基于机器学习的汽油加氢裂化辛烷值损失预测和脱硫优化
2022-02-25龙梦舒闵超赵伟张馨慧代博仁
龙梦舒, 闵超, 赵伟, 张馨慧, 代博仁
(1.西南石油大学理学院, 成都 610000; 2.西南石油大学人工智能研究院, 成都 610500; 3.胜利油田勘探开发研究院, 东营 257000)
汽油是近千种物质的混合物,在汽油炼制过程中,辛烷值作为衡量汽油防爆性好坏的重要指标,是炼油厂控制生产质量、调和工艺等过程的重要参数[1]。辛烷值含量越高,汽油的防爆能力就越强,压缩比也就越高[2]。为了获得防爆能力更高、更安全的汽油产品,就需要降低汽油在加氢脱硫工艺中的辛烷值损失,在硫含量达标的前提下,尽可能地使辛烷值含量达到最高,以此来获得高质量的汽油。
中国催化裂化工艺中的加氢脱硫技术出现较晚,国际竞争力相对还不足。目前中国对于降低汽油炼制过程中的辛烷值损失主要有两种方法:一是调整环境变量,如控制反应温度、氢油比等;二是优化设备仪器,使用更先进的仪器也能对降低汽油辛烷值有辅助作用[3-4]。目前,许多研究都试图利用加氢裂化的物理化学反应机理的角度来分析辛烷值损失[5]。但是,原油组分复杂,这类方法很难准确把握相关机理;另一方面,加氢裂化实验和模拟复杂,费时费力。随着中国石化企业信息化、自动化程度的不断加深,在汽油炼化过程上积累了大量数据,为利用大数据方法研究辛烷值损失预测提供了可能,绕开机理分析纯利用数据分析获得辛烷值损失预测的主要手段是机器学习,Lu等[6]将主成分分析过滤方法与传统的随机森林算法结合,预测了汽油产品的辛烷值含量。Chen等[7]在随机森林过滤方法的基础上引入长短期记忆网络,建立了变量与产品良率的非线性映射关系。Li等[8]基于变量之间的非线性关系,采用BP(back propagation)神经网络预测辛烷值并取得了良好的预测效果。
为了在更大程度上降低汽油产品的辛烷值损失,提高汽油质量并降低成本以此提升市场竞争力,构建出准确率更高的辛烷值损失预测模型是很有必要的。在已有特征选择方法与预测模型的基础上,综合考虑炼油工艺的复杂性及控制变量的非线性,利用实际炼油作业过程数据,通过四种降维分析方法挑选出最具有代表性、独立性、和合理性的主要变量,从数据驱动的角度,基于逻辑回归、支持向量机等机器学习算法建立有效的辛烷值损失预测模型,并在此基础上构建硫含量优化模型,利用遗传算法求解,求解各个参数的最优操作范围,在辛烷值损失尽可能小的情况下,将硫含量降到最低。
1 数据处理
1.1 数据来源及整理思路
S_Zorb工艺是一项生产低成本清洁汽油的技术,可将汽油含硫量降至超低标准,并同时保护汽油的辛烷值[9-10]。S_Zorb工艺能使汽油的质量得到提升,并集加氢、重整与催化裂化技术于一体,采取临氢、流化催化裂化及再生吸附循环的方法,以含硫汽油为原料,在反应器的临氢环境中,使得原料汽油与吸附剂发生脱硫反应,以较小的辛烷值损失来获取较好的脱硫效果[11]。
根据某石化企业2017—2020年这四年中S_Zorb装置积累的运行数据,从中提取出了325个数据样本,并按日期顺序从1开始依次编号,其中第285号和313号样本提供了当天每个时刻的完整数据。因此,第285号和313号样本,需要先对基础数据进行基本的预加工,再填入样本总表。对于325个总样本需先采用最大最小限幅方法筛掉不合理的值,再用拉依达准则(3σ准则)方法去除部分异常值,最后填补缺失值。由于两个样本的原始数据的范围均符合企业所提供的变量范围,且数据并未出现空值,因此直接进行异常值处理。
1.2 数据预处理及整合

