基于光流估计的轻量级视频插帧算法
2022-03-02张维君吴杰宏高利军
杨 华,王 姣,张维君,吴杰宏,高利军
(沈阳航空航天大学 计算机学院,沈阳 110136)
海量视频数据的存储和传输给基础设施和网络带宽带来了巨大挑战,对源视频进行压缩能够解决上述问题,但会导致视频质量的下降,在接收端对压缩后的视频进行处理进而提高视频的帧率至关重要[1]。视频插帧算法的主要目的是合成两个连续视频帧之间的中间帧,从而提高视频播放的帧率,保证视频中物体运动的连贯性,减少用户观看时的卡顿感,改善用户的观看体验。
光流在视频的处理中占据重要的地位,代表的是在两个时刻之间每个像素点的运动矢量,利用视频序列中相邻帧之间像素点的对应关系计算得到物体的运动信息。传统的基于光流估计的视频插帧算法是先计算输入帧的双向流,进而细化生成中间流,能够在一定程度上避免重叠和抖动效应[2]。但现实世界中复杂、大规模非线性运动使得视频插帧面临较大困难[3]。深度学习与视频插帧算法的结合为视频插帧研究提供了新思路。Liu等[4]提出了深度体素流(Deep Voxel Flow,DVF)的端到端的深度网络模型,此算法根据相邻帧的体素来学习重建帧,解决不同体素移动的速度不一致问题。Jiang等[5]提出了一种基于U-Net架构的双向流估计算法,通过U-Net模型来改进近似流,将两帧图像扭曲并线性融合成中间帧,解决了被遮挡的像素对插值帧造成的伪影问题,此算法的缺点是光流估计的速度较慢,无法应用于实时视频插帧任务中。Bao等[6]提出了用深度感知投影层来合成中间流,该算法能够学习分层特征并从相邻像素收集上下文信息,解决了大规模运动或遮挡对插值质量的影响,但引入深度估计模型导致计算量的增加,降低了运行速度。Xu等[7]提出的二次视频插帧(Quadratic Video Interpolation,QVI)算法,利用高阶运动信息估计插值流,但合成的中间帧仍然存在重影和不准确运动。Liu等[8]提出了一种增强型二次视频插帧(Enhanced Quadratic Video Interpolation,EQVI)算法,采用最小二乘法修正运动流的估计,引入了残差上下文合成网络,使模型能够处理更复杂的场景和运动模式,并设计了多尺度融合(MS-Fusion)网络以进一步提高插帧性能。
