密集人群人脸检测方法研究
2022-03-01秦学赵耀
王 腾,秦学,赵耀
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 引言
人脸检测是机器视觉领域研究的经典问题,其目标是通过算法找出图像中人脸的相关信息。人脸检测算法研究可以分为基于传统方法的检测和基于深度学习的检测两个阶段。
基于传统的方法以Adaboost 框架和可变形组件模型(Deformable Part Model,DPM)为代表,Adaboost 采用多个弱分类器,构建出精度更好的强分类器,再通过多次迭代寻求最优分类来检测人脸;DPM 方法采用融合的梯度直方图提取特征,再用训练好的SVM 分类。这些方法在目标区域时间效率低,且对于旋转、拉伸、视角变化等检测效果较差,很难满足密集人群中人脸检测需求。
基于深度学习的检测方法采用卷积神经网络等技术,在检测过程中将更多的人脸特征信息用于密集人群中多目标多尺度的人脸检测,在大部分复杂场景中都表现出了较好的适应性。Li 等提出级联卷积的神经网络人脸检测方法(CascadeCNN),一定程度上解决了传统方法在非限制环境中对光照等敏感的问题;YANG 等为解决人脸检测中出现的遮挡问题,提出了Faceness-Net,该算法通过检测头发、五官等人脸关键部分生成人脸部件图,由生成的部件推理出人脸候选区域,得到了较高的召回率,最后采用CNN 网络对人脸的分类和边界回归进行进一步训练,提升人脸的检测效果。
人脸检测属于通用目标检测二分类的一种。随着目标检测中模型性能的提升,相关学者开始将通用目标检测算法用于人脸检测,如Jiang 等将通用目标检测算法Faster R-CNN 应用于小人脸检测;Hu 等提出了一种基于中心凹描述符的小尺寸人脸检测方法HR,该方法结合FPN 特征金字塔多层信息,在小人脸的检测上取得了极佳的效果。上述目标检测方法在准确率上取得了很好的效果,但这些方法的检测速度欠佳,为了提升算法的检测速度,相关学者又提出了以SSD和YOLO 为代表的基于回归的端到端的单步目标检测算法,此类算法具有更快的检测速度,满足实时检测的需要。由于人脸的远近、摄像的角度以及人脸的大小导致密集人群下的人脸存在多尺度问题,而YOLOv3 采用类似特征金字塔FPN 进行多尺度预测,相比单步目标检测SSD 算法在精度和速度上都要优于后者。综上,本文选取YOLOv3模型为基础进行实验。
对于当前YOLOv3模型的改进,Lawal 等将YOLOv3模型与密集卷积网络结构结合,实现了更好的特征重用,在遮挡的水果检测中取得了很好的检测效果;Li 等在YOLOv3 基础上引入多种注意力机制,以此全局和局部信息选择性地强调有用的特征信息,同时抑制无用的特征,在Pascal和KITTI数据集上取得了较高的检测精度。