(1)
通过拉依达准则方法检测到285样本和313样本数据存在部分异常值,先将其剔除。剔除掉异常数据之后,该数据对应位置便为空,则采用K-近邻算法,以原料辛烷值及原料硫含量两个变量为输入,其他需要填补的变量为输出,进行空值的自动填充,其中取k=3。以已知的313号样本的“反吹氢气压力”变量为例,先将检测到的两个异常值剔除,再对空值采用K-近邻算法进行填补,如表1所示。

表1 反吹氢气压力数据处理结果
285号样本和313号样本经异常值处理后,再将两个样本的每个操作变量取平均值后,填入样本总表的相应位置,形成一个完整的总样本数据表,以供特征选择及模型建立使用。
2 因素分析与特征选择
由于汽油炼制过程是复杂的,设备也多种多样,这325个样本的各个变量之间呈现出高度的非线性及强耦合性。因此,要基于7种原料和4种吸附剂的变化性质及354个操作变量(共计367个变量)构建出辛烷值损失预测模型,就需要先进行降维处理,筛选出建模中最具有代表性、独立性及合理性的特征。
2.1 单因素分析
原料汽油中辛烷值较高是由于含有大量的烯烃[12-13]。在利用S_Zorb装置进行加工的过程中,吸附剂也是影响辛烷值损失和脱硫效果的重要因素[14-15]。实际上调整吸附剂活性的常用手段是控制再生剂的硫含量,若同时控制压力不变,那么降低氢油比会有效降低烯烃加氢饱和形成烷烃的速率,以此来减少辛烷值的损失。
受反应动力学控制,提高反应器出口温度到426 ℃的过程中,脱硫反应速率也会相应增加,因此反应温度的控制也是必要的[16-17]。若将其他反应条件控制不变,那么在反应温度升高的同时,产品辛烷值损失呈逐渐下降趋势,而脱硫率则是先逐渐上升后再逐渐下降。若反应压力逐渐增大,烯烃反应也会逐渐加速,从而使得烯烃含量降低,加速了辛烷值损失,但是脱硫效果会变更好。其反应温度及反应压力对于辛烷值损失和脱硫率的影响如图1所示。