总体上说,上述方法由于缺乏对中间流的直接监督,造成了插值速度和性能的降低,且因为模型复杂而无法应用于实时视频分析。鉴于此,本文结合实时中间流估计(Real-Time Intermediate Flow Estimation,RIFE)模型[9],提出一种基于光流估计的轻量级视频插帧算法SKFEVI(Selective Kernel Flow Estimation Video Interpolation),给定连续的两个视频帧,引入了注意力机制(Selective Kernel Networks,SKNet)机制[10],只需一次光流估计,通过block模块迭代直接估计中间流信息,并进行翘曲变换。同时,为了解决帧变换的伪影问题,将输入帧、变换帧以及估计的光流信息同时输送到融合网络中融合,最终输出中间帧。在确保插值帧质量的同时,提高了视频插帧的速度。
1 视频插帧算法
1.1 光流估计原理
传统的基于光流的视频插帧算法主要通过光流估计合成中间帧,即给定两个连续视频图像I0和I1,首先估计双向光流,然后对其进行缩放和反转得到近似中间流Ft→0和Ft→1,最后得到一个中间帧It。这种方式不仅需要两次光流估计,而且大多数缺乏对中间流的直接监督,很难生成高质量的中间帧。本文在RIFE网络模型上改进,并受文献[10]的启发,将连续帧输入到如图1所示的SKFEVI网络结构中。SKFEVI模型结构包括3个部分:光流估计网络、向后翘曲(Backward Warp)变换和融合网络。将连续的两帧图像输入到光流估计网络中得到光流图两帧原图像以及光流图经过翘曲变换得到多尺度估计的图像,把估计图像输入融合网络重建合成图像,可以降低仿射结果出现的运动边界像素重叠和伪影问题。
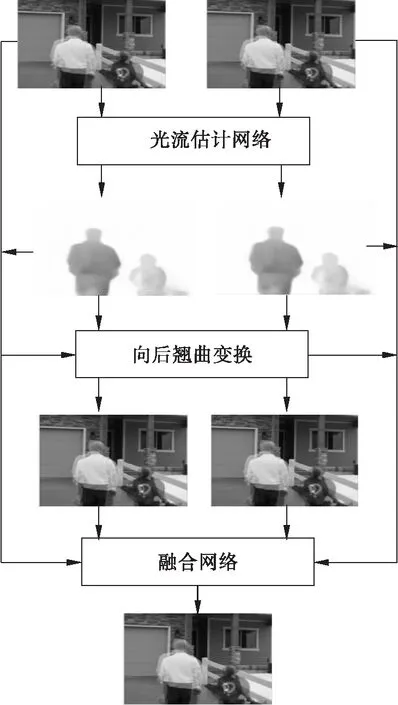
图1 SKFEVI模型结构图
1.2 SKFEVI模型
本文引入了注意力SKNet机制进行特征融合,克服了模型精度不高的问题。特征相加的融合方式可以融合不同尺度的特征,使模型能够包含更多细节信息,减少计算量,并且加入的Mish激活函数能使网络模型具有更好的准确性和泛化能力。一般来说,融合不同尺度的特征是提高模型性能的一个重要手段,所以SKFEVI模型在引入SKNet机制对图像特征进行分层提取后,采用特征融合改善模型精度。
光流估计网络对输入的视频帧进行一次光流估计并输出光流图,与RIFE网络相比,SKFEVI模型每一层的block模块增加了注意力SKNet机制,增强了对不同尺度目标的感受野,使网络针对不同图像选择合适的卷积核,增强了特征的表达能力,光流估计网络结构如图2所示,计算方法如式(1)所示。
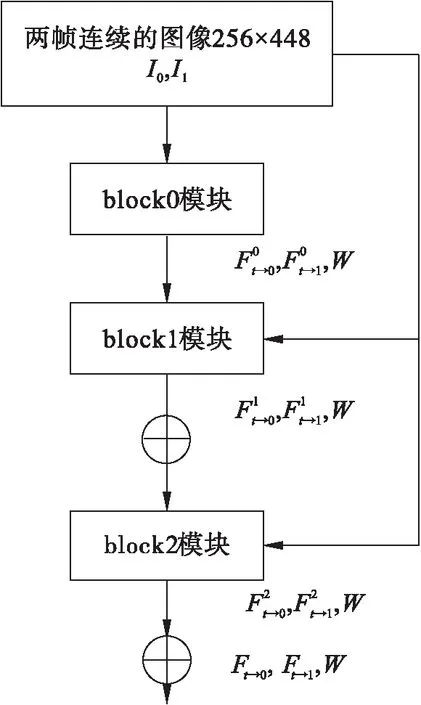
图2 光流估计网络结构图
(1)
光流估计网络由3个block模块组成,每个block模块在第一层通过注意力机制进行特征提取,并把提取到的上层语义信息和底层语义信息进行特征融合,使信息更加丰富,从而使小目标的插帧效果会更好;并且在每一层加了Mish激活函数特征融合进行范围约束,使得到的结果准确性更高。block模块结构如图3所示,Mish激活函数如式(2)所示。
