数字人文视域下口述记忆资源知识图谱构建研究
2022-02-11王阮邓君
王阮 邓君
摘 要:[目的/意义]传统资源开发方式已无法适应数字人文时代的发展需要。伴随数字与人文研究的碰撞不断深入,以知识图谱为代表的数字人文技术方法能为口述记忆资源深度挖掘提供新视角。[方法/过程]构建口述记忆资源知识图谱模型,以国家图书馆中国记忆项目东北抗日联军专题老战士口述记忆资源为数据源进行实例可视化展示与多维语义查询。[结果/结论]本文验证了知识图谱技术方法在知识挖掘、知识发现与知识服务等方面的适用性与实用性,有效创新了数字人文环境下口述记忆资源开发路径。
关键词:数字人文;口述记忆资源;知识图谱
DOI:10.3969/j.issn.1008-0821.2022.02.003
〔中图分类号〕G250 〔文献标识码〕A 〔文章编号〕1008-0821(2022)02-0022-12
Research on the Construction of Knowledge Graph of Oral Memory
Resources from the Perspective of Digital Humanities
Wang Ruan Deng Jun*
(School of Business and Management,Jilin University,Changchun 130022,China)
Abstract:[Purpose/Significance]The traditional development mode of resources can not meet the development needs of the digital humanistic era.With the deepening of the collision between digital and humanistic research,the digital humanistic technology method represented by knowledge graph can provide a new perspective for the in-depth mining of oral memory resources.[Method/Process]The knowledge graph model of oral memory resources was constructed,and oral memory resources of special veterans of the Northeast Anti Japanese coalition army of China Memory Project of the national library were used as the data source for example visual display and multi-dimensional semantic query.[Result/Conclusion]The study verifies the applicability and practicability of knowledge graph technology in resources knowledge mining,knowledge discovery and knowledge service,and effectively innovates the development path of oral memory resources in the digital humanistic environment.