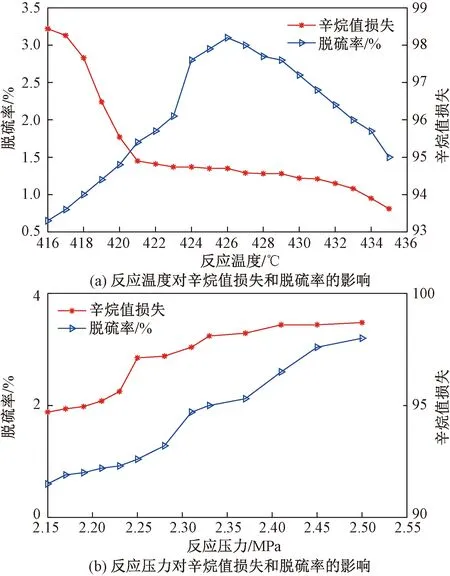
图1 辛烷值损失与脱硫率变化曲线
总的来说,在原油加工过程中,原料的硫含量、辛烷值(research octane number,RON)、烯烃、溴值、芳烃,待生与再生吸附剂性质中的焦炭、硫以及反应温度,反应压力、氢油比等性质对工艺流程中的RON和硫含量有着关键作用。
2.2 低方差过滤
对于所有的样本,若某变量中大部分样本取值都是相同的,即变量本身的方差很小,那么可以认为这个变量存在的意义不大[18]。该方法只适用于离散型变量,因此本文中所涉及的变量可以用该方法进行初步降维。设某变量X,其取值为{x1,x2,…,xn},那么该变量的方差计算公式为
(2)
根据计算得到的各变量的方差,并依据其方差分布选取其中位数10-13作为阈值,将方差低于此阈值的变量都移除,剔除之后还剩余198个变量。图2所示为变量低方差过滤的部分结果。
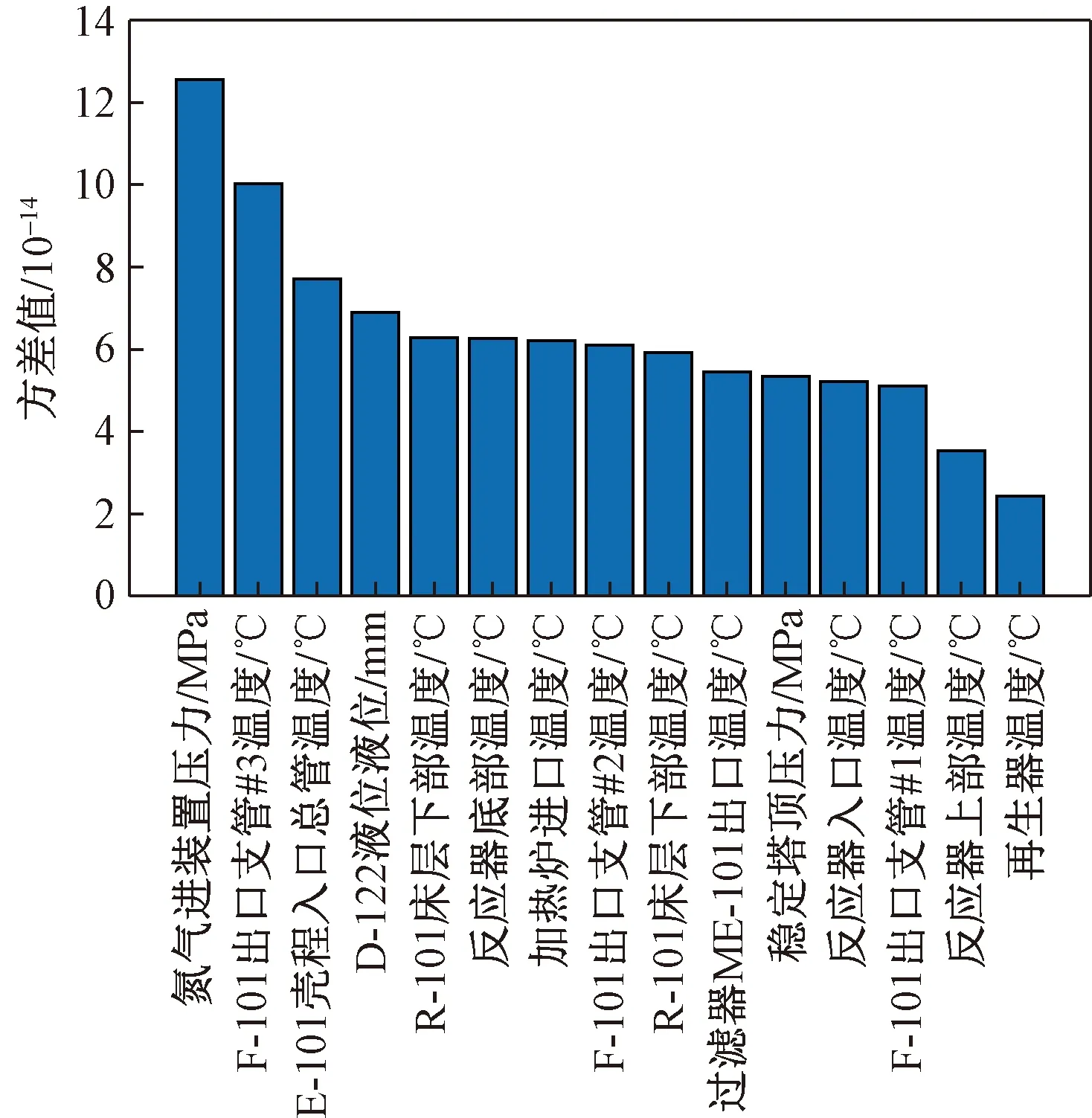
图2 低方差过滤部分结果展示
在这些被筛选出来的变量中,去除掉含零值较多的变量以避免对后续的分析产生不必要的影响,去除之后还剩余192个变量。
2.3 多因素分析
2.3.1 相关性分析
相关系数r是进行统计分析时常用的指标,多用于判断变量间直线相关的方向和程度,计算方法也非常简便,即两个变量之间的协方差与其标准差的乘积之比,称为积差法[19]。其表达式为
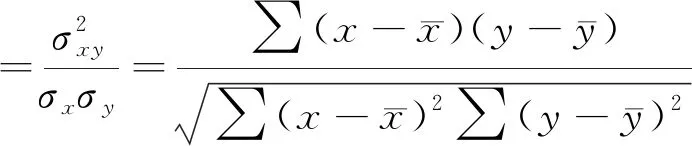
(3)
将上文筛选得到的192个变量以及对应的辛烷值损失值做相关性分析,得到各变量与辛烷值损失之间的相关性系数如表2所示。

