基于改进YOLOv4的工业棒料识别算法
2022-01-25,,2,
,,2,
(1.西安工程大学机电工程学院,陕西 西安 710048;2.绍兴市柯桥区西纺纺织产业创新研究院,浙江 绍兴 312030)
0 引言
机械制造业是国民经济的支柱产业,其中棒料是批量生产辊锻件、模锻件及辗压件等零件的主要原材料,广泛应用于工程机械、汽车制造和建筑等行业。目前,大多数企业主要依靠人工将大量堆放在地上的棒料放在料架和辊道上来完成上料工作[1],而这种上料方式自动化程度低,费时费力且效率低下。
随着中国制造2025提出,以机器视觉技术引导的上料自动化已成为制造企业上料的必然趋势。为此,广大学者开展了深入的机器视觉的零件识别方法研究:基于模板匹配的目标识别方法[2-5]在目标大小和形状变化时,就无法与模板匹配,需重新训练补充模板,匹配耗时越长;基于卷积神经网络的目标识别方法[6-11]对密集目标和存在遮挡时的识别效果还不太理想,而且这类算法复杂且计算量庞大,实际工业生产中并没有推广应用。而由于卷积神经网络具有自学习自适应和大数据处理等优势,所以这类方法是目标识别方法的研究热点。
为了解决工业环境下棒料堆积、相互遮挡而造成的难以快速有效识别的问题,研究了基于卷积神经网络的目标识别方法[12-15]。以YOLOv4为改进算法的基础框架,通过设计一种轻量化的工业棒料识别算法,实现了棒料的快速识别;采用对YOLOv4原损失函数进行改进优化,引入Repulsion损失函数,减少棒料的误检、漏检问题,从而改善棒料间相互遮挡而难以有效识别的问题。
1 YOLOv4算法
1.1 YOLOv4算法框架
YOLOv4的算法框架如图1所示,主要包含4部分:输入(Input),输入尺寸为416×416的3通道图片;主干网络(CSP-Darknet53),CSP-Darknet53网络采用全卷积神经网络的方式,用卷积操作代替池化和全连接操作进行特征提取;Neck模块,包含空间金字塔池化结构(SPP)和特征金字塔结构(PANet),该模块对主干网络提取到的最后3层特征图反复进行特征融合再提取,融合深浅层的语义信息特征和空间信息特征[16],实现多尺度目标检测;预测模块,采用YOLO Head结构预测目标的位置、类别和置信度。

图1 YOLOv4的算法框架
1.2 YOLOv4算法损失函数
YOLOv4算法的损失函数由3部分构成:回归框损失函数LCIoU、置信度损失函数Lcon和类别损失函数Lclass,即
L=LCIoU+Lcon+Lclass
(1)
其中,回归框损失函数LCIoU为:
(2)
(3)
(4)
SIoU为真实框面积和预测框面积之间交集与并集的比值;b、b1分别为预测框和真实框的中心点坐标;ρ2(b,b1)为预测框和真实框中心点坐标之间的欧氏距离;c2为预测框和真实框的最小闭包区域的对角线距离;w1和h1分别为真实框的宽、高;w和h分别为预测框的宽、高;v用来度量长宽比的相似性,若真实框和预测框的宽高相似,则v为0;α为权重函数。
置信度损失函数和类别损失函数分别为:
(5)
(6)
K为特征图的尺寸;M为特征图使用的先验框的数量;cij为置信度;c为预测的类别。
2 改进的YOLOv4算法
YOLOv4的主干网络采用全连接神经网络的方式进行特征提取,网络结构复杂、模型计算量大,往往需要使用高性能的计算机运行才能达到预期识别精度和速度。为了降低棒料识别算法的硬件需求,在保证识别精度的条件下提高识别速度,所以需要对YOLOv4的主干网络进行轻量化改进,采用轻量级网络Mobilenetv3替换原YOLOv4的主干网络。
工业棒料往往由于堆叠产生遮挡,若直接采用YOLOv4对密集的棒料进行识别则会出现误检漏检问题。因棒料堆叠且外观特征相似,易导致目标预测框偏移,使识别时定位不准确,从而出现误检问题。由于棒料堆叠导致目标预测框和其他目标预测框过于靠近,所以在非极大值抑制操作时容易被误删,从而出现棒料漏检问题。为了解决棒料识别过程中的误检漏检问题,借鉴行人检测遮挡问题的研究方法[17-18],将Repulsion损失函数与YOLOv4原损失函数结合,改进优化损失函数。

