基于Rasch评分量表模型的英语学习需求量表信效度检验
2022-02-18邵健
邵健
(浙江工商职业技术学院,浙江宁波 315012)
1 问题的提出
了解学生的学习需求是开展教学必不可少的环节,自Munby在语言教学中首次引入需求分析以来[1],需求分析就在语言教学中起到了指导和参考作用[2]19。经Berwick[3]、Brindley[4]、Dudley-Evan &John[5]和Hutchison & Water[6]等人完善,语言学习需求模型日趋成熟,以Dudley-Evan & John的模型为例,涉及学习者和学习内容本体两个层面共计七个维度的需求调研和分析。就国内学界而言,学习需求理论研究不仅成果数量较少,且起步较晚[7],理论方面仅有陈冰冰[8-9]、王欢[10]、徐飞;马之成[11]等少数几篇介绍性的综述类文章。多数学者将关注点聚焦于本土学生的学习需求调研和分析,如课程思政元素需求调研[12],基于需求的大学英语教学改革[13]以及将调研成果应用在课程开发、建设和实施等实操问题上[14-16]。这些应用类成果大多未成体系,彼此之间关联度不高,缺乏主题上的延续性,无论数量还是质量,都缺乏规模效应;且研究对象多集中于本科院校学生、高校教师和高校层面,缺乏对其他水平英语学习者的调研,对于以高职学生为代表的低水平英语学习者的研究数量尤其少。
造成这种情况的原因在于学习需求理论是一个宏观的框架体系,它涉及学习者个体学习需求以及行业社会对人才的目标需求两个层面[6]59,覆盖学习者个体、学习过程和环境、学习者差距、用人单位、行业及专家等最多达八个维度的需求调研[9]。鉴于理论的复杂性,一份问卷或者一次调研很难涵盖理论中涉及的所有要点,国内英语学习需求分析所涉及的层面和内容并不统一。而由于研究者大多是高校教师,缺乏对校外用人单位或行业需求的了解,其研究大多聚焦于学校和学生个人,少有着眼于行业对专业人才英语能力及知识的需求。因此,在需求理论这一概念统摄下很难进行统一的调研。较为理想的做法是,先聚焦于英语学习需求分析的某个维度或者层面,进而设计开发出一份需求调研量表,再对其进行心理测量学意义上的信效度检验,通过开发有效的测量工具,丰富分析手段,提高解释力,改变数据分析手段单调、多以频数统计为主的情况[17]。
综上,本文以Hutchison & Water需求分析理论中的学习需求维度[6]为理论依托,开发一份着眼于低水平英语学习者,且以学习者个体层面的语言学习需求为切入点的量表,为避免真分数理论自带的不足和弊端,采用基于隐性特质理论的Rasch模型中的评分量表模型(Rasch Rating Scale Model,RRSM)对问卷进行信效度检验,以此对量表的质量进行评价。Rasch模型和真分数理论效验工具的最大区别在于对量表使用者的关注,真分数理论关注的重点在于量表,而Rasch模型则同时分析量表和量表使用者,通过量表使用者即被试在量表题项上的反应,估算出数据和模型之间的拟合程度。通过模型给出的各项拟合指标,可以获得对量表难度区分度以及被试的能力水平的直接观察。这有助于研究者从分析量表本身转变为分析量表使用者及量表和使用者之间对应关系,拓展量表信效度分析的深度和广度。该模型已被用于口语、写作等主观性测试的信效度检验[18-20],但总体而言,国内运用Rasch模型进行多层面、多维度的研究较为匮乏。
2 研究设计
2.1 对象
