基于四元数胶囊网络的知识图谱补全模型
2022-02-24王思懿李冠宇祁瑞华王维美
陈 恒,王思懿,李冠宇,祁瑞华,杨 晨,王维美
(1.大连外国语大学 语言智能研究中心,辽宁 大连 116044;2.大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 概述
知识图谱(Knowledge Graph,KG)是一种规模较大的语义网络系统,旨在描述客观真实世界中实体或概念之间的关联关系。KG 在各领域的应用越来越广泛,YAGO[1]、Freebase[2]和DBpedia[3]等众多知识图谱采用RDF 三元组的形式描述真实世界中的关系和头、尾实体,即(主语,谓语,宾语),例如(Chicago,City_Of,US)。知识图谱已被广泛应用于许多行业与领域,如推荐系统[4]、问答系统[5]、搜索系统[6]和自然语言处理[7]。尽管KG 应用场景较为广泛,但是知识图谱仍不完整,即缺少大量真实客观三元组[8-11]。为此,研究人员提出许多典型嵌入模型,如TransE[12]、TransH[13]、TransR[14]等模型,这些模型用来学习KG 中实体和关系的低维嵌入。TransE 将知识图谱中的关系解释为头实体到尾实体的平移,但不能建模较为复杂的关系模式。因此,TransH 和TransR 提出了新的解决方法,便于有效建模M-M 等关系。Trans 系列模型面向KG 中的实体和关系进行表示学习,该类模型在建模和推理缺失三元组方面效果显著[15-16]。
TransE、DistMult[17]和ComplEx[18]作为典型的嵌入模型,仅能挖掘实体之间的线性关联,不能有效捕获三元组空间结构信息。目前,很多神经网络模型被应用于知识图谱补全任务[19-20]。文献[19]提出基于三元组整体架构的卷积神经网络模型,ConvKB 在基准数据集WN18RR 和FB15K-237 上具有较好的链接预测结果。大部分KG 嵌入模型通过对三元组同维度条目进行建模表示,每个维度获取三元组相应的属性信息。但是,上述嵌入表示模型并未利用“深层”结构来挖掘和建模实体和关系的特征信息。文献[21]引入胶囊网络(CapsNet),CapsNet 利用一组神经元获取图形中的对象,然后通过动态路由机制确定从父胶囊到子胶囊的连接。因此,胶囊网络不仅能基于统计信息提取特征,还可以解释特征。与CNN 相比,胶囊网络的优势在于:在CNN 中,卷积层的每个值都是线性权重的总和,即标量,在CapsNet 中,胶囊是一组神经元,即一个向量,其中包含对象的方向、状态和其他特征[21],因此,与神经元相比,胶囊可以在嵌入三元组中编码更多特征,深层次挖掘各维度属性信息;CNN 每层都需要相同的卷积操作,因此需要大量网络数据学习特征,与CNN不同,胶囊网络可以学习胶囊中的特征变量,并最大限度地保留有价值的信息[22],因此胶囊网络利用较少的数据学习推断特征变量,并达到CNN 预期效果;CNN 不断池化会丢失大量重要的特征信息,不能有效处理图像的模糊性问题,与CNN 不同,胶囊网络每个胶囊携带大量信息,这些信息会在整个网络保存[21],因此胶囊网络可以有效处理图像的模糊性问题。