表2 变量与辛烷值损失的相关系数
从相关性分析的概念可以得知,相关性系数绝对值小于0.2表示两个变量之间的相关性极低,若相关性系数绝对值大于0.8,则认为这两个变量高度关联。那么就可以将系数值小于0.2的这部分变量剔除掉,则还剩下69个变量,这些变量可以认为是与辛烷值损失相关性较高的变量。
2.3.2 基于随机森林的特征选择
随机森林是决策树的集成,它从数据集中随机抽取出多个训练集,每个训练集都能训练得到一组决策树,由众多的树组合的模型即称之为随机森林[20-21]。随机森林是由决策树组{h(X,θk),k=1,2,…,K}结合而形成,其中随机向量{θk}独立同分布,K表示决策树的数量,在确定了X的前提下,通过投票的形式来决出每棵树的最佳结果[22]。随机森林能够分析变量之间复杂的相互作用且具备特征分类的能力,当需要对高维数据进行降维时,随机森林可以作为一个很好的度量变量重要性的工具。
采用基于袋外数据分类准确率来度量各个变量的重要性,即袋外数据的自变量值产生轻微变动后得到的分类准确率,与原始分类准确率相比之下的平均减少量[23]。设训练样本有M={1,2,…,m}个,利用决策树来分类袋外数据,分类正确的个数表示为RM,而变量特征Xi(i=1,2,…,n)会扰动袋外数据中Xi的值,决策树会将扰动后的数据进行分类,分类正确的个数表示为RMi,重复此步骤后得到变量的重要性度量计算公式为
(4)
以筛选得到的69个变量的样本数据为输入,以辛烷值损失为参考目标,输出各变量对目标的重要性,部分变量的重要性得分如图3所示。

图3 变量重要性
设定一个阈值8.5,去除掉所有得分小于阈值的特征变量,最终选择了18个操作变量为影响辛烷值损失的主要操作变量如表3所示。

表3 变量重要性排序
2.4 综合选择
综上所述,根据单因素分析挑选出的10个变量以及多通过因素分析降维得到的18个变量相结合,最终确立了28个影响辛烷值损失的具备独立性和代表性的变量,如表4所示。

表4 变量综合排序
该28个变量是通过层层筛选所得出的,具有科学性和代表性,这些变量将作为之后建立模型基础数据。
3 辛烷值损失预测及脱硫优化
根据上述特征选择所得到的28个影响辛烷值损失的变量,建立辛烷值损失预测模型,选取了逻辑回归、BP神经网络以及支持向量机(support vector machine,SVM)三种机器学习算法来对辛烷值损失进行预测。其中,将2017年4月—2019年10月的265个样本数据作为训练集,剩下的从2019年11月—2020年5月的60个样本数据为测试集。
3.1 模型求解及比较
3.1.1 逻辑回归
逻辑回归是多元统计分析常用的方法,它主要适用于描述一组自变量与响应变量之间的最佳映射关系[24-25]。逻辑回归是以线性回归为基础拓展出来的,通常使用Sigmoid函数来解决分类问题,即逻辑回归函数,表达式为
(5)
式(5)中:z表示响应变量的值。
用特征向量的线性组合来拟合多维空间里点的轨迹走向及分布,在最大似然估计的基础上推导出逻辑回归模型的损失函数J(θ),其表达式为

