基于演化博弈的违章停车动态罚金策略效用仿真评价
2022-03-02牟振华汪寒冰林本江陈逸群金程程陈艳艳
牟振华,汪寒冰,林本江,陈逸群,金程程,陈艳艳
(1.山东建筑大学,交通工程学院,济南250101;2.济南市规划设计研究院,济南250000;3.北京工业大学,城市交通学院,北京100124)
0 引言
随着社会经济的发展和居民生活水平的提高,机动车保有量快速增加,而停车位供给却相对增加缓慢,导致了大量的供需矛盾和违章停车现象。解决违章停车问题不仅需要基础设施建设,更需要交通管理措施的升级。违章停车研究在停车诱导设施[1]、违章停车检测[2]等方面成果较多。停车收费方面的既有研究,例如,弹性工作制度和动态停车收费组合策略[3],区域差异性停车收费策略[4]等在优化车辆空间布局有着良好的效果。因此,本文根据演化博弈理论制定违章停车动态罚金策略,以驾驶员和执法者两类群体作为主体,研究两群体之间博弈机理和群体演化方向,并探究该策略的违章抑制程度和社会总成本。
以往的研究中,薛渊等[5]发现了不同初始比例和激励措施对执行政策有显著影响。本文则在特定的违章特征值,包括初始违章概率和执法概率等基础上,研究本地区政策的合理性和动态罚金策略的有效性;徐松鹤等[6]考虑到群体内的“示范效应”,改进了复制动态方程,构建随机演化博弈模型。本文在违章停车问题中运用该模型考虑了违章群体内的从众心理和执法者短时间内的持续执法;王浩等[7]对违章停车的中心点参数进行敏感性分析,得出执法成本比执法奖励对不违章停车影响更大。本文在违章停车问题研究上确定以社会总成本为目标函数,通过激励执法和罚金动态化的方式建立了违章停车动态罚金最优控制模型;XU等[8]将演化博弈理论和动态学习效应相结合,研究通勤者群体在动态停车收费策略下对各种交通方式的选择。本文在此基础上将最优控制理论与改进的复制动态方程相结合,并通过执法激励和罚金动态化的措施求解使社会总成本最小的罚金演化路径。本文的创新点在于:①将改进的复制动态方程与违章停车问题相结合并做出了相应的调整与假设;②研究基于执法激励和罚金动态化,将演化博弈理论与最优控制相结合,以违章抑制效果和社会成本最优为目的求解动态罚金的合理演化路径;③研究在敏感性最高(动态执法状态)和临界状态(动态罚金系数趋于稳定、执法者保持短时间持续执法状态)下,改进后的动态罚金模型特有的策略优势。
本文阐述违章罚金思路的形成过程,基于以往对违章问题的研究提出动态罚金策略;在改进的复制动态方程基础上,结合执法激励和动态罚金的措施构建动态罚金最优控制模型法;对改进后的动态罚金最优控制模型的均衡点和稳定性进行分析并通过最优控制的方法进行求解;通过数据仿真验证各稳定点的正确性,并采用从一般到特殊的研究方法,先研究了各参数对违章特征值演化路径的影响,再以济南市某区为例对敏感性最高和临界状态下改进前、后的动态罚金策略进行对比。
1 动态罚金策略
