基于有向图模型的旅游领域命名实体识别
2022-02-24崔丽平古丽拉阿东别克王智悦
崔丽平,古丽拉·阿东别克,王智悦
(1.新疆大学 信息科学与工程学院,乌鲁木齐 830046;2.新疆多语种信息技术重点实验室,乌鲁木齐 830046;3.国家语言资源监测与研究少数民族语言中心哈萨克和柯尔克孜语文基地,乌鲁木齐 830046)
0 概述
随着信息化建设的加快,旅游逐渐成为人们休闲放松的重要方式。在旅游过程中,游客利用智能化的应用软件解决出行问题,例如景点的智能线路推荐、景区的智能问答系统实现等,旅游领域的命名实体识别(Named Entity Recognition,NER)作为智能化服务,逐渐引起研究人员的关注。
NER 是自然语言处理的一项研究任务,是信息检索、问答系统、机器翻译等诸多任务的基础。以往的NER 任务大多针对通用领域,近年来,NER 被应用在某些特定领域上,文献[1]在生物医学领域中利用支持向量机(Support Vector Machine,SVM)进行蛋白质、基因、核糖核酸等实体识别;文献[2]在社交媒体领域中对微博中的实体进行研究;文献[3]对电子病历中的实体进行研究。此外,研究人员对一些实体(如化学实体[4]、古籍文本中的人名[5]等)研究较少。
旅游领域的NER 研究相对较少。文献[6]提出基于隐马尔科夫模型(Hidden Markov Model,HMM)的旅游景点识别方法,该方法首次在旅游领域上进行NER 任务,但未充分考虑到上下文信息,解决一词多义的问题表现欠佳。因为很多实体在不同的语境中会代表不同的意思,例如“玉门关”在其他的文本中指的是地名,在旅游文本中指的是旅游景点玉门关。文献[7]提出使用层叠条件随机场(Conditional Random Field,CRF)识别景点名的方法,该方法过于依赖人工特征的建立,而且规则制定要耗费大量的人力,以致于不能广泛使用。文献[8]提出一种基于CNN-BiLSTM-CRF 的网络模型,避免了人工特征的构建,但该方法是基于字进行识别,未能充分利用词典信息。对于特定领域的NER 任务,词典是十分重要的外部资源,尤其是旅游文本中存在许多较长的景点名,例如阿尔金山自然保护区、巴音布鲁克天鹅湖等,可以利用词典获取这类词汇信息进而提高NER 的准确率。
本文提出一种有向图神经网络模型用于旅游领域中的命名实体识别。将预训练词向量通过具有多个卷积核的卷积神经网络(Convolutional Neural Network,CNN)提取字特征,基于词典构建每个句子的有向图,生成对应的邻接矩阵,通过边的连接融合词特征与字特征,将词向量和邻接矩阵输入图神经网络进行全局语义信息的提取,并引入CRF 得到最优序列。
1 相关工作
1.1 命名实体识别
