自然语言问答系统研究进展分析*
——以中国知网2000-2020年收录论文为样本
2022-03-03郭辉,王琲,刘飞
郭 辉,王 琲,刘 飞
(1.新疆医科大学第五附属医院,新疆 乌鲁木齐 830011;2.新疆维吾尔自治区人民医院,新疆 乌鲁木齐 830001;3.新疆医科大学图书馆,新疆 乌鲁木齐 830017)
1 引言
自然语言问答系统是一种使用自然语言提问和回答的搜索引擎,其特点是可以利用对问题的语义分析提供给用户精确简洁的问题答案。自然语言问答系统是通过人机对话,采用自然语言问答的方式获取信息的系统,可用于知识工程、信息检索、专家系统等领域[1]2-4。本文对我国自然语言问答系统的文献进行调研与分析,文献调研的数据来源为中国知网(CNKI),选取的文献时间范围设定在2000年至2020年,采用文献计量的方法得出文献计量分析结果,包括学科领域分布、文献的年度分布、机构分布、高频关键词及基于关键词共现的热点主题,以便了解和掌握我国自然语言问答系统领域的研究现状,为未来的研究提供一定的理论参考。
2 数据来源及统计分析
2.1 数据来源
利用CNKI 数据库检索自然语言问答系统研究文献。首先将“问答系统”选为主题词,考虑到“问答技术”“知识问答”“智能问答”也是自然语言处理的一个方向,因此再将“问答技术”“知识问答”“智能问答”也选为主题词。最终构建出如下检索式:
主题=(“问答系统”OR“问答技术”OR“知识问答”OR“智能问答”)。
利用上述检索式在CNKI数据库中进行检索,检索时间为2000 年1 月至2020 年12 月。去除与自然语言问答系统无关的文献,共得到8 353篇相关文献。这些文献的来源有学术期刊、博士学位论文、硕士学位论文、会议论文、报纸全文等多种形式。其中:期刊论文(4 751篇,占56.87%)、学位论文(937篇,占11.65%)。