被试为某高职院校中外合作非英语专业学生317人,其中男生89人,女生228人。根据国际第二语言能力量表(ISLPR)对学生的语言水平进行评价,据此将学生编入三个级别语言班,其中初级班63人,中级班142人,高级班112人。
2.2 量表
以Hutchison & Water提出的学习需求[6]为基础编制量表,共计16个题项,分别涉及英语学习的目的动机、知识、技能和策略以及英语学习环境等内容。量表应答则采用莱克特五级级阶(Likert scale),0分表示非常不赞同,4分表示非常赞同。该量表经初步检验后被认为具有较好的信效度[21]。
2.3 分析软件及模型构建
采用Linacre J.M.开发的WINSTEPS3.69.13软件,以评分量表模型计算量表的各项指标,计算公式如下:Ln(Pnik/(1-Pnik)=Bn-Di-Fk,公式中,Pnik表示第n个被试在第i个题项上选择应答k的概率,Bn用以界定第n个考生的能力参数,Di用以界定题项i的难度系数,Fj则被模型设定为选项之间的阶梯阈值,被试在该值上选择两个相邻选项之一的概率相等(Bond & Fox,2015:348)。
3 结果及讨论
3.1 Wright图
Wright图是对被试及量表项目之间对应关系的最直观表现。图中最左侧自上而下的数字是Rasch模型特有的洛基单位,它是模型中各个参数的统一参考度量,从跨度看,最大为5个洛基单位,最小为-4个洛基单位。以图中的两列纵轴为界,纵轴左侧代表了317个被试的分布,符号“#”代表3个被试,符号“.”代表1个或2个被试;纵轴右侧则是量表题项。纵轴上的M,S以及T分别代表被试及题项的逻辑均值、标准差以及两个标准差的位置,由此反映被试和题项之间的对应关系。纵轴最上端的<more>和<frequ>代表了所测量项目的度量方向。就被试部分来说,越靠近纵轴上方,说明被试对题项的评分越高,即越认可题项所陈述的英语学习需求内容;而题项部分如果越靠近纵轴上方,则说明该题项的评分越高,即该题项所陈述的英语学习需求内容被认可的程度越高。从图中可以看出,被试多集中在0个洛基单位以上,说明被试对英语学习的整体需求持正面肯定态度;而题项则基本沿0个洛基单位上下均匀分布,这说明被试对这些题项的态度持正反两方面态度。从被试和题项的对应关系看,两者的均值相差约为1个洛基单位,对应情况总体较为理想;大多数被试对英语学习的需求较高,而就量表题项而言,被试对语言的实际运用(Practical App)需求最高,其次是扩展视野(Horizon)、获取信息(Information)、语言技能(Skills)及结合工作情境(Working),需求最低的则依次为语言学习环境和氛围(Atmosphere)及考级需求(CET)。这批学生的英语学习需求结果和高职英语教学培养综合应用能力的目标和以能力为本位、以就业为导向的教育理念保持一致。

图1 Wright图(Wright Map)
3.2 信度和分隔指数
Rasch模型可以计算被试和题项的分隔比率、分隔指数及信度等层面显著性指标,分隔指数被用于衡量层面个体之间的差异,表示被试和题项在潜在构念上分布的精确性[22],其取值一般要求在2以上,信度则用以测量分隔指数的可靠性,一般要求0.8以上[23]146,24,取值越大,说明分隔指数越可靠。计算结果如表1所示。表中被试的分隔指数为2.92,说明根据英语学习需求的不同,参与调查的人群大致可以分成三个群体;同理量表的分隔指数8.01表明英语学习需求可以分为八个等级,这一数字大于题项应答所采用的五点级阶,说明对于这批学生的英语需求水平区分还存在进一步细化的空间。从信度系数看,无论是被试还是量表,均高出了0.8,证明量表和被试的信度比较理想。
