基于标签映射的移动终端用户个性信息挖掘
2022-03-01刘瑛,陈清
刘 瑛,陈 清
(华东交通大学理工学院,江西南昌 330100)
1 引言
计算机网络日益普及,信息数据大爆炸的时代也随之到来,人类开始进入新的纪元。对于信息爆炸导致的“信息过量”等现象,提出数据挖掘的分析工具。通过数据挖掘技术可以及时从海量数据中挖掘出需要的知识,提高数据利用率,有助于各行业的决策正确,解决数据与知识之间不对等的问题。数据挖掘是通过分析海量不完整有噪声的数据,挖掘潜在知识的过程,它可以有效帮助人们分析、理解数据,通过提取有效信息,指导人们做出正确的决策。数据挖掘比传统数据分析方法处理数据的过程更简单,得出数据内部结构和联系的层次更深[1-3]。
而数据挖掘中,聚类是较为重要的一个技术,它可以帮助人们对事物的内在联系进行探索与认识。对于移动终端用户的个性信息挖掘,目前的方法是依据统计学习思想分析用户个性信息[4-5]。王保加等提出基于多模态特征的医学图像聚类方法,通过多模态特征挖掘用户个性化信息[6],戴大洋等提出基于小波特征提取的高频面板数据聚类方法,使用小波特征提取用户个性信息[7]。但这两种方法忽视了用户个性信息标签之间存在的相关性,选取的表征用户个性信息的特征维受维数限制无法覆盖全部的标签,导致部分标签无法有效表征至用户个性信息的特征向量上。基于以上分析,本文提出基于标签映射的移动终端用户个性信息挖掘方法,通过统计用户标签得到用户个性信息特征,结合相似度计算与特征映射确定每一特征维上的特征值,通过模糊聚类有效准确地实现用户个性信息聚类。
2 基于标签映射的移动终端用户个性信息挖掘
2.1 特征提取
通过移动终端应用程序编程接口(Application Programming Interface,API)获取每个用户个性信息的标签,因为用户标签的建立具有半指导的特点,其标签具有较强的随意性,分析处理标签时难度较高。所以需要对形式特殊的标签进行处理,获得符合全部条件的用户标签所组成的标签集合。通过统计工具统计所有标签,并根据从大到小的顺序排列标签出现的次数,利用设定阈值选择顺序在前的标签为用户向量的特征维[8-9]。
2.2 基于标签信息的特征映射
抽取用户的个性信息数据内的标签字段并建立用户特征集,因为部分标签词条较长,不能直接度量这一类特征的相似度,所以需要准确的划分长词条,并且通过集合的方式描述该特征用词。预处理和格式化用户个性化信息标签后建立用户特征集合