2.2 学科分布
从学科分布来看,如表1所示,轻工业、医学、行政、自动化、数字图书馆、电力、园艺和建筑等是自然语言问答系统研究的主要领域。其中计算机软件学科的研究文献最多,通过分析文献内容可知,该领域主要关注于自然语言问答系统的开发和改进研究。

表1 自然语言问答系统发文量学科分布
2.3 文献的年度分布
文献发表的年度分布情况如图1 所示,从2000 年开始,自然语言问答系统研究的文献数量处于波动上升的趋势,2008年至2013年发文量减少,2013 年至2020 年又持续上升。总体来看,近20年自然语言问答系统的研究文献数量呈上升趋势,其年度分布也较为均衡。
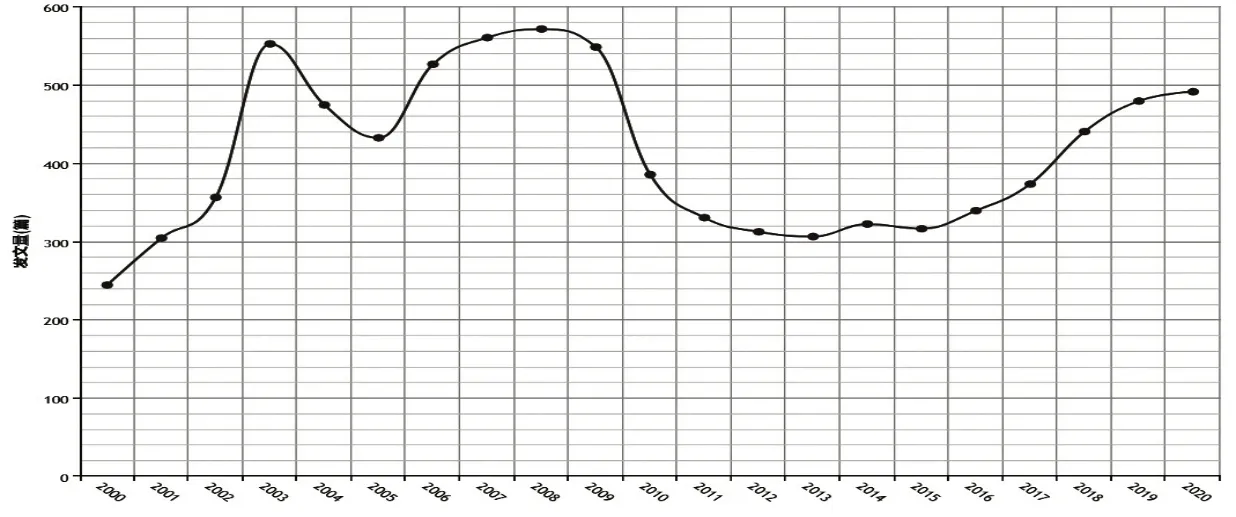
图1 近20年自然语言问答系统发文量
2.4 文献的机构分布
自然语言问答系统的研究机构共有34 个。其中,发文量15 篇及以上的机构如表2 所示。发文量排名前三位机构分别是:哈尔滨工业大学(165篇)、北京邮电大学(96篇)、电子科技大学(57篇)。说明这三所机构在整个自然语言问答系统研究领域中占据重要地位。
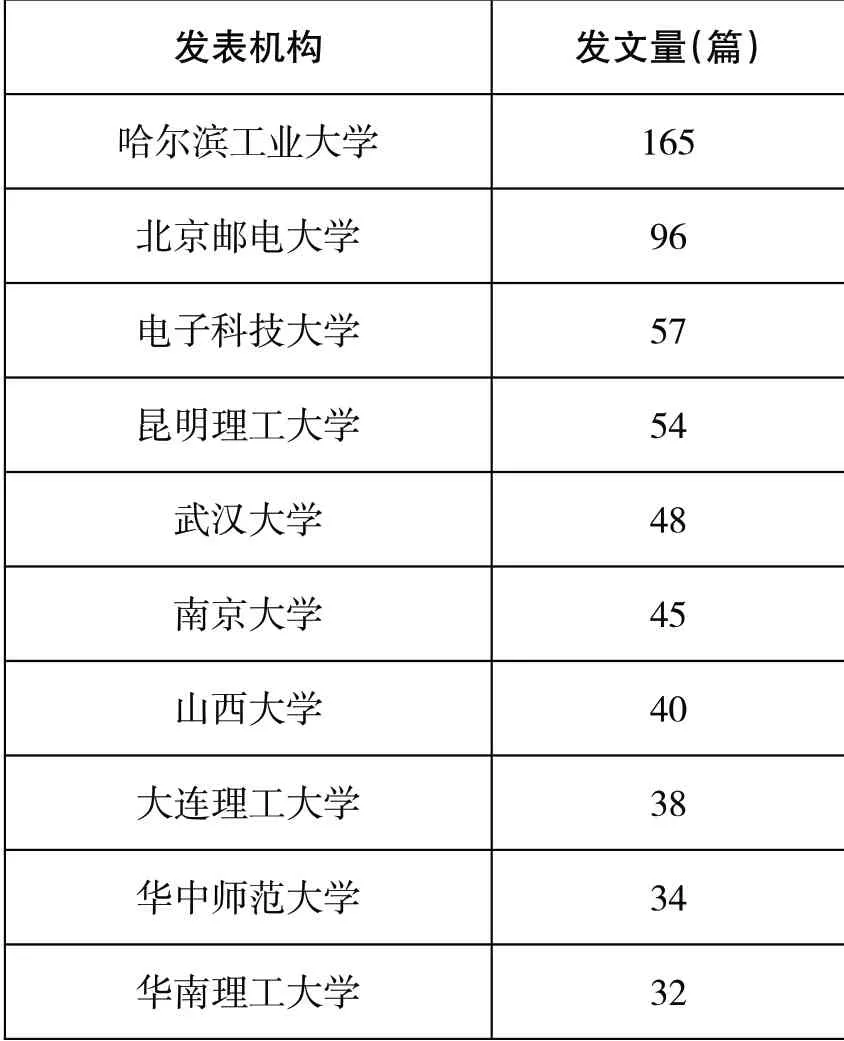
表2 自然语言问答系统研究文献机构分布
3 自然语言问答系统的研究主题分析
3.1 关键词整合
关键词是由作者主观赋予文献的词组,以反映文献的核心内容,是文献的核心所在。因不同的文献作者对于关键词的使用不统一,在对关键词进行分析之前,有必要对关键词进行如下规范化处理。
(1)同义词合并:将表示同义的词汇合并为一个规范的词汇。如将“关键词提取”和“关键词抽取”合并为“关键词提取”。
(2)上下位类合并:将下位类合并到上位类,将一些比较零散的特指概念合并到上位类,如将“姓名识别”和“命名实体识别”统一合并为“命名实体识别”。
