基于改进多嵌入空间的实时语义数据流推理
2022-02-24姚光涛顾进广
高 峰,姚光涛,顾进广
(1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.武汉科技大学 大数据科学与工程研究院,武汉 430065;3.智能信息处理与实时工业系统湖北省重点实验室,武汉 430065;4.富媒体数字出版内容组织与知识服务重点实验室,武汉 430065)
0 概述
近年来,物联网和移动互联网取得快速发展,其中产生了海量的传感器数据以及其他类型的数据,这些数据具有高速、实时、动态的特征,对它们进行分析并推理出其中隐含的知识具有重要的理论和现实意义。将实时数据与知识图谱技术相结合,并以RDF(Resource Description Framework)三元组加时间标注的方式进行表示,可以形成实时语义数据流数据,基于实时语义数据流的RDF 流推理逐渐引起研究人员的关注。
目前的语义数据流推理引擎包括集中式和分布式两大类:集中式流推理以CSPARQL(Continuous SPARQL)[1]引擎为代 表,使 用Esper[2]、Jena[3]和Sesame[4]进行窗口运算以及处理查询;分布式流推理属于新兴领域,目前尚处于研究阶段,主要包括CQELS[5]的分布式版本、基于Storm 集群的Katts[6]、基于Spark 框架的Strider[7]等。现有的语义数据流引擎虽然能够在一定程度上完成语义推理,但仍存在一些问题,如缺乏对海量数据的适应性、推理性能不佳、推理时延较大等,难以适应当前海量数据场景下人们对推理查询实时性的需求。
随着知识图谱嵌入表示学习的兴起,可以对知识图谱中的实体和关系进行向量表示,将实体相互之间复杂的语义关系转换为向量计算,这种简单的向量计算的方式对提升知识图谱推理效率具有重要意义。然而,现有的知识表示学习模型存在一定不足,如只关注静态图谱嵌入而忽略知识图谱的动态更新,或缺乏推理能力等,导致其无法直接应用于实时动态语义数据流推理任务。
为了使得知识表示学习模型能够适应知识图谱的在线更新,本文建立一种PUKALE(Parallel Universe KALE)模型。针对传递闭包等复杂推理场景,在联合嵌入模型KALE 的基础上引入多嵌入空间,提出能够适应复杂推理的嵌入空间生成算法。为了在进行增量更新训练时更合理地选择嵌入空间,提出基于实体关系映射的嵌入空间选择算法。将PUKALE 模型嵌入至语义数据流推理引擎CSPARQL-engine 中,以实现对实时语义数据流的推理查询。
1 相关工作
目前,语义数据流处理平台大多基于SPARQL[8],首先读取所有的RDF 数据并构建所读取数据的完整索引,然后评估SPARQL 的推理查询性能。Streaming SPARQL[9]流处理平台基于SPARQL,设计一个扩展用于处理数据流上的窗口查询,允许在数据流上定义基于时间和计数的窗口,但其没有考虑关于数据结构选择和连续执行计算状态共享的性能问题。CSPARQL 是SPARQL 的一个扩展,其特点是支持连续查询,即在RDF 数据流上注册然后连续执行的查询。CQELS 支持流式数据以及静态RDF 数据,此外,CQELS 是一个本地自适应的查询处理器,在本地实现所需的查询运算符,能够提供一个灵活的查询执行框架,在查询执行的过程中,其根据一些启发式规则不断地对操作符进行重新排序,提高了查询执行的延迟和复杂性。EP-SPARQL[10]是一种描述事件处理和流推理的语言,可以翻译成基于Prolog的复杂事件处理框架ETALIS[11],它可以将基于RDF的数据转化为逻辑事实,然后将EP-SPARQL 查询转化为Prolog 逻辑规则,但是其转化过程耗时,性能不高。StreamRule[12]结 合RSP 引擎和Clingo[13]用于流的过滤以及聚合,提升了知识密集场景下的复杂推理能力。结合了Spark 和Flink 分布式平台的实时语义数据流推理平台BigSR[14]能利用分布式处理来有效降低推理延时,但其对硬件资源要求较高。
BORDES 等[15]提出一种 知识表示 学习模型TransE,其将三元组中实体之间的关系嵌入到低维向量空间中进行计算,由于参数少、易于训练、可扩展性强,使得知识表示在知识图谱领域受到广泛关注。随后,针对TransE 出现了一些扩展性模型,如TransH[16]、TransR[17]等,尽管这些模型在TransE 模型的基础上做了进一步扩展,但是它们都没有利用逻辑规则。KALE[18]模型在TransE 模型的基础上引入逻辑规则,建立三元组与逻辑规则的统一框架,使得模型具备一定的推理能力,可以推理出三元组之间隐藏的知识。然而,KALE 模型缺乏对流式增量数据的更新能力,当流式数据中出现新的实体或关系时,KALE 模型需要在整个数据集上重新训练,在数据规模较大、更新较频繁的场景下,时间消耗难以被人们接受。TAY 等[19]在TransE 的基础上进行改进,提出puTransE 模型,其通过划分子嵌入空间的方式使得模型具备处理动态知识图谱的能力,然而,该模型不具备推理能力,不能直接应用于数据流推理任务。还有一些动态图嵌入方法[20-22]支持在线学习图节点嵌入,然而这些方法不能被用于动态知识图谱嵌入,因为它们学习的是结构相近的节点的嵌入,而没有考虑边的语义信息。
2 PUKALE 模型
2.1 PUKALE 框架
图1 所示为PUKALE 模型框架。模型在初始训练时,会根据训练集三元组的个数和嵌入空间三元组的限定值生成n个嵌入空间,模型在n个嵌入空间中分别训练;当增量更新的三元组到达时,如果增量更新的三元组的实体和关系在已有的嵌入空间中,则对相应的嵌入空间重新训练;若最后一个嵌入空间三元组个数没有达到限定值,则将增量更新的三元组加入当前嵌入空间中重新训练,否则,重新创建一个嵌入空间进行训练。