(6)
式(6)中:m表示样本个数,每个样本都有n个特征。
对于训练集样本,预测前后对比结果如图4所示。根据预测结果得到均方误差(MSE)为0.738 1,可决系数(R2)为0.72。

图4 逻辑回归模型预测前后对比
3.1.2 BP神经网络
BP神经网络是当前阶段使用比较广泛的神经网络预测模型,其训练模式为误差逆向传播。BP神经网络逆向传播过程按照梯度下降的学习规则,利用逆向传播对该网络的权值及阈值不断地进行调整,使得该网络的输出值和真实值的误差均方差最小[26-28]。图5为BP神经网络结构图。

图5 BP神经网络结构图
逆向误差修正阶段遵循的是梯度下降的学习规则,不断地对网格参数做出调整,表达式为

(7)
那么进行权值调整的公式为
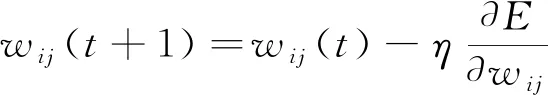
(8)
式中:aj表示输出层第j个节点的值;yj表示隐含层第j个节点输出值;η为学习率。
以训练集265个样本数据的28个主要变量为输入,那么输入层节点数就是28个,输出层节点数只有1个,设定隐藏层神经元个数初为8个。输入数据时首先进行了归一化处理,训练过程中不断计算更新的权重,反复迭代,最终运行结果及预测得到的辛烷值损失与原数据比较结果如图6所示。
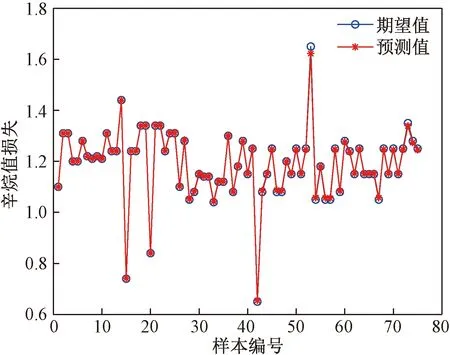
图6 BP神经网络模型预测前后对比
根据BP神经网络预测得到的预测结果得出均方误差为0.000 355,同时也可以得到模型的R2达到了0.976 64。
3.1.3 支持向量机
支持向量机(SVM)是基于结构风险最小化提出的建模方式,属于有监督的机器学习算法[29]。SVM可以根据输入的样本数据, 寻找模型的复杂性和学习能力之间的最佳平衡点, 遵循结构风险最小原理, 有效避免经典学习算法中过度学习的问题, 已经成功应用在石化、化工等领域[30]。本文构建模型的核函数是高斯径向基函数,表达式为
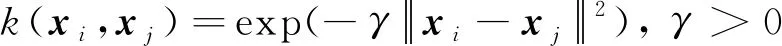
(9)
分类预测的表达式为
zsgn[wφ(z)-b]=

(10)
式中:xi、xj为输入的特征向量;w为权重向量;b为偏置。
建立SVM辛烷值损失预测模型,根据筛选出的28个影响辛烷值损失的主要变量,将训练集265个样本的数据先进行了归一化处理,然后导入构建好的模型中进行训练和测试,预测结果如图7所示。

图7 SVM模型预测前后对比
可以看到,基于SVM建立的辛烷值损失预测模型均方误差(NMSE)为0.000 043,其R2高达0.999 7。
3.1.4 结果对比
逻辑回归预测模型、神经网络预测模型以及SVM预测模型对于辛烷值损失的预测效果对比如图8所示。

