基于残差卷积注意力网络的视频修复
2022-01-28李德财姚剑敏林志贤董泽宇
李德财,严 群,2*,姚剑敏,2,林志贤,董泽宇
(1.福州大学 物理与信息工程学院, 福建 福州 350108;2.晋江市博感电子科技有限公司, 福建 晋江 362200)
1 引 言
视频修复旨在用视频中时空相关的内容来填充视频序列中的缺失区域[1]。高质量的视频修复对损坏的视频修复[2-3],未损坏的对象移除[4-5],视频重新定向[6]和曝光不足或过度的视频修复[7]等任务具有重要意义。高质量的视频修复仍然面临着许多挑战,例如缺乏对视频的高度理解[8]和高度的计算复杂性。大多数现有的视频修复算法[9-14]遵循传统的图像修复方式,通过将问题公式化为基于块拼接的优化任务,通过采样空间或空间-时间匹配来解决已知区域的最小化问题。尽管有一些好的修复结果,但这些方法不能处理复杂运动的情况,且计算复杂度较高。
随着深度卷积神经网络的发展,深度视频修复取得了重大进展。其中使用3D卷积和递归网络进行视频修复[15-16]越来越受到人们的关注。文献[6]采用循环网络来确保时间的一致性。文献[16]首次提出将3D和2D全卷积网络相结合来学习视频的时间信息和空间细节。Xu等人[17-18]通过联合估计空间特征和光流来提高性能。Chang等人提出了用于自由形式视频修复的时态SN-PatchGAN[19]和时态移位模块[20]。于冰等人[21]提出基于时空特征的生成对抗网络进行视频修复。这些方法通常会从附近的帧中收集信息来填充丢失的区域,但由于有限的时间感受野,在每一帧上直接应用图像修复算法会导致时间伪影和抖动。为解决上述挑战,目前最先进的方法是应用注意力模块来捕捉长距离帧的对应关系,从而可以使用来自远处帧的内容来填充目标帧中的缺失区域[22-23]。文献[22]是通过对视频帧进行加权求和来合成缺失的内容,并进行逐帧关注。文献[23]通过逐像素的关注,从边界向内逐渐填充具有相似像素的缺失区域。虽然有较好的修复结果,但由于视频中复杂的运动会引起明显的外观变化,导致修复帧的匹配效果较差,无法对复杂的空间信息进行合理匹配。此外由于没有对复杂的时间信息处理模块进行针对性优化,而是对所有视频进行逐帧处理,导致修复结果的时间一致性较差,而且需要较大的计算量和较长的处理时间。