图1 PUKALE 模型框架Fig.1 PUKALE model framework
算法1 是PUKALE 模型算法的伪代码表示:第1 行根据训练集数据生成初始嵌入空间;第2 行读取推理规则到模型中;第3 行~第19 行表示对每个嵌入空间分别进行训练,包括随机生成超参数、随机初始化向量空间等。在训练完成后,会保存每个嵌入空间的实体和关系矩阵。
算法1PUKALE 模型算法

2.2 嵌入空间生成策略
对于PUKALE 模型中嵌入空间的生成,本文实现并测试3 种嵌入空间的生成策略:第1 种策略是语义相关的生成方法;第2 种策略是结构上相关的方法;第3 种策略是上述两者的结合。
1)第1 种语义相关策略在对一个嵌入空间划分三元组时,具有相同关系的三元组更倾向于划分到同一个嵌入空间,而具有不同关系的三元组更倾向于划分到不同的嵌入空间。如图2(a)虚线部分所示,假设(e3,r1,e4)是初始三元组,则(e1,r1,e2)和(e3,r1,e4)更倾向于划分到同一嵌入空间中。
2)第2 种结构相关策略的思路是在创建一个嵌入空间时,首先随机选择一个三元组加入当前嵌入空间,然后以当前三元组的头实体和尾实体为起点,选择出度和入度方向的三元组加入当前嵌入空间,随后继续以新加入的三元组的头实体和尾实体为起点,添加出度和入度方向的三元组,以此类推,直到添加的三元组个数达到嵌入空间的限定值。从新加入三元组的顶点出发继续选择出度和入度方向的三元组,一方面是为了适应复杂环境(如军事态势感知)中的传递闭包推理场景;另一方面,随着时间的推进,图谱中会频繁进行三元组的添加、删除等图谱更新操作,为了适应这些更新,模型不仅要快速学习所更新实体以及关系的嵌入,还要考虑其对现有实体以及关系嵌入的影响。以图2(b)为例,假设在实体e1和实体e2之间添加一个关系r1,构成新的三元组(e1,r1,e2),则需要对和e1、e2有关的5 个三元组重新训 练,它们分别 为(e1,r7,e5)、(e4,r8,e1)、(e1,r3,e3)、(e2,r2,e3)、(e1,r1,e2),而不需要在整个图谱上重新进行训练。对于超参数嵌入空间三元组限定值的设置,本文在[500,3 000]范围内以步长500 递增进行调优,嵌入空间限定值设置在1 500 个时模型效果较好,继续增大该限定值,模型准确度并没有明显提升,而嵌入空间计算延迟会略有增加。结构相关策略选择三元组的方式如图2(b)所示,假设(e3,r1,e4)是初始三元组,则虚线部分是所选择的三元组。
3)第3 种嵌入空间生成策略是第1 种策略和第2 种策略的结合,其生成嵌入空间的主要思路是:首先随机选择一个三元组,将其加入当前嵌入空间并记录当前三元组的谓语关系;之后以当前三元组的头尾实体为起点选择出度和入度方向的三元组加入嵌入空间,与第2 种策略不同的是,其不是继续以新的实体为起点添加三元组,而是重新随机选择一个语义相似的三元组加入嵌入空间,继续重复前面的流程,直到三元组的个数达到嵌入空间三元组的限定值。在结构相关策略的基础上引入语义相关策略的原因是,三元组的更新操作影响的不仅是以对应顶点出发的结构上相近的三元组,还有结构上虽然不相近但是关系相同的三元组,同样以添加(e1,r1,e2)为例,关系嵌入r1的变化会影响图谱上包含r1的其他三元组,如(e3,r1,e4)。第3 种策略可以兼顾2 种类型的三元组,与结构相关策略相比,该策略选择的三元组更具多样性,在嵌入空间训练时可以学习到更多的信息。第3 种策略的三元组选择方式如图2(c)所示,假设(e3,r1,e4)是初始三元组,则虚线部分是所选择的三元组。
第3 种嵌入空间生成算法描述如算法2 所示。此外,本文也尝试puTransE 中的语义双向随机游走嵌入空间生成方式,该策略与策略3 的主要区别在于,随机游走从顶点出发选择三元组的路径是随机的,而策略3 会选择出度和入度方向的所有三元组。puTransE 生成嵌入空间的方式如图2(d)虚线部分所示,如果初始时三元组是(e3,r1,e4),则下一轮选择的三元组是以实体e3、e4为起点或终点的一个随机三元组。