Fu={uw1,uw2,uw3,…uwm}
(1)
建立特征维集合
Fd={dw1,dw2,dw3,…dwn}
(2)
其中,m与n分别代表当前用户特征所含的词数目与特征维所含的词数目。
设X为移动终端用户ui的特征集合数量,x为各特征于该用户特征集合内出现的次数,得到用户各特征初始特征值的计算公式为
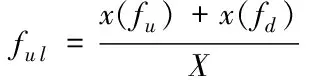
(3)
其中,x(fu)与x(fd)分别为用户特征集合与特征维集合。用户特征集合和特征维集合之间的平均相似度用SF(fu,fd)描述,计算公式为
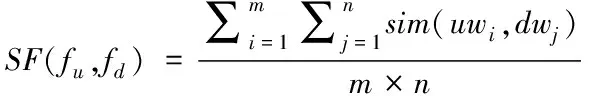
(4)
其中,uwi与dwj分别为包含i个词的用户特征集合与包含j个词的特征维集合,用户特征和特征维之间的相似度通过sim(uwi,dwj)描述,利用HowNet计算词语相似度得到
(5)
其中,S1i为词语W1在HowNet中的第i个义原,S2j为词语W2在HowNet中的第j个义原,S1i、S2j两个义原之间的相似度为Sim(S1i,S2j),计算公式为
(6)
其中,βi(1≤i≤4)是调节参数且满足β1+β2+β3+β4=1,β1≥β2≥β3≥β4。
获得用户特征和特征维间的平均相似度,将相似度最高的用户特征选作该用户隶属度的特征向量[10],特征维的特征值为特征的特征值和最大相似度的乘积,各特征维的对应特征值计算公式为
T(fd)=fd((fu)a)×max{SF((fu)a,fd)}
(7)
其中,α=1,2,3,…,X,用户的X个特征分别和特征维中fd计算所得最大相似度值通过max{SF((fu)a,fd)}表示,fd((fu)a)与T(fd)分别代表相似度最大时该特征的特征值与特征fd的对应特征值。
2.3 基于模糊聚类的移动终端用户信息聚类
2.3.1 数据标准化
设置待聚类的e个用户为论域U={y1,y2,…,ye},通过一个t维的特征向量表征每个用户,得到
yp={yp1,yp2,…,ypt}
(8)
其中,p=1,2,3,…,e,得到原始数据矩阵为
(9)
因为不同数据所具有的量纲不同,需要通过标准差规格化方法适当变换数据实现不同量纲量的比较,计算公式为