Key words:digital humanities;oral memory resources;knowledge graph
近年來,数字技术的迅速崛起、升温,极大改变了人文学科的研究范式、教学手段与成果呈现方式。云计算、大数据、物联网、移动互联网、区块链等技术的发展和应用推动了“数智时代”的到来,助推了人文领域的数字人文浪潮,也成为图情领域发展的新生长点[1]。作为实践性和操作性很强的研究领域,口述记忆资源受数字时代形态变化的影响,呈现出不断修正、更新、螺旋式推进的趋势与规律[2]。
早在2002年,文化部、财政部便依托全国各级公共图书馆、文化馆,多形式、多渠道开展数字文化资源服务,提出要加强信息基础建设,以群众基本文化需求为导向,创新信息技术服务手段[3]。2019年,《公共数字文化工程融合创新发展实施方案》的发布,进一步推动了公共数字文化融合发展,以把握导向、统筹规划、创新驱动、开放共享为发展原则,实现服务业态创新、服务效能提升,建立能够实现共建共享、管理规范、服务高效的服务体系[4]。我国作为中华文化的守护者和传承者,拥有相当丰富且数量庞大的人文资源亟待挖掘,如何检索、利用浩瀚繁杂的口述记忆资源,将其蕴含的丰富内部事实、数据和知识展现出来,实现口述记忆资源深度开发与知识发现具有迫切性和必要性。
基于此,本文以口述记忆资源为研究对象,以知识图谱可视化技术重现珍贵历史记忆,展示从理念基础到技术方法再到实践操作的口述记忆资源知识图谱架构过程,引入东北抗日联军专题老战士口述记忆资源进行图谱可视化展示,以深化助益研究的深度与广度,试图在“数字”与“人文”的碰撞中创启新篇章。
1 文献综述
1.1 口述记忆资源
《荷马史诗》《马可波罗游记》通过口头传说与叙述编纂记录了西方国家的口述研究本源。我国口述传统可追溯到3 000多年前,以《礼记》中“动则左史书之,言则右史书之”记载周朝史官记录人们的口述言谈为起点[5]。口述记忆资源的形成是对个人进行有计划采访的结果,其成果通常为采访或采访的逐字记录[6]。从文化意义上来说,口述资源是对被遗忘内容的重新提及,是对传统的重构和被压抑内容的回归,具有文化记忆资源的重要特征[7],也因此成为当代文化工作开展的重要组成部分。
1948年,哥伦比亚大学口述研究室[8]的建立旨在收集和整理个人传记回忆录和群体访谈录等重要口述资料。1979年,新加坡口述小组逐步规范化口述资料收集与整理工作,着力保存新加坡早期历史集体回忆[9]。随后,国内口述记忆资源建设实践项目掀起研究热潮,聚焦资源建设体系[10-12]、国内外研究进展[13-14]。数字时代背景下,数字技术极大改变了口述记忆资源的信息获取方式,使其具有资源异构性、资源交互性、开放式建构的不同特征[15],因此出现了以元数据方案制定[16]、口述资源管理系统开发[17]等为代表的数字资源实践成果。
1.2 知识图谱