图2 嵌入空间三元组选择策略示意图Fig.2 Schematic diagram of embedding space triplet selection strategies
算法2结合语义和结构的嵌入空间生成算法


2.3 嵌入空间选择策略
在PUKALE 模型的训练过程中,每个嵌入空间都会生成独立的实体向量矩阵和关系向量矩阵。对于嵌入空间的选择问题,本文分析如下2 种策略:
1)第1 种策略是线性遍历每个嵌入空间,如果输入的三元组对应的实体和关系存在于当前嵌入空间,则计算当前三元组在当前嵌入空间的能量分数并进行记录,最终该三元组的全局能量分数就是所有符合条件的嵌入空间中能量分数的最大值。这种方式的时间复杂度是O(n),其中,n是嵌入空间的个数。在嵌入空间数量比较大的情况下,顺序遍历会有很多无效的遍历,从而浪费大量时间。
2)本文对第1 种策略进行优化,提出第2 种嵌入空间选择策略,建立实体和关系到各个嵌入空间的索引映射,如图3 所示。在训练时,如果一个三元组到达,则根据三元组的实体和关系查找对应的索引列表,索引列表中重叠的嵌入空间就是符合要求的嵌入空间。如图4 所示,这种建立在索引机制上的嵌入空间选择方式可以有效避免多余的遍历,在不影响模型准确度的前提下能够提高嵌入空间的选择速度,其时间复杂度可以达到O(k),其中,k是查找的索引列表最大长度。该策略对应的算法描述如算法3 所示。

图3 实体和关系到嵌入空间的索引映射Fig.3 Index mapping of entities and relationships to embedding space
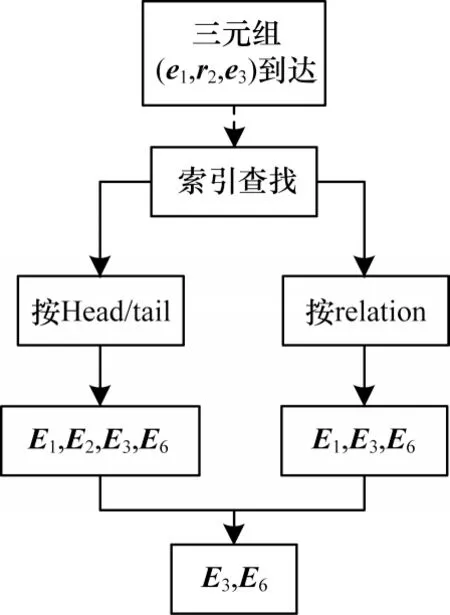
图4 基于索引映射的嵌入空间选择流程Fig.4 Procedure of embedding space selection based on index mapping
算法3基于索引映射的嵌入空间选择算法

2.4 算法复杂度分析
为了分析PUKALE 模型的空间复杂度和时间复杂度,将PUKALE 和TransE 及其相关改进模型进行空间和时间复杂度对比,结果如表1 所示。

表1 知识表示学习模型的空间和时间复杂度对比Table 1 Comparison of space complexity and time complexity of knowledge representation learning models
在表1 中:d表示嵌入学习的向量空间维度;ne表示实体个数;nr表示关系个数;nt表示三元组个数;ng表示逻辑规则个数;ns表示生成的语义空间个数。从表1 可以看出,PUKALE 的空间及时间复杂度与性能最好的TransE 相差不大,与KALE 相比,PUKALE 的空间复杂度相同而时间复杂度降低,原因是对于流式增量数据,KALE 是在完整数据集上重新训练,而PUKALE 中引入了子嵌入空间,其在子嵌入空间中进行局部训练,在图谱规模较大、嵌入空间个数较多的场景下,可以大幅缩短模型的训练时间。
2.5 PUKALE 训练方案
为了对PUKALE 模型进行有效训练,本文使用KALE 中基于间距的Hinge 表达式优化损失函数,其常用形式如下:

间距模型常用于二分类或者样本相似性分析任务,本文基于间距模型并结合联合嵌入模型中所提的损失函数,提出一种PUKALE 模型的损失函数,如下:

其中:L表示正确三元组和否定三元组之间的margin距离;S+为数据集中正确三元组组成的集合;S-为否定三元组组成的集合;I为模型计算出的真值;γ是距离超参数。
PUKALE 模型的训练过程为:首先随机初始化三元组(h,r,t)中实体和关系的向量表示;然后对训练样本生成否定三元组,生成方式是随机替换样本的头实 体或尾实体,构 造出负例三元组(h′,r,t)或(h,r,t′);最后针对每个三元组计算统一得分函数,对于正确的三元组,其期望得分更低,而对于否定三元组,其期望得分更高,这样即可通过训练样本的分数来区分正负样本。
2.6 基于PUKALE 的实时语义数据流推理
现有的数据流推理引擎CSPARQL-engine 主要包括ESPER 流处理引擎、Sparql 推理引擎和Jena 查询引擎。ESPER 是一个复杂事件处理以及事件流处理引擎,Jena 是Apache 的开源并基于Java 的RDF 流处理工具,CSPARQL 支持流式数据的持续查询功能。本文将基于多嵌入空间的PUKALE 模型嵌入到CSPARQL-engine 中,使得复杂的规则推理可以映射至低维向量空间进行简单的向量计算,从而降低图谱规模不断增大后的推理延迟,使其满足大规模流式数据场景下的实时推理需求。实时语义数据流推理架构如图5 所示,推理过程如下:
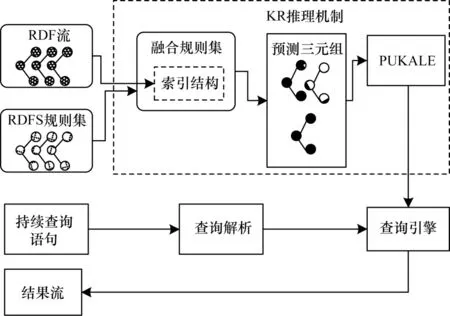
图5 基于PUKALE 的实时语义数据流推理过程Fig.5 Procedure of real-time semantic data flow reasoning based on PUKALE
1)输入到CSPARQL-engine 中的RDF 数据先通过Jena 进行格式化,转换成系统可以识别的数据格式。
2)系统读取Jena 格式化后的数据,在RDF 三元组的基础上加上时间戳形成四元组,将该四元组放到RDF 数据流中。
3)系统读取并解析CSPARQL 查询,获得查询的时间步长和RDF 流窗口大小。
4)系统从ESPER 流引擎中取出指定窗口内的数据,将其输入到查询引擎中,同时作为输入数据输入到PUKALE 模型中。
5)PUKALE 模型获取数据后,根据预设的逻辑规则进行计算,推理出隐藏的三元组知识,然后生成推理三元组集合并输入查询引擎。
6)系统根据查询语句在查询引擎中进行持续查询,并返回查询结果。
3 实验与结果分析
本节首先通过实验分析嵌入空间生成算法和选择算法的性能,然后评估PUKALE 模型的动态更新效果以及模型性能,最后将其嵌入到CSPARQL-engine,并完成2 个语义数据流的推理查询测试。实验所使用的软件环境均为Windows10 操作系统,Java8 编程环境,Maven 版本3.6;硬件环境为CPU i5-8265U@1.6 GHz,内存大小8 GB。
3.1 PUKALE 模型实验
为了测试嵌入空间生成算法和选择算法以及PUKALE 模型的性能,本节进行4 个实验:前2 个实验是对嵌入空间生成算法和选择算法的性能测试;第3 个是测试新增数据集时PUKALE 模型和KALE模型在同等规模数据集下更新相同个数三元组时的时间消耗;第4 个是测试对比PUKALE 模型与其他知识表示学习模型的性能。
为了评价PUKALE 模型在军情态势预测数据集上的效果,对于样本中的每一个三元组(s,p,o),模型会生成多个否定三元组实例,生成方式是主语s或宾语o替换为实体集合中的其他实体,形成(s′,p,o)或(s,p,o′),之后计算所有生成的三元组的得分,最后模型对三元组的得分进行排序,根据排序结果统计正实例三元组在列表中的位置排名。本文使用与KALE 相同的评估指标:
1)MRR(Mean Reciprocal Rank),其为一个国际通用的搜索算法性能评估指标。
2)HITS@K,指前K个位置中正实例三元组所占的比例。
3.1.1 嵌入空间生成策略性能分析
本文通过实验分析2.2 节所提3 种嵌入空间生成策略以及puTransE 随机游走策略对PUKALE 模型准确性的影响。实验使用的数据集是海军军情态势预测数据集,其包含100 000 个三元组。为了使模型有更好的适应性,本文减少超参数对模型性能的影响,在各个嵌入空间的训练过程中,模型的初始参数不是固定的,而是采用随机设置的方式,以避免参数耦合影响模型的训练效果。训练参数设定如下:嵌入空间三元组限定值为1 500;向量空间维度为30;margin 参数范围 为{0.1,0.2,0.3};学习率learning_rate 参数范围为{0.1,0.01}。
实验结果如表2 所示。从表2 可以看出:第1 种语义相关策略在数据集关系个数较少的情况下不适用,原因在于这种划分方式虽然可以让一个嵌入空间中的三元组尽可能满足语义的相关性,但是划分到每个嵌入空间的关系个数比较少,三元组关系不具备多样性,训练效果比较差;在第2 种结构相关的三元组选择策略下模型的准确率有明显提高,一方面是因为划分至嵌入空间的关系个数增加,解决了第1 种策略嵌入空间关系个数太少的缺陷,另一方面,结构相关的三元组划分到同一个嵌入空间,避免了相互影响的三元组分散在多个嵌入空间,减少了图谱更新时需要重新训练的嵌入空间个数,提升了模型的训练效率和准确率,此外,这种方式下相邻嵌入空间的三元组存在一定程度的重叠,经过测试,所有嵌入空间三元组的总重复率为4.6%;第3 种语义结构结合策略相比第2 种结构相关策略,模型的准确率进一步提升,因为图谱中三元组的更新影响的不仅是顶点入度出度方向的三元组,还有关系相同的三元组,策略2 只选择了受顶点变化影响的三元组,而忽略了受关系变化影响的三元组,策略3 在策略2 的基础上加入了关系相同的三元组,使得嵌入空间重训练时可以学习到更多的信息;与puTransE中的随机游走策略相比,策略3 下的模型准确率更高,原因是其模型可以推理出更多隐含的三元组。