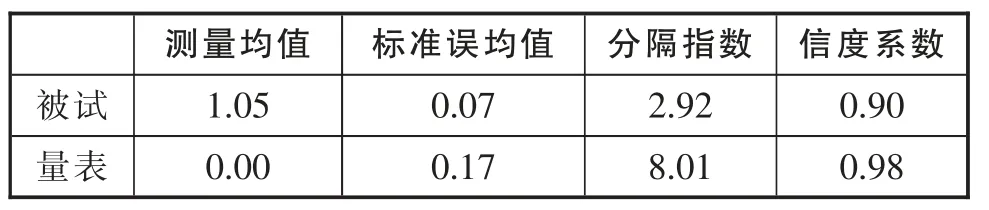
表1 分隔指数和信度
3.3 模型适配度检验
模型计算被试和题项的得分估值,用未加权均方拟合统计量(Outfit Mnsq)和加权均方拟合统计量(Infit Mnsq)体现,后者是前者的加权形式,比前者敏感但不会受极端值的影响。两个指标衡量被试真实得分和模型预测得分之间的适配程度,它们的理想取值为1,表示所估计层面具备局部独立性。但在实际测量中,理想值不容易达到,取值会围绕1波动,波动范围在0.7至1.3之间,但也可根据实际研究需要放宽到0.6到1.5之间,如果分析的参数数量较少,该值还可以放宽至0.5到3之间[18]。经过计算,英语需求量表和被试的加权均方拟合统计量分别是0.99和1.04,可以认为数据和模型的适配程度较为理想,具体见表2。
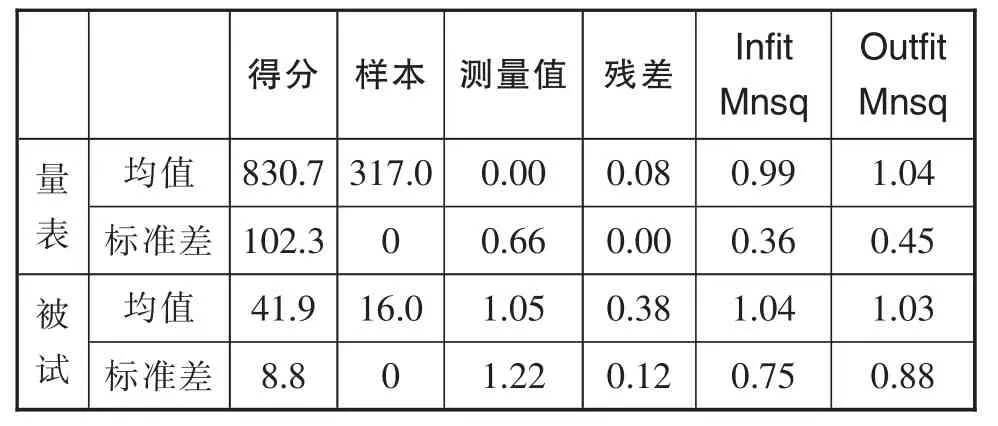
表2 模型适配度检验表
可通过量表中各题项的估值、均方拟合统计量和点相关值来判断量表题项是否具有一致性和同质性,是否体现其所要测量的潜在构念。点相关值需要取正值,如果出现负值,说明题项与量表所要测量的构念相悖,而点相关值取值越接近1,说明题项和量表其他部分的相关程度越高,整个量表的合理性也越为理想。下表是量表的适配度检验结果,其点相关系数均取值为正值,说明题项和所测量的构念之间保持一致,从其取值看,考级需求(CET)和语言学习环境和氛围(Atmosphere)在0.5分以下,说明这两题和其他题目之间的相关度相对略低。再看每个题项的均方拟合统计量,还是考级需求远超过1.5的临界值,精神支持和鼓励略高于1.5,而其他14个题项的加权均方拟合统计量均在0.6到1.5之间,说明量表中各个题项得分符合Rasch模型的预测值,没有出现很大的偏差,具体见表3。

表3 量表题项适配度检验表
3.4 量表级阶分析
量表级阶(rating scale)统计可帮助分析被试对题项应答五个级阶的运用以及级阶对被试英语学习需求的划分[25]。Linacre提出了量表运用标准[26],包括评分级阶的递增性、评分级阶之间的间隔性、评分级阶的频次分布等,具体而言,未加权均方拟合统计量要小于2;评分级阶的阶梯刻度值从低分范畴到高分范畴要依次递增,彼此之间的洛基单位差相对均匀,不存在倒序情况;每个级阶的频次分布均匀。满足了以上条件就说明被试对应答级阶的运用合理有效。表4显示,未加权均方拟合统计量取值均在2以下,1至4分段的拟合指标几乎接近理想值1。阶梯刻度值的起始值从低分段往高分段呈现递增态势。但是,在各个分值的频次分布上还是存在一定的问题,主要是0和1段占比明显低于其评分段,这就造成1和2两个评分级阶间隔过于小的情况。而剩余几个评分段之间的洛基单位间隔比较均匀,分别为2.23和1.94,符合Linacre提到的标准[26]。综合看来,被试对于各种英语学习需求的陈述认可度多在2,3,4三个级阶段,因此可以认为被试对英语学习需求程度较高。此外,量表级阶各个分数段之间的区分较为理想,特别是后几个级阶段,对被试的区分有效。
