An iterative data-driven turbulence modeling framework based on Reynolds stress representation
2022-03-04YuhuiYinZhiShenYufeiZhangHaixinChenSongFu
Yuhui Yin, Zhi Shen, Yufei Zhang, Haixin Chen, Song Fu
a School of Aerospace Engineering, Tsinghua University, Beijing 100084, China
b China Academy of Launch Vehicle Technology, Beijing 100076, China
Keywords:Turbulence modeling Reynolds-averaged Navier-Stokes equations Reynolds stress representation Machine learning
ABSTRACT Data-driven turbulence modeling studies have reached such a stage that the basic framework is settled,but several essential issues remain that strongly affect the performance. Two problems are studied in the current research: (1) the processing of the Reynolds stress tensor and (2) the coupling method between the machine learning model and flow solver. For the Reynolds stress processing issue, we perform the theoretical derivation to extend the relevant tensor arguments of Reynolds stress. Then, the tensor representation theorem is employed to give the complete irreducible invariants and integrity basis. An adaptive regularization term is employed to enhance the representation performance. For the coupling issue, an iterative coupling framework with consistent convergence is proposed and then applied to a canonical separated flow. The results have high consistency with the direct numerical simulation true values, which proves the validity of the current approach.
1. Introduction
Modern engineering design requires high accuracy of flow separation prediction for the computational fluid dynamics (CFD) computation. For the complex turbulent flow separation problem, the traditional turbulence simulation methods either produce unsatisfactory flow prediction or require large computational costs, which cannot meet the requirements of accuracy and efficiency. With the rapid development of data science and machine learning (ML)techniques, the influences of flow structure and physical features that are ignored or difficult to consider in traditional turbulence modeling can be extracted and mapped to the turbulence quantities. The obtained augmented turbulence is referred to as datadriven turbulence modeling. Duraisamy et al. [1] demonstrated the data-driven turbulence modeling as a mathematical expression.First, the baseline turbulence model can be expressed as M:
There exist three elements in the expression. (1) w represents a set of independent variables selected from mean flow quantities.(2) P (■) represents the algebraic or differential equations that w follows. (3) c represents a set of parameters that are generally calibrated with canonical flows.
The high-fidelity data, denoted byθ, can take effect in several aspects to augment the baseline turbulence model, leading to the data-driven turbulence model,~M:
The expression shows four roles that the data can play. (1)Extend the set of independent variables w [2,3]. (2) Modify certain terms in the governing equations P (■) [4–8]. (3) Recalibrate model parameters c [9–12]. (4) Directly model the discrepancyδbetween the model and true values [13–25]. Sometimes the baseline model prediction is neglected, and the discrepancy changes to the entire true value. This situation is also included in the fourth direction.
Different choices of correction terms reflect the researchers’view of where the main discrepancy is located and correspond to different upper limits of augmentation. Regardless of the direction,the final obtained model can be regarded as a new constitutive relation that can predict Reynolds stress and mean flow quantities closer to the true values.
1.1. Classification of predicting targets
The complexity of the Reynolds stress leads to different strategies for selecting the predicting targets, each having its advantages and limitations. Four commonly employed choices are separately reviewed as follows from the aspects of spatial invariance, physical interpretability, and smoothness.
(1) The first choice is the multiplying factor of the turbulence model equation term, marked asβ(x) [4–8,26–30]. As a scalar field, predictingβcan ensure spatial invariance. By multiplying a spatially non-uniform factor fieldβ(x), the turbulent quantities in certain areas are altered and the overall performance of the turbulence model can be enhanced. The statistical inference method is generally employed to solve the inverse problem. After acquiring theβfield, a machine learning model is trained to predict theβfield using mean flow featuresη. The entire process is named field inversion machine learning (FIML) [6–8].However, the inferredβfield can yield a quite close result, but the Reynolds stress might be far from the truth because there might exist many different turbulence fields all producing the same mean flow field. The inference cannot guarantee the correct turbulence field.
(2) The second choice is the eddy viscosityνt. Also, as a scalar,predictingνtsatisfies the spatial invariance. A similar problem asβis how to acquire the “correct”νt. There are two methods. The first is employing statistical inference. By changing the inferred variable from the turbulence model term to the turbulence model result, the optimalνtfield can be directly acquired [31]. However, the inferredνtfaces the same problem as FIML. The second is to compute the optimal viscosity using the pointwise least-square approximation [3,21]. However, the result might lose clear physical implications and smoothness in the complex flow region where the Reynolds stress anisotropy is remarkable, which deteriorates the model performance.
(3) The third choice involves the Reynolds stress eigenvalues (k,λ1,λ2) and eigenvectors (v1, v2, v3) [2,3,32]. Selecting such targets means discarding all the assumptions and modeling the entire stress as a second-order symmetric tensor. These features can be computed by eigendecomposition of the true value from high fidelity databases, or by inference from observed mean flow quantities [33].
The eigendecomposition method needs to deal with the spatial invariance problem. The invariance of three scalars (k, λ1,λ2) can be guaranteed but the vectors (v1, v2, v3) are naturally spatially variant. One solution is to introduce the baseline eigenvectors and change the targets to the discrepancy between two sets of vectors [3,32]. Such a treatment introduces spatial rotation invariance, but reflection invariance is still missing. In addition, the rotation angle faces discontinuity because of the switching of the eigenvalue ranking and needs further numerical treatment [32].
(4) The fourth choice is the Reynolds stress representation based on the tensor function representation theorem. This method comes from the nonlinear eddy viscosity model (marked as NEVM below) in traditional turbulence modeling. Researchers supposed the Reynolds stress as a tensor function of strain rate S and rotation rateΩ, which is:
In addition, prior physics of turbulence modeling require the tensor function to be isotropic under the extended Galilean transformation [34], which means that the symmetric transformation group of the Reynolds stress function is the entire full orthogonal group (rotation and reflection), which is:
where Q is a temporal-constant orthogonal matrix.
Pope [35] deduced 10 tensor bases (referred to as the integrity basis) and 5 invariants formed by S andΩusing the Cayley-Hamilton theorem. Any symmetric isotropic tensor can be obtained by the linear combination of the 10 tensor bases and the coeffi-cients are functions of the 5 invariants.
One clear advantage of the Reynolds stress representation is a combination of the accuracy and realizability. Taking multiple tensor bases evades the poor performance ofνmt. Meanwhile, the coefficients are all scalars, naturally guaranteeing spatial invariance.Therefore, current research follows this direction.
1.2. The coupling method: frozen and iterative
After the predicting targets are selected, we need to select a coupling method between the ML model and the CFD solver, which can be divided into two categories: frozen substitution and iterative substitution.
In frozen substitution, the ML model establishes the mapping from the mean flow features computed by the baseline model to the Reynolds stress true value. Therefore, when used for prediction, the baseline Reynolds-averaged Navier-Stokes (RANS) simulation is performed to acquire the baseline mean features. The model is executed once, and the predicted value corresponds to the true stress. The stress is then substituted into the RANS equations and frozen until convergence. The flow chart is shown in Fig. 1a.
In the iterative substitution, the model establishes the mapping from the true mean flow features obtained from the high-fidelity database, e.g., the direct numerical simulation (DNS) results, to the true Reynolds stress. When used for prediction, using the baseline input features leads to incorrect stress at the beginning. Therefore,iteration is needed, and the model is executed in each CFD iteration step. After the iteration converges, the mean flow and the Reynolds stress both converge to correct results. The flow chart is shown in Fig. 1b.
