融入深层病理信息挖掘的乳腺肿块识别模型
2022-02-23李广丽李传秀邬任重卓建武张红斌
李广丽,袁 天,李传秀,邬任重,卓建武,张红斌+
1.华东交通大学 信息工程学院,南昌330013
2.华东交通大学 软件学院,南昌330013
权威报告显示:乳腺癌是女性中最常见的癌症,也是女性第二大致命性疾病。故乳腺肿块是一种令人担忧的乳腺异常,约90%的乳腺肿块属于癌变。乳腺肿块多隐藏于乳腺组织中且边缘不清晰,医生需结合扎实的专业知识和丰富的诊断经验完成准确的人工筛查。但医生诊断水平参差不齐,人工筛查繁琐,主观性大,易导致较高的错诊率或漏诊率,计算机辅助乳腺肿块识别模型能有效地辅助医生的临床诊断工作。众所周知,绝大多数医学图像处理应用领域都面临样本稀缺难题,而造成该问题的主要因素是:(1)医学图像的标注代价太大,需花费非常大的人力、物力,才能获取一定数量的高质量样本;(2)由于涉及伦理条款,大量医学图像样本存在个人隐私,而无法正常获取,极大地限制了可用的样本数;(3)由于所涉及的专业背景差异性较大,故医(医学)工(计算机)合作之间存在一定“鸿沟”,进而制约了高质量样本的生成。医学图像样本稀缺容易导致识别模型出现过拟合。综上所述,如何应对医学图像样本稀缺问题已变得尤为重要。针对该问题,有学者提出采用GAN(generative adversarial networks)模型生成新样本,以扩充数据集,然而新样本的真实性受到一定质疑;有学者构建多任务学习框架(如复合分割和识别),即通过不同任务之间的信息共享来应对样本稀缺,但多任务学习框架的设计及训练难度均较大。
深层病理信息是一种经过多次挖掘的低维特征,它的判别性更高,且维度较低,能更好地匹配样本数量,降低模型过拟合风险,进而在一定程度上应对医学图像样本稀缺问题。相比于上述两类方法,它无需生成新样本且模型训练难度不大,故“性价比”更高。提出“融入深层病理信息挖掘的乳腺肿块识别模型”:在样本精选基础上,由浅入深地挖掘有限标注样本中的深层病理信息,以训练优质、高效的乳腺肿块识别模型。本文贡献:
(1)设计样本精选算法,跨越不同的乳腺造影图像数据集,精选优质样本,为训练鲁棒的乳腺肿块识别模型奠定数据基础,从数据增强角度应对样本稀缺问题;
(2)设计多视角有效区域基因优选(multi-view efficient range-based gene selection,MvERGS)算法,精化原始图像特征,并执行判别相关分析(discriminant correlation analysis,DCA),获取特征间的跨模态相关性,其判别性更强且维度更低,以匹配样本数量,降低模型过拟合风险,进而应对样本稀缺问题。
1 相关工作
1.1 图像特征学习
图像特征是乳腺肿块识别的重要前提。尺度不变特征变换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradients,HOG)等特征在乳腺肿块识别中发挥了重要作用。Li提取图像内部及其边缘纹理基元,采用线性判别分析(linear discriminant analysis,LDA)完成乳腺肿块识别。Liu 等基于互信息模型优选关键特征,采用支撑向量机(support vector machine,SVM)训练乳腺肿块识别模型。此外,完全局部二值模式(completed local binary pattern,CLBP)、灰度共生矩阵(grey-level cooccurrence matrix,GLCM)等特征也被用于乳腺肿块识别。
