基于迁移学习的海底底质声呐图像分类
2022-03-01陈佳辉陈岚萍夏小云
陈佳辉,陈岚萍,夏小云,朱 蓉
(1. 常州大学信息科学与工程学院,江苏 常州 213164;2. 嘉兴学院数理与信息工程学院,浙江 嘉兴 314001)
1 引言
海底底质通常是指海底表面的覆盖物和沉积物,主要有沙质、泥质、礁石等。海底底质分类对海洋测绘、水下作战和海洋养殖有着重要意义。早期的底质分类方法主要通过机械钻孔对海底底质进行采样,再根据先验知识来判断。这种方式不但笨重、成本高,而且会对海洋环境造成破坏。随着声呐技术的日益成熟,人们开始将其作为海底探测的主要手段之一,通过向海底发射声波并对回波信息进行采集,以期获得蕴含丰富底质信息的数据,并对数据进行分析、成像,最终形成能够真实反映海底环境的声呐图像。研究人员可以根据声呐图像来获取海底底质类型、地形地貌、是否有沉船、鱼群等信息。
随着图像处理技术和机器学习的发展,许多研究者通过提取不同底质声呐图像的特征,并用传统机器学习的方法来对海底底质声呐图像进行分类。例如,支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest)、各类神经网络算法等[1-8],以上方法都采用了传统的机器学习方法,虽然取得了较好的分类效果但是需要手动提取特征,并且需要多种特征进行融合才能得到较好的准确率。不同于传统的机器学习,深度学习能够自动提取图像特征,并且提取到的特征更加多样化。基于这种优点,研究者们尝试用深度学习的方法来进行海底底质声呐图像分类研究。2016年,NATO STO—Centre for Maritime Research and Experimentation(北约科学技术组织海上研究试验中心)首次提出将卷积神经网络用于水下声呐图像分类。Keqing Zhu[9]针对海底目标分类问题,将卷积神经网络作为特征提取器,再用SVM作为分类器,最终的精度达到88.9%。X Wang[10]提出了一种基于权值自适应的深度卷积网络,实验证明该方法能较好地区分海床类型、飞机、沉船。
目前采用深度学习模型对海底底质声呐图像进行分类的研究还处于初步阶段,存在较大的研究空间,但是海底底质声呐图像获取困难,每一张图像的形成都要启用声呐、船舶进行实地航行,这导致海底底质声呐图像的数据量较小,而深度学习模型的训练需要庞大的数据作为支撑。对于小样本而言,重新训练模型未必能达到预期的效果,而迁移学习在处理小样本的问题上有较好的表现,本文以此作为切入点,采取基于迁移学习的方法来对海底底质声呐图像进行分类。通过对比实验结果表明,本文模型的准确率优于现有的传统机器学习方法,可达98.1%。此外,在数据预处理阶段对数据进行了增广,增加数据多样性,提升了模型的泛化能力。