针对上述问题,该文提出了一种基于残差网络[24]的卷积注意力网络(RCAN)用以视频修复。该网络以视频所有帧作为输入,使用自注意力机制和全局注意力机制[25]来提取所有帧的时空特征信息,进而对所有输入帧进行修复。此外残差网络的引入,能够增强深度网络的性能,提高网络对所有帧的时空特征的学习能力,同时网络采用时空对抗损失函数进行优化,提高模型泛化能力,实现时空一致的视频修复。此外网络还能够高度自由地定义层数和参数量,降低计算复杂度,减少计算资源需求,加快网络训练速度,大幅度提高实际应用能力。
2 残差卷积注意力网络
2.1 网络概述
(1)
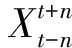
本文提出的残差卷积注意力网络,以目标帧的相邻帧和远距离帧即视频所有帧作为输入,对所有视频输入帧进行修复。通过将自注意力机制和全局注意力机制引入进残差网络中,增强网络对所有帧的空间及时间维度信息的学习能力,保持与相邻帧以及远距离关键帧的时空一致,提高视频修复效果。
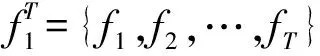
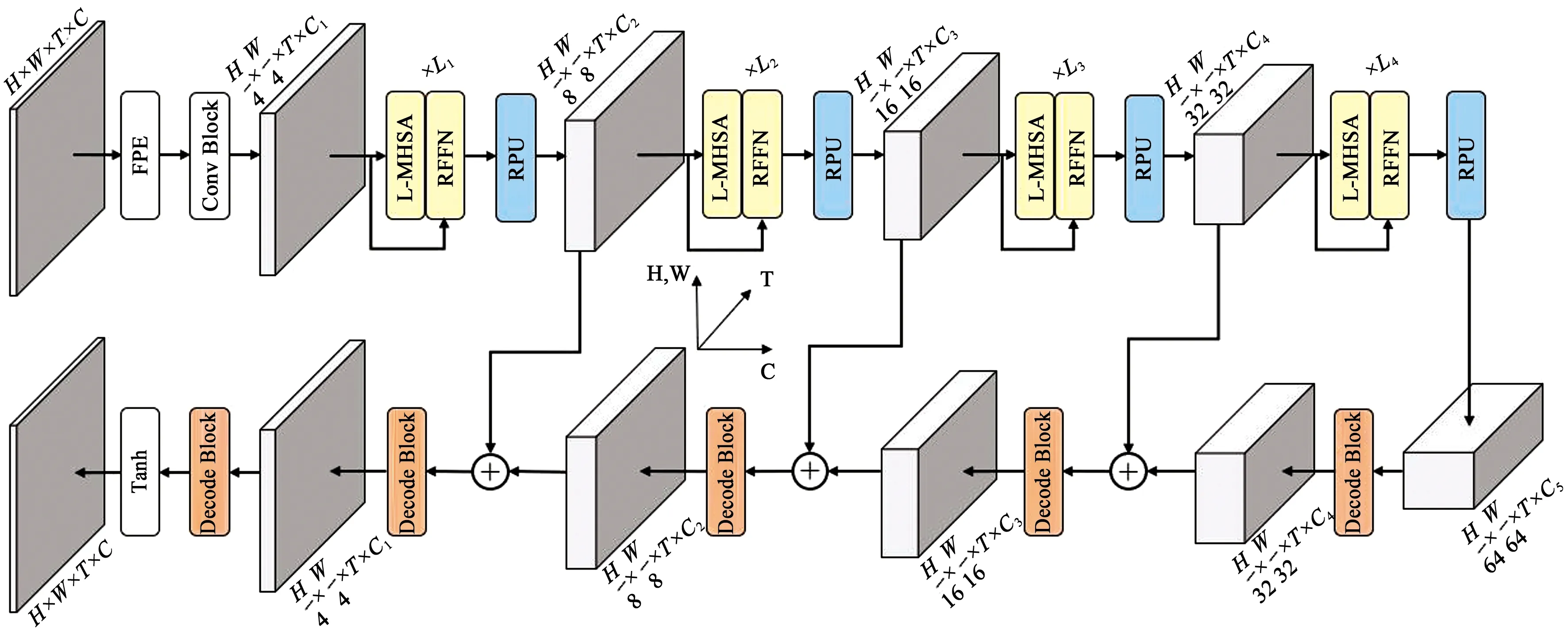
图1 残差卷积注意力网络结构
2.2 残差卷积注意力模块
残差卷积注意力模块由轻量型多头自注意力机制,残差前馈网络以及残差感知单元构成,每部分具体描述如下。
2.2.1 轻量型多头自注意力机制
自注意力机制由自注意层构成,在自注意层中,输入向量通过3个不同的投影矩阵转换为3个不同的向量,即查询向量q、键向量k与值向量v,各向量的维度相同。之后将不同输入获得的向量合为3个不同的矩阵Q、K和V,进行放缩点积计算,具体以计算过程如下:
(2)
自注意层进一步完善,形成了多头自注意力机制。其中多头自注意力机制进行了h次放缩点积计算,使模型能够在不同位置联合关注来自不同表示子空间的信息。具体处理过程如下:
MultiHead(Q,K,V)=
Concat(head1,…,headh)WO,
(3)
其中headi=Attention(Qi,Ki,Vi),Wo是线性投影矩阵。多头自注意力机制进行放缩点积计算时,会根据头部的个数来动态调整每个头部的维度,以保持多头自注意力机制的总计算量与全维单头注意力机制的计算量相当,不增加其计算量。
为减少原始自注意力模块的计算复杂度,本文采用了分块处理,具体结构如图2所示。在自注意力网络中通过卷积网络映射出不同的空间,将特征图分成不同的特征块,将每个特征块的特征空间划分为成不同的特征块,之后计算当前图像的注意力。分块处理即将x∈H×W×C的图像进行处理,变成一系列xp∈N×(P2·C)的展平的2D块的序列[27]。这个序列共有N=HW/P2个展平的2D块,每个块的维度是(P2·C),其中P是块大小,C是通道数。进行分块处理,可以使网络更关注低层次特征,提高对低层次特征的提取能力,同时局部图像变小,可以降低计算量,提高模型速度。
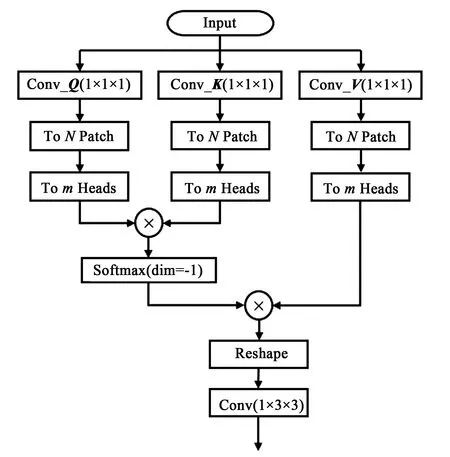
图2 轻量型多头自注意力机制
2.2.2 残差前馈网络及残差感知单元
残差网络是由一系列残差块组成的。残差块的引入可以解决网络退化现象,在增加网络层数时,网络不会发生退化,提高了网络的性能。残差块的一个通用表示为:
xl+1=xl+F(xl,Wl),
(4)
其分为映射和残差两部分,恒等映射通过直连实现,残差部分通常由2~3个卷积组成。其中直连是深度残差网络中旁路的支线,可以跳过一层或多层的连接,直接将输入连接到后面的网络层,使得后面的网络层可以直接学习残差,保留了信息的完整性和有效性。这种连接方式不会增加额外的参数计算复杂度,能够简化学习目标和难度,加速深度神经网络的训练,提高深度网络的性能。
本文提出的残差前馈网络在原始的前馈网络基础上添加残差连接,并使用LeakyRelu作为激活函数,通过改变连接方式来获得更好的性能。具体结构如图3(a)所示,包含了一个扩张层、深度卷积、投影层以及残差连接结构。