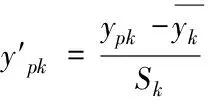
(10)
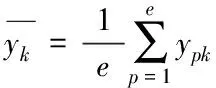
2.3.2 模糊相似矩阵
设置论域U={y1,y2,…,ye},yp={yp1,yp2,…,ypt},p=1,2,3,…,e,用户yp与yg之间的相似度通过模糊相似矩阵中的每一个元素值反映,表征为rpg=R(yp,yg)。rpg的值需要通过指数相似系数法确定,得到
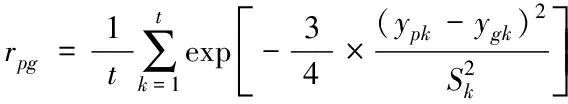
(11)
2.3.3 最佳聚类阈值
以获得的模糊相似矩阵为基础展开模糊聚类[11]。分析模糊聚类,不同的阈值λ∈[0,1]所对应的聚类结果不同,最佳聚类阈值λ所对应的聚类结果为最佳聚类结果。最佳聚类阈值λ的确定需要应用统计量E。

通过数理统计方差分析理论可知,当E>Eα(r-1,e-r)(α=0.05)时,类和类间具有明显差异,聚类较为合理;在E>Eα(r-1,e-r)的情况下,选择对应差值E-Eα中最大的E的λ为最佳λ值,则其对应得到最佳聚类结果[12]。通过移动终端用户个性信息的最佳聚类效果,得出其最佳挖掘效果
3 实验分析
实验选取Weka3.9编程工具,Java程序语言,面向某省人口资源统计机构的移动终端的用户个性信息搜索过程进行实验,将该省全员人口真实数据集为实验对象,实验环境为Intel(R)Core(TM)i7-2600@3.40GHz CPU,内存为4GB,硬盘为1 TB,操作系统为Windows 7。
为验证本文方法的用户个性信息挖掘能力,进行如下实验,设某用户个性信息特征的采集时间间隔和训练集规模分别为95s和550,个性信息分布长度及对该用户个性信息智能化调度的码元宽度分别为2300和0.2ms。利用本文方法挖掘到的某用户个性信息原始数据如图1所示。
图1 用户个性信息挖掘结果
从图1中可以看出,本文方法可稳定挖掘用户个性信息数据,本文方法的数据挖掘性能较好。
分别采用文献[6]方法(基于多模态特征的医学图像聚类方法)、文献[7]方法(基于小波特征提取的高频面板数据聚类方法)与本文方法进行对比,以测试方法的挖掘效果。在实验数据集中随机选取8组数据集进行测试,数据集内的数据量依次增大且属性维数、类别数都不相同。