图8 三种模型预测结果对比
根据预测结果可以知道逻辑回归预测模型的R2=0.72,均方误差(NMSE)为0.28,效果有些差强人意,这是由于逻辑回归模型使用的是线性分类器,而模型本身是非线性的,所以很容易出现欠拟合的情况,从而导致精度不高。
而BP神经网络预测模型的R2达到了0.97以上,NMSE为0.03,相比于逻辑回归而言,BP神经网络预测模型更适合用于辛烷值损失的预测。由于BP神经网络的预测效果很大程度上会受网格参数的影响,尤其是输入层和隐藏层节点数的设置,若参数设置不适当,将会很大程度上影响到模型的预测结果,因此只要合理的设置参数,便可以达到满意的结果。
同时可以看出,基于SVM建立的辛烷值损失预测模型的R2高达0.99,说明该模型已经达到了理想的预测效果。基于SVM建立预测模型时,核函数的选择非常重要,通常来讲高斯核函数的效果是最好的,同时该模型适用于样本较少及特征变量维度较高的情况,与本文所使用的数据样本情况也十分符合。
将60个测试样本放入训练好的SVM模型中进行验证,得到结果如图9所示。可以看到SVM模型在测试集上的预测准确率达到了0.982 4,均方误差为0.000 12。通过对实际工业数据的运用及验证说明,该模型能够准确有效地预测汽油炼制过程中的辛烷值损失,因此该预测方案具有较高的可行性与可靠性。

图9 SVM模型测试集预测结果
3.2 辛烷值损失优化模型
在获得的325个样本中,有60个样本的硫含量是大于5 μg/g因而未达到脱硫标准的,因此我们可以先辛烷值损失预测模型建立的基础上,首先需保证硫含量低于5 μg/g,再利用优化算法对操作变量进行有效的优化,使得在脱硫的基础上辛烷值的损幅尽可能小。因此可以建立目标函数式及其约束条件为

(11)
式(11)中x=[x1,x2,…,x19]T,表5为这19个控制变量的符号及其取值范围,θ=[θ1,θ2,…,θ8]T分别表示原料硫含量、烯烃、芳烃、溴值、待生焦炭、待生S、再生S原料这八个性质变量,y*表示原料辛烷值,y1为预测出的产品辛烷值,y2为产品硫含量。

表5 变量符号表示及取值范围
由于涉及的预测模型均为非解析的机器学习模型,传统的梯度下降的算法是无法求解的,因此可以使用遗传算法求解上述优化模型[31-32]。其算法流程图如图10所示。