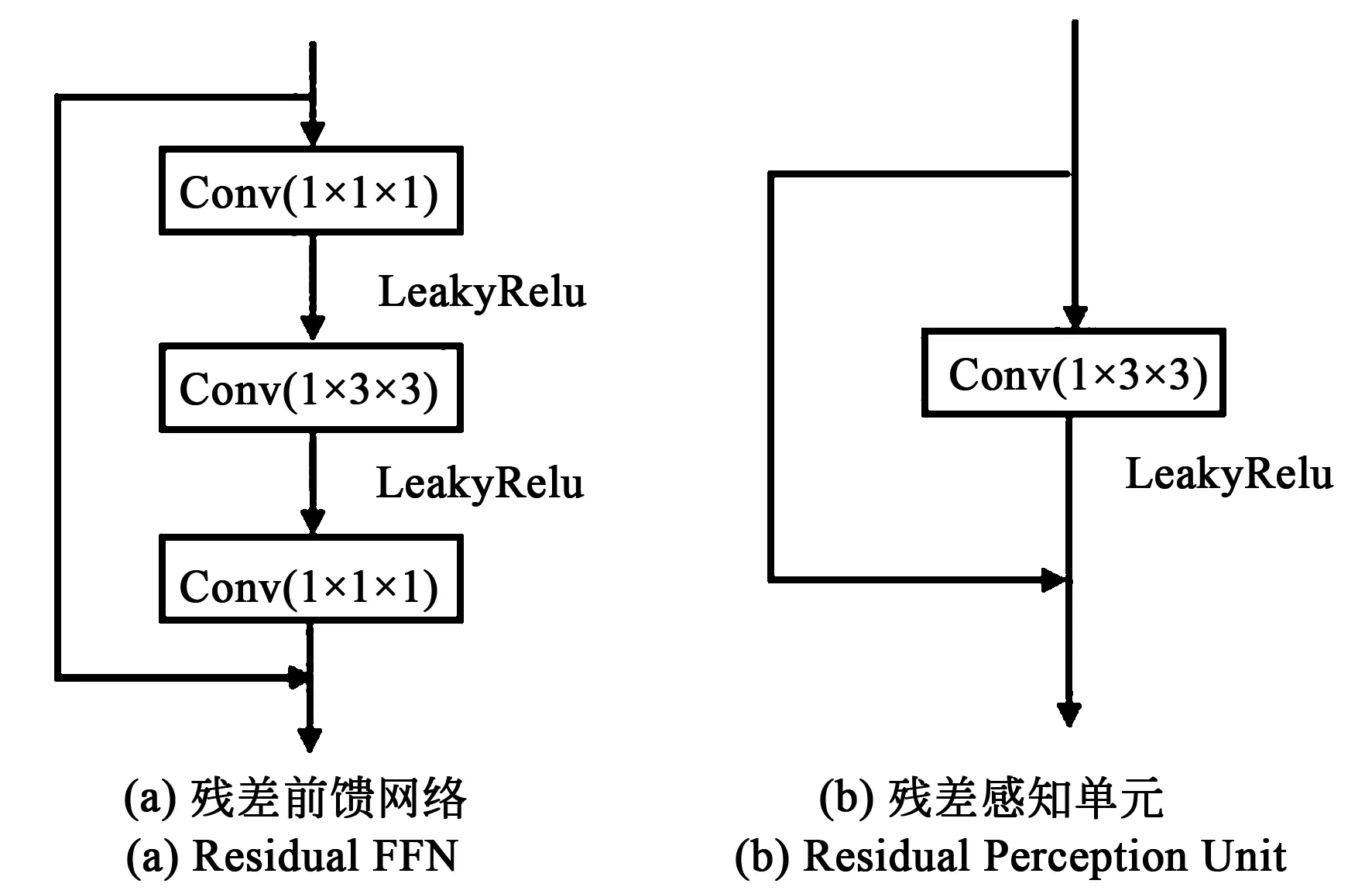
图3 残差前馈网络与残差感知单元
视觉任务中经常使用旋转与平移来增广数据,这些操作应当不能影响模型最终的结果。然而,Transformer中的绝对位置编码会破坏该不变性。此外,Transformer忽略了块内的局部相关性与结构信息。为缓解该限制,本文提出了残差感知单元以提升局部信息,定义如下:
RPU(X)=DWConv(X)+X.
(5)
具体结构如图3(b)所示,由一个卷积核为1×3×3的3D卷积和一个残差连接组成。
2.3 解码模块
解码模块由反卷积的叠加并添加残差连接构成,具体结构如图4所示。先将残差卷积注意力模块的输出进行转换处理,从T帧变成单帧进行处理,然后进行反卷积,卷积核大小为3×3,步长为1,将通道数减半,输入帧特征比例加倍,之后进行3×3卷积,步长为1,将通道数减半,最后进行1×1卷积进行投影。
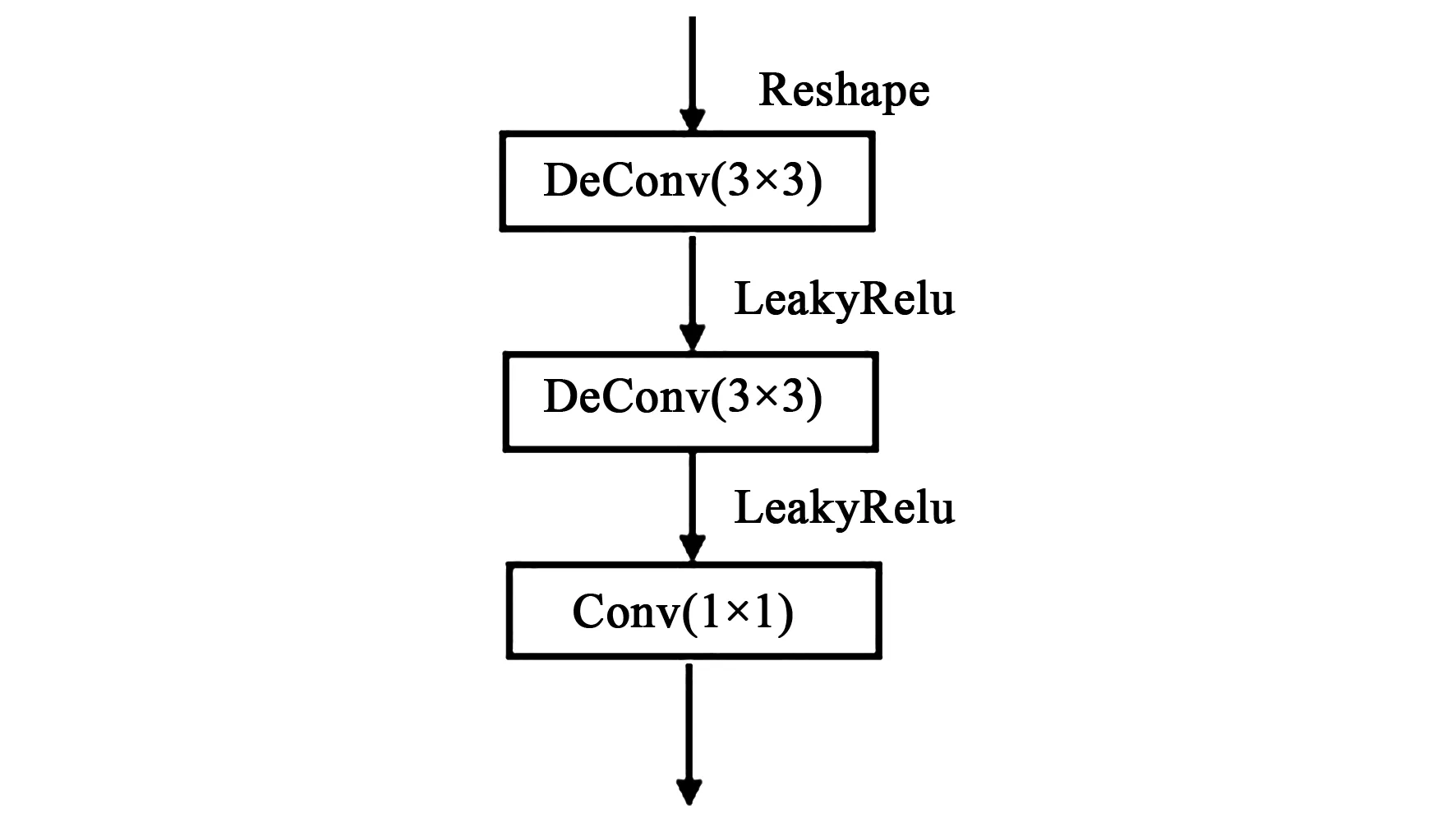
图4 解码模块
RCAN共包含5个解码模块,每个模块通过反卷积将特征反向解码,将输入帧特征比例依次变为1/32,1/16,1/8,1/4,最后经过Tanh激活函数得到完整的修复图像。其中第2,3,4个解码模块与对应的残差卷积注意力模块添加了残差连接,将上一个解码模块的输出与残差卷积注意力模块的输出拼接在一起,然后输入下一个解码模块。此外第一个解码模块与第五个解码模块的通道数有所不同,第一个解码模块通道数减半一次,由512降为256,而第五个解码模块通道数由32降为16再降为3。
2.4 损失函数
选择优化目标函数的原则是确保生成的视频的像素重建精度、修复内容的合理性及时空一致性。该文选择像素级重建损失和时空对抗损失作为损失函数。在生成帧和原始帧之间计算L1,以此衡量每个像素的重建精度。目标修复区域的L1表示为:
(6)
原始无空洞的有效区域的L1表示为:
(7)
由于对抗性训练有助于高质量内容生成,该文借鉴使用了T-PatchGAN(Temporal Patch-GAN)[28]作为判别器。具体来说,T-PatchGAN由6层3D卷积层组成,其可以学习区分每个时空特征的真假,以便网络更好地利用真实数据的时空信息和局部到全局的感知细节进行重建。T-PatchGAN判别器的详细优化函数如下:
(8)
本文在其基础上进行改进,提出了时空对抗损失函数,具体计算过程如下所示:
(9)
结合两部分的总体损失函数为:
L=λrh·Lrh+λrv·Lrv+λadv·Ladv,
(10)
其中:λrh、λrv、λadv表示两个像素级重建损失及时空对抗损失在网络总体损失函数中的比重,通过调整比重参数,可以更有针对性地调整网络参数,提高网络训练的灵活性和网络的泛化能力。一般情况下为了平衡时空对抗损失和重建损失,将损失权重设置为λrh=0.5,λrv=0.5,λadv=0.9。
2.5 训练细节
该网络使用YouTube-VOS[29]数据集进行训练,训练使用数据集原始的数据分割方式,其中训练视频3 471个,验证视频474个,测试视频508个。将视频帧大小调整为384×192,然后对每个视频帧进行固定掩膜处理,之后对视频帧进行随机旋转,提高网络对视频序列旋转角度的鲁棒性,最后将经过处理后的视频帧输入到网络中进行训练。
该网络使用4张NVIDIA RTX2080Ti显卡进行训练,使用Adam优化器,初始学习率为1e-4,batch size为6,步数为50万步。此外还可以在DAVIS[30]数据集上训练,不过由于DAVIS数据集规模较小,一般是将在YouTube-VOS数据集上训练得到的模型来初始化模型,提高其训练速度和精度。
3 实验结果
3.1 实验数据
为了更公平合理地评估本文提出的模型,更好地与现有视频修复模型进行比较,本文采用了视频修复中常用的DAVIS和YouTube-VOS数据集。其中DAVIS是面向实例级分割的数据集,共有50个视频,3 455帧,每个视频序列包含一个对象或者两个空间连接的对象。视频中的每一帧,都拥有像素级别的精度。YouTube-VOS是迄今为止最大、最全面的视频对象分割数据集。YouTube-VOS包含94种类别,4 453个YouTube视频,每个视频时长约3~6 s,平均视频长度约为150帧,共有197 272个对象注释,每个对象由专业注释员手动分割。