动态罚金策略是根据违章停车现象的发展现状,以社会总成本最小为目标确定适合的罚金金额,本文以1个月的单位步长研究违章问题在不同演化时间最适合的罚金金额。违章停车现象中的驾驶员和执法者两类群体在决策的选择上会由于认知能力有限以及受周围环境的影响做出有意识、局限性的有限理性选择行为。演化博弈理论适用于研究有限理性[9]的群体博弈行为,因此,将其运用到违章停车问题。
1.1 模型假设与变量设置
驾驶员和执法者两类群体行为特征如下:驾驶员考虑自身利益和损失,并由于停车设施不足、时间成本过高和违章从众心理等原因[10]对违章停车行为进行有限理性选择;执法者为保证社会总损失最小,通过警告、罚单等措施对驾驶员的行为进行教育与惩罚,但由于警力缺失等原因无法做到完全执法。两群体之间的对抗与制约关系形成了博弈过程。
模型假设:①驾驶员以自身利益和损失作为决策选择的主导因素,违章和不违章的概率分别为x和1-x,执法者以社会总成本最小为决策选择的主导因素,执法者执法和不执法的概率分别为y和1-y;②驾驶员违章会比不违章节省寻找车位的时间,驾驶成本分别为qθ2和qθ1,其中,θ2>θ1;③执法者找到违章车辆的时间与违章者找到车位的时间相同,因此,执法的时间成本系数与违章时间成本系数θ1相等,执法成本为Cθ1,不执法时的成本为0。模型中需要的参数和变量值如表1所示。

表1 参数定义Table 1 Parameter definition
1.2 动态罚金最优控制模型
在经典的演化博弈模型基础上,动态罚金最优控制模型将执法收益与违章罚金相联系,模拟执法者惩治违章停车现象后所获得的收益,即B=αP,然后,加入动态罚金系数实现罚金动态化,即罚金金额为,以此构建收益矩阵。
驾驶人违章和不违章的期望收益为
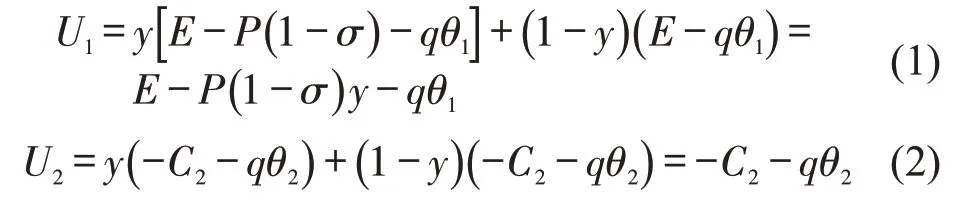
将驾驶员违章和不违章的平均收益作为驾驶员的期望收益,即
得到驾驶员违章停车的复制动态方程为
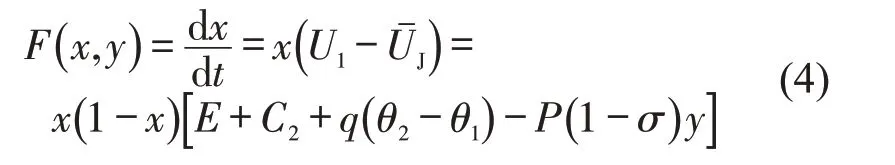
执法者执法和不执法的期望收益为
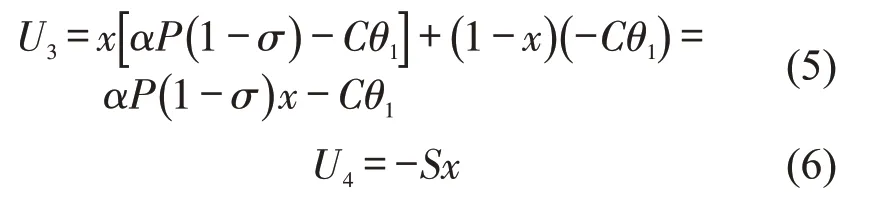
将执法者执法与不执法的平均收益作为的执法者的期望收益,即
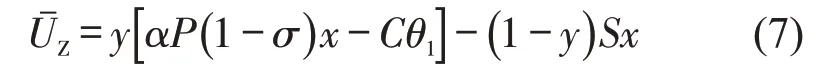
得到执法者的复制动态方程为
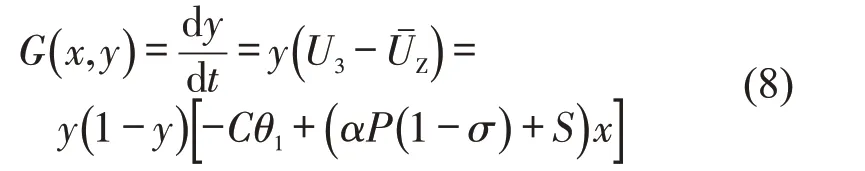
可得
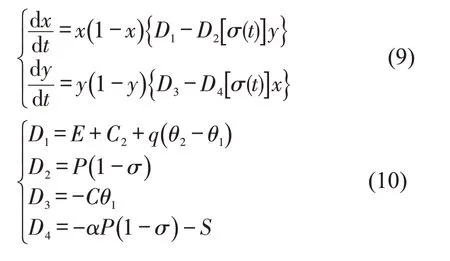

表2 驾驶人与执法者博弈的收益矩阵Table 2 Profit matrix of game between drivers and law enforcers
1.3 改进后的复制动态方程
改进后的复制动态方程将违章者和执法者可供选择行为之间的内在关系引入改进的复制动态方程,通过设置违章停车影响因子a1来模拟驾驶员违章停车行为选择过程中的从众心理,设置执法影响因子b1来模拟执法者持续执法和动态执法过程。