1.2 特征优选
由于特征维度高且包含噪声,故需对原始图像特征执行特征优选,改善其判别性并压缩特征维度,更好地匹配医学图像样本数。特征优选方法分为单模态特征优选和多模态特征优选,具体如下:
(1)单模态特征优选
Ji 等从光学断层扫描图像中提取光学系数作为特征,基于最大相关和最小冗余算法优选特征,完成类风湿关节炎检测。Veeramuthu 等采用空间灰度差特征提取算法和基于相关性的特征选择方法,完成脑图像分类。Kumar等基于粒子群优化(particle swarm optimization,PSO)算法进行特征优选。Sudha等改良狮子算法,从乳腺图像的纹理、强度直方图和形状等特征中优选子集。Zhu 等综合LDA 和局部保留投影法优选神经影像学特征。单模态特征优选法可精化原始特征,提升识别精度。
(2)多模态特征优选
由于包含正电子发射断层扫描(positron emission tomography,PET)、磁共振成像(magnetic resonance imaging,MRI)、计算机断层扫描(computed tomography,CT)等图像,故可围绕它们展开多模态特征优选。Zhang等提出多模态多任务学习框架,实现多模态特征融合,完成阿尔茨海默病(Alzheimer's disease,AD)诊断。Zhou 等对不同模态执行隐特征学习,将特征映射到标签空间完成AD 诊断。Zheng等利用稀疏深度多项式网络(sparse deep polynomial network,S-DPN)完成多模态数据融合,获取判别性更强的新特征。也有学者采用超图完成多模态数据间的高阶相关性分析,生成高质量特征。多模态特征优选法充分利用特征间的互补性来改善识别精度。
1.3 乳腺肿块识别
近年来,深度学习模型在乳腺肿块识别中扮演了重要角色。相关工作可分为四类:微调模型法、集成深度学习法、迁移学习法和多任务协同学习法。微调模型法微调预训练之后的卷积神经网络(convolutional neural network,CNN)完成识别任务。该方法简单、易用,但受样本数制约。Ragab等将预训练后的AlexNet模型的全连接层接入SVM,训练识别模型;集成深度学习法利用多个模型之间的互补性提升识别精度,故该方法需大量计算资源。Dhungel 等采 用DCNN(deep convolutional neural network)和深度置信网络(deep belief network,DBN)分别构建两个预测模型,然后集成它们的结果,实现乳腺肿块识别;迁移学习法通过知识迁移实现识别任务。Khan 等使用预训练的GoogLeNet、VGGNet和ResNet 模型提取图像特征,将特征接入全连接层,对其池化并完成乳腺肿块分类。Shen 等先训练块级别(patch-level)识别模型,然后去掉全连接层,添加新卷积层,训练面向整幅造影图像的识别模型。多任务协同学习法指诊断模型包含多个相关子任务,如病灶分割、肿瘤识别、病灶定位等,它们相辅相成、互为补充,通过协同学习来改善识别精度,同时降低对样本数的依赖。
综上,乳腺造影图像偏少使乳腺肿块识别任务更具挑战,特征优选算法能精化原始图像特征,更好地匹配样本数,进而改善模型识别性能。提出“融入深层病理信息挖掘的乳腺肿块识别模型”,从多个角度积极应对医学图像样本稀缺问题:
(1)跨越不同的乳腺造影图像数据集精选优质样本,为训练鲁棒的识别模型奠定数据基础。