为了提高YOLOv3 网络对密集人群下人脸的召回率和检测的准确率,本文对YOLOv3的网络结构进行改进和优化。首先,在小型预测尺度和中型预测尺度之间加入改进的密集卷积模块,实现在增强网络的特征传播的同时,保留浅层信息的完整性,从而达到降低人脸遮挡影响,提高人脸的检测效果;其次,为了丰富小型预测尺度和中型预测尺度两个特征图的语义信息,采用从原网络的4 倍下采样特征图输出,将输出特征图进行改进的ResNet 残差模块操作,对此特征图进行分流操作,一处与26×26 特征图上采样处进行张量堆叠,另一处采用2 倍下采样后与13×13 特征图上采样处进行张量拼接,最终实现更浅层网络与浅层网络和深层网络的语义信息的特征融合,同时通过改进的ResNet 残差模块操作获得更多的感受野,从而使网络获得更多的人脸特征信息,提高模型的检测效果;最后,利用K-means++算法选择更适合模型先验框,提高模型对人脸的召回率。
1 网络结构改进
与YOLOv2 网络相比,YOLOv3 网络具有两大优势。其一,为了进一步加强目标在网络中的表征能力,YOLOv3 采用DarkNet53 作为主干网络结构,如图1 所示。DarkNet53 借鉴ResNet 中的残差思想,通过引入残差单元来增加网络的层数,避免梯度消失,进而提高网络的检测性能,其残差单元结构如图2(a)和图2(b)所示,图2(c)为残差块;其二,针对YOLOv1和YOLOv2 小物体检测能力较弱的问题,YOLOv3 采用类似(FPN)特征金字塔和上采样的思想进行多尺度融合,FPN 融合多尺度特征的特征方法通过从上到下的路径对深层网络的特征图进行上采样操作,使其跟浅层网络特征图大小一致,通过横向连接将包含不同特征信息的特征图融合,实现丰富预测特征图的浅层的位置信息和深层的语义信息的效果。
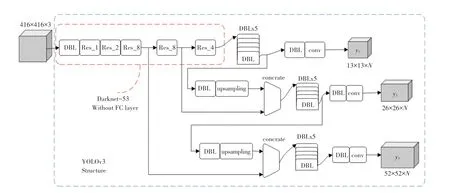
图1 YOLOv3 可视化结构图Fig.1 YOLOv3 visual structure diagram

图2 DarkNet 结构单元Fig.2 Darknet structural unit
1.1 改进网络模型
真实场景下的人脸背景环境十分复杂,太阳光线角度变化、天气变化、人脸的相互遮挡、以及姿态等问题都能影响到人脸的检测效果。为了更好地降低背景干扰,本文利用改进的YOLOv3 网络,在特征提取和尺度融合部分进行相应的优化来对人脸进行检测,改进的YOLOv3 网络结构如图3 所示。