(3)基本概念剔除:鉴于自然语言、问答系统,问答技术等基本概念无法反映自然语言问答系统的研究热点及趋势,本文将这些概念进行剔除。否则因其频次过高,与其他概念的共现程度过高,会导致结果的分析和判断出现偏差。
(4)属性描述整合:当关键词归属于某一概念时,将该属性关键词合并到该概念。如将“问答对质量”合并到“问答对”。
3.2 关键词词频分析
通过以上关键词筛选、整合之后,得到如表3所示的关键词词频结果。
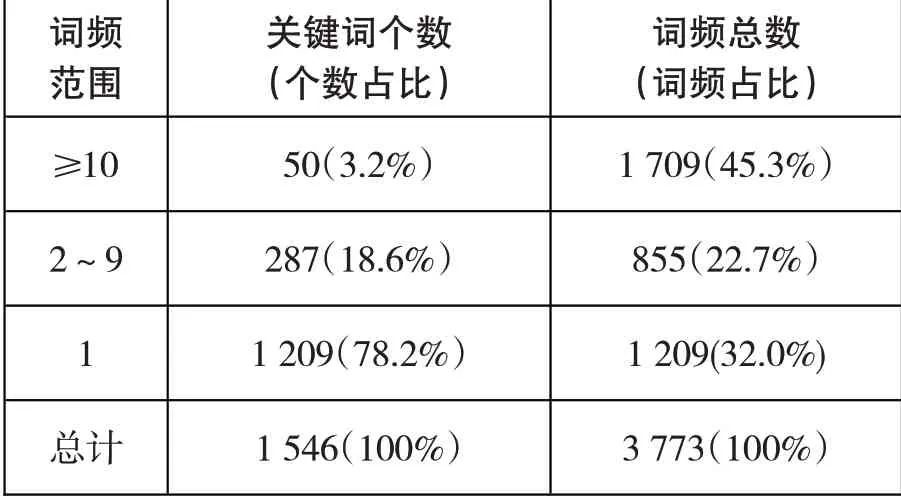
表3 自然语言问答系统研究文献关键词词频统计
对于高频词的截取,目前尚无统一见解。如果选取关键词范围太小,则不能反映学科构成情况;如果选取范围太大,则会给共词分析带来不必要的干扰。目前,高频关键词的截取使用最多的方法是结合研究者的经验在选词个数和词频高度上平衡[2],如马费成等人选取了累计词频达62%的前69 个关键词来表征我国数字信息资源领域的研究热点[3],邱均平等人利用集中分散的“二八定律”,选取累计词频25.2%的前77个关键词来表征我国图书馆学近十年的研究热点[4],李武和董伟则选取了频次不小于5的46个关键词来代表我国开放存取研究的主题[5]。本研究延用此方法,选取词频在20 及以上的47 个高频关键词进行研究热点分析,这些关键词基本上体现了自然语言问答系统领域的核心研究主题,如表4所示。
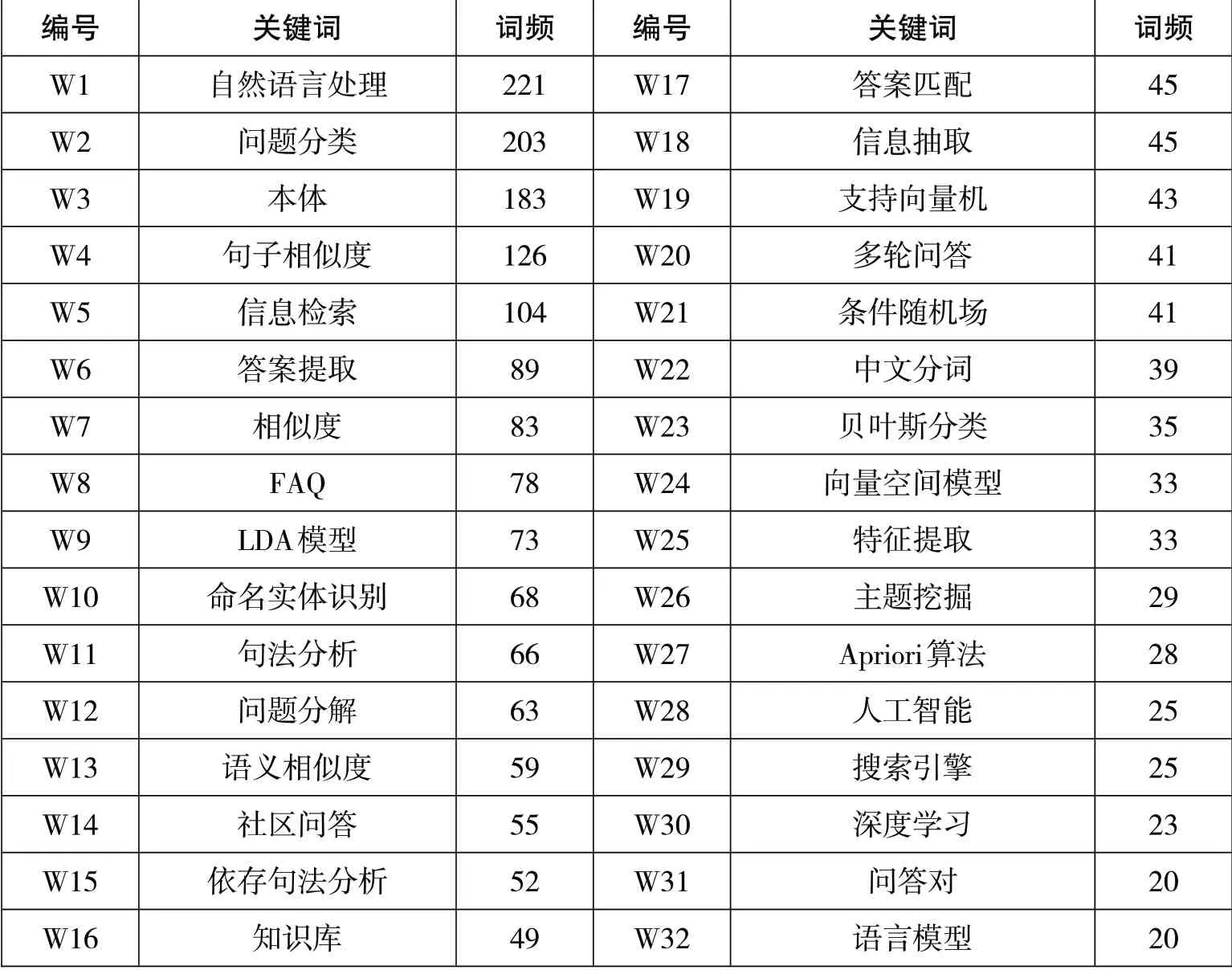
表4 自然语言问答系统研究文献的高频关键词统计(部分)
3.3 共词分析
