一种随机平均分布的集成学习方法
2022-02-19艾旭升盛胜利李春华
艾旭升 盛胜利 李春华
1(苏州工业职业技术学院软件与服务外包学院 江苏 苏州 215104) 2(苏州科技大学电子与信息工程学院 江苏 苏州 215009)
0 引 言
情感引导非语言的社会信号(例如肢体语言和面部表情)表达需求,需求和欲望是人类交流中重要的副语言信息。目前,语音情感识别在医疗和心理咨询、客户服务和电信等领域已经有着广泛的应用。在医疗领域,语音情感识别可以帮助临床医生在线评估患者因情绪困难而产生的心理障碍。在客户呼叫中心行业中,语音情感识别自动检测客户的满意度,提高服务质量。在电信领域,语音情感识别帮助调度中心优先接入高优先级的紧急呼叫。
近年来,注意力模型引起了学术界的广泛关注。特别是在图像处理、语音识别和自然语言处理领域,注意力模型与卷积循环神经网络的结合可以更好地聚焦输入目标,成为学术界关注的热点。在语音情感识别中,各个帧对情感的影响并不相同,注意力模型估计每个帧的重要性,而不是简单取平均值或最大值,有利于卷积循环神经网络更准确地识别目标情感。在训练过程中,学习算法往往采用交叉熵损失函数评价模型的好坏,通过减少损失函数值逐渐逼近最佳模型。然而大多数语音情感样本的样例分布并不平衡,存在多数类样例数大于少数类样例数的现象,训练得到的模型识别少数类的能力偏低,影响模型的整体性能。因此,在不平衡样本上训练模型时,需要考虑不平衡问题,防止模型向多数类偏置。
为解决传统机器学习中的不平衡问题,学术界已经提出了很多方法或算法,一些方法在深度学习领域仍然适用。比如Bagging并不与具体算法相关,方便迁移到深度学习领域。然而,当基于放回抽样的Bagging应用到深度学习时,经过有限轮学习后,基分类器的训练误差尽管接近0,重复的训练样例还是带来了过学习风险,降低综合分类器的情感识别能力。为解决传统Bagging方法的过学习问题,本文基于机会均等原则,提出一种随机平均分布的集成方法(Redagging)。Redagging等概率地把训练样例放入子训练样本,避免子训练样本中的重复样例,提高综合分类器的预测能力。图1展示了在10个IEMOCAP样本上两种集成方法的实验结果,深色柱体代表Bagging基分类器的平均UAR(Unweighted Average Recall),浅色柱体代表Redagging基分类器的平均UAR。可以看出,在大多数样本上,Redagging基分类器的平均UAR明显高于Bagging基分类器的平均UAR,因而只要保证Redagging基分类器的异构性,理论上Redagging综合分类器的性能将超越Bagging综合分类器的性能。