本文使用两种自由形式的掩膜进行模型验证:一种是固定掩膜,用来模拟水印去除、空洞修复等应用;另一种是动态掩膜,用来模拟对象移除等应用。固定掩膜是随机生成不规则形状的掩膜并将其应用在整个视频帧的固定区域,动态掩膜是同一对象掩膜应用在整个视频帧中;但每一帧的掩膜区域不同,一般使用数据集中标注的对象分割标注数据。本文使用YouTube-VOS数据集进行固定掩膜测试,使用DAVIS数据集进行固定掩膜和移动掩膜测试。
3.2 评价标准
实验结果分析采用峰值信噪比(PSNR)、结构相似性(SSIM)和 FID三种评价标准。其中PSNR是基于对应像素点间误差的图像质量评价方法,通过均方差进行定义。其具体计算公式如式(11)所示:
(11)
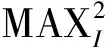
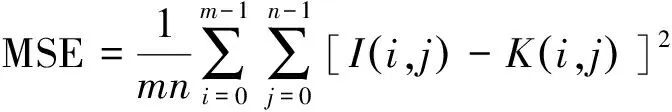
(12)
SSIM基于原始图像x和生成图像y之间的亮度、对比度和结构来进行衡量。计算公式如式(13)所示:
(13)
其中μ是均值,σ是方差,c1、c2为两个常数,避免分母为零。
FID是计算原始图像和生成图像的特征向量之间距离的一种度量。计算公式如式(14)所示:
FID(x,g)=‖μx-μg‖+
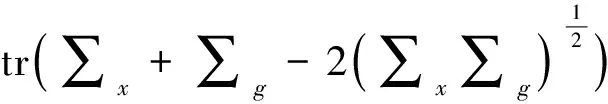
(14)
其中:x为原始图像,g为生成图像,tr表示矩阵对角线的元素之和,μ是均值,∑是协方差。FID的数值越小,表示生成图像的多样性和质量越好。
3.3 与现有方法对比
为了更好地验证RCAN模型视频修复质量的有效性,本文选择将RCAN模型与4种现存主流模型进行了对比。其中VINet[6]、DFVI[17]、LGTSM[31]是基于卷积神经网络或递归网络的模型,能够同时对所有帧进行修复,但只使用了相邻帧没有使用远距离帧建模。CPN[22]、OPN[23]是基于注意力的模型,对视频逐帧修复,使用了远距离帧建模,而对相邻帧关注度不够。本文提出的RCAN模型是在注意力的基础上,使用视频相邻帧及远距离帧即视频所有帧进行建模,能够同时对所有帧进行修复。