近年来,四元数和神经网络模型的组合受到越来越多的关注,原因在于四元数允许神经网络模型在学习过程中使用比CNN 更少的参数来编码输入特征组之间的潜在依存关系。深层四元数网络[23]、深层四元数卷积神经网络[24]和深层四元数循环神经网络[25]已经用于图像和语言处理任务。然而,在知识图谱补全领域,关于四元数和胶囊网络相结合的工作较少,因此将四元数引入胶囊网络,以此探索优化的胶囊网络模型在链接预测和三元组分类任务的应用。本文将实体、关系的四元数嵌入向量作为优化的胶囊网络模型的输入,以此捕获实体和关系在低维空间中的联系,为评估四元数嵌入的胶囊神经网络模 型,使用FB15K、WN18RR 和FB15K-237 进行链接预测实验。
1 相关工作
1.1 基准嵌入模型
TransE 模型将知识图谱中的关系解释为头实体到尾实体的平移,例如,对于事实三元组(Chicago,City_Of,US),即h+r≈t,如图1所示。在TransE 中,认为||h+r-t||无限接近零,即t无限接近 于h+r[26]。TransE 的打分函数如式(1)所示:


图1 实体和关系的低维嵌入Fig.1 Low dimensional embedding of entities and relationships
TransE 模型在处理一对一关系模式方面效果显著,但不适合一对多/多对一关系。因此,TransH 模型提出任意一个实体在不同的关系下应该拥有不同的表示[27]。TransH 的打分函数如式(2)所示。区别于TransH,TransR 认为一个实体是多种属性的综合体,且不同的关系应拥有不同的语义空间。式(3)为TransR 模型的打分函数。

DisMult 是RESCAL 的简化模型,因此只能建模知识图谱中存在的对称关系,不能建模知识图谱中其他类型的关系。针对DisMult 存在的问题,ComplEx 将DisMult 扩展到复数空间。在ComplEx模型中,头实体、关系和尾实体的嵌入向量h、r、t不再投影到实数空间,而是映射于复数空间。DistMult和ComplEx 打分函数如式(4)和式(5)所示:
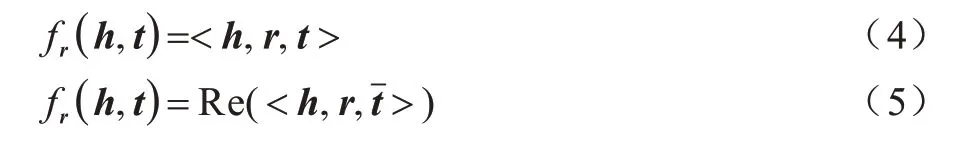
1.2 神经网络模型
典型的嵌入模型仅能挖掘实体之间的线性关联而不能有效捕获三元组空间结构信息。为解决该问题,研究者开始应用CNN 补全知识图谱,DKRL[28]模型利用两种编码器来编码实体描述信息,分别是连续词袋模型和CNN 模型,之后利用三元组的全局特性和实体的描述资源进行表示学习。DKRL 的打分函数如式(6)所示:

ConvE[29]随机初始化头实体和关系,通过卷积和全连接操作建模三元组,最终权重矩阵和尾实体向量进行点乘运算,得分用于判定当前三元组的可信度。在ConvE 中,仅将头实体嵌入和关系嵌入视为CNN 模型的输入,并未考虑三元组全局特性,为解决此问题,ConvKB 以嵌入三元组(h,r,t)为输入,和不同过滤器进行卷积操作,从而获取三元组的全局特性。ConvE 和ConvKB 的打分函数如式(7)和式(8)所示:
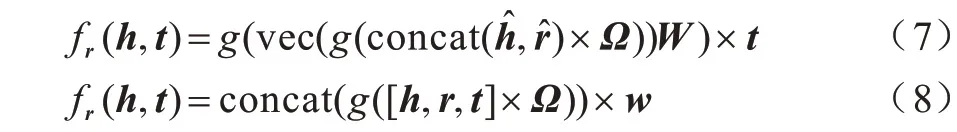
ConvKB 模型利用卷积神经网络对实体和关系进行编码,无法捕获三元组空间结构信息。参照文献[21],本文将神经元替换为胶囊,以学习实体和关系的矢 量表示。CapsE[20]使 用TransE 训练的实 体、关系嵌入作为胶囊网络输入,但在表征不同实体外部依赖关系方面表现力仍然较差。因此,本文引入四元数编码三元组结构信息,以尽可能全面地捕获三元组的全局特性,从而有效补全知识图谱中丢失的三元组。实验结果表明,在KGC 补全任务中,四元数嵌入的胶囊网络知识图谱补全方法较CapsE 效果更优。CapsE 的打分函数如式(9)所示:
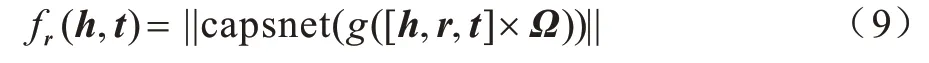
上述知识图谱补全模型的打分函数如表1 所示。

表1 不同模型的打分函数及参数Table 1 Scoring functions and parameters of different models
2 模型设计
2.1 相关算法
四元数是包含一个实数和3 个虚数单位的超复数,其表示形式为Q=a+bi+cj+dk,其中,a、b、c、d是实数,i、j、k 是虚数单位。四元数嵌入模型QuaR[30]具有以下优点:1)四元数嵌入模型参数较少,计算复杂度低;2)四元数嵌入模型结构简单,易于扩展,在知识图谱补全领域效果显著。本文使用由QuaR 模型训练的实体和关系的四元数嵌入矩阵作为胶囊网络模型的输入。与结合TransE 的胶囊网络模型CapsE 不同,本文采用QuaR 模型训练得到的实体和关系的超复数嵌入,将更加准确和直观。受欧拉四元数扩展公式的启发,在QuaR 模型中,实体被表示为四元数,关系则被建模为四元数空间中的旋转。另外,与实数模型TransE 相比,四元数融入胶囊神经网络可以建模和推理更多的关系[30]。与TransE 相比,QuaR 模型可以建模对称与反对称等多种关系类型,因此,在四元数嵌入的胶囊网络模型中可以推理更多的关系模式,准确率更高。
优化的胶囊神经网络算法如算法1 所示。在四元数胶囊网络算法中,本文使用QuaR 模型训练生成的四元数矩阵来初始化实体和关系嵌入(分别见第3 行和第4 行)。在算法迭代过程中,采用卷积操作和内积运算来训练矩阵。首先,从训练集S中抽取一个小批量数据集b(见第6 行)。其次,对数据集中每个三元组,选取负样本S′(错误三元组),其中负样本从正例三元组获取得到(见第9 行)。最后,对抽样得到的小批量数据集进行分数预测和损失校正(分别见第12 行和第14 行)。另外,使用Adam 优化器更新模型参数,算法依据验证集性能而中止。最终,本文将KG=(E,R,T)表示为知识图谱,实体的集合表示为E,关系的集合表示为R,三元组的集合表示为T。