图3 改进的YOLOv3 网络结构Fig.3 Improved yolov3 network structure
1.2 改进的密集卷积网络
密集卷积网络(DenseNet)是Huang 等人提出的一种不同于ResNet的网络特征加强,避免梯度消失的方法。该方法借鉴了ResNet 与GoogLeNet 思想,通过特征重用和旁路设置将模块内任一卷积层的输入,包含前面所有卷积层的输出,使特征得到充分复用的同时防止出现特征消失,从而提高网络的性能,其结构如图4 所示。

图4 DenseNet 网络Fig.4 DeseNet network
为了降低密集人群中遮挡人脸的影响,本文在26×26 预测尺度(图3 中第二个Res_8)和52×52 预测尺度(图3 中第一个Res_8)中间引入改进的密集卷积(DenseNet)网络,将前面的所有特征层作为后一层网络的输入,使低分辨率特征和高分辨率的特征都能在后面网络进行学习,从而实现融合的效果;同时,从密集卷积开始处引入残差,在密集卷积网络结束处进行张量叠加。通过引入残差思想,不仅可以结合密集卷积网络加强特征传播的优势,还能从早期的人脸特征图中获得更细粒度的信息。改进的密集卷积网络结构如图5 所示,其中改进的密集卷积网络res_d 由6个密集卷积单元、张量拼接、DBL 以及张量叠加组成,密集卷积单元由张量拼接、DBL_1X1、DBL_3×3组成,如图6 所示。DBL_1X1 单元由步长为1 大小为1×1的卷积单元层、批归一化(batch normalization)和激活函数(leak relu)组成,DBL_3×3 由步长为1 大小为3×3的卷积单元层、批归一化(batch normalization)和激活函数(leak relu)组成。
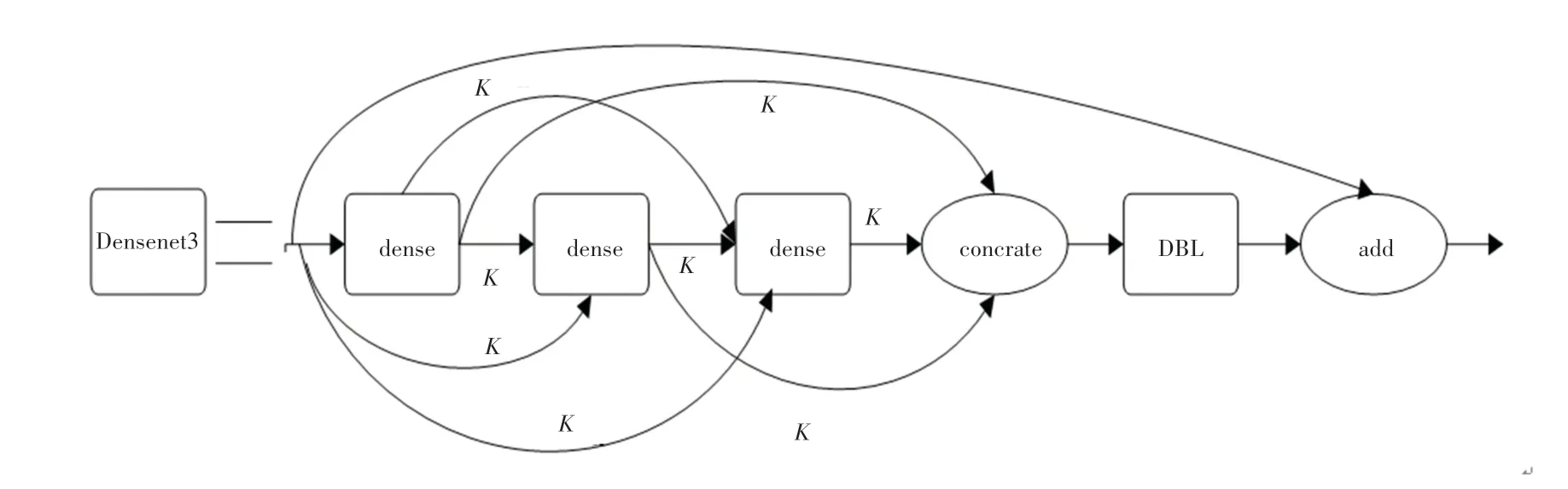
图5 改进的DenseNet 网络Fig.5 Improved DenseNet network
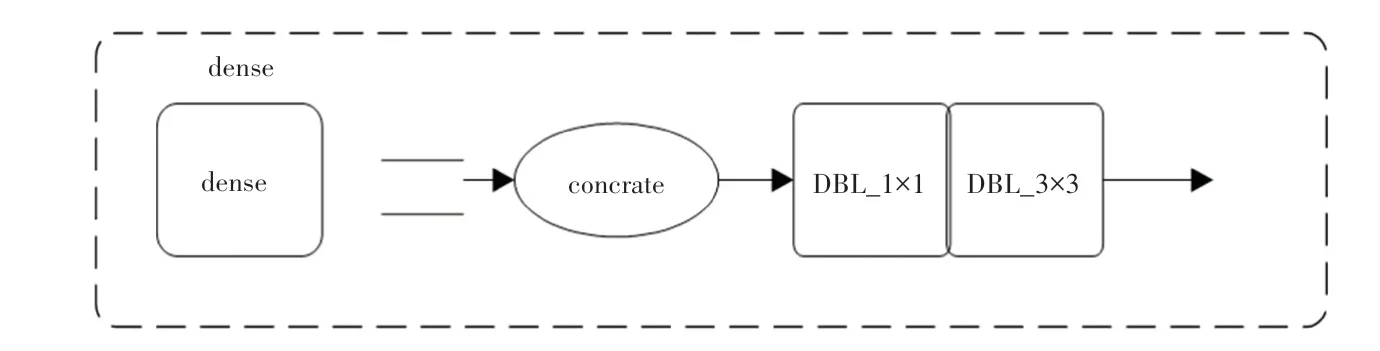
图6 密集卷积单元Fig.6 Dense convolution unit
1.3 改进的ResNet 残差模块
由于小型人脸具有小目标物体的特性,即所占像素少,覆盖面积小、包含信息少等基本特点。在密集人群下小型人脸比常规人脸相比可利用的像素较少,难以提取到较好的特征,而且随着网络层数的增加,小型人脸的特征信息与位置信息也逐渐丢失,难以被网络检测。要提升小型人脸检测性能,就需要将深层语义信息与浅层表征信息相结合,而YOLOv3的多尺度预测采用类似FPN 这种融合多尺度特征的方法,通过从上到下的路径,对深层网络的特征图进行上采样操作,并采用横向连接的方式,使深层特征图和浅层特征图能够堆叠,从而达到将高层语义信息和低层语义信息融合,丰富不同尺度特征图语义信息的效果。