基于知识表示学习的实时语义数据流推理
2022-02-19顾进广
高 峰 熊 辉 顾进广
(武汉科技大学计算机科学与技术学院 湖北 武汉 430065)(湖北省智能信息处理与实时工业系统重点实验室 湖北 武汉 430065)
0 引 言
随着传感器网络、社交媒体和移动互联网等应用的发展,网络上产生了海量数据,数据的实时处理和分析具有重要意义。将实时数据流与知识图谱技术结合,对数据流进行知识标注后可得语义数据流(Semantic Data Stream),语义数据流处理系统(RDF Stream Processing, RSP)能将静态背景知识与动态信息结合,实现实时的、基于知识的查询和推理。
针对实时推理,已经出现了不少实时语义数据流推理平台,其中:集中式的系统包括C-SPARQL引擎[1],这是一种基于ESPER数据流处理引擎和Jena查询的流推理系统;分布式的系统包括基于LARS[2]架构的BigSR[3]流推理平台。它们都能在一定的程度上解决语义推理问题,但是传统的实时语义流推理平台在进行传递规则推理,特别是传递闭包规则推理时会产生大量中间结果,导致推理效率急剧下降[4-5]。
近年来,以深度学习为代表的知识表示学习技术发展较快[6]。知识表示学习是指在知识库中,以实体和关系为基础进行表示学习,实现对实体和关系之间语义信息的向量化表示。这种方式能够将实体之间复杂的语义关系转化为简单的向量计算,对于提升推理效率效果明显。因此,本文提出一种基于C-SPARQL平台和KALE知识表示学习模型[7]的CSKR(Continuous Sparql with KALE Reasoning)实时流推理平台。首先通过索引算法对ESPER引擎中实时数据流的谓语构建索引,再根据查询语句以及推理规则生成预测的三元组集合,最后输入给扩展的KALE模型并计算出推理结果。
1 相关工作
1.1 实时语义数据流推理
语义数据流中的信息是不断变化与更新的,因此传统的语义推理和查询的方法无法适用于这种情况。现在已经有一些工作能够处理动态RDF数据流。例如Streaming SPARQL[8]、C-SPARQL、CQELS[9]、EP-SPARQL[10]等。Streaming SPARQL 基于时代关系函数,用来扩展SPARQL语言,虽然支持RDF流处理,但是没有考虑到连续计算过程中状态共享的性能问题。C-SPARQL是一个基于ESPER数据流处理引擎和Jena组件的流推理平台,通过添加新的运算符来扩展SPARQL语言,从而支持对RDF数据流的处理。CQELS同时支持静态数据和动态数据并支持多源RDF流处理,可以提供优秀的查询性能,但是没有考虑并行的问题,对大数据集支持不好,大大降低了流处理性能。EP-SPARQL偏向于复杂事件处理和流推理,它可以转化成一种基于Prolog复杂事务处理框架语言ETALIS[11],并实现实时语义数据流推理和查询。LARS是一种基于逻辑的推理分析框架,在此基础上BigSR结合了Spark和Flink推出了分布式实时语义数据流推理平台,该平台吞吐量较大并且延迟在毫秒以内。虽然此类方法能利用分布式处理有效降低推理延时,但对硬件资源要求较高,本文方法则无此限制。