2 实验模型及方法
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一[11-12]。其主要包括以下几种结构:输入层、卷积层、池化层、全连接层。其中卷积层和池化层为卷积神经网络中最核心的部分。
卷积层(Convolutional layer)的功能是通过卷积核对输入数据进行卷积运算并提取其特征,卷积核中的每个元素都由权重系数和一个偏差量(bias vector)构成。其具体公式如下所示
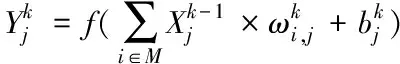
(1)
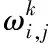
池化层(Pooling layer)也叫下采样层,通常设置在连续的卷积层之间。池化的作用是可以减少图像的冗余信息,从而降低特征图的数据量,减少计算复杂度。其方式主要有最大池化(Max Pooling)和平均池化(Average Pooling)两种[12],以池化窗口大小为2×2为例,公式分别为
Ppool=MAX(xm,n,xm+1,n,xm,n+1,xm+1,n+1)
(2)
Ppool=AVG(xm,n,xm+1,n,xm,n+1,xm+1,n+1)
(3)
其中:Ppool为池化后的输出,MAX为取最大值函数,AVG为取平均值函数,xm,n,xm+1,n,xm,n+1,xm+1,n+1为相邻的四个像素。
2.2 迁移学习及模型选择
迁移学习是指通过从已学习的相关任务中转移知识来帮助完成新任务的方法。其核心是模型的复用,即把为任务A开发的模型作为初始点,重新使用在为任务B开发模型的过程中。
迁移学习中包含域和任务两个重要的概念。一个域D由一个特征空间χ和特征空间上的边际概率分布P(X)组成,其中X={x1,x2,…,xn}。在给定一个域D={X,P(X)}之后,一个任务T由一个标签空间Y以及一个条件概率分布P(Y/X)构成。若给定一个源域(source domain)Ds和对应的任务Ts,目标域(target domain)Dt和对应的任务Tt,迁移学习旨在Ds≠Dt或Ts≠Tt的条件下通过使用Ts和Ds所获取的知识来帮助Tt在Dt中的预测函数Ft()[15]。
在进行迁移学习之前,首先要先确定预训练模型。AlexNet、VGG16、VGG19、InceptionV3、ResNet50[16]都是性能优异的模型,通过对比各个模型之间的参数量、模型大小、Top-1准确率和Top-5准确率,发现InceptionV3不仅模型较为轻便,而且有着较高的准确率,比较符合本课题的研究。详见表1。
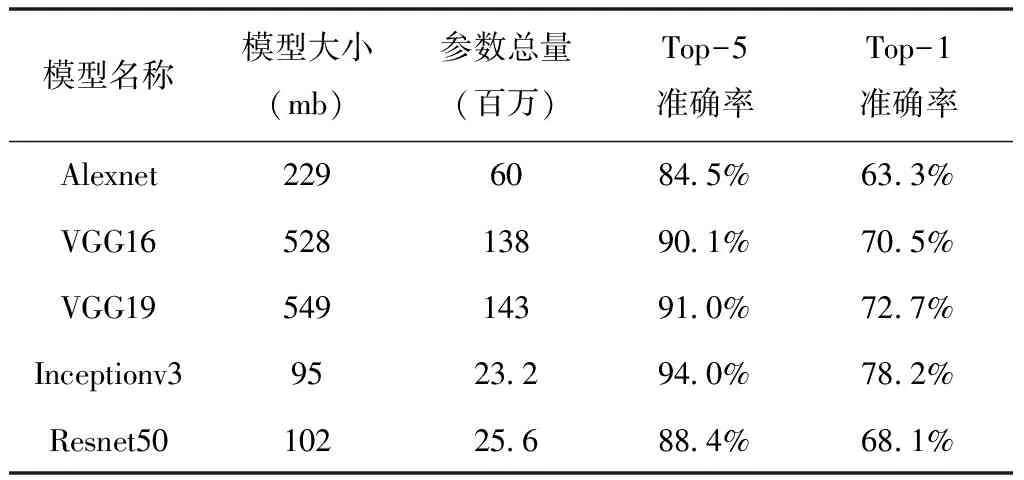