表2 嵌入空间生成策略性能对比Table 2 Performance comparison of embedding space generation strategies
如图6、表3 所示,本文以数据流传递闭包规则为例进行推理查询。以t1为初始三元组,假设使用随机游走策略划分三元组,由于随机游走的随机性,三元组t1、t2可能划分在嵌入空间E1,t3、t4可能划分在嵌入空间E2,则E1中可以推理出t5,E2中可以推断出t6。假设使用结构语义结合策略,则三元组t1、t2、t3、t4会划分到同一个嵌入空间E3,在E3中除了可以推理出t5、t6外,还 可以推理出t7、t8。而在传递 闭包规则中,推理的结果可以作为推理条件继续使用,将其加入嵌入空间进行训练,模型可以学习更多的信息,即准确率会提升。

图6 传递闭包图谱示例Fig.6 Sample of transitive closure graph

表3 传递闭包图谱三元组编号Table 3 Transitive closure graph triples numbers
3.1.2 嵌入空间选择策略性能分析
本节通过在10 万、30 万、50 万规模的数据集上分别进行实验,记录不同规模数据集下嵌入空间的平均选择时间,以分析2.2 节所提2 种嵌入空间选择策略的性能。在3 个不同规模数据集上的参数设定均一致,嵌入空间三元组限定值为1 500,向量空间维度为30,margin 参数范围为{0.1,0.2,0.3},学习率learning_rate参数范围为{0.1,0.01},实验结果如表4 所示。从表4可以看出,随着训练集三元组规模的增大,子嵌入空间个数增多,索引映射的时间消耗明显低于线性遍历,原因在于索引映射使用索引算法避免了对多余子嵌入空间的遍历,从而节省了时间。
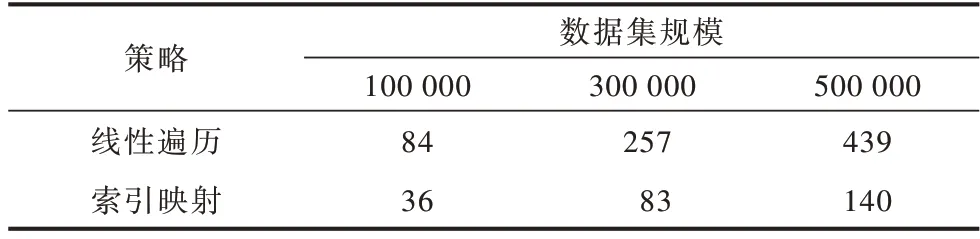
表4 不同规模数据集下嵌入空间选择时间对比Table 4 Comparison of embedding space selection time under different scale datasets ms
3.1.3 PUKALE 模型动态更新分析
PUKALE 模型中引入了多嵌入空间,避免了数据集三元组增量更新时模型在整个数据集上重新训练。为了验证PUKALE 模型引入多嵌入空间的有效性,本文对比PUKALE 模型和KALE 模型在不同规模数据集下增量更新时的训练时间消耗,数据集详细信息如表5 所示,KALE 和PUKALE 在表5 的3 个不同规模数据集上动态更新所消耗时间如表6 所示。实验参数设置:嵌入空间三元组个数限定值为1 500,margin 参数范围 为{0.1,0.2,0.3},学习率learning_rate 参数范围为{0.1,0.01}。
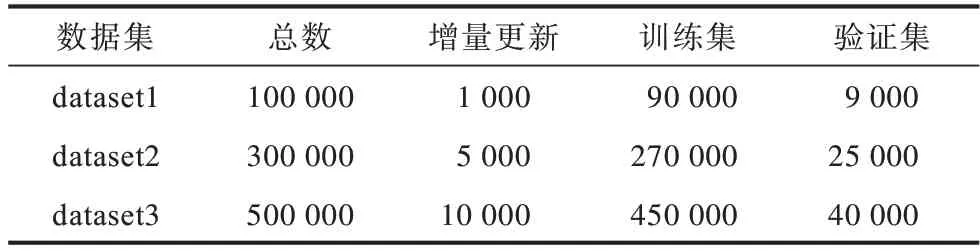
表5 用于增量更新测试的数据集信息Table 5 Datasets information for incremental update test

