整算子;AMBO算法参数为鸟群中个体的数量α=51,要考虑的邻域解数β=3,跟随鸟共享的邻域解数χ=1,领导鸟更换后鸟群的迭代次数ω=10,算子权重自适应调整周期m=10,扰动机制触发周期g=10;基本MBO算法的参数引自文献[17]:鸟群中个体的数量α=51,要考虑的邻域解(β=3,跟随鸟共享的邻域解数χ=1,领导鸟更换后鸟群的迭代次数ω=10,邻域算子采用插入算子、交换算子与批量调整算子.将算法终止条件统一设置为连续迭代100次最优值不变;采用MATLAB 2014b编程,测试环境为Windows 10系统,CPU为i7-7700k、内存为16 GB.随机生成30个订单总数为20的任务,每个任务进行30次重复实验,得到的平均值与其标准偏差(SD)结果如表4所示.
3种算法实验所得的最优解均值、解的标准偏差、平均收敛迭代次数及算法平均运行时间的结果如表5所示,并根据算法迭代过程绘制了3种算法的平均收敛过程图如图7所示.其中:ξ为迭代次数;κ为每次迭代中30次重复的多目标最优值.

图7 3种算法收敛效果图Fig.7 Convergence effect diagram of three algorithms
由表4、表5和图7可知,GA算法收敛较快,但易陷入局部最优,求解精度差;而基本MBO算法虽然有一定的局部搜索能力,但其搜索能力有限,收敛速度慢且容易陷入局部最优,无法使候鸟集中在最优值附近;而本文提出的AMBO算法,采用了自适应算子权重与变邻域搜索,加快收敛速度且增强了局部搜索能力,较其他两种算法其求解精度更高,稳定性更好,求解时间与MBO算法较为接近,说明了AMBO算法的有效性.

表4 算法结果对比Tab.4 Comparison of algorithm results

表5 3种算法的实验结果Tab.5 Experimental results of three algorithms
进一步验证算法的有效性与稳定性,用3种算法对不同任务量求解.表6分别为订单总数为30、40、50的3种不同任务规模随机重复平均实验结果.
由表6可以看出,在小规模算例中,随着任务规模的增大,最优解均值会增加,算法运行时间将明显增加,算法平均收敛次数增加也十分明显.GA算法在收敛速度上有一定的优势,但其缺点在于容易陷入局部最优.MBO算法在运行时间上比GA慢,但其全局搜索结果比GA更好.AMBO算法的求解时间相比于GA算法较长,与MBO算法较接近,但其求解精度与解的标准偏差均优于MBO算法与GA算法.

表6 3种算法在不同规模下的实验结果
上述测试算例规模较小,为进一步测试算例规模对算法的影响,选取任务规模为60、80、100的大规模案例,以最大CPU运行时间为终止条件,每个任务规模随机重复30次,以相对百分比增加率[6](RPI)值与其标准差测试各算法寻优能力.最大CPU运行时间正比于量规模,因此设定CPU运行时间为n×ρ,n为订单总数,即排产任务规模,ρ为设置的常数,随着算法规模的增加,算法的测试时间也将增加,为了综合比较算法的性能,设置三种不同的ρ分别为10、20、30 s,在ρ=30时所对比算法大部分已达到收敛状态.RPI值计算公式如下:
(17)