在人工智能视角下,知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法[18]。目前,知识图谱可划分为科学知识图谱和领域知识图谱。科学知识图谱是一种信息计量的方法,是基于Citespace、Histcite等工具技术实现的对于科学知识结构、关系及演化过程的一种可视化呈现。在图情领域,科学知识图谱多应用于文献分析和热点梳理,如图书馆微信服务研究现状分析[19],创新政策领域发展研究[20]等;而领域知识图谱则是结构化的语义知识库,用于描述概念及其相互关系,构成网状的知识结构[21]。如探索构建中国历代存世典籍知识图谱,为研究者挖掘海量古籍书目数据背后隐藏的知识提供一站式平台[22];分析网络舆情管理活动的知识需求,阐述网络舆情知识图谱的构建方法[23];立足大数据环境唐诗知识服务需求,以大规模唐诗数据为基础构建唐诗知识图谱并提供智能知识服务[24]。
综上所述,数字人文正以宽视野、广维度、集成化方式重塑和改造人文知识形态,数据研究范式的创新思维也正在促进数字技术与人文研究深度融合。以知识图谱为代表的技术方法实现了传统“叙事·记忆”范式到数字“数据·驱动”范式转变,有效解决了资源零散碎片化问题,拓宽了学科边界,助力多学科交叉融合,有利于完善资源体系结构。作为信息资源建设的有机组成部分,数字人文环境下,于口述记忆资源而言,无论是对传统资源的印证补充,亦或是抢救和传承社会记忆,从收集、加工、存储乃至利用,创新资源开发路径,打造全新数智数据生态已成大势所趋。以数字技术赋能口述记忆资源开发,必将加速推动口述记忆资源由简约叙事型、记录型研究向深度广度数字化、智慧化纵深发展迁移。
2 需求分析
2.1 数字人文时代必然要求
数字人文的核心是以数字化的研究对象为基础,保障和创新人文研究的内容、方法和模式[25],为学者提供规律性、趋势性、差异化、宏观性研究的知识和线索,通过设计、计算、分析以及可视化表达的方式扩展学术疆域和潜力,推动人文领域知识研究[26]。近年来,数字技术的“加持”使数字人文超越了早期的方法论和工具论的认识,更加强调跨学科性、动态性、混杂性与兼容性,人文知识脉络和内容得以重构,数智时代知识系统与认知方式的创新构建成为可能,这一理念与研究范式的变革为资源开发理论与实践带来了新契机。数字人文概念的提出和数字化馆际的逐步建构,以及由此带来的变革之路,创新之维,使得传统资源开发方式已不再适应现阶段开放、融合、发展的信息化社会。数字人文视域下,口述记忆资源开发不仅需要内容层面的知识提取,实现不同资源互联,更需要以资源重组调整为手段,以数字技术驱动为工具,深入发掘隐性知识,助力资源开发更为智慧、高效,为人文研究者提供规律性、趋势性、全局性的知识脉络。
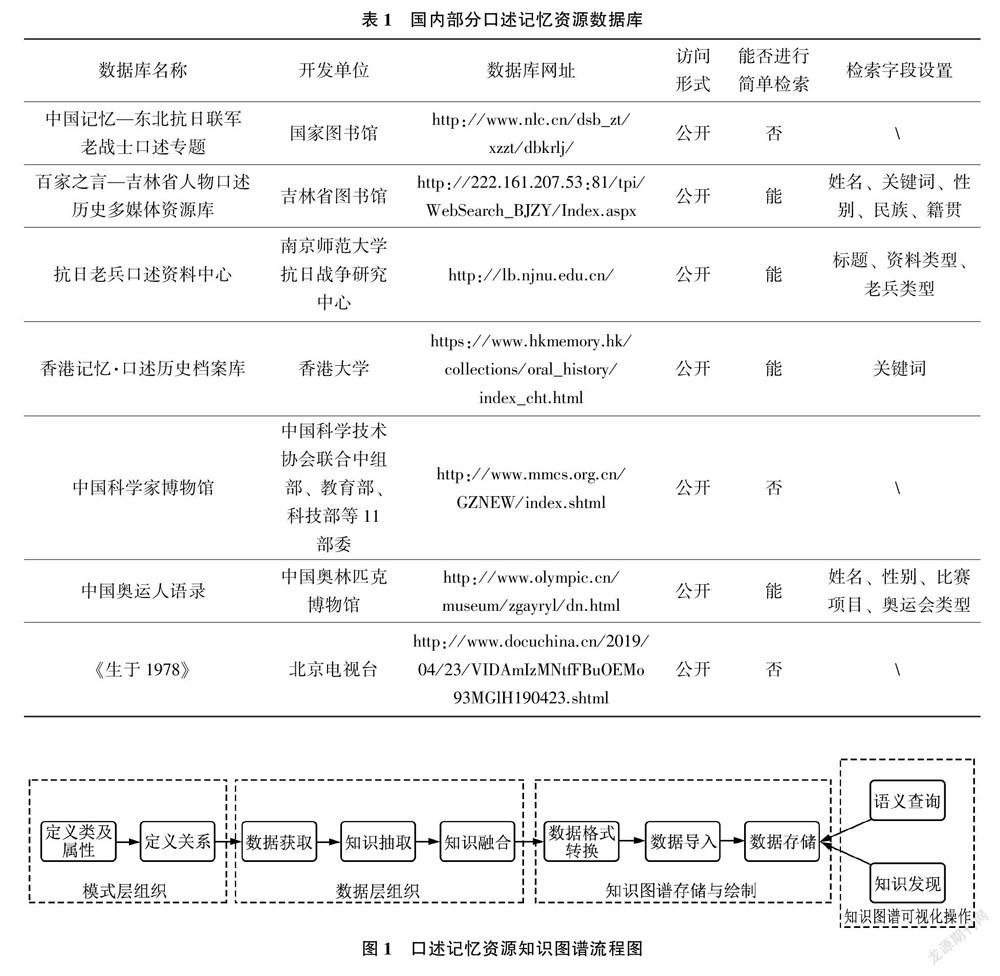
2.2 口述记忆资源开发需求
口述记忆资源作为社会记忆之本源,其打破了传统历史记录的构建方式,在内容上具有平民性与生动性,形式上更具多样性和异构性,是完善社会记忆、集体记忆的宝贵原始记录,对于史实溯源、风貌再现、文化承载、情感传递等方面具有重要作用。随着记忆工程的不断推进以及受国际研究和实践发展的影响,口述记忆资源呈“指数级”增长,文化传承与记忆功能备受关注,我国形成了部分以历史事件、人物事迹、馆藏特色等为主题的口述记忆资源数据库,如表1所示。这些数据库的存在是口述记忆资源开发工作的丰硕成果,但仅以公开访问和简单检索为利用途径的手段已难以适应并应对数字人文时代带来的变革。