NER 主要是基于规则和词典、基于统计机器学习、基于深度学习的方法。基于规则和词典的方法需要考虑数据的结构和特点,在特定的语料上取得较高的识别效果,但是依赖于大量规则的制定,手工编写规则又耗费时间和精力。基于统计机器学习的方法具有较好的移植性,对未登录词也具有较高的识别效果。常用的机 器学习模型有SVM[9]、HMM[10]、条件随机场[11]、最大熵(Maximum Entropy,ME)[12]等,这些方法都被成功地用于进行命名实体的序列化标注,然而都需要从文本中选择对该项任务有影响的各种特征,并将这些特征加入到词向量中,所以对语料库的依赖性很高。
随着深度学习在图像和语音领域的广泛应用,深度学习的众多方法也被应用在自然语言处理任务中。文献[13]提出基于神经网络的NER 方法,该方法利用具有固定大小的窗口在字符序列上滑动以提取特征。由于窗口的限制,该方法不能考虑到长距离字符之间的有效信息。循环神经网络(Recurrent Neural Network,RNN)的优势在于它通过记忆单元存储序列信息,但是在实际的应用中,RNN 的记忆功能会随着距离的变长而衰减,从而丧失学习远距离信息的能力。文献[14]基于RNN 提出长短时记忆(Long Short Term Memory,LSTM)神经网络,该方法利用门结构解决梯度消失的问题,然而3 个门单元增加了计算量。门循环单元(Gated Recurrent Unit,GRU)[15]只用了2 个门保存和更新信息,能够减少训练参数,缩短训练的时间。由于单向的RNN 不能满足NER 任务的需求,文献[16]提出双向LSTM模型(BiLSTM)用于序列标注任务,通过不同方向充分学习上下文特征。文献[17]构建BiLSTM 与CRF结合的模型,用CRF 规范实体标签的顺序。因此,BiLSTM+CRF结构成为NER 任务中的主流模型[18-19]。
文献[20]提出一种基于注意力机制的机器翻译模型,摒弃之前传统的Encoder-Decoder 模型结合RNN 或CNN 的固有模式,使用完全基于注意力机制的方式。由于Transformer 有强大的并行计算能力和长距离特征捕获能力,因此在机器翻译、预训练语言模型等语言理解任务中表现出色,逐渐取代RNN 结构成为提取特征的主流模型。在NER 任务上,基于自注意力的Transformer 编码器相较于LSTM 的效果较差,虽然自注意力可以进一步获得字词之间的关系,却无法捕捉字词间的顺序关系,并且经过自注意力计算后相对位置信息的特性会丢失。位置信息的丢失和方向信息的缺失影响NER 的效果[21]。
在英文的NER 任务上主要使用基于词的方法,但是在中文NER 任务中,由于中文存在严重的边界模糊现象,基于词的方法会产生歧义,进而影响NER结果。基于字的方法比基于词的方法更适合中文NER 任务[22-23],然而基于字的方法存在无法提取词汇信息的缺陷,这些潜在词的信息对NER 任务十分重要。因此,构造字词结合训练的方法[24-26]成为研究热点。