The model training and performance are greatly affected by the coupling method. First, the coupling directly affects the training data preparation. In the frozen framework, the input features are constructed from the baseline model, and the relevant quantities including the primitive variables (ρ, u,p) and turbulence variables(k, ω) are easy to acquire. However, in the iterative framework, input features are constructed from the true value, e.g., the DNS result. However, most DNS databases do not provide turbulent dissipation. How to generate a (ω) field compatible with the true result is worth considering. Noted that similar problems are also discussed in several researches by Akolekar et al. [36], Schmelzer et al. [17], Liu et al. [21], and Duraisamy [37]. Given that there is no unified statement of the issue, the problem is referred to as “truth compatibility” in the current research.
Second, the coupling affects convergence and accuracy. Inappropriate Reynolds stress treatments may cause ill-conditioned problems [38], which means that the computed mean flow given the true stress is different from the true mean flow. Relevant studies reached a consensus that the iterative framework has better accuracy and decreases the propagation error. However, the iterative framework may encounter convergence difficulty because the model needs to take the intermediate flow quantities as input and ensure that the iteration ends in the final correct results, which requires the ML model to have strong dynamic robustness.
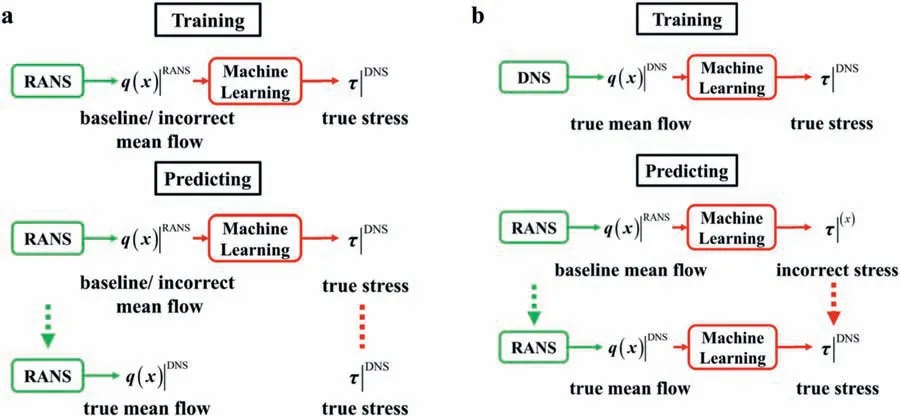
Fig. 1. Two coupling methods of the ML and CFD solver. a The frozen method. b The iterative method.
Third, importantly, the coupling method determines the physical relevance between the input and the stress. In the frozen framework, the mapping from baseline mean flow to true stress lacks sufficient physical implications. The excavated rule by the ML is more like identifying the baseline error region and modifying it, but not a constitutive relation. In contrast, in the iterative framework, the mapping is established from true mean flow to true stress. The physical relevance is more reasonable, and the excavated rule is closer to the nature of turbulence.
In summary, the two coupling methods each have their advantages and limitations. In the current research, since we have selected the Reynolds representation coefficients as targets, the consistency between the mean flow and the stress is more necessary and should be guaranteed first. Therefore, we selected the iterative framework.
1.3. Motivation
In the present work, we construct an iterative data-driven turbulence modeling framework based on Reynolds stress representation. Two main processes have been developed. First, we review the selection of tensor arguments that the Reynolds stress depends on and further discuss the physical implications. We then reformulate the tensor invariants and integrity basis using the tensor function representation theorem. The results under two-dimensional flow and three-dimensional flow are given out separately.
Second, a novel iterative framework is proposed. The framework is designed to manifest “consistent convergence” including the truth compatibility and the dynamic robustness mentioned above. In addition, the framework separates the ML process and the Reynolds stress representation, while nearly all earlier studies combined them. The treatment greatly enhances the physical interpretability and smoothness of the coefficients and the final prediction performance.
The rest of this paper is organized as follows. Sect. 2 introduces the methodology from three aspects: tensor representation analysis, framework construction, and representation coefficient computation. Sect. 3 presents the numerical results of ML model training and prediction of the canonical periodic hill flow. Sect. 4 discusses the effect of the remaining part after the Reynolds stress representation and the ML model calling frequency. Sect. 5 summarizes the paper.
2. Methodology
The three-dimensional compressible RANS equations for a Newtonian fluid without body force, heat transfer, and heat generation are
whereλandμare the bulk viscosity and molecular viscosity, respectively. T represents the total stress tensor, including the pressure, the molecular viscous stress, and the Reynolds stressτthat must be closed.
Regardless of traditional modeling or data-driven modeling,τcan always be expressed as follows:
(S,Ω,···)represents tensor arguments of the Reynolds stress function. The argument can be a vector, two-order symmetric tensor, or two-order antisymmetric tensor.(Tturb,Lturb)represents the turbulent time scale and length scale, which are generally constructed by (k, ω). To build a new constitutive relation, the first step is to select proper arguments. Then the tensor invariants and integrity basis can be acquired, which leads to the first part of the methodology.
2.1. . Tensor representation analysi s
2.1.1. Extension of the tensor arguments
Tensor representation analysis has been employed in turbulence modeling for decades. As mentioned above, since Lumley [39] and Pope [35] proposed a complete form of the NEVM, with the development of subsequent studies [40–42], the model using (S,Ω)as tensor arguments is currently being perfected. In the current research, we start from the basic nonlinear eddy viscosity model and explore other potential tensor arguments apart from (S,Ω). More specifically, we evaluate the hypotheses of the NEVM and introduce additional quantities when these hypotheses do not hold.
The original form of the NEVM deduced by Lumley [39] is as follows:
whereqis the turbulent velocity scale, andξ= x/(q3/ε) is the nondimensional spatial coordinate normalized byqand the dissipation rateε. Two assumptions are used during the deduction: (1)incompressible turbulence, (2) weak historical effect.
The first assumption is the incompressible hypothesis. In the incompressible flow, the pressure can be obtained from the mean velocity field through the Poisson equation, and the velocity field contains all the mean field information. However, most flow problems in actual engineering are compressible. The pressure becomes an independent state variable, which should be added to the arguments set.
The second assumption is the weak historical effect. The consideration of including the historical effect is also a key direction in traditional modeling research. A commonly used approach is to consider the temporal and spatial historical effects in S to produce an “effective” strain rate~S [43], which can be expressed as a convolution form:
whereΛmis the turbulent time scale. We perform series expansion at local (x,t) on the equation above:
Taking the first-order approximation, the above expression shows that ˜S includes the local S and the total derivative DS/Dt.We further deduce the transport equation of S by applying the left gradient and right gradient to the mean velocity equation and summing them. The final result is shown below:
We analyze the right-hand side of the equation in sequence.(S2+Ω2) can be expressed by the integrity basis of (S,Ω).νΔS represents the viscous diffusion and is not an active source term dominating the historical effect. The remaining two terms are the pressure gradient related term and the Reynolds stress gradient related term. If we want to represent the effect of ˜S, the two gradients should be included.
Based on the analysis above, this paper adds two additional tensor arguments into the original (S,Ω), which are the pressure gradient vector vpand the turbulent kinetic energy (marked as TKE below) gradient vector vk, defined as follows:
The final Reynolds stress isotropic tensor function is
Generally, the TKE is solved by its own transport equation and the expression above can be normalized to
where b is the nondimensional Reynolds deviatoric tensor b=τ/2k-I/3, and the superscript ^(·)means normalization using turbulence scales, as Eq. (14) shows.
It is worth mentioning that the final tensor argument set is basically the same as in earlier studies [3,32], except including the density into the pressure term and the alternative normalization.The main purpose of this part is to systematically deduce the additional tensor arguments rather than determine the arguments ad hoc.