1.2 知识表示学习模型
在Mikolov等[12]提出了word2vec词表示学习模型之后,表示学习的方式在知识图谱的领域受到了广泛的关注。Bordes等[13]提出了TransE知识表示学习模型,这是一种既简单又高效的模型,该模型将三元组中的关系看作平移向量,表示头实体与尾实体之间的平移。因此,对于每一个事实三元组,都应当满足以下条件:
ei+rk≈ej
(1)
式中:ei表示头实体向量;rk表示关系向量;ej表示尾实体向量。
TransE模型的真值公式表示为:
(2)
式中:d表示向量空间的维度;I则表示每一个三元组经过计算之后得到的真值。
因为TransE模型的参数简单、计算复杂度低,但是性能高效的特性,大量研究工作对其进行扩展和应用,并且出现了大量基于TransE模型改进和补充的知识表示学习模型。例如TransH[14]、TransR[15]、TransA[16]TransD[17]等模型。其中:TransH是一种针对TransE当中不能很好解决实体和关系之间一对多、多对一和多对多问题的改进模型;而TransR认为不同的关系拥有不同的语义空间,因此它将实体和关系嵌入到不同的空间中,在对应的关系空间中实现翻译。
虽然以上模型都对TransE模型做了相应的改进,但是都没有利用三元组之间的关系。KALE模型在TransE模型的基础上根据Tim等[18]提出的关系抽取方式建立了三元组与推理规则的统一框架,改善了原有TransE模型训练过程中只利用了实体内部的联系而忽略了三元组之间推理规则的问题。因此本文以KALE模型为基础,提出了相应的KR推理机制,并应用于实时流推理平台。
2 CSKR平台框架
传统语义数据流推理中,主要包含ESPER流引擎、推理引擎和Sparql查询引擎,CSKR将其中的推理引擎转换为KALE模型并加入推理机制,将复杂的规则推理变成简单的向量计算,从而大大降低了推理延迟,用来满足大数据情况下的实时推理需求,CSKR推理主要包括以下几个步骤:
(1) 加载RDF数据,通过Jena解析,将RDF数据转化为ESPER数据流处理引擎可识别的数据格式。
(2) 读取解析后的数据,并加上时间戳,放入RDF数据流中。
(3) 从ESPER流引擎中取出指定窗口内的数据,作为输入数据输入到联合嵌入式模型当中。
(4) 联合嵌入式模型获取数据后,根据推理规则,预测可能存在的三元组集合,并将集合内的三元组进行向量计算后,依据目标函数的阈值进行分类,得出推理的三元组集合。
(5) 将推理结果放入Sparql引擎中进行查询,并返回查询结果。
CSKR平台总体框架如图1所示。
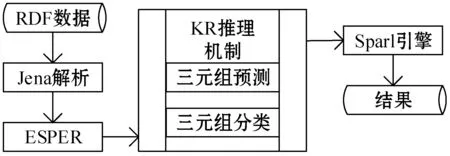
图1 CSKR平台总体框架
3 CSKR推理机制
本文在KALE的基础上进行扩展,得到针对传递性规则的知识表示模型。基本的KALE模型只能应用于链接预测和分类的场景,无法直接替换传统的推理引擎,因此本文提出一种基于三元组预测机制的CSKR推理平台。
3.1 推理规则和模型框架