如果两个词在众多文献中共现的频次越高,则说明它们之间的关系越密切。揭示高频关键词之间的关系,则需要统计分析它们在同一篇文献中共现的次数及规律,即为共词分析[6]。通过对文献中这种词对共现的量化分析,能够初步揭示研究主题之间的关联,进一步发现学科热点。因此,可考虑通过构建这些高频关键词的共现矩阵来找出自然语言问答系统研究领域的核心词汇,通过对这些词汇进行理解和表征,能够更清晰地理解该研究领域研究热点之间的关系。上文中表4 所统计出来的47个高频关键词基本上涵盖了自然语言问答系统研究的主要方向,能够基本反映出该领域的研究热点。对这47个高频词的共现次数进行统计,构建出高频关键词共现矩阵,表5所示为部分关键词(10个)构成的共现矩阵。

表5 自然语言问答系统研究文献关键词共现矩阵(部分)
由于表5 中共现矩阵中的关键词两两共现词频是绝对词频,无法客观反映出关键词之间的依赖程度。本研究对词频进行包容化处理,将绝对词频转化为相对词频,以明确关键词之间的紧密联系程度。在目前研究中,包容化处理的方法主要有包容指数法、临近指数法、相互包容系数法等[1]10-16。目前使用较广泛的是Ochiia 系数法,公式为:

其中,Cij表示词i与词j在文献集合中的共现次数,Ci表示词i的出现次数,Cj表示词j的出现次数,Oij是经包容化处理后的相对共现频率。经包容化处理后,使用绝对词频的共现矩阵转换为使用相对词频的相关矩阵,如表6所示。在相关矩阵中,数值大小反映关键词间的相关程度,数值越大,相关性越强。
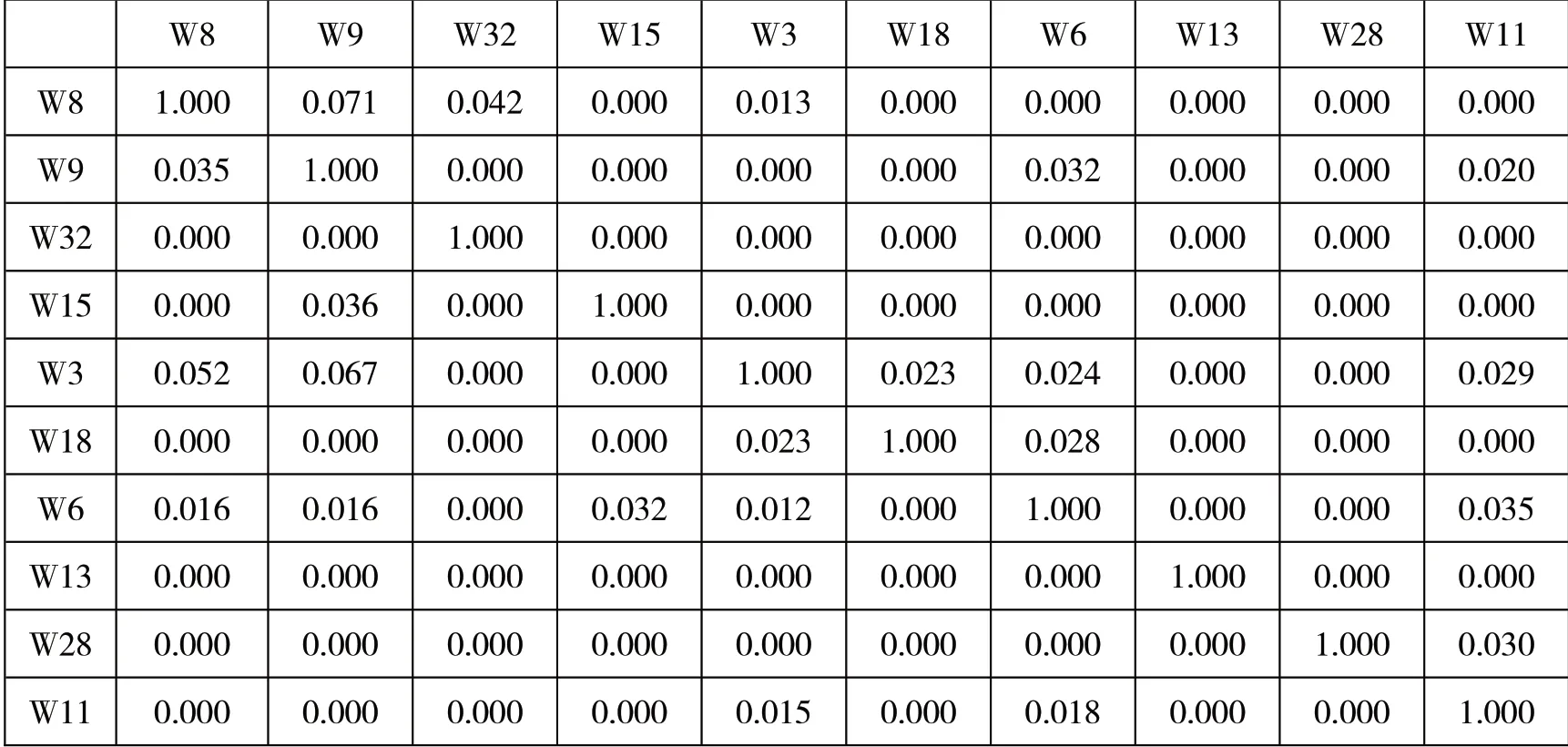
表6 自然语言问答系统研究文献关键词相关矩阵(部分)
由于相关矩阵中的0值过多,统计时容易造成误差过大,为了方便进一步处理,用1与相关矩阵中的全部数据进行相减(相异矩阵=1-相似矩阵),得到表示两词间相依程度的相异矩阵,如表7所示。相异矩阵中的数据表示不相似数据,数值越大表明关键词之间的关系越远,相关度越差;反之,数值越小表明关键词之间的关系越近,相关度越高。