文献[27]提出Lattice LSTM 结构,使用词典动态将字词信息送入LSTM 结构中进行计算,在多个数据集上取得了最好成绩。RNN 的链式结构和缺乏全局语义的特点决定了基于RNN 的模型容易产生歧义,Lattice LSTM 结构如图1 所示。“市长”和“长江”两个词共同包含“长”字,RNN 会严格按照字和词汇出现的顺序进行信息传递,因此,“长”会优先被划分到左边的“市长”一词中[28],这显然是错误的。针对这个问题,本文使用图神经网络进行信息传递,在每次计算时,每个节点都会同时获得与其相连节点的信息,以削弱字符语序和匹配词序对识别的影响。
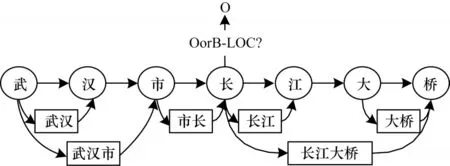
图1 Lattice LSTM 结构Fig.1 Structure of Lattice LSTM
1.2 图神经网络
图是由一系列对象(节点)和关系类型(边)组成的结构化数据。文献[29]提出图神经网络的概念。文献[30]提出基于谱图论的一种图卷积的变体。图神经网络 包括图注 意力网络[31](Graph Attention Network,GAT)、图生成网络[32]等。图神经网络在自然语言处理领域的应用逐渐成为研究热点,文献[33]提出将图卷积神经网络(GCN)用于文本分类,文献[34]利用依存句法分析构建图神经网络并用于关系抽取。
2 L-CGNN 模型
L-CGNN 模型的整体结构分为特征表示层、GGNN 层、CRF 层3 个部分。特征表示层的主要任务有:1)获取预训练词向量并使用具有不同卷积核的CNN 提取局部特征,充分获得每个字的局部特征;2)通过词典匹配句子中的词汇信息,构建句子的有向图结构得到相应的邻接矩阵用于表示字与词汇的关系。GGNN 层接收特征表示层传入的词向量矩阵和邻接矩阵,动态融合字词信息获得全局的语义表示。通过CRF 层进行解码获得最优标签序列。L-CGNN 模型结构如图2 所示。
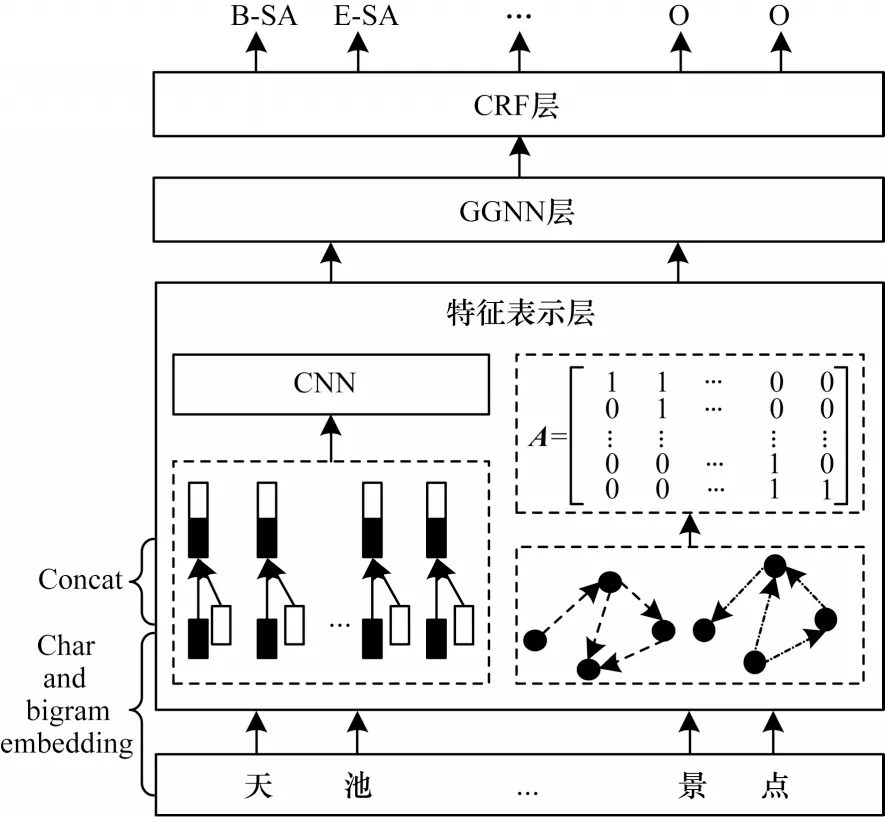
图2 L-CGNN 模型结构Fig.2 Structure of L-CGNN model
2.1 特征表示层
特征表示层首先对文本进行词向量表示,然后构建文本的图结构。
1)词向量
神经网络的输入是向量矩阵,因此先将字转换成向量矩阵形式。词向量给定包含n个字的句子S={c1,c2,…,cn},其中ci是第i个字,每个字通过查询预训练字向量表,转换为基于字的词向量,如式(1)所示:

其中:Ec为预训练词向量表。通过引入bigram 特征后得到的词向量是由基于字的向量、前向bigram 词向量、后向bigram 词向量3 个部分组成,以提高NER效果[35-36]。加入bigram 的词向量如式(2)所示:
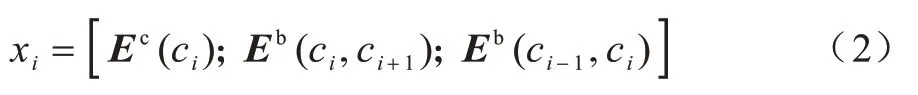
其中:Eb为预先训练的bigram 向量矩阵。因为旅游文本的实体名通常较长,并且嵌套现象严重,字向量和bigram 向量并不能很好表示局部信息。例如天山大峡谷是新疆著名景点,对于山字,除了字向量特征外,只能获取到天山和山天的信息,导致天山可能被当作单独的一个景点名被识别,然而这里的天山大峡谷是一个完整的景点名,需要更多的信息辅助识别。