目前传统实时语义流推理平台主要采用的推理规则是RDFS/OWL规则集。它们在RDF的基础上增加了对本体的描述和类型约束,并且添加了相关的推理规则。但是在推理过程中,因为传递规则尤其是传递闭包规则的复杂性,导致传统推理方法性能很差,所以产生了大量重复数据,计算量呈指数级的上升。
在知识表示学习方向,KALE模型将三元组之间的规则嵌入到表示学习过程当中,建立了规则和三元组之间的统一框架。KALE模型基于Tim等[18]提出的关系抽取方法,以逻辑连接词推理的方式对两种类型的规则建立了统一得分函数。
第一种类型为假设(em,rs,en)⟹(em,rt,en),则根据关系抽取以及逻辑连接词的推导,可以得到如式(3)所示的真值公式。
I(f)=I(em,,rs,en)·I(em,,rt,en)-
I(em,,rs,em)+1
(3)
式中:I表示三元组的真值。同样的第二种类型为(em,rs,en) ∧(en,rk,el)⟹(em,rt,el),可以得到如式(4)所示的统一真值公式。
I(f)=I(el,,rs,em)·I(em,,rk,en)·I(el,,rt,en)-
I(em,,rs,en)·I(en,,rk,el)+1
(4)
KALE模型具体框架如图2所示。

图2 KALE模型框架
KALE模型利用卷积神经网络分别学习三元组中实体和关系的描述,得到头、尾实体和关系的向量表示em、en、rs。基于上述工作,KALE模型对知识图谱中的三元组计算统一得分函数,对于正确的三元组,其得分越低越好;而对于一个负采样产生的样本,其得分越高越好,这样通过训练模型区分正负样本。因此,在模型训练过程中,采用合页损失函数作为训练目标,并使用随机梯度下降算法进行优化,其损失函数定义如式(5)所示[7]。
(5)
式中:S+为正实例三元组的集合;S-为负实例三元组的集合;I为统一得分函数;γ是margin的超参数,表示正负样本得分之间的间隔距离。
由于在实时推理中,传递性规则执行的效率较差,尤其是传递闭包产生大量中间结果导致性能下降,本文主要在KALE模型的基础上实现传递性规则和传递闭包规则的实时流推理模型。
3.2 索引分类
数据流中的三元组中的主语和宾语变化较为频繁,而其中的谓语则相对固定,例如存在两个不同的三元组(e1,r,e2)和(e3,r,e4),他们的谓语都是r,但是主语和宾语分别为e1、e2和e3、e4,根据这种情况,本文对谓语建立了相应的索引以提高推理效率。
每当读取一个新的三元组时,CSKR的数据流引擎抽取当前谓语,然后去索引节点中检索,如果节点中不包括该谓语,则对该谓语建立相应的索引,并在这个索引上建立对应的主语集合和宾语集合,最后将这个三元组的主语和宾语分别放入对应的集合;如果节点中包括当前谓语,则直接将三元组的主语和宾语放入对应的集合。当读取完所有的三元组数据之后,CSKR可以得到如图3所示的索引结构。

图3 KR算法索引结构
具体索引算法如算法1所示。
算法1索引算法
输入:triples。
输出:out。
begin
valout=outMap
for (tintriples) {
if (out.containsKey(t.p) {