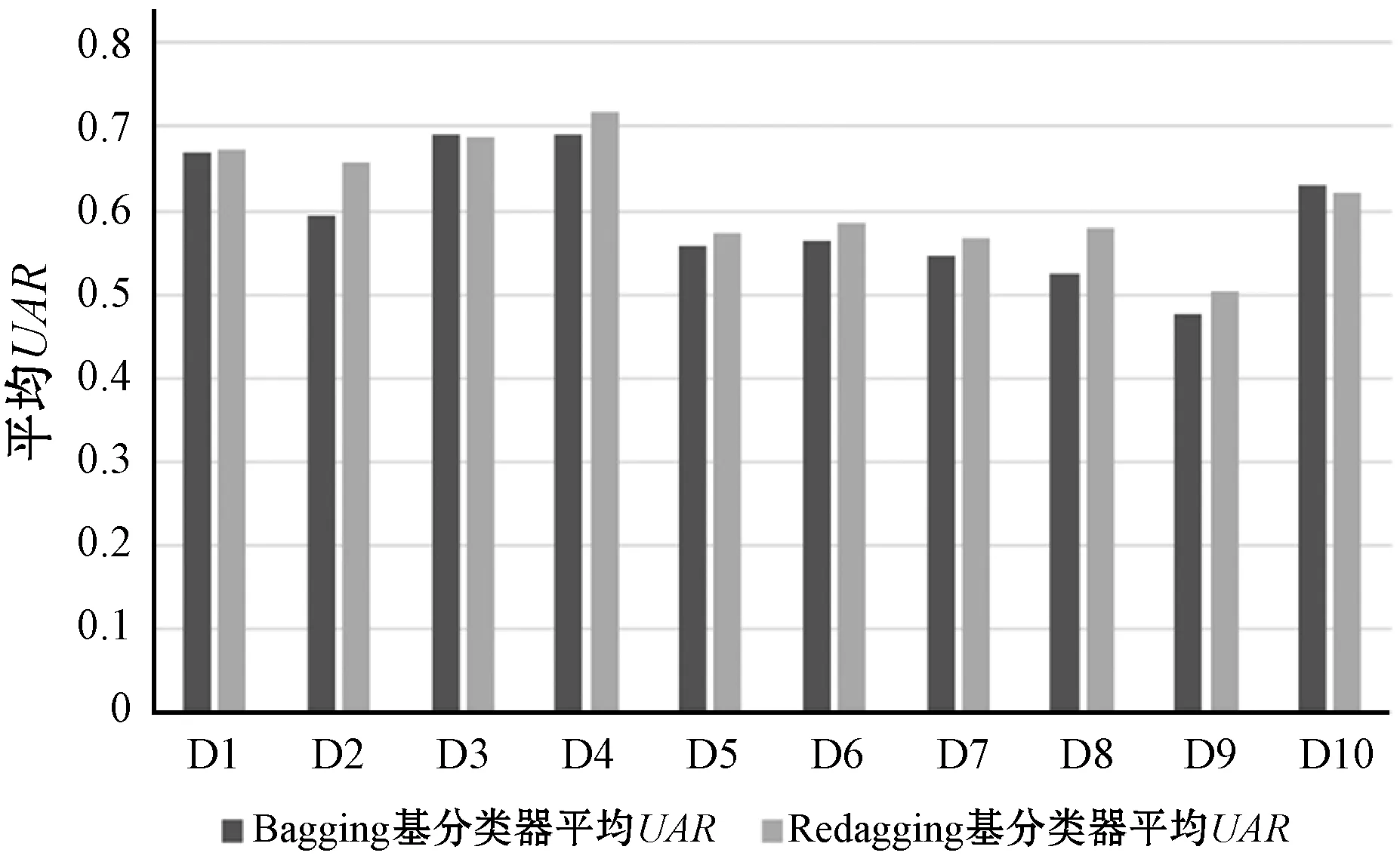
图1 两种集成学习方法的基分类器比较
1 相关工作
语音情感识别研究初期,大多采用传统机器学习方法,语音信号转化为统计特征后,语音情感识别转化为多分类问题[1-2]。随着深度学习在图像识别方面的成功应用,深度学习也开始解决语音情感识别问题,其中卷积循环神经网络和注意力模型受到广泛关注[3-4]。Lee等[5]开始采用双向长短期记忆网络(BiLSTM)抽取高层属性,情感识别准确率明显提高。Trigeorgis等[6]结合卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM),抽取语音信号代表的高层特征,进一步提高了识别精度。Chen等[7]在前面工作的基础上,提出融入关注度模型的卷积循环神经网络,处理3通道的底层特征,显著提高了卷积循环神经网络的情感识别能力。Latif等[8]采用多种滤波器宽度的并行卷积层,直接从原始语音中捕获各种上下文信息,取得了良好的实验效果。Kwon[9]提出深度跨步卷积神经网络(DSCNN),聚焦语音信号的显著性和描述性特征,从而提高预测准确率。
同时,深度学习的不平衡问题也引起研究者的重视,学者开始重新评估以往不平衡问题的解决方法,试图迁移到深度学习领域。Hensman等[10]研究不平衡数据集对CNN神经网络的影响,指出过采样是抵消样本分布不平衡的可行方法。Lin等[11]在交叉熵损失函数的基础上,提出焦点损失函数(Focal Loss),在存在大量背景样本的情况下,显著提高前景物体的识别精度。Etienne等[12]通过声道长度扰动合成少数类样例,合成的少数类样例和原样本一起训练模型,改善模型预测少数类的能力。Buda等[13]比较多种不平衡问题解决方法,分析不平衡数据集对CNN神经网络分类的影响,认为不平衡问题确实存在,需要采用过采样方法和选取合适的阈值来提高模型的预测能力。Zheng等[14]从不同角度抽取情感特征来构建异构基分类器,然后使用集成学习方法执行情感识别任务。目前,在深度学习领域,集成学习解决不平衡问题的研究还很少,缺乏集成学习方法和其他不平衡学习方法的比较研究,而易于移植的集成学习方法是快速提高学习算法性能的常用途径之一,迁移集成学习方法到深度学习领域具有重要的研究价值。