算法1胶囊网络算法

2.2 模型架构
胶囊网络模型由输入层、卷积层、初级胶囊层、数字胶囊层和输出层5 个部分构成。其中,胶囊神经网络的隐藏层包含卷积层、初级胶囊层和数字胶囊层。胶囊网络的卷积层通过不同的卷积核在输入矩阵的不同位置提取特征,以获得包含多个神经元的特征矩阵。初级胶囊层将卷积操作生成的特征图重组成相应的胶囊,之后通过动态路由算法将初级胶囊层与数字胶囊层连接以获得输出值。数字胶囊层位于卷积层和初级胶囊层后,其功能是将卷积层、初级胶囊层中具有类别区分性的局部信息进行整合,以在整个胶囊神经网络中执行回归分类任务。
本文优化的四元数胶囊模型如图2 所示。该模型主要分为4 个层次:第1 层为卷积层,本文使用数百个滤波器(卷积核)在三元组矩阵上重复卷积操作;第2 层为主胶囊层,该层将卷积操作生成的特征图重构成相应的胶囊,从而最大限度地保留有价值的信息;第3 层为次胶囊层,父胶囊与权重矩阵相乘生成较小维度的子胶囊,同时得到多个连续矢量;第4 层为内积胶囊层,连续矢量与权重矩阵执行内积操作生成相应的三元组分数,该分数用于判断给定三元组的正确性。
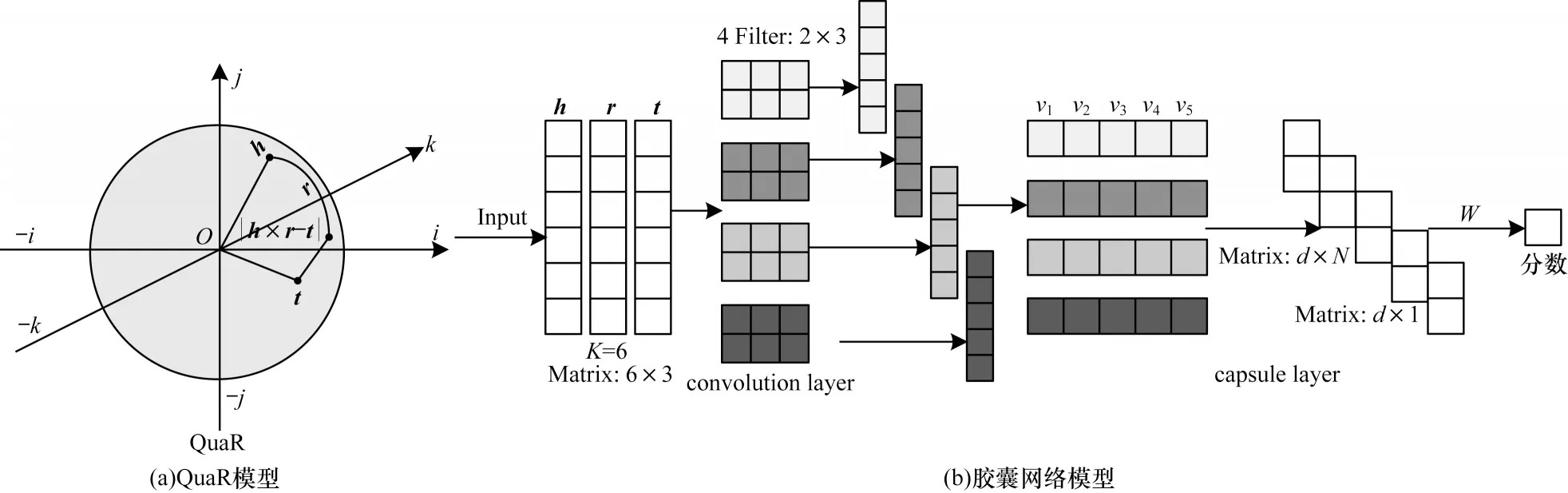
图2 四元数胶囊模型Fig.2 Quaternion capsule model
在卷积层中,首先将h、r、t分别表示为K维四元数向量,其表示形式为h=(a1+b1i+c1j+d1k,…,aK+bKi+cKj+dKk),其中,ai表示头实体的实部,bi、ci、di表示头实 体的虚部,ai、bi、ci、di随机初始化或 由QuaR 模型训练得到,i、j、k 是虚数单位,即指在超复数空间中的旋转。与结合实数嵌入的胶囊网络模型CapsE 不同,本文采用QuaR 模型训练得到的超复数嵌入表示实体和关系,这可以深层次挖掘实体和关系之间的复杂联系。参照文献[12],本文将超复数嵌入三元组向量h、r、t定义成一个三元组嵌入矩阵A=[h,r,t]∈QK×3,其中,表示A的第i行。然后,本文使用滤波器(卷积核)ω∈Q2×3与A=[h,r,t]∈QK×3重复卷积操作,最终生成特征 图q=[q1,q2,…,qK-1]∈QK,qi=g(ω·Ai,:+b),·表示点积,其中,b∈Q是偏差项,g是非线性激活函数,例如ReLU或Sigmoid。在卷积层中,本文使用四元数乘法和四元数加法计算并编码多个向量胶囊,得到包含多个向量胶囊的特征矩阵。由此,相关的四元数运算规则如式(10)~式(13)所示:

将Q1=a+bi+cj+dk 和Q2=a′+b′i+c′j+d′k 相加,得到:
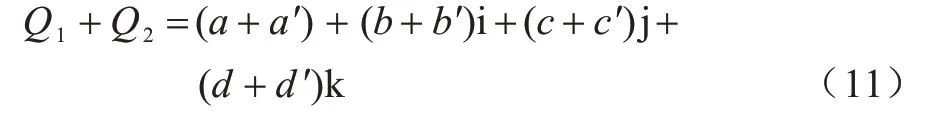
将Q1=a+bi+cj+dk 和Q2=a′+b′i+c′j+d′k 相乘,得到:
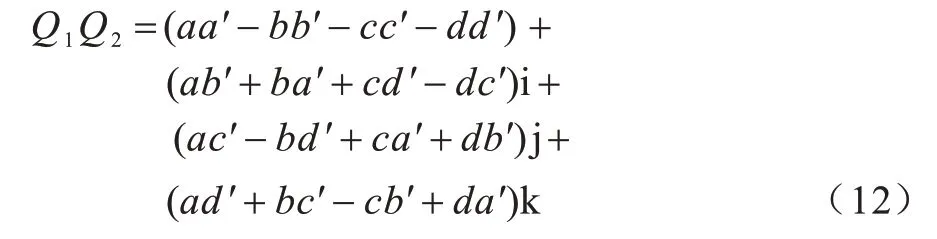
将Q1=a+bi+cj+dk 和Q2=a′+b′i+c′j+d′k 相除,得到:
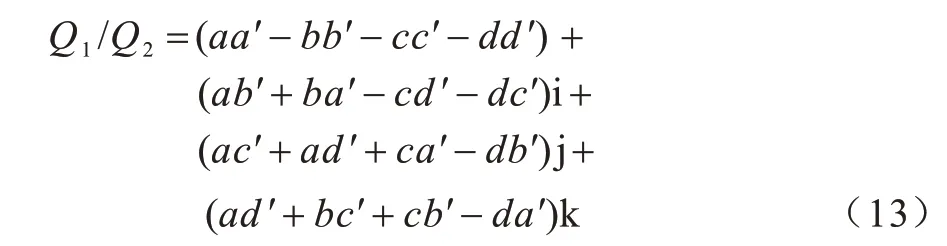