2.1.2. Complete irreducible tensor invariants and integrity basis
The implication of the tensor function representation is briefly introduced in Sect. 1.1. Here, we restate the representation of b in a mathematical manner. Given a set of tensor arguments, the isotropic tensor function representation theorem indicates that any composed tensor function can be expressed as a linear combinati o nof several tensor bases:
(I1,I2, ...,Ia) are the complete and irreducible tensor invariants formed by the argument set. Completeness means that all the other invariants can be represented by these invariants. Irreducibility means that they are independent of each other. Ti, i=1,2,...,ware the complete and irreducible tensor bases. Tiare all second-order symmetric tensors and collectively referred to as the integrity basis.giare the representation coefficients corresponding to the tensor bases, which are all functions of the invariants (I1,I2, ...,Ia).
The representation process is to acquire the invariants and integrity basis. Theoretically this set of invariants and tensor bases is applicable to all symmetric tensors. If identifying b as the target, a corresponding set ofgiis settled simultaneously.
There are two methods to compute the invariants and integrity basis. The traditional method uses the Cayley-Hamilton theorem.This theorem indicates that a high-degree tensor polynomial can be expressed by low-degree polynomials. In the actual computation process, the general form of the tensor polynomial composed of this set of tensor arguments is given first. Then, the C-H theorem is repeatedly applied to the polynomial to simplify the expression. Finally, a set of low-degree tensor bases and invariants appearing in the reduction process are acquired. The deduction of Pope [35] followed this method. However, there are deficiencies.First, the general form of tensor polynomials is easy to acquire only if the number of arguments is small, for example, only S andΩ. If the number increases, the general form will be complex and multiple, increasing the difficulty of reduction. Second, it is also difficult to prove whether the final results are irreducible. For example, the 10 tensor bases given by Pope were proven not to be the minimal representation in later research [40].
We employ the other method proposed by Zheng [44] which directly constructs the basis rather than simplifying it from a complex situation. This method can directly and systematically deduce the results for any number of tensor arguments. We suppose a symmetric tensor function H is composed ofLsymmetric tensors Ai, mantisymmetric tensors Wp, andNvectors vm:
It is difficult to directly find invariants and tensor bases and to verify their completeness and irreducibility. Therefore, introducing intermediate variables to transform the problem is necessary. For the construction of invariants, the intermediate variable is each component of tensor arguments. For the construction of tensor bases, the intermediate variable is the complete orthogonal basis of the symmetric second-order tensor in space.
For invariants, because of the definition of invariance, they can be computed using the components of all arguments no matter in which coordinate system and remain unchanged. Therefore, in turn, if we construct a set of invariants that can represent all the components in a certain coordinate, these invariants are complete and can represent all the scalar-valued functions. The requirements above for the invariants (I1,I2, ...,Ia) can be described mathematically as:
whereχtrepresents each component of tensor arguments. Because a symmetric tensor contains 6 independent components, an antisymmetric tensor contains 3, and a vector contains 3, there are in total (6L+3M+3N) components.
For tensor bases, after acquiring the invariants above, to further represent a symmetric tensor-valued function, we should select a set of tensor bases that can express all 6 complete orthogonal bases expanding the entire symmetric tensor space, which is described as:
where the coefficientsηware isotropic functions of (I1,I2, ...,Ia) and E1, E2,..., E6are:
e1,e2, e3are three independent orthogonal basis vectors constructing the entire space.
One advantage of the method is that the coordinate can be properly selected to minimize the number of components needing representation. For example, when dealing with a symmetric tensor, the coordinate can be the same as its principal axes, and there only exist 3 independent components. When multiple tensor arguments exist, all the possibilities between the principal axes need to be considered and the final complete form is acquired.
In the current research, we employ the method above and further develop the conclusion. The original work only gave the general expression in three-dimensional space of the situation in which the numbers of Ai, Wpare arbitrary but all the vmare collinear. We deduce the situation with arbitrary numbers of Ai,Wpand vm. In addition, the expression in two-dimensional space is also acquired. The two expressions are listed in the Appendix.Here we only give the two-dimensional situation of the argument set(ˆS,ˆΩ,ˆvp,ˆvk). There are a total of 11 invariants and 7 tensor bases, as follows:
The form of vectorsvp/vkis worthy of mention. In earlier studies, the vectors are transformed to corresponding antisymmetric tensors using A=-ε·v, whereεis the permutation tensor.In the current research, the vectors are directly introduced. To verify which treatment is rational, we takeAk=-ε·vkin a twodimensional situation as an example. The components of b, S, and Akare as follows:
whereA13=-A31=∂k/∂y, A23=-A32=-∂k/∂x. According to the representation theorem, if Akis used, there should be(SAk-AkS)in the integrity basis, the components of(SAk-AkS)can be computed as:
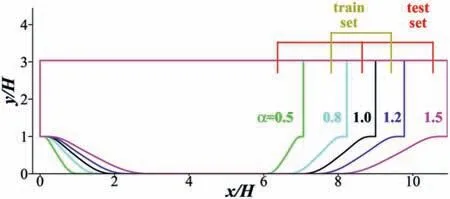
Fig. 2. Parameterized periodic hill geometries with different α [32].
It can be found that this term makes no contribution to the component to the deviatoric stress b. Therefore, it is physically unreasonable. As a comparison, if vkis used, the term(vk⊗vk)is:
wherev1=∂k/∂x,v2=∂k/∂y. This term makes an effective contribution to b.
In summary, in this part, we extend the tensor argument set from (S,Ω) to (S,Ω, vp, vk) and deduce the corresponding invariants and integrity basis in three-dimensional and two-dimensional situations. The difference between the current treatment and earlier studies is analyzed, proving the validity.
2.2. Framework construction
We illustrate the construction of the data-driven turbulence modeling framework according to the sequence of preprocessing,training, predicting, and solving.
2.2.1. Training data preparation
The first step of preprocessing is to determine what data should be used for the construction. The flow case used for the training and testing in the current research is the periodic hill. There exists a massive flow separation area near the leeward side of the curved wall, which makes it difficult for the RANS method to accurately simulate the flow. The parameterized periodic hill geometries and corresponding databases provided by Xiao et al. [45] are employed. The factorαis introduced to scale the hill width, as shown in Fig. 2. The Reynolds number based onHand the bulk velocity at crestUbisReb= 5600 for all 5 cases. The DNS simulations are conducted under incompressible conditions. Theα= 0.8 and 1.2 are selected as the training set andα= 0.5, 1.0, and 1.5 are selected as the testing set, which is consistent with our previous work [32].
The following issue after the flow case selection is to determine the status in which the training data should be. In Sect. 1.2, we propose the truth compatibility requirement, which is simply described as “all the features are constructed from the true value”.The subsequent problem is that the true values of some quantities cannot be acquired from the high-fidelity database. To overcome this problem, we extend the implication of truth compatibility by substituting the “true value” with the “end-state value”.
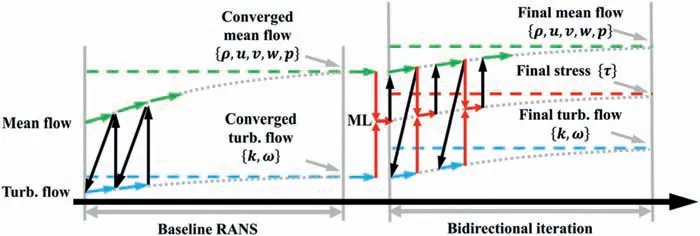
Fig. 3. CFD solution process of the iterative framework.