假设驾驶员选择违章停车行为的人数为p1,选择不违章停车的人数为p2,违章停车概率为

在复制动态过程中,驾驶员选择违章停车行为变化率与违章停车基数和违章停车期望收益成正比,即

式中:a1为违章停车影响因子,a1值越大代表违章停车的基数越大,驾驶员群体选择违章停车的扩散速率越大,即从众心理影响程度越大。对式(11)求导,即
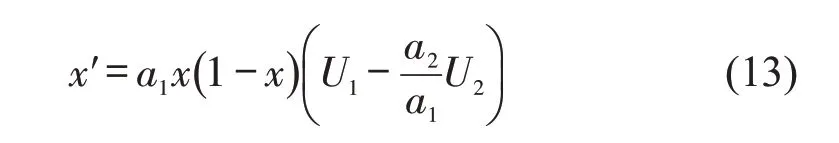
同理,假设执法者选择执法的人数为q1,选择不执法的人数为q2,执法者执法概率为

在复制动态过程中,执法者选择执法的变化率与执法者基数和执法期望收益成正比,即

式中:b1为执法影响因子,b1值越大代表执法群体的基数越大,执法者的敏感性越高,执法者策略变化越快,越趋近于动态执法的过程。对式(14)求导,可得
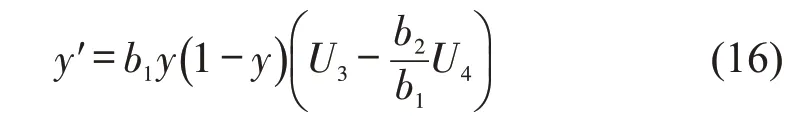
当a1=a2,b1=b2时,即为经典的演化博弈模型。由于a1,a2,b1,b2是任意的,结合违章停车问题,令a2=1-a1,b2=1-b1,模拟驾驶员选择违章和不违章,执法者选择执法和不执法之间的关系。为保证分母不出现0 的情景,令a1=0.05+0.9a1,b1=0.05+0.9b1,使a1和b1在[0.05,0.95]的范围内,因此,。λ为违章期望系数,用来描述驾驶员违章期望收益与不违章期望收益之间的影响;τ为执法期望系数,用来描述执法者执法期望收益和不执法期望收益的影响程度。λ>1 代表不违章期望收益占主导;λ<1 代表违章期望收益占主导。同理,τ>1 代表不执法期望收益占主导;τ<1代表执法期望收益占主导。
改进后的复制动态方程为
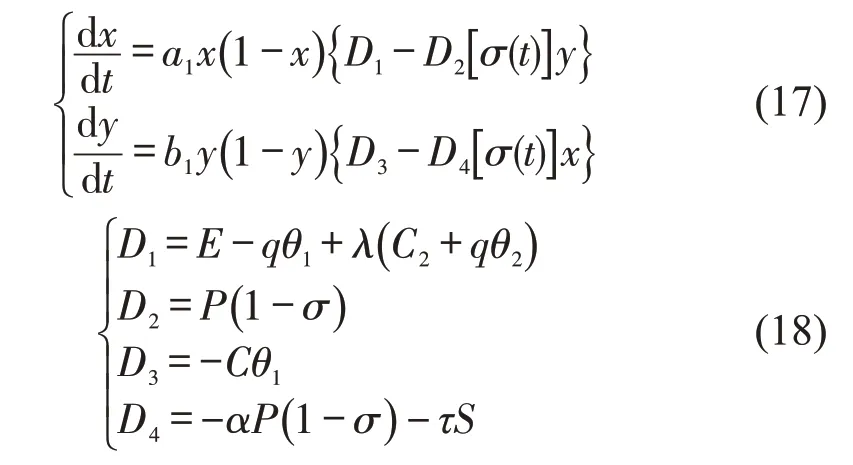
以往的研究表明执法成本和不违章的净损失对违章现象的影响速率更大,本文以社会总成本最小为目的建立目标函数。根据执法者和驾驶人的收益成本矩阵可以计算t时刻驾驶员违章和执法者执法的成本为xqθ1+yCθ2,假设动态罚金策略的成本为[11]。因此,动态罚金的目标函数为
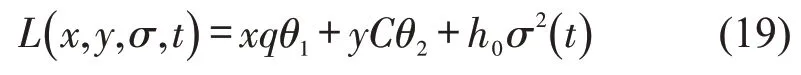
为使社会总成本最小化,根据庞特里亚金极小值原理得到目标函数为
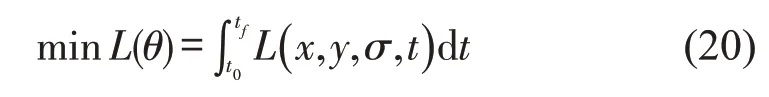
式中:t0和tf分别为演化起始时间和演化终止时间。
2 模型分析和求解方法
2.1 均衡点和稳定性分析
式(17)和式(18)组成了驾驶人与执法者的动态博弈系统。令和,可以得到5个均衡点:。分别讨论均衡点的稳定性能。
由动态方程式(17)和式(18)构成复制动态系统的雅克比矩阵J为
雅克比矩阵的行列式和迹为
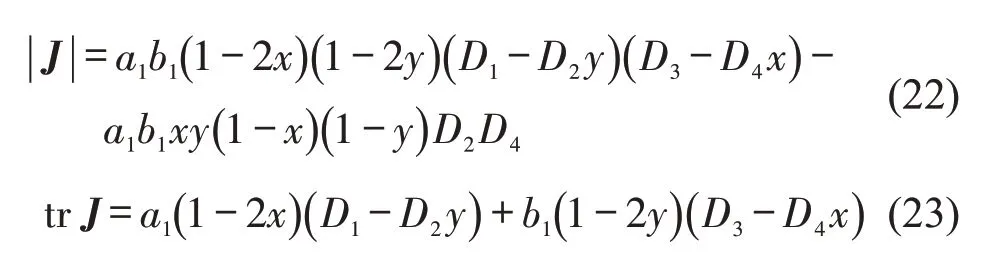
为解释动态罚金最优控制模型中驾驶员与执法者之间的策略选择行为,本文对演化博弈理论的收敛性和稳定性进行分析,如表3所示。