表1 模型对比
2.3 Inception V3
Inception V3[14]由Google在2014年发布的GooLeNet(Inception V1)改进而来,Inception V3采用了Inception结构,对比传统卷积的单一尺寸卷积核操作,Inception V3选用多尺寸的卷积核,并且在同一个卷积层进行卷积操作。同时,Inception V3提出将一个较大的二维卷积拆成两个较小的一维卷积,进一步减少的参数数量。另一方面,Inception V3优化了Inception Model的结构。
2.4 InceptionV3-FC
2.4.1 模型迁移
图1为本实验的整体框图,主要分为预训练模型和InceptionV3-FC两部分。预训练模型部分为已在ImageNet上训练成熟的InceptionV3模型;InceptionV3-FC部分先冻结InceptionV3模型瓶颈层(bottleneck)以上的所有参数,迁移到InceptionV3-FC当中,将其作为InceptionV3-FC的特征提取器,之后再删除原有的分类层,并加入全新的全连接层和softmax分类器形成新的网络(InceptionV3-FC),最后对海底底质声呐图像数据进行训练并分类。
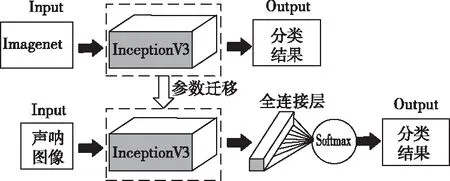
图1 实验模型图
由图1可知,InceptionV3-FC在原有的InceptionV3模型之后接入了新的全连接层,这有利于保证模型迁移的效果。根据Zhang Chenlin[17]等人的研究显示,在迁移学习的过程中,当源域和目标域相差较大时,增加全连接层的网络的性能要比不含全连接层的更好,尤其是在源域图像是物体为中心的图像,而目标图像是非物体为中心的图像的情况下,全连接层可以保持较大的模型容量(capacity),从而保证模型迁移之后的效果。由于海底底质声呐图像与ImageNet上的图像差别较大,并且属于非物体为中心的图像。因此,本文接入了新的全连接层,构建了适用于声呐图像的InceptionV3-FC。全连接层的数学表达过程如下式
y=w·x+b
(4)
其中,w为权值矩阵,b为偏置项,x为输入向量。
2.4.2 fine-tune微调
由图1所示,InceptionV3-FC保留了源模型特征提取的能力,即全连接层之前的参数被完全保留,不需要重新学习,而新建立的全连接层和softmax分类层则需要针对声呐数据进行重新训练。微调时将softmax分类层输出个数调整成海底底质声呐图像的类别数,同时用较小的学习率来对模型进行训练。这种方式适用于目标域样本数量较小且与源域数据相似度较低的情况,有利于模型的训练,能够有效防止过拟合。softmax层的数学表达式如下所示
