基于单目相机与激光雷达融合的SLAM方法
2022-02-22齐继超张建博
齐继超, 何 丽, 袁 亮, 冉 腾, 张建博
(新疆大学,乌鲁木齐 830000)
0 引言
同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)[1]是移动机器人研究领域的热点、难点,是移动机器人在未知环境中实现自主导航的前提。激光雷达和视觉传感器是SLAM中的两种主流传感器,近年来基于这两种传感器的SLAM算法得到了广泛的研究和应用[2]。
然而,单一传感器的SLAM方法总是存在一定的缺陷,传统单目视觉SLAM存在对光照变化敏感以及尺度漂移等问题[3-4];激光SLAM在几何结构相似的环境中易失效并且回环检测准确度差[5-6]。因此,将单目视觉传感器与激光传感器融合的SLAM算法成为现阶段研究的热点方向。利用激光雷达准确的三维点云信息,为单目相机采集的RGB图像中对应的像素赋予深度值,从而实现两种传感器的融合,通过这种融合方式可以提高单目视觉SLAM算法的准确性。然而,现阶段单目视觉与激光雷达基于数据层的融合往往因为恢复特征点尺度算法的失效,用于定位的特征点不足,从而出现算法定位不精确以及鲁棒性差的情况[7]。
本文有效地解决了在激光与单目视觉融合的SLAM算法中用于估计位姿的特征点不足导致位姿估计不准确的问题;同时,选用两种深度情况的特征点,通过对特征点深度信息的判断提出一种多策略的视觉与激光融合的SLAM算法,提高了传统融合算法的定位精度和鲁棒性。
1 传感器模型
1.1 单目相机
