Domain-Invariant Similarity Activation Map Contrastive Learning for Retrieval-Based Long-Term Visual Localization
2022-01-25HanjiangHuHeshengWangZheLiuandWeidongChen
Hanjiang Hu,Hesheng Wang,,Zhe Liu,and Weidong Chen,
Abstract—Visual localization is a crucial component in the application of mobile robot and autonomous driving.Image retrieval is an efficient and effective technique in image-based localization methods.Due to the drastic variability of environmental conditions,e.g.,illumination changes,retrievalbased visual localization is severely affected and becomes a challenging problem.In this work,a general architecture is first formulated probabilistically to extract domain-invariant features through multi-domain image translation.Then,a novel gradientweighted similarity activation mapping loss (Grad-SAM) is incorporated for finer localization with high accuracy.We also propose a new adaptive triplet loss to boost the contrastive learning of the embedding in a self-supervised manner.The final coarse-to-fine image retrieval pipeline is implemented as the sequential combination of models with and without Grad-SAM loss.Extensive experiments have been conducted to validate the effectiveness of the proposed approach on the CMU-Seasons dataset.The strong generalization ability of our approach is verified with the RobotCar dataset using models pre-trained on urban parts of the CMU-Seasons dataset.Our performance is on par with or even outperforms the state-of-the-art image-based localization baselines in medium or high precision,especially under challenging environments with illumination variance,vegetation,and night-time images.Moreover,real-site experiments have been conducted to validate the efficiency and effectiveness of the coarse-to-fine strategy for localization.
I.INTRODUCTION
VISUAL localization is an essential problem in visual perception for autonomous driving and mobile robots[1]–[3],which is low-cost and efficient compared with global positioning system-based (GPS-based) or light detection and ranging-based (LiDAR-based) localization methods.Image retrieval,i.e.,recognizing the most similar place in the database for each query image [4]–[6],is a convenient and effective technique for image-based localization,which serves place recognition for loop closure and provides initial pose for finer 6-DoF camera pose regression [7],[8] for relocalization in simultaneous localization and mapping (SLAM).
However,the drastic perceptual changes caused by longterm environmental condition variance,e.g.,changing seasons,illumination,and weather,casts serious challenges on image-based localization in long-term outdoor self-driving scenarios [9].Traditional feature descriptors (SIFT,BRIEF,ORB,BRISK,etc.) can be only used for image matching under scenes without significant appearance changes due to the reliance on image pixels.With convolutional neural networks (CNNs) making remarkable progress in the field of computer vision and autonomous driving [10],learning-based methods have gained significant attention owing to the robustness of deep features against changing environments for place recognition and retrieval [11]–[13].
Contrastive learning is an important technique for image recognition tasks [14]–[16],also known as deep metric learning,which aims to learn metrics and latent representations with closer distance for similar images.Compared to face recognition,supervised learning for place recognition[13],[17] suffers from difficulty in determining which clip of images should be grouped to the same place in the sequence of continuous images.Moreover,supervised contrastive learning methods for outdoor place recognition [18],[19] need numerous paired samples for model training due to heterogeneously entangled scenes with multiple environmental conditions,which is costly and inefficient.Additionally,considering a feature map with salient areas in the explanation of CNNs for classification task [20]–[22],retrieval-based localization could be addressed through such attentive or contextual information [23],[24].However,these methods have no direct access to the similarity of the extracted feature so they are not appropriate for high-precision localization.
To address these issues,we first propose an unsupervised and implicitly content-disentangled representation learning through probabilistic modeling to obtain domain-invariant features (DIF) based on multi-domain image translation with feature consistency loss (FCL).For retrieval with high accuracy,a novel gradient-weighted similarity activity mapping (Grad-SAM) loss is introduced inside the training framework inspired by [20]–[22].Furthermore,a novel unsupervised adaptive triplet loss is incorporated in the pipeline to promote the training of FCL or Grad-SAM and the two-stage test pipeline is implemented in a coarse-to-fine manner for the performance compensation and improvement.We further investigate the localization and place recognition performance of the proposed method by conducting extensive experiments on both CMU-Seasons dataset and RobotCar-Seasons dataset.Compared to state-of-the-art image-based baselines,our method presents competitive results in medium and high precision.In the real-site experiment,the proposed two-stage method is validated to be simultaneously timeefficient and effective.An example of image retrieval is shown in Fig.1.Our contributions are summarized as follows:
1) A domain-invariant feature learning framework is proposed based on multi-domain image-to-image translation architecture with feature consistency loss and is statistically formulated as a probabilistic model of image disentanglement.
2) A new Grad-SAM loss is proposed inside the framework to leverage the localizing information of feature map for highaccuracy retrieval.
3) A novel adaptive triplet loss is introduced for FCL or Grad-SAM learning for the self-supervised contrastive learning and gives the effective two-stage retrieval pipeline from coarse to fine.
4) The effectiveness of the proposed approach is validated on CMU-Seasons dataset and RobotCar-Seasons dataset for visual localization through extensive experimentation.Our results are on par with state-of-the-art baselines of image retrieval-based localization for medium and high precision.Also,the time-efficiency and effectiveness of its applicability is shown through a real-site experiment as well.