一般来说,集合学习方法分为三种:Bagging[15]、Boosting[16]和Stacking[17]。Bagging采用有放回抽样构建子训练样本,每个子训练样本构建一个模型,最终的分类结果由全部模型的投票结果决定。Boosting通过增加错误分类样例的权重和降低正确分类样例的权重逐步提高模型的分类能力,是一种串行集成方法。Stacking先训练多种类型的基分类器,然后把多个基分类器的输出作为输入传输到元分类器,最后由元分类器判定分类结果。Boosting是通过降低训练误差而提高泛化误差,而深度学习算法经过有限轮后训练误差逼近0,因而Boosting并不适用深度学习任务。Stacking构造多种类型的基分类器,不适用提升单种模型的预测能力。Bagging通过抽样样本构建异构的基分类器,与具体学习算法分离,并且基分类器构建过程并行进行,具有良好的移植性和扩展性。本文提出的Redagging方法仍然具备Bagging的优点,与Bagging相比,Redagging有2个不同点:(1) 训练样例在一个子训练样本中很少重复出现;(2) 训练样例平均分布到子训练样本。
2 卷积循环神经网络和注意力模型
2.1 输入向量
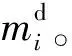
mi=log(qi)
(1)
(2)
(3)
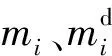
2.2 卷积循环神经网络
输入x后,首先卷积层(CNN)捕捉低层特征,接下来的BiLSTM层包含2个LSTM单元,分别顺序和逆序提取高层特征,接着进入全连接层后,输出向量p=(p1,p2,…,pT)。任意t∈{1,2,…,T},pt代表情感et的概率,最后标签y判定为T个情感中pt取得最大值的情感。卷积循环神经网络(CRNN)结构如图2所示,其中通道数c为1或3。
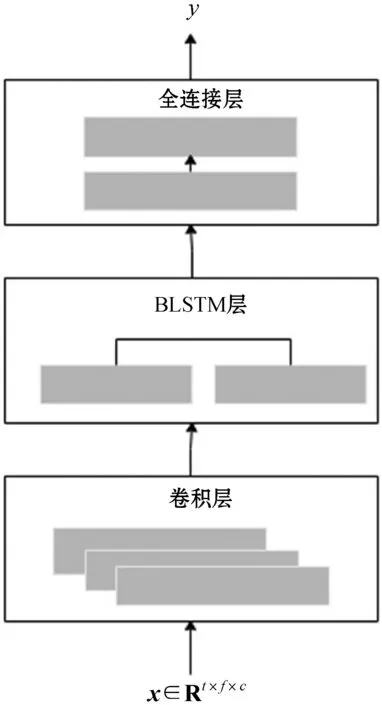
图2 卷积循环神经网络
CRNN的BiLSTM层简单地认为每个帧对目标情感的贡献度相同,但研究证明各个帧对目标情感的贡献度并不一致[4],而图2的网络结构并没有考虑由此带来的影响,下面给出一种融入注意力模型的卷积循环神经网络模型ARCNN以解决这一问题。
2.3 融入注意力模型的卷积循环神经网络
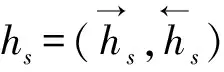
(4)
式中:W表示可训练的网络参数。
(5)
ARCNN整体设计如图3所示。
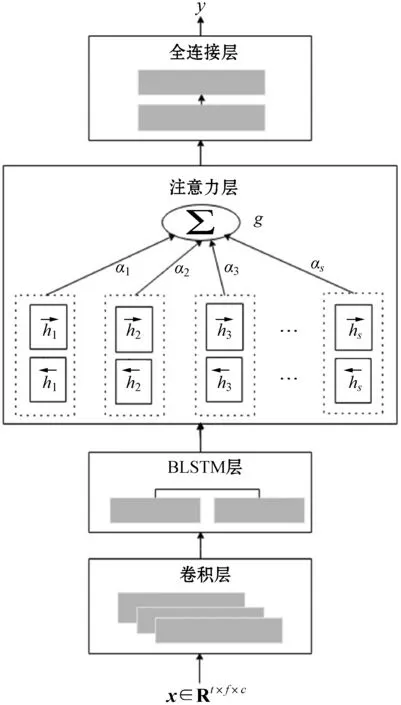
图3 注意力卷积循环神经网络
基于图3定义的网络结构,ARCNN各层的参数设置如表1所示。每个全卷积层都跟着一个Max池化层,最后一个池化层输出大小为300×5×512,经过全连接层后,转化为768维的序列,再经过BiLSTM层后,向量大小变成300×256。接下来的全连接层转换到300×1向量,然后采用式(4)和式(5)计算语句情感特征,再经过全连接层和Softmax激活函数后,输出概率最大的分量下标y。