表6 不同规模数据集下增量更新时间对比Table 6 Comparison of incremental update time under different scale datasets min
在训练集三元组增量更新时,KALE 模型在整个图谱上重新训练,是一种全量更新的方式,随着三元组数目的不断增大,KALE 模型重新训练所消耗的时间会显著增加。而PUKALE 模型的增量更新方式是在选定的嵌入空间进行更新,是一种局部更新的方式,相比于全量更新,其训练时间明显降低,适用于大规模数据流更新场景。
在动态更新实验过程中,不同规模数据集上PUKALE 模型和KALE 模型的准确率对比如表7 所示。从表7 可以看出,对于不同规模的三元组,随着三元组数量的增多,PUKALE 模型的准确率会逐渐提高,同等规模三元组在进行增量更新时,PUKALE模型在各个子嵌入空间的平均准确率也略有提高,这表明PUKALE 模型的增量更新具有有效性。
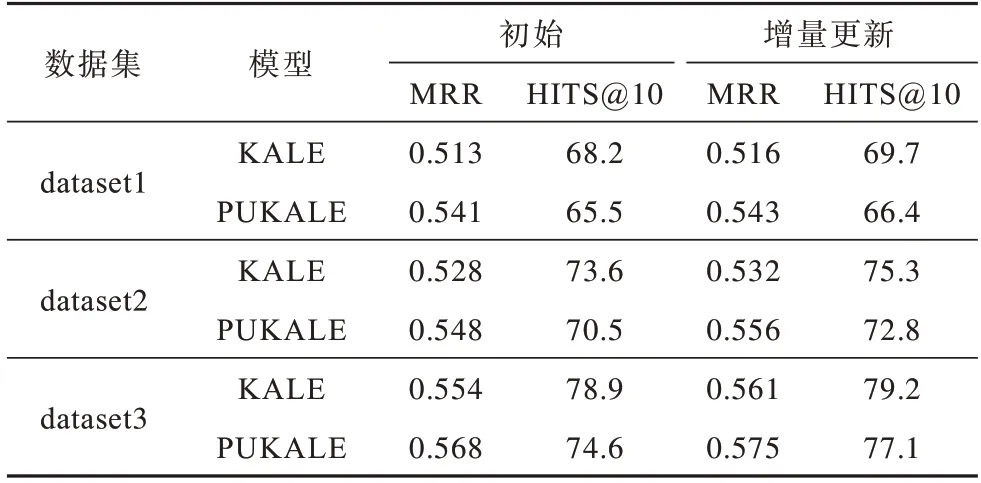
表7 不同规模数据集下模型准确率对比Table 7 Comparison of models accuracy under different scale datasets
3.1.4 PUKALE 模型性能分析
为了比较PUKALE 模型和其他知识表示学习模型的训练效果,本文进行对比实验,设置如下:向量空间维度d分别设置为{30,40,50};训练集三元组个数为90 000;验证集三元组个数为10 000;嵌入空间三元组个数分别设置为{1 000,1 500,2 000,3 000};margin 参数范围为{0.1,0.2,0.3};学习率learning_rate 参数范围为{0.1,0.01}。实验结果如表8 所示。
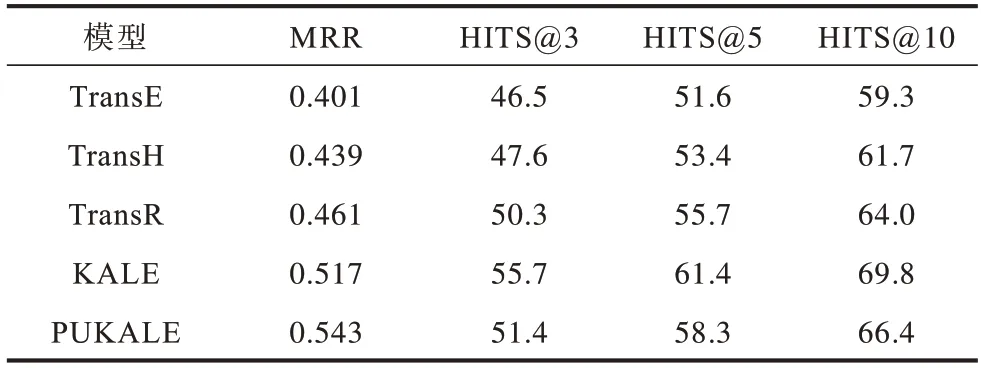
表8 PUKALE 与其他知识表示学习模型准确率对比Table 8 Comparison of accuracy between PUKALE and other knowledge representation learning models
从表8 可以看出,KALE 模型和PUKALE 模型的准确率均优于TranE、TransH、TransR 模型,PUKALE 在各个嵌入空间的平均准确率比KALE低,但是MRR 相比KALE 有所提高,PUKALE 准确率比KALE 低的原因在于KALE 训练时只有一个全局嵌入空间,其可以完整学习所有三元组的信息,而PUKALE 是将三元组按语义相关和结构相关划分到各个子嵌入空间中,由于嵌入空间生成算法具有差异性,因此相关的三元组不一定能全部划分到同一个嵌入空间,导致在各个嵌入空间学习的信息不一定完整,平均准确率降低。PUKALE 的MRR 有所提高的原因在于嵌入空间的选择机制会忽略掉一些不相关的嵌入空间和三元组,精简了三元组的搜索范围,使得测试三元组的排名更靠前。虽然PUKALE的准确性低于KALE,但是PUKALE 支持增量更新,进行增量更新时是在局部嵌入空间重新训练,而不是在整个数据集上进行重新训练。在大规模三元组场景下,PUKALE 的更新时间消耗远低于KALE,这在后续的实时语义数据流处理中具有重要意义。
3.2 PUKALE 在语义数据流推理中的性能分析
本节将PUKAEL 模型添加推理嵌入到CSPARQLengine 中进行2 种场景实验,测试其在2 种场景下的推理查询时延,并与传统的CSPARQL 推理查询和KALE推理查询进行对比。场景1 是具有传递闭包规则的舰船战斗群隶属关系推理,场景2 是较为复杂的动态威胁感知推理。场景1 的规则如表9 所示。

