时域精细结构与包络信息在噪声下声调识别中的作用△
2022-01-27亓贝尔刘佳星古鑫刘博
亓贝尔 刘佳星 古鑫 刘博
汉语作为一种声调语言,声调信息对于安静和噪声环境下识别言语、理解语义均具有重要作用[1,2]。围绕包络信息(envelope,Env)和精细结构信息(temproal fine sturcture,TFS)对言语识别作用的研究已证实,在安静环境下Env对非声调语言识别起重要作用,TFS对音调和声调识别起重要作用[3~5]。但是,在噪声环境下TFS和Env对言语识别中所起作用以及重要程度尚无定论。本研究拟通过分析不同类型噪声环境下听力正常人的汉语普通话声调识别能力,探讨TFS和Env在噪声下声调识别中的作用,分析在不同类型噪声环境下TFS和Env作用的差异。
1 资料与方法
1.1研究对象 受试者纳入标准:母语为汉语普通话、无耳聋家族史、无耳科疾病史,双耳0.25~8 kHz倍频程纯音听阈≤20 dB HL,226 Hz探测音鼓室导抗图A型,1 kHz同、对侧声反射均可引出。共纳入符合上述标准的受试者20例(男10例,女10例)为研究对象,年龄19~30岁,平均24.2±3.2岁,均经本人同意并签署知情同意书。
1.2研究方法
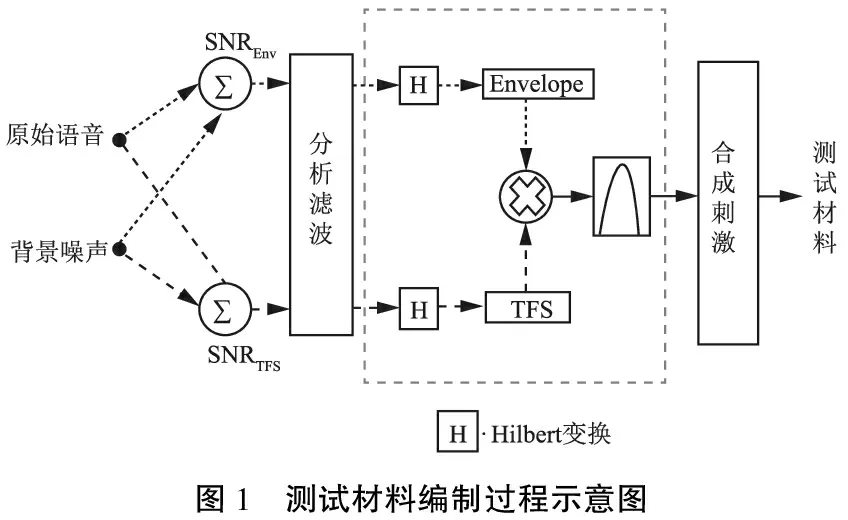
1.2.1编制噪声下声调识别能力测试材料 采用听觉嵌合体处理方案(图1)[6],编制本研究所需的噪声下声调识别能力测试材料。原始语音材料为男女两位母语为汉语普通话播音者录制的80个单音节词(10个音节×4声×2位播音者),背景噪声分别为基于播音者语谱特性的言语谱噪声(speech spectrum-shaped noise,SSN)以及两人谈话噪声(two-talker babble,TTB),其中谈话噪声由上述两名播音者的单轨音频资料混合至多轨而产生。将原始材料与背景噪声按照信噪比(signal-to-noise ratios,SNR)为-18、-12、-6、0、+6 dB进行合成,最终形成包含2 000 个测试音的正式测试材料(即80个单音节词×5 SNRTFS×5 SNREnv)以及包含80个测试音的练习材料(即20个单音节词×2 SNRTFS×2 SNREnv),上述提取与合成过程均使用MATLAB软件编程实现。语音平衡对声调识别无显著影响,即使音节之间有小差异也不影响总的声调识别结果,因此,测试材料并未考虑语音平衡问题。
1.2.2噪声下声调识别能力测试 在基于MATLAB语言的GUI交互系统控制下以“四选一”(four alternative forced-choice,4AFC)方法完成噪声下声调识别能力测试(图2)。受试者通过练习掌握测试方法后,随机选择一侧耳以其自觉舒适的强度聆听正式测试材料。正式测试时每个测试项只播放一次,允许受试者猜测没把握的选项,测试过程中不对结果做出反馈。全部测试在本底噪声≤45 dB A的安静房间内由同一个声卡在同一台电脑的控制下完成,使用Sennheiser HD 280 pro压耳式耳机给声;测试成绩(%)=(正确选项/总测试项)×100%。

1.3统计学方法 采用广义线性模型(generalized linear model,GLM)分析不同信噪比条件下TFS成分和Env成分在声调识别中的作用,以MATLAB统计学工具箱完成统计分析,以P<0.05为差异有统计学意义。
