融合标签与内容感知的用户群信息推荐仿真
2022-03-01赵慧娜李国贞王佳伟
赵慧娜,李国贞,王佳伟
(1. 河南工业大学漯河工学院,河南 漯河 462000;2. 重庆交通大学,重庆400064)
1 引言
在大数据和信息挖掘技术快速进步的同时,网络数据呈现出野蛮增长态势,据估计[1],2025年的世界数据总量可增长至163ZB。面对体量如此庞大的数据集合,要想快速搜索得到所需信息,必须依赖强大的推荐系统[2]。目前,很多网络应用的后台都有推荐系统的支撑。其中的关键技术就是推荐算法,能够通过数据分析处理得到对于用户有价值的信息。
当前大部分的推荐算法可以归纳成三种。其一是协同过滤[3],即通过评价数据估计出兴趣信息。随着用户数量的上升,数据的稀疏问题表现的尤为明显。此外,新用户的持续出现也催生了冷启动现象的发生。这些都是约束协同过滤实际性能的重要因素。其二是根据内容推荐,通过内容可以获得关于特征的描述信息,有利于改善稀疏性与冷启动[4]。不同的事物往往会存在特征差异,可是如果分析的内容过于单一或模糊,便有可能引起逻辑混淆,影响推荐精准性。其三是混合推荐,通过前述两种算法融合,或者与其它算法的融合,来获得更好的信息推荐性能。文献[5]通过AlphaMF得到用户的反馈,结合环境完成信息推荐。该算法隶属于协同过滤分类,虽然在冷启动方面有一定优化,但是仍然不能有效解决稀疏性问题。文献[6]根据用户的会话次序构建NARM模型,进而对用户需求进行预测,该算法的问题是模型构建的依据单一,会话过程中的操作顺序并不能完全体现用户需求程度。文献[7]结合了情境与交互动作,同时搭建CRNNs模型,该算法在建模过程中增加了依据信息,问题是交互动作不能替代会话的环境信息。文献[6]和[7]都可以看做基于内容的推荐算法。当一些事物存在局部相似性时,这类算法很难对其进行精确刻画和有效的区分。
本文提出了融合标签与内容感知的用户群信息推荐算法,该算法的优势是:通过内容感知能够获取到更多的标签,加上异构图与GCN特征提取,能够提高标签筛选的精准性;基于评价、影响度、时间、相似度多种关联因素建立偏好模型,拓展了标签比较的宽度。因此,将标签与内容感知结合,既得到了信息推荐的查准性,也提高了查全性。
2 基于内容感知的推荐算法
在内容语料库内,将所有的词采取去重处理,得到的唯一词作为节点,用来组成异构图。将词汇的共现作为边,于是可以得到图G(P,B),P与B分别表示节点与边的集合。图的边分为两种情况,一种是文本与词的连接,一种是词与词的连接。针对第一种情况,利用TF-IDF来确定加权值。TF代表词频率值;IDF代表逆文本频率值。针对第二种情况,利用互信息来确定加权值。综合边的构成情况,将边的加权值计算公式表示如下

(1)
其中,TF表示某词在文本里的频次;IDF表示TF不小于零的所有文本倒数取对数;PMI(i,j)表示词i和j的互信息,为提高共现词的统计效果,对语料库采取滑窗方式得到PMI(i,j),公式表示为
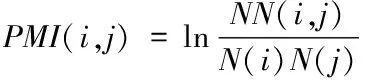
(2)
其中,N表示累计滑窗个数;N(i,j)表示同时含有词i与词j的滑窗个数;N(i)表示只含有词i的滑窗个数;N(j)表示只含有词j的滑窗个数。互信息描述的是词i与词j间的语义关联度。如果PMI(i,j)>0,说明词i与词j间具有较高的关联程度;如果PMI(i,j)<0,则说明词i与词j间具有较少的关联程度,或者根本不具有关联性。所以,利用异构文本生成图的时候,应该保证只在关联程度较高的词间构建边。
针对前述构建的图G,很容易得出其邻接矩阵A。把A和单位特征矩阵一起采取卷积处理,通过邻域属性进行编码。其过程可以描述为
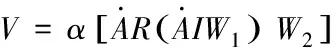
(3)

