基于恒虚警率的深度神经网络Dropout 正则化方法
2022-03-03肖家麟袁晴龙唐志祺
肖家麟, 李 钰, 袁晴龙, 唐志祺
(华东理工大学信息科学与工程学院,上海 200237)
深度神经网络具有强大的特征提取能力,在机器学习领域表现优异[1]。将该类算法部署于嵌入式设备上,从而实现工业现场的物体识别,已经成为众多工业智能装备、机器人系统的迫切需求。深度神经网络模型拥有大量的可训练参数,并且通过增加网络层数和卷积核数量可以进一步提升其性能[2]。然而,随着层数和卷积核数量的增加,模型变得更加复杂。而嵌入式系统的硬件计算资源有限,会造成性能与资源之间的矛盾,主要表现在两个方面:一方面,大量参数的学习受限于训练数据的规模,过参数化会导致模型冗余的问题。例如,VGG16 模型的参数量可达到552 MB[3];另一方面,当训练数据不足时会出现过拟合现象,导致模型泛化能力变差。因此,减小过参数化和过拟合问题的影响是深度神经网络嵌入式应用研究的重点。随着嵌入式硬件的性能提升和机器学习新算法的不断提出,对实时嵌入式物体识别算法网络结构正则化方法的研究也在不断深入。
在正则化方法中,Dropout 是非常有效的技术,能够有效防止过拟合[1]。该方法在每轮迭代中,将网络中的神经元以一定的概率丢弃,训练完成后,整体的网络架构还会被使用。文献[1]建议输入层的丢弃概率为0.2,隐藏层的丢弃概率为0.5,输出层则不需要Dropout。由于在相同层中节点被删除的概率相等,减少了神经元之间复杂的共适应关系,因此,每次神经元的合作运算都是全新的,不会依赖于某个神经元或某种结构,在训练中不会只依赖数据的某个特征。Salehinejad 等[4]提出了一种自适应技术,降低了由于数据集不平衡和模型参数初始化过于接近训练数据所造成的不利影响。Chen 等[5]提出了DropCluster,在卷积层输出中寻找相关特征的模型权重。Qi 等[6]提出使用基于变分推理的Dropout 正则化将变分递归神经网络(RNN)推广到更高级的聚类,并在每次迭代时随机删除聚类;然后在模型训练过程中对聚类进行学习和更新,使它们适应数据和RNN 架构,如门控递归单元(GRU)。Luo 等[7]提出了一种基于Dropout 正则化的多尺度融合(MSF)Dropout 方法,首先训练几组具有不同Dropout 率组合的网络模型,然后使用改进的遗传算法来计算每个网络模型的最优规模。Tam 等[8]提出使用神经网络的Fiedler 值作为一个工具进行正则化。Tseng 等[9]提出了Gradient Dropout 方法,在深度神经网络参数的内环优化中随机降低梯度,从而降低基于梯度的元学习的过拟合风险。Steverson 等[10]开发了一个测试框架来评估机器学习网络防御的对抗性鲁棒性,使用了深度强化学习和对抗性自然语言处理的技术,实验结果发现更高概率的Dropout 会提高鲁棒性。Cai 等[11]提出在卷积操作之前Dropout 会有更好的正则化效果。胡辉等[12]提出了一种将Dropblock算法和Dropout 算法相结合的正则化策略,实现对整个卷积分类网络的浅层、中层和深层网络进行正则化。这种方法可有效加快分类网络的收敛速度和提升稳定性,还能有效提高深度卷积分类网络的分类准确率。钟忺等[13]提出了多尺度融合Dropout(MSF Dropout)方法,这种方法利用验证数据集对多个不同尺度的网络模型进行训练,通过学习得到符合该数据集特征的最佳尺度组合。