(2)充分挖掘有限标注样本中的深层病理信息,进一步缓解模型过拟合问题:设计MvERGS 算法,降低噪声干扰并提升特征判别性;深入分析特征间的典型相关性,采用跨模态特征来刻画病灶区域。
综上,本文模型称为RMD,“R”表示样本精选策略(sample refinement),“M”表示特征优选算法MvERGS,“D”表示跨模态分析DCA。它们有机地结合在一起,以改善乳腺肿块识别性能。
2 RMD 模型框架
RMD 模型的框架如图1 所示,包括:样本精选、特征优选、跨模态分析及乳腺肿块识别。首先,设计样本精选策略,筛选优质乳腺造影图像样本;其次,从形状、纹理、深度学习等角度提取SIFT(S)、Gist(G)、HOG(H)、LBP(L)、DENSENET161(D)、
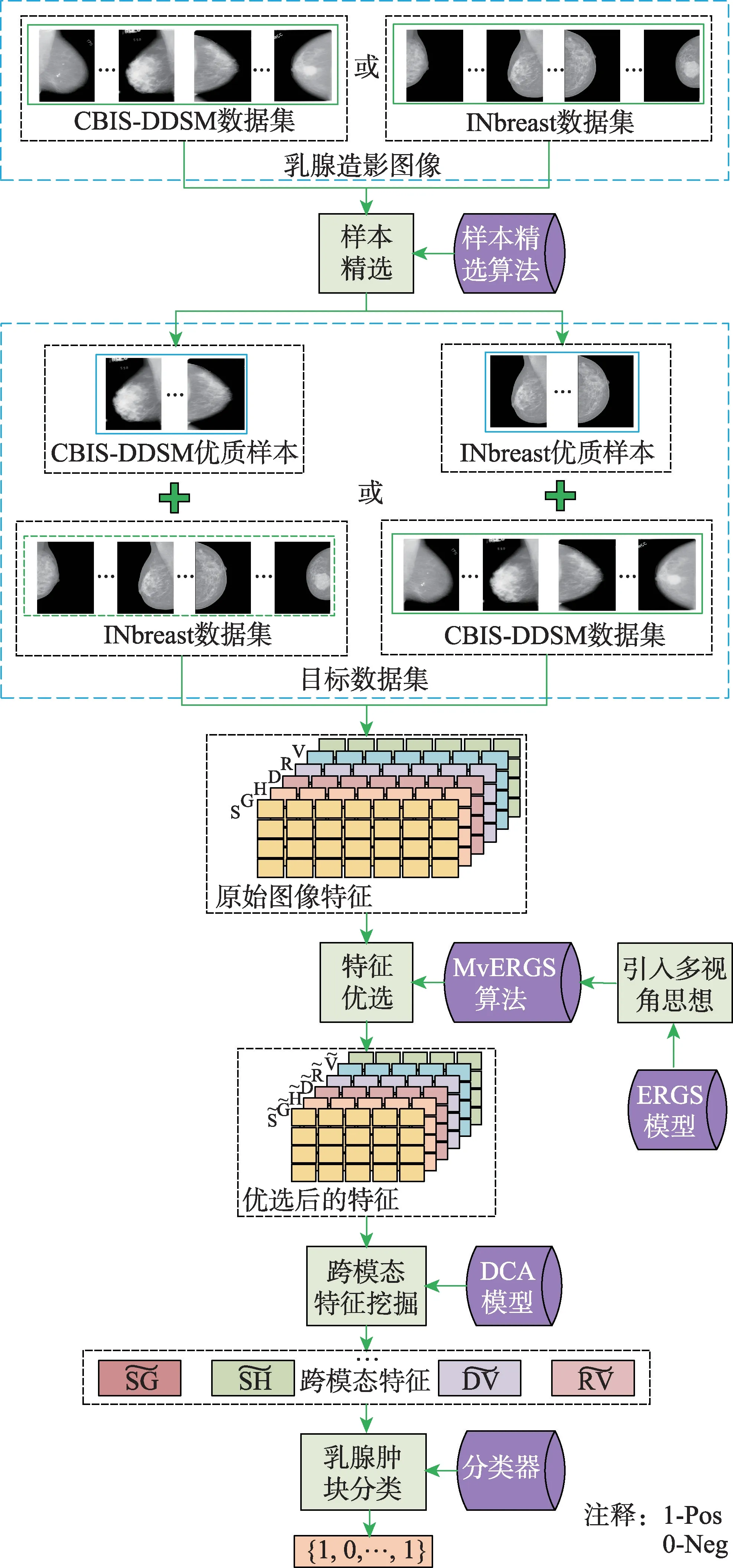
图1 RMD 模型框架Fig.1 Framework of RMD model
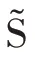
2.1 图像特征提取
图像特征应准确刻画乳腺肿块视觉特性,且兼顾互补性,为跨模态分析做好准备。SIFT 定位多变的肿块形状;Gist 从全局视角刻画肿块纹理特性;HOG 捕获肿块边缘信息,进而描述肿块表象和形状;LBP从局部视角刻画肿块纹理变化。DENSENET161、RESNET50 和VGG16 等深度学习特征是对传统特征的有益补充。实验中尝试了上述深度学习模型的同源网络结构,但效果略差。
2.2 样本精选(R)
乳腺肿块识别面临样本稀缺问题,考虑到随机选取样本以扩充数据集会引入更多噪声信息,进而影响模型识别性能,尽量挑选置信度高的样本来扩展现有数据集,降低噪声对识别的影响。因而,本文设计了一个更有针对性的样本精选策略,它跨越不同的乳腺造影图像数据集,筛选优质样本(由一组分类器共同置信)并充分利用新样本所蕴含的病理学知识,训练出更有效且鲁棒的识别模型。综上,在RMD 模型中,样本精选算法的基本思想:选取表现最优异的一组分类器,采用硬投票机制从源数据集中优选出样本,即将源数据集中能被这组分类器正确分类的样本选出,与目标数据集合并,训练新的分类模型。该思想简单、易行,既关注置信度更高的源样本,又能充分利用不同分类器在决策时的互补性,最终为训练高质量的分类模型奠定数据基础。样本精选算法如下所示:
算法1 样本精选算法

2.3 特征优选(M)
2.2 节精选出的样本非常有限且受个体差异影响,充分挖掘有限标注样本中的病理信息是应对样本稀缺问题的一种更为有效的方法。本节从特征优选角度挖掘乳腺造影图像病理特征。原始图像特征维度偏高且存在噪声,会影响识别精度并制约识别效率。设计MvERGS 算法,从两个视角精化原始特征并提升其判别性,以应对样本稀缺导致的模型过拟合问题(特征优选后维度将大幅降低,从而更好地匹配样本数)。同时,该算法具有良好的拓展性,可引入更多视角,从互补的角度更全面、细致地刻画乳腺造影图像中的病灶区域,并进一步完善特征表示,不断增强特征的判别性,从而提升模型识别精准度。其次,算法具有一定鲁棒性,即它仅处理最底层的特征分量,并不依赖于特征所描述的视觉内容。
设乳腺造影图像数据集={,,…,x},包含个样本,特征集={,,…,f},特征维度,类标签集合={,}。 μ和σ表示特征f在c类样本上的均值和标准差。特征f在c类样本上的有效区间为:


MvERGS 算法视角1:考虑特征重叠区域在有效区间上的占比,它是衡量特征优劣的相对值,不受样本数、有效区间绝对大小影响,具有较强鲁棒性和稳定性。该占比越小,则特征的判别性更强,它能将异类样本有效地区分开。相反,占比越大,则特征判别性较弱,异类样本间的混淆度偏高,识别精度较低。计算特征在所有类别样本上的重叠程度-OAR:
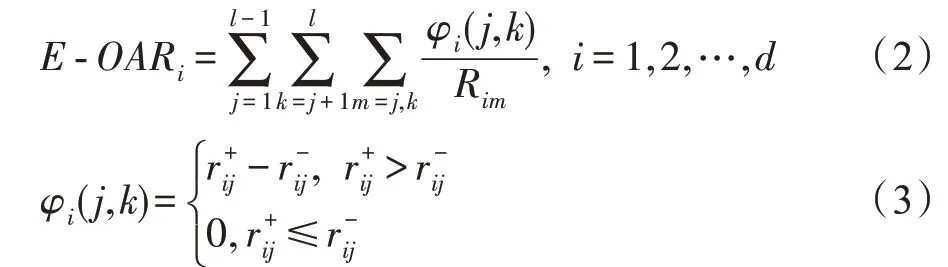
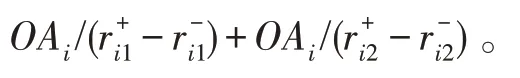
对每个特征f的-OAR进行标准化并计算它在所有类别样本上的权重Ew:
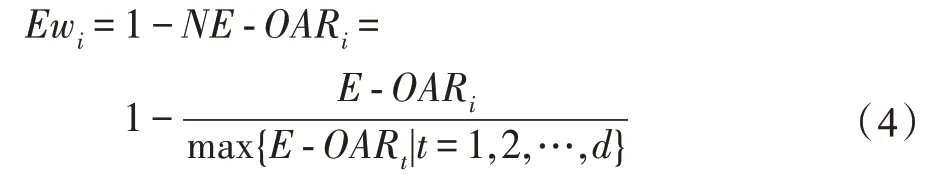
DifLab(x)={x|x∈-NN(x)∧(x)≠(x)}表示样本x在特征f上与样本x类别标签(x)不同的样本集合,-NN(x)指样本x在特征f处的近邻,采用式(5)计算样本x在特征f处基于近邻中异类样本所占比的重叠区域:

计算特征f基于近邻中异类样本所占比的平均重叠区域并对其标准化:
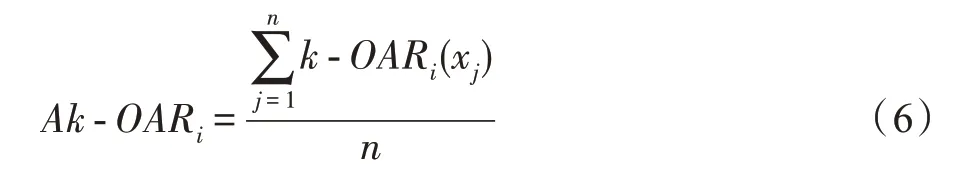
-OAR越大,特征混淆度越大,特征区分能力越弱。计算特征f基于-OAR权重Kw:
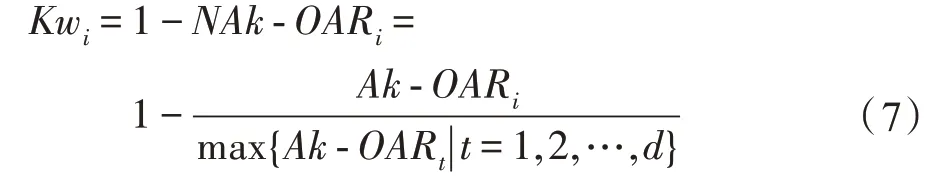
综合考虑式(4)、式(7)两种权重,用调制它们,∈[0,1],故新特征权重如下:
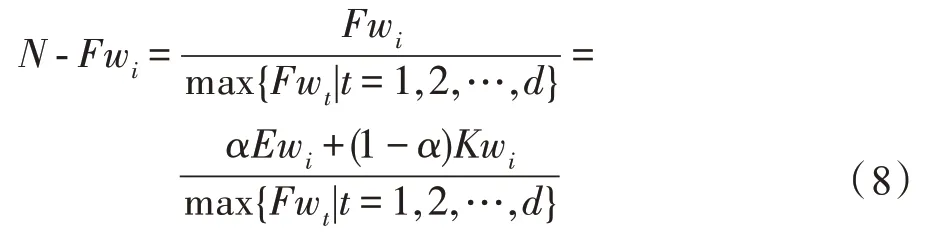
根据式(9)和参数(阈值)执行特征优选,-Fw权值大小与对应特征重要性成正比,若大于则优选该权重并构造权重队列,基于生成特征。
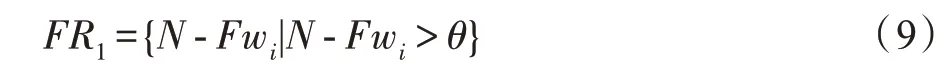
MvERGS 算法视角2:考虑特征在有效区间上的重叠区域,它是衡量特征优劣的绝对值。重叠区域越小,即异类样本的混淆度较低,特征判别性越强,它是对MvERGS 算法视角1 的有益补充。鉴于传统的ERGS 算法能在一定程度上有效地提纯特征,故基于该算法中特征f的权重w,得到权重矩阵。使用式(10)对权重矩阵进行标准化,生成-:
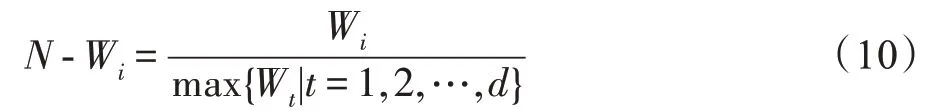
基于参数执行特征优选,与类似,生成特征。拼接特征和获得新特征。新特征从两个视角刻画原始特征中各分量重要性,不同视角能形成一定互补并增强特征判别性。特征优选是对原始特征的精化,能改善识别精度。虽然维度更低,但其仅保留原始特征中的核心部分,在一定程度上确保了特征中有效信息的完整性。故能提升实时运行效率并为跨模态相关性挖掘做好准备。同时,特征降维后还能更好地匹配样本数,缓解样本稀缺导致的模型过拟合。
2.4 跨模态相关性挖掘(D)
MvERGS 算法精化原始特征,所生成的新特征中蕴含浅层病理信息,应进一步提取标注样本中深层病理信息,更好地应对样本稀缺。同类乳腺肿块的纹理、形状、颜色、边缘等视觉表象指向相同或相似的病灶区域,即图像特征间蕴含丰富的跨模态相关性,这对于改善识别性能具有非常重要的意义。故在MvERGS 特征优选基础上,继续挖掘新特征之间的跨模态相关性,不断优化识别精度。

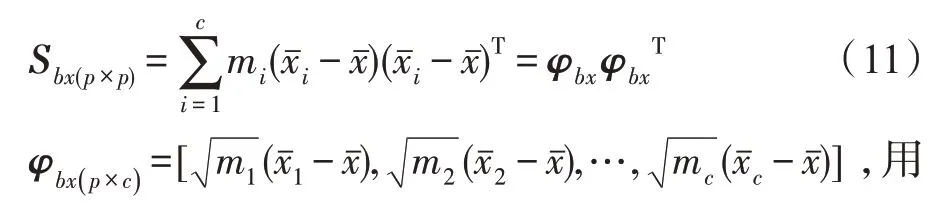
式(12)对角化类间散度矩阵S:



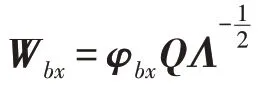

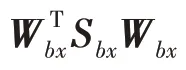

单位化协方差矩阵′,将原特征、映射到中间空间:


3 实验与分析
3.1 实验设置