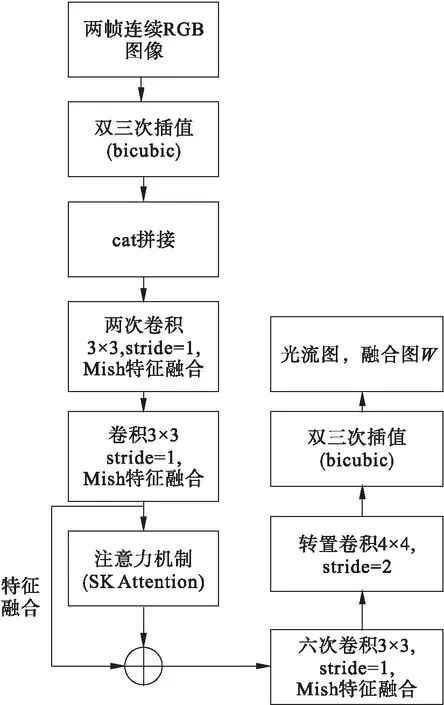
图3 block模块结构图
f(x)=x*tanh[ln(1+ex)]
(2)
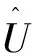
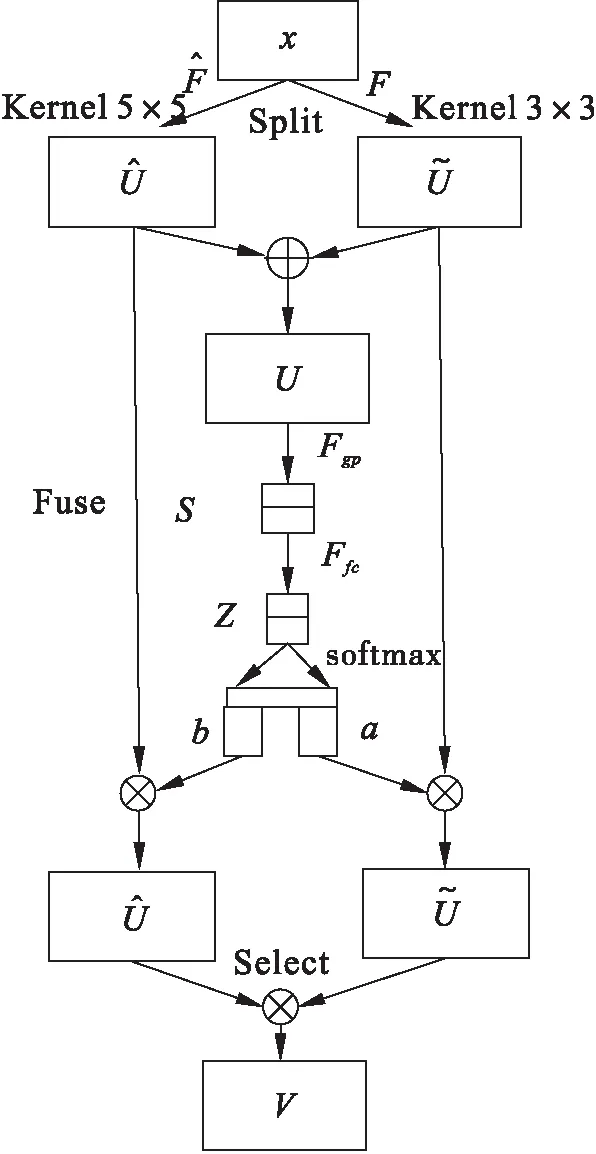
图4 注意力机制(SKNet)网络结构
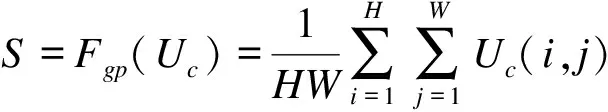
(3)
Z=Ffc(s)=δ[B(Ws)]
(4)

(5)
从图1可以看出,本文采用迭代提取光流的策略,每一阶段处理的图像,都会被用于下一阶段输入图像进行映射变换,因此需要考虑光流融合的策略。融合网络包括一个上下文提取器和U-Net架构,都含有4个步幅为2的残差块(ResNet)。融合方式如式(6)所示
(6)
其中:⊙是元素乘法器;Δ是用于细化图像细节的重建残差;W是输出两帧图像的融合图。
1.3 损失函数
模型效果的损失函数就是计算插帧值与真实帧之间的像素误差。本文模型的训练损失l是重建损失lδ和ldis的线性组合, 用权重λ1和λ2来平衡估计图像的准确性,如式(7)所示
l=λ1lδ+λ2ldis
(7)
本文采用的Huber损失函数[11]可以避免当插帧值图像和真实值图像相差很大时带来的梯度爆炸问题,它同时具有均方误差损失(MSE)和平均绝对值误差损失(MAE)这两个损失函数的优点,可获得更精确的最小值且对异常值更具有鲁棒性,定义形式如式(8)所示
(8)

SKFEVI模型可以直接预测中间流信息,为了使光流估计的中间结果比较准确,在训练阶段加入ldis蒸馏损失。该损失定义如式(9)所示
(9)

2 实验
2.1 实验条件
本文实验使用Windows 10系统、CPU型号为Intel(R)E52620V4、GPU型号为NVIDIA Geforce GTX TiTAN XP;代码用Python语言编写,使用PyTorch深度学习框架。采用Adam[12]作为优化器,在300个epoch内权重衰减为10-4,batch-size为16。
2.2 参数设置及数据集
本文采用 Vimeo90K-Triplet数据集训练和测试模型。Vimeo90K-Triplet数据集是一个从Vimeo90K视频中剪辑提取的大规模、用于视频帧插的数据集,其中涵盖了各种场景和动作,分辨率均为256×448,该数据集中有73 171个用于训练的三元组,其中每个三元组有3个连续的视频帧,其中3 782个三元组作为测试集。采用三元组中3个连续的视频帧的第一帧和第三帧作为模型的输入,第二帧作为模型的真值。在训练阶段,通过水平和垂直翻转随机增强训练数据;在测试阶段,图像的原始大小保持不变,不作数据随机处理。