单目相机因结构简单、成本低廉而备受研究者们的关注,单目SLAM是视觉SLAM的研究热点。单目相机成像模型如图1所示,像素点P在归一化平面中可以得到像素坐标系下的坐标值,但像素P的空间位置可能出现在光心与归一化平面连线的任意位置。因此,缺乏深度信息会造成当机器人沿连线运动时,像素位置变化较小导致位姿估计不准确。

图1 单目相机成像模型Fig.1 Monocular camera imaging model
单目SLAM通常通过构建对极几何问题[8]来估计帧间位姿。I1和I2为连续的两个图像帧,O1和O2为两帧的光心,p1和p2为两帧中某一个对应的特征点。则I1到I2间的旋转矩阵R和位移向量t可表示为
(1)
式中,K为相机内参。
1.2 激光雷达
激光雷达是通过发射激光束探测目标的位置、速度等特征量的雷达系统,其测量模型为
(2)
式中:r是激光雷达到障碍物的距离;C是光速;t是所消耗的时间。
激光雷达发射持续不断的激光束,激光束遇到物体时会发生反射,激光雷达接收到一部分反射的激光,通过测量激光发射和返回传感器所消耗的时间可以计算物体到激光雷达的距离。本文通过激光雷达为视觉特征点提供深度信息。
2 单目相机融合激光雷达的里程计算法
2.1 算法整体流程
单目相机融合激光雷达的里程计算法的整体流程如图2所示。首先对单目相机采集的RGB图像进行特征提取与匹配,然后通过激光点云的投影得到特征点深度值,最后对前一帧中特征点深度情况进行判断,进而估计先验位姿。

图2 整体算法流程Fig.2 Overall process of the algorithm
2.2 提取视觉特征点深度