MSF Dropout 具备自适应数据集的能力,网络能够使用最佳尺度来进行高精确度的预测。当选择了合适的尺度数量和尺度梯度后,这种方法的预测精度获得了明显的提升,还能很好地控制计算时间。刘磊[14]提出了一种统一的Dropout 算法框架,将基于不同分布采样的Dropout 方法统一到一个基于β分布的Dropout 框架中,进而将Dropout 方法选择问题转变为一个参数调节问题。这种方法被应用在视网膜病变的检测场景下,验证了鲁棒性和先进性。
为了增强模型泛化能力,Wan 等[15]提出将每个神经元的权重或偏置以一定的概率设置为0,而不是将神经元的输出设置为0。为简化网络结构,Molchanov 等[16]提出变分Dropout 正则化方法,基本思想是同时对全连接层和卷积层进行稀疏化,该方法对性能的影响很小,大大减少了标准卷积网络的参数。Srivastava 等[17]提出了一种基于贝叶斯理论的方法,将Dropout 解释为深度高斯过程的贝叶斯近似,总结出了一种估计神经网络输出置信度的简单方法,此方法广泛应用在不确定性估计中。Provilkov等[18]提出对BPE 算法进行Dropout 正则化(BPEDropout),使性能获得了很大的提升。
深度神经网络的参数众多,其中有些参数对最终的输出结果贡献不大,这些参数称为冗余参数。为此,一些学者提出了利用剪枝或量化来简化网络结构的方法。文献[19]提出对卷积层进行完全的剪枝,但是对卷积输出层进行剪枝时,也会对网络层造成影响。Courbariaux 等[20]提出了二值化神经网络(BNN),将参数进行量化,这种方法既快速又节能,但由于参数的精度下降,一定程度上会降低识别的正确率。
以上防止过参数化和过拟合的研究为提高深度神经网络的性能提供了很好的思路,然而对自适应剪枝和针对特定嵌入式平台的研究还值得进一步深入。受恒虚警检测方法启发,本文提出了一种基于恒虚警率检测的Dropout 方法(CFAR-Dropout)。其主要思想是通过设计一个恒虚警检测器,计算每个节点的激活值,利用恒虚警思想自适应地调整阈值,从而决定哪些节点需要Dropout。该方法在防止过拟合的同时,其本质上是在Dropout 时对不同样本进行了区分,使系统对样本的局部结构特征更加敏感,能趋向于保留对特征更感兴趣的节点。
1 网络模型与正则化方法
1.1 网络模型
模型和计算平台的契合程度决定了模型的实际表现。本文使用的平台是嵌入式平台PYNQ-Z2,考虑这个平台的运算能力,创建了一种基于VGG16(Visual Geometry Group Network-16)的变种卷积网络模型。VGG16 模型[3]包含13 层卷积层、5 层池化层、3 层全连接层。卷积层和全连接层都有权重系数,被称为权重层,共16 个权重层(卷积-卷积-池化-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接);池化层则不涉及权重。该模型中13 层卷积层和5 层池化层负责进行特征的提取,最后3 层全连接层负责完成分类任务,其网络结构参数如表1 所示。这种模型的优点是结构简单、权重参数较少,能在一定程度上防止过拟合,但存在需要训练的特征数量大、训练时间过长和调参难度大等问题。由于需要的特征存储容量大,不利于直接部署在嵌入式系统中。因此,需要对参数进行量化操作,减少运算量。