资源采集进程缓慢、完整系统的资源整理知识框架缺失、存储丰富度与资源描述细粒度匮乏等开发弊端,使口述记忆资源开发利用愈加受阻。一方面,以馆藏或数据库为存储介质的口述记忆资源难以快速挖掘资源潜在信息,用户需手动查阅或频繁点击搜索才能提取出与研究问题相关的信息;另一方面,用户难以实现资源重组与互联,易造成完整知识链缺失,导致资源整合困难。因此,口述记忆资源亟需一种能够实现资源深度描述和知识语义链接的新方式。
数字人文背景下,人文研究者应冲破传统资源开发理念的束缚,积极主动参与记忆构建[27],注入数字技术方法,维护、传承并拓展口述记忆资源服务空间,促进资源整合、优化并开拓领域发展新局面。基于此,笔者提出口述记忆资源知识图谱框架构想并辅以实例填充,旨在创新口述记忆资源开发路径,为实现资源深度关联、聚合与发现提供新思路。
3 数字人文视域下口述记憶资源知识图谱构建
口述记忆资源知识图谱构建是口述记忆资源开发的新尝试,如图1所示,涵盖模式层和数据层。其中,模式层定义口述记忆资源的类、属性、关系要素;数据层则引入实验数据源,将数据格式转换→数据导入→数据存储过程予以揭示。最终通过可视化操作完成对口述记忆资源知识图谱的实例检验,表明该流程具有较好的可操作性。
3.1 模式层组织
模式层是类及其属性和各种关系的组织模型,包含对口述记忆资源相关概念及层级关系的形式化、立体化表达。
为确保口述记忆资源模式层组织的完整性与系统性,本文从口述记忆资源外部特征、内容特征、形式特征入手,梳理总结相关概念及层次关系。外部特征即描述口述记忆资源外在信息,如项目版权所有者、项目收集时间等。对外部特征的抽取整合有助于了解口述记忆资源形成过程,对深入探究口述记忆资源价值和内容具有重要启示意义;内容特征旨在从人物、事件、地点等维度抽取相关信息,如口述者提及的战争及其发生时间、地点等。对内容信息的挖掘是实现后续知识关联的重要前提;形式特征囊括采访时长、格式、文件类型、资源大小等附加信息,对形式特征的分析概括有助于了解口述记忆资源存在形式、存储方式。
1)定义类及属性
类是具有共同特征或属性的实体集合的抽象表达。“人物”类包含姓名、语言、国籍、性别、政治面貌等多个属性;“地点”类主要描述资源内容或资源本身地域空间;“时间”类则存储口述记忆资源涉及的所有时间点或时间段;“项目”类指口述项目,包含项目名称、采访时长、资源文件大小、资源格式、资源类型、来源等属性;“事件”类主要涵盖口述访谈中口述者提及的或与之相关的其他人物涉及的事件,且存在事件名称这一属性信息;“版权”类是项目权限信息的抽象集合,包括版权所有者属性;“身份”类则包含口述过程涉及的所有人物身份信息。
2)定义关系
常见的关系类型可分为分类关系和非分类关系。分类关系即上下位关系(is_a),非分类关系则反映了语义关系,包含整体与部分关系(is_part_of)、同义关系(same_to)、属性关系(is_attribute_of)等。本文多为自定义关系,如“人物”类与“项目”类之间的参与关系(participate_in),连接“项目”类和“事件”类的包含关系(involve)等,如图2所示。
3.2 数据层组织
数据层组织旨在描述数据源与已定义实体及其属性、关系,同时根据研究需要及时补充调整,全方位展现口述记忆资源。
1)数据获取