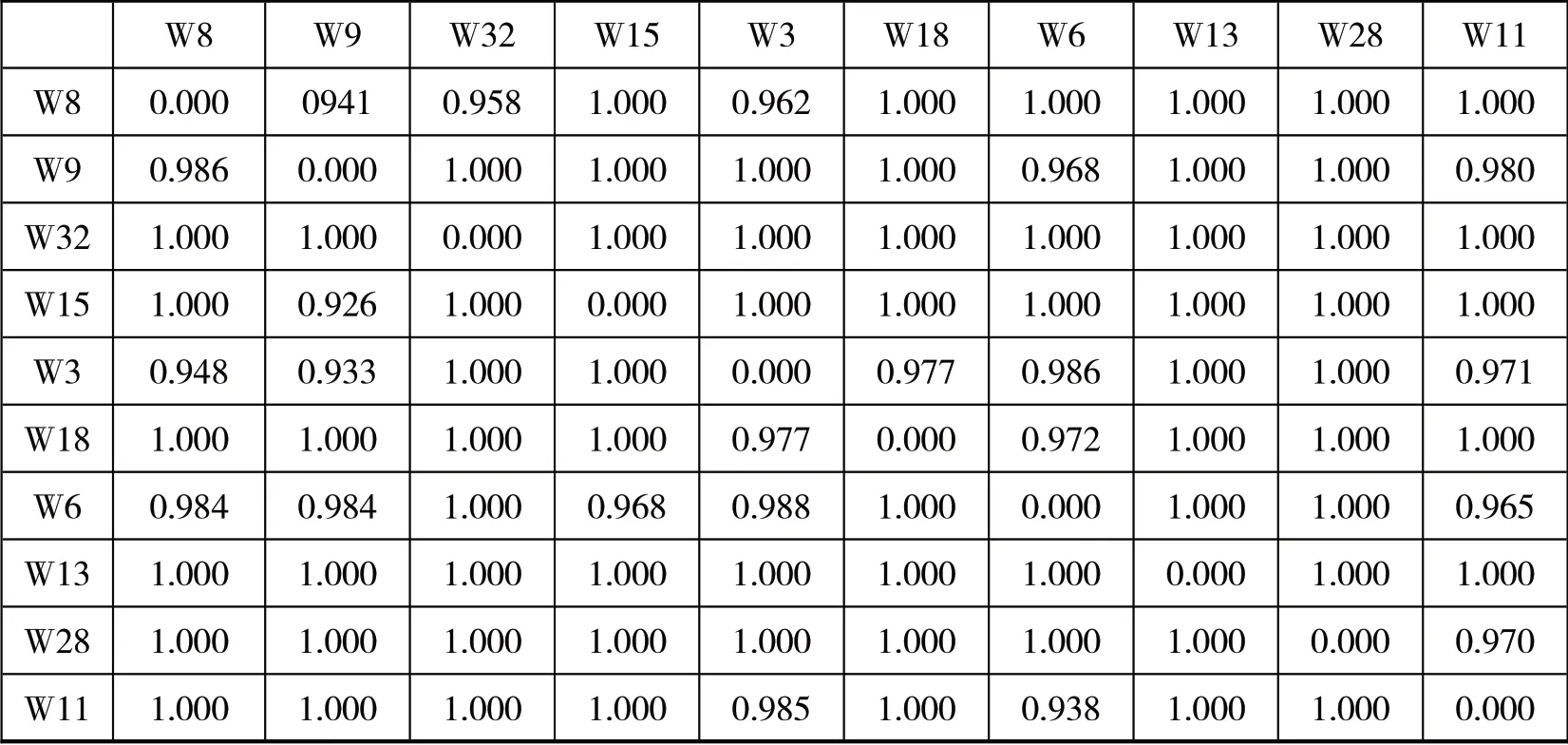
表7 自然语言问答系统领域关键词相异矩阵(部分)
共词聚类分析是共词分析中常用的一种方法,在共词分析的基础上,以词的共现频率为研究对象,利用聚类方法,把众多分析对象之间复杂的共词网状关系简化成书目相对较少的类团之间的关系[7]。通过聚类分析,能够发现关系紧密的关键词构成的相对独立的类团,这些类团能够反映学科领域的研究主题。
层次聚类是聚类分析中的经典方法。本文采用SPSS 统计软件,利用高频关键词共现的相异矩阵进行自下而上的层次化聚类分析,在SPSS 中选择离差平方和聚类方法(Ward 法),距离测度选择区间数据类型(count)中的Euclidean 方法。聚类后得到5大类,如表8所示。

表8 自然语言问答系统研究文献关键词聚类结果
经过聚类分析,目前自然语言问答系统的研究主题主要有问题分类、答案抽取、信息检索、推理、机器学习等五大类。其中,问题分类主要涉及句法分析技术、命名实体识别、句子的语义分析以及分类方法,如支持向量机、隐马尔科夫模型等;答案抽取主要涉及文本分析的技术,如句子相似度、指代消解、特征提取等;信息检索主要涉及检索的方式和支持有效检索的技术,如文本检索、语义角色标注和语义相似度等;推理主要与知识库、推理方式等关键词共现,如与知识库相关的关键词有“语料库”“知识库”“本体”,与推理方式相关的关键词有“基于规则的推理”;机器学习类别主要涉及机器学习的技术,如贝叶斯、条件随机场等。
4 自然语言问答系统主要应用领域分析
通过对CNKI 数据库中2000—2020 年自然语言问答系统领域中的硕博论文整理分析,开发应用的重要文献主要集中于以下八大领域。