卷积神经网络逐渐被用于自然语言任务中提取局部特征。CNN 结构包含卷积层、激活层、池化层,由于池化层会削弱位置特征的表达,而位置特征对于序列标注任务十分重要,所以本文没有使用池化操作,而是使用3 个不同大小的卷积核提取特征,对卷积核进行填充操作以获得相同维度的表示。3 个卷积核的大小为k×w,其中k依次取1、3、5,对应w依次取d、d+2、d+4,d为词向量xi的维度,局部特征提取流程如图3 所示。
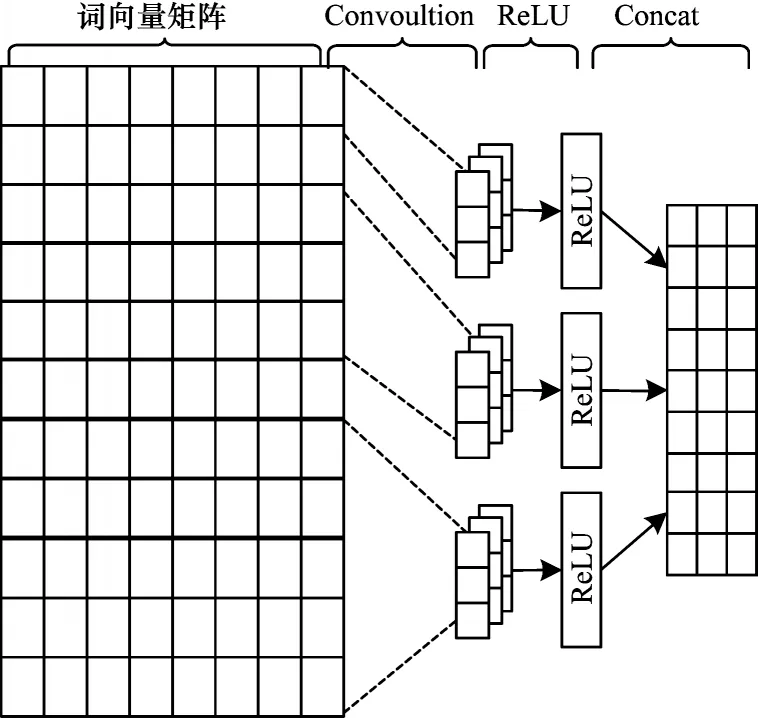
图3 局部特征提取流程Fig.3 Extraction procedure of local feature
局部特征的提取如式(3)、式(4)所示:
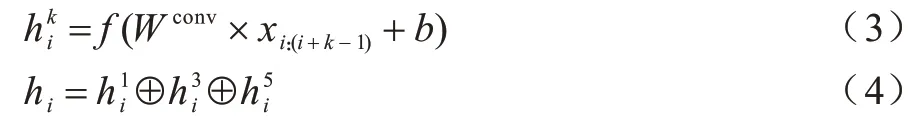
其中:Wconv∈ℝk×w;f为线性修正单元(ReLU);b为偏置项,将不同卷积核提取的局部特征拼接,得到最终的特征表示。
2)文本图结构
对于一个有n个节点的图,文本图结构可以用形状为n×n的邻接矩阵表示。本文中图结构的构建主要分为两个步骤。给定包含n个汉字的句子S={c1,c2,…,cn},将句子中每个字作为图的节点。首先连接所有相邻的节点,由于信息传递的方向性对于序列标注任务具有重要意义,因此在句子的第i个字和第i+1 个字之间(ci,ci+1之间)都连接2 条方向相反的边。其次连接词汇边,若i和j是第i个字从字典中匹配到词的开始节点和结束节点,本文在这2 个节点之间连 接2 条方向相反的 边,即 令Ai,j=1,Aj,i=1。字词结合的有向图如图4 所示。
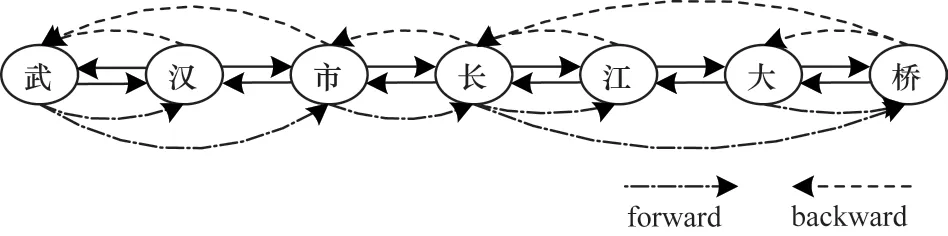
图4 字词结合的有向图Fig.4 Directed graph containing word-character
从图4 可以看出,如果一个节点在字典中匹配到词汇数不止一个,则该节点和与之构成词汇的所有节点之间都存在相应的边,这样在后续的传递过程中可以同时学习所有词汇与字的信息,有效消除字或词汇固有序列的影响。
2.2 基于门控机制图神经网络
门控图神经网络(GGNN)是一种基于GRU 的经典空间域消息传递模型[37],与GCN 等其他图神经结构相比,GGNN 在捕捉长距离依赖方面优于GCN,更适合于中文的NER 任务。本文将特征表示层得到的词向量和邻接矩阵传入GGNN 进行上下文语义学习。信息传递过程如式(5)~式(10)所示:
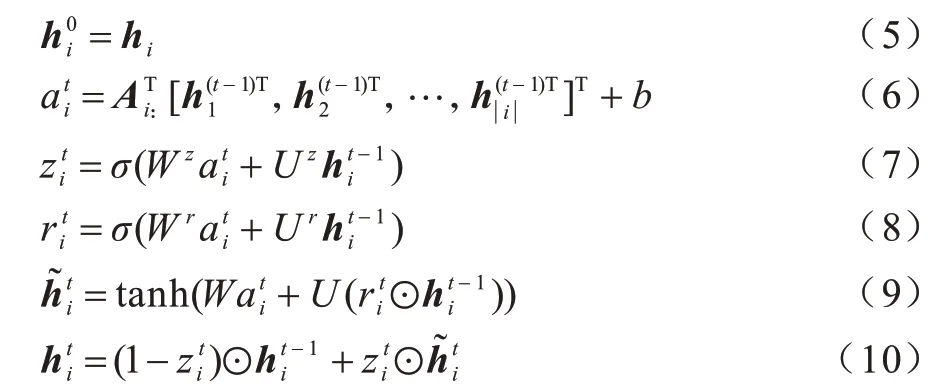
2.3 条件随机场层
条件随机模型可以看成是一个无向图模型或马尔科夫随机场,用于学习标签的约束,解决标签偏置问题。对于给定的观察列,通过计算整个标记序列的联合概率的方法获得最优标记序列。随机变量X={x1,x2,…,xn} 表示观察序列,随机变量Y={y1,y2,…,yn}表示相应的标记序列,P(Y|X)表示在给定X的条件下Y的条件概率分布,则CRF 计算如式(11)所示:
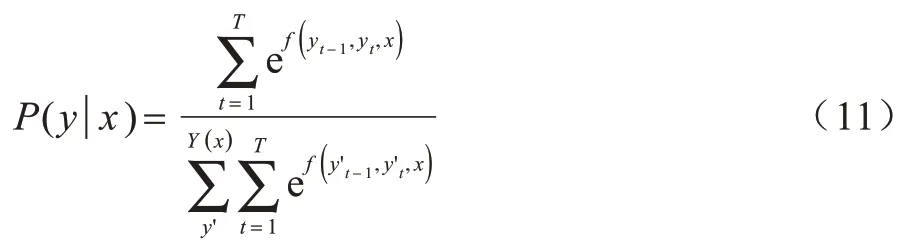
其中:Y(x)为所有可能的标签序列;f(yt-1,yt,x)用于计算yt-1到yt的转移分数和yt的分数。最后使得P(y|x)分数最大的标记序列y,即句子对应的实体标签序列如式(12)所示:

3 实验
3.1 数据集
本文实验的数据集包括旅游数据集和简历数据集。
Beats1作为一个综合性的音乐信息传播平台,将音乐的电台传播和网络传播的特点综合在一起,形成了具有实时性、主动性和社交性的全球网络音乐电台,加之自身运营平台的大众化优势、传播内容的专业化和覆盖范围的全球化,使其具备了成为世界性音乐电台的基本条件。
1)旅游数据集,目前还没有公认度较高的旅游领域数据集,本文从去哪儿网、携程、马蜂窝等旅游网站收集有关新疆的旅游攻略,经过去除空白行、空格、非文本相关内容等预处理操作,得到旅游领域文本1 200 余篇。旅游数据集使用NLTK 工具对预处理后的语料进行半自动化标注,之后进行人工校对、标注,构建用于旅游领域实体识别的训练集、评估集和测试集,并通过高德地图旅游景点数据和旅游网站检索构造旅游景点词典。
针对旅游领域实体类型的定义,本文参考文献[7]的分类标准,将旅游领域实体分为地名、景点名、特色美食3 大类。考虑到新疆地域的特点,本文新增了人名、民族2 种实体类型,采用BIOES 标注体系进行实体标注,例如天山大峡谷位于乌鲁木齐县境内,按照采用的标注体系可以标记为“天/B-SA 山/I-SA 大/I-SA 峡/I-SA 谷/E-SA 位/O 于/O 乌/B-LOC鲁/I-LOC 木/I-LOC 齐/I-LOC 县/E-LOC 境/O 内/O”。旅游数据集训练集合计4 176,验证集合计541,测试集合计540。旅游数据集实体信息如表1 所示。
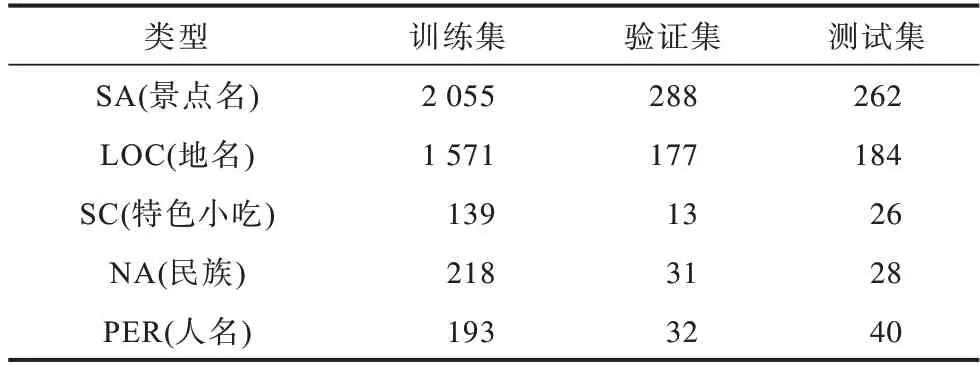
表1 旅游数据集实体信息Table 1 Entities information of tourism dataset
2)简历数据集,文献[27]提出该数据集共有CONT(country)、EDU(educational institution)、LOC、PER、ORG、PRO(profession)、RACE(ethics background)和TITLE(job title)8 种不同的实体类型。
旅游数据集和简历数据集的数据统计如表2所示。
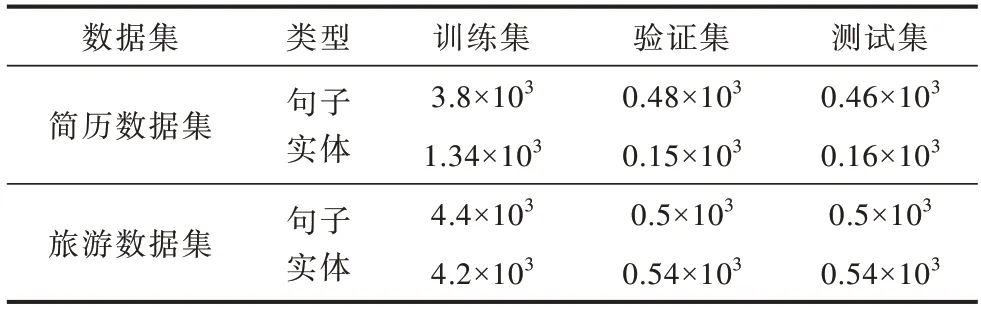
表2 旅游数据集和简历数据集的数据统计Table 2 Data statistics of tourism and resume datasets
实验使用的预训练词向量表来源于文献[38],通用的词典来源于文献[27],该字典包含704.4×103个词,其中单个字有5.7×103个,2个字构成的词有291.5×103个,3 个字构成的词有278.1×103个,其他129.1×103个。