本文择取国家图书馆中国记忆项目东北抗日联军专题老战士口述史[28]板块,采用网络爬虫技术从目标网站爬取实验数据源,包含35个东北抗联老战士口述资料、珍贵文字资料10 186条,希冀藉由东北抗联老战士口述资料回溯并再现抗战史实。
2)知识抽取
知识抽取包含实体抽取、属性抽取、关系抽取3个部分,其中实体抽取是属性、关系抽取的前提,旨在提取口述记忆资源关联数据,实现模式层组织所定义的口述记忆资源类及属性和关系映射。
实体抽取的关键在于提取与口述记忆资源关联的数据实例。考虑到本文数据量少且结构化较强,因此,实体提取采用自动分词与人工匹配相结合的方法。首先通过ROST内容挖掘工具对数据源进行分词处理,分词结果示例如图3所示。随后,在此基础上,将符合模式层定义层级划入相应实体类别。若数据源与模式层定义的概念层级存在冲突、缺失的部分,可进一步补充和完善模式层。本研究实体抽取过程中,包含人物、地点、时间、项目、事件、版权、身份7类实体。
属性是对实体做进一步语义描述的重要信息,可以实现对实体的完整勾画,其构成要素一般包含属性名和属性值两个部分。属性抽取即参照数据模型构建的实体类型及其属性,从目标网站中提取对应属性和属性值的数据操作。依据数据源,属性抽取包含16项,对应7类实体中的5类,如表2所示。
关系是知识图谱的重要组成部分,是实体与实体相互关联的通道,也是形成网状知识结构的前提和必备要素。早期的关系抽取研究主要是通过人工构造语法和语义规则采用模式匹配的方法进行识别。发展至今,出现了大量基于特征向量或核函数的监督学习方法[29]。由于本文涉及实体关系数量较少,且关系类型已在图2呈现,即按照模型定义的关系类型及关联实体进行信息提取,此处不再赘述。
3)知识融合
经过知识抽取形成的实体及其属性、关系集可能包含大量冗余和错误信息,知识融合主要解决实体和属性的“校对”问题。一方面,需要对分词产生的错误信息进行矫正修改,例如,通过工具获得“东北”“小”“部队活动”错误分词结果时,需要将其整合为“东北小部队活动”这一事件实体;另一方面,同一属性和实体往往会有不同称呼,因此需要在知识抽取后进行属性或实体的映射与链接,例如本文中“东北抗联”“抗联”“抗日联军”等均可视为同一实体。
3.3 知识图谱绘制及存储
抽取、融合完毕的数据需要存储才能实现知识图谱可视化及知识查询等操作,通常包括关系型数据库和非关系型数据库两种存储方式。为方便后续的关联挖掘,本文使用最为广泛、效率更高的非关系型数据库(Neo4j)作为知识图谱可视化工具,同时采用LOAD CSV命令进行数据源批量导入,囊括实体245个,实体关联关系556条。最终,东北抗日联军老战士专题口述记忆资源知识图谱如图4所示。
该图谱以网状结构展示了项目全貌,囊括了与项目本身关联的事件、时间、地点、人物等要素。通过整合35位抗战老兵或其亲属提供的口述资料,揭示了人物及人物身份、出生时间、籍贯、参与项目概况,事件及事件发生地点、发生时间、所属项目等内容。
图4中的圆圈表示实体,以颜色区分实体类型,其中,红色标签代表整个东北抗日联军老战士口述史专题项目,蓝色标签标识时间与地点实体,浅绿色标签显示人物身份,深绿色标签则展示单个老戰士口述信息。实体与实体通过“边”建立联系,例如,深绿色标签与粉色标签相连显示的即为项目与事件的“包含”关系,与紫色标签的链接则表示相关人物项目“参与”情况。