图2 改进YOLOv4算法的网络结构
2.1 主干网络的改进
主干网络的改进:首先对Mobilenetv3进行微调,即去除其最后的平均池化层和1×1卷积层,然后将剩余部分作为YOLOv4模型的主干网络。改进YOLOv4算法的主干网络由1个普通卷积层conv和多个bneck结构组成,如图2所示。bneck结构由深度可分离卷积、具有线性瓶颈的逆残差结构和轻量级的注意力模型SENet组成,如图3所示。
深度可分离卷积先采用深度卷积将输入特征中的每个通道与对应的单通道卷积核进行卷积操作,保持特征图数量不变,然后用N个1×1×M卷积核对所有特征图进行整合,得到N个卷积特征图,如图4所示,其参数量为M×b×b×c×c+M×c×c×N=M×c2×(b2+N)。标准卷积的计算方式如图5所示,其参数量为M×b2×c2×N。很容易得到深度可分离卷积的参数量是标准卷积的(1/N+1/b2),极大地减少了网络参数量,加快了模型运行速度,进而提高了算法的检测速度。

图3 bneck的结构
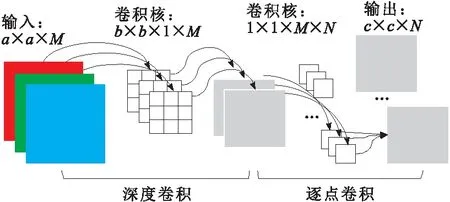
图4 深度可分离卷积
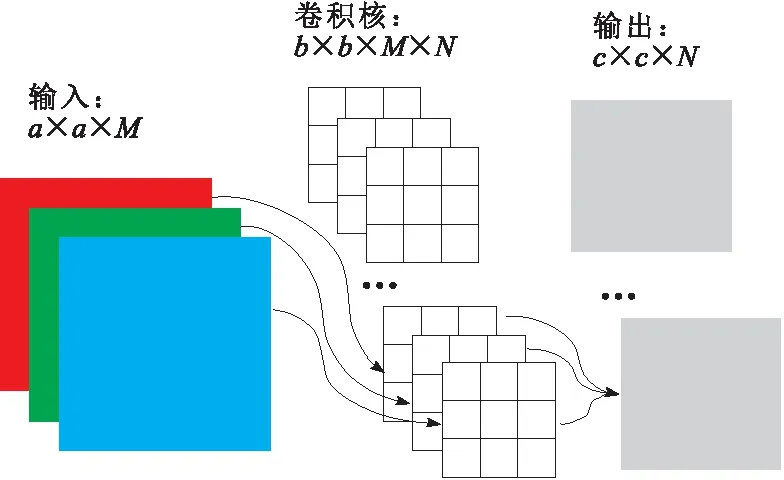
图5 标准卷积
2.2 损失函数的改进
将原YOLOv4损失函数和Repulsion损失函数串联起来得到改进后的损失函数,即
LR=L+α×LRepGT+β×LRepBox
(7)
L为YOLOv4原损失函数;LRepGT为目标预测框
与相邻真实框所产生的损失值;LRepBox为目标预测框与相邻的其他目标预测框所产生的损失值;系数α和β为平衡2个损失值的权值。RepGT和RepBox损失函数具体如下所述。
a.RepGT损失函数的表达式为:
(8)
(9)
(10)
BP为预测框P回归调整得到的目标预测框;GRep为除了指定目标外,与目标预测框交并比最大的真实框;P1为预测框P和真实框重合度达到阈值的正例集合;Aarea()为计算面积的函数。Smoothln函数中的δ值用来调节整个损失函数对交集大的框对的敏感性,当δ=1时,LRepGT取得最好效果;当δ=0时,LRepBox取得最好效果,本文实验取δ=0.5。
b.RepBox损失函数的表达式为
(11)
Pi和Pj分别为预测不同目标的预测框;BPi和BPj是分别从预测框Pi和Pj回归的目标预测框;SIoU(BPi,BPj)为BPi和BPj之间交集与并集的比值;ε为防止除数为0而设置的极小值。分母中的示性函数表示:只对有交集的BPi和BPj目标预测框计算损失值,否则不进行损失计算。
从式(8)可以看出,当BP和GRep之间的交集越大,即越靠近时,所产生的RepGT损失越大,使目标预测框和相邻的真实目标框远离,因此可以有效防止目标预测框误检。从式(11)可以看出,当BPi和BPj的交集越大,即越靠近时,则产生的RepBox损失越大,使目标预测框远离不是预测同一真实目标的相邻预测框,可以降低非极大值抑制后不同目标的预测框被误删的概率,从而减少目标漏检。
3 实验与结果分析
3.1 实验环境与棒料实验数据集
实验平台配置:CPU型号Intel x299/i7-7820x,GPU型号为NVIDIA GeForce RTX 2080Ti,内存为16 GB,实验基于Ubuntu操作系统,以Tensorflow深度学习框架和Python编程语言在自制棒料数据集上进行相关实验。
为了验证改进YOLOv4算法是否能快速有效识别棒料,实验选择尺寸为直径30 mm,长100 mm的圆柱棒料通过模拟棒料离散和随机堆叠的摆放方式来保证数据集更加贴近实际生产环境,直径使用工业相机拍摄了1 467张零件图片作为实验数据集,实验数据集只有1类,即棒料。实验数据集中的原始图片大小为600×600,训练前按7∶3的比例在实验数据集中随机选择1 027张图片作为训练集,剩余440张图片作为测试集,棒料数据集的部分样本图片如图6所示。