The rest of this paper is organized as follows.Section II presents the related work in place recognition and representation learning for image retrieval.Section III presents the formulation of domain-invariant feature learning model with FCL.Section IV introduces the adaptive triplet loss and the two-stage retrieval pipeline with Grad-SAM loss.Section V shows the experimental results on visual localization benchmark.Finally,in Section VI we draw our conclusions and present some suggestions for the future work.
II.RELATED WORK
A.Place Recognition and Localization
Outdoor visual place recognition has been studied for many years for visual localization in autonomous driving or loop closure detection of SLAM,in which the most similar images are retrieved from key frame database for query images.Traditional feature descriptors have been used in traditional robotic applications [25],[26] and are aggregated for image retrieval and matching [27]–[30],which have successfully addressed most cases of loop closure detection in visual SLAM [31] without significant environmental changes.VLAD [32] is the most successful man-made feature for place recognition and has been extended to different versions.NetVLAD [4] extracts deep features through VLAD-like network architecture.DenseVLAD [6] presents impressive results through extracting multi-scale SIFT descriptor for aggregation under drastic perceptual variance.To reduce the false positive rates of single feature-based methods,sequencebased place recognition [33],[34] is proposed for real-time loop closure for SLAM.

Fig.1.On the first row,column (a) shows a query image under Overcast +Mixed Foliage condition and column (b) shows the retrieved image under Sunny+No Foliage condition.On the second row,the gradient-weighted similarity activation maps are shown for the above images.The activation map visualizes the salient area on the image which contributes most to the matching and retrieval across the different environments.
Since convolutional neural networks (CNNs) has successfully addressed many tasks in computer vision [35],long-term visual place recognition and localization have significantly developed assisted along with CNNs [4],[13],[36].Some solutions to the change of appearance are based on image translation [37]–[40],where images are transfered across different domains based on generative adversarial networks (GANs) [41],[42].Poravet al.[43] first translates query images to database domain through CycleGAN [44] and retrieves target images through hand-crafted descriptors.ToDayGAN [45] similarly translates night-images to dayimages and uses DenseVLAD for retrieval.Jenicek and Chum [36] proposes to use U-Net to obtain photometric normalization image and finds deep embedding for retrieval.However,generalization ability is limited by translation-based methods because the accuracy of retrieval on image level largely depends on the quality of the translated image compared to the retrieval with latent-feature.
Some other recent work follows the pipeline of learning the robust deep representation through neural networks together with semantic [46],[47],geometric [48],[49],context-aware information[23],[24],[50],[51],etc.Although these models can perform the image retrieval in the feature level,the representation features are trained with the aid of auxiliary information which is costly to obtain in most cases.With the least human effort for auxiliary perception information and inspired by classification activation map [20]–[22] in visual explanation of CNN,we introduce the notion of activation map to the representation learning for fine place recognition,of which the necessity and advantages lie in implementing retrieval in the latent feature space with self-supervised attentive information without any human effort or laborious annotations.
B.Disentanglement Representation
Latent representation reveals the feature vectors in the latent space which determine the distribution of samples.Therefore,it is essential to find the latent disentangled representation to analyze the attributes of data distribution.A similar application is the latent factor model (LFM) in recommender systems [52]–[54],where the latent factor contributes to the preference of specific users.In the field of style transfer or image translation [37],[55],deep representations of images are modeled according to the variations of data which depend on different factors across domains [56],[57],e.g.,disentangled content and style representation.Supervised approaches [58],[59] learn class-specific representations through labeled data,and many works have appeared to learn disentangled representation in unsupervised manners [60],[61].Recently,fully-and partially-shared representation of latent space have been investigated for unsupervised image-to-image translation [39],[40].Inspired by these methods,where the content code is shared across all the domains but the style code is domain-specific,our domain-invariant representation learning is probabilistically formulated and modeled as an extended and modified version of CycleGAN [44] or ComboGAN [38].
For the application of representation learning in place recognition under changing environments,where each environmental condition corresponds to one domain style and the images share similar scene content across different environments,it is appropriate to make the assumption of disentangled representation to this problem case.Recent works for condition-invariant deep representation learning [5],[62]–[64] in long-term changing environments mainly rely on variance-removal or other auxiliary information introduced in Section II-A.Reference [17] removes the dimension related to the changing condition through PCA for the deep embeddings of latent space through classification model.Reference [12]separates the condition-invariant representation from VLAD features with GANs across multiple domains.Reference [65]filters the distracting feature maps in the shallow CNNs but matches with deep features in deeper CNNs to improve condition-and viewpoint-invariance [66] using image pairs.Compared to these two-stage or supervised methods,we adopt domain-invariant feature learning methods [63],[64] which possess advantages on direct,low-cost,and efficient learning.
C.Contrastive Learning
Contrastive learning,a.k.a.,deep metric learning [14],[67]stems from distance metric learning [68],[69] in machine learning but extracts deep features through deep neural networks,i.e.,learning appropriate embeddings and metrics for effective discrimination between similar sample pairs and different sample pairs.With the help of neural networks,deep metric learning typically utilizes siamese networks [70],[71]or triplet networks [72],[73],which makes the embedding of same category closer than that of different category with triple labeled input samples for face recognition,human reidentification,etc.
Coming to long-term place recognition and visual localization,many works have recently used supervised learning together with siamese networks and triplet loss [18],[62].To avoid vanishing gradient of small distance from different pairs with triplet loss form [14],[15] proposes another form of triplet