在主胶囊层中,本文将卷积操作生成的多个特征向量重组以构建胶囊(v1,v2,v3,v4,v5)。胶囊是一组神经元的集合,vi包含4 个神经元。在次胶囊层中,本文将重组后的父胶囊和变换矩阵相乘生成低维度的子胶囊,并得到一个向量s;最终,向量s和权重执行内积操作生成相应分数,该得分用于确定一个事实三元组的准确与否。本文将嵌入维度设置为K=6,卷积核的数量为ω=4,主胶囊层内神经元的数目定义为4,次胶囊内神经元的数目定义为2。在胶囊层中,本文使用四元数乘法、四元数加法和四元数范数计算并编码多个向量胶囊,从而深层次挖掘实体和关系之间复杂的语义联系。
在所有胶囊层中,首先将每个胶囊i∈{1,2,…,K}向量输出值定义为Vi∈QN×1,然后矢量输出Vi和变换矩阵Wi∈Qd×N相乘产生和不同权 重内积生成胶囊矢量s,最终压缩矢量e与W执行点乘运算获得对应得分,其值用来判断三元组正确性,如式(14)~式(17)所示:
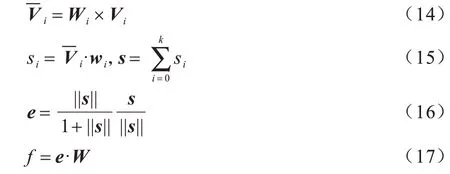
四元数胶囊网络模型的评分函数如式(8)所示:

其中:Ψ表示卷积核的数量;*表示卷积操作;Caps 代表胶囊神经网络运算。另外,四元数胶囊网络模型的损失函数如式(19)所示:

其中:T表示正确的三元组;T′表示错误的三元组,负样本由正确三元组生成;θ的数值通过式(20)计算。

负样本的组建方式如式(21)所示,即把正例三元组中的尾实体与头实体依次使用其他实体取代,即不能同时替换。
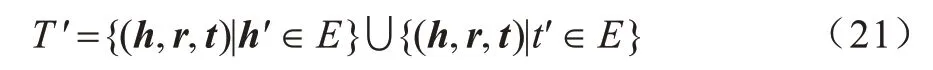
本文利用Adam[31]最小化四元数胶囊网络模型的目标函数,将Re LU 视为模型的激活函数。
3 KGC 实验
3.1 数据集
本文使用从Freebase 和WordNet 中抽取的FB15K[12]、FB15K-237[32]和WN18RR[29]3 个基准数据集进行知识图谱补全实验。参照文献[32],将数据集FB15K 中反转事实三元组丢弃,得到新数据集FB15K-237。同理,本文将数据集WN18 中反转事实三元组丢弃,得到新数据集WN18RR。
数据集的统计如表2 所示。

表2 数据集统计Table 2 Dataset statistics
3.2 参数设置
本文利用ConvKB[19]模型和QuaR[30]模型实现基于四元数嵌入的胶囊网络方法。在ConvKB 中,本文设置滤波器(卷积核)的数量为|ω|=N∈{50,100,200,400,600},其中,Adam 学习率设定为γ∈{0.000 01,0.000 05,0.000 1,0.000 5}。在实验中,训练胶囊网络模型100 次记录一次Hit@10,最优Hit@10 超参数如下:在 FBI5K-237 上,N=50,K=100,γ=0.000 01;在WN18RR 上,N=400,K=100,γ=0.000 05。