out.get(t.p).get(subject).add(t.s)
out.get(t.p).get(object).add(t.o)
} else {
out.put(t.p,tripleMap)
out.get(t.p).put(subject,subjectSet)
out.get(t.p).put(object,objectSet)
out.get(t.p).get(subject).add(t.s)
out.get(t.p).get(object).add(t.o)
}
}
returnout
end
3.3 三元组预测和分类
为了将KALE应用于推理模型,CSKR首先需要生成预测三元组集合,再将预测三元组集合放入模型中计算得分函数。由于预测三元组集合的生成会根据数据特性生成不同数量的冗余数据,本文使用关系生成和实体生成两种不同的策略来生成预测三元组,并使用如下方式自动选择恰当的策略:在最开始的五次计算里,分别计算两种生成算法生成的预测三元组集合数量,然后选取数量少的集合作为输入参数进行接下来的计算,并对选取的策略标记加一,当五次采样结束后,CSKR会选取标记多的策略作为接下来的生成算法。
关系生成算法首先根据规则集中的关系推理解析查询语句,当查询中包含需要推理的规则时,CSKR会从索引节点中获取推理条件中谓语对应的主语集合与宾语集合,并与推理结果中的谓语组成新的预测三元组。例如存在如下传递推理规则:当三元组数据集中包含(e1,r1,e2)和(e2,r2,e3), 则一定可以推理出(e1,r3,e3)这样的新三元组。根据关系生成算法,推理引擎将会先获取r1的主语集合set1和r2中的宾语集合set2,并将set1中的实体作为主语,set2中的实体作为宾语,最后与r3组成新的预测三元组。其主要生成算法如算法2所示。
算法2关系生成策略
输入:tripleMap,rules,gate。
输出:out。
begin
valout=outSet
for (ruleinrules) {
valsubjectSet=tripleMap.get(rule.p1).get(subject)
valobjectSet=tripleMap.get(rule.p2).get(object)
for (sinsubject) {
for (oinobject) {
out.add(s,rule.p3,o)
}
}
}
returnout
end
实体生成算法则是根据实体所在的位置生成对应的预测三元组集合。如果一个实体既是某个三元组的宾语,也是另外一个三元组的主语,则生成算法认为该实体在这两个三元组中对应的主语和谓语可能存在某种传递规则。其具体算法如算法3所示。
算法3实体生成策略
输入:triples,rules。
输出:out。
begin
valout=outSet
for (t1intriples) {
for (t2intriples) {
if (t1.o==t2.s) {
for (ruleinrules) {
out.add(t1.s,rule.p,t2.o)
}
}
}
}
returnout
end