The end-state value is defined as the quantity for which the computation converges. To better illustrate the end-state of different variables, the CFD solving process is explained first, as shown in Fig. 3. The lateral axis represents the iteration. The left part shows the baseline RANS process. The green and blue arrows represent the iteration of the mean and turbulent flow, respectively.The black arrows represent the data transfer, and the dotted lines represent the converged results. The right part shows the iterative computation. The ML model is introduced and executed in each iteration step (red arrows). The mean flow, ML-predicted Reynolds stress, and turbulent flow each have their own convergence paths and end-states. The mean flow receives the Reynolds stress from the ML model and the end-state value is the DNS true value, which is the ultimate aim of the framework. The ML model computes the Reynolds stress using input features from mean flow and turbulent flow and transfers the stress to the mean flow. The end-state value is also the DNS true value because only the true Reynolds stress corresponds to the true mean flow. However, the turbulent flow follows a different path. During the iteration, (k, ω) only serves as the reference value to nondimensionalize the input features of the ML model, which means that the turbulence equations only accept mean flow results and no longer transfer back. Therefore, the end-state values of (k, ω) do not correspond to the true turbulence, but instead the converged results of the turbulence equations given the true mean flow, as shown by the blue dotted line.
In summary, the end-state values are divided into two categories. The first type corresponds to the DNS true value, including the mean flow features such as S,Ω, andÑ(p/ρ) and the Reynolds stressτ. The training data should be interpolated from the DNS fine grid to the RANS coarse grid and discretized if gradients are needed.
The second type corresponds to the variables that are not true but compatible with the true values, including the turbulent flow features given by the baseline turbulence equations (k, ω). To acquire the results, the turbulence model needs to be solved solely with all the mean flow terms frozen as the DNS true values. Noted that the turbulent viscosityνtin the (k,ω) equations is not frozen,but iterated with the (k, ω). In each iteration step, theνtis computed using the same expression in the baseline SST turbulence model:
where thea1andF2are the parameters in the SST model,Ωis the norm of the rotation rate tensor.
The computed (k, ω) can never be the same with the directly statistical (k, ω) of DNS because of the deficiency of the fluctuation information of physical quantities during the modeling. But on the other hand, although they are not the correct values, they can reflect the actual turbulence behavior to some extend. Therefore,such (k, ω) are up to the task performing as the nondimensionalization parameters. Since they are different from both the original baseline RANS and the true DNS, they are referred to as pseudo DNS results in this paper, abbreviated as (k,ω)pDNS. Theνtused in the following features is also computed by (k, ω)pDNS.
At the end of this section, the truth compatibility problem is further discussed and the differences between the current research and the former researches [17,21,36] are clarified. Computing the frozen turbulence model equations using true mean flow quantities is a commonly employed method in iterative frameworks to acquire the compatible turbulent quantities. The first difference is the treatment of TKE. In the work of Liu et al. [21], thekpDNSis the only TKE appearing in the framework, which is reasonable because the predicting target in the work isνtand the true TKE is not necessary. Schmelzer et al. [17] employed a more complicated treatment of TKE by constructing thePkterm with the true Reynolds deviatoric tensor b and adding an additional corrective termR. The purpose is to directly computing the true TKE with the modified turbulence model equation. The attempt to separating different aspects of correction is fascinating but the left remedy termRstill lacks physical interpretability.
The treatment in current research is a trade-off between the two methods above. The original turbulence model equations are not modified but only substituted with true mean flow quantities.The acquiredkpDNSonly works as the turbulent scales for nondimensionalization. When predicting the entire Reynolds stress, the TKE is predicted using a sole machine learning model corresponding to the true TKE from DNS results. The machine learning model of TKE will be further illustrated in Sect. 2.2.3. As a summary, the current method retains the original simple and robust form of the turbulence model equations and predicts the true TKE for the reconstruction of the Reynolds stress simultaneously.
2.2.2. Input feature selection
Once the training data are acquired, the next step is to construct the input feature set. In this paper we follow the feature selection criteria proposed in our earlier research [32]. The input features are constructed from two perspectives: tensor analysis and flow characteristic.
The tensor analysis perspective is based on the Reynolds representation illustrated above. The acquired 11 complete irreducible tensor invariants of (S,Ω, vp, vk) are shown in Eq. (20). The number and some expressions of invariants in the current research are different from those in earlier research. This is because a new treatment of vectors is employed, and the new one is more effective as proven in Sect. 2.1.
The flow characteristic perspective includes two parts: flow structure identification and turb./mean flow relative strength. The first part extracts the key flow structures relevant to turbulence

Table 1 Input features in the current research.
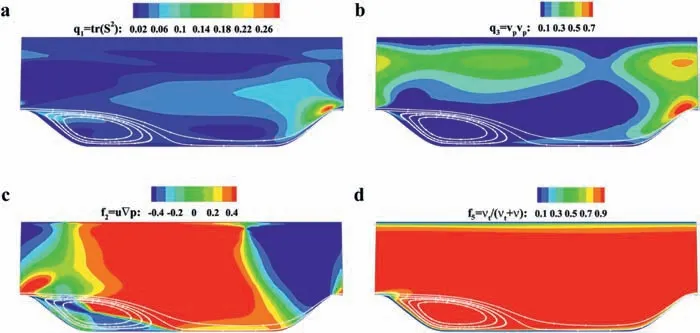
Fig. 4. Four representative input features. a q1 = tr(S2). b q3 = vp□vp. c f2 = u□∇p. d f5 = νt/(νt+ν).
production or dissipation, such as the free shear layer and the strong adverse pressure gradient flow, by selecting several marker functions. The second part directly shows the intensity distribution of the turbulence, which can help locate the region with high uncertainty and provide the modifying direction.
Considering the smoothness and effectiveness, not all 11 invariants are selected. Those high-degree invariants with small magnitudes and unsmooth distributions are abandoned and 4 invariantsq1,q2,q3,q4remain. The flow characteristic perspective provides 5 more input featuresf1-f5. Note that the marker of the shear layer and swirl flow has a different expression compared to the previous work [32] because the formerly usedd2Ω/(νt+ν)leads to large values far away from the wall.

where the symbol “||□||” represents the tensor norm. Such a“a/(|a|+b)” treatment can constrain the value range to (-1, 1) without significantly changing the original distribution. The thought is also employed in some flow characteristic perspective features.
Four representative features are shown in Fig. 4. The white solid lines indicate the flow paths of the DNS results. Different features correspond to different flow structures and regions, such as the boundary layer, shear layer, and adverse pressure gradient flow. A significant advantage is that all features are compatible with the true mean flow rather than the baseline mean flow in the frozen framework, which guarantees a “truth to truth” mapping.2.2.3. Predicting target selection
We have illustrated the concept of the Reynolds stress representation in Sect. 2 A. The representation form is given in Eq. (15) and the expression of tensor bases is given in Eq. (21). Therefore, the only unknown variables are the representation coefficientsgi. In traditional modeling, the stress expression is substituted into the algebraic stress equation and simplified. The acquired coefficients are complex polynomials of the invariants [40]. In data-driven modeling, with the help of the DNS database, the determination ofgibecomes a numerical optimization problem.
The predicting targets in former ML frameworks based on the Reynolds stress representation generally follow the idea of a tensor basis neural network (marked as TBNN below) [13]. This concept is characterized by embedding the combination ofgiand Tiinto the ML model, as shown in Fig. 5a. The output of the ML model is the directly predicted deviatoric stress bpred, and the loss function is defined as
Thegiterm is not explicitly shown, but only performs as the latent variables. No more preprocessing is needed besides separating the DNS Reynolds stressτtrueinto the magnitude and btrue.