hi=βdtanh(Wx·xi+Wu·ui)
(4)
其中,βd表示第d维隐层的加权系数;Wx、Wu分别表示给定文本和隐藏向量的加权矩阵。GCN网络的最终输出向量表示为
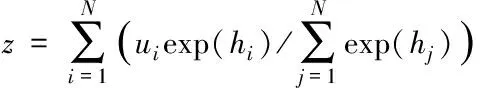
(5)
对网络输出z采取分类操作,利用如下公式筛选得到推荐标签

(6)
其中,Nz表示输出向量z中元素数量。在整个网络训练的过程中,采用交叉熵来作为样本训练的评判依据。于是损失函数设计为
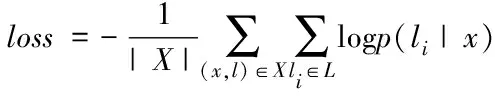
(7)
其中,X表示训练的样本集合;x表示文本内容;L表示标签;p(li|x)表示文本x属于标签li的概率大小。
3 融合标签的信息推荐
3.1 标签偏好
用户的兴趣信息体现在标签的偏好上,如何准确判断用户的偏好,是信息准确推荐的关键。本文首先基于评分与影响来权衡偏好,求解公式表示如下
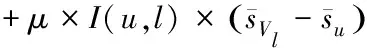
(8)
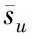
由于用户所需信息并不是永恒不变的,因此标签的偏好还需要引入时间因素。根据标签的最近使用时间,可以判断用户对其需求性。最近使用时间越近,说明当前对该标签的兴趣越大。基于该思想,将标签偏好关于时间的加权计算表示如下
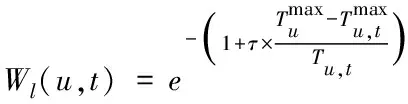
(9)
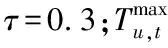
引入时间因素后的标签偏好计算方式更新如下

(10)
其中,ν表示时间整定系数。
3.2 相似度分析
相似度分析的目的是为了搜索到更多的用户群信息推荐依据,本文在相似度分析时,包含了用户和项目两个方面。对于网络用户,根据兴趣可以划分出不同的群体,同一群体内的用户通常拥有类似属性。于是,依靠某用户历史数据搜索出相似用户,相似用户的数据标签便很大程度符合推荐条件。
对于任意用户ui,关于标签选择的属性信息可以描述为Ui=(ci1,ci2,…,cim)。这里的cij为用户ui选择标签lj的频次。由此推导得出群内全部用户的标签选择信息为
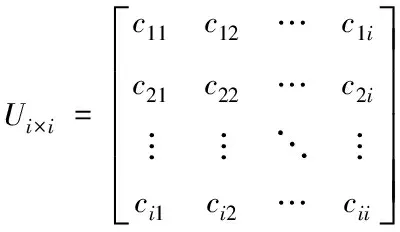
(11)
根据标签选择频次,采用Pearson计算ui与uj两用户关于标签的相似度,公式表示如下
Sim(Ui,Uj)=
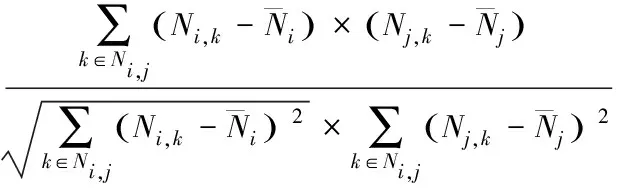
(12)