表1 网络结构参数表Table 1 Network structure
1.2 Dropout 正则化方法
Dropout 作为消除冗余的重要方法,自从提出就得到了广泛的应用,其工作原理如图1 所示。图1(a)示出了原神经网络的节点连接状态,图1(b)示出了Dropout 正则化后的节点连接状态,图中虚线圆是被丢弃的节点,虚线箭头是节省的运算通路,可以直观地感受到通过Dropout 正则化,运算量将大大减少。

图1 Dropout 正则化前后对比Fig. 1 Comparison before and after Dropout
经过Dropout 正则化产生的局部网络本身属于原网络的一部分,虽然总的网络个数增加了,但参数却比原网络更少,能有效防止模型过拟合问题。因此,在保持训练复杂度的情况下可以同时得到多个网络的训练结果,当测试时再将这些局部网络组合起来,可以提升网络的泛化性。另一方面,神经网络的节点之间相互影响,很容易拟合到一些噪声,可能产生过拟合现象。Dropout 正则化随机选择节点删除,打破了这种相互影响,能有效防止模型的过拟合问题[21]。这个过程可以表示为

式中:f(x)为激活函数;x是该层的输入;W是该层的权值矩阵;y为该层的输出;m为该层的掩膜(mask),mask 中每个元素为1 的概率为p。
Wan 等[15]提出的Dropconnect 方法是对Dropout正则化的一种泛化。与式(1)不同的是,式(2)中的M是一个掩模矩阵,相乘后权重以一定的概率被设置为0 和1。Dropconnect 正则化方法在训练时网络层的输出可以被写成

1.3 参数的优化方法
深度神经网络训练期间更新生成的参数包含大量冗余信息。对参数的量化主要包括神经网络层的3 个方面:输入激活、突触权重和输出激活。如果3 个部分都是二进制的,称之为完全二值化;具有一个或两个部分是二进制的情况称为部分二值化[2]。本文对权重进行二值化。
深度神经网络中的目标函数F(ω) 可以分解为多个函数f1,f2,···,fn。考虑经验风险最小化,即


完成参数的二值化后,可以显著减少计算参数权重需要消耗的资源,但实验结果的准确性会有一定程度的下降。为了降低这种负面影响,可以适度地增加网络层数,这就需要在实验中进行权衡。
2 基于恒虚警率的Dropout 正则化方法
2.1 基于恒虚警率检测的Dropout 正则化方法(CFARDropout)的基本原理
恒虚警率检测是利用信号和噪声的统计特性等信息来建立最佳判决的数学理论,常用在雷达系统中。它主要解决在受噪声干扰的观测中有无信号的判决问题[22]。恒虚警检测的基本流程是在保持虚警概率(α)为恒定的条件下对接收机输出的信号和噪声进行判别,以确定目标信号是否存在。通过恒虚警检测保持恒虚警率,可以有效地抗干扰。
在雷达信号检测中,当外界干扰强度变化时,雷达能自动调整其灵敏度,使雷达的虚警概率保持不变,这种特性称为恒虚警率特性。本文受此启发提出了基于恒虚警率检测的Dropout 正则化方法。设置一个恒虚警率,将深度神经网络神经元的输入看作输入信号,将神经元的激活值看作输出信号。这种方法可以在输入数据不同和输出结果分布不均匀时自适应调整阈值,使分类效果依然良好。

那么,节点的激活值为

在Dropout 正则化方法中,M是一个服从伯努利分布取值的掩模矩阵,其取值概率设置之后是固定的[1]。在稀疏性Dropout 正则化方法中,节点以激活值的中值为阈值取舍,其阈值也是固定的[15]。此时,M中的元素值取决于节点的激活值。当节点的激活值大于阈值λ时,mij取1;激活值小于阈值β时,mij取0。每次进行恒虚警检测后,系统可以自适应地调整λ值,λ值在每一层都可能不同。
在实验中,神经网络训练需要设置权重初始值,选取的初始值应当尽量使各层激活值的分布有适当的广度。分别使用标准差为1 和0.01 的高斯分布作为权重初始值时,各层激活值的分布如图2 所示。

图2 权重初始值是标准差为1(a)和0.01(b)的高斯分布时激活值的分布Fig. 2 Initial weight value is the distribution with the activation value with Gaussian distribution of standard deviations 1(a) and 0.01(b)
图2(a)显示标准差为1 时,各层激活值呈偏向0 和1 的分布。偏向0 和1 的数据分布会造成反向传播中梯度的值不断变小,最后消失,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习,这种现象称为梯度消失。图2(b)显示标准差为0.01时,不同层的激活值过于集中在一个区域,这种现象意味着激活值表现的特征基本相同,很多特征被忽略,最后的识别效果会受影响。为了避免这两种现象,使每一层能根据当前状态自动调整,当前一层节点数为n时,将初始值设为标准差为√ 的高斯分布。此时激活值的分布如图3 所示。

图3 权重初始值是标准差为 1 / 的高斯分布时激活值的分布Fig. 3 Initial value of the weight is the distribution of the activation value with a Gaussian distribution of standard deviation 1/