Several deficiencies exist in the framework above. First, embeddinggiTiinto the ML model makesgiinaccessible. The training process only minimizes the discrepancy of the final combination,while the distribution of each coefficient is ignored. This mixes the error of model training and the representation. Second, the estimation of the TKE is generally missing in former studies. The reason for this might be that the TBNN using dimensionless features as input cannot be directly used to map a dimensional quantity.

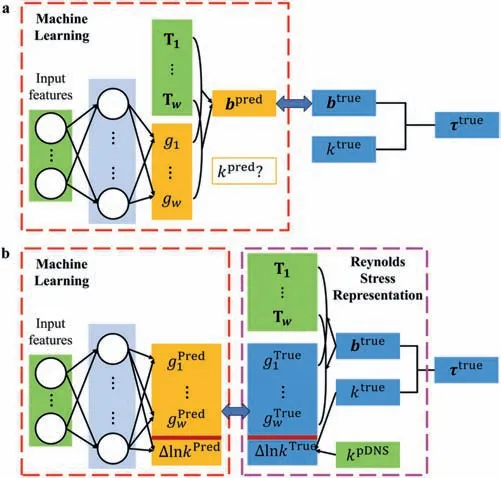
Fig. 5. Comparison of the entire framework and predicting target selection. a Previous framework [13]. b Current framework.

The current framework can remedy the problems of the former framework in the following aspects. First, the true TKE value is predicted, which further improves the modeling accuracy of the Reynolds stress. The treatment ofΔlnkmakes the target dimensionless and suitable for the ML model. In addition, by introducing the pDNS value computed by the baseline turbulence model,prior knowledge is included in the model, which can also decrease the modeling difficulty and benefit the convergence. Second, the separation of the ML and the Reynolds stress representation enables us to evaluate the physical interpretation and smoothness of representation coefficients before the training. As will be stated in Sect. 2.3, the direct computation ofgtrueiusing Eq. (28) yields severely nonphysical and unsmooth distributions. In a separated representation part, the constraints and regularization are easier to impose without affecting the model training.
2.2.4. Model training and prediction
The model training and prediction flow chart is shown in Fig. 6,which can be summarized in the following steps:
(1) Interpolate the DNS mean flow results onto the RANS grid and discretize to acquire qDNS, interpolate the DNS Reynolds stress onto the RANS grid to acquireτDNS.
(2) Iterate the turbulence equations with the mean flow quantities frozen as the DNS results to acquire (k,ω)pDNS.
(3) Compute the TKE discrepancyΔlnkand representation coeffi-cientsgiusingτDNS, qDNS, and (k,ω)pDNS.
(4) Train the ML model:f:{qDNS,(k,ε)pDNS}→{Δlnk, gi}.
(5) During the application, the computation restarts from the baseline RANS results. In each iteration step, the ML model is executed using q and (k,ω) to predict the Reynolds stressτpre.
(6) The final mean flow q|finalis acquired after the computation converges.
2.3. Representation coefficient computation
2.3.1. Tensor basis selection
The 7 tensor bases given in Eq. (21) are theoretically independent. However, not all bases are selected considering the practical representation effect, numerical error, and computational robustness. The tensor bases are gradually added into the set one by one from low-degree to high-degree. The corresponding representation effect and the mean flow result achieved by substituting the acquired {Δlnk, gi} into the CFD solver are evaluated.
It is found that the addition of the pressure gradient vpcorrelation terms does not significantly improve the representation effect and leads to divergence during the substitution computation.In addition, the high-degree tensor polynomials such as T5, T6, T7are small-valued and exhibit strong numerical oscillation, which also has no effect on the representation process. Therefore, 3 tensor bases are selected and remarked as T1-, T2, T3:
The components in the shear stress direction are shown in Fig. 7.
2.3.2. Adaptive regularization method
The representation coefficients can be computed by solving the optimization problem given by Eq. (28). However, it is found that such acquired coefficients lack smoothness and physical interpretability if the original expression is directly used. Taking theα= 1.0 case as an example, the coefficientg1acquired by directly solving Eq. (28) is shown in Fig. 8a, and the corresponding Reynolds shear stress is shown in Fig. 9a. The true value is shown in Fig. 9e. Although the representation effect is quite promising,the coefficient distribution is far from satisfactory. The presented value range is truncated for the following comparison, while the actual value range is far greater. Such severely varying coefficients will result in substantial prediction error during the ML model training.
In addition to the magnitude, the distribution of directly solved coefficients also faces nonphysical and unsmooth problems. The relation betweeng1and eddy viscosityνtcan be deduced by taking the first term in Eq. (15):
The original expression of the eddy viscosity isνt=Cμk/ω,whereCμis an empirical parameter requiring calibration. As it is a constant,Cμcan be included in the definition ofνt, which is the procedure of the program in the current research. Therefore, the equation above is further simplified by substituting the expression ofνt:
Note that whetherCμis included in the definition ofνtvaries in different programs. In the current program,Cμis included.
Therefore, a negativeg1corresponds to a positive eddy viscosity and positive dissipation. However, the value of the directly solvedg1is positive in a considerable part of the flow field. The CFD solving process diverges when substituting the coefficients into the RANS equations, which confirms the deterioration of robustness because of negative dissipation. The unsmoothness is marked by the dashed box in Fig. 8a, where the coefficient jump occurs.

Fig. 6. Model training and prediction flow chart.
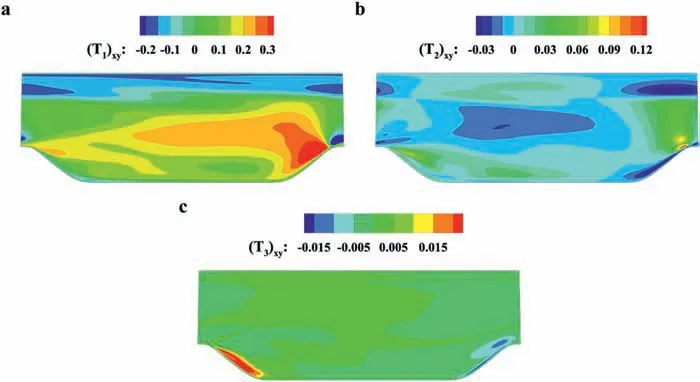
Fig. 7. The components in the shear stress direction of the selected tensor bases. a T1 =S. b T2 =SΩ-ΩS. c T3 =vk ⊗vk.
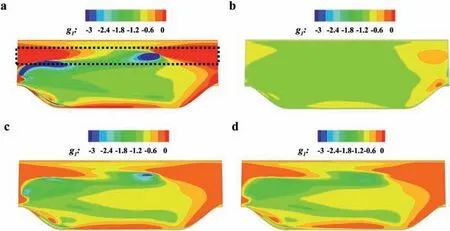
Fig. 8. Coefficient distribution comparison of different regularizations. a No regularization (λ = 0). b Large regularization (λ = 0.1). c Small regularization (λ = 0.001). d Adaptive regularization (varying λ).
In consideration of the coefficient distribution, it is found that the non-physical and unsmooth areas are mainly located at the main flow near the upper surface. The flow field in these areas has almost no mean flow characteristics such as the velocity gradient;therefore, there is almost no turbulence production. However, because of the spatial transport effect of the turbulence, the Reynolds stress can still be conveyed from other areas. If the coefficients are still computed using the original expression (Eq. (28)) in these areas, the representation process can be analogous to “dividing by zero” and lead to the value jump. Although the Reynolds stress in these areas cannot be accurately represented, the actual magnitude is relatively small, and the influence on the mean flow is limited,which reminds us that the coefficients in these areas can be specifically processed to ensure smoothness.