在实验中,本文将批量大小定义成128,动态路由过程的迭代次数定义为m∈{1,3,5,7},次胶囊层内神经元数目定义为8,权重矩阵W随机初始化生成。本文训练胶囊网络模型多达1 000 次,其中,训练胶囊网络模型100 次记录一次Hit@10,最优Hit@10 超参数如下:在数据集FBI5K-237 上,N=50,K=100,γ=0.000 1;在数据集WN18RR 上,N=400,K=100,γ=0.000 05。
3.3 链接预测
3.3.1 实验设置
链接预测即发现知识图谱中缺失的链接(事实三元组)。对于RDF 三元组(Chicago,City_Of,?),即预测并补全该元组中缺失的尾实体。本文参考TransE 模型,将测试数据集中的三元组依次移除头实体或者尾实体后,采用评价函数对每个新三元组得分进行排名。
3.3.2 评估指标
本文采用3 个评价标准:正确实体的平均排名MR、正确实体在TopN的比例Hit@N和正确实体的平均倒数排名MRR。其中,MR 越小、MRR 越大或者Hit@N 越大,代表模型效果越好。
3.3.3 实验分析
本文在如下环境中进行链接预测实验:Window 7操作系统,64 位处理器,GPU 类型为1755 MHz,24GD6 GeForce RTX 2080 Ti。数据集WN18RR 和FB15K-237在不同模型下的实验结果如表3 所示,其中粗体表示最优结果。

表3 不同模型在WN18RR 和FB15k-237 数据集上的实验结果Table 3 Experimental results of different models on WN18RR and FB15K-237 datasets
分析表3 可以看出:四元数胶囊网络模型在WN18RR 和FB15K-237 上取得较好的实验结果。
在FB15K-237 上,四元数胶囊网络方法获得最高Hit@3、Hit@10 和最好MRR。具体分析如下:
1)本文方法优于CapsE 模型,但Hit@1 除外;本文方法较CapsE 在MRR 上提高了4.4%,在Hit@10 上提高了2.5 个百分点。由此可知,四元数编码序列输入的胶囊网络模型在很多实验指标上要优于结合实值嵌入的胶囊网络模型。这也说明四元数在表征不同实体之间的外部依存关系方面性能强大。
2)本文方法 较ConvE 在Hit@3 上提高了7.9 个百分点,在Hit@10 上提高了11.7 个百分点。由此可知,与卷积神经网络模型相比,胶囊网络模型可以在嵌入三元组中编码更多的特征信息,以捕获实体和关系在低维空间中的联系。
在WN18RR 数据集上,四元数胶囊网络方法获得最高Hit@1、Hit@10 和最好MR,具体分析如下:
1)本文方法优于RotatE 模型,但MRR 除外;本文方法较RotatE 在Hit@3 上提高了2.2 个百分点,在Hit@10 上提高了2.1 个百分点。由此可知,和复数模型相比,结合四元数嵌入的胶囊网络模型表现能力更优,原因在于四元数作为一种超复数,是复数在更高维度上的扩展。最终,训练得到的实体、关系超复数嵌入结合胶囊网络可以深层次挖掘实体及关系间存在的某种关联。