在模型训练中,系统会根据正实例的排名不断调整得分函数的阈值,当三元组经过计算后,其得分大于阈值时,系统判定该三元组为正实例,否则为负实例。训练完成后,推理引擎将新的预测三元组集合进行重新计算,并将得分大于阈值的三元组作为最后的推理结果。
4 实验与结果分析
4.1 实验设置
本文实验所使用的软件环境为操作系统Windows 10,采用Java 8作为编程环境,开发环境为IntelliJ IDEA。硬件环境为CPU i5 10210U@1.6 GHz, 内存大小为16 GB。
本文采用并扩展里海大学推出的LUBM(Lehigh University Benchmark)标准数据集[19]进行实验,扩展数据集已在Github开源。实验内容主要包括CSKR的推理准确性实验和推理性能对比实验。
4.2 推理实验场景
LUBM数据集本身不存在传递闭包规则,因此,为了适应本实验对传递规则以及传递闭包规则测试的情况,本实验随机对LUBM数据集部分GraduateStudent实体之间增加了schoolMate关系,并构造了传递规则Rule1和传递闭包规则Rule2,规则如表1所示。

表1 传递规则以及传递闭包规则
针对以上传递规则,本实验构造了两个查询语句Query1和Query2如表2所示。

表2 实验查询语句
表2中Query1表示查询University1的所有成员,在Rule1的条件,假设存在学生GraduateStudent1与学生GraduateStudent2之间拥有schoolMate的关系,且GraduateStudent2与University1之间拥有memberOf的关系,那么在查询结果当中应当包含可以推理出来的三元组(GraduateStudent1, memberOf, University1)。Query2表示查询GraduateStudent1的所有校友,在Rule2的条件,假设存在学生GraduateStudent1与学生GraduateStudent2之间拥有schoolMate的关系,且学生GraduateStudent2与学生GraduateStudent3之间拥有schoolMate的关系,那么在查询结果当中应当包含可以推理出来的三元组(GraduateStudent1, schoolMate, GraduateStudent3),并且该推理结果仍然可以作为推理条件去推理新的结果,具有传递闭包性。
4.3 CSKR推理命中率
为了更好地评价本文模型在LUBM数据集上的效果,本文沿用了KALE模型中同样的评价方式。对于每一个测试三元组(s,p,o),模型会打碎主语s,并将其替换为主语集合中的其他主语s′, 构成新的负实例三元组(s′,p,o),最后计算该负实例的真值。在所有主语遍历完后,模型将会得到一个根据真值降序的列表以及正实例三元组中主语s在列表中的排名。同样地,在替换完宾语之后,也可以得到一个正实例三元组中宾语o在列表中的排名。最终本文得到两个指标: (1) MRR(Mean Reciprocal Rank)是一个常用的衡量算法的指标,目前被广泛用在允许返回多个结果的问题当中。(2) HITS@N是指正例三元组排在真值降序列表中前n位置的比例。