3.2 模型对比
为验证模型的有效性,本文使用现有的应用于旅游领域NER 任务的机器学习方法和主流的深度学习模型进行对比。
1)HMM 模型[6],以HMM 算法为原理,用于旅游领域NER 任务;
3)BiLSTM+CRF 模型是NER 任务的经典模型;
4)BiLSTM+CRF(融 合bigram)模型为验 证bigram 对NER 任务的作用,设计包含bigram 特征的BiLSTM+CRF 模型进行对比分析;
5)Transformer+CRF 模型[21],Transformer 具有强大的特征提取能力,在很多的自然语言处理任务中逐渐取代RNN 模型,所以本文加入该模型的对比;
6)ID-CNN+CRF 模型[24],膨胀卷积、空洞卷积主要是通过扩大感受域的方法获得更广泛的序列信息,在英文NER 任务上曾取得最佳成绩;
7)Lattice LSTM 模型[27],该模型是字词结合训练的代表性方法,创造性地将字符和词汇通过网格的方法融合在一起,并且在MSRA、Weibo、OntoNotes4、Resume 这4 个数据集上取得最好成绩;
8)Bert+CRF 模型,Bert 作为一种预训练模型,在自然语言处理的多项任务中逐渐成为主流模型。
3.3 实验环境与参数设置
本文模型使用的GPU 为GeForce GTX 1080Ti,操作系统为Ubuntu18.04,编程语言为Python3.6,框架为PyTorch 1.1.0。为实体识别算法的一致性,本文设置初始化参数,预训练词向量维度为300,GGNN 神经元个数为200,丢码率为0.5,初始学习率为0.001,衰减率为0.05。
3.4 评价指标
评价指标采用准确率(P)、召回率(R)和F1 值,如式(13)、式(14)所示:
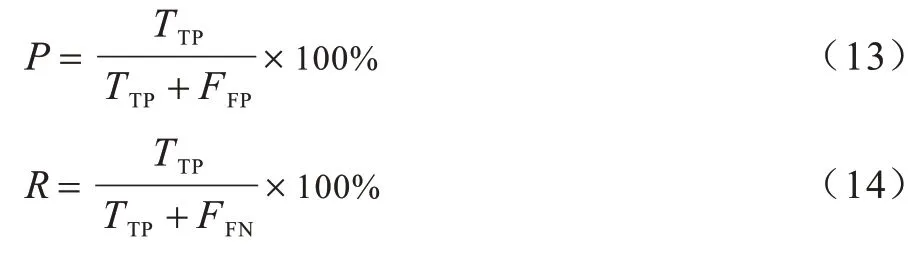
其中:TTP为正确识别的实体个数;FFP为识别不相关的实体个数;FFN为数据集中存在且未被识别出来的实体个数。
通常精确率和召回率的数值越高,代表实验的效果好。一般精确率和召回率会出现矛盾的情况,即精确率越高,召回率越低。F1 值综合考量两者的加权调和平均值,F1 值如式(15)所示:

3.5 实验结果分析
在旅游领域NER 数据集上,本文选择HMM、CRF、BiLSTM+CRF、BiLSTM+CRF(融合bigram)、Transformer+CRF、ID-CNN+CRF、Lattice LSTM、Bert+CRF 等模型进行实验。不同模型的实验结果对比如表3 所示,*Dic 为自建词典。
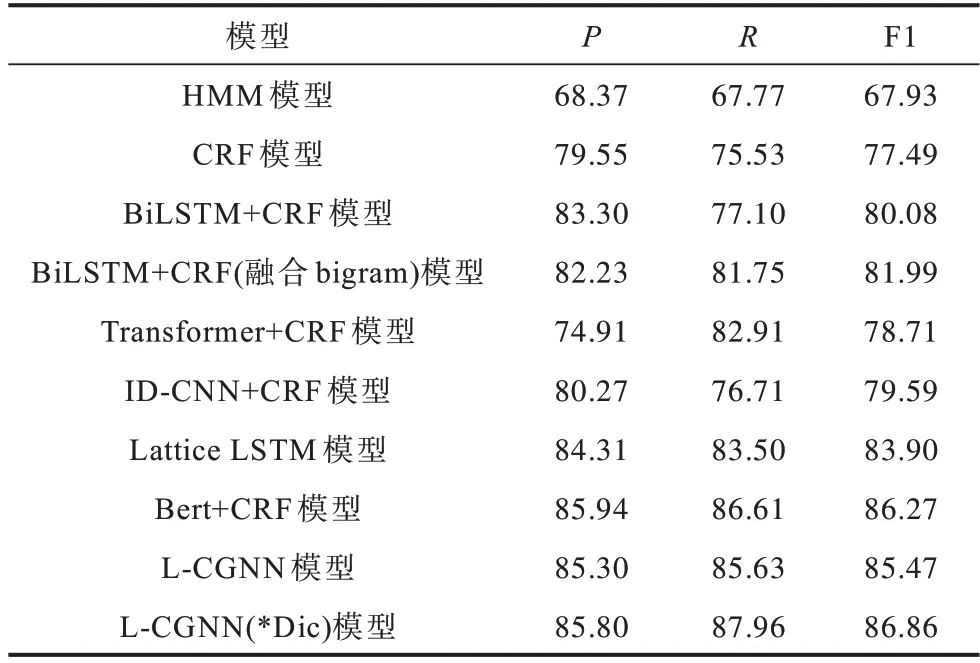
表3 在旅游数据集上不同模型的实验结果对比Table 3 Experimental results comparison among different models on tourism dataset %