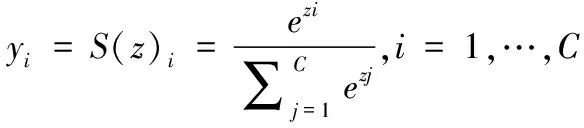
(5)

2.4.3 训练流程
InceptionV3-FC,对输入的样本图像进行特征提取,根据特征来对其进行分类,并利用反向传播算法更新网络参数,从而使准确率达到最高,具体过程如下:
1)载入InceptionV3模型的参数,将其作为初始化参数。
2)输入图像,通过卷积层、池化层、Inception模块、全连接层、softmax分类层,得到不同底质类别的概率。
3)计算误差,将softmax的输出和实际的样本标签做交叉熵,具体公式如下

(6)
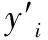
4)利用反向传播算法,更新网络连接权值和相关参数,使得loss值减小并趋于稳定。
3 实验数据及预处理
本实验数据来自浙江星天海洋科学技术有限公司和北京蓝创海洋科技有限公司。主要分为沙质、礁石、泥质三种底质的声呐图像,为了得到更好的实验效果,要对原始声呐图像数据进行预处理。由于原始数据大小不一,首先要对图像进行裁剪并对尺寸归一化处理。根据InceptionV3模型图像输入尺寸的要求,用matlab将原始图像裁剪成多幅299×299像素的图像,裁剪之后的图像示例如图2所示。同时,为了增加实验模型的泛化性和鲁棒性,本实验采用翻转、角度变换等数据增广手段来增加数据的多样性。增广后的图像如图3所示。

图2 裁剪之后的声呐图像

图3 数据增广效果示例
完成对原始数据进行裁剪、增广之后一共得到沙质、礁石、泥质三种底质声呐图像共2011张,其中沙底质声呐图像684张,礁石底质声呐图像675张、泥底质声呐图像652张。
4 可视化特征图
深度学习模型最大的作用在于自动提取特征,本节将以可视化的方式来展示经过卷积计算之后的特征图。为了更直观地看出模型的提取效果,以一副沙底质的声呐图像作为示例,输出其在第1层卷积层、第1个混合层(即mixed_0层)和第6个混合层(即mixed_5层)之后的特征图。
图4为经过第1层卷积层之后的特征图,从图中可知,经过第1层卷积之后,声呐图像的纹理特征得到了较好的保留,可以清晰的看见沙底质声呐图像的沙纹纹理特征。
图4 第一层卷积层部分特征
图5为经过第1个混合层模块之后的特征图,其大小为35×35像素,一共256张,取8张作为展示。从图5可以得出,经过第1个混合层模块之后,此时模型学习的还是图像整体的轮廓特征,相对第1层卷积层的输出来看,此时声呐图像的纹理轮廓较为模糊,但也基本保留了图像的信息。

图5 mixed_0层部分特征
图6为经过第6个混合层模块之后的特征图,其输出大小为17×17像素,一共768张。输出的特征图中,图像的分辨率降低,轮廓较为模糊,随着层数的加深,模型学习到的特征越来越抽象,保留的基本信息也越来越少。