为了使小型物体预测尺度获得更丰富的小型人脸特征语义信息,从而提高人脸检测性能,YOLOv3 网络主要是在52×52 大小的预测尺度上进行检测。本文采用从更浅层网络第二个残差块即特征图大小104×104 处引出,用步长为2的卷积下采样后进行改进的ResNet 残差模块操作,得到的特征图分流,一处与小型人脸预测尺度和26×26 特征图上采样处进行特征融合,另一处进行一次步长为2 卷积大小为3×3的下采样,与中型人脸预测尺度和13×13 特征图上采样处进行特征融合,使更浅层语义信息、浅层语义信息和高层语义信息进行融合,从而丰富中小型人脸预测尺度的特征语义信息,加强小型人脸的特征,最终提高小型人脸的检测性能。
本文改进的ResNet 残差结构采用类似Res2Net卷积方式来代替ResNet 中3×3 卷积,不同的是经1×1 卷积后的特征子图没有进行通道分割,而是保留其通道信息的完整性,每个特征子图的输入,为第一个卷积特征子图和上一个3×3 特征子图对应的卷积的输出之和,如果该特征子图没有上一个3×3 特征子图,那该3×3 卷积特征子图的输入即为第一个卷积特征子图的输出,将2个通道相同、感受野不同的3×3 特征图进行融合,显然改进后的ResNet 网络中第一个特征子图下所有的3×3 卷积均可利用之前的特征,并且在保留了原通道信息的完整性前提下获得更多的感受野,改进后ResNet 残差模块作为中小型人脸预测尺度的输入,将使得网络的整体语义表征能力更加出色,特征表现力更强。ResNet、Res2Net、改进的ResNet的基本结构,改进的ResNet模块如图7(a)~图7(d)所示。
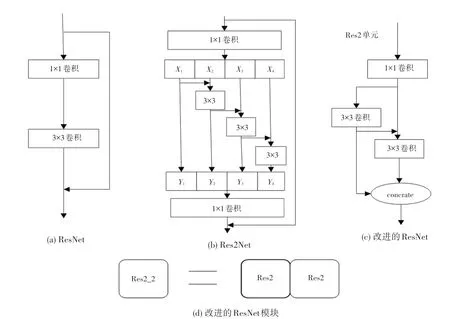
图7 残差网络和改进的ResNet 网络Fig.7 Residual network and improved ResNet network
1.4 Kmeans++聚类算法
本文采用香港大学的WIDER FACE 人脸数据集,该数据集存在模糊度、表情、曝光、遮挡以及姿态等问题,且在图片中人脸数据标注框离散程度较高,多为长方形。而原YOLOv3模型为了提高目标检测的速度和精度引入了先验框,并在图像上预设好了不同大小和不同长宽比。由于数据集的不同,标注框的大小也不同。根据网络检测机制,先验框的大小选取对模型的识别精度有直接的关系。因此,为了得到更准确的预测目标,需要对YOLOv3模型先验框重新聚类,但K-means 随机初始化聚类结果不稳定,会导致先验框聚类结果差别较大,故采用Kmeans++算法对数据集中人脸的框标签进行聚类,具体过程如下:
(1)从数据集的人脸框标签中随机选择一个作为样本的聚类中心;
(2)计算数据集人脸框标签与当前已有类聚类中心的最短距离();
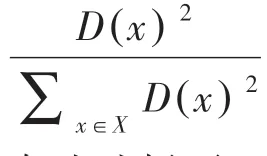
(4)重复步骤(2)、步骤(3),直到选出个聚类中心,使用K-means 算法找到聚类中心。
通过K-means++聚类得到先验框。
2 实验结果与分析
本文在Windows10 操作系统下完成软件平台的搭建和实验,GPU 选用NVIDIA GeForce 3060,软件工具:prcharm2021.1.3 专业版、Anaconda3、python 版本3.6、Pytorch-gpu(≥1.6.0)。
2.1 数据集的选择
本文在WIDER FACE 数据集上进行训练和测试,该数据集是当前已知人脸数据集中人脸数量最多、检测环境最为复杂数据集之一,其人脸数据集图像3 万多张,一半可用于训练和验证模型,另一半用于对模型性能的测试,所有标注人脸数图像接近40万张,平均每一张图像就有13 张人脸,符合本文数据集的选取要求。
考虑到WIDER FACE 数据集中测试模型的数据集未公开其标注的标签,故本文选取该数据集用于训练和测试。选取的人脸数据集经预处理转换成VOC 格式的局部数据集,共包含16 102 张图片,包含标注的人脸有196 144 张,然后将训练集和测试集以9:1的比例进行划分,得到训练集14 491 张图像,包含174 489 张人脸;测试集1 611 张图像,包含21 655 张人脸。由于数据集中的人脸种类齐全,且存在尺寸、遮挡、光照、表情等多种影响因素,比较符合密集人群场景下人脸的复杂环境,同时可以更好地验证模型的泛化性。
2.2 评价指标
本文采用准确率、召回率、平均准确度均值以及值等指标对模型的性能进行评价,同时还考虑模型的实时性。准确率、召回率及1值,如式(1)式(3)。
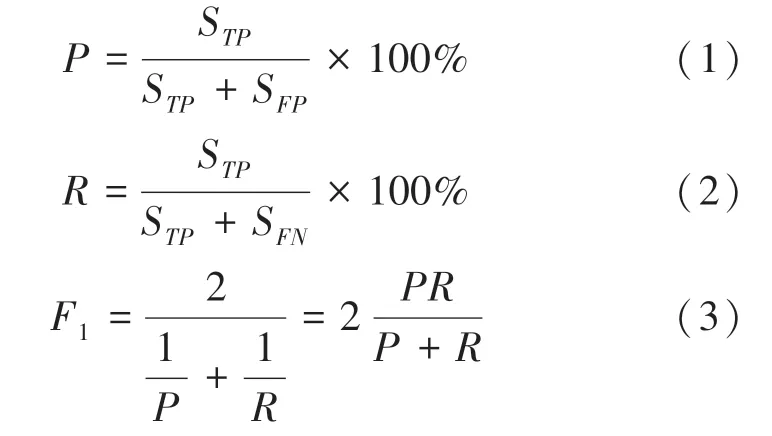
其中,表示准确率,即本次预测正确的人脸数占预测人脸数的百分比;S表示测试的所有数据中标注人脸被正确预测的个数;S表示测试的所有数据中不是标注人脸而被预测为人脸的个数; S +S为本次所有的预测为人脸的数据;表示人脸的召回率,即本次预测正确的人脸数占测试数据中标注人脸数的百分比,也就是在测试数据中的标注人脸数被模型成功预测的个数;S表示本次预测中测试数据中标注人脸未被正确预测的个数;S+S为本次测试数据中的标注人脸的个数;表示准确率和召回率的调和均值,其值为[0,1],值越接近1,模型性能越好。