从表3 可以看出,HMM 和CRF 模型在旅游领域NER 任务上的P、R、F1 数值都低于其他深度学习模型,HMM 模型仅依赖于当前状态和对应的观察对象,序列标注问题不仅与单个词相关,还与观察序列的长度、单词的上下文等相关。CRF 模型解决了标注偏置问题,识别效果相较于HMM 模型有很大程度的提高。由于CRF 模型不能充分捕捉上下文语义信息,因此在不规范的旅游文本上识别效果不佳。
与ID-CNN+CRF模型相比,BiLSTM+CRF模型的识别效果较优,BiLSTM 模型能够获得长距离依赖关系,加强对语义的理解,ID-CNN 模型虽然通过扩大感受域的方法加强距离关系的捕捉,但仍存在不足。BiLSTM+CRF 模型融合bigram 特征后,对实体识别的效果略有提升,表明加入bigram 特征可以提高NER 效果。
对比Transformer+CRF 与BiLSTM+CRF 模型,Transformer+CRF 模型在命名实体识别效果上低于BiLSTM+CRF模型。Transformer在方向性、相对位置、稀疏性方面不适合NER 任务。虽然Transformer对位置信息进行编码,但在NER 任务上,效果仍然不理想。
Lattice LSTM 模型通过字典的方式融合词汇信息与字符信息以提升NER 效果,由于其严格的序列学习特性,每次都会按照匹配词出现的顺序学习,因此会出现歧义现象。Lattice LSTM 模型实验效果相较于L-CGNN 模型较差。
Bert+CRF 模型在该任务上的结果优于Lattice LSTM 模型。Bert 利用Transformer 编码器提高特征提取能力,获得充分的上下文信息。对于旅游领域,词典是非常重要的外部资源,对于NER 等任务具有十分重要的意义。因此,L-CGNN(*Dic)模型在旅游数据集上识别效果优于Bert+CRF 模型。
本文提出L-CGNN 模型通过词典构建有向图结构,利用图神经网络获得语义信息,不仅融合字符与词汇信息,还可以利用图特殊的结构进行传递。在每次计算时,L-CGNN 模型同时将节点匹配到与所有词汇信息相融合,从而减少词序导致的歧义现象。
为验证L-CGNN 模型解决匹配词先后顺序对NER 效果的影响,本文在公开的简历数据集上进行实验,实验结果如表4 所示。
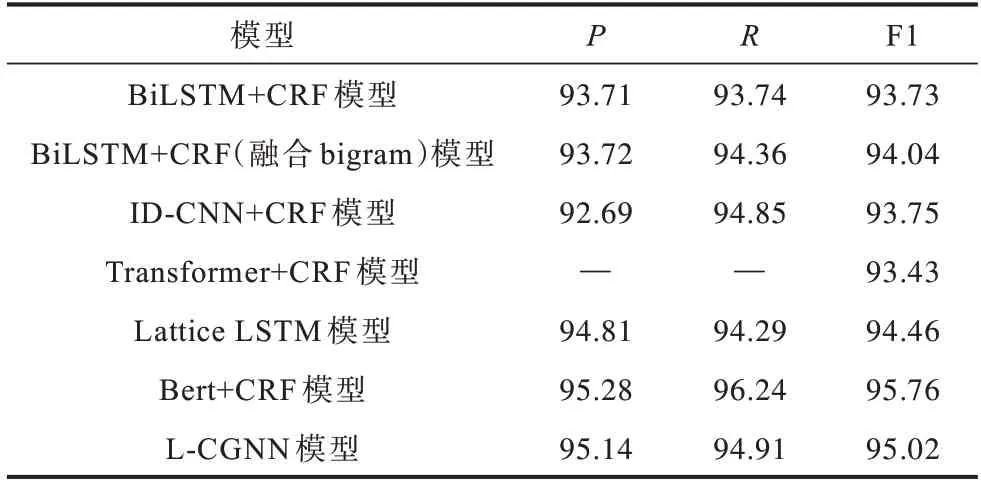
表4 在简历数据集上不同模型的实验结果对比Table 4 Experimental results comparison among different models on resume dataset %
从表4 可以看出,Transformer+CRF 中的P、R没有公布,所以未能获取。与其他模型(除Bert+CRF模型外)相比,L-CGNN 模型在P、R、F1 值上的分数较高。本文模型略低于Bert+CRF 模型,主要是因为有向图结果依赖于字典的质量,通用的词典质量低于专有领域词典,未能取得与旅游领域一样高于Bert+CRF 模型的数值。这组实验进一步表明L-CGNN 模型具有一定的泛化能力。