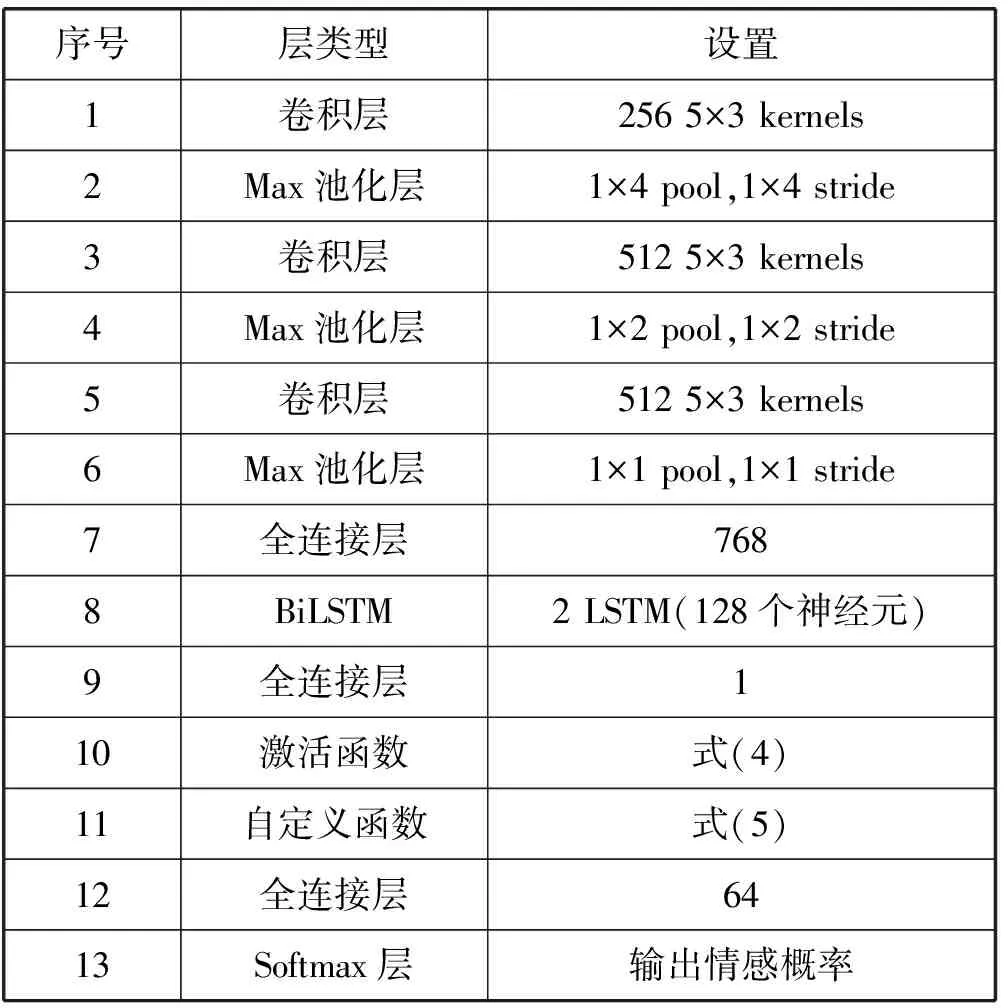
表1 ARCNN架构
需要说明的是,每个池化层、第1个全连接层和第3个全连接层都跟着BatchNormalization层[18]和LeakyLeRU[19]激活层。因为BatchNormalization层和LeakyLeRU激活层不改变向量维度,为节省空间没有在表1中列出。后面的实验把ARCNN作为基准方法或基分类器。
3 基于随机平均分布的集成学习方法
给定一个训练集D={(x1,y1),(x2,y2),…,(xm,ym)},xi∈X,yi∈Y,X代表样例空间,Y={0,1,…,T-1}。按照yi值进行划分,得到T个训练子集{D1,D2,…,DT},任意t∈{1,2,…,T},Dt中的元素yi值相同。为讨论方便,假设|D1|<|D2|<…<|DT|,|Dt|代表Dt的大小。
3.1 Bagging
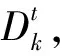
算法1Bagging

输出:H(x)=argmax(p)
%argmax取p最大分量的下标
fork=1,2,…,K
fort=1,2,…,T
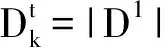
end for
end for
p=(h1(x)+h2(x)+…+hK(x))/K
%取平均值
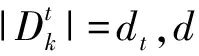
证明:事件A0:x不出现,那么:
事件A1:x出现1次,那么:
因为P(A)=1-P(A0)-P(A1)=
已知d→+∞,dt≈d,因此:
为了避免自举样本重复样例带来的过学习问题,需要减少重复样例。另外,基分类器的异构性同样重要,同构的基分类器也不能提高模型的识别能力。
3.2 Redagging
Redagging基于标签t的训练子集Dt,随机生成不少于K|D1|个样例的样本池Dt*,然后把Dt*按照顺序分配到每个自举样本Dk。因为新方法把每个样例随机平均分布到自举样本,所以命名为随机平均分布集成方法(Redagging)。其中:K代表自举样本数,|D1|代表训练集中少数类样例数;|DT|代表多数类样例数。Redagging的伪代码实现如算法2所示,其中伪随机数采用NumPy[20]提供的梅森旋转算法[21]接口生成。
算法2Redagging
输出:H(x)=argmax(p)
%argmax取p最大分量的下标
fort=1,2,…,T
fori=1,2,…,I
r=产生一个伪随机数;
Dt,i=基于r生成Dt的随机排列;