表9 场景1 闭包规则Table 9 Scenario 1 closure rule
表9 规则表示,如果舰船目标x 和舰船目标y 处于同一个战斗组,舰船目标y 和舰船目标z 处于同一个战斗组,则舰船目标x 和舰船目标z 处于同一个战斗组。对于舰船目标x,如果获取了与其同组的y 和z,则可以通过分析其同组舰船目标的历史活动进行意图分析。因此,在数据流平台快速推理出x 同组的其他舰船目标比较关键。另外,该规则存在传递闭包特征,推理结果可以作为推理条件继续使用。
针对表9 构造的Rule1,本文在CSPARQL-engine中使用如下查询语句Query1,表示查询出所有与舰船x 同组的舰船。
Query1传递闭包查询

场景2 的规则如表10 所示。该规则表示,如果舰船目标a 装载了武器b,武器b 的目标是c,而舰船目标d 的类型是c,则舰船目标a 对舰船目标d 存在潜在威胁。

表10 场景2 复杂推理规则Table 10 Scenario 2 complex reasoning rule
针对规则2,本文使用的推理查询语句如Query2所示。Query2 是一个较为复杂的推理查询,表示如果在时间点time1 和位置1 发现了2 艘舰船x 和y,并且x对y 有威胁,而在时间点time2(time2>time1)和位置2又发现了x 和y,并且2 个区域在一定范围内,则查询出2 艘舰船的信息。
Query2复杂推理规则查询
针对以上2 个查询,本文实验所设置的参数如下:数据流窗口大小分别为{10,20,30,40},单位为秒;每秒窗口三元组的数量为{2 000,4 000,8 000,16 000,32 000,64 000};窗口的步长为1 s。根据以上输入参数可以得到实验结果如图7、图8 所示。
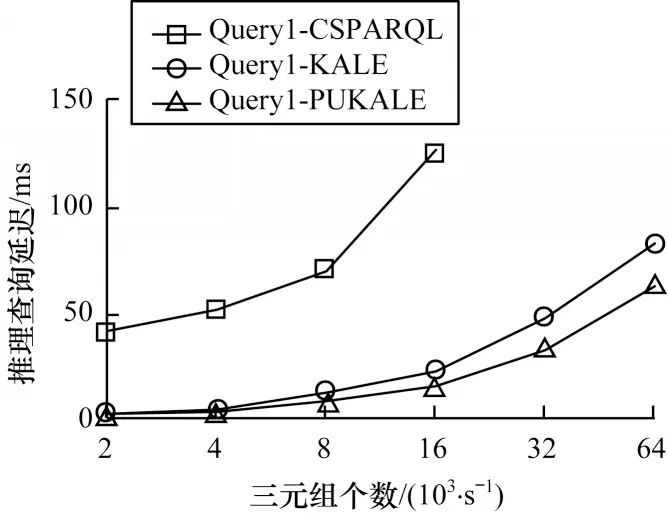
图7 规则1 推理查询时间延迟Fig.7 Rule1 reasoning and query time delay
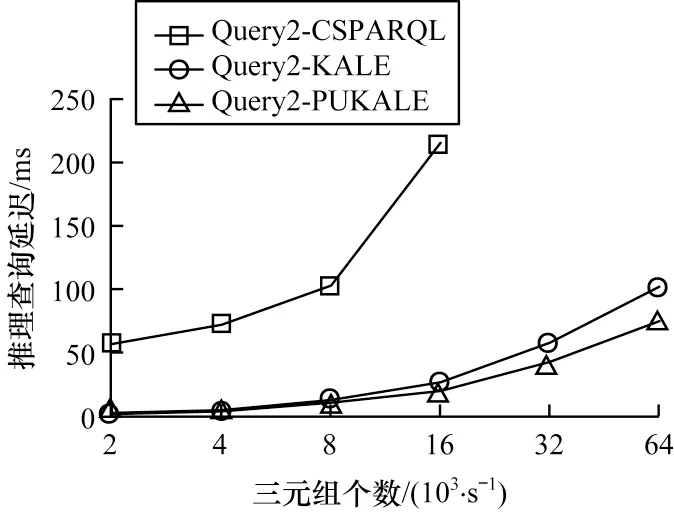
图8 规则2 推理查询时间延迟Fig.8 Rule2 reasoning and query time delay