召回率和准确率往往相互制约,召回率提升,准确率就会下降,反之亦然。为了更好地权衡召回率和准确率,本文引入人脸的即曲线,其面积为的值,如式(4)所示。
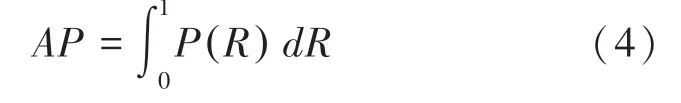
(mean average precision)表示人脸的预测平均精度的均值,由于在本实验中只有人脸一个类别,这里的值就等于值。是当前目标检测中最重要的模型衡量指标之一,公式(5)。
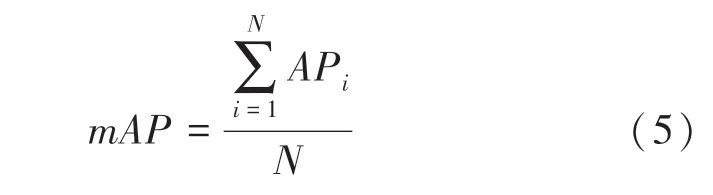
2.3 实验结果及分析
2.3.1 训练结果
本次实验设置了初始学习率为1×e,用于前50个的训练,后450个的起始学习率为2×e,模型共训练了500个。为了加快模型训练人脸数据集的进程,训练采用迁移学习的方式,将训练过数据集的权重作为本次实验的预训练权重,数据集中包含person 这一类具有的人脸特征,能够帮助模型更快收敛。同时,为了进一步加快网络学习人脸的特征,本实验冻结了除最后一层分类层外的所有层,从而加快人脸的训练速度。改进前后YOLOv3的损失函数如图8 所示,前50个采用了冻结的主干提取层的方式,其模型损失随迭代次数的增加,YOLOv3和改进后的YOLOv3模型损失下降明显;从50个到150个,两个网络损失依旧下降,但较前50个缓;两个网络在后350个中损失下降平缓,基本保持不变,原YOLOv3 网络的最终损失维持在0.58 左右,改进后的YOLOv3 网络的最终损失基本维持在0.31 左右,可见改进后的网络的收敛速度更快,损失值更小。
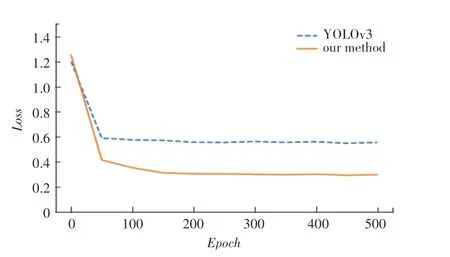
图8 改进前后YOLOv3模型的损失函数Fig.8 Loss function of yolov3 model before and after improvement
2.3.2 算法检测指标分析
本文对数据集进行筛选,选取密集小人脸的图像200 张用于模型性能的测试,测试集包含6 468张人脸图像,将实验测试的阈值设定为0.5。
其算法检测指标对比见表1。与原网络相比,改进后的YOLOv3 网络检测速度下降了0.005 s,检测准确率由75.82%提高到80.84%,召回率由72.16%提高到74.18%,1值由74%提高到77%,值由72.54%提高到75.11%,表明改进后YOLOv3 网络对密集人群的人脸检测性能有所提升。
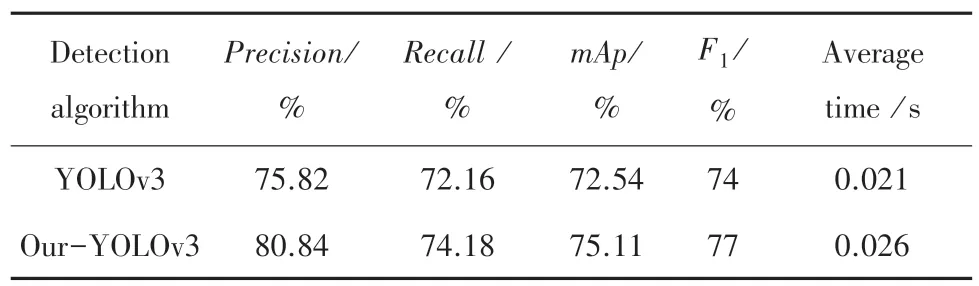
表1 算法检测指标对比Tab.1 Comparison of algorithm detection indexes