4 口述记忆资源知识图谱可视化
作为图形优化的查询语言,Cypher可实现隐性知识挖掘,相较于结构化查询语言(如SQL)更为快捷方便,为进一步探索口述记忆资源单维、二维、多维知识发现分析提供可能途径。
4.1 宏观层面的项目单一维度知识发现
调取项目图谱如图5所示,该项目采集时间为2012年,采集地点以北京市、辽宁省、黑龙江省、湖北省、新疆维吾尔族自治区为主,包含陆保平、吴玉清、王铁环等35名东北抗联老兵口述者。
进一步点击单个实体,还能够得到更多与该实体关联的数据属性,例如“潘兆会口述史”,如图6所示,由此发现其访谈总时长为“11分38秒”,设备录制时间为“2012年5月27日”,资源文件大小为“73.62MB”,资源格式及类型分别为“wmv”和“vedio”。故而,实体属性和关系的细粒度描绘使得对单个实体维度的认知更加全面。
4.2 简单关系的人物—身份关系二维知识发现
图7展示了通过身份相连的人物潜在关系图谱,其中粉色代表人物实体,浅绿色则为人物身份信息,人物实体与身份实体的链接描述了享有相同身份的人物信息。
不难发现,该项目涉及的军队编制信息包括第一军、第二军、第三军、第五军、第六军、教导旅、东北游击区等。例如,王明、吴玉清、胡真一、冯万祥等人为第五军战士,孟宪德、陆保平、张正恩、江子华等属于教导旅,而李在德、于桂珍、周淑玲等都曾所属于第三军。进一步查询李在德实体,可以获得详细信息(性别“男”,语言“中文”,国籍“中国”,政治面貌“中国共产党党员”)。
值得关注的是,在该实例中还存在同一人物享有多个身份的情况。例如,柴世荣战士曾服役于第五军以及教导旅,冯仲云战士在第三军、第六军均有任职经历等,由此说明人物在军队中存在潜在调动关系,通过简单知识推理可以为后续厘清人物任职经历提供研究方向和思路指导。
4.3 复杂关系的多维知识发现
4.3.1 基于事件—项目—时空关系的知识发现
提取与事件关联的知识图谱如图8所示,该图谱展示了不同项目包含的历史事件及其发生时间与地点信息。绿色表示项目实体,粉色代表事件实体,蓝色则表示事件地理位置及事件发生时间。
总体而言,本文数据源以抗日战争和苏联整训为事件主体,事件发生地聚焦东北地区,跨越包含华北地区以及重庆、苏联、朝鲜等在内的广大区域,通过口述方式记述反映了东北抗日联军最为漫长、最为悲壮的14年抗日斗争,回溯了重要珍贵的红色记忆。其中,涉及抗日战争的口述项目占比65%,涉及苏联整训的口述项目占比35%。此外,关联事件还涉及九一八事变、抗美援朝、平津战役、辽沈战役、重庆谈判等,时间跨度为1931—1966年。通过对历史事件的归类聚合,如图9所示,有利于进一步发掘更多关联历史事件,充实该时期历史活动,并在时间线的梳理下更好地理顺事件发生节点。
4.3.2 基于身份—人物—项目—地点关系的知识发现
通过Cypher语句“MATCH(p:Person)-[r]-(pr:Project)WITH p,r,pr MATCH(p:Person)-[r2]-(pl:Place),(p:Person)-[r3]->(i:Identity)return p,r,pr,r2,pl,r3,i LIMIT 50”调取身份—人物—项目—地点关系信息如图10所示,该图谱涉及不同项目人物籍贯信息,呈现出多维复杂关系。
