融合视觉上下文与跨通道信息的生猪脸部轻量化检测模型
2022-03-01戴百生李润泽张逸轩刘洪贵刘润泽
戴百生 ,李润泽,张逸轩,刘洪贵,刘润泽
(1 东北农业大学 电气与信息学院,哈尔滨 150030;2 农业农村部生猪养殖设施工程重点实验室,哈尔滨 150030;3 东北农业大学 动物科学技术学院,哈尔滨 150030)
0 引言
随着生猪养殖规模化程度的日益提高,养殖标准化、精细化以及养殖场管理现代化,已成为生猪养殖行业未来发展的必然趋势。实现生猪的精准养殖与规模化猪场的现代化管理,亟需对生猪的个体身份、健康状态、行为模式进行智能化的感知与理解。而生猪脸部正是区分其个体信息、反应其情绪状态与行为意图的重要区域。利用计算机视觉技术对生猪脸部进行非接触式快速、准确的自动检测,是实现生猪现代化养殖与管理的重要手段。
目前,国内外已有一些关于生猪脸部检测与识别方面的研究。Wada 等人通过手工定位并分割出生猪脸部等区域,借助人脸识别领域经典的Eigenfaces 方法,实现对生猪个体的身份识别。秦兴等人同样采用手工定位的方式,在提取出生猪脸部图像后,通过训练双线性卷积神经网络(Bilinear-CNN)对其个体身份进行识别。为了提高生猪脸部识别的实用性,Marsot 等人则采用Haar 级联分类器,对生猪脸部进行自动检测,针对检测出的生猪脸部图像区域,训练CNN模型完成对生猪个体身份的识别。燕红文等人为了提高生猪脸部定位精度,进一步将注意力机制与Tiny-YOLO模型相结合,在实现生猪脸部检测的同时,识别生猪脸部的不同姿态。Hansen 等人则利用Mask-RCNN模型,对生猪脸部区域进行检测与分割,并结合生猪眼部区域特征,对生猪情绪状态进行监测,以判断生猪是否处于焦虑状态。
虽然上述研究在生猪脸部检测方面取得了一定成功,但多数方法仍不能较好地处理复杂场景下的生猪脸部检测,难以满足不同养殖条件下生猪的实时监测需求。特别是在真实饲养环境中,生猪脸部区域通常会被养殖设施和其他个体遮挡,导致在视频画面中脸部区域显示不完整,或由于生猪自身的运动,造成脸部姿态的旋转、扭曲等视角变化的多样性。这些因素都会给生猪脸部的自动检测算法在真实应用场景下带来不利影响。
为了提高生猪目标检测的精度、速度和实用性,本文首先构建了包含限位栏和群养两种真实饲养环境下的生猪脸部检测数据集,用于生猪脸部目标检测算法的训练与测试;其次,本文基于NanoDet 架构,提出了一种融合视觉上下文与跨通道信息的生猪脸部轻量化检测。在应用轻量化特征提取骨干网络的同时,设计了Nonlocal-PAN 特征融合模块,来融合图像内部的上下文信息与跨通道信息,并采用Anchor-Free(无锚点)目标检测结构,对生猪脸部进行检测,以提高对存在遮挡、视角变化等复杂情况下的生猪目标检测的准确性、实时性和实用性。
1 试验数据
1.1 数据采集
本文构建的生猪脸部检测图像数据,采集自东北农业大学阿城实验实习基地猪场。为获取不同养殖环境下的生猪脸部图像数据,于2020 年7 月~10 月,分别选取了该猪场限位栏饲养条件下的妊娠猪舍和群养条件下的保育猪舍进行视频和图像数据采集。针对限位栏下的妊娠母猪,通过海康威视监控摄像头,固定角度拍摄5个栏位妊娠母猪共计5个批次的视频场景数据;针对群养环境下的保育猪,利用VIVO手机,非定点移动拍摄12个群养栏中约120 头保育猪图像场景数据。采集到的限位栏和群养条件下的生猪场景数据分别如图1(a)、(b)所示。

图1 不同养殖环境下生猪场景数据示例Fig.1 Illustrations of pigs in different breeding condition
1.2 数据整理
针对限位栏下妊娠母猪视频数据,对其进行视频帧解析处理,每隔5 s 进行视频帧的抽取,获得分辨率为2 560×1 440像素的图像数据;针对群养环境下保育猪图像数据,将图像尺寸统一调整分辨率为768×1 024像素。分别从两种不同养殖条件下的生猪图像中,各随机选取2 000 幅,共同构成生猪脸部检测数据集,共计4 000 幅图像数据。对数据集中所有图像,利用labelImg 图像标注工具,对图像中不同姿态、视角和大小的生猪脸部区域进行标注,并按照Microsoft COCO 目标检测数据集的标注格式,存储生猪脸部目标区域的标注信息。
为了训练和验证本文所提生猪脸部检测模型,按照9 ∶1的比例将数据集划分为训练集和测试集。其中,训练集3 600 幅,包含11 570个生猪脸部目标框;测试集400 幅,包含1 346个生猪脸部目标框。
2 检测模型
本文提出的生猪脸部检测模型总体结构如图2所示,主要由特征提取模块(Backbone 网络)、特征融合模块(Neck 网络)及目标检测模块(Head 网络)组成。特征提取模块采用轻量化的ShuffleNet v2模型,提取待检测图像特征;特征融合模块设计了Nonlocal-PAN 结构,融合图像视觉上下文及跨通道信息;目标检测模块采用轻量化的NanoDet 目标检测头,实现对生猪脸部目标的检测。