实验结果表明:在相同的条件限制下,CSPARQL-engine 在PUKALE 作为推理引擎时的推理查询延迟明显低于传统的CSPARQL 规则推理引擎,而且传统的CSPARQL 规则推理引擎在三元组输入速率达到32 000 个/s 时失去响应,而在使用PUKALE 和KALE 作为推理引擎时,CSPARQLengine 还能正常工作;CSPARQL-engine 在使用PUKALE 作为推理引擎时的推理查询时延在三元组速率低于16 000 个/s 时与KALE 作为推理引擎时延迟差别不大,但在三元组速率达到32 000 个/s 或64 000 个/s 时,PUKALE 推理的性能略好于KALE,原因在于KALE 推理只有一个全局配置空间,在计算时对所有三元组都会计算一次,在三元组个数较多的情况下会有较多的无效计算,比较耗时,而PUKALE 采用多嵌入空间的方式,能过滤掉一些无效嵌入空间和三元组,因此,在三元组个数较多的情况下,其计算量较少,性能较高。
4 结束语
本文在知识表示学习模型KALE 的基础上引入多嵌入空间,提出一种PUKALE 模型,并设计3 种嵌入空间生成策略以及2 种嵌入空间选择策略。为了提升数据流推理引擎的推理效率,本文将PUKALE 模型嵌入实时数据流推理平台CSPARQL-engine,并与传统的CSPARQL 推理和KALE 推理进行对比。实验结果表明,相较KALE 的全量更新方式,PUKALE 中的增量更新方式在三元组数量较大、更新较频繁的场景下具有显著优势,在50 万图谱规模数据集中时间消耗约下降93%。此外,相较传统的CSPARQL 推理,PUKALE 推理的查询时间约缩短85%,且其更适用于大规模实时语义数据流推理查询任务。
PUKALE 模型在知识图谱在线更新时使用局部子嵌入空间训练,虽然避免了在整个图谱上重新训练,缩短了训练时间,然而,局部子空间并不能保存图谱全局结构信息,从而导致信息学习不全的问题。此外,PUKALE 利用TransE 的打分函数计算每个三元组的能量分数,其并不能很好地建模1~N、N~1、N~N的关系。因此,后续将为PUKALE 设计新的三元组学习及打分机制,弱化TransE 中三元组h+r≈t的严格限制,进一步提升PUKALE 模型对1~N、N~1、N~N关系的建模及适应能力。