end for
Dt*=Dt,1∪Dt,2∪…∪Dt,I;
%Dt*为标签t生成至少K|D1|个样例
end for
fork=1,2,…,K
fort=1,2,…,T
%[]取Dt*中第k段t标签样本
end for
end for
p=(h1(x)+h2(x)+…+hK(x))/K
%取平均值
与Bagging相比,Redagging在所有自举样本上平均分布样例,重复样例很低,自举样本由于随机数种子不同,仍然保持样本间的差异性。在10个IEMOCAP[22]数据集上比较Bagging和Redagging,实验结果如图4所示。可以看出,Redagging基分类器的平均UAR高于Bagging基分类器的平均UAR,表明自举样本的重复样例造成性能下降;并且,Redagging的UAR也高于基分类器的平均UAR,反映了基分类器的异构性。
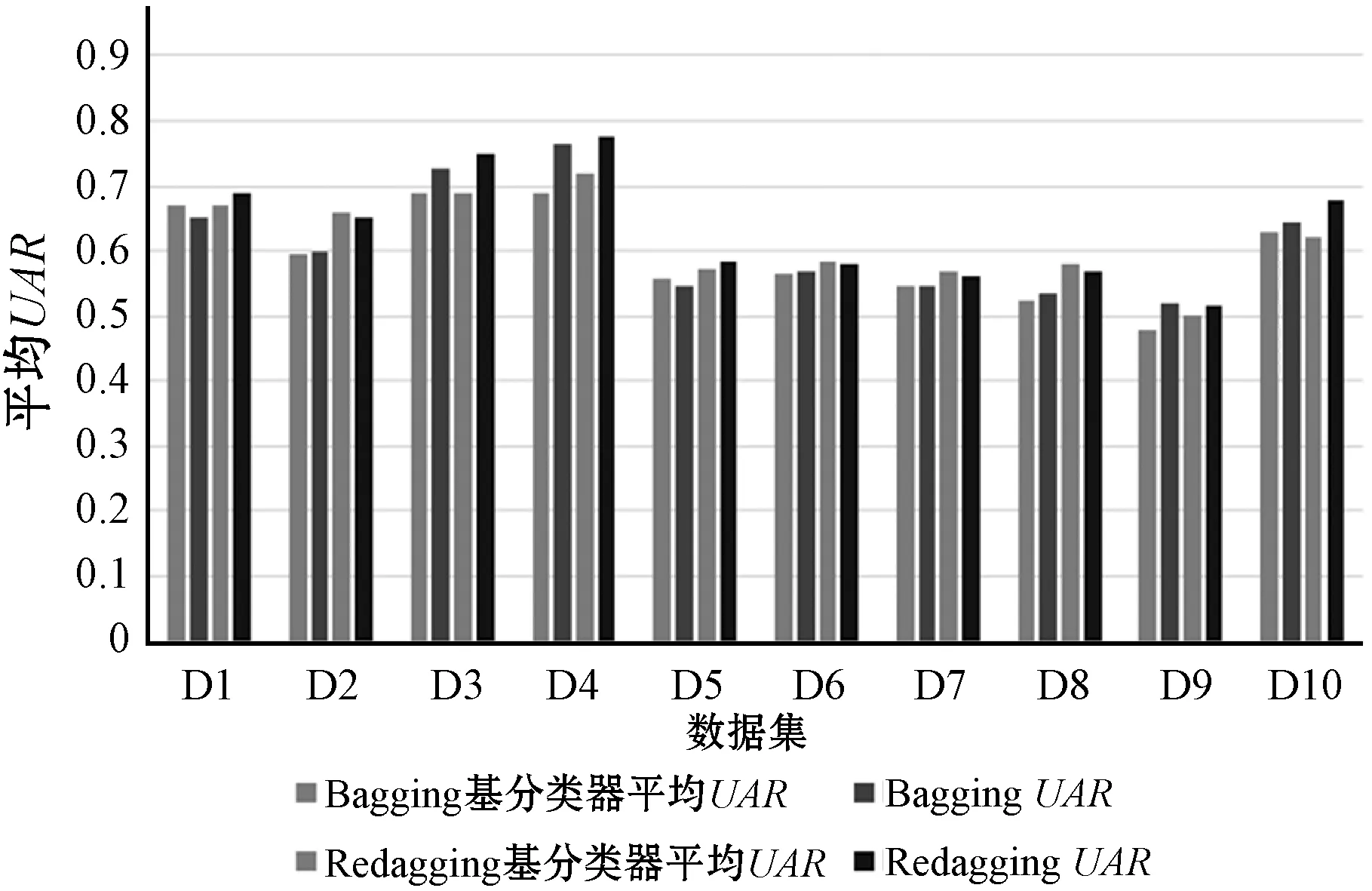
图4 两种方法在10个IEMOCAP数据集上的UAR比较
4 实验与结果分析
实验运行在H3C G4900服务器上,服务器配置Tesla V100独立32 GB GPU显卡,安装Python 3.7.0、CUDA 10.01加速平台和cuDNN 7.4.2.24深度学习加速平台。
语音信号通过python_speech_features库[23]转换语音信号到输入向量,窗口大小等于25 ms,位移等于10 ms,采用NumPy[20]数组存储向量和执行矩阵运算。为区别通道数c=1或c=3两种情况,命名ARCNN有两个别名:通道数c=1时,ARCNN命名为ARCNN-2D;输入通道数c=3时,ARCNN命名为ARCNN-3D。ARCNN各层调用Keras[24]函数实现,采用categorical_crossentropy损失函数[25]评价模型,选择Adam优化器[26],学习率设为10-3。
在IEMOCAP和EMODB[27]数据集上,ARCNN-2D和ARCNN-3D作为基准方法,与过采样、Bagging、欠采样、Redagging作比较。过采样随机复制训练集中的少数类样例,直到所有标签的样例数相同。欠采样随机去除训练集中的多数类样例,直到所有标签的样例数相同。Bagging参照算法1,ARCNN-2D和ARCNN-3D作为基分类器。Redagging参照算法2,ARCNN-2D和ARCNN-3D作为基分类器。考虑到初始化权重的随机性,每个实验任务运行5次,取5次运行结果的平均值作为实验结果。
4.1 基于IEMOCAP数据库的性能比较