在特征提取后进行特征匹配,同时将激光雷达采集的点云数据投影在RGB图上。在特征点周围选取方形区域[9],如图3(a)所示,红色点为视觉特征点,蓝色点为激光点云。对方形区域内的激光点按照深度进行划分,如图3(b)所示,通过深度直方图建立若干深度为d的区间,选取最靠近该特征点的深度区间中的点云并拟合成平面。最后将光心和特征点的连线与平面的交点到光心的距离记为该特征点的深度h。

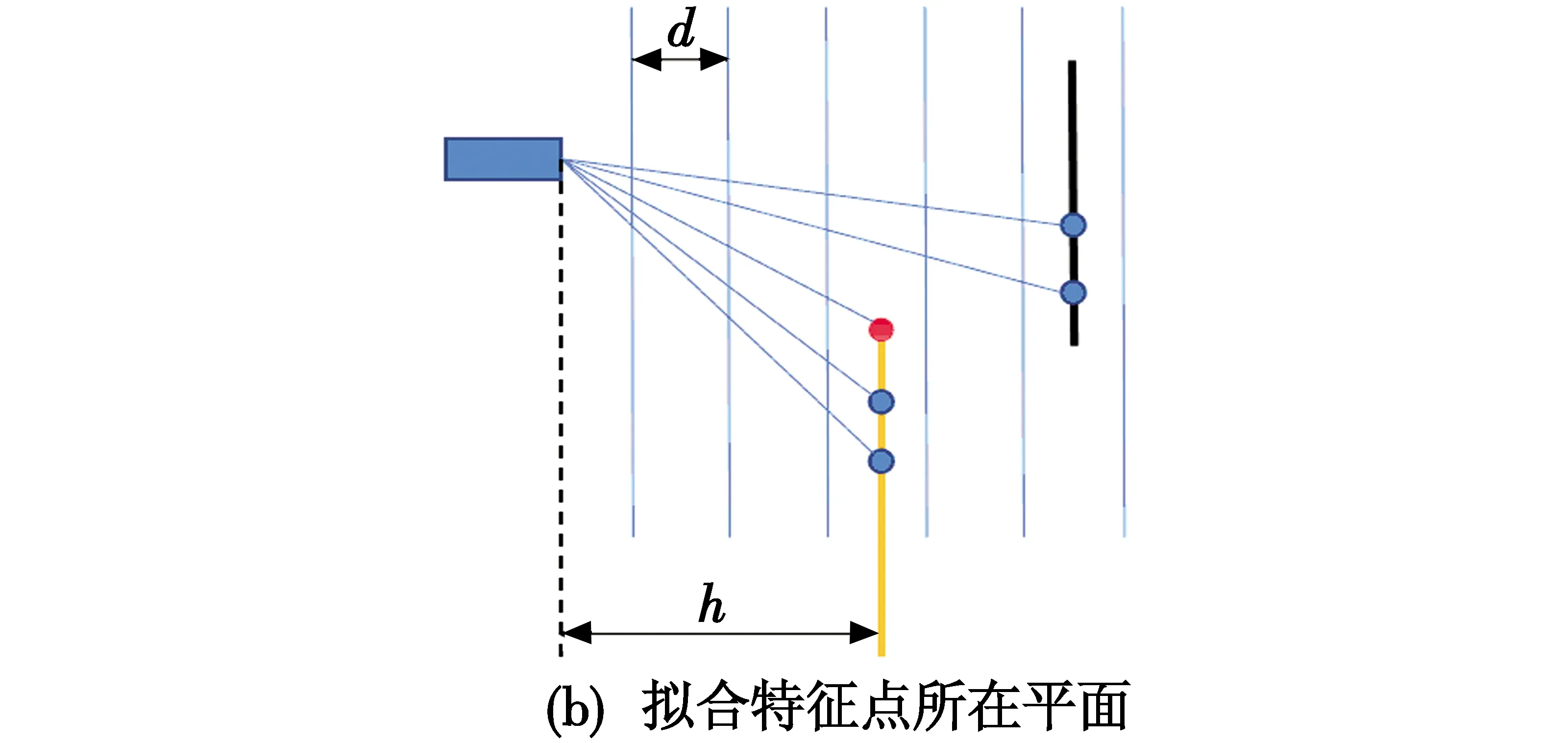
图3 提取特征点深度Fig.3 Extracting depth of feature points
2.3 帧间位姿估计算法
在估计帧与帧之间位姿阶段,先对前一帧中的特征点进行判断,假设当前帧为第k帧,则在第k-1帧中存在如图4所示的3种不同情况。
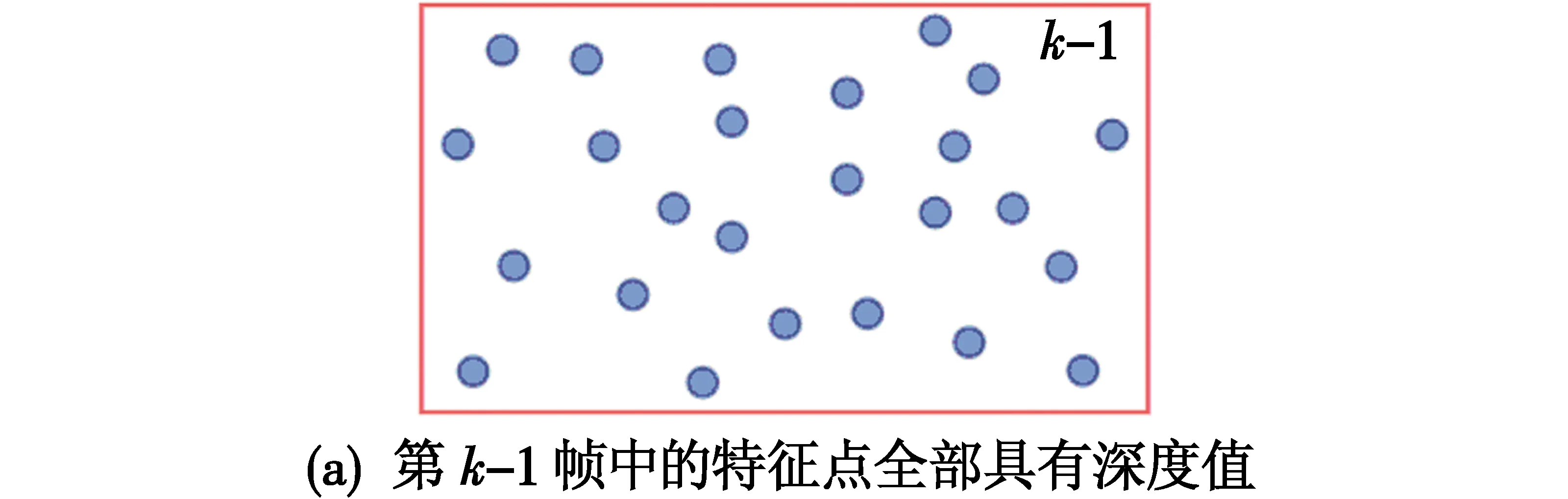


图4 第k-1帧中特征点深度值情况Fig.4 The depth value of feature points in the k-1 frame
根据第k-1帧中特征点的3种不同情况采取不同的位姿估计策略。
1) 第k-1帧中的特征点全部具有深度信息,如图4(a)所示。
此时,对两帧中所有的特征点构建PNP问题[10]求解位姿,即
(3)
2) 第k-1帧中的特征点不全具有深度信息,如图4(b)所示。
此时,选用有深度与无深度两种特征点进行位姿的估计。对有深度的特征点采取构建PNP问题的方式求解位姿T′2,方式如式(3)。取T′2中的位移部分t2作为该情况下所要估计位姿的位移向量;并对所有特征点构建对极几何问题求解T″2,取T″2中的旋转部分R2作为所要估计位姿的旋转矩阵,即