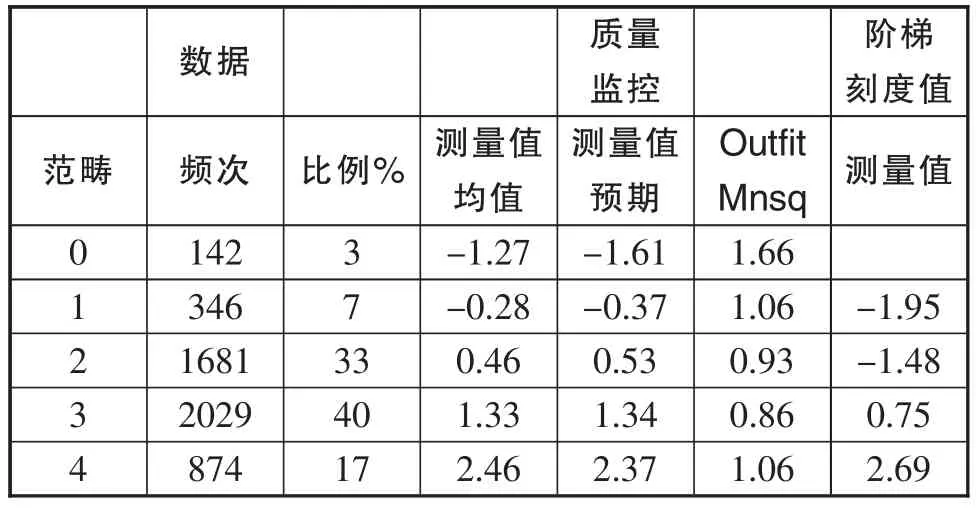
表4 级阶统计表
3.5 量表单维性检验
量表质量检验的另一重要指标即量表题项所测量的是否属于同一种潜在构念。英语学习需求量表共计包含16个题项,如归属于同一个构念,即英语学习需求,就说明量表内在质量佳,量表属于单维结构。Rasch模型应用于量表研究的优势之一就是可通过对残差的主成分分析来检验量表中是否还存在可以解释的其他维度,以此检验量表题项和量表级阶的质量,作为量表效度的佐证[23]141。Raiche则认为,只要第一个残差因子的特征根在1.4至2.1之间,即可判定量表属于单维结构[27]。Linacre对其进行了补充,提出了量表的单维判定标准为Rasch模型测量对方差的解释率在60%以上,第一个残差因子的特征根小于3且对残差方差的解释比例小于5%。但他也承认这种标准有非常多的例外情况,这是因为“单维性更多地依赖数据第二维度的大小,而非第一个维度所解释的方差大小,这是由于未被解释的方差成分可能来自于Rasch模型的随机噪声”[28]337。Bond & Fox将模型的解释比例降低到50%,同时,他们认为除了Linacre的判定标准外,还需要综合题项在残差上的因子负荷综合判断[23]141。本文参考Bond & Fox和范劲松的方法[22-23]对量表单维性进行综合的评判。对残差的因子分析发现,Rasch模型的测量结果解释了44.8%的方差,对残差的因子分析发现,第一个因子的特征值为2.8,解释了9.6%的残差方差。接下来需要结合标准化残差分布图中题项的聚合情况对量表的单维性进行综合评判。由下图可见,A,B,C,D和E这几个题项在图中分布位置较为靠近,它们分别对应量表中的英语的实际应用能力(Practical Application)、扩展视野(Horizon)、掌握英语学习方法(Methodology)、语言技能(Skills)、获取信息(Information)这五个题项。从题项的内容看,这五个题项并没有组成有意义的因子维度,综上,可以认为量表基本保持了单一维度,可以确立量表的单维假设。

图2 标准化残差分布
3.6 项目差异功能(DIF)分析
量表的质量还需要通过该量表对测量对象的公平性体现出来,可以人为地将被试分隔为不同群体,如不同性别、年龄、收入群体等,检验量表在不同群体间是否存在题项的项目功能差异,量表一旦存在群体之间的差异,就有可能对群体造成偏差,进而影响测量结果的准确性,造成量表适用性弱化。Winsteps软件会自动计算DIF差异值,并进行t检验,以此决断量表在不同群体间是否存在差异。本文以被试的语言水平分级将被试分为初级、中级和高级三个语言水平,计算量表题项在这三个群体之间的差异性。由于包含三个组别,因此,需要进行48组t检验(16*3),结果如下图所示,其中,在语言学习环境和氛围(Atmosphere)题项上,初级班和高级班之间存在显著差异(DIF Contrast=0.69,t=3.3,df=141,p=0.012);获取知识(knowledge)题项上,初级班和高级班之间存在显著差异(DIF Contrast=-0.74,t=-3.25,df=137,p=0.014)。在其他题项上,三个组别之间均不存在显著差异。以上结果说明,语言水平越低的群体,对于精神鼓励和支持的需求越高,反之则越低,位于语言水平两个极端的群体之间存着着测量偏差;而高级班群体对于获取知识的需求则显著地高于初级班群体,同理,在该题项的测量上,位于语言水平两个极端的群体之间也存在着测量偏差。