To overcome the problems above, two methods are proposed in the current research. First, the value range ofg1is constrained to(-∞, 0) to ensure positive dissipation, which can be solved using the constrained least square method.
Second, we introduce the regularization termR. Regularization is a commonly employed method to limit the drastic changes of coefficients. By adding an additional term into the target function,the optimization not only minimizes the original target but also considers the effect ofR. Taking the neural network training as an example, the modified loss function ˜Lwith the commonly used L2
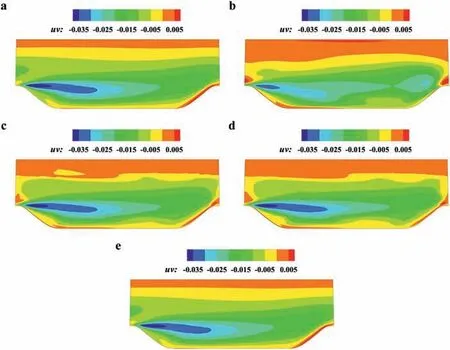
Fig. 9. Reynolds shear stress distribution comparison of different regularizations. a No regularization (λ = 0). b Large regularization (λ = 0.1). c Small regularization(λ = 0.001). d Adaptive regularization (varying λ). e True value.

To verify the regularization effect, large and smallλvalues are selected, and theg1distributions are shown in Fig. 8b and 8c.The corresponding Reynolds shear stress distributions are shown in Fig. 9b and 9c. The comparison shows that employing regularization surely constrains the coefficient near the baseline value but also decreases the representation effect.λ= 0.1 leads to better smoothness, but the discrepancy between the true stress and represented stress is larger. In contrast,λ= 0.001 cannot eliminate the unsmooth area, but the represented stress is closer to the true value.
In summary, employing a unified regularization parameter in the entire flow field cannot meet the requirements of improving the representation effect in key areas and ensuring smoothness in other areas simultaneously. To overcome this deficiency, combined with the previous analysis of the nonphysical and unsmooth problems, an adaptive regularization method based on the magnitude of the tensor basis is proposed in the current research.λvaries for differentgiand is defined as:

whereθiis the threshold for different Ti, which is predetermined manually based on the distribution of ||Ti||. When ||Ti||>θi,βapproaches 0, andλapproachesλmin; conversely, when ||Ti||<θi,βapproaches 1 andλapproachesλmax. In the current research,theθifor each Tiis [0.1, 0.05, 0.01].λminandλmaxare 0.001 and 0.1, respectively. It is worthy mentioning that the selection ofθiseems to be ad hoc. The entire strain rate and rotation rate magnitude will no doubt vary a lot for different flow conditions. But after normalized by the turbulent quantities, the nondimensional||Ti|| actually does not vary so much. The final prediction results of the stress field and mean flow field at different geometries can prove the validity.
The computed coefficient distribution and corresponding Reynolds shear stress are shown in Figs. 8d and 9d. The coefficient distribution and the represented Reynolds shear stress with adaptive regularization show better smoothness in those mainstream areas compared with the small regularization and better accuracy in those critical areas such as the separation shear layer at the same time. Therefore, the results with adaptive regularization are selected as the goal of the following ML training.
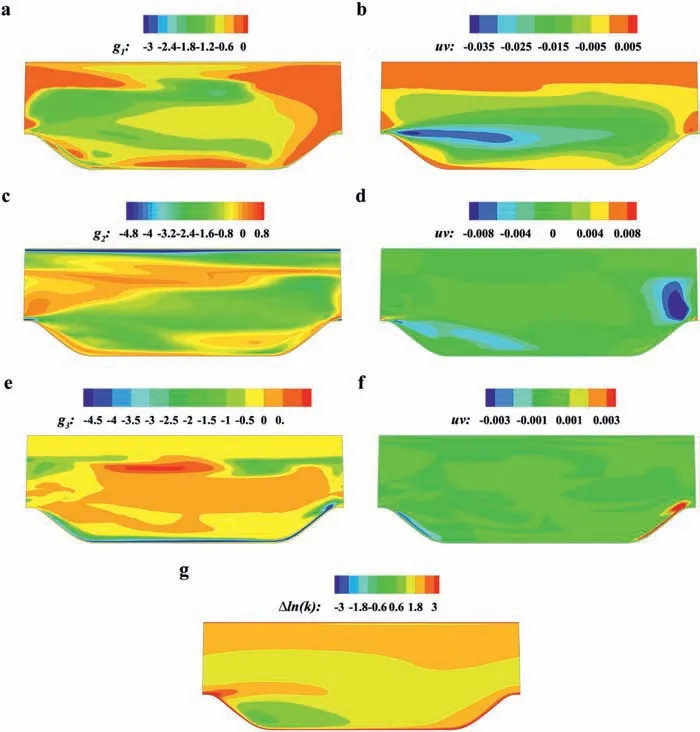
Fig. 10. Predicting targets and corresponding Reynolds shear stress components. a Coefficient g1. b Shear stress of g1S. c Coefficient g2. d Shear stress of g2(SΩ-ΩS). e Coefficient g3. f Shear stress of g3(vk ⊗vk). g Δln k.
The final acquired prediction targets {Δlnk, gi} are shown in Fig. 10a, 10c, 10e, and 10g. The corresponding Reynolds shear stress represented by each tensor basis is shown in Fig. 10b, 10d and 10f. The first tensor basis T1=S, corresponding to the linear eddy viscosity part, still occupies the majority of the entire representation result. T2=(SΩ-ΩS)and T3=(vk⊗vk)supplement the Reynolds stress near the separation shear layer and the boundary layer near the curved wall. TheΔlnkdistribution indicates that the TKE is underestimated near the separation shear layer, which is an important reason for the inaccurate separation bubble prediction.
3. Results
3.1. ML model training
The ML model is trained after the training data preparation and representation coefficient computation according to the methods above. The random forest (RF) is selected as the ML model in the current research. The RF model is a representative of integrated learning that is realized by combining multiple simple learning machines. During the training of RF, the entire training set is separated into several subsets and a decision tree is trained on each subset. Random feature selection is introduced to ensure the "good but different" characteristics of the decision trees and avoid overfitting. The final prediction result is acquired by averaging all the decision tree results. The entire flow chart is shown in Fig. 11.The ML training is realized using the sci-kit learn package [48] in Python.
Four RF models are trained for each target. The number of decision trees is determined by comparing the effect of different selections. 300, 500, and 700 are tested. The results show that there is clear enhancement between 300 and 500, but the difference between 500 and 700 is not significant. Therefore, the number 500 is selected. The loss function type is the mean absolute error. The maximum feature number is log2(9) ≈3 according to the “log2”rule. The feature importance rankings are shown in Fig. 12. The influence of features differs in each target, indicating the rationality of the individual training of each model.
3.2. Iterative computation platform
The trained ML model needs to be coupled with the CFD code and executed in each step. The CFD code used in the current research is the open-source CFL3D Version 6.7 programmed by Fortran, while the ML model is constructed in Python. The solving process will be extremely inefficient if the data are transferred by writing/reading files. Therefore, an iterative computation platform based on hybrid programming of Fortran/Python is developed. With the help of the CFFI module in Python, the Python part is packaged into a dynamic link library and coupled with CFL3D.The flow chart of computation is shown in Fig. 13.