理论上,高激活值的节点代表对样本感兴趣程度高的部分,低激活值的节点代表对样本感兴趣程度低的部分,所以低激活值节点Rjl应该删除。但在实际应用中,数据分布并不均匀,中值并不能很好地区分高低激活,所以本文提出了基于恒虚警检测的Dropout 正则化方法。
在雷达系统中,当接收机有信号输入(D0),而检测器判为无信号(H1)时,称为漏警,漏警率为PM;当接收机无信号输入(D1),而检测器判为有信号(H0)时,称为虚警,虚警率为PF。这两个概率都是越小越好,但理论上两者无法同时达到最小。在其他条件一定时,虚警概率越小,漏警概率就会越大;漏警概率越小,虚警概率就会越大。转化为统计的语言就是一个假设检验犯第一类错误和第二类错误的概率,无法同时变小。所以,可采用的方法是给定其中一个错误的概率不超过某个值时,让另一个错误的概率尽量小。本文中让虚警率恒定,使漏警率最小,从而求得阈值。虚警率PF和漏警率PM分别为

利用拉格朗日乘子λ构造目标函数

当PF=α时,漏警率可以达到最小值。此时,目标函数J对输入z求导。可得

然后,可由式(14)求出阈值λ

本文中假定激活值数据服从高斯分布,如果某个节点为高激活值节点,但判为低激活值节点,称为漏警Rhl。如果某个节点为低激活值节点,但判为高激活值节点,这种情况称为虚警Rlh。虚警率PF和漏警率PM分别为

由PF=α,可以求出R0,则λ为

经过以上步骤,得到调整后的阈值,可以将节点分为高激活值节点和低激活值节点。
文献[23]指出相关性接近0 的弱相关节点对相关性高的节点有补充作用,所以低激活节点并非全无用。若保留比例为 γ (0 ≤γ ≤1) ,则相应的高激活值节点删除的比率为1−γ。高激活值节点的掩模矩阵中的元素以伯努利概率P+取值为0 或1,低激活值节点的掩模矩阵中的元素以伯努利概率P−取值为0 或1。

按以下方式处理节点

其中:S为保留节点的比率;R+为保留的节点;R−为删除的节点。CFAR-Dropout 的原理如图4 所示。

图4 CFAR-Dropout 原理简图Fig. 4 CFAR-Dropout schematic diagram
当进入新的一层进行计算时,输入发生变化,依旧需要将虚警率保持为α,所以将α称为恒虚警率。经过实验得出α的最佳取值范围为0.030~0.120,本文取0.1。
3 实验验证
3.1 实验平台
本文实验在嵌入式平台PYNQ-Z2 上完成。PYNQ 主要芯片采用ZYNQ XC7Z020,其内部异构双核ARM-A9 CPU+FPGA,PS(ARM)和PL(FPGA)之间通过片上高速AXI 总线进行数据交互,能有效克服ARM 和FPGA 间数据传输的低速、延时、外界干扰等问题。在PYNQ 的ARM-A9 CPU 上运行的软件包括Jupyter Notebooks 网络服务器、 IPython 内核和程序包、Linux-Ubuntu 以及FPGA 的基本硬件库和API。
PC 端负责进行数据集的准备和预处理,选择合适的物体识别方案,搭建好网络结构,训练后得到参数权重。通过VIVADO HLS 创建卷积Pool 和池化Conv IP 核,设计的加速电路如图5 所示。由于神经网络中的卷积层与全连接层相似,所以全连接层可以复用卷积的IP 核。