本文使用YouTube-VOS测试集的508个视频,并使用固定掩膜进行模型验证。该网络在YouTube-VOS数据集上的视频修复结果与其他模型结果的比较如表1所示。与其他模型相比,该模型的PSNR为30.69 dB,SSIM为0.965,FID为0.059,运行时间为每帧0.85 s,远快于DFVI和LGTSM,内存为6 742 MB,整体性能优于其他模型。结果表明RCAN在像素级和整体感知上都有着更好的视频修复质量和较快的修复速度。
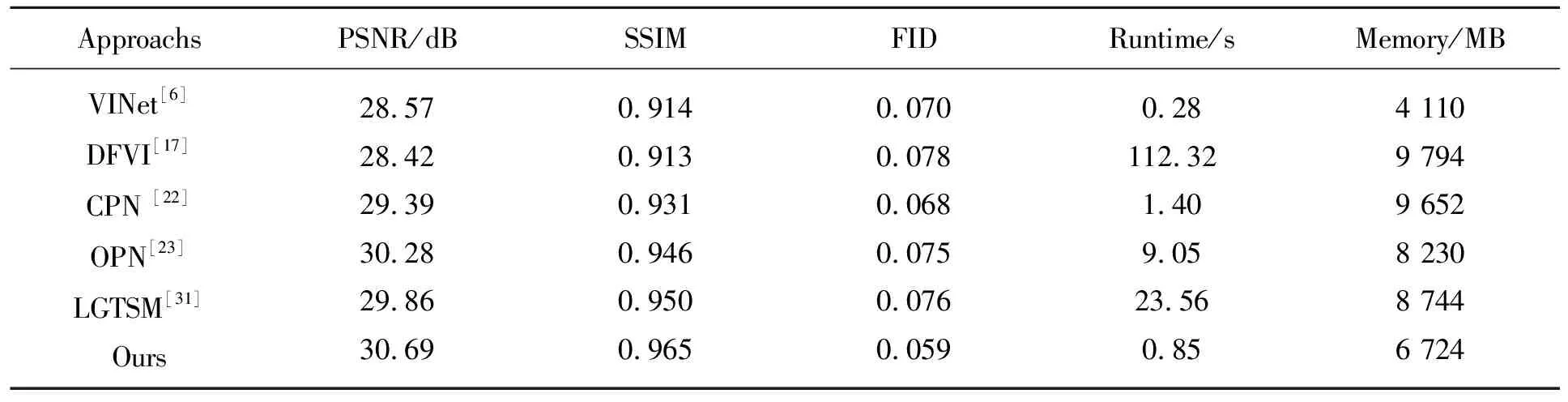
表1 RCAN与现有网络在YouTube-VOS上的修复结果对比
为了更好地验证模型性能,实验还比较了不同模型的视觉效果,结果如图5所示。图5(a)是输入帧,图5(b)是LGTSM模型的结果,图5(c)是CPN模型结果,图5(d)是本文RCAN模型结果。其中第一行和第三行中框选区域为修复区域,第二行和第四行为放大的修复结果,通过对比放大的修复结果可知,RCAN的修复质量更好,时空结构更一致,修复内容更完整。实验表明了RCAN模型在固定掩膜视频修复中的有效性。

图5 YouTube-VOS固定掩膜修复结果
此外为了更好地验证网络的通用性,本文还在DAVIS数据集上使用固定掩膜以及移动掩膜两种方式进行验证。固定掩膜验证结果如表2所示,PSNR为30.67 dB,SSIM为0.956,FID为0.167,运行时间为每帧0.69 s,内存消耗为6 928 MB,整体性能优于其他模型。数据显示在DAVIS数据集上,本文模型取得了较高的修复精度和较快的修复速度。
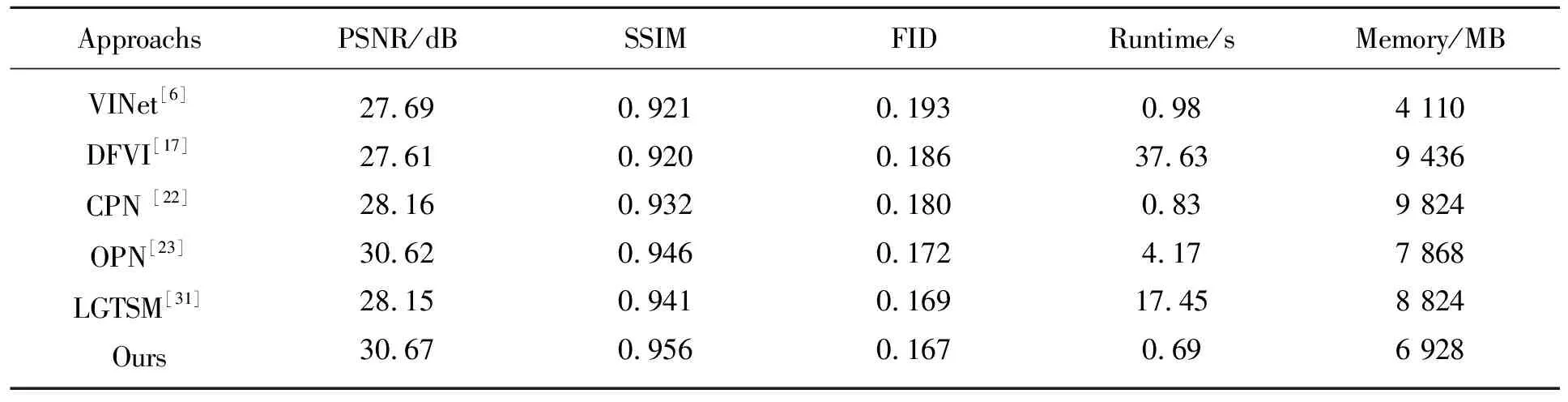
表2 RCAN与现有网络在DAVIS上的修复结果对比
使用固定掩膜及移动掩膜两种方式的定性修复结果如图6所示,前两行是固定掩膜测试,后两行是移动掩膜测试,图6(a)是输入帧,图6(b)是LGTSM模型的结果,图6(c)是CPN模型结果。图6(d)是本文RCAN模型结果。对比发现,本文模型结果空间结构相似性和时间连贯性更强,在复杂场景中也有很好的修复结果。