(13)
与用户相似度计算一样,根据标签选择频次,采用Pearson计算Ii与Ij两个项目关于标签的相似度,公式与式(12)一样。从而得到项目关于标签的相似度矩阵。
利用相似度得到其对标签偏好的影响为
ΔPre=λ1×P×Ui,j+λ2×P×Ii,j
(14)
其中,λ1与λ2分别为两种相似度的加权系数;P为用户的历史偏好;Ui,j为用户i与j相似度;Ii,j为项目i与j相似度。结合相似度,最终的标签偏好计算公式更新为
Pre′=Pre+ΔPre
(15)
4 实验与结果分析
4.1 实验设置
主要是确定仿真数据集、性能评判方式,以及对比方法。由于用户群信息推荐缺乏成熟的数据集,因此本文通过网络爬取统计得到表1所示的数据。从表中数据可以看出,3491位用户一共选择过38618个项目,搜索到累计8107次的用户朋友关系,同时还包括了其它关系和标签规模。
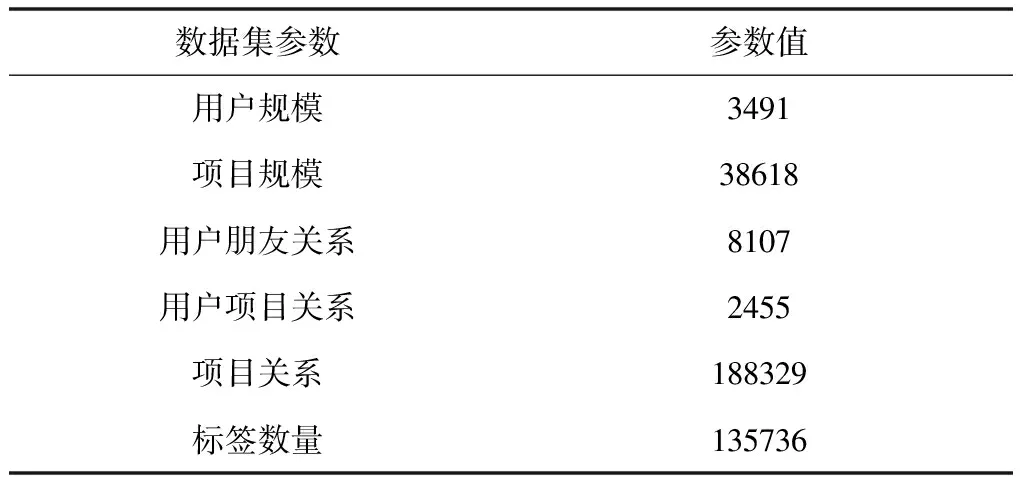
表1 仿真数据集参数
信息推荐算法的主要性能评判指标就是准确率,是用来描述推荐结果查准性的,其计算公式表示为
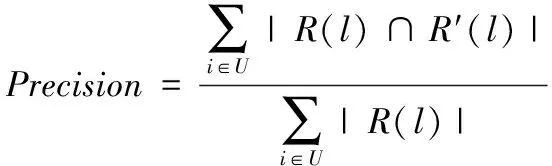
(16)
其中,R(l)与R′(l)分别表示通过训练集与测试集获取到的推荐结果。为了防止单纯追求准确而遗漏算法的查全性,实验过程中同时观察算法的召回率,其计算公式表示为
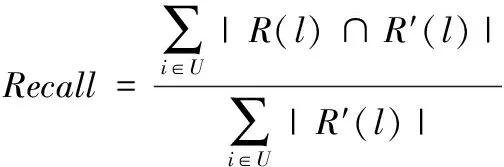
(17)
根据式(16)与式(17)可以看出,Precision与Recall具有彼此约束的关系。如果想提升它们中的任何一项指标,都可以独立完成,但是并不能说明算法的性能绝对提升,只有Precision与Recall指标同时提升才能真正说明算法的真实性能。因此,本文还采用综合指标得到它们的调和性能,计算公式为
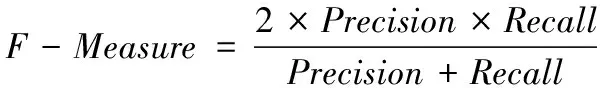
(18)
作为用户群信息推荐结果的比对,本文采用SociRank[8]、TLSTM[9]和TTLMF[10]算法。其中,SociRank的特点是结合了项目的焦点、交互关系,以及关注情况来确定偏好;TLSTM的特点是通过LSTM模型训练获取项目主题向量;TTLMF的特点是引入了信任关系与时间因素。
4.2 结果分析比较
在本文提出的信息推荐算法中,对结果影响最大的参数是标签偏好计算公式里的影响程度整定系数μ、时间整定系数ν、以及两种相似度的加权系数λ1与λ2。首先分析这四个参数对推荐结果的影响,确定μ、ν、λ1与λ2变化时,推荐性能的变化情况,从而得到合理的参数值。考虑到加权系数λ1与λ2的和为1,实验过程中只需要观察其中一个参数即可。关于μ、ν、λ1参数对推荐结果的影响如图1所示。