选取公开数据集CBIS-DDSM(从链接https://wiki.cancerimagingarchive.net/display/Public/CBIS-DDSM中获取)、INbreast(从链接http://medicalresearch.inescporto.pt/breastresearch/index.php/Get_INbreast_Database 中获取)进行实验比较,它们的相关信息如表1 所示。

表1 CBIS-DDSM 和INbreast数据集的相关信息Table 1 Detailed information about CBIS-DDSM and INbreast datasets
对于INbreast 数据集,参照文献[29]将BI-RADS中标注1 和2 的图像归为阴性样本,将标注4、5、6 的图像归为阳性样本。采用PCA 算法将SIFT 和HOG降成500 维和300 维。在提取深度学习特征时,由于分辨率较大,对图像执行中央裁剪操作,使输入图像变为224×224。VGG16 选取第一个全连接层,特征维度4 096。DENSENET161 和RESNET50 均选取最后一个平均池化层,特征维度分别为2 208 和2 048。
RMD 模型包括:RMD-NN、RMD-LR、RMD-RF、RMD-DT、RMD-SVM、RMD-NB、RMD-Adaboost、RMD-GBDT 和RMD-XGBoost。对比基线有五类,具体如下所示:
(1)主流特征优选算法:GS-XGBoost、ERGS、Fisher Score、PSO、HGSCCA。
(2)基于MvERGS算法(M)的识别模型:M-NN、M-LR、M-RF、M-DT、M-SVM、M-NB、M-Adaboost、M-GBDT 和M-XGBoost。
(3)基于MvERGS 算法(M)与跨模态相关性挖掘(D)的识别模型:MD-NN、MD-LR、MD-RF、MDDT、MD-SVM、MD-NB、MD-Adaboost、MD-GBDT 和MD-XGBoost。
(4)迁移学习类模型:DenseNet121、ResNet152、VGG16和Shen 等的模型。
(5)基于感兴趣区域(ROI)的识别模型:Tsochatzidis等的模型、Rampun等的模型、Zhu等的模型、Carneiro 等的模型及Dhungel等的模型。
其中,第(2)、(3)类基线的实验结果可视为对RMD 模型执行了消融分析。由于第(5)类基线基于ROI,与这些模型进行间接比较。
采用精准度(Accuracy,Acc)、AUC、敏感度(Sensitivity,Sen)、特异性(Specificity,Spe)和准确率(Precision,Pre)等指标评判乳腺肿块识别性能。精准度、AUC 越高,识别效果越好;敏感度越高,假阴率越低,漏诊越少;特异性越高,假阳率越低,确诊概率越高。
3.2 与主流基线比较
选取多个主流基线与RMD 模型进行识别性能对比,实验结果如表2 和表3 所示。为了与Shen 等进行比较,添加被忽略的BI-RADS=3 的乳腺造影图像,重新训练识别模型。对于本文所提3 类模型M、MD 和RMD,选取每类模型中Acc、AUC 的最优值进行展示。如表2 左半部分所示,在CBIS-DDSM 数据集中,MD-XGBoost 模型的Acc 最优值是77.75%,而MD-LR 的AUC 最优值是85.16%。选取识别精准度最优的模型完成样本精选,如执行“INbreast➝DDSM”样本精选时:考虑到INbreast 中样本偏少,采用“精选样本数=最优分类器精准度×测试样本数”的方式,共精选出23 个样本。执行“DDSM➝INbreast”样本精选时,采用算法1,即选取精准度Top 3 的分类器对样本执行硬投票,共精选出706 个样本。调制MvERGS算法的参数=0.5 和=9,采用串接融合方法生成跨模态特征。