(4)
(5)
3) 第k-1帧中的特征点均不具有深度信息,如图4(c)所示。
在第k-1帧中的特征点均不具有深度值的情况下采用改进的对极几何算法求取位姿。首先通过式(3)对两帧内所有的特征点构建对极几何问题求解位姿T′3,取T′3中的旋转矩阵R3作为该情况下所要估计位姿的旋转矩阵;构建对极几何问题求取位姿的方式在估计旋转时表现良好,但对于平移部分估计效果较差,本文估计位移向量为
(6)
式中:t为T′3中的位移向量;d1为两帧中特征点的实际距离。取t3和R3构成该情况下所要估计的位姿T3
(7)
综上,在对第k-1帧中的特征点深度值判断后,分别采取对应的3种策略估计位姿T1,T2和T3,算法对应的伪代码如下所示。

output:T1或T2或T3
3.方法落后,是影响风险管理审计的关键因素。风险管理审计还缺乏一套较为系统、科学的风险管理方法做指导。一方面,审计范围主要停留在控制风险、确保审计质量等基本层面,没有按科学的风险管理过程进行管理,成果应用不充分;另一方面,没有具体的、针对性强的风险管理策略。审计经验不足,创新能力不强,导致不能恰当地预测风险、识别风险、评估风险和应对风险,阻碍了内部审计有效开展风险管理审计。
begin
T1,T2,T3,m←0;
for对每个i≤N执行
ifi有深度then
m=m+1;
end
end
ifm=0
执行式(4),(6),(7)得到位姿T3;
else ifm=N
执行式(3)得到位姿T1;
else
执行式(3)~(5)得到位姿T2;
end
returnT1或T2或T3;