表3 动态罚金策略均衡点及稳定性分析Table 3 Equilibrium point and stability analysis of dynamic fines strategy
表3 中D1
①当D1>D2,D3>D4,D1>0 时,即违章会获益、执法会获益的情景下,违章停车现象会向着高违章概率和高执法概率方向,即(1,1)的方向发展。
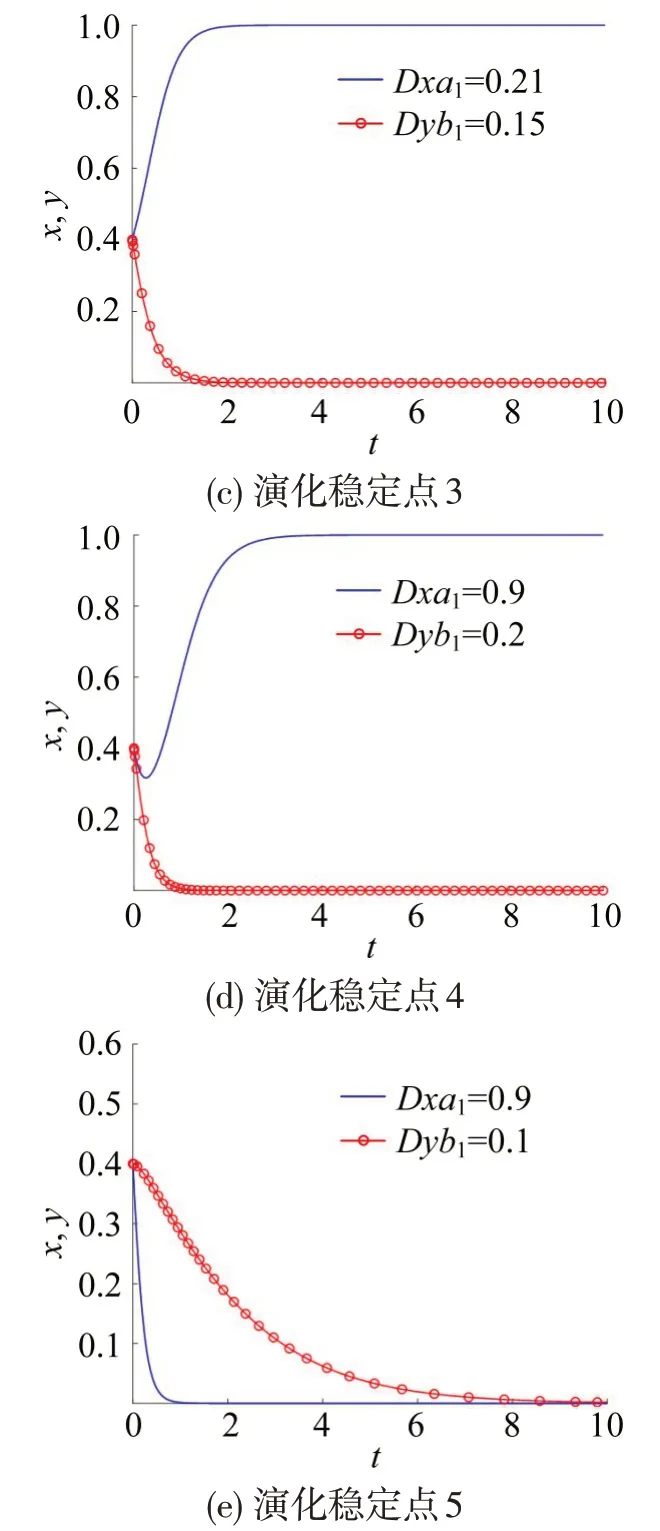
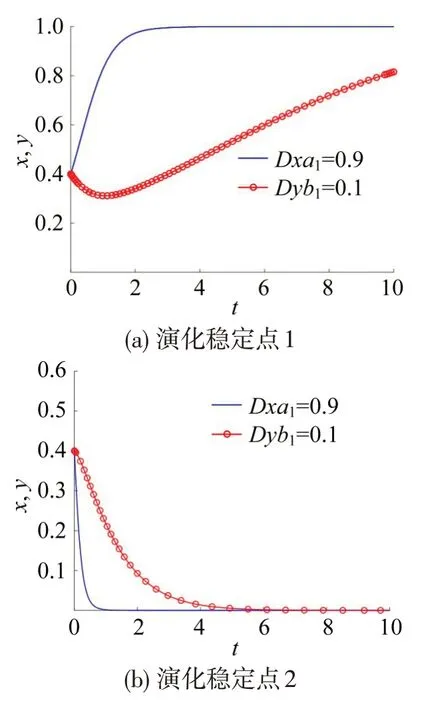
②当D1 ③当D1>D2,D3 ④ 当D1 ⑤当D1 根据式(17)~式(20)构建一阶非线性哈密顿方程,即 初始条件为 综上可知,在该模型下的违章停车执法问题上没有合理的稳定演化方向,因此,初始违章特征值会影响演化方向和结果,针对特定城市选择合适的违章特征值尤为重要。根据式(29)确定初始违章特征值后,代入式(28)得出的值,再代入式(27)求解出动态罚金最优控制系数,确定动态罚金策略的最优解。 本文以济南市实际数据为例,确定初始违章特征值,通过数值仿真比较复制动态方程改进前、后动态罚金策略的违章抑制作用和策略成本,根据违章停车传播模型预测不同时段实施动态罚金策略的违章特征值,进一步研究实施动态罚金策略的时效性。 本文假设驾驶员是因为停车设施不足而违章停车,此时,停车泊位缺口数等于总体违章数,违章概率通过停车泊位缺口数除以机动车出行次数计算,2019年济南市泊位缺口数为60.40万,常住人口890.87 万人,济南市综合交通调查报告显示,人均小汽车出行次数为2.1次。计算可得初始违章概率为0.2152。通过某交警大队的执法数据,得到7~12月份的执法概率分别为0.1818,0.1597,0.1458,0.1328,0.1676和0.1296,初始执法概率取平均值为0.1529。 分别对5个稳定点进行数值仿真,研究稳定点分析结果的正确性。数值仿真如图1所示。 图1 中,Dxa1和Dyb1分别表示在违章停车影响因子和执法影响因子数值条件下改进的动态罚金策略违章概率和执法概率的演化路径。通过调整各参数数值,使各参数之间的关系满足表3中各稳定点的约束条件,由图1 可知,改进后动态罚金最优控制模型的5个稳定点与2.1节中均衡点和稳定性分析结果一致,说明了该方法的有效性。在5个稳定点中第2 个稳定点和第5 个稳定点向着(0,0),即驾驶员不违章和执法者不执法的方向演化,这两个稳定点具有较强的现实意义,能够在节省大量执法资源的同时较大程度上改善违章停车现象。下面对这两个稳定点进行进一步研究。 图1 5个稳定点演化路径Fig.1 Evolution path diagram of five stable points 仅考虑第2和第5个具有合理演化方向的稳定点,研究动态罚金系数σ、执法激励系数α对违章概率和执法概率演化路径的影响。采用四阶-五阶Rung-Kutta算法求解动态罚金最优控制模型,并对比复制动态方程改进前、后的模型。 