标签间的相似度受表征标签的特征向量维数影响,特征向量维数越高,相似度越精确。对比三种方法的准确率与召回率。结果如图2、图3所示。

图2 三种方法的准确率对比

图3 三种方法的召回率对比
通过图2可知,三种方法的准确率均随着数据集的增大而提升,但本文方法的准确率随着数据集的增大在开始呈上升态势,在准确率达到95%以上后保持稳定,不受数据集内数据量继续增大的影响,文献[6]方法与文献[7]方法的准确率波动幅度较大,且准确率均低于本文方法,证明本文方法的用户个性信息挖掘准确性较好。
通过图3可知,三种方法的召回率均跟随数据集的不断增加而提升,其中本文方法的召回率最高,且在数据集达到4后平稳,具有较好的召回性能,文献[6]方法和文献[7]方法的召回率波动幅度大,召回性都低于本文方法。
结合图2图3可以发现,本文方法的挖掘效果优于文献[6]方法和文献[7]方法,原因是本文方法采用表征标签的特征向量维数很高,具有较高的精确度,通过本文方法所得标签间的相似度更精确,得到挖掘效果更优。
结合准确率与召回率提出F1聚类评价指标—F1参数,它符合聚类相似标签时能够区分不相似标签的条件并且更容易理解,F1参数值越高,聚类效果越好,挖掘效果越好。对三种方法在轮廓系数从5至30内的F1参数实验结果进行比较,结果如图4所示。
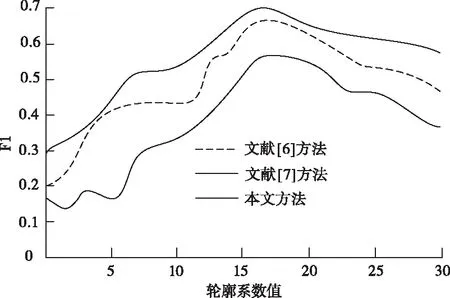
图4 三种方法的F1参数对比
从图中可以看出,三种方法均在轮廓系数值为19时的聚类效果最突出,本文方法的F1参数值始终高于文献[6]方法和文献[7]方法,证明本文方法的移动终端用户个性信息挖掘效果最好。
为了进一步验证本文方法的挖掘效果,选取CA指标与NMI指标进行分析。
CA意为正确划分的样本所占的百分比,计算公式为

(12)
其中,N、gi、ci分别表示样本数量、真实类别标签、实验类别标签。聚类后会重新排列类序号,实验类别标签ci至真实类别标签gi的最优映射描述为map(ci)。在gi=map(ci)的情况下,δ(gi=map(ci))=1,在gi≠map(ci)的情况下,δ(gi=map(ci))=0。CA值越大,挖掘准确率越高。
对比三种方法的CA值,结果如表1所示。
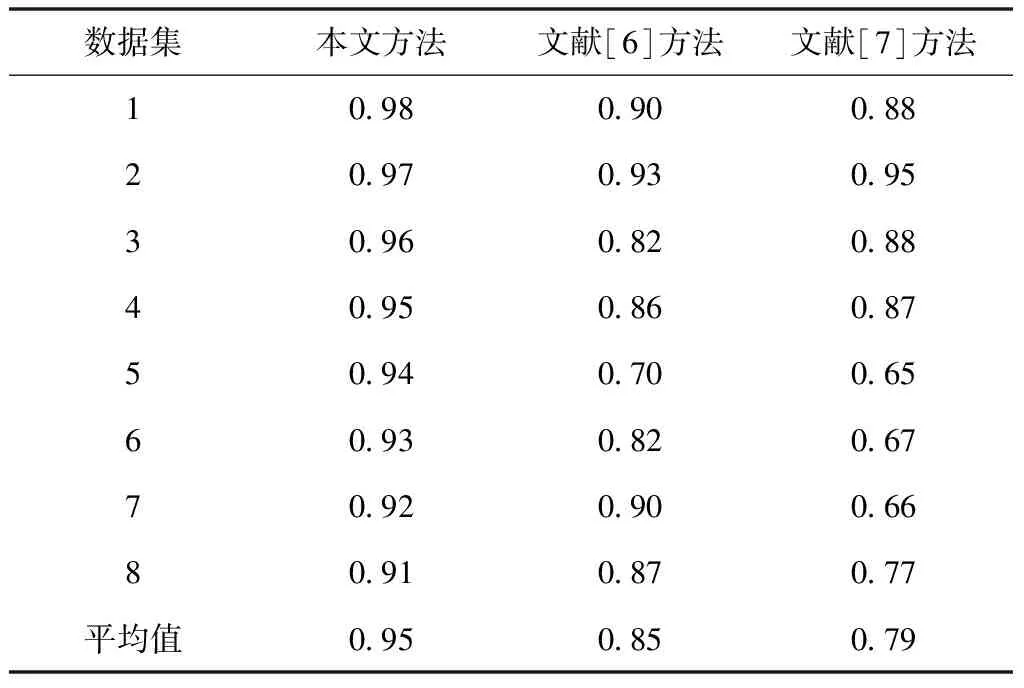