图2 生猪脸部目标检测网络结构Fig.2 Network structure of proposed pig face detection model
2.1 特征提取模块
为了使生猪脸部检测模型在保证检测精度的同时具有易在边缘计算端部署的轻量化结构,以便于该模型在生产现场中进行实际应用,本文采用轻量化的ShuffleNet v2 网络作为检测模型的特征提取模块(即Backbone 网络)。该网络提出一种通道分割(Channel Split)和通道随机混合(Channel Shuffle)机制。通过对通道分组并进行重新组合,到达混合信息的效果,实现在减少模型参数的同时提高网络特征提取性能,该网络的基本结构如图3 所示。

图3 ShuffleNet 基本结构Fig.3 Basic structure of ShuffleNet
该结构改进了自残差网络(ResNet)的残差结构。其中,图3(a)结构通过通道分割操作,将特征图的通道分成两组,左侧分支直接映射,右侧分支通过深度可分离卷积操作,确保输入通道和输出通道保持一致,以提高网络效率,再将左右两分支输出进行拼接后,使用通道随机混合操作,得到该结构的最终输出。图3(b)则通过不进行通道分割的量分支结构,实现通道数量的加倍,用以网络的降采样。整个ShuffleNet v2 即通过这些基本结构堆叠而成,在轻量化模型参数的同时,提高模型计算效率,并利用特征重用的思想提高模型特征提取能力。为了提高对不同尺寸生猪脸部目标检测的性能,本文将ShuffleNet v2 网络中体现不同尺度特征的第2、3、4阶段的输出作为后续特征融合模块的输入。
2.2 特征融合模块
为了提高对存在遮挡和视角多变的生猪脸部目标的检测性能,需要综合利用生猪躯干、环境设施等视觉上下文信息,以及生猪脸部不同视角表现出的不同模式特征,来辅助定位复杂场景下的生猪脸部区域。本文提出一种Nonlocal-PAN 结构,对提取到的特征进行上下文信息融合和通道注意力的加权,该网络的具体结构如图2 中特征融合模块所示。受YOLO-Nano模型启发,本文先在现有PAN 网络不同尺度的横向连接(lateral connection)中加入传统的SE 通道注意力块,来突出不同视角下生猪脸部表现出来的不同模式特征,进而在各尺度特征融合输出后,加入轻量化的ECA 通道注意力块。ECA 内部结构如图4 所示。
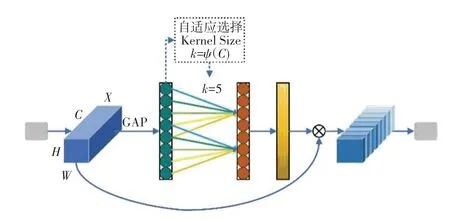
图4 ECA 注意力块结构Fig.4 Structure of ECA attention block
通过自适应选择一维卷积核大小,实现局部跨通道交互,进一步提高特征融合能力;并在最终融合特征图上利用Nonlocal 块来建模不同尺度特征图上视觉上下文信息,提高网络对存在遮挡的生猪脸部特征提取能力,Nonlocal 块结构如图5 所示,其计算过程如下:

图5 Nonlocal 块结构Fig.5 Structure of nonlocal block

式中,为输入特征图;、是位置索引;为与输入特征图大小一致的经过非局部操作的输出;为计算任意两位置间的特征相似性度量函数;为任意位置处的特征表示函数;()为规范化因子; W为权重矩阵;(x)可通过W x形式计算获得。在本文工作中,相似性度量函数选用如下形式进行计算:
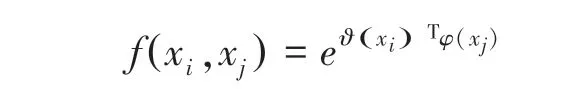
式中,(x)和(x) 可分别通过W x和W x计算获得。
2.3 目标检测模块
基于前述特征融合模块输出的3个不同尺度上的特征图,采用轻量化的NanoDet 检测模块完成对生猪脸部区域的检测。该模块主要通过ATSS机制,自动选择正负样本进行训练,并引入Generalized focal loss和GIoU loss,对生猪脸部区域进行类别预测和位置回归,模型总体损失函数计算方式如下:

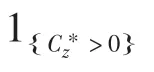
3 实验结果与分析
3.1 模型训练
本文使用Pytorch 框架进行实验,采用随机梯度下降方法(SGD)作为模型训练的优化器,批处理样本数(Batch size)为96,迭代次数(Epoch)为150,初始学习率(Learning rate)为0.14,并根据Epoch 适时调整学习率,调整因子设置为0.1,网络输入图像尺寸统一调整为512×512 像素。
图6 给出了训练集上的模型损失函数曲线,从中可以看出,在生猪脸部目标检测训练集上,本文所采用的损失函数均能够有效收敛。
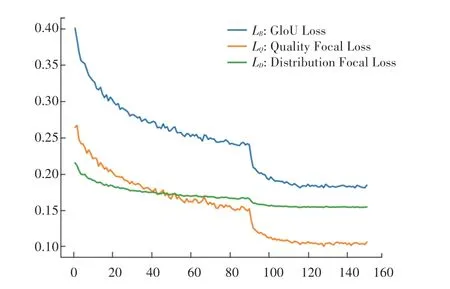
图6 训练集上不同损失函数收敛曲线Fig.6 Convergence curves of different model loss on training set
3.2 评价指标
考虑本文主要针对单一类别的生猪脸部目标进行检测,故采用该单一类别在不同交并比()水平下的平均精度(,)、平均召回率(,)以及模型大小作为评价本文生猪脸部检测模型的性能指标,其中:

式中,为精度;为召回率;为预测框与真实目标框()间的交并比()值。
3.3 结果分析
表1 给出了本文检测模型与轻量化NanoDet 检测模型在生猪脸部测试集上的检测性能对比结果。在400 张测试图像共计1 346个生猪脸部目标的测试数据上,本文模型在为0.5、0.75和0.50:0.95水平下,分别获得了96.98%、81.16%和67.44%的平均精度,并取得了最大检测目标个数为100 水平下72.82%的平均召回率。相较于NanoDet模型,本文模型在模型大小仅提升0.5 MB的前提下,在各指标上均有一定的提高。在增加Nonlocal-PAN 特征融合模块输入与输出特征通道数(取192)时,模型检测性能可以得到进一步提升,但随之模型大小也有相对提升。
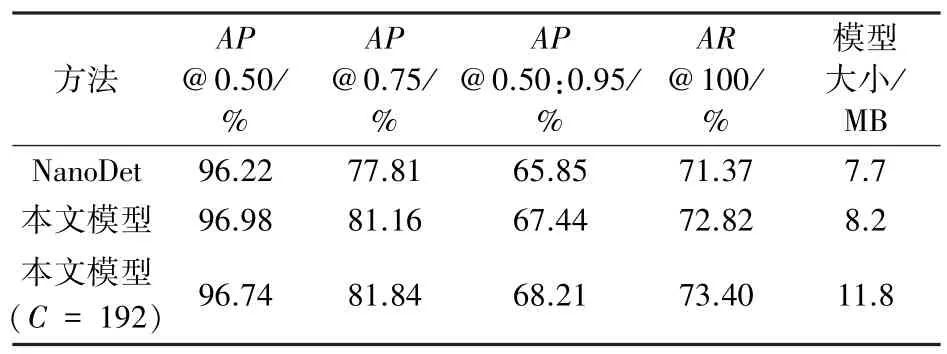
表1 本文模型与轻量化NanoDet模型对生猪脸部检测性能的对比Tab.1 Comparison of pig face detection performance between proposed model and NanoDet model
表2 给出本文模型和文献[5]中使用的Tiny-YOLO模型在生猪脸部检测时的不同性能对比。相较于文献[5]所用数据集,本文数据中存在遮挡和视角变化情况更为突出,且在模型大小更小的情况下,本文模型仍然取得了较为优势的生猪脸部检测性能。

表2 不同生猪脸部检测模型性能对比Tab.2 Comparison of different pig face detection models
本文模型在两种不同养殖环景下生猪脸部目标检测结果如图7 所示。从图中可以看出,对于存在遮挡、视角变化的生猪脸部,本文模型在不同养殖环境下都能较为有效的检测出其位置。

图7 不同养殖环境下生猪脸部目标检测结果Fig.7 Pig face detection results of different breeding condition
4 结束语
本文提出了一种轻量化的生猪脸部目标检测模型,通过在特征融合网络PAN 结构中引入Nonlocal上下文建模与通道注意力机制,融合了图像中视觉上下文信息与跨通道信息,提高了对存在遮挡与视角变化的生猪脸部目标的检测性能。与现有轻量化目标检测模型相比,在不同水平下,本文所提模型的平均精度均有所提升,且与现有生猪脸部检测模型相比,本文所提模型在具有更小模型大小的同时,提升了模型检测的性能。实验结果表明本文模型具有良好的边缘计算端支持特性和实用性。未来工作将改进损失函数的设计,进一步提高对密集遮挡环境下的生猪脸部目标检测性能。