3.6 消融实验
为探讨不同特征对实验结果的影响,本文分别去除某些特征进行命名实体的识别,实验结果如表5所示。W/O 代表去除该特征,例如W/O lexicon 代表去除字典信息。
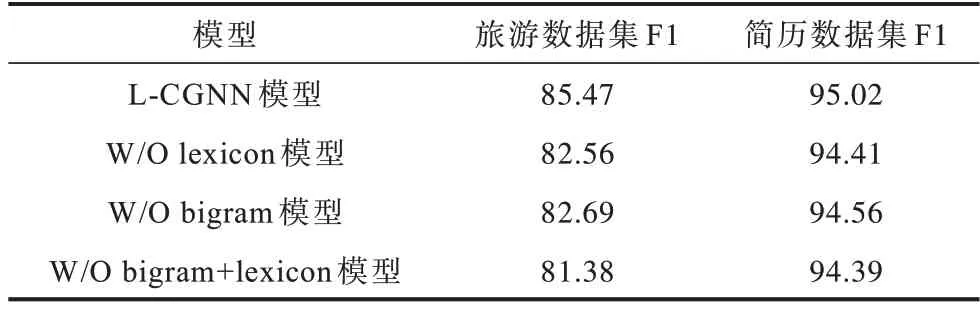
表5 不同特征对实验结果的影响Table 5 Influence of different features on experimental results %
从表5 可以看出,在两个数据集上,如果去除字典特征,最终的识别效果较差。同样的,在去除bigram 特征的情况下,模型的识别效果也会被削弱。同时去除字典和bigram 两个特征后,F1 值有了很大程度降低,说明加入的特征能够改善最终的识别效果。
3.7 收敛速率与资源消耗对比
为进一步说明本文模型的性能,本文对比BiLSTM+CRF、Lattice LSTM 和L-CGNN 这3 种模型的收敛速度。不同模型的收敛曲线对比如图5所示。
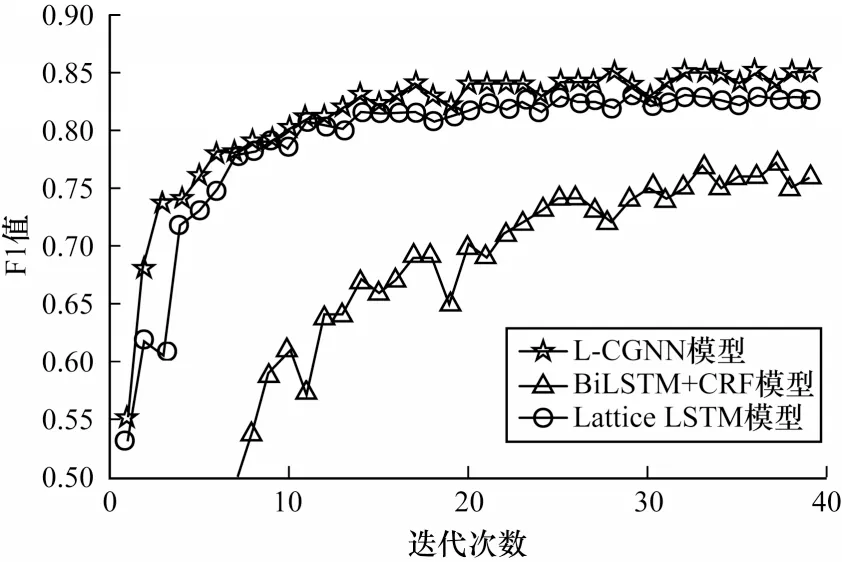
图5 不同模型的收敛曲线对比Fig.5 Convergence curves comparison among different models
从图5 可以看出,L-CGNN 模型的收敛速度优于其他模型。BiLSTM+CRF 模型通过双向LSTM 学习,使得信息更新较慢,并且没有包含任何词汇特征,因此,识别速率提升较慢。Lattice LSTM 和L-CGNN 模型都包含字典外部信息,识别效果相对较好。在一段时间后,L-CGNN 模型识别效果明显优于Lattice LSTM 模型,说明本文模型在融合词汇方面具有较优的效果。
在资源消耗方面,本文从训练时间上分别对HMM、CRF、BiLSTM+CRF、Lattice LSTM、L-CGNN等模型进行对比实验,结果如表6 所示。

表6 在旅游数据集上不同模型的训练时间对比Table 6 Training time comparison among different models on tourism dataset s
从表6 可以看出,HMM 和CRF 模型是基于机器学习方法,所以训练速度较快,但识别效果欠佳。相比BiLSTM+CRF 模型,由于L-CGNN 模型构建邻接矩阵,因此在训练上的时间消耗略大。对比融合词典的Lattice LSTM 模型,L-CGNN 模型的时间消耗较低,且具有最优的识别效果。
4 结束语
针对旅游领域的命名实体识别任务,本文提出基于字典构建文本的有向图结构模型,通过卷积神经网络提取字特征,利用词典构建句子的有向图,生成对应的邻接矩阵,并将包含局部特征的词向量和邻接矩阵输入图神经网络中,引入条件随机场得到最优的标记序列。实验结果表明,相比Lattice LSTM、ID-CNN+CRF、CRF 等模型,本文模型具有较高的识别准确率。后续将研究更有效的图神经网络,用于命名实体识别,进一步提高实体识别准确率。