3.4 消融实验
本文提出的RCAN模型将自注意力机制和全局注意力机制引入残差网络中,增强网络对所有帧的空间及时间维度信息的学习能力,保持与相邻帧以及远距离关键帧的时空一致,提高视频修复效果。表3是残差网络加入注意力机制后在DAVIS数据集上的修复效果对比,修复图像的PSNR和SSIM得到了大幅度的提升,分别提高了5.4 dB和0.04,FID降低了0.075。结果表明引入注意力机制,网络能够关注到重要的特征并抑制无关的干扰特征,能够关注到视频所有帧的关键帧及相邻帧和远距离帧的关键特征,从而提高了模型对所有帧的时空特征学习能力,提高了视频修复效果。
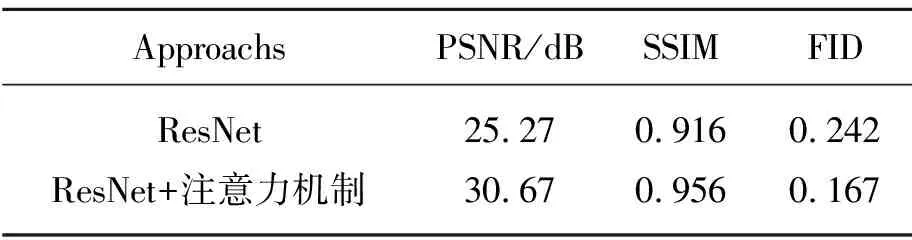
表3 添加注意力机制修复结果对比
此外RCAN模型还可以高度自由地定义层数和参数量,通过控制残差卷积注意力模块的残差层数来控制模型深度,以此来控制模型的复杂度和计算量。表4是网络在不同残差层数结构的结果比较,数据显示网络层数越多,网络的整体精度越高,但同时也提高了网络的复杂度和计算量。在现实应用中,可根据实际应用情况的不同来定义和选择网络的层数和参数量,提高模型的实际应用能力。
4 结 论
本文提出了一种新的用于视频修复的残差卷积注意力网络,通过将自注意力机制和全局注意力机制引入进残差网络中,规避了卷积结构由于其感受野而无法获得全局信息的缺陷,并由此获得更加强大的表达能力,增强了网络对视频输入帧时空特征的学习能力以及泛化能力,提高了视频修复质量。同时结合时空对抗损失,提升修复内容的真实性,提高了网络的整体性能。此外网络还能够根据现实应用中的实际情况自由地定义层数和参数量,来权衡网络精度和速度,提高了模型的实际应用能力。实验表明,本文提出的模型在YouTube-VOS和DAVIS数据集上的修复效果明显优于其他模型,对比DFVI模型,平均PSNR高出2.67 dB,SSIM高出0.044,FID降低了12.98%,表明了残差卷积注意力网络在视频修复中的有效性。