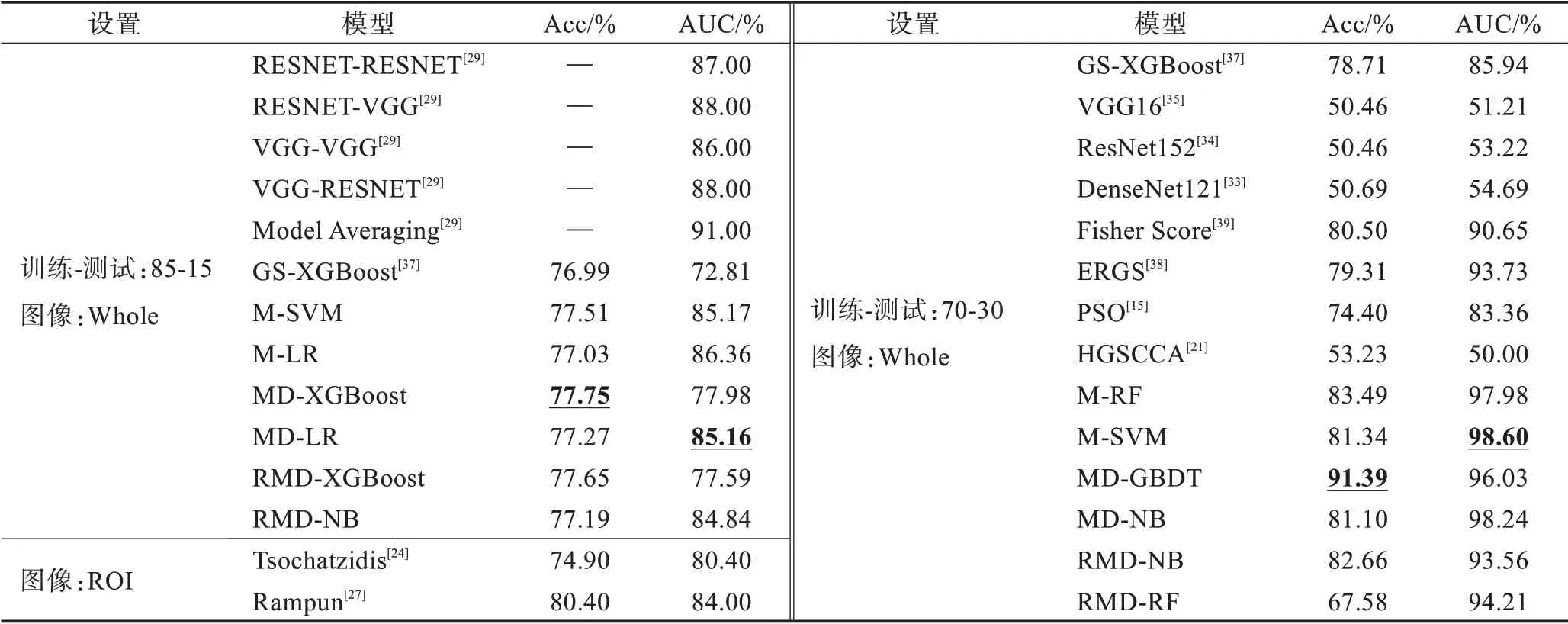
表2 在CBIS-DDSM 数据集上RMD 与基线的对比Table 2 Comparison of RMD and baselines on CBIS-DDSM dataset
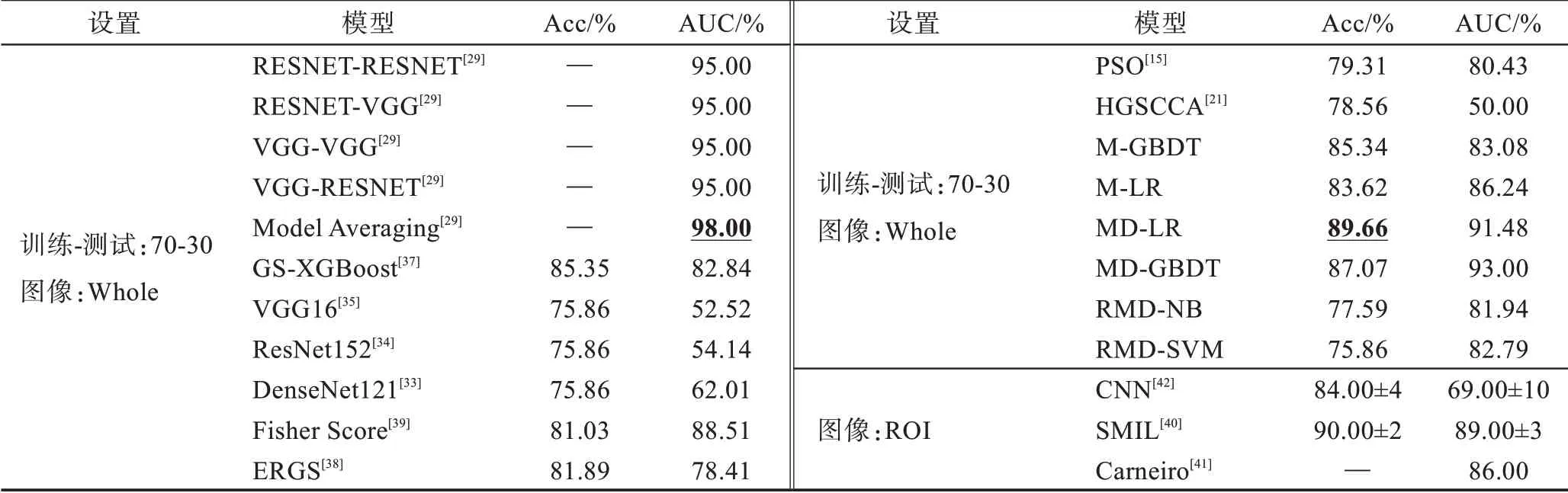
表3 在INbreast数据集上RMD 与基线的对比Table 3 Comparison of RMD and baselines on INbreast dataset
如表2 所示:选85-15 划分比时,RMD 类模型精准度优于基线,相比M 类模型,MD、RMD 类模型精准度更优,样本精选策略、跨模态相关性挖掘发挥重要作用。作为变种,M-LR 模型的AUC 值超过Shen的VGG-VGG 模型,即MvERGS 算法较好地抑制了原始图像特征中的噪声干扰;选70-30划分比时,RMD类模型精准度优于基线。作为变种,MD-GBDT 模型的精准度最优,较最强基线提升10.89 个百分点。M-SVM、MD-NB 等模型AUC 表现突出,优于Shen 的Model Averaging 模型。主要原因:相比于传统ERGS模型仅从单个视角提纯特征,MvERGS 算法从两个互补的视角来精化原始图像特征,确保了原始特征中有效信息的完整性,为训练识别模型奠定重要基础。此外,实验结果也验证了在MvERGS 算法中增加新视角的必要性;同时,RMD 模型运用DCA 算法深入挖掘异构特征间的典型相关性,生成跨模态特征,即位于异构特征间的具有相同或相似语义的潜在相关性。因此,它具有更强的判别性,能更精准地刻画病灶区域,并训练高效的识别模型。显然,RMD模型有效缓解了因样本稀缺导致的模型过拟合(表2中VGG16、ResNet152 等深度学习模型的结果存在一定过拟合)。MD-GBDT 模型获得最优的整体识别性能,而Shen 未公开精准度数值。相比Shen 集成4个深度学习模型,MD-GBDT、MD-NB 等模型的训练过程更为简单,也更易于复现。此外,相比于PSO、HGSCCA(hyper-graph based sparse canonical correlation analysis)、Fisher Score 等主流特征选择算法,RMD 是一种多阶段的、逐层精化的特征选择算法,它能由浅入深地挖掘有限标注样本中所蕴涵的深层病理信息。该信息维度更低但判别性更强,基于它可以训练出高质量的乳腺肿块识别模型,从而更好地应对样本稀缺问题。最后,对比基于ROI 的识别模型,RMD 模型也有较强竞争力,且具备如下优势:AUC、Acc 等关键指标更优且不依赖人工标注ROI;贴近真实诊断过程。综上,RMD 类模型在CBIS-DDSM 数据集上表现较优。