2)本文方法较ConvKB 在MR 上提高了8.1%,在Hit@10 上提高了2.5 个百分点;本文方法较ConvE在Hit@1 上提高了3.0 个百分点,在Hit@10 上提高了7.2 个百分点。由此可知,和CNN 模型相比,胶囊网络可以学习实体和关系更多的特征信息,深入挖掘各维度属性信息。
3)RotatE 模型的MRR 指标优于ConvE、ConvKB等模型。可以看出,复数旋转模型RotatE 在WN18RR上补全效果显著,在某个指标上优于现有CNN 模型。
为验证超复数胶囊网络模型推理各类关系模式的能力,本文选取WN18RR 进行链接预测实验。如图3 所示,超复数胶囊网络模型在建模和推理多种关系模式中具有优越的表示能力。
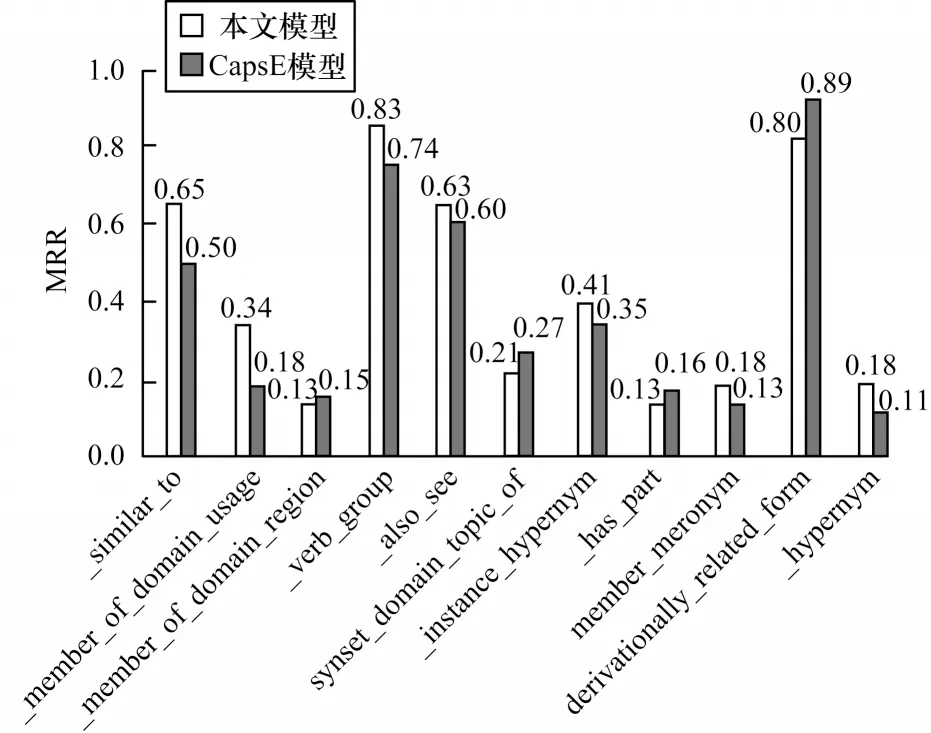
图3 不同关系模式的MRR 指标Fig.3 MRR index of different relationship patterns
3.4 三元组分类
3.4.1 实验设置
三元组分类即判断一个事实三元组是否正确,或头、尾实体是否存在某种依存关系,这是一个简单的二分类问题。例如,(Beijing,Capital_Of,China)是正确的三元组,(London,Capital_Of,China)是错误的三元组。参照文献[12-14],本文将阈值设置为δ=0.5,即对于任意一个测试三元组,使用评分函数计算三元组的分数,若该分数高于阈值δ=0.5,则三元组是正确的,否则为负例三元组。在实验中,本文选取验证集上的三元组,依次计算每个三元组的得分,并将每个分数作为阈值δ来计算三元组的分类准确率。最终,本文将分类准确率最高时的δ作为模型阈值,即δ的数值大小最终设置为0.5。另外,阈值取值范围为δ∈[0,1]。
3.4.2 实验分析
参考文献[14,34],利用Freebase 的子集FB15K执行三元组分类任务。实验环境与3.3.3 节相同。FB15K 最优参数为:N=50,K=100,γ=0.000 1。三元组分类的实验结果如表4 所示。

表4 三元组分类实验结果比较Table4 Comparison of experimental results of triple classification %
分析表4 可以看出:基于四元数嵌入的胶囊网络模型优于其他所有模型,准确率达到92.7%,这说明四元数嵌入的胶囊网络模型在预测精度方面效果显著,适用于大规模的知识图谱补全任务。
4 结束语
为补全知识库中缺失的事实三元组,本文将四元数融入胶囊神经网络模型以预测缺失的知识。采用超复数嵌入取代传统的实值嵌入编码三元组结构信息,捕获三元组全局特性,四元数结合优化的胶囊网络模型可以有效补全知识图谱中丢失的三元组,预测精度更高。实验结果表明,与传统嵌入方法相比,四元数胶囊网络模型在硬性指标上显著提升。下一步将重新设计胶囊网络模型,采用内联胶囊路由协议或核密度估计路由协议代替传统的动态路由,并且将关系和实体的文本信息融入胶囊神经网络,提高四元数胶囊网络模型的预测精确率。