2 结果
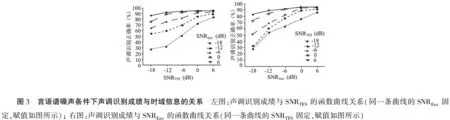
2.1言语谱噪声下声调识别成绩与时域信息的关系 SSN条件下,本组受试者声调识别成绩与时域信息的函数曲线关系见图3,当某一种信息量固定时,增加另一种信息量可以改善声调识别成绩,即时域包络信息一定时,增加时域精细结构信息有利于声调识别,反之亦然。当SNRTFS和SNREnv信息量相等时,SSN噪声五种信噪比条件下的声调识别平均正确率分别为27.6%、60.2%、82.1%、93.9%和94.7%,提示当两者信息量相等时,信噪比越高声调识别能力越好。
2.2两人谈话噪声下声调识别成绩与时域信息的关系 两人谈话噪声条件下,本组受试者声调识别成绩与时域信息的函数曲线关系见图4,当某一种信息量固定时,增加另一种信息量可以改善声调识别成绩,但这种相互改善的趋势较SSN噪声下弱。当SNRTFS和SNREnv相等时,TTB噪声下五种信噪比时的声调识别平均正确率分别为53.5%、 72.0%、 86.4%、92.7%和95.0%。提示当两者信息量相等时,信噪比越高声调识别能力越好。

2.3时域包络与时域精细结构在噪声下声调识别中的作用 采用广义线性模型(generalized linear model,GLM)方法评估时域包络信息和时域精细结构信息在噪声下声调识别中的作用。在SSN噪声条件下,Env、TFS以及二者协同作用与声调识别成绩的回归系数分别为0.095(t=36.7,P<0.000 1)、0.070(t=26.0,P<0.000 1)和-0.002(t=8.8,P<0.000 1)。在TTB噪声条件下,Env、TFS以及二者协同作用与声调识别成绩回归系数分别为0.052(t=19.6,P<0.000 1)、0.073(t=28.8,P<0.000 1)和-0.000 3(t=1.5,P=0.13),提示两种噪声条件下时域包络信息和时域精细结构信息对声调识别中均具有重要作用,但是两者的协同作用更有助于提高言语谱噪声条件下的声调识别能力,在多人谈话噪声条件下声调识别能力没有明显改善。
3 讨论
Rosen[7]指出任何一个声信号的时域波形都可以通过Hilbert变化用数学方法描述为包络(envelop)成分和精细结构(fine structure)成分的组合。精细结构信息反映的是声音信号中快速变化的成分,其中时域精细结构指0.5~10.0 kHz的时域信息,包含言语信号的瞬时相位信息[6]。包络信息反映的是声音信号中缓慢变化的成分,其中时域包络是指500 Hz以下时域信息,包含信号的时长、幅值轮廓及周期性信息[6]。Smith等[3]提出了基于听觉感知二分法构建刺激声的“声嵌合”(auditory chimera)技术,即通过Hilbert转换分别提取A和B两个声信号的Env成分和TFS成分, 然后将两个声信号的包络与精细结构成分互换形成“嫁接声”, 受试者根据“嫁接声”判断其听到的是A还是B, 从而获得受试者依靠何种成分进行言语识别。利用该技术发现,在安静环境下包络信息对非声调言语感知起决定性作用[3],精细结构信息对声调语言感知和音乐识别起决定性作用[4]。Füllgrabe等[8]和Moore[9]发现利用声码器方法将时域精细结构信息替代后,受试者在噪声环境下的言语(英语)识别成绩明显下降,从而推测TFS信息在噪声环境下的言语(英语)识别中起主要作用;Apoux等[6]则发现无论是稳态噪声还是竞争言语噪声环境下,Env信息在语句(英语)识别中占主导地位,TFS信息作用甚微。