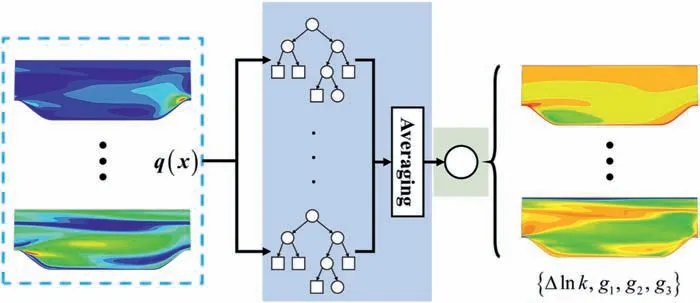
Fig. 11. The entire framework of RF.
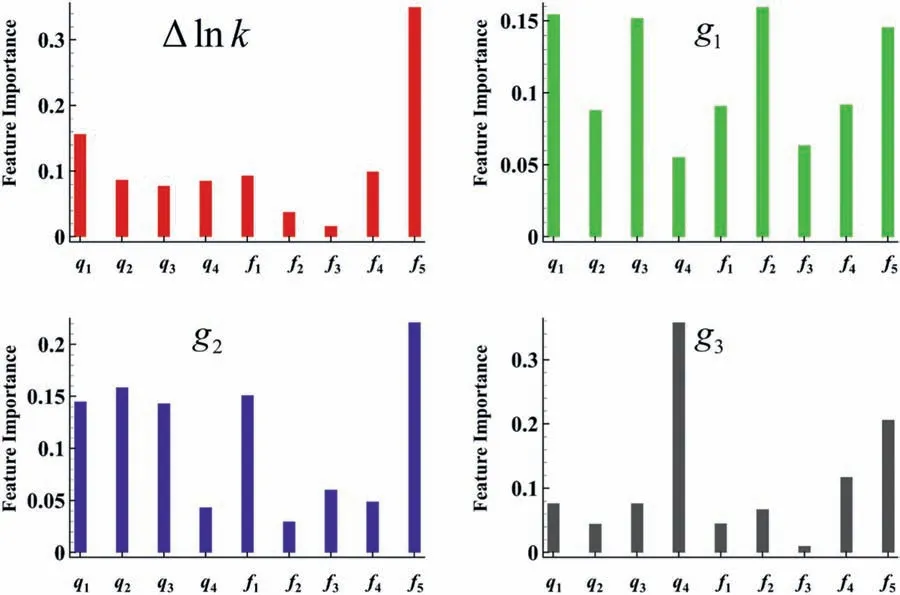
Fig. 12. Feature importance rankings of different targets.
3.3. Prediction performance
The Reynolds stress and mean flow prediction are evaluated after the iterative computation converges. To verify the generalization capability, we mainly focus on the performance of the three testing sets. From the aspect of the hill slope, theα= 0.5 and 1.5 cases are extrapolation cases, and theα= 1.0 case is an interpolation case. The comparison between the predicted and theoretical values of Reynolds shear stress for the testing cases is shown in Fig. 14. The theoretical values are computed by the Reynolds stress representation using the true Reynolds stress and mean flow field.Therefore, the theoretical value is only the part that can be represented by three tensor bases but is close enough to the true stress,as compared in Fig. 9. More details about the treatment of the discrepancy between the two distributions are discussed in Sect. 4.
The theoretical values indicate that the Reynolds stress of the testing cases are quite different in distribution and magnitude,which requires the ML model to have a strong generalization capability. The prediction values are close to the theoretical values in key areas, such as the separated shear layer and boundary layer,but there still exist some unsmooth areas.
Further evaluation of the mean flow field. The velocity contours are shown in Fig. 15, and the profiles are shown in Fig. 16. The comparison of lower surface friction is shown in Fig. 17. In these comparisons, the reference values are selected as the true value directly from the DNS results since the final purpose of the datadriven turbulence modeling is to correct the mean flow field.
The velocity contour comparison indicates that the mean flow field has better smoothness than the Reynolds stress distribution.This is reasonable because the Reynolds stress can be regarded as an external source term in the velocity transport equation. The unsmooth distribution of the Reynolds stress can be modified by the transport and dissipation of the RANS equation. The iterative embedding framework of the ML model can further increase the coupling effect of the mean flow and the Reynolds stress. The unsmoothness problem near the mainstream area in our previous work [32] is also resolved, which confirms the effect of adaptive regularization. In addition to the smoothness, the prediction accuracy of the flow separation and reattachment is also satisfactory,especially in the small slope case (α= 1.5), proving the generalization capacity.
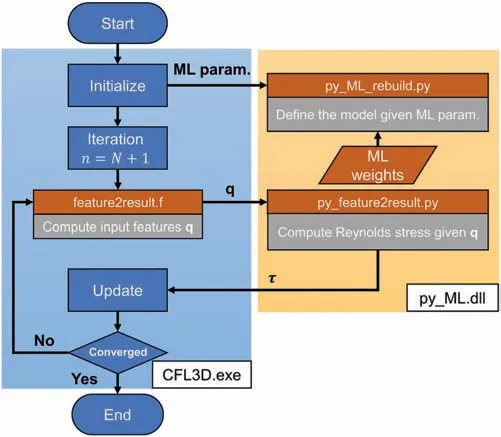
Fig. 13. Iterative computation platform flow chart.
4. Discussion
The main framework, key methods, and prediction performance are illustrated in the two sections above. Two more issues are discussed in this section. The first concerns the remaining Reynolds stress. Although the discrepancy between the representation stress and the true value stress is small, it still exists. Can the prediction result be further improved if the remaining part is also included in the targets? The second concerns the ML model calling frequency. Because the data are transferred between two different programs, the efficiency still needs further improvement. What if the ML model is not executed in each iteration step, but instead executed after an interval of several steps? The effects are evaluated below.
4.1. Effect of the remaining part after the Reynolds stress representation


Fig. 14. Reynolds stress comparison of testing sets. a α = 0.5 (extrapolation) prediction. b corresponding theoretical value. c α = 1.0 (interpolation) prediction. d corresponding theoretical value. e α = 1.5 (extrapolation) prediction. f corresponding theoretical value.
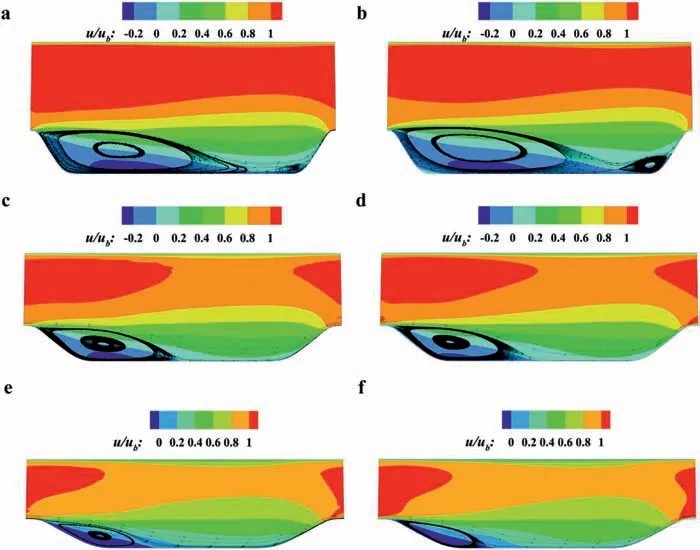
Fig. 15. Velocity contour comparison of testing sets. a α = 0.5 (extrapolation) prediction. b α = 0.5 DNS true value. c α = 1.0 (interpolation) prediction. d α = 1.0 DNS true value. e α = 1.5 (extrapolation) prediction. f α = 1.5 DNS true value.
