基于分类算法的互联网招聘岗位申请率预测分析
2022-02-16李佳容
李佳容
(山东财经大学,山东 济南 250014)
1 引言
伴随着网络技术的发展与应用,不同于传统意义的基于互联网与大数据技术进行的招聘活动,已经渐渐覆盖了市面传统招聘方式。据艾瑞资讯统计数据显示,在中国求职者的求职和企业招聘的主要方式中,互联网招聘占比高达到85.1%[1]。尤其是后疫情时代,线上招聘相较于线下而言优势更加突出,成为众多求职者与企业的首选方式[1]。因此,如何利用招聘岗位数据通过数据挖掘技术建立高效的招聘岗位申请预测模型,从海量的招聘岗位数据中提取有用的信息,并为我们创造价值,已经成为一个关键的问题和研究热点。
2 互联网岗位招聘中存在的主要问题
2.1 招聘网站求职者与职位信息匹配度低
在招聘网站上,求职者往往查询相关职业时普遍出现的问题是求职者与职位的匹配度较低。匹配度较低与人才的供需不平衡有关,但同时也与各招聘企业以及招聘网站在人才招聘过程中的工作不到位有关,其没有对岗位及求职者资料进行准确的定位和筛查。这一问题反映出人才市场方面没有完全发挥大数据的优势,进行海量的筛选与精准的匹配。
2.2 信息处理应用难度大
当下处于后疫情时代,大量求职者依托互联网信息进行应聘和求职。在大数据背景下,作为招聘网站不得不去面对信息处理难度大这一问题。但由于其他外界因素干扰,例如人员的素质问题,使得企业招聘过程中大数据的应用效果不佳,信息处理与应用能力较差,致使招聘最终效果不佳。
随着信息技术领域的快速发展,各种数据信息量激增,大数据技术作为收集、存储、管理海量数据进而分析、预测某类人群习惯特点乃至某个行业发展趋势的重要手段,为管理决策者提供传统处理模式不能比拟的全面策略依据[2]。鉴于此,本文针对后疫情时代大数据下的人才招聘问题,结合KNN、逻辑回归、决策树、朴素贝叶斯、支持向量机、随机森林分布算法,建构招聘网站岗位申请率预测模型,寻找建立符合网站招聘的预测岗位申请率的最优模型,以期达到个性化推荐效果,为企业及用人单位实现高效网络招聘提供必要的参考,进而有利于用人企业招聘到匹配合适的人才,促进人才招聘工作的推进。
3 需求分析
3.1 问题域分析
本文以国外某招聘网站的数据为例,进行互联网招聘岗位申请率预测分析。
招聘网站上有对招聘岗位的详细描述,包括岗位职责、工作地址、任职要求等岗位信息;求职者在招聘网站上有个人信息的详细描述,包括位置、工作经验、目标职位等个人信息。这些数据将在招聘网站后台汇集,按照科学的方法对岗位和求职者的信息进行接近度计算,来反映岗位与求职者在地理位置、目标岗位与工作描述各度量之间的紧密程度。根据相关度得到匹配效果,把全部的指标数据与招聘预测关联进行数据化处理,最终以最优模型预测达到最佳效果。
3.2 基于大数据的招聘成本分析
3.2.1 招聘模式层面
通过报纸、杂志上的广告信息来宣传招聘是传统招聘的主要招聘方式。招聘网站则采用网络化的模式,借助互联网多种模式的并行应用,与传统的招聘模式相比,更加个性化与多元化。
3.2.2 投入成本层面
传统招聘会有一定的花费,互联网招聘在花费及人力资源方面来讲具有一定的优势,只需要网站上发布信息,用很少的人力资源投入,而传统招聘需要大量的人力投入。
3.2.3 时间成本层面
招聘需要收集大量的简历,投入大量的人力进行时间成本的运营。从时间成本的维度来讲,传统的招聘使用时间更长,人员的工时更多,而招聘网站采用互联网大大节约了时间,对数据的处理筛选收集都十分便利,节约时间。
3.3 基于大数据的招聘基本特征分析
3.3.1 网络化
网络化是基于大数据的人才招聘的最基本特征之一,在招聘过程当中依托网络进行大数据的分析,通过信息的收集、信息的整理、信息处理,以及信息的筛选录用,现在的活动都是通过网络来完成的,包括网络化的面试都可以通过网上视频实现。无论从求职者还是招聘者角度来看,都节约了大量时间且充分发挥了网络的优势,形成了大数据人才招聘的基本特征。
3.3.2 便捷化
与传统招聘相比,其招聘周期更短,更加便捷有效,简历的投放甚至到面试均可以通过网络来实现,为大数据背景下的人才招聘提供了巨大的优势。
3.3.3 信息数据化