聚焦于人物与地点间的籍贯关系可以发现,该项目涉及的人物籍贯集中于黑龙江省、吉林省、辽宁省,体现了东北抗日联军老战士活动区域的地理位置特色。与此同时,在身份信息的辅助下进一步发现,同一项目所包含的人物及其亲属还存在籍贯不同的情况。例如在柴国华口述史中,教导旅战士柴国华籍贯为俄罗斯,而其亲属柴世荣籍贯为山东省。在冯忆罗口述史中,冯忆罗及其亲属冯仲云籍贯分别为黑龙江省和江苏省。基于此,可以根据冯忆罗籍贯为黑龙江省且加入新四军等信息,推理冯仲云可能存在从江苏省迁移至黑龙江省参与东北抗日战争后定居黑龙江省的迁移轨迹。当然,这一轨迹仅为推断,尚不构成事实,可以通过进一步查阅相关史实资料确定其准确的时空迁移轨迹。故而,从知识图谱呈现出来的项目—人物—地点潜在地理位置信息可以为后续深入研究提供一定思路导引,这也是知识图谱相较于其他知识展示和表达方式的优势所在。
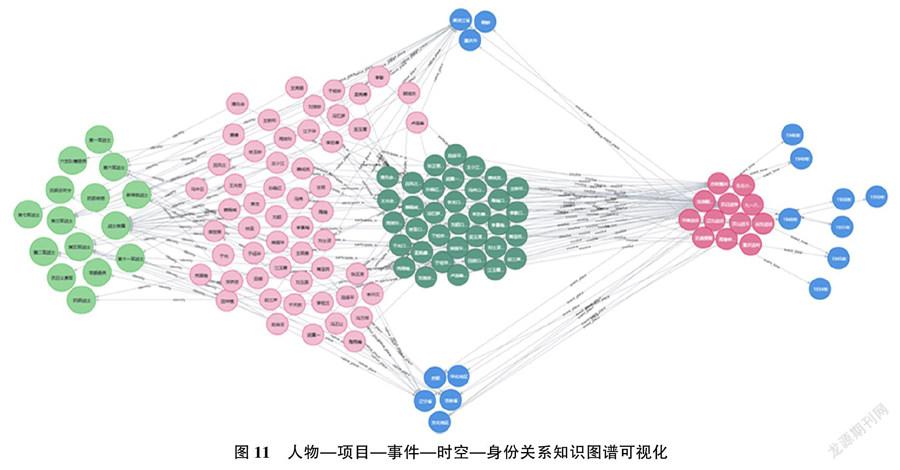
4.3.3 基于人物—项目—事件—时空—身份关系的知识发现
调用以人物实体为中心的项目—事件—时空—身份关系知识图谱,如图11所示。深绿色代表项目,深红色为历史事件,粉色代表人物,浅绿色表示人物身份信息,蓝色则为时间、地点信息。
在图11中,人物通过参与关系与项目实体产生联系,单个项目通过包含关系与事件实体及其发生时间、发生地点相连,因此,人物可以通过项目这一中间实体实现与历史事件及其发生时间、地点的关联呈现,同时在身份信息的辅助下厘清项目涉及的关联人物参与历史事件的时空轨迹。
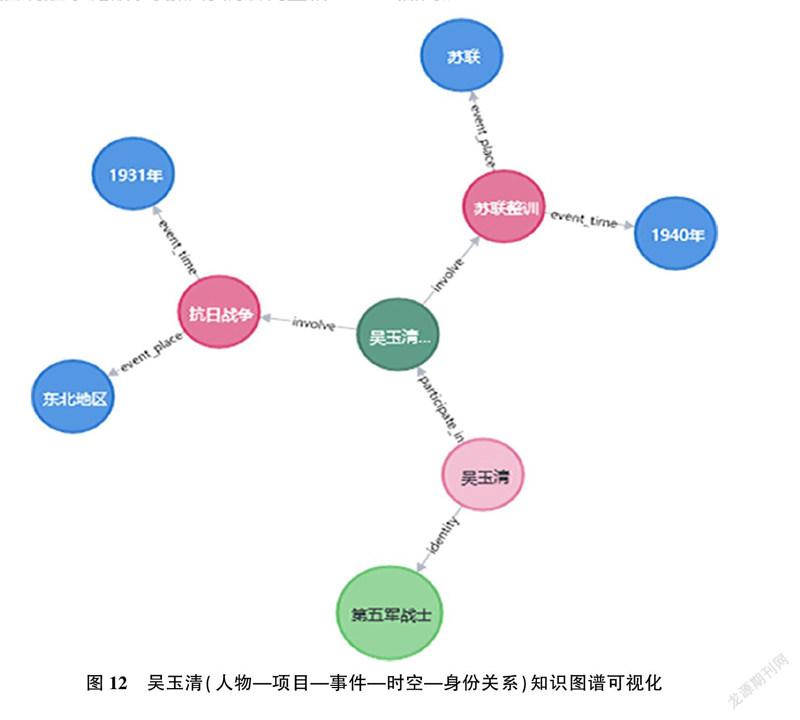
由于图谱连线过于庞杂,此部分仅以吴玉清口述史项目为例进行展示。如图12所示,吴玉清作为第五军战士曾于1931年在东北地区参与过抗日战争,并于1940年赴苏联参加苏联整训活动。基于此,通过多维图谱对应关系可以分析出相关人物在一定时期内的任职经历,对人物事迹、身份信息、时空轨迹以及历史事件深入研究具有重要现实意义。
5 结 语
本文依托中国记忆项目东北抗日联军老战士口述史专题数据源构建口述记忆资源知识图谱,验证了以知识图谱为代表的数字人文技术方法在口述记忆资源研究领域的可操作性。一方面,知识图谱作为一种新兴可视化工具,以灵活的网系结构实现了繁杂的口述记忆资源知识聚合,能辅助用户快速捕获领域知识,提取相关知识,方便用户从宏观层面进行知识概览,有助于人文学者进行知识分析与服务;另一方面,用户可借助知识图谱Cypher语句查询功能提取与之关联的项目、人物、事件、时间、地点等信息及其相互关系,推理发现潜藏信息,从多维语义关联视角聚类并揭示口述记忆资源内部事实。
综上所述,数字技术为人文研究指明了新的发展方向,特别是以知识图谱为代表的数字人文技术方法为口述记忆资源开发提供了新视角、新路径、新方法,切实实现了技术与人文并举。未来,“数字”与“人文”的碰撞必将为人文研究注入源源不断的活力。
参考文献
[1]夏翠娟,娄秀明,潘威,等.数智时代的知识组织方法在历史地理信息化中的应用初探——兼论图情领域与人文研究的跨学科融合范式[J].图书情报知识,2021,38(3):37-49.
[2]王玉龍.不同的记录不同的过去:口述历史档案的兴起及其理论影响[J].档案学研究,2016,(5):40-44.
[3]倪劼.化“繁”为“简”:公共数字文化资源传递方式创新[J].图书馆,2021,(5):44-50.