3.3.1 动态罚金系数和执法激励系数对演化的影响 (1)第2 个稳定点的仿真数据取值如表4所示。演化路径如图2所示。图2 中,Dxσ,Dyσ,Dxα,Dyα分别表示当动态罚金系数σ和执法激励系数α取不同值时,改进的复制动态方程中违章概率的演化路径。图2(a)将α设置为0,即排除激励作用的影响,当动态罚金系数σ的绝对值不断增加,罚金金额不断变大时,违章概率趋近于0 的速率不断加快,对违章现象的抑制作用不断加强。同时,执法概率的变化不大,意味着改变动态罚金系数σ可以实现不额外增加警力的情景下,使违章停车现象获得良好的改善。图2(b)将σ设置为0,即排除罚金变化的影响,当激励系数α不断增加时,违章概率趋近于0 的速率不断加快,执法概率收敛于0 的速率不断变缓,意味着执法激励策略在抑制违章停车现象的同时也会增加额外的执法成本。 (2)第5演化稳定点执法成本参数C取值为6,其余参数与表4 相同。由此可见,第2 稳定点适用于低执法成本的情景,第6稳定点适用于高执法成本的情景。演化路径如图3所示。 表4 博弈模型参数取值Table 4 Game model parameter value 图3的分析结果与图2的分析结果相似,图3中(a)图和(b)图分别令α=0 和σ=0,排除了两者之间的相互影响。由图3(a)可知,动态罚金系数σ只会对驾驶员群体产生影响,罚金金额越高,违章停车现象的收敛速率越快;图3(b)揭示了执法概率与违章概率之间的关系,当α增加时,即执法收益增加时,违章概率会因为执法强度增加而加速收敛。 图2 动态罚金系数和执法激励系数对第2稳定点演化路径影响Fig.2 Influence diagram of dynamic fines coefficient and law enforcement incentive coefficient on evolution path of second stable point 图3 动态罚金系数和执法激励系数对第5稳定点演化路径影响Fig.3 Influence diagram of dynamic fines coefficient and law enforcement incentive coefficient on evolution path of fifth stable point 由此可见,罚金动态化的措施和执法激励的措施都能够改善违章停车现象,也验证了本文通过罚金动态化和执法激励建立动态罚金策略的有效性。 3.3.2 违章期望系数和执法期望系数对演化的影响 基于改进复制动态方程的动态罚金模型中违章概率和执法概率的演化路径如图4所示。 图4 中Dxλ,Dyτ分别表示在违章期望系数λ和执法期望系数τ数值条件下,基于改进复制动态方程的动态罚金模型中违章概率和执法概率的演化路径。图4(a)是在违章期望系数λ取固定值1.44时,研究执法期望系数τ对违章概率和执法概率的影响。由于,随着执法影响因子b1增加,执法期望系数τ不断减小,违章概率收敛于1的速率和执法概率收敛于0的速率不断加快,说明执法期望系数τ同时影响违章概率和执法概率的演化路径,τ值越大,越向着不利方向,即驾驶员违章和执法者不执法方向进行演化。 