招聘过程中可以通过海选与筛选,把所有的信息进行数据化的处理,进而完成数据的手机筛选以及匹配等工作,信息处理量较大,处理方便简单,为人才招聘提供了良好的方式与手段。
4 基于分类算法的申请率预测试验
4.1 试验设置
运用Python程序设计语言,在Python3.8的环境下,使用Spyder开发软件。为保证有足够的数据对模型进行训练,从而测试算法的分类效果及分类性能,使用“Apply_Rate_2019.csv”数据集。该数据集是自阿里云天池上下载的数据,该数据集包含1200890条数据,10个字段。
这10个字段的含义分别为:
(1)标题接近度:求职者查询与招聘网站上职位名称的接近度。
(2)描述接近度:求职者查询与工作描述的接近度。
(3)主查询接近度:求职者查询与职位名称、工作描述两者的接近度。
(4)查询得分:求职者查询热门与招聘网站提供的岗位列表的匹配度。
(5)查询标题得分:求职者查询热门与招聘网站提供的职位名称的匹配度。
(6)城市匹配度:招聘网站提供的岗位与用户所在位置匹配度。
(7)工作经验匹配度:招聘网站提供的岗位所需的工作经验与用户的匹配度。
(8)是否申请该岗位:求职者是否点击申请该岗位,该字段含“0”和“1”两类值。
(9)搜索日期。
(10)类ID:选择点击的职务类ID。
4.2 试验流程
(1)对获得的招聘网站数据进行清洗与下采样处理,得到有效的相关度数据;
(2)切分数据集将其分为训练集和测试集,建模并调整超参数使其尽可能达到最优状态;
(3)使用评价指标对模型进行朴素贝叶斯等分类模型进行评估;
(4)对建立模型进行优化,进一步调整超参数使其能够达到最好的预测效果;
(5)部署该模型以此为依据进行预测。
4.3 评价指标
(1)准确率(Accuracy):预测正确的样本占所有样本的比例,其计算公式为:

(2)精确率(Precision):被模型预测为正类的正样本占被模型预测为正类的比例,其计算公式为:Precision = TP/(TP+FP)
(3)召回率(Recall):被模型预测为正类的正样本占所有正样本的比例,其计算公式为:Recall = TP/(TP+FN)
(4)F1score:是精确率和召回率的加权调和平均,综合两者的结果,当其结果较高时,说明预测结果较好,其计算公式为:F1=(2*P*R)/(P+R)
上述公式中,TP表示被模型预测为正类的正样本;TN表示被模型预测为负类的负样本;FP表示被模型预测为正类的负样本;FN表示被模型预测为负类的正样本。
4.4 试验结果对比与分析
本文采用相同的数据集,运用K近邻、逻辑回归、决策树、朴素贝叶斯、支持向量机、随机森林分布等六种算法进行对比分析。
由表1中六类分类算法性能表现可以看出,决策树、K近邻和随机森林模型召回率Recall较低;支持向量机模型各方面指标表现都不好;逻辑回归和朴素贝叶斯的精确率和召回率所差无几,通过观察F1score值发现朴素贝叶斯模型的值较高,证明该模型性能表现较好。
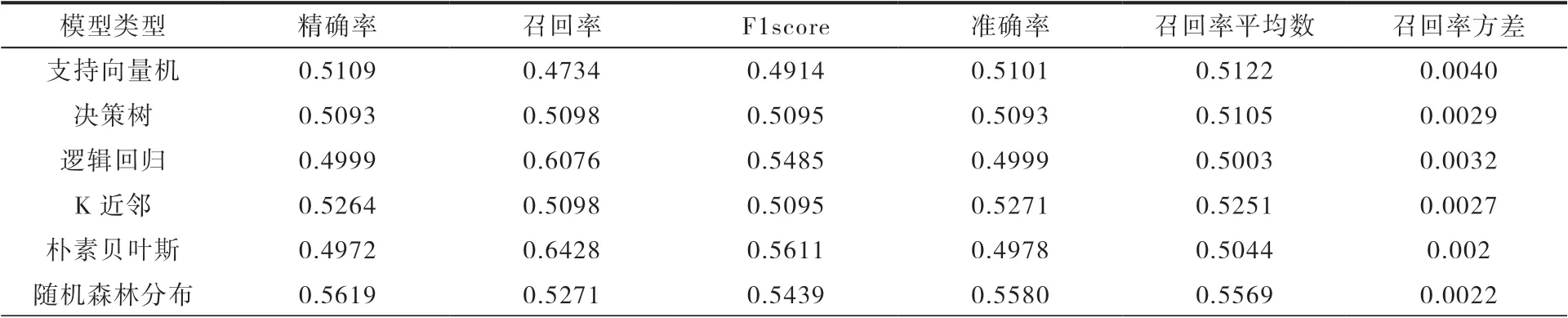
表1 模型评估结果
朴素贝叶斯分类器属于概率分类器,通过此分类器对互联网招聘岗位申请率数据集的分类,可以看出,朴素贝叶斯算法有稳定的分类效率,能处理多分类任务,适合增量式训练[3],具有较强的可伸缩性、较高的准确率、较快的计算速度,且对结果的解释更容易理解[4],因此朴素贝叶斯分类模型具有较大优势。
5 结论
为全面提升招聘的工作效率并实现高效寻才,企业招聘将深入数字化发展,全面提升数字化水平,最终实现智能化。特别是随着大数据挖掘技术的发展,分类预测问题备受人们的关注。本文面向互联网招聘岗位申请率的相关度数据,在对数据集进行预处理和下采样的基础上,采用朴素贝叶斯等六种分类模型,通过对模型的F1score等指标进行模型分析与评估,最终确定朴素贝叶斯模型预测效果最好,具有更大的优势和较强的可扩展性,有利于实现招聘岗位的个性化推荐。稳定性好、效率性高是朴素贝叶斯算法的核心优势[4]。但在现实生活中,相互独立的数据不易找到,因此对于朴素贝叶斯算法来说,要达到极高的准确率是很难实现的。在接下来的研究中,可以对该分类算法进行有针对性的优化改进,引入位置、词性因子等因素对特征权重的计算进行优化,提高分类的准确性。