图5 卷积和池化部分IP 核Fig. 5 Binarization error rate convolution and pooling of IP cores
嵌入式平台PYNQ-Z2 加载PC 端训练的权重参数,将加速电路的比特流文件烧写在PL 端形成加速电路。之后,系统通过相机或者以太网接口开始读取图片或者视频帧。PS 端和PL 端通过AXI 总线进行信息交互, PS 端都会调用PL 端的加速电路进行运算神经网络的每一层。运算结束后,实现物体识别。系统流程如图6 所示。
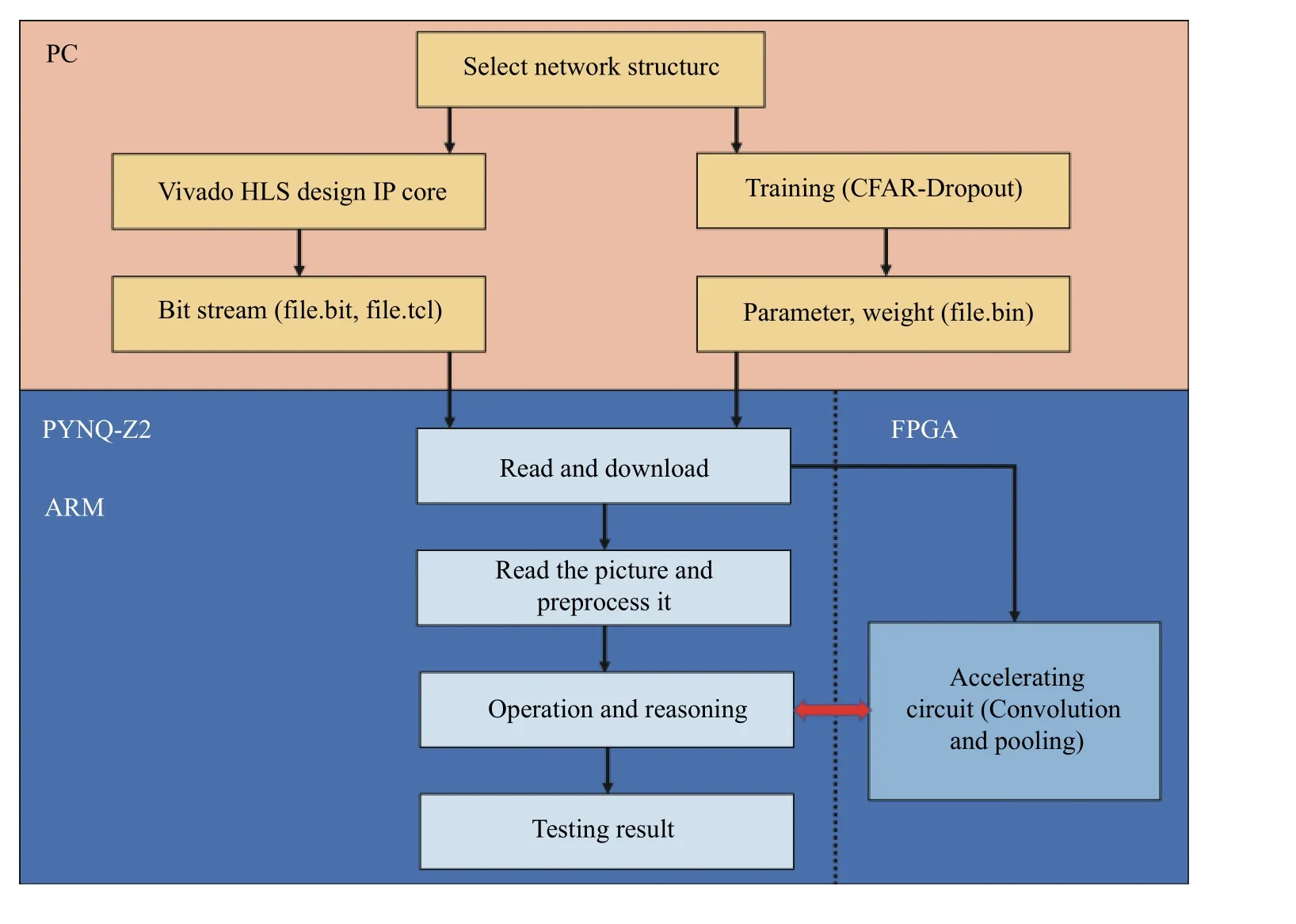
图6 物体识别系统检测步骤Fig. 6 Object recognition system detection steps
3.2 实验结果
3.2.1 基于公开数据集的实验验证 为了测试CFARDropout 正则化的效果,以Dropout 正则化方法作为比较对象,采用基于VGG16 的二值化模型。实验采用3 种公开数据集,其中数据集CIFAR-10 包含6 万张32×32 的RGB 图片,共分为10 个类别,训练数据50 000 张图片(每类5 000 张),测试数据10 000 张图片;数据集MNIST 由大小为28×28 的手写数字图片组成,包含60 000 张训练图片和10 000 张测试图片;数据集SVHN 是真实世界的街景门牌号数据集,结构与MNIST 类似,其训练集含有73 257 张图像,其测试集含有26 032 张图像。
实验中一次输入的数据量不能过大,所以将训练集分为多个批次,分批次训练完成。如果批次数量取值过小,训练数据就会非常难收敛;如果增大批次数量,相对处理速度加快,但所需内存容量增加,所以需要选择合适的批次数量,在内存效率和内存容量之间达到平衡。训练批次数量设置为200,测试集的批次数量设置为100。最终,数据集CIFAR-10和MNIST 各测试了100 批,共10000 次。数据集SVHN 测试了261 批,共26 032 次。所有测试集测试完毕,取各批次错误率的均值,得到平均错误率。
将虚警率α设置为不同大小,对3 个数据集进行多次重复实验,其折线图如图7 所示。
由图7 可知,当α为0.030~0.120 时,测试错误率较低。α取值过小,在实际中很难实现,恒虚警检测没有起到作用,最极端的情况下,虚警率取值等于0 时,相当于使用标准的Dropout 方法;α取值过大,相当于人为增加了误差,错误率也会上升。