图4(b)是在执法期望系数τ取固定值1.44 时,研究违章期望系数λ对违章概率和执法概率的影响。随着违章影响因子a1增加,违章期望系数λ不断减小时,违章概率从收敛于1逐渐收敛到0,违章期望系数λ对执法概率基本没有影响。说明违章期望系数λ仅影响违章概率的演化路径,λ值越小,越向着有利方向,即驾驶员不违章和执法者不执法的方向进行演化。根据数值检测,由驾驶员违章向不违章方向演化的临界值为a1=0.6,即λ=0.69 时,违章概率演化方向趋于定值,不同的违章特征和初始参数设置具有不同的演化临界值,不同城市需根据实际数据确定。 图4 违章期望系数和执法期望系数对演化路径影响Fig.4 Influence diagram of expectation coefficient of violation and expectation coefficient of law enforcement on evolution path 综上所述,改进后的动态罚金策略各参数作用如下:动态罚金系数σ相当于改变初始罚金值可以实现不额外增加警力的情景下,使违章停车现象获得良好地改善;激励系数α不断增加,在抑制违章停车现象的同时也会增加额外的执法成本;在不利的演化方向中,执法影响因子b1越小,执法期望系数τ值越大,向着更不利方向,即驾驶员违章和执法者不执法方向进行演化;违章影响因子a1越大,违章期望系数λ越小,向着有利方向,即驾驶员不违章和执法者不执法的方向进行演化。 以济南市为例,根据初始违章和执法概率x0=0.2152,y0=0.1529,违章停车执法过程中各参数取值如表5所示。 表5 博弈模型参数取值Table 5 Game model parameter value a1=1,b1=1,即λ=0.05,τ=0.05 的条件下,违章停车和执法数量的变化速率最快,即敏感度最高时动态罚金策略的演化趋势如图5所示。 图5 中PD指动态罚金策略的复制动态方程在改进后的基础罚金值。图5(a)中执法激励系数α为0.4、动态罚金策略基础罚金值为15时,动态罚金系数σ先增加,最大至1.042倍罚金,随后逐渐收敛于基础罚金值,4 个单位步长时间基本完成了违章停车的治理过程。基础罚金的增加对完成治理的时间基本没有影响。同时,初始罚金越低,动态罚金策略的控制强度越高,随着违章现状的改善,罚金金额不断向基础罚金方向演化。 图5 最大变化速率下不同罚金下σ 的演化趋势Fig.5 Evolution trend diagram of σ under different fines at maximum rate of change 图5(b)是在初始违章、执法概率和表4 的取值条件下,研究违章期望系数λ临界取值时执法期望系数τ对动态罚金系数演化路径的影响。数据仿真可知,违章期望系数λ影响动态罚金系数的演化方向,该条件下的临界取值为a1=0.83,即λ=0.25。