如表3 所示:使用70-30 划分比时,变种模型MD表现更优,其中MD-LR 模型精准度最优,较最强基线提升4.31 个百分点,MD-GBDT 模型AUC 值逼近最优单模型(95%)。显然基于MvERGS 算法的特征优选、基于DCA 法的跨模态相关性挖掘等在乳腺肿块识别中均发挥重要作用。这也从另一个侧面验证了MvERGS 算法的鲁棒性、特征中有效信息的完整性及增加新视角的必要性。同时,跨模态相关性挖掘在保留特征判别性的基础上,进一步压缩特征维度,既增强了识别模型的性能,又较好地匹配了样本数,以应对样本稀缺问题。其次,由于AUC 值偏低,深度学习模型VGG16、ResNet152 及DenseNet121 出现了过拟合(由于“DDSM➝INbreast”迁移的样本更多,故相比表2,这些模型的过拟合有所缓解),主要原因:医学图像样本稀缺使得这些模型学不到关键特征。相反,RMD 类模型却能获取较好的AUC 值,且整体识别性能更优。相比于PSO、HGSCCA、Fisher Score 等主流特征选择算法,RMD 是一种多阶段的、逐层精化的特征选择算法,它通过MvERGS、DCA 等算法由浅入深地挖掘有限标注样本中所蕴涵的深层病理信息,即取维度更低且判别性更强的新特征,从而积极应对因样本稀缺或模型复杂所导致的过拟合问题。最后,相比基于ROI的识别模型,RMD 模型在AUC 指标上更有优势。综上,RMD 模型在INbreast数据集上表现尚优,但优势不显著。
3.3 特征鲁棒性证明
提取单类别特征“S”“G”“H”“L”“D”“R”“V”,基于传统分类器完成识别任务,取每个特征在分类器上最优结果做展示,实验结果如表4 所示。
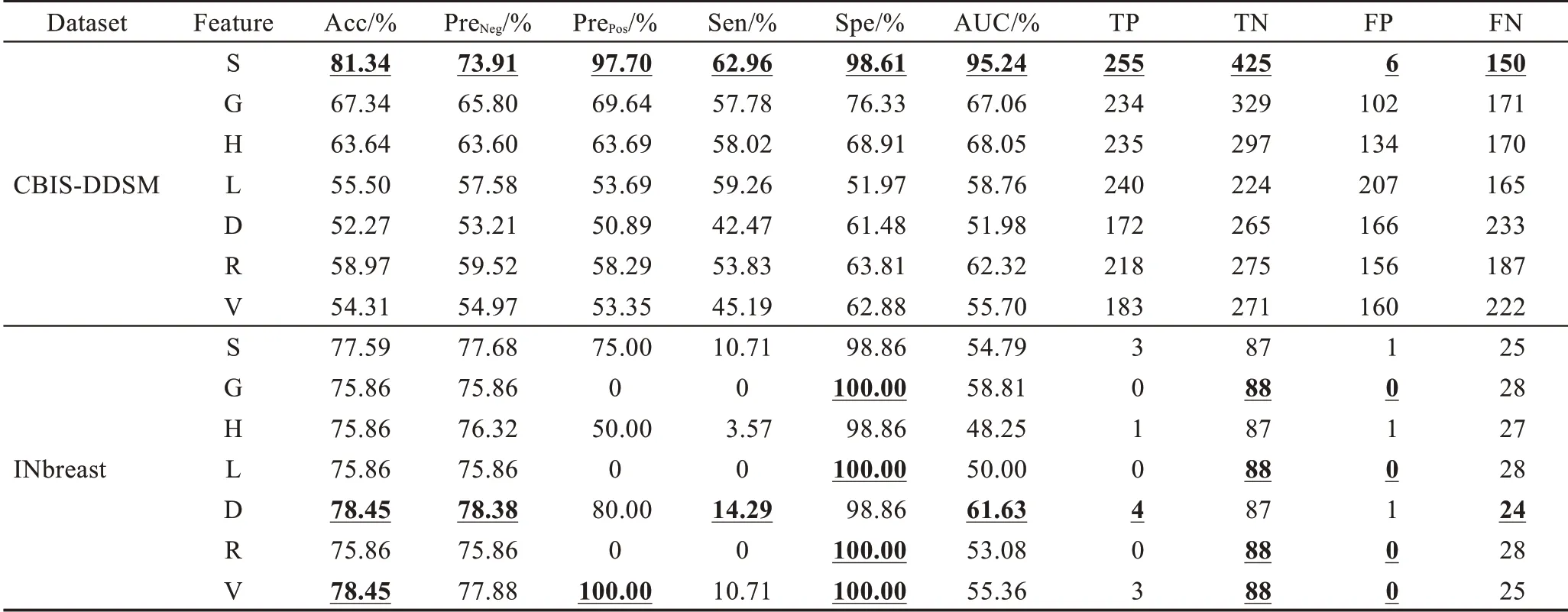
表4 原图像特征的识别性能Table 4 Recognition performance of original image features
在CBIS-DDSM 数据集中,S 特征表现优异,其假阳率仅为1.39%,S 特征可减少形态、视角等变化带来的噪声,帮助模型准确锁定乳腺肿块形状。G 特征次之,它从全局角度捕获纹理异常的乳腺肿块。TP ≪TN,模型存在过拟合倾向。在INbreast 数据集中,D特征和V 特征表现优异。阳性预测样本数远小于阴性预测样本数(TP+FP ≪TN+FN)或阳性样本预测概率为0(Pre=0),识别模型出现了较严重的过拟合,而样本稀缺是导致这一结果的最重要因素。因此,采用高维度的原始特征进行乳腺肿块识别,由于出现过拟合,整体识别性能并不好。这就需要充分挖掘原始图像特征中所蕴含的低维、深层病理信息,更准确地刻画乳腺造影图像的病灶区域,并匹配样本数,降低模型过拟合风险。因此,本文所提RMD模型能由浅入深地挖掘有价值的病理信息,进而改善识别性能,积极应对样本稀缺问题。
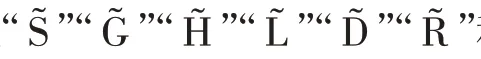
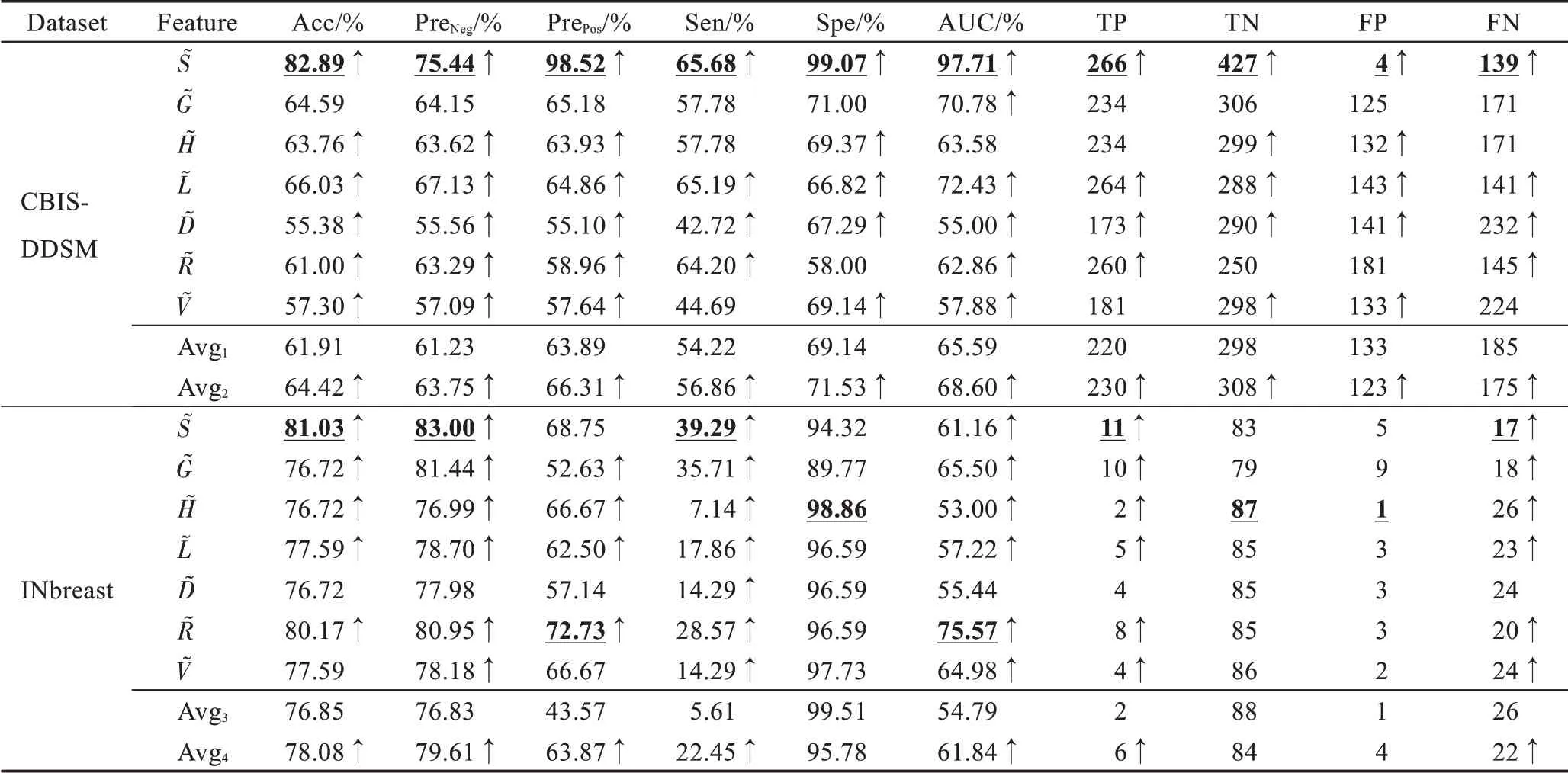
表5 基于MvERGS 算法的识别性能Table 5 Recognition performance based on MvERGS algorithm
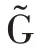
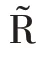
综上所述,MvERGS 特征优选后两个数据集上的识别性能都有提升,过拟合得到一定缓解。当然,两个数据集上的敏感度、精准度等指标还偏低,需要继续执行跨模态相关性挖掘,以改善这些指标。


图2 MD 类模型在两个数据集上的精准度和AUC 值Fig.2 Accuracy and AUC values of MD model on two datasets