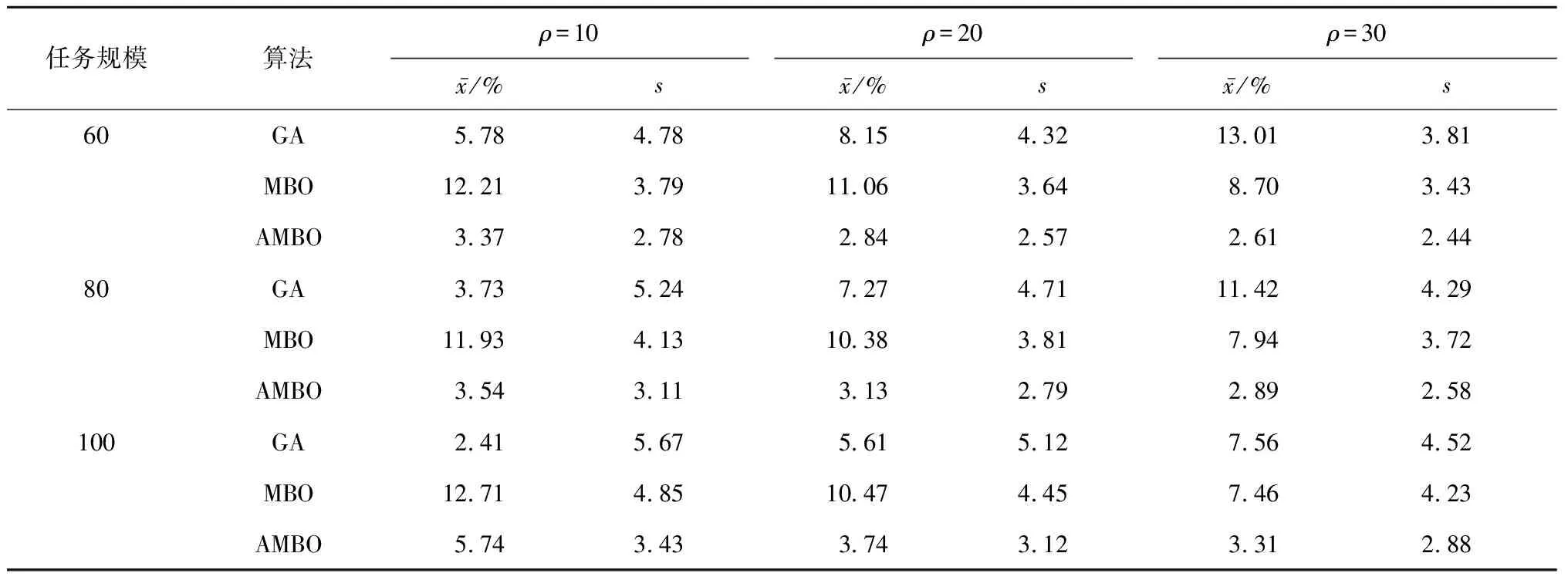
表7 当ρ=10,20,30时,GA、MBO与AMBO算法RPI值比较Tab.7 Comparison of RPI among GA, MBO, and AMBO algorithms at ρ=10,20, and 30

表8 当ρ=10,20,30时,AMBO与对比算法的T检验结果比较
由表7和8可知,当ρ=10,任务规模为60的测试实例中,AMBO算法均优于MBO算法与GA算法;任务规模为80的测试实例中,AMBO算法GA算法无显著差异,但优于MBO算法;任务规模为100的测试实例中,AMBO算法劣于GA算法但优于MBO算法.当ρ=20,30时,AMBO算法能在所有测试实例中优于MBO算法与GA算法.AMBO算法为了保证精度而牺牲了求解速度,在大规模算例中,尽管AMBO算法在分配较少的时间(ρ=10)时劣于GA,但在分配更多CPU时间(ρ=20,30)后,AMBO仍优于GA算法.因此,在大规模算例下,AMBO算法总体上优于MBO算法与GA算法.
从上述测试结果可以看出,AMBO算法在任务规模为50以下的小规模算例中,其求解精度与稳定性均优于MBO算法与GA算法;在大规模算例中,AMBO算法的寻优能力优于MBO算法,虽然在较少CPU时间内会劣于GA算法,但总体优于GA算法,故能说明AMBO算法的有效性.
4 结语
针对2+1+1型三阶段混合流水车间的ILS-HFSP,提出了基于变邻域搜索的AMBO算法,解决了最小化完工时间与最小化系统平均在制品数量的多目标优化问题.所设计的算法借鉴了自适应大邻域搜索算法,在邻域算子处设计了时间窗算子与算子权重随算法的迭代自适应调整策略,提高了算法的全局搜索能力与求解精度.通过对不同规模任务的30次随机重复实验,表明所建立的调度数学模型及改进的候鸟迁徙优化算法是可行有效的,AMBO算法相比于MBO算法与GA算法,具有求解质量更高、最优解标准偏差更小的优点.本研究可以降低混合流水车间的平均在制品数量,填补了ILS-HFSP问题关于最小化完工时间与最小化在制品数量多目标优化研究的空白,也更符合工厂实际生产.未来将结合缓存区配置优化与动态排程等方面进行进一步研究.