图7 恒虚警率不同时的测试错误率Fig. 7 Test error rates with different constant false alarm rates
(1)正则化方法的过拟合性能测试。将本文的网络模型命名为A,α设置为0.1。采用不同的正则化方法,对数据集CIFAR-10 和MNIST 各测试了10 000 次;对数据集SVHN 测试了26 032 次,实验结果如表2 所示。
从表2 可以看到,当不使用正则化方法时,测试误差远远大于训练误差,产生了过拟合现象。使用Dropout 和CFAR-Dropout 方法后,测试误差接近训练误差,说明这两种方法都能有效缓解过拟合。CFAR-Dropout 在3 个数据集上都取得了最好的实验结果,但由于数据集本身不同的特征,CFAR-Dropout方法对训练CIFAR-10 数据集的误差降低最明显。与Dropout 相比,CFAR-Dropout 方法由于更敏感,进一步降低了训练和测试误差,降低程度在2%左右。

表2 不同正则化方法的错误率Table 2 Error rates of different regularization methods
(2)在PYNQ-Z2 上的实验。首先,嵌入式PYNQZ2 读取加载训练好的参数权重,将bit 流文件烧录生成加速电路;然后,使用PYNQ-Z2 的以太网接口或者摄像头读取图像,进行识别后输出结果。实验结果如表3 所示。

表3 不同的正则化方法在PYNQ 上的错误率Table 3 Error rates of different regularization methods on PYNQ
从表3 可以看到,CFAR-Dropout 方法的实测错误率比Dropout 方法更低。PYNQ 通过以太网接口直接读取图像和训练时的测试误差率差别极小,在0.5%之内,这一现象说明神经网络成功部署在嵌入式平台上,可以正常运行。使用相机拍照时,错误率略微上升。经过分析,这种现象的出现是因为受到外界光照、摄像头性能等因素的影响。
(3)参数量化的效果测试。对神经网络的权重进行二值化之后,速率大大提升,但是准确率会有一定程度的下降。在这种情况下,需要权衡网络大小、速率和精度之间的关系。在MNIST 数据集上进行了一组实验,重复实验10 000 次,比较了网络层数不同时的浮点错误率和二进制错误率,结果见表4。

表4 网络层数对正确率的影响Table 4 Influence of network layer numbers on accuracy
从表4 可以发现,当神经元层数比较少时,错误率差别较大;当神经元层数增加时,错误率差别变小,能效比增加。实际应用中,可以通过增加一定层数的方式降低错误率,但当网络层数增加时,运算量又会增大,这就需要对速率和准确率进行权衡,在具体的实验中选择最恰当的网络层数。
实验还表明,参数二值化可以极大地提高运算速率,表5 示出了不同网络结构的参数量和运行速率对比结果。