执法期望系数τ影响罚款金额的取值,当b1<0.15,即τ>4.41时,罚款金额先减小,然后向基础罚金值方向演化。执法影响因子b1越小,执法概率的变化速率越缓慢,执法的敏感度越低,说明现实中执法者保持较为稳定的执法状态可以对驾驶员起到较好的威慑作用,降低罚金金额才能使违章现状发展到初始现状。 综上可知,在完成违章停车治理的时间上,敏感度最高状态与临界状态相比,即动态执法与连续执法相比,连续执法需要2 个单位的时间,动态执法则需要4个单位时间,连续执法的治理速度提高了1倍。临界变化速率下不同罚金模型改进前、后演化趋势如图6所示。 图6中,P指动态罚金策略的复制动态方程在改进前的基础罚金值。参数取值是在初始违章、执法概率和表4 的取值条件下,研究临界变化率下,即a1=0.83、b1=0.15 条件下,复制动态方程改进前、后的违章抑制性和策略最优解。未改进的动态罚金模型θ1=1/12,θ2=1/4,由于违章停车因子a1和执法因子b1影响,改进后θ1和θ2取值时需要相应的放大。由图6(a)和图6(b)可知,改进后的动态罚金策略比未改进前对违章抑制程度更强,执法力度更低,意味着改进后的动态罚金模型花费更少的社会资源就能达到理想的违章治理效果。初始罚金值P对未改进的动态罚金模型影响较大,对改进后的动态罚金模型影响较小,尤其对执法概率的影响可以忽略不计。由图6(c)可知,临界状态下改进后的动态罚金模型可以实现通过降低罚金的方法达到治理违章停车现象的效果,改进前的动态罚金模型则是通过设置较高的罚金金额来抑制违章停车现象。 图6 临界变化速率下不同罚金模型改进前、后演化趋势Fig.6 Evolution trend diagram of different fines models before and after improvement of critical rate of change 由图7可知,改进前的动态罚金策略成本波动较大且呈现周期性复现的规律,周期长度大约为10个单位步长。基础罚金的增加可以减小改进前策略成本曲线的波峰,但是经过周期时间的演化后仍会复现同等程度的违章停车现象;改进后的动态罚金策略成本逐渐向着较小的方向演化,没有出现违章停车复现的情景,并且基础罚金值的增加对策略成本的影响较小。说明临界状态下改进后的动态罚金策略不需要通过增加基础罚金值的方式,就能够达到较好的治理效果并长期保持,实现了违章停车问题的理想治理结果。从策略成本的角度分析,对10 个单位步长的曲线求积分可知,基础罚金下改进后的策略成本为1.22,改进前的策略成本为8.01,改进后的策略成本约为改进前的1/8。当罚金金额增加到3倍基础罚金时,改进前的策略成本为2.84,改进后的策略成本仍约为改进前的1/3。仅依靠增加基础罚金的方式无法达到改进后的动态罚金策略的效果,并且随着演化时间增加,改进后的动态罚金策略更具优势。 