(1)电子商务领域。自然语言问答系统在该领域中的应用主要有:在问句理解方面,中文领域基于模板自动生成的语义解析方法[8];在知识库构建方面,知识表示模型的改进以及知识自动融合和补全的方法;在商品咨询方面,将中文自然语言查询转换为基于SPARQL 查询的方法[9]。这些问答系统的改进方法应用在电子商务领域可提高了商品的查准率和查全率。
(2)财经领域。自然语言问答系统在财经领域的应用有:以维基百科为知识来源构建金融领域的自动问答系统[10],识别财经领域中的股票名称、股票代码等命名实体的问答系统[11],以问句后续解析为主的查询子系统[12]、问句解析子系统[13],面向金融领域的网友问答子系统和自动问答子系统[14]以及企业问答系统[15]。
(3)医疗领域。自然语言问答系统在医疗领域中的应用有基于多次推断的自动化医疗疾病诊断系统[16]、中草药问答系统[17]、基于中草药语义网的自动问答系统[18]、基于垂直领域问答的医疗健康领域问答系统[19]、孕妇保健智能语音手机问答系统[20]以及基于疾病知识图谱的问答系统[21]。
(4)旅游领域。自然语言问答系统在旅游业领域的应用有:维护用户多次输入文本的上下相关性的问答系统[22],由模式匹配、句子相似度计算、旅游景点推荐、信息检索和答案获取等模块组成的面向中文旅游领域的问答系统[23],基于本体知识库模型,并采用SPARQL 查询语言和Jena包来完成对知识的推理和答案的抽取的问答系统[24]。
(5)教育领域。自然语言问答系统在教育领域的应用有:构建以某一门课程为知识库或本体的问答系统,如基于互联网资源的本体自动构建技术,实现了《C程序设计》课程本体的自动构建并应用于答疑系统[25];以《计算机操作系统》学科的领域知识库为基础设计自动问答系统[26];高考地理在线解答系统[27];自动解答高中地理因果推理类试题问题的系统[28];基于中国历史人物(基于Android 