表1 三种方法的CA值对比
通过表1可以看出,三种方法的CA值随着数据集内数据量的增加而变化,文献[6]方法和文献[7]方法的波动较大,且不断降低,本文方法的CA值相对平稳,且数值均在0.9以上,证明本文方法优于文献[6]方法和文献[7]方法,并且本文方法的移动终端用户个性信息挖掘可扩展性较好。
NMI意为真实聚类效果和实验结果之间的标准化互信息,计算公式为
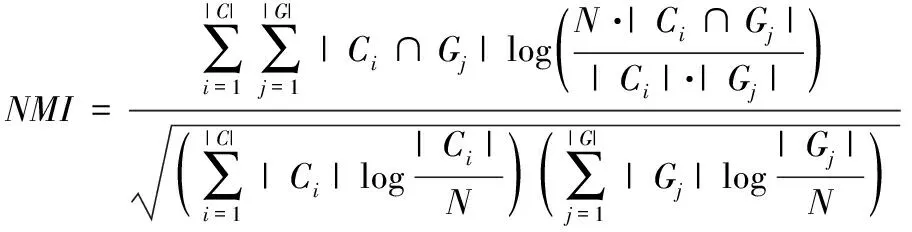
(13)
其中,C为实验聚类结果集,G为真实聚类结果集,Ci∈C为实验结果集的第i类,Gj∈G为实验结果集的第j类,|Ci|与|Ci∩Gj|分别为Ci类与同时在Ci类和Gj类的样本个数。NMI值越大,说明实验结果和真实聚类结果越接近,挖掘效果越好。
对比三种方法的NMI值,结果如表2所示。
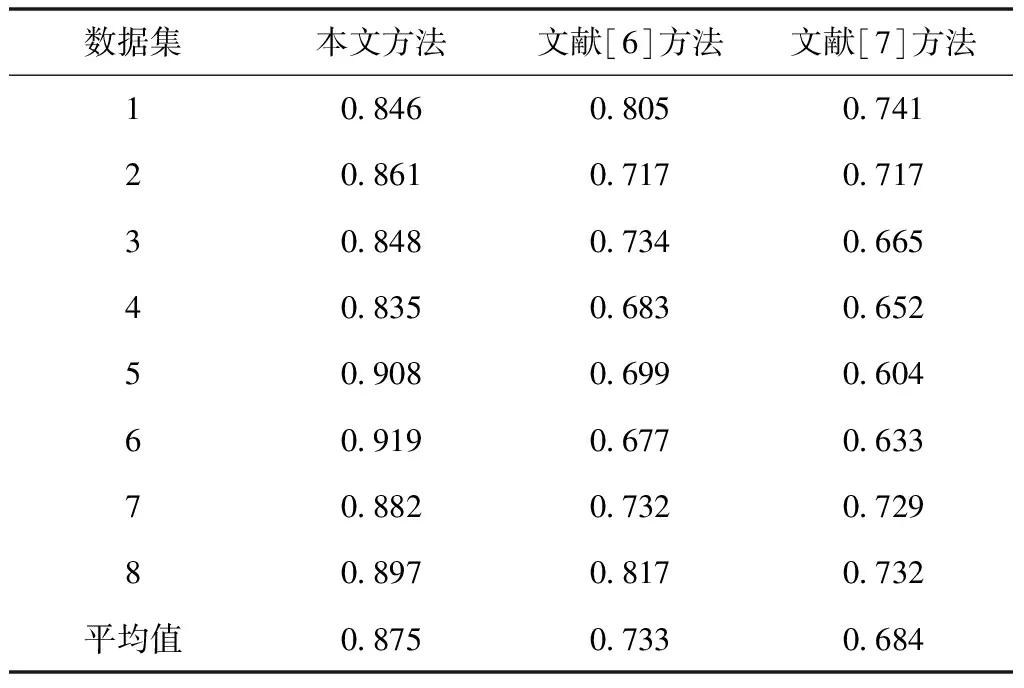
表2 三种方法的NMI值对比
通过表2可以看出,文献[6]方法和文献[7]方法在所有数据集上的平均NMI值均低于0.75,本文方法在所有数据集上的平均NMI值高达0.875,且高于文献[6]方法和文献[7]方法。文献[6]方法和文献[7]方法的NMI值波动较大,本文方法的NMI值相对平稳,说明本文方法的移动终端用户个性信息挖掘稳定性较好,不易受数据量的影响。
对比三种方法的运行时间,结果如表3所示。
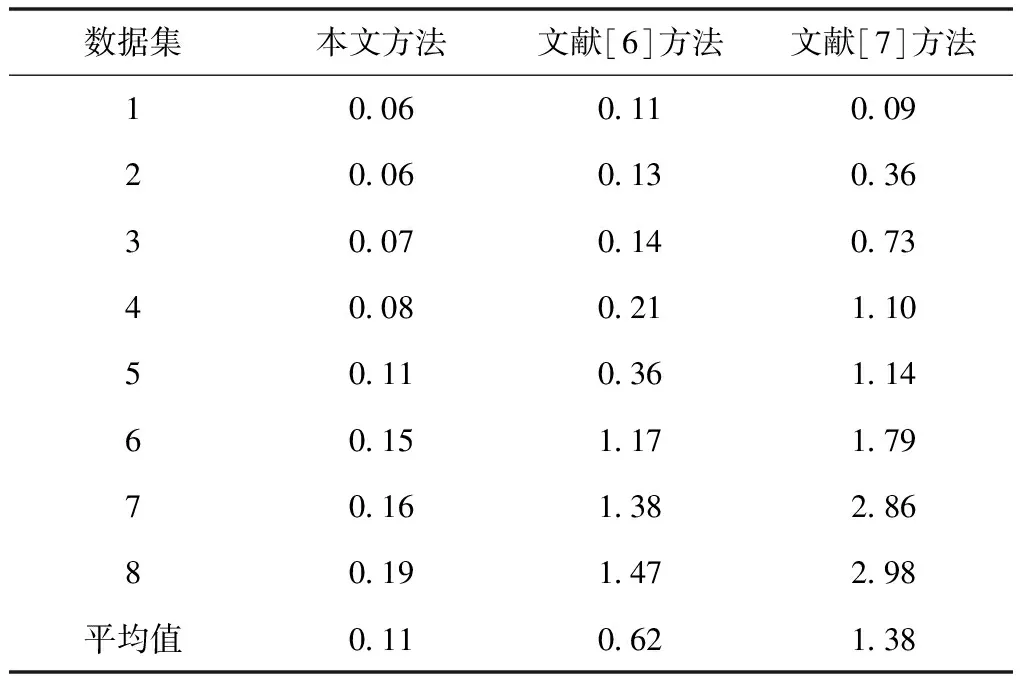
表3 三种方法的运行时间对比(单位:s)
通过表3可知,随着数据量的增大,三种方法的运行时间均有增加,其中文献[7]方法的运行时间存在明显的急剧上升状况,而本文方法在所有数据集上的运行时间都低于文献[6]方法和文献[7]方法且变化缓慢,远优于文献[6]方法和文献[7]方法,说明本文方法的移动终端用户个性信息挖掘效率高。
4 结论
针对移动终端用户个性信息标签之间存在一定的相关性,本文提出了基于标签映射的移动终端用户个性信息挖掘方法。在考虑用户个性信息词语相关性的同时引入标签映射,实现用户个性信息聚类效果的有效提升,同时通过实验验证了本文方法的移动终端用户个性信息挖掘优越性,相比其它方法,本文方法在实际移动终端用户个性信息挖掘应用中的效果更好。