[4]中华人民共和国文化和旅游部.文化和旅游部办公厅关于印发《公共数字文化工程融合创新发展实施方案》的通知[EB/OL].http://zwgk.mct.gov.cn/auto255/201904/t20190422_843023.html,2021-06-10.
[5]李星玥.以《长征》为例分析口述历史档案重构战争记忆[J].档案与建设,2017,(10):38-41.
[6]庞喜哲.我国口述历史档案平台建设研究[D].武汉:武汉大学,2017.
[7]冯惠玲.数字记忆:文化记忆的数字宫殿[J].中国图书馆学报,2020,46(3):4-16.
[8]王鹏,范智新.美国口述历史工作的特点及启示[J].中国档案,2019,(6):76-77.
[9]张惠萍.新加坡口述档案及对中国的启示[J].兰台世界,2010,(15):9-10.
[10]严春子.口述资源的建设利用探析——以吉林省图书馆口述资源建设实践为例[J].图书馆学研究,2018,(8):33-35.
[11]全根先.口述史、影像史与中国记忆资源建设[J].国家图书馆学刊,2015,24(1):10-16.
[12]宋本蓉,田苗.中国记忆学者口述资源库建设的实践——以冯其庸先生为个案[J].图书馆,2015,(12):23-26,50.
[13]高冕.中美英国家图书馆记忆工程中的口述历史资源建设比较研究[J].图书馆学研究,2020,(23):14-22.
[14]李竟彤.中美高校图书馆口述资源建设比较分析[J].图书馆学研究,2019,(23):9-16.
[15]冯云.口述历史资源数字化管理与利用探讨[J].图书馆工作与研究,2021,(9):62-68,83.
[16]聂勇浩,李若欣.基于都柏林核心元素集的口述档案元数据方案[J].档案学研究,2020,(3):129-136.
[17]可新方,王雨辰.美国肯塔基大学口述历史档案管理系统的开发与应用[J].中国档案,2020,(3):82-83.
[18]Amit S.Introducing the Knowledge Graph:Things,Not Strings[EB/OL].https://blog.google/products/search/introducing-knowledge-graph-things-not/,2020-11-01.
[19]孙学军,曹祺.基于知识图谱的图书馆微信服务研究现状分析[J].情报科学,2019,37(9):164-169.
[20]栾静静,刘大伟,杨亮.基于文献计量和知识图谱的创新政策领域发展研究[J].情报探索,2020,(3):91-102.
[21]徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述[J].电子科技大学学报.2016,45(4):589-606.
[22]欧阳剑,梁珠芳,任树怀.大规模中国历代存世典籍知识图谱构建研究[J].图书情报工作,2021,65(5):126-135.
[23]娄国哲,王兰成.基于知识图谱的网络舆情知识组织方法研究[J].情报理论与实践,2019,42(1):58-64.
[24]周莉娜,洪亮,高子阳.唐诗知识图谱的构建及其智能知识服务设计[J].图书情报工作,2019,63(2):24-33.
[25]郭金龙,许鑫.数字人文中的文本挖掘研究[J].大学图书馆学报,2012,30(3):11-18.
[26](美)安妮·伯迪克,约翰娜·德鲁克,彼得·伦恩费尔德,等.数字人文:改变知识创新与分享的游戏规则[M].马林青,韩若画,译.北京:中国人民大学出版社,2018:3-4,42-45.
[27]冯惠玲.档案记忆观、资源观与“中国记忆”数字资源建设[J].档案学通讯,2012,(3):4-8.
[28]中国国家图书馆.中国记忆项目东北抗日联军专题[EB/OL].http://www.nlc.cn/dsb_zt/xzzt/dbkrlj/lzsks/,2021-04-17.
[29]刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
(责任编辑:郭沫含)
收稿日期:2021-10-30
基金项目:国家社会科学基金项目“数字人文视角下历史档案资源知识聚合与知识发现研究”(项目编号:19BTQ102)。
作者简介:王阮(1992-),女,助理研究员,博士后,研究方向:数字信息资源开发、数字人文与知识服务。
通讯作者:邓君(1977-),女,吉林大學教授,博士生导师,中国人民大学档案事业发展研究中心研究员,研究方向:数字信息资源管理、数字人文与知识服务、用户信息行为、档案管理与应用。