end。
3 实验及分析
3.1 实验平台
本文算法运行的平台是DELL G3笔记本电脑,CPU为i5-9300,8 GiB内存,64位Ubuntu系统,本文采用KITTI[11]数据集Sequence 01和Sequence 04进行实验,验证算法的有效性和性能。该数据集包含:1台Velodyne HDL-64E三维激光雷达,用于采集三维点云信息;2台1.4 Megapixels:Point Grey Flea 2(FL2-14S3C-C)彩色相机,用于采集彩色RGB图像。
3.2 实验结果与分析
实验运行的过程中,在可视化界面Rviz下可以得到实时的激光点云与视觉特征点,如图5所示。

图5 当前帧视觉特征点与激光点云Fig.5 Current-frame visual feature point with laser point cloud
图6所示为本文算法与LIMO算法[9]在Sequence 01数据集上的轨迹对比,通过使用evo工具进行数据对齐。图6(a)为本文算法估计轨迹、LIMO算法估计轨迹和真实轨迹的对比,容易看出,本文算法相较于LIMO算法更接近于真实轨迹。图6(b)为本文算法和LIMO算法分别在x轴、y轴和z轴的数据对比,可以看出,两种算法在x轴的估计值与真实轨迹较为符合,在y轴出现估计值与真实轨迹误差逐渐变大的情况,但本文算法相较于LIMO算法有明显提升。
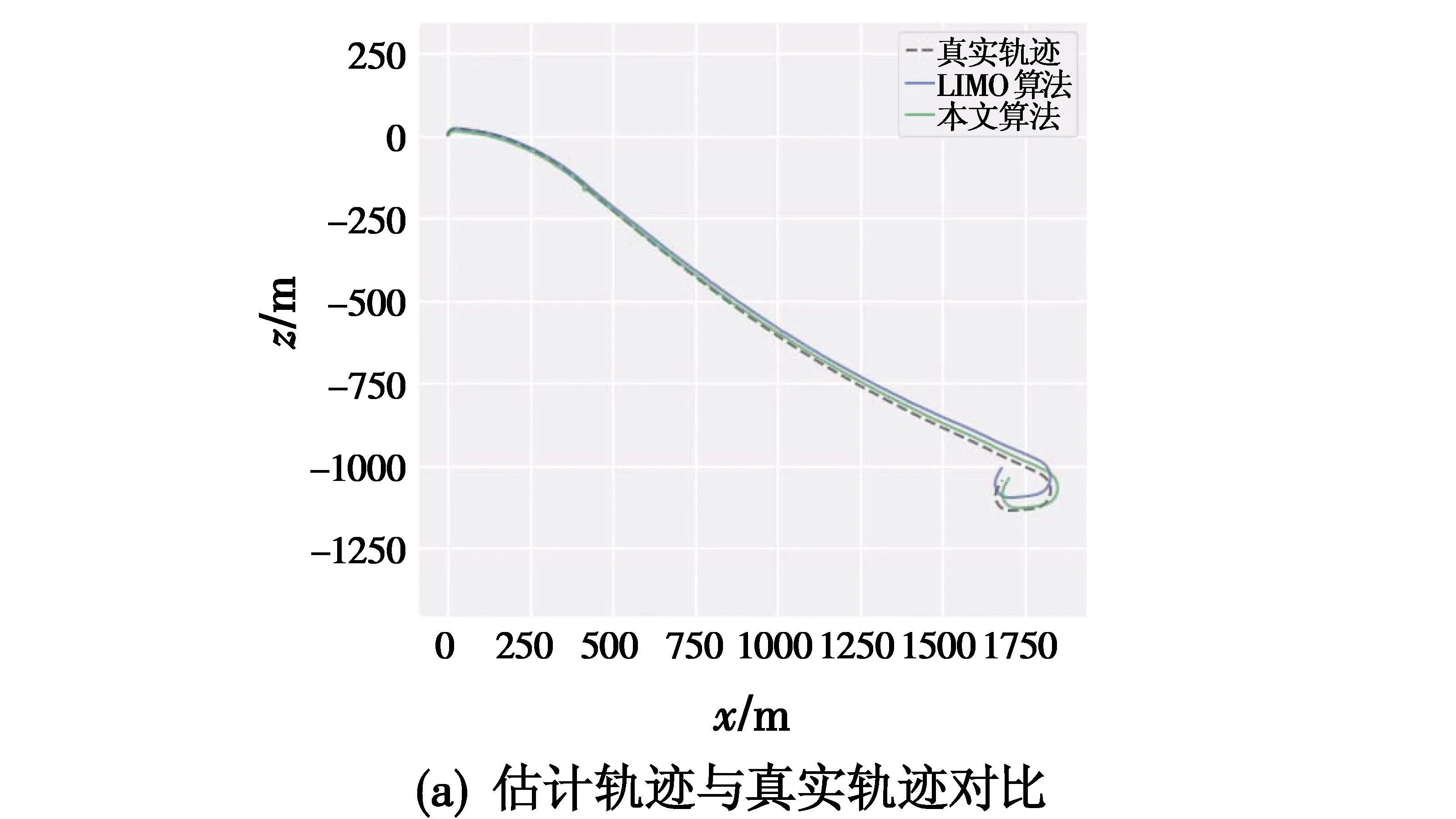
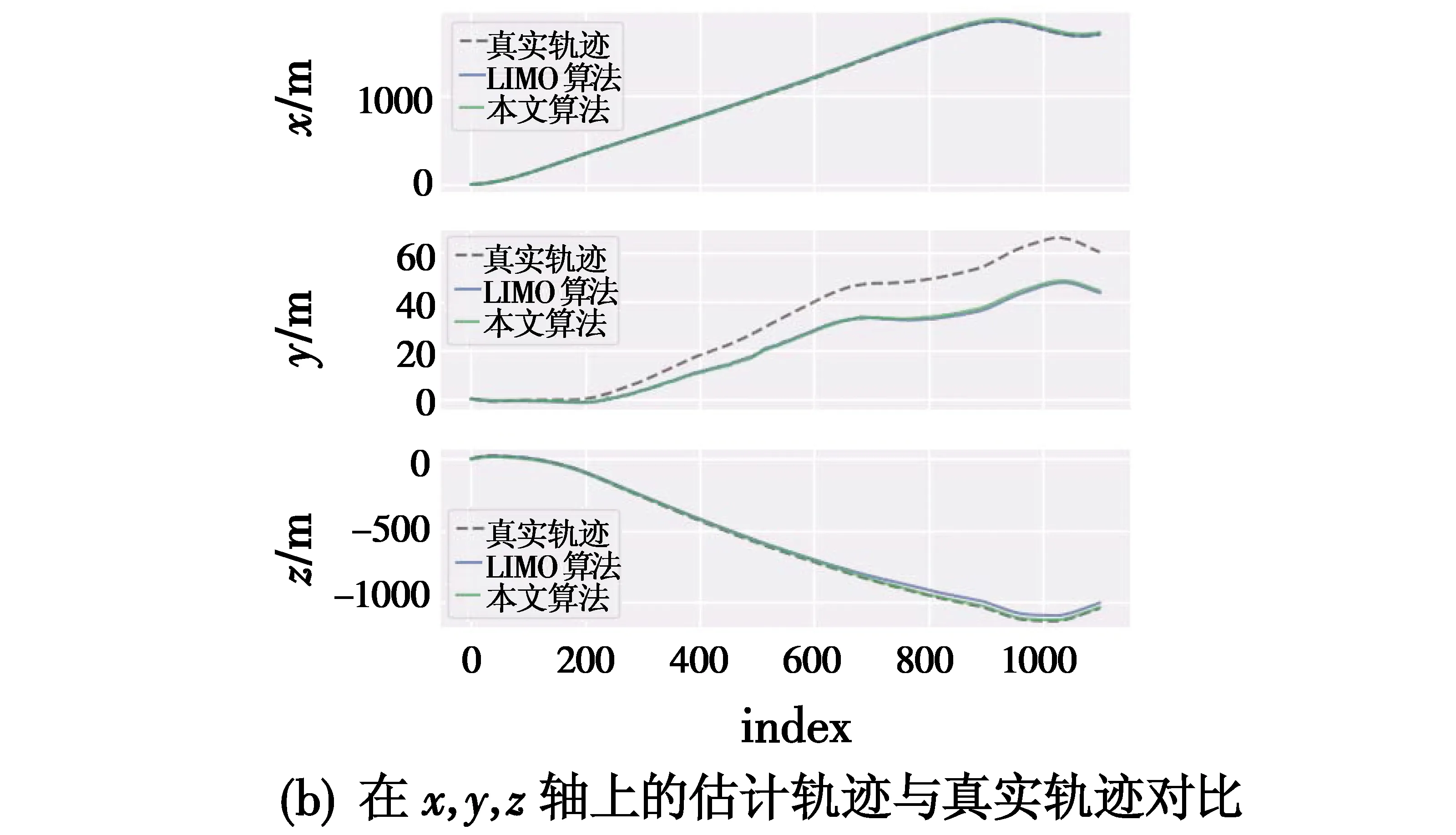