图3 三个级别DIF分析结果
3.7 层面偏差分析
Rasch模型可以分析量表和使用者之间的对应关系[29],对层面之间的交互作用进行偏差分析,以此析取随机误差和系统性误差,从而为量表的效度提供证据。本研究以Facets软件检验被试、语言分班和量表三个层面是否存在严重偏差,如果t值的绝对值取值在2以上,则被认为存在系统偏差。分析结果如表5所示,首先,被试和语言分班之间不存在严重偏差。被试和量表之间的偏差数为42个,相对于所分析的5072个交互数占比0.83%,低于5%的水平,因此,可以认为两者之间不存在严重的系统性误差。在分班级别和量表的交互层面上出现了4例偏差,相对于全部48例交互数占比超过5%,仔细检查这四例偏差,发现1例中级班和考级需求(CET)、1例高级班和考级需求(CET)、2例高级班和获取知识(knowledge)之间的交互偏差。由此可见,该量表和低水平学习者中程度相对较好的高级班之间存在一定的系统偏差,说明该量表更适合用于低水平学习者英语学习需求的调查和检验。对于水平相对较高的学生,量表中的部分题目(考级需求和获取知识)不是十分适宜。但是,这也从另一个层面说明该量表确实适用于低水平学习者。

表5 偏差分析
4 小结
本文从模型拟合指标、级阶统计(Rating scale)、单维度检验、信度、DIF检验的数据指标几个方面入手,对低水平英语学习者学习需求量表的信效度进行了检验。结果发现该量表具有较为理想的信度和效度,具体表现如下:(1)量表和被试的测量信度均在0.9及以上,信度较为理想。量表可以将被试区分为三种需求群体,这与本文最初预设的三个级别被试相符。(2)模型对比了被试应答的实际数据和模型的预测数据,以未加权均方拟合统计量和加权均方拟合统计量衡量两者间的适配程度,两个指标均在理想值1左右波动,说明量表和被试之间具有良好的适配性,数据体现了量表的潜在构念。(3)量表级阶分析结果表明,数据结果大多符合Linacre提出的判定标准[26,30],但是对0和1这两个级阶的使用频率远远低于其他三个。(4)单维性检验和DIF检验结果倾向于支持量表的单维结构,进一步支持了量表的构念效度[23]。(5)量表、被试和语言级别三个层面的偏差分析结果表明,量表适合低水平学习者的需求调查,对于该群体中语言水平相对最高的群体而言,在个别题项上会产生系统误差。
在进行量表的信效度检验时发现,个别题项需要删减或修改,这些题项包括:考级需求(CET)、语言学习环境和氛围(atmosphere)和获取知识(knowledge)。一方面,被试对以上三题的需求程度最低;另一方面,以上三个题项在多个分析项目中出现指标不理想的情况。造成以上情况的原因在于高职英语教学的实际需求。目前高校大多取消了将学位和英语等级考试挂钩的规定,语言学习的考级需求缺乏政策推动。而高职英语教学的目标被定义为“培养学生综合能力”,实际教学则注重“实用为主,够用为度”,因此,无论是教师层面还是学生层面,都弱化了系统性的语法语言知识讲解,更多地关注语言的实际使用,特别是结合实际工作场景的语言技能锻炼。
综上,该需求量表具有良好的信效度,可以用作低水平学习者英语学习需求的调查,此外,本文所用的研究方法也为量表的信效度检验提供了参考。