2.3 评价指标
为了与其他视频插帧算法进行比较,本文采用测量峰值性噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性(Structural Similarity,SSIM)两个指标对不同的方法进行比较。
(1)PSNR是评价图像质量的客观标准,由计算最大信号值与噪声强度的比值得到[13],PSNR的数值越大,则表示测试图像和原始图像之间的像素误差越小,失真越少,质量越好。具体定义如式(10)和(11)所示
(10)
(11)
(2)SSIM能够更好地反映人们对于图像质量的主观感受,是描述测试图像和原始图像之间结构相似性的指标,取值范围为[0,1]。从亮度、结构和对比度3个方面度量真实值图像和估计图像的相似性,定义如式(12)所示
(12)
其中:μx和μy分别是数据集的第二帧图像和视频插帧算法得到的中间帧图像的均值,作为亮度的度量;σx和σy则分别是数据集的第二帧图像和视频插帧算法得到的中间帧图像的方差,作为对比度的度量;而σxy为数据集的第二帧图像和视频插帧算法得到的中间帧图像的协方差,作为结构相似性的度量。为了防止分母为零,C1、C2均为常数。
2.4 实验结果
图5展示了一组训练图像经过各个阶段处理后的可视化结果。向光流预测网络中输入连续的两帧RGB图像I0和I1,分别是测试数据集中三元组的第一帧和第三帧图像,并经过光流预测网络的blocki模块迭代,插值采样,SKNet对图像进行多维度特征提取,Mish激活函数对提取到的不同层特征进行特征融合,得到光流图F0,并且使用线性运动假设近似估计光流图F1和融合图W;通过上下文提取器(ContextNet)对原始两帧图像分别提取上下文特征,并对提取到的特征和对应的光流图一起使用Backward Warp变换,得到两帧粗略图。为了消除Backward Warp变换后的伪影问题,最后将输入帧、光流图以及经过Backward Warp变换的两帧图像输入融合网络,最后融合网络的上下文提取器(ContextNet)和U-Net网络重建插入帧,得到插帧图像。

图5 各个阶段的视频帧可视化结果
SKFEVI算法经过一次光流估计即可得到图像的光流图,降低了模型复杂度,从可视化图上的处理结果可以看出,该算法能够消除运动物体边界的伪影和重叠问题,处理的结果图更接近于真实帧。