图10 遗传算法流程图
该优化模型经遗传算法求解,迭代之后得到各
个参数值的最优组合,在产品辛烷值尽可能高的情况下,硫含量有了明显的下降,图11(a)和图11(b)展示了部分样本的优化结果。
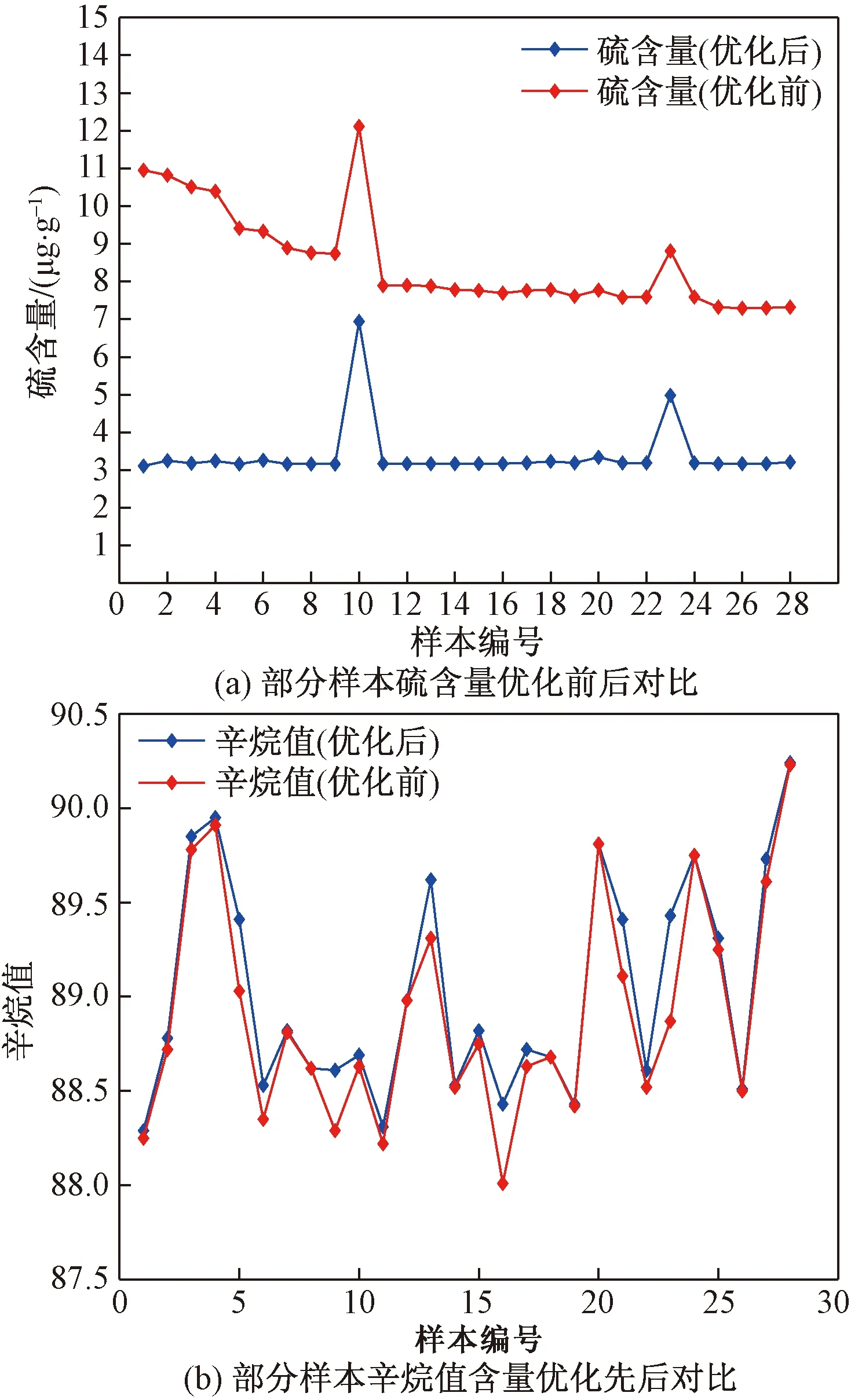
图11 辛烷值和硫含量优化前后对比
可以看出根据优化模型对可操作变量的参数进行优化之后,硫含量有了明显的下降且绝大部分样本硫含量都降到了5 μg/g以下,部分样本的产品辛烷值相比之前也有小幅度提升,达到了降低辛烷值损失的目的。
4 结论
针对汽油炼制过程中的降低辛烷值损失的问题,将数据进行初步清洗之后,采用单因素分析、方差过滤、随机森林特征选择等方法,对样本的众多变量进行了降维处理,从367个变量中筛选出了28个影响辛烷值损失的主要变量,以用于预测模型的建立。另外,基于逻辑回归、BP神经网络、SVM三种机器学习算法构建出了辛烷值损失预测模型,从预测结果能够得出基于SVM建立的预测模型准确率是最高的,其训练集样本预测精度达到99.97%,测试样本预测精度达到98.24%,能够准确高效地对辛烷值损失值进行预测。基于已有的预测模型,建立出了优化产品辛烷值和硫含量的优化模型,通过遗传算法进行求解,经过优化之后样本硫含量能够控制在5 μg/g以内。因此,可以利用构建好的SVM预测模型来建立优化模型对产品辛烷值和硫含量进行优化,能够快速准确地得出原油加氢脱硫过程中的控制参数,以达到降低硫含量及保护辛烷值的目的,对于汽油的炼制具有现实意义。