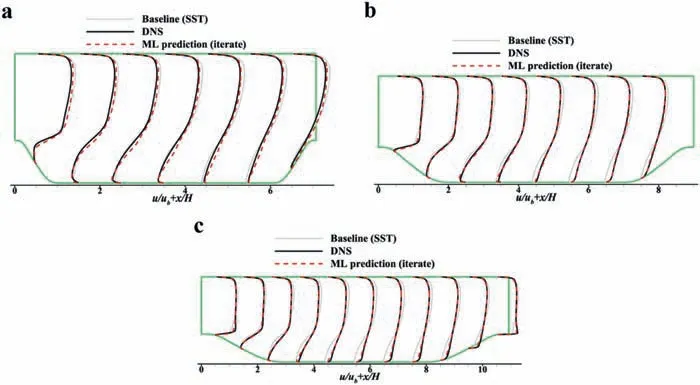
Fig. 16. Velocity profile comparison of both the training and testing sets. a α = 0.5 (extrapolation). b α = 1.0 (interpolation). c α = 1.5 (extrapolation).


4.2. Effect of the ML model calling frequency
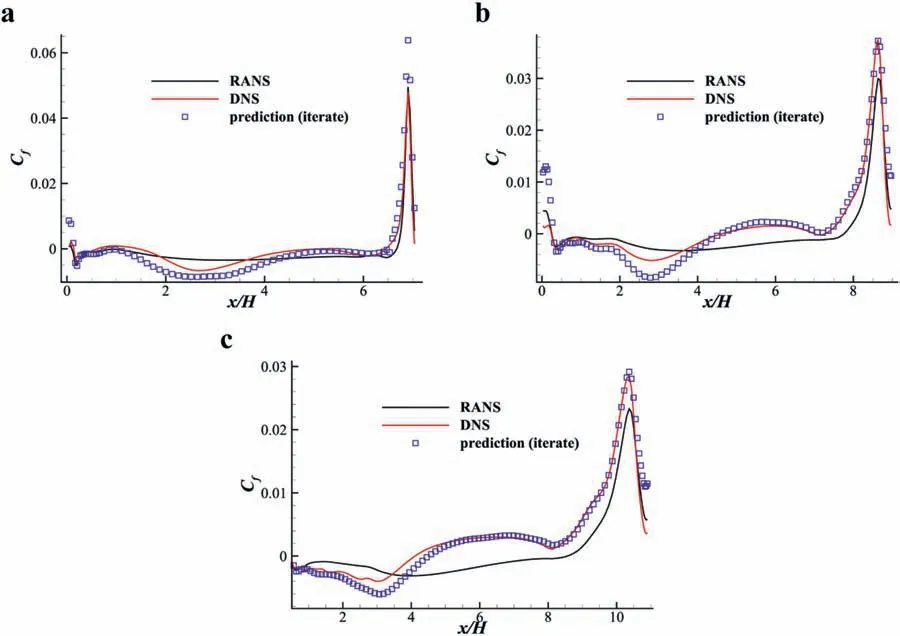
Fig. 17. Lower surface friction coefficient comparison of both the training and testing sets. a α = 0.5 (extrapolation). b α = 1.0 (interpolation). c α = 1.5 (extrapolation).
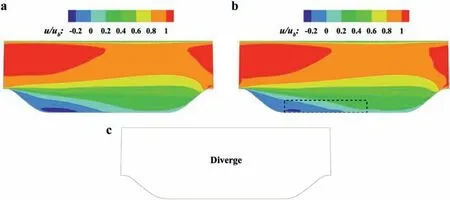
Fig. 18. Velocity contour comparison of different treatments. a Not considering τb. b Considering only the eigenvalues. c Considering the eigenvalues and eigenvectors.

Table 2 Time cost comparison.
As described in Figs. 3 and 13, the original iterative flow chart needs to call the ML model and update the Reynolds stress in each iteration step. This will increase the time cost significantly compared with the baseline RANS computation. Still taking theα= 1.0 case as an example, the grid number of the case is 77 in the normal direction and 89 in the streamwise direction, for a total 6853 of points. The time costs of the direct SST computation and the iterative coupling calculation are listed in Table 2. It can be observed that the iteration cost increases considerably, but the time cost relative to unsteady simulations such as LES or DNS is still acceptable.
A natural idea is to execute the ML model after an interval of several steps. To verify the effect, we modify the program and test four intervals: executing the ML model every 1, 3, 5, and 10 steps.The time costs are also listed in Table 2. The results show that the computation will diverge if the interval is too large. The ratio of total time cost between different intervals is essentially the same as the ratio of the interval steps, which indicates that the data transfer and Python computation occupy the main proportion of the time cost. The 3 converged mean flow results are generally the same, but the per 5 step case shows vibration near the periodic hill top, as shown in Fig. 19.
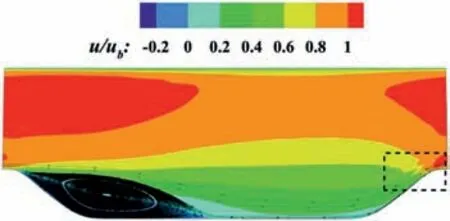
Fig. 19. Mean flow velocity of the “Executed every 5 steps” case.
In summary, executing the ML model after an interval can accelerate the computation. However, the smoothness and the convergence will be affected if the interval step is too large.
5. Conclusion
An iterative data-driven turbulence modeling framework based on Reynolds stress representation is established in the current research. Reynolds stress representation analysis is proposed, including extending the relevant tensor arguments and deducing the complete irreducible tensor invariants and integrity basis. Then,the four steps of the model construction are illustrated. The truth compatibility principle of the training data is proposed. A novel framework separating the Reynolds stress representation and ML is proposed. After the framework construction, the calculation process of the representation coefficient is discussed in detail. The direct solution of the representation coefficient is proven to produce nonphysical and unsmooth distributions, and the adaptive regularization method proposed in the current research can establish a better tradeoff between smoothness and accuracy. The model performance is evaluated in periodic hill cases, and the results indicate that the iterative framework proposed in the current research has better dynamic convergence characteristics and better solution smoothness and accuracy. Finally, the effects of the remaining part after the Reynolds stress representation and the ML model calling frequency are evaluated.
Data availability statements
The data that support the findings of this study (the dataset of flows over periodic hills of parameterized geometries) are available within the article [45].
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (91852108, 11872230 and 92152301).
Appendix: The invariants and symmetric integrity basis of arbitrary numbers of Ai, Wp, and vm
We suppose that a symmetric tensorHis an isotropic tensor function of a set of tensor arguments(Ai,Wp,vm),i=1,2,···,L, p=1,2,···,M, m=1,2,···,N.The complete and irreducible invariants and integrity basis are listed here.

As a verification, if we take (S,Ω) as the arguments, the invariants and integrity basis acquired from Eqs. (A3) and (A4) are {S2},{Ω2} and {I, S, SΩ-ΩS}, which is the same as Pope’s conclusion in a two-dimensional situation [35].
杂志排行

Theoretical & Applied Mechanics Letters的其它文章
- A machine learning based solver for pressure Poisson equations
- Optimization for vibro-impact nonlinear energy sink under random excitation
- Performance improvement of the stochastic-resonance-based tri-stable energy harvester under random rotational vibration
- Simulation and experimental analysis of melt pool evolution in laser engineered net shaping
- Clamping force of a multilayered cylindrical clamper with internal friction
- Hydrothermal analysis of hybrid nanofluid flow on a vertical plate by considering slip condition