平台)的自动问答系统[29];基于《论语》的问答系统[30];入学咨询的中文问答系统[31];面向国家科技计划项目申报信息咨询的自动问答原型系统[32];基于《数据库系统原理》课程知识库的中文问答系统[33];虚拟学术社区[34]。
(6)人工智能领域。问答系统在人工智能领域的应用有人机情感交互行为一致性协同控制模型[35]、面向智能家居的交互系统[36]、基于大学计算机系教师信息的问答系统[37]、采筑智能问答平台[38]以及视觉问答系统。
(7)社区问答领域。自然语言问答系统在社区问答系统领域的应用主要有基于社区问答系统(CQA)的答案摘要系统[39]、社区问答检索系统[40]、基于全信息的社区问答原型系统[41]。
(8)其他领域。自然语言问答系统还应用在图书馆领域[42]、农业领域[43]、数字人文领域[44]等。
5 结论与展望
自然语言问答系统是一种基于自然语言处理的应用系统。该系统包括自然语言处理及信息检索和答案抽取等方面的基本技术,如词法分析、句法分析、文本检索、语义解析、答案抽取等。目前,问题回答系统的研究已经成为一个热点,它是信息检索和自然语言处理的交叉研究方向。本文通过对现有自然语言问答系统的研究现状进行梳理,通过分析该领域的研究热点,为新的研究角度提供方向上的理论支持。本文通过文献计量的方法对我国自然语言问答系统研究的学科领域分布、文献的年度分布、机构分布、高频关键词及基于关键词共现的热点主题进行了分析。
从学术方面看,分析结果表明计算机软件及其应用学科是自然语言问答系统的主要所属学科,哈尔滨工业大学是该领域研究的领军机构,自然语言问答系统的研究主题包括问题分类、答案抽取、信息检索、推理以及机器学习等五大类。研究的核心主要是语言以及文本,语义、句法等研究的基础仍然要依赖于语法、语义的研究。