表1是本文提出的SKFEVI算法和近年来基于深度学习的视频插帧算法进行比较的结果,所有对比模型使用的参数为开源模型中的参数。可以看出,SKFEVI算法在PSNR和SSIM评价指标上都取得较好的结果,均有所提升,且处理一对图像的运行速度达到了22 ms,达到了光流估计速度和估计中间帧质量的平衡。
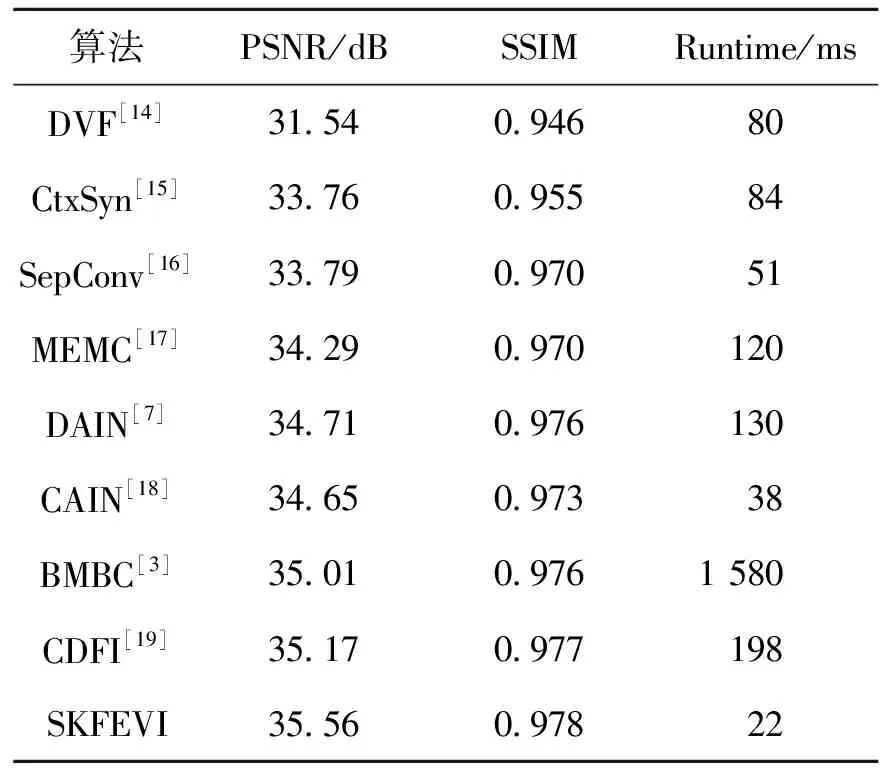
表1 不同方法的比较
由于定量分析评价指标的实验结果与最终人眼观看的实验结果存在一定的差距,因此本文选取了一些典型的、动作幅度较大的图像进行图片效果的测试,选取DVF算法[14]、SepConv算法[16]以及DAIN算法作为对比实验,测试结果如图6所示。
从图6可以看出,SKFEVI算法的结果图(图6f)更接近于真值目标图(图6b),插帧值在清晰度等细节方面明显优于其他算法。DVF算法(图6c)对相邻帧之间像素细节处理还有很多的不足,如合成的中间帧存在模糊、运动不准确等问题。SepConv算法(图6d)可以对高频细节作较为细致的处理,但是当图像中存在高速运动的物体时,最后的插值结果仍会存在模糊问题,产生伪影。DAIN算法(图6e)虽然解决了伪影问题,但会导致部分铁铲的缺失,致使插入帧不准确。总体来说,SKFEVI算法在对视频帧中存在高速运动的物体进行处理后,可以获得较为清晰、平滑的视频合成帧。

图6 SKFEVI算法与其他视频插帧算法对比
2.5 消融实验
为了验证模型中的注意力机制和特征融合模块有效性,本文对其进行消融实验。实验的数据是基于640 p的视频帧计算得到的。本文将一个带有6层卷积模块的残差网络作为基本网络(BaseNetworks),依次加入SKNet模块和特征融合模块(Feature Fusion,FF)。实验结果如表2所示,可以明显看出,增加较小的时间开销,所提出的注意力机制和特征融合模块可以有效地提升视频插帧结果的性能,较好地满足了对算法实时性的要求。
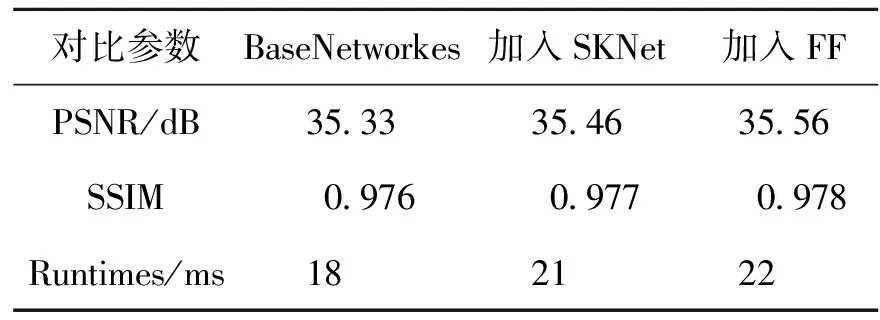
表2 不同模块对模型的影响
3 结论
为了提高视频插帧的中间帧质量,改善现有视频插帧模型复杂、实时性差的问题,本文提出了一种基于光流估计的轻量级视频插帧算法(SKFEVI),引入的注意力机制对不同层特征进行提取和特征融合,该算法对输入的视频帧直接估计中间流,避免了由预先训练光流模型或带有光流标签的数据集带来的速度过慢问题,实现了速度和质量的权衡,使模型更具灵活性。通过量化指标可以得出,在Vimeo90K-Triplet数据集上的PSNR指标提升到了35.56 dB,比RIFE模型提升了0.26 dB,SSIM达到了0.978。在视觉效果上,插帧的图像也较为清晰,优于其他算法,且对于复杂的、大的非线性运动的图像也能重建较为接近真实值的中间帧。