综上所述,在MvERGS 特征优选基础上,继续执行跨模态相关性挖掘,不但能从深层角度挖掘出不同模态特征间的互补信息,以丰富特征语义内涵,还能在保证有效信息完整的情形下极大地降低特征维度,为应对数据稀缺和提升识别模型的实时性能奠定重要基础。
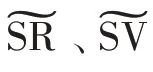
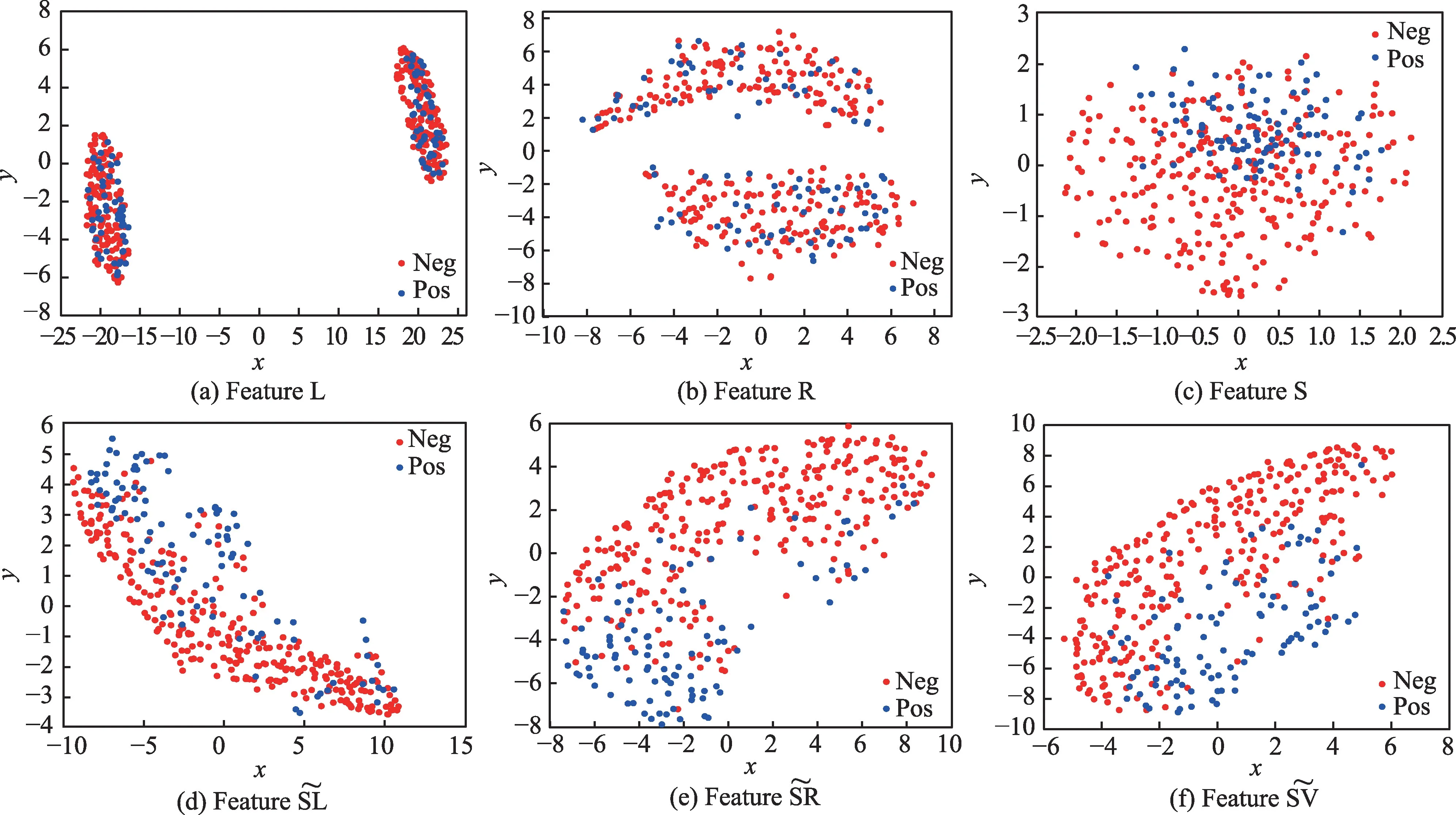
图3 MD 模型中部分特征的t-SNE 可视化Fig.3 t-SNE visualization of some features in MD model

在临床诊断中,特异性和敏感度也非常重要。特异性越高,假阳率越低,确诊概率越高;敏感度越高,假阴率越低,漏诊减少,真实患者可以得到及时治疗,后者相对前者付出更大代价。特异性和敏感度从不同角度评估模型实用性。绘制如图4 所示RMD 模型特异性均值、敏感度均值变化图,橙色柱体表示增加量,绿色柱体表示减少量,蓝色柱体表示均值,若含橙色柱体,则蓝色柱体和橙色柱体高度之和为相应指标均值。蓝色柱体表示引入样本精选策略后对应指标均值。
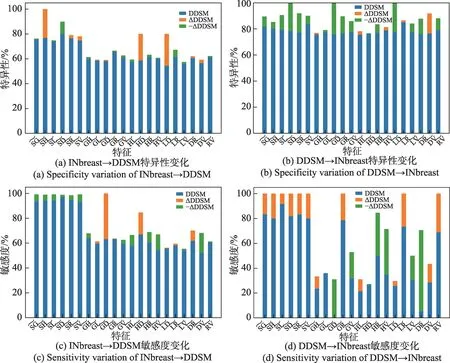
图4 样本精选前后RMD 模型特异性和敏感度变化Fig.4 Variations of specificity and sensitivity of RMD model after using sample refinement strategy
选取均值能从统计角度发现真实的变化趋势。“INbreast➝DDSM”表示样本精选方向,即从INbreast数据集中精选样本,以补充DDSM 数据集。“DDSM➝INbreast”的含义刚好相反。
综上所述,对于样本更均衡的数据集,RMD 模型能获取更优的特异性,这有助于降低诊断的假阳率,提高确诊率。而对于样本相对稀缺的数据集,RMD模型能获取更优的敏感度,这有助于降低漏诊现象,减少病人所付代价。显然,引入样本精选策略后,识别模型的特异性和敏感度均呈现积极变化,这在一定程度上增强了模型的实用性。
4 结论与展望
乳腺肿块识别模型能辅助医生的临床诊断工作,但样本稀缺会制约识别精度,进而影响模型的实用性。提出融入深层病理信息挖掘的乳腺肿块识别模型RMD,它从样本精选、特征优选、跨模态相关性挖掘等角度积极应对样本稀缺问题。实验表明:RMD 模型在两个通用乳腺造影图像数据集上均取得了较好的识别精度,且构成模型的各个部分(R、M、D)均是有效的。RMD 模型的最大特点:执行多阶段、逐层精化的特征选择,以获取判别性更强且维度更低的新特征。当然,RMD 模型是非端到端的,为此,围绕该模型,开发出基于Web 的乳腺癌诊断平台并完成内部测试,该平台将特征提取、样本精选、特征优选、跨模态相关性挖掘、肿瘤识别等集于一体,期望该平台有助于加速模型真正落地,从而更好地辅助医生的临床诊断工作。未来拟引入Non-Local Block模型,在乳腺肿块识别基础上完成病灶定位;此外,期望将RMD 模型应用到新冠肺炎检测中。
感谢Lee 等人及癌症影像档案公开数据库(cancer imaging archive public access,TCIA)收集、整理CBIS-DDSM 数据集。感谢Breast Research Group及Hospital de São João,Breast Centre,Porto,Portugal提供、整理、标注了INbreast 数据集。这两个数据集是本项研究得以顺利开展的最重要基础。感谢南昌大学医学院周颖老师在病理学方面提供的指导。