IEMOCAP由五个会话组成,每个会话由一对发言者(女性和男性)在背诵台词和即兴表演情景中完成。样例平均时长为4.5 s,采样率为16 kHz,实验在高兴、愤怒、悲伤和中性四种情感样本上运行。每个任务使用10-fold交叉验证技术,每个样本中的1个说话人构成测试集,另外1个说话人构成验证集,其余8个说话人构成训练集,10个样本的训练集描述如表2所示,验证集和测试集的不平衡比与训练集的不平衡比接近。实验中Bagging和Redagging的K值设为5,当K>5,两种方法的性能没有显著提升。
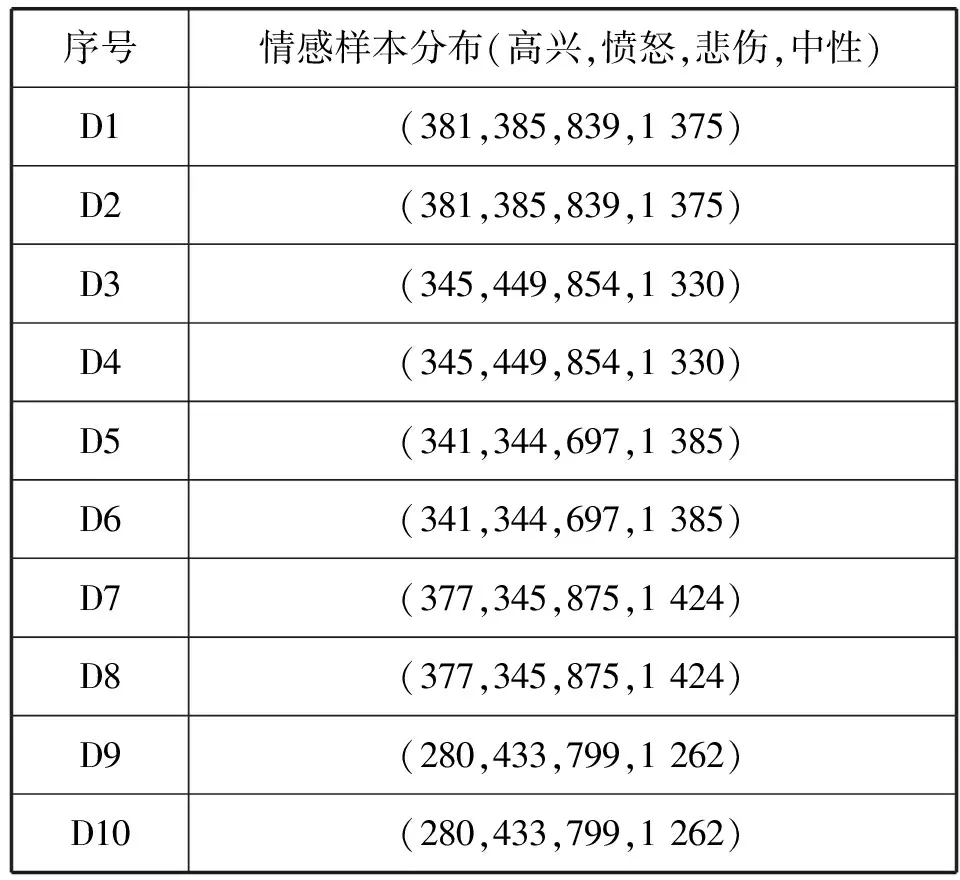
表2 IEMOCAP训练集描述
在10个IEMOCAP样本上测试ARCNN和4种不平衡方法,每个训练集上循环10代取得最高UAR的模型,保存在验证集上,五种方法在测试集上的平均UAR如表3所示。可以看出,在五种方法中,Redagging表现最好,欠采样和过采样次之,采用ARCNN-3D作为基分类器的Bagging方法优于未采样的ARCNN-3D,但采用ARCNN-2D作为基分类器的Bagging方法和未采样的ARCNN-2D保持在一个水平。为了进一步比较五种方法的整体表现,进一步统计每个方法在10个样本上的平均排名,统计结果如图5所示。可以看出,当ARCNN-2D作为基准方法时,采用ARCNN-2D作为基分类器的Redagging平均排名最靠前,欠采样次之,紧跟着是过采样和采用ARCNN-2D基分类器的Bagging方法,平均排名最低的是未采样的ARCNN-2D;当ARCNN-3D作为基准方法时,采用ARCNN-3D作为基分类器的Redagging平均排名仍然最靠前,欠采样次之,过采样和采用ARCNN-3D基分类器的Bagging方法并不比未采样的ARCNN-3D排名靠前。
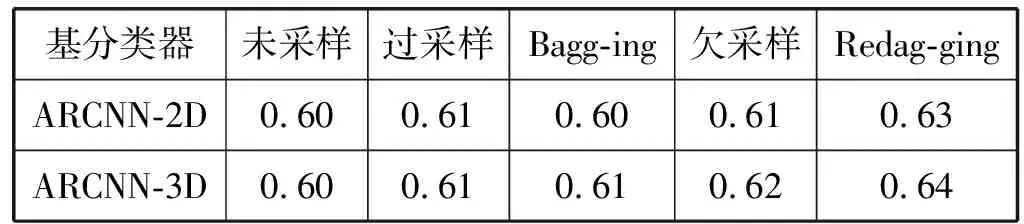
表3 五种方法在10个IEMOCAP样本上的平均UAR
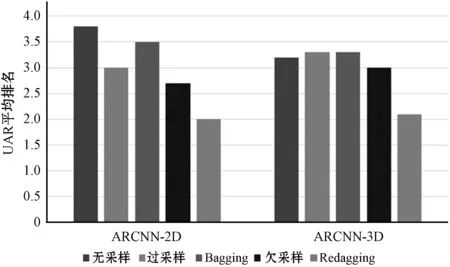
图5 五种方法在10个IEMOCAP样本上的召回率平均排名
F1值是召回率和精度的加权平均,当评价不平衡学习方法时,F1值是一个重要指标。当算法在10代内取得最大召回率时,对应的平均F1值如表4所示。可以看出,在五种方法中,Redagging表现最好,欠采样次之,过采样和Bagging并没有显著提高未采样的ARCNN性能。为了进一步比较方法在不同样本的表现,统计每个方法在10个样本上的F1值平均排名,统计结果如图6所示。可以看出,在五种方法中,Redagging平均排名最靠前,欠采样紧随其后,过采样和Bagging平均排名垫底。需要指出的是,尽管采用ARCNN-2D基分类器的欠采样方法提升了ARCNN-2D性能,但由于欠采样是随机去除训练样例训练单个分类器,性能容易波动。在表4中,基于ARCNN-2D的欠采样方法比基准方法的平均F1值高,而在图6中,它的F1值平均排名比基准方法靠后,正反映了欠采样方法的不稳定性。