Env 和TFS信息对于噪声环境下的声调语言感知所起的作用与噪声环境下的非声调语言识别中起主要作用是相同还是不同值得探讨。为此,本研究选用了日常社交中最常遇到的噪声场景,即多人谈话噪声(babble noise,BN),常用的有2、4、8、12人及以上人数谈话的噪声,多人谈话噪声作为一种波动性噪声,对言语信号的掩蔽作用主要体现在能量掩蔽和信息掩蔽。有研究显示随着谈话者人数减少,多人谈话噪声的信息掩蔽效应作用增大、能量掩蔽效应作用减小[10];其中2人谈话噪声信息掩蔽作用较强,常与言语谱噪声共同用于研究能量掩蔽和信息掩蔽对听觉信号获取的影响机制。故本研究选用两人谈话噪声和言语谱噪声作为竞争噪声,观察这两种噪声下听力正常人的声调识别能力及TFS和Env的作用。结果显示噪声环境下的声调识别需同时依靠TFS信息和Env信息,而非独立依靠TFS信息,该结果既不同于安静环境下声调识别研究结论,亦不同于噪声下言语(英语)识别研究结论。噪声环境下TFS线索在声调识别的主导地位减弱,其原因考虑与声音信号各成分的特性相关,TFS反映的是声音信号中快速变化的成分,其中时域精细结构指0.5~10.0 kHz的时域信息,包含言语信号的瞬时相位信息[5]。Env反映的是声音信号中缓慢变化的成分,其中时域包络是指500 Hz以下时域信息,包含信号的时长、幅值轮廓及周期性信息[5]。无论是稳态噪声或竞争性言语噪声,其掩蔽作对于聆听者获取瞬时信息的影响较其获得缓慢变化信息的更大。因此非目标声音(噪声)对目标声音(汉语单音节词)的掩蔽作用,限制了TFS信息在噪声下声调识别中的作用地位。但是,在竞争性言语噪声条件下,TFS对于声调识别的作用较Env大,可能与语音掩蔽释放(speech masking release)理论相关[11,12]。该理论认为波动背景噪声比稳定背景噪声提供了更多获取目标语音TFS的机会。在波动背景噪声下,非目标声音时域和频域的波谷区域对目标信号的掩蔽作用相对减弱,有助于听觉系统“瞥见(glimpse)”目标信号的生理学特点,即听力正常人可以从目标信号相对不受背景影响的时频区域中提取语音信息[13~15]。另外,本研究采用的是4AFC测试,机会概率为25%;测试结果显示只有在最难的测试条件下(即SNR=-18 dB),平均正确率(28%)才会接近机会概率,因此地板效应(floor effect)对本研究影响很小,故未予考虑。本研究结果显示无论是TFS信噪比较好(如:SNRTFS≥0 dB)、Env信噪比较差(如:SNREnv≤-6 dB)条件下,亦或TFS信噪比较差(SNRTFS≤-6 dB)、Env信噪比较好(SNREnv≥0 dB)条件下,听力正常者均可获得较好的声调识别,提示TFS和Env 信息协同作用于噪声环境下的声调识别,两种信息成分互相补充。该结果支持随着听力损失程度加重、外周感受器提取和利用TFS信息的能力下降后,听障者将更多依赖Env线索进行声调识别的研究结果[16,17]。
综上所述,时域精细结构信息和时域包络信息对于听力正常人噪声下声调识别具有同等作用,两者协同作用更有助于提高噪声条件下的声调识别成绩。本研究结果为进一步了解人工耳蜗植入者进行噪声下言语识别的困难所在、改进人工耳蜗言语编码策略提供参考。