图6 部分棒料数据集
3.2 改进算法的模型训练方法及评价指标
3.2.1 模型训练方法
由于卷积神经网络需要大量数据集训练才会取得较好的检测效果,训练样本过少会导致网络过拟合。为了避免过拟合,提高模型的泛化能力和准确率,针对本实验小数据集的情况,实验中改进算法采用迁移学习的训练方式进行训练,同时在训练时不断对棒料图片的色调、饱和度和曝光度进行随机调整,以达到数据集扩充的目的。本实验设置训练的迭代轮次为100:前50轮训练时先冻结主干网络,加载预训练权重,只对最后的全连接层进行训练;后50轮训练时再将主干网络解冻,使用自制棒料数据集将整个网络一起训练。网络训练的参数设置如表1所示,其中批尺寸即为batch size,表示每次输入网络中进行训练的样本数量;动量因子为训练时损失函数的值下降的趋势。

表1 网络的训练参数
3.2.2 评价指标
a.准确度评价指标。实验采用平均精度(AP)作为衡量改进算法性能好坏的评价指标,一般目标识别算法的性能越好,其平均精度越高。平均精度表示网络对每类目标识别的平均准确度,计算方法为每类目标准确率-召回率曲线与x轴围成图像的面积,即
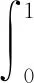
(12)
其中,P为准确率;R为召回率。
b.速度评价指标。实验采用每秒检测棒料图片的帧数(帧/s)作为改进算法检测速度的评价指标。
c.模型的参数量作为辅助指标衡量改进算法的复杂程度。
3.3 实验及结果分析
3.3.1 改进YOLOv4算法的性能分析
为了验证改进YOLOv4算法的收敛速度和稳定性,将改进算法与YOLOv4、YOLOv3和Faster R-CNN这4种算法的损失函数曲线进行对比。为了更加清晰地对比收敛效果,这里选取每一轮次的总损失值作为对比数据,如图7所示。可以看出4种算法经过训练最终都达到了收敛,但改进YOLOv4算法与其他3种算法相比, 算法的收敛速度更快,损失函数曲线更加平滑,且训练到85轮之后损失值震荡的范围和损失值也更小。由此可见,改进YOLOv4算法在保证收敛性能的同时还具有较好的鲁棒性。

图7 4种不同算法的损失函数对比
3.3.2 改进YOLOv4算法的棒料识别效果及结果分析
为了验证改进YOLOv4算法的棒料识别性能,将改进YOLOv4算法与YOLOv4、YOLOv3和Faster R-CNN算法在准确度、识别速度和模型参数3方面进行对比,如表2所示。

表2 4种不同算法的识别结果对比
由表2可知,改进YOLOv4算法的准确度为97.85%,与YOLOv4、YOLOv3和Faster R-CNN相比分别提升了1.62%、1.90%和5.22%。从算法的识别速度来看,改进YOLOv4算法均高于其他3种算法,达到了63帧/s;从算法的模型参数来看,改进YOLOv4算法的模型参数为46.5 MB,YOLOv4的模型参数约是改进算法的5.5倍,YOLOv3的模型参数约是改进算法的5.3倍,Faster R-CNN的模型参数约是改进算法的2.4倍。总的来看,改进YOLOv4算法提高了棒料识别准确度,大大减少了模型参数,提升了棒料的识别速度,从而实现了棒料的快速有效检测。棒料识别算法的部分识别效果如图8所示。

图8 部分棒料数据集的识别效果
可以看出,离散棒料全部可以准确识别出来,如图8a所示,共7根棒料全部能准确识别;对于轻度遮挡下的棒料由于部分特征丢失,存在少量的漏检,但整体识别效果良好,如图8b所示,共8根棒料识别出7根;而对于重度遮挡下的棒料由于特征丢失严重且棒料间颜色对比度低,所以识别效果相对较差,如图8c所示,在10根棒料中,只识别出表层和边缘特征丢失不多的6根棒料。总的来说,改进YOLOv4算法对于棒料的识别效果良好。
4 结束语
针对存在遮挡干扰时棒料如何进行快速有效识别的问题展开了研究,提出了一种基于改进YOLOv4的棒料识别算法。与YOLOv4相比,改进算法的棒料识别准确率更高,识别速度更快,对于离散和轻度遮挡时棒料的识别效果良好,但当棒料严重遮挡时不能全部有效识别。而棒料上料时往往是从表层开始进行抓取,当表层棒料抓取之后就将棒料严重遮挡问题转化成轻度遮挡或者离散情况了,这时棒料的识别效果就会更好,所以改进的棒料识别算法可以作为棒料上料过程的识别模块,为棒料的定位抓取奠定基础,同时也作为下一步的研究工作。