原网络与改进的YOLOv3 网络在WIDER FACE数据集上平均准确率如图9 所示,改进后的YOLOv3网络比原网络的平均准确率高了2.57%,说明引入残差密集卷积网络和改进ResNet的YOLOv3 在人脸的召回率和准确率上都有一定的提升。
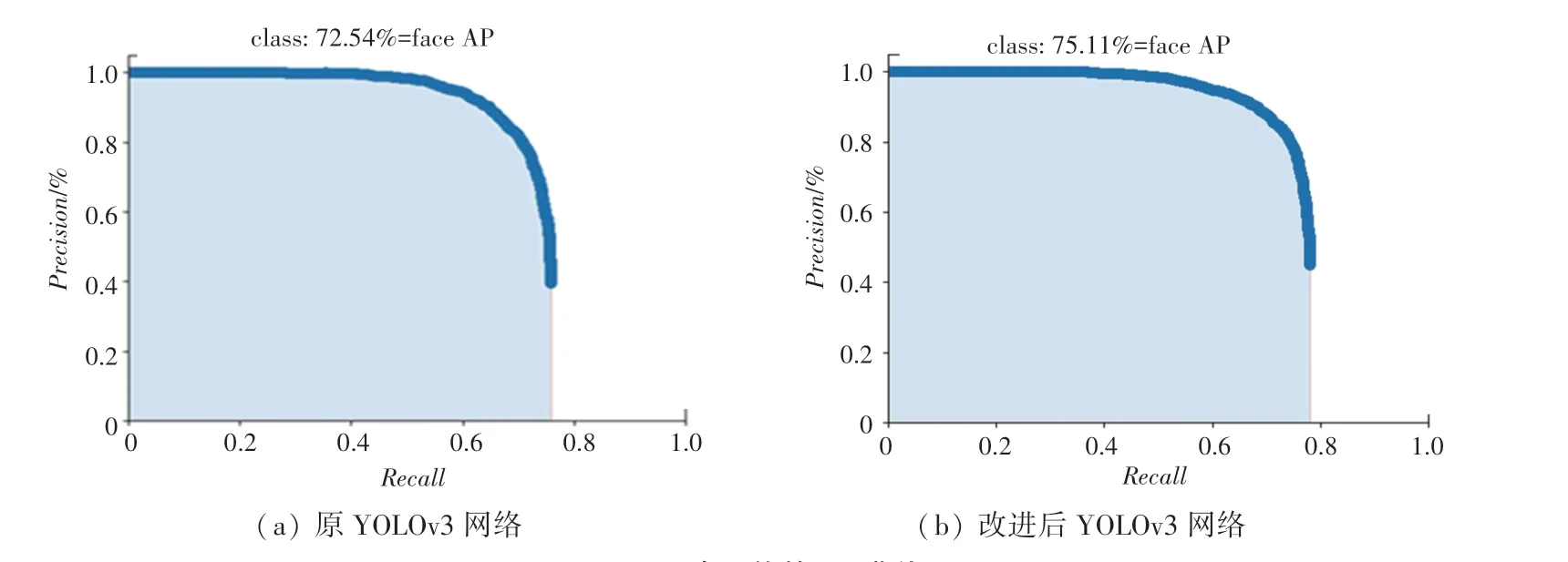
图9 两个网络的AP 曲线Fig.9 AP curve of two networks
2.3.3 检测结果分析
YOLOv3 算法与改进YOLOv3 对小人脸检测的检测结果如图10 所示,对比可知,经过改进的YOLOv3 网络对密集人群中的小人脸检测检测性能更好。YOLOv3 算法与改进YOLOv3 对遮挡人脸检测的检测结果如图11 所示,对比表明了改进的YOLOv3 可以在分布密集、姿态多样、存在面部遮挡的多样化场景下学习到更多的人脸细节特征,从而具有更高的检测精度和人脸召回率。

图10 YOLOv3 算法与改进YOLOv3 对小人脸检测的检测结果Fig.10 YOLOv3 algorithm and improved YOLOv3 detection results for small face detection

图11 YOLOv3 算法与改进YOLOv3 对遮挡人脸检测的检测结果Fig.11 YOLOv3 algorithm and improved YOLOv3 face detection results of occluded face detection
3 结束语
针对密集人群下人脸检测任务中人脸的尺度变化、小人脸、不同程度遮挡、光照强弱差异等问题,本文对YOLOv3 网络进行了改进。首先,在浅层网络特征和深层网络特征中添加改进的残差密集卷积网络结构,这样在结合上下文信息的同时能够加强人脸特征传播,防止人脸特征的消失,使网络学习到更多人脸特征,从而降低人脸在遮挡情况下的影响,提高模型人脸检测效果;其次,对于密集人群中的中、小人脸检测,本文采用了从更浅层引入更具有位置信息的人脸特征,进行改进的ResNet 操作,获得更多的感受野同时再与不同预测尺度特征图融合,使更浅层、浅层、深层网络的语义信息进行融合,从而达到丰富不同预测尺度特征图人脸特征信息的作用,提高密集人群中小人脸的精度;最后,利用Kmeans++算法选择适合模型的先验框,提升模型对人脸的召回率。通过对WIDER FACE 数据集实验验证,本文采用改进算法对密集人群中人脸的多尺度、遮挡、姿态变化、以及小人脸有良好效果。但改进后的YOLOv3 算法对于曝光模糊的人脸图像检测效果一般,改进的YOLOv3 算法如果未来应用于工程实践,模型计算量、精确率、网络结构将是其主要研究方向。