本实验将向量空间的维度d的分别设置为{30,40,50},为了验证KALE模型对于TransE模型的改进有利于本实验的数据集,加入了TransE模型在相同条件下的对比实验。根据设置,实验后可以得到如表3所示的实验结果。
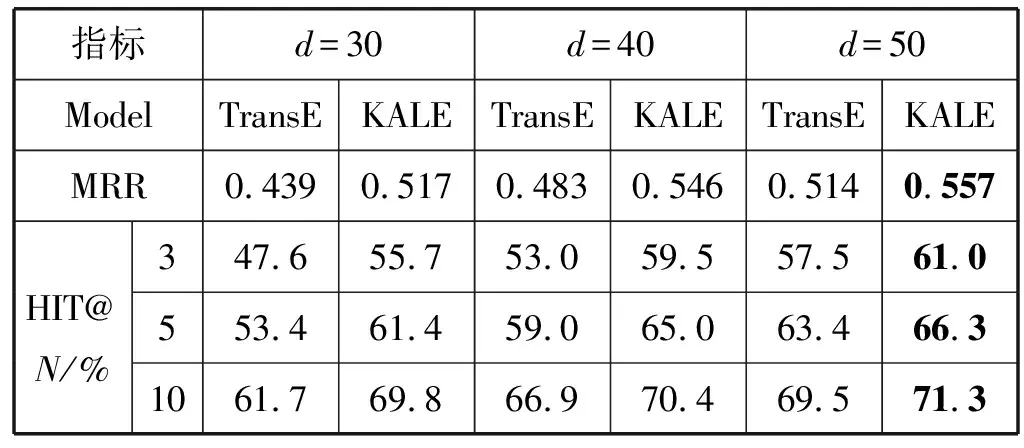
表3 KALE与TransE的推理命中率实验结果
根据实验结果可知,随着d的逐渐增加,KALE模型在LUMB数据集上,评价指标越好,并且在相同维度的条件下,KALE模型的结果均好于TransE模型。
随着向量矩阵的维度逐渐增加,虽然评价指标有所提升,但是模型计算得分函数的计算量也会依次增加,而且当维度从30增加到50的时候,HIT@10的结果提升不到3%, 计算消耗却增加了70%左右。考虑到该模型将应用于大数据低延迟的场景,因此,本实验选取d为30的KALE模型作为CSKR的推理引擎,然后与传统C-SPARQL推理系统做对比。
4.4 CSKR查询和推理时延
在传统C-SPARQL推理引擎中,目前遇到的困难是,在碰到复杂的传递闭包规则时,推理会产生大量的重复三元组,急剧增加了推理延迟,降低推理效率,所以不能很好地处理实时数据。本实验选取单位数量的三元组作为数据输入,并以处理数据的延迟作为评价指标,分别设计了普通的传递规则和复杂的传递闭包规则查询语句,并统计在复杂规则推理下,两个系统的平均查询延迟。
因为ESPER数据流处理引擎支持窗口操作,所以本实验选取的窗口大小分别为{10,20,40},单位为s, 每秒窗口三元组的数量分别为{200,1 600},单位为个,窗口的步长为1 s。根据以上的输入参数得到的实验结果如图4所示。
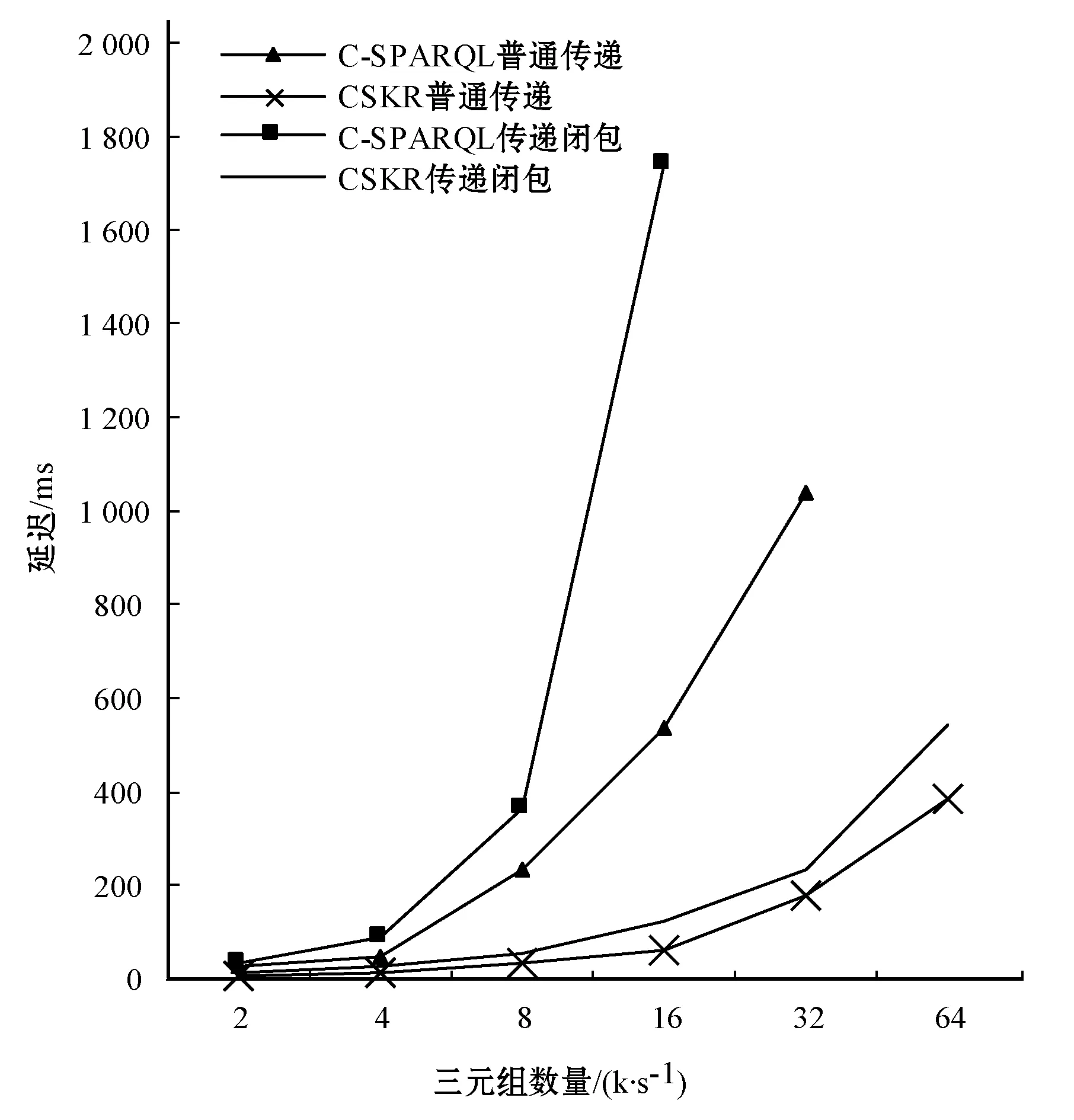
图4 LUBM数据集的实验结果
实验结果表明,在相同条件下,CSKR平台查询所消耗的延迟明显低于传统的C-SPARQL平台,在普通传递规则下最多能降低80%左右的延迟时间,而在传递闭包规则下最多能降低93%左右的延迟时间。在普通传递规则下,C-SPARQL数据量达到每秒32 000个三元组时计算量过大失去响应;在传递闭包规则下,C-SPARQL数据量达到每秒16 000个三元组时失去响应,而CSKR吞吐量均能达到每秒64 000个三元组以上,较C-SPARQL有明显优势。
5 结 语
本文在传统的推理系统C-SPARQL上融入了基于知识表示学习的KALE模型,并加入索引和三元组预测机制。实验结果表明,在普通传递规则和传递闭包规则下,CSKR较C-SPARQL性能提升十分明显,前者CSKR时延降低最多能达到80%左右,吞吐量提升2倍以上,而后者时延降低最多能达到93%左右,吞吐量提升4倍以上,并且CSKR的结合方式也为传统的实时数据流规则推理系统提供了新的研究方向。
虽然CSKR平台在生成预测三元组的时候采用了根据数据特性自适应的策略,但是两种生成算法仍然会产生大量冗余数据,造成性能浪费。因此,在未来工作中,如何进一步优化预测三元组生成算法依旧是研究重点。