表5 不同网络结构的参数量和运行速率Table 5 Numbers of parameters and running rates of different network structures
对比本文和VGG16 的网络结构可以发现,虽然两者结构类似,卷积层和全连接层数量一致,但本文模型的参数量明显减少,只有原网络结构的8%,运行速率明显增加。与其他网络结构对比,本文的网络结构的运行速率在嵌入式上具有明显优势。
3.2.2 基于移液机器人物体识别的实验结果 以一个4×6 细胞培养板为例,实验设备包括一台PC、一台PYNQ-Z2、一个摄像头、一个显示器、测试的图片和物体,如图8 所示。

图8 实验设备Fig. 8 Experimental equipment
(1)数据集的准备。训练需要制作特定数据集,分别控制光照、背景和拍摄角度等变量,拍摄原始数据集图片。但由于原始数据量始终有限,所以需要通过数据增强的方法增加样本数。本文使用的是有监督单样本数据增强,原始图片经过加噪、模糊和颜色变换,然后进行翻转、裁剪、变形和缩放等几何操作,可以生成大量新的数据集图片。将图片转换为类似于CIFAR-10 数据集的格式,包含数据:是一个numpy 格式数组,阵列的每一行存储一个224×224 的彩色图像。标签:是一个列表,索引处的数字指示数组中对应的映像数据。标签名:是一个列表,用来保存标签名。
(2)输入图像的预处理。图像由摄像头输入后,在PYNQ-Z2 上进行图像的预处理。图像预处理包括图像尺寸、通道顺序和图像格式标准化的调整,目的是满足识别网络的要求。由于对象本身的透明和反光特殊性,对图像首先进行中值滤波,之后采取了一种边缘提取方法提升准确度,这种方法可以计算出更小的梯度变化。按照这种方法设置好x方向和y方向的3×3 边缘检测算子:

图9 示出了一般物体的边缘提取结果,图10 示出了细胞培养板的边缘提取结果。其中图9(a)、图10(a)为原图,图9(b)、图10(b)为用Canny 算子进行边缘提取,图9(c)、图10(c)为用本文算子进行边缘提取。

图9 一般物体边缘提取Fig. 9 General object edge extraction

图10 细胞培养板边缘提取Fig. 10 Cell culture plate edge extraction
通过检测可以发现,对于一般物体,Canny 算子和本文算子的提取效果近似。对于透明的细胞培养板,本文算子的提取效果更好。原因是透明物体的边缘像素值相差比较小,本文算子通过将滤波器中的权重系数放大,从而增大了像素值间的差异。
由于输入的是640×480、通道顺序为BGR 的彩色图像,为了适应识别网络,需要调整图像尺寸为224×224。PYNQ-Z2 是ARM+FPGA 双核结构,安装了Linux 系统,可以使用python 进行编译工作。在系统顶层直接调用OpenCv 编写函数作相应调整,用相应函数或模块即可调整图像尺寸,变更图像通道顺序,使图像格式符合系统需要。
(3) 实验结果。系统通过bin 文件加载好参数权重,再将bit 流文件烧录形成加速电路,调用FPGA 部分进行加速运算,最终ARM 部分输出结果如图11所示。

图11 细胞培养板的识别结果Fig. 11 Recognition results of cell culture plate
图11(a)为程序中的判断结果,图11(b)为输出在显示器上的结果。实验步骤包括关键目标检测、语义标注和目标框选。嵌入式PYNQ-Z2 目标检测完成后,在识别的物体周围进行目标框选,并在左下角标注物体种类。图11 中两图左下角标注均为“4×6 细胞培养板”,识别成功。通过函数记录耗时,此次推理过程总共花了1538 μs,而优化之前推理需要250454 μs,速率显著提升。
4 结束语
为进一步提高深度神经网络Dropout 正则化算法的性能并验证其在移液机器人物体识别中的应用效果,本文提出了基于恒虚警率的Dropout 正则化方法(CFAR-Dropout)。实验结果表明,本文方法通过自适应地删减神经元并对参数进行量化优化后,可以有效防止过拟合和过参数化现象。将优化的网络结构部署在嵌入式PYNQ-Z2 上后,可以达到更好的识别精度和速率,可以应用于移液机器人系统来有效提高嵌入式物体识别系统的性能。