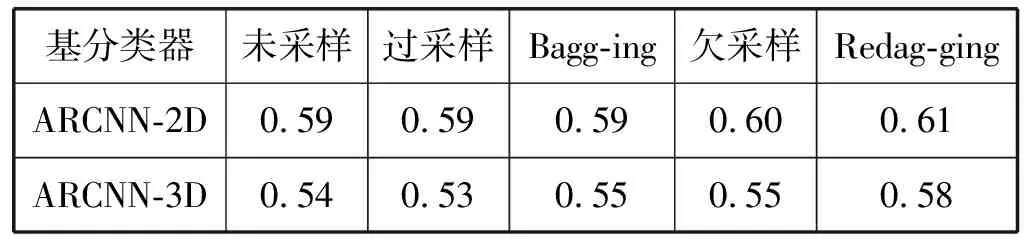
表4 五种方法在10个IEMOCAP样本上的平均F1值
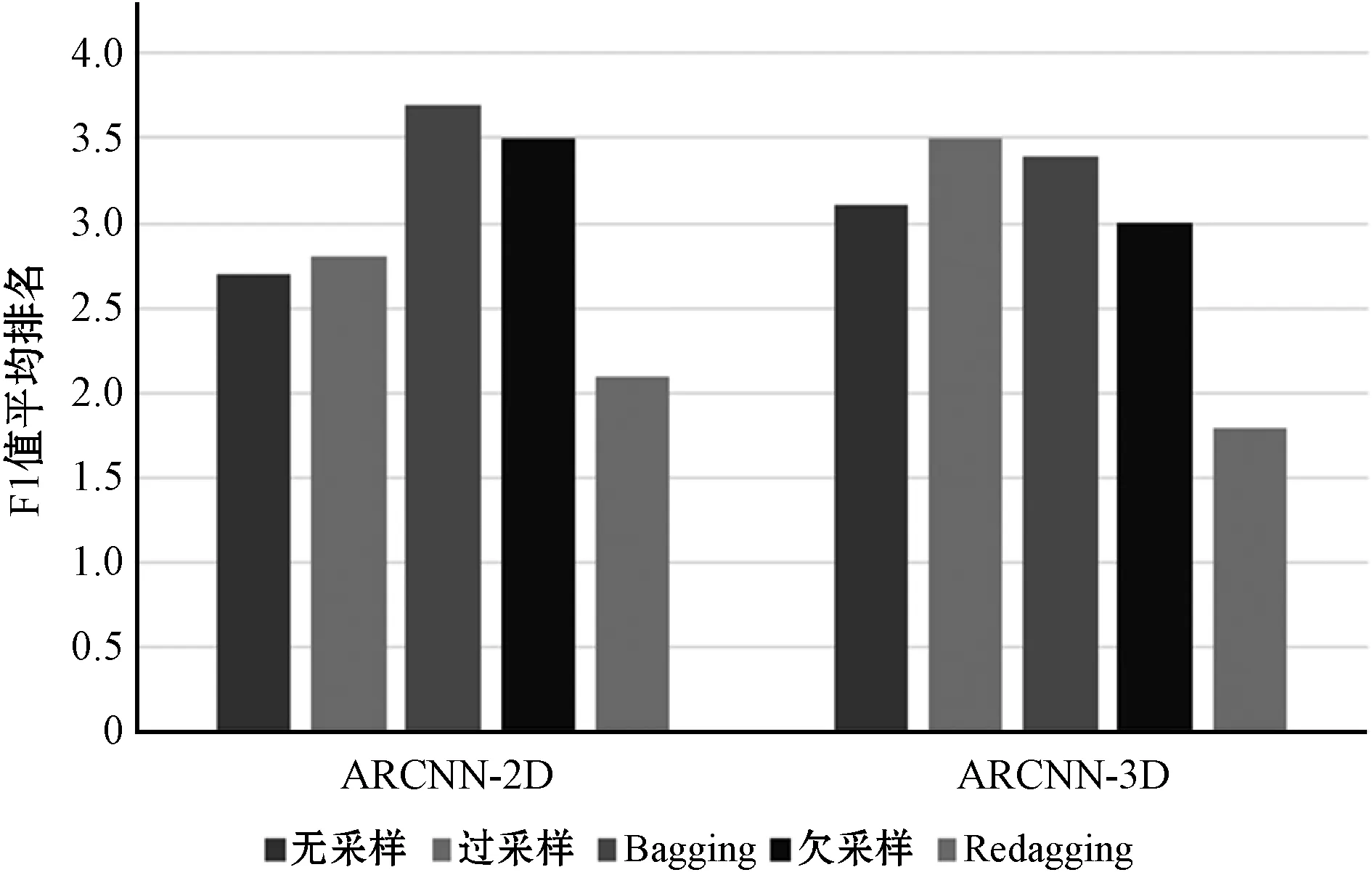
图6 五种方法在10个IEMOCAP样本的F1值平均排名
在表3和表4中,ARCNN-3D性能并没有超越ARCNN-2D,原因可能是ARCNN-3D输入有更多的通道,需要采用更多的卷积层。这种超出了本文的讨论范围,并且性能更好的分类器也会带来不平衡方法的性能提升,不会影响上面的分析结果
4.2 基于Emo-DB数据库的性能比较
Emo-DB由10位专业演员的535句话组成,涵盖7种情绪(中立、恐惧、喜悦、愤怒、悲伤、厌恶和无聊),原始音频在44.1 kHz采样,后来下采样到16 kHz。尽管大多数论文采用了全部7种情感,但事实上焦虑和厌恶两种情感在某些验证集上样例数小于3个,而每次实验是在25代中找到UAR最高的模型,采用这两种情感样本易于造成实验数据波动,因此在本实验中只采用了愤怒、无聊、高兴、悲伤和中性五种情感样本。实验使用10-fold交叉验证技术。每个样本中的1个说话人构成测试集,另外1个说话人构成验证集,剩下的8个说话人构成训练集,10个样本的训练集描述如表5所示,验证集和测试集的不平衡比与训练集的不平衡比接近。实验中Bagging和Redagging的K值设为4,当K>4,两种方法的性能没有显著提升。
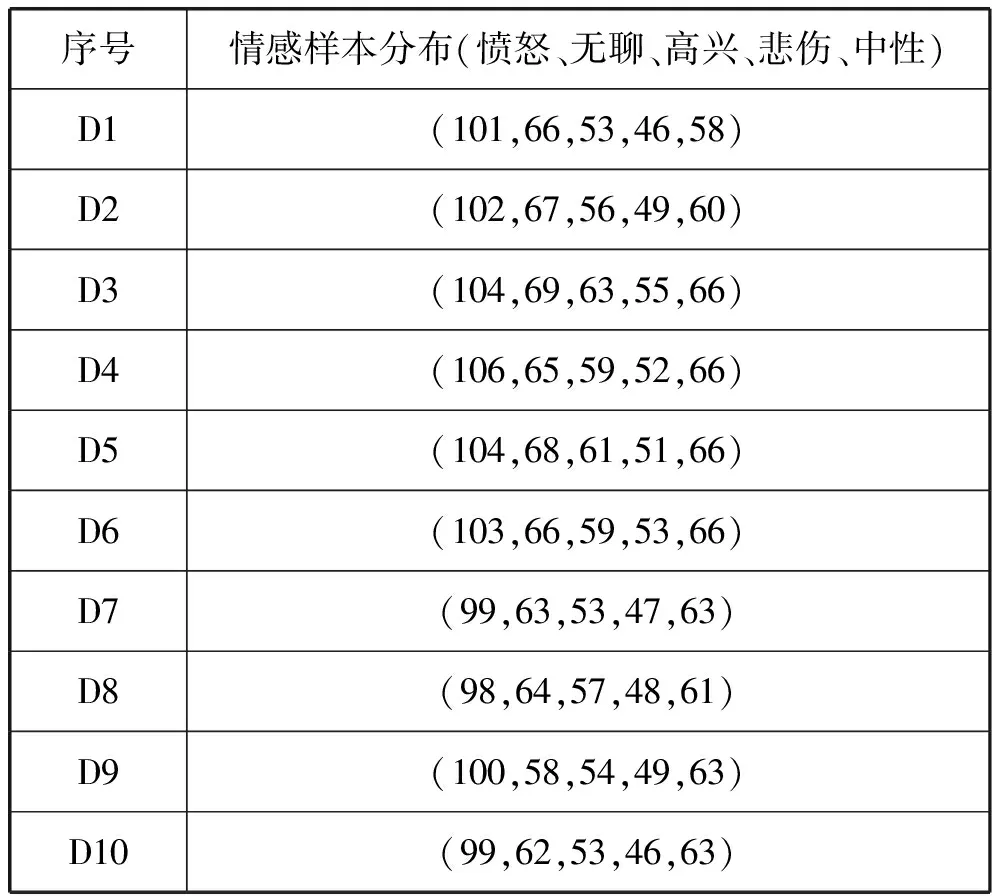
表5 EMODB训练集描述
在10个EMODB样本上测试ARCNN和4种不平衡方法,每个训练集上循环25代,取得最高UAR的模型保存在验证集上,五种方法在测试集上平均UAR如表6所示。可以看出,在五种方法中,Redagging表现最好,过采样次之,然后是Bagging,欠采样并没有提升ARCNN性能。为了进一步比较5种方法的整体表现,进一步统计每个方法在10个样本上的UAR平均排名,统计结果如图7所示。
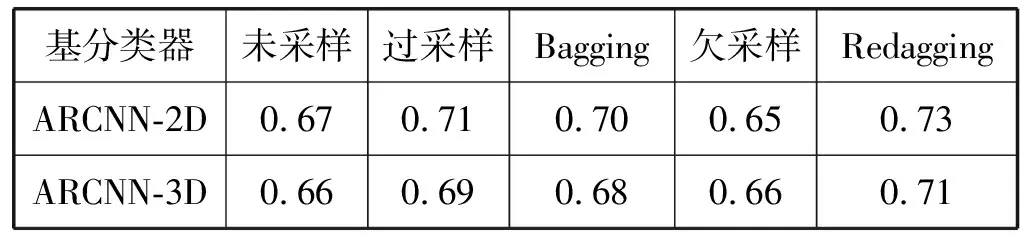
表6 五种方法在10个EMODB样本上的平均UAR
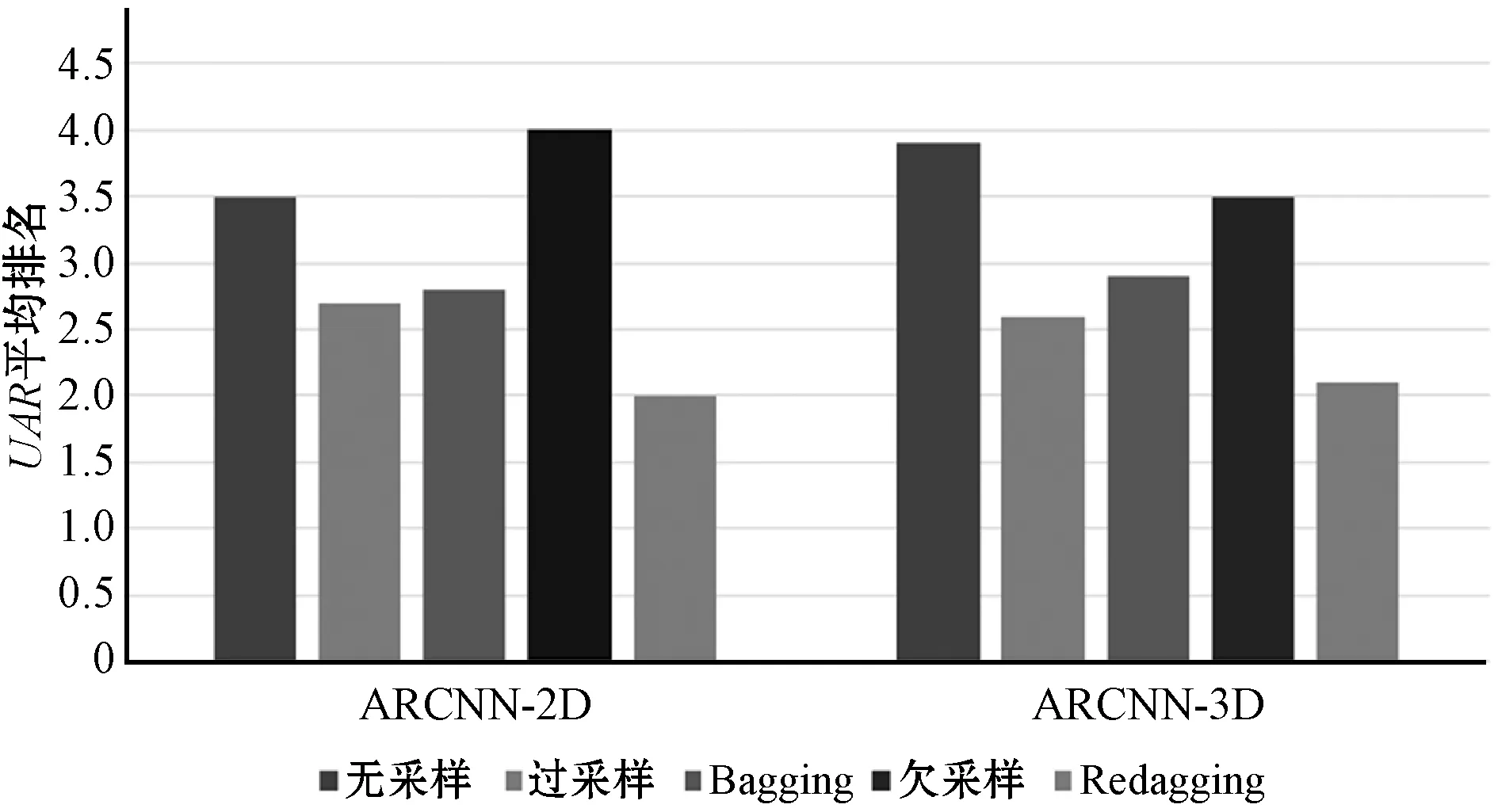
图7 五种方法在10个EMODB样本上的UAR平均排名