图1 μ、ν、λ1对F-Measure的影响
根据F-Measure曲线的变化趋势可以得到,在μ=1.2、ν=0.1、λ1=0.4、λ2=0.6的时候,F-Measure可以取得最大值。基于该结果确定的参数,继续对算法的推荐性能进行验证。
通过仿真确定本文算法的最佳推荐数量。以往的研究表明,推荐数量受算法影响严重,实验过程中的起始推荐数量从5开始,每次的增加步长设置为5,得到推荐数量变化对推荐性能的影响,结果如图2所示。

图2 推荐数量对推荐性能的影响
根据实验结果,在推荐数量达到30之前,算法的各项指标均呈现上升趋势。在推荐数量为30时,Precision值为0.350,Recall为0.583,F-Measure为0.438。在推荐数量超过30之后,各项指标开始出现下降。依据该结果可以确定,在推荐数量为30时,算法可以获得最佳的推荐效果。
基于数据集的多次重复实验,得到本文算法与各对比算法的推荐结果,如图3所示。根据结果可得,本文算法的Precision指标为0.354,分别比SociRank、TLSTM和TTLMF提高了0.053、0.025和0.013;Recall指标为0.592,分别比SociRank、TLSTM和TTLMF提高了0.041、0.029和0.013;F-Measure指标为0.443,分别比SociRank、TLSTM和TTLMF提高了0.054、0.028和0.014。从数据可以看出,本文算法有效提升了用户群信息推荐的性能。
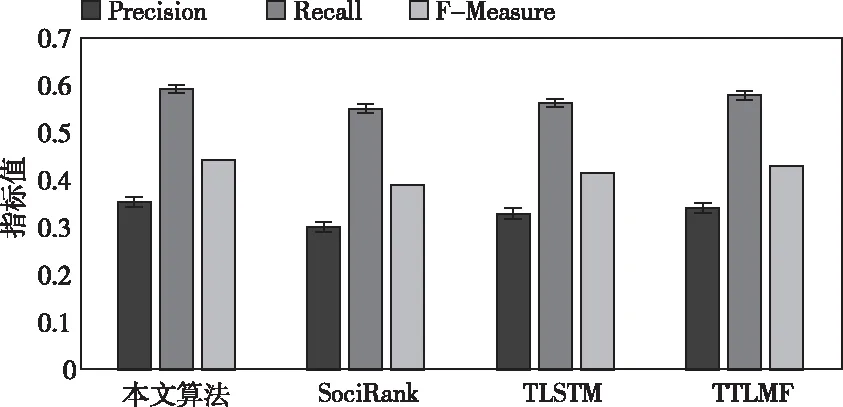
图3 不同算法的推荐性能对比
5 结束语
针对网络信息过载引发信息推荐难的问题,本文提出了融合标签与内容感知的用户群信息推荐算法。该算法的核心是通过内容感知获得项目特征,形成标签,并利用用户兴趣偏好与标签进行比较,从而得到推荐信息。根据仿真,得到了算法中重要参数和推荐数量对推荐结果的影响,确定了参数和推荐数量的最优值;同时也通过Precision、Recall和F-Measure三项指标的提升,证明本文算法有效提高了信息推荐的准确性,能够对数据稀疏性和新用户介入具有良好的适应性。