图6 本文算法与LIMO算法轨迹对比Fig.6 The trajectory of our algorithm and LIMO algorithm
为进一步评估本文算法的性能,本文采用evo工具中提供的绝对位姿误差(Absolute Pose Error,APE)对比算法的定位精度,验证本文算法对于定位精度的准确性与鲁棒性的提升,对两种算法在Sequence 01与Sequence 04数据集上分别进行10次实验,取两种算法在10次实验中旋转部分APE、平移部分APE与同时考虑旋转和平移APE的平均值,统计结果如表1所示。

表1 算法绝对位姿误差比较Table 1 Comparison of absolute pose errors of the algorithms
通过对表1中数据分析可得,本文算法相较于LIMO算法在Sequence 01数据集的平移部分误差降低了9.657%,在旋转部分降低了15.581%;相较于LIMO算法在Sequence 04数据集的平移部分误差降低了8.198%,在旋转部分降低了13.300%;由于旋转部分误差较小,常用平移部分误差代替整体位姿误差,因此两种算法在同时考虑平移与旋转APE的提升与平移部分APE的提升基本一致。
4 结束语
本文对单目SLAM与激光SLAM融合的前端里程计进行设计。在里程计执行前,先对上一帧中特征点的深度值进行判断,然后根据3种判断结果提出各自对应的位姿估计方式,解决了激光与视觉融合SLAM中特征点深度值的缺失导致位姿估计不准确的问题。最终经过在KITTI数据集上进行反复实验验证了算法在定位准确性和鲁棒性上均有所提升。