自然语言处理涉及计算机科学、人工智能以及语言学等多种学科,学科之间的交叉融合对于自然语言处理的发展起到良好的促进作用。同时,自然语言处理的发展也促进了其他学科的发展,推动部分传统学科与自然语言相结合,促进其他学科的不断创新发展。提升计算机处理语言的能力,已经成为人们未来研究的焦点。
从目前的应用角度看,自然语言问答系统已经应用到诸多领域,其应用领域主要有电子商务、财经、医疗、旅游、教育、人工智能、社区问答以及其他领域。自然语言处理的广泛应用的核心在于准确地理解语言文本,而理解文本的难点不仅仅需要语法逻辑的正确,更重要的还需要依赖于丰富的知识库,两者同时具备才能够准确地对文本进行理解和分析。随着技术的发展,各行各业对自然语言处理的需要逐渐增加并且对其准确性要求也更高,如在一些银行或医学等领域对自然语言处理的需要和要求都很高。其专业化服务是趋势也是挑战,行业的不同,依赖的专业库也不同,而专业库的构建工作是一项耗时耗力的工作,也是目前其发展的一个重点难点。未来可以考虑借助一些现有的显性结构化知识,来理解知识库设计到的语言成分之间的关系,逐渐走向自动化构建知识库,减轻人工的工作量。
通过以上分析可发现,虽然目前自然语言问答系统领域已有大量研究,无论是学术界还是产业界,提高计算机语言处理的准确性等能力一直是大家关注的焦点。但自然语言问答系统在中文处理方面的精确率上的处理技术研究还不够成熟,如分词、实体识别、外来语识别和一词多义等,导致大部分问答系统的准确率还比较低,对文本的深层语义理解还不够准确,无法真正地理解自然语言问题。因此,未来的研究可以是自然语言处理技术,从而推动自然语言问答系统在中文处理研究的进一步发展。可借鉴Google推出的一种深入探索自然语言理解的测试机平台,即首先让计算机对某个文章进行理解,再由人们对计算机进行提问测试其理解能力和准确性能。