图7 不同罚金下模型改进前、后策略成本对比图Fig.7 Comparison chart of strategy cost before and after model improvement under different fines 综上所述,从一般到具体,先通过实际数据确定了初始违章和执法概率;然后,对6 个稳定点的演化方向进行数据仿真,结果与2.1 节分析结果一致;接着,研究动态罚金系数σ、执法激励系数α、违章期望系数λ和执法期望系数τ对两个合理演化稳定点的违章和执法概率的影响规律;最后,以济南市为例研究了改进后的动态罚金策略在敏感度最高时治理违章停车现象的时间,即5个单位步长。并找到了违章期望系数λ和执法期望系数τ的临界值,即由λ确定动态罚金系数σ达到稳定状态、再由τ确定执法者达到持续执法的情景下,比较改进前、后动态罚金策略的违章抑制作用和社会总成本。 本文在演化博弈理论的基础上以驾驶员和执法者群体作为研究主体,以社会总成本最小为目标,在改进的复制动态方程基础上通过激励执法和罚金动态化的措施构建动态罚金最优控制模型,并进一步分析了不同演化条件下违章者和执法者的演化趋势和稳定性。通过数据仿真研究了模型中各参数对违章和执法概率的影响,运用改进后的模型对济南市违章停车问题进行研究。所得结论如下: (1)改进后的动态罚金模型能够找到违章停车问题的合理演化方向,在不断降低违章概率的同时还能够减少执法力度,并使驾驶员群体在较长时间内持续保持较低的违章水平。 (2)在临界状态下,即动态罚金系数趋于稳定值,执法者保持短时间的持续执法状态,改进的动态罚金策略可以通过改变常用的罚款方式,即降低罚款金额,不仅能够实现对违章停车现象的有效治理还能促进警民融合。 (3)在治理违章停车的效率上,临界状态与敏感度最高状态相比,即连续执法与动态执法相比治理速度提高了1倍,即连续执法需要2个单位时间,动态执法则需要4个单位时间。 (4)改进后的动态罚金策略违章抑制性更强,基础罚金下策略成本更低,约为改进前的1/8,执法效力更持久,演化时间范围内没有出现违章复现的情景,所需的执法力度更低且最终收敛于0.15,短时间内不会出现违章停车周期性复现的情景。 研究结果证明了改进后动态罚金策略对治理违章停车问题的有效性,较改进前更具优势。该策略以降低社会总成本为目的,针对具体的城市从博弈论的角度对治理违章停车现象提供了理论参考和建议。2.2 求解方法


3 数值试验分析
3.1 初始违章特征值
3.2 稳定点演化方向
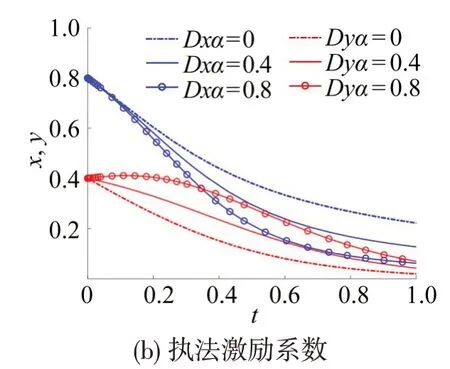
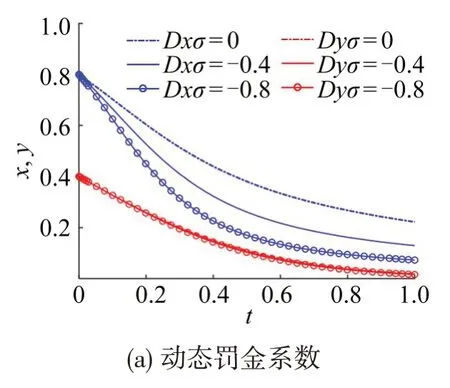
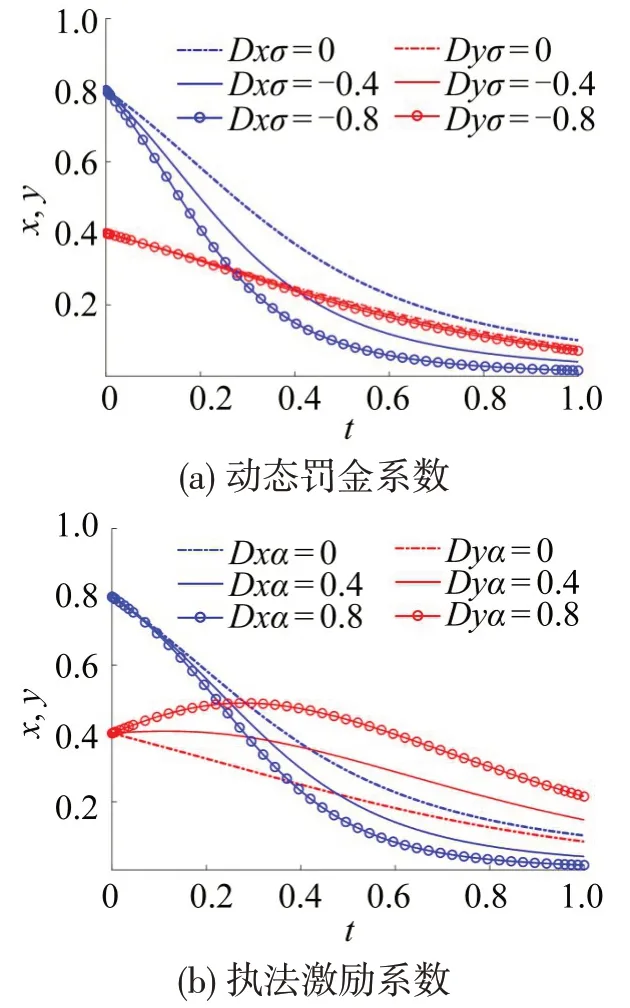
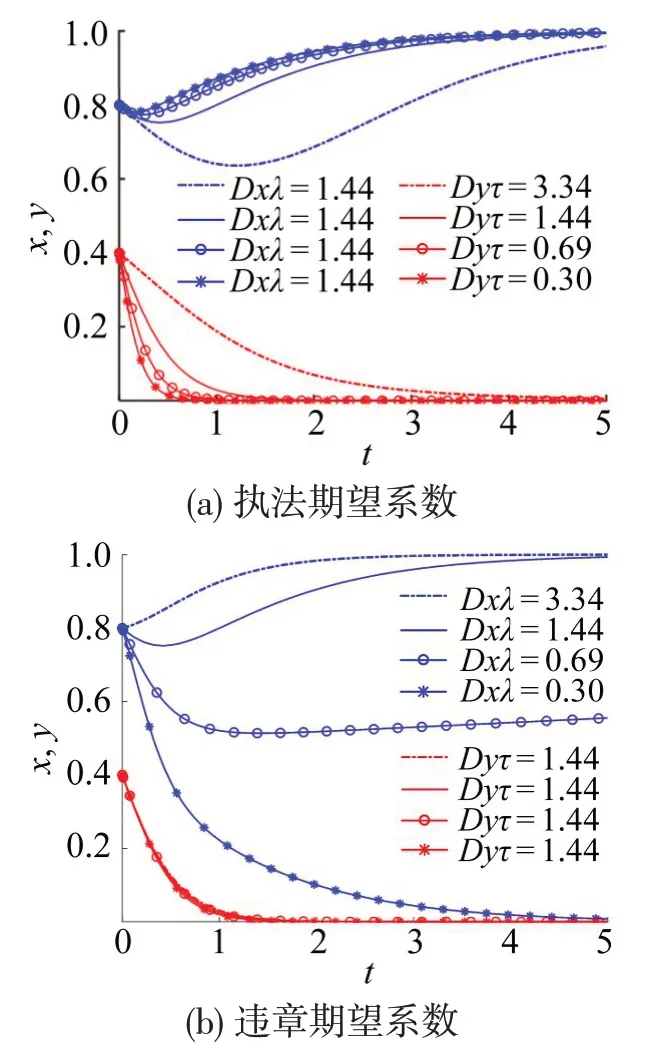
3.3 模型参数影响

3.4 济南市违章停车现状分析

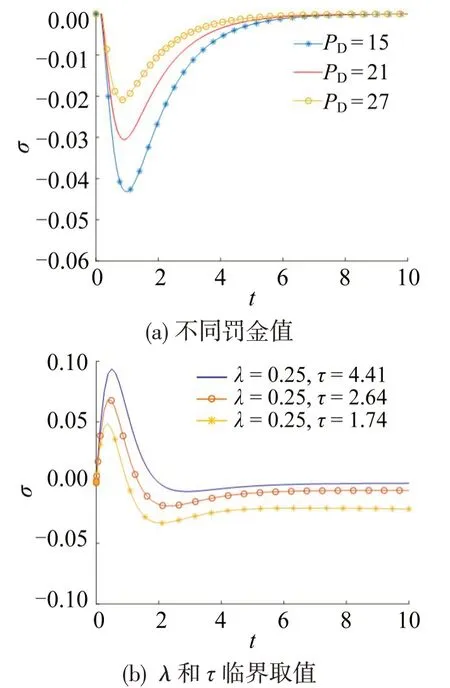
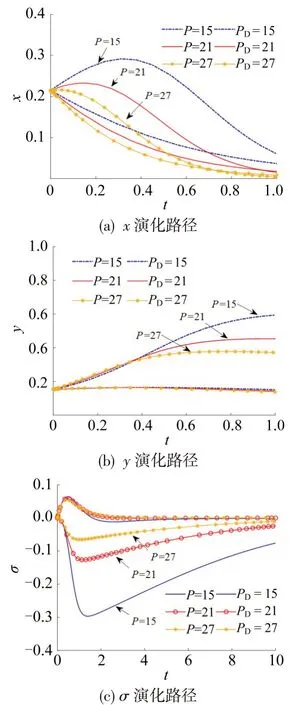

4 结论
