大数据分类算法在物料编码的应用
2022-02-28韩亚红
韩亚红

【摘要】物料编码是ERP的基础,通过大数据分类算法,对物料进行自动分类,提高物料编码管理工作效率。本文基于Python实现物料的自动分类。
【关键词】物料编码、物料分类、大数据、Python
1引言
物料是在ERP的基础,物料编码是以简短的文字、符合或数字、号码来代表物料、品名、规格或类别等其他有关事项的一种管理工具。在编码过程中,需要对物料进行分类,并给出相应的编码,由于不同员工对物料分类有不同的理解,出错率也时常发生。实验表明,通过大数据技术快速对物料进行分类,可节约人力,避免人工分类带来的错误率高、效率低等诸多问题。
本文基于Python语言,结合第三方库jieba和panda库,实现物料的自动分类。
2物料分类流程及相关技术
物料分类实际是短中文文本分类问题,分类问题的主要目标是确定新数据所属的类别。分类是给定一堆样本数据,以及这些数据所属的类别标签,通过算法来预测新数据的类別。
物料分类步骤主要有1.预处理(中文文本分词)2. 关键词(对样本数据进行词频统计,获取关键词)3、分类器。
2.1物料预处理
对中文文本进行分类,主要是分词。文本分词采用结巴分词(jieba)库实现,结巴分词有三种分词模式:全模式、精确模式和搜索引擎模式。针对物料名称短而精的特点,本文采用了精确模式对物料进行分词。代码和结果如下:
import jieba
import pandas as pd
txt=pd.read_excel(“C:\\Users\\shiyan.xlsx”)
for name in txt[“名称”]:
words=jieba.lcut(name)
print(words)
[‘不锈钢’, ‘清洁剂’][‘防爆’, ‘内燃’, ‘叉车’]
2.2关键词
物料编码原先设定为按照类别、大类、中类、小类规则进行人工编码,所以样本数据已经有了分类,在已有的类别码基础上利用结巴分词库和extract_tags函数获取此类别的关键词。
实现思路为:TF-IDF文本关键词抽取方法流程
(1)利用EXCEL将同一分类下的物料进行拼接,形成文本D。
(2)对给定的文本D进行分词,磁性标注和去除停用词等数据预处理操作,获得n个候选关键词D=【t1,t2….tn】
(3)计算词语ti在文本D中词频
(4)计算词语ti在整个语料的IDF=log(Dn/(Dt+1))
(5)计算获取词语ti的TF-IDF
(6)对关键词计算结果进行倒序排列,获得排名前的TOPN个词汇作为文本关键词。
利用jieba. analyse库中extract_tags实现,代码和结果如下:
txt=pd.read_excel("C:\\Users\\5510387hyh\\Desktop\\物料分类.xlsx")
for name in txt["名称"]:
word=jieba.analyse.extract_tags(name,topK=3)
物料类别 名称 关键词
420350700 砂轮磨头砂轮磨头磨头磨头磨削工具磨削工具百洁布磨头钨钢滚磨刀钨钢滚磨刀磨削针具金刚石磨头 ['磨头', '磨削', '钨钢']
2.3文本分类
常用的分类算法:K-最近邻发KNN,决策树分类法,贝叶斯分类算法,支持向量机的分类器,神经网络,模糊分类法等。本文采用贝叶斯分类器进行分类,贝叶斯分类的思想:单独考量每一维度特征被分类的条件概率,然后综合这些概率对所在的特征向量做出分类。首先利用CountVectorizer将文本关键词进行向量化,再运用贝叶斯分类算法进行分类,代码如下:
vec=CountVectorizer()
x_train=vec.fit_transform(train_features)
clf=MultinomialNB(alpha=0.001).fit(x_train,train_labels)
predicted_labels=clf.predict(x_test)
3实验和结果
实验采用已有的物料库中的物料作为训练和测试数据,该数据包含1407个类别,总共11000条物料,其中训练样本10000条物料,测试样本1000条物料。
准确率和查全率作为物料分类的评价标准。准确率计算公式为分类正确的物料条数/已分类的物料条数。查全率计算公式为分类正确的物料条数/测试样本的物料条数。
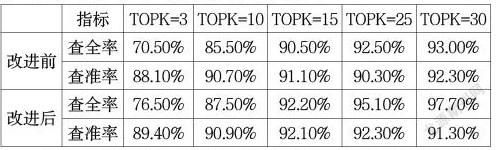
在实验中发现,由于物料编码的特殊性,如果某一类中包含多个不同名称,会导致名称出现次数少的,自动分类出错。在此基础上,改进实验思路:将测试数据进行物料名称唯一性处理,再进行物料分类。实验过程中发现,利用extract_tags去掉停用词获取关键词时,会将单个字的词过滤掉,比如“毯”,“带”等关键字,这大大降低了检索的正确性,在此基础上将单个词添加到关键词中去大大增加了分类的准确性。
从上图可以看出,关键词取得少会导致查全率降低,关键词取过多会导致查准率降低,总体上利用贝叶斯分类器分类,选择合适的关键词个数,可以取得较好的查全率和查准率。
4结语
本文利用Excel、Python语言以及jieba库,实现了物料的自动分类,在实验过程中发现,物料名称的简洁性以及标准性对物料分类结果有很大的影响,尽量减少修饰性词语。由于jieba库的强大功能,物料分类过程实现比较简单,分类效果良好,大大减少了编码的工作量,提高了物料分类的准确性。
参考文献:
[1]孙强,李建华,李生红,基于Python的文本分类系统开发研究[J].计算机应用与软件,2011,3.13-14
[2]鲍仲平,企业信息的编码和描述[J].电子标准化与质量,1995,3,37-40
[3]徐易,基于短文本的分类算法研究[J].上海交通大学,2010.