可以看出,当ARCNN-2D作为基准方法时,采用ARCNN-2D作为基分类器的Redagging平均排名最靠前,过采样次之,紧跟着是采用ARCNN-2D基分类器的Bagging方法,欠采样平均排名跟在ARCNN-2D之后;当ARCNN-3D作为基准方法时,采用ARCNN-3D作为基分类器的Redagging平均排名仍然最靠前,过采样次之,采用ARCNN-3D作为基分类器的Bagging方法紧随其后,然后是欠采样,未采样的ARCNN-3D平均排名最低。
当算法在25代内取得最大UAR时,对应的平均F1值如表7所示。可以看出,与未采样的ARCNN相比,不平衡学习方法都提高了平均F1值,其中Redagging提高最显著。为了进一步比较方法在不同样本的表现,进一步统计每个方法在10个样本上的平均排名,统计结果如图8所示。可以看出,在五种方法中,Redagging平均排名最靠前,其他不平衡学习方法的平均排名也高于未采样的ARCNN。
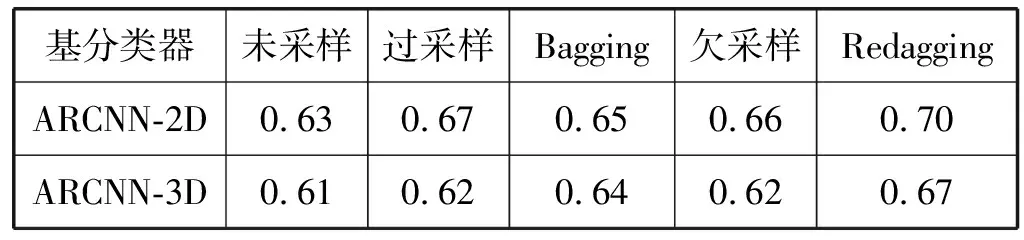
表7 五种方法在10个EMODB样本上的平均F1值
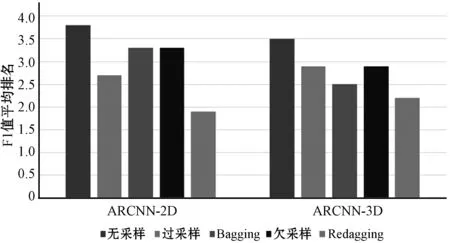
图8 五种方法在10个EMODB样本的F1值平均排名
如果采用更多的卷积层,ARCNN-3D可能优于ARCNN-2D,但这个差异不影响Redagging的优越性,因为性能更好的基分类器也会进一步提升Redagging性能。整体而言,在IEMOCAP和EMODB两个数据库上的实验表明,从UAR和F1值两个指标来看,Redagging不仅优于Bagging,也优于重采样和欠采样方法,有效提高了ARCNN的情感识别能力。
5 结 语
本文基于卷积循环网络和注意力模型,提出基于随机平均分布的集成学习方法(Redagging),解决了Bagging方法的过学习问题,提升了ARCNN的分类性能。在IEMOCAP和EMODB数据库的实验结果表明,与包括Bagging在内的其他不平衡学习方法相比,不管单通道输入向量还是3通道输入向量,Redagging都能提升卷积循环神经网络和注意力模型的情感识别能力,验证了本文方法的有效性。
Redagging是Bagging方法的改进版本,独立于具体学习算法,适用于在不平衡数据集上提升基分类器(比如深度神经网络模型)的泛化能力。事实上,在机器学习技术的应用场景下,只要存在不平衡数据集带来的模型偏置问题,Redagging都可能有所帮助。本文以语音情感识别任务为例,证实了Redagging方法的合理性和有效性,未来将推广到图像识别领域,研究解决背景检测、异常行为检测和人脸属性识别等任务的不平衡问题。