图6 mixed_5层部分特征
观察三组特征图可知,底层网络提取的是海底底质的边缘、轮廓信息。随着网络深度一步步加深,网络提取出的特征越来越抽象,并且更加具有代表性。由此可以得出卷积神经网络可以通过底层的整体特征来整合出高层的抽象特征,并利用高层的抽象特征来对图像进行区分。
5 实验结果及对比
5.1 实验结果分析
实验过程中,本文随机将声呐数据集按照8:1:1的比例划分成训练集、验证集、测试集。在训练模型时,相关参数设置如表2所示:
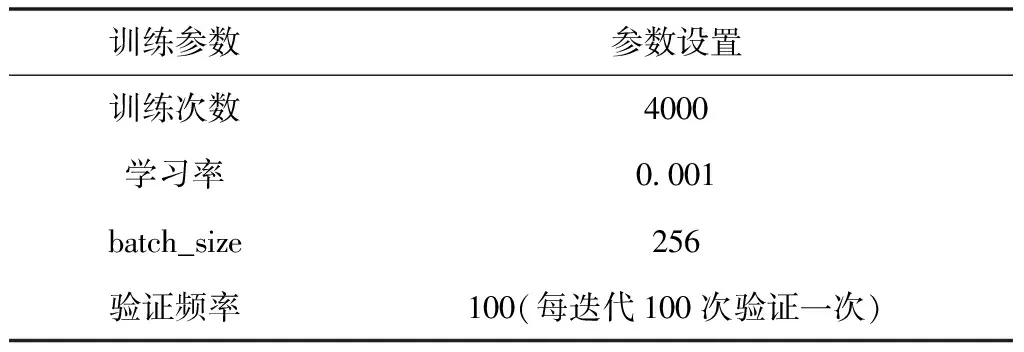
表 2 网络基本参数设置
图7(a)(b)为训练集和验证集的准确率和损失函数曲线图,由图可知在迭代次数2000次之前,准确率成上升趋势且上升速度较快,对应的损失函数的值则呈下降趋势,在2000次到4000次之间准确率上升变缓,最终达到收敛,并且在训练集上的最终准确率为99.6%,在验证集上的最终准确率为97.2%训练完成之后,用测试集进行测试,最终测试准确率为98.1%。
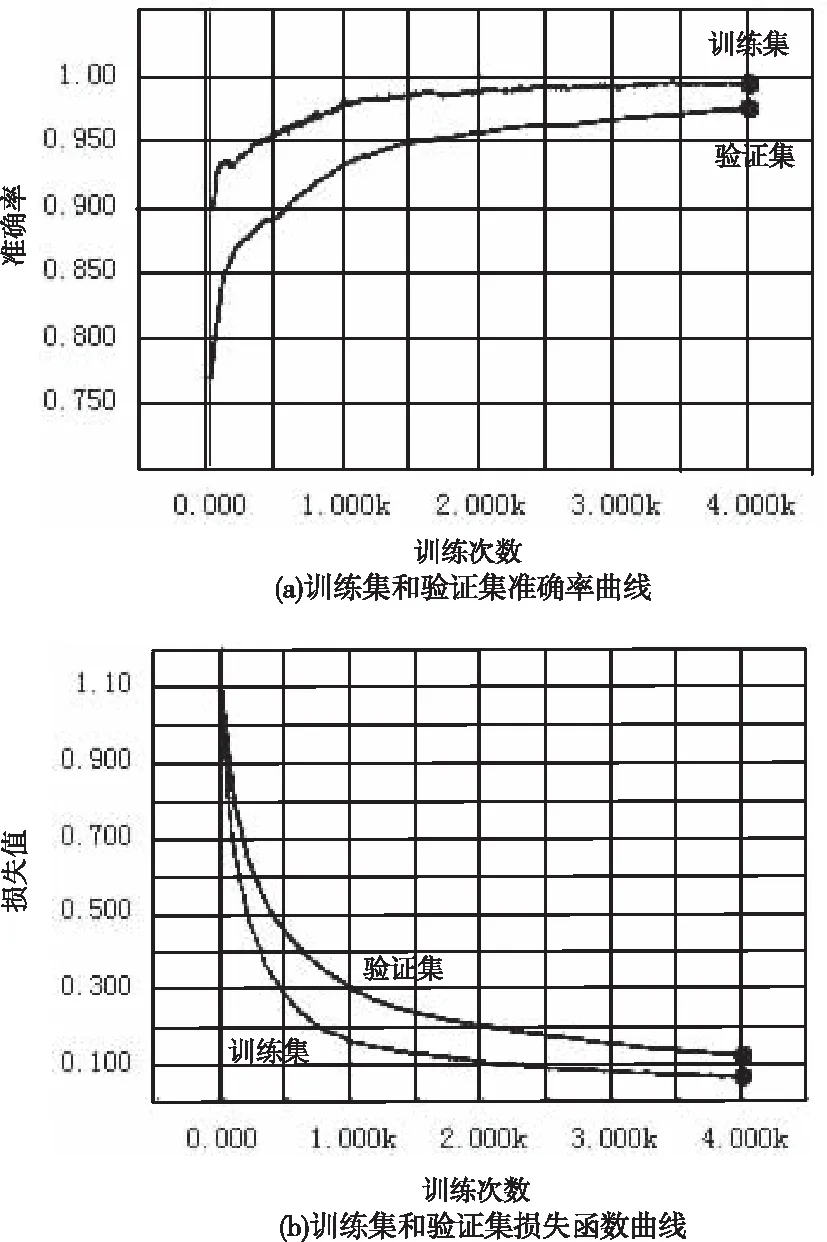
图7 训练、验证准确率以及损失值曲线图
5.2 性能测试及对比
本文在对随机的测试集进行测试之后,还对每一类海底底质的分类效果进行了测试。如表3所示,选取沙底质、礁石底质、泥底质声呐图像各50张。其中分类效果最好的是礁石底质,50张测试图像中仅有1张被分类为沙底质。相较于礁石底质来说沙底质和泥底质的准确率略低,沙底质测试图像中有3张被分类为泥底质,泥底质测试图像中有3张被分类为沙底质,1张被分类为礁石底质。
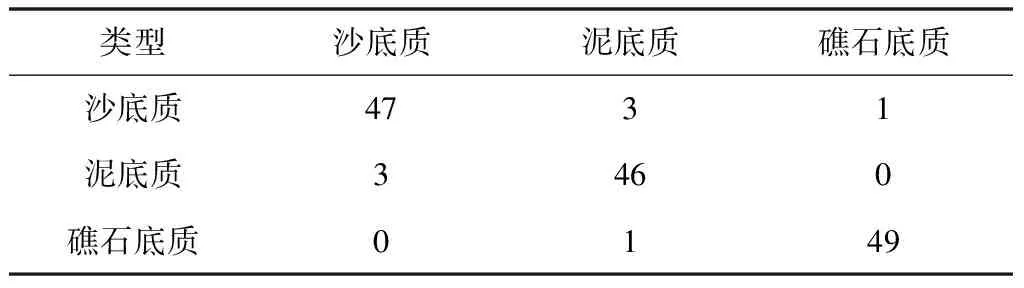
表3 三类底质分类结果
为了进一步测试本文模型的性能,将本文模型与其它相关方法进行对比。其对比结果如表4所示。

表4 相关方法性能对比结果
由表4可知,本实验模型不但可以自动提取特征,并且有更高的准确率。同时不需要重新学习所有参数,训练速度较快。
6 结束语
本文采用迁移学习的方法来对海底底质声呐图像进行分类,并且在真实声呐数据上进行实验,最终总体分类精度达到98.1%,尤其是在礁石图像上取得了较为出色的分类精度。与传统方法相比,本文的方法准确率更高,可以为海底底质分类提供技术支持。在后续研究中,将对声呐数据进行扩充,如加入茅草地、基岩等底质类型的声呐图像数据,进一步扩充可分类的海底底质的类别。此外,还将采用手动提取的特征和深度学习网络提取的特征相融合的方法来进一步丰富提取到的特征,提升沙底质和泥底质的分类精度,力争实现海底底质分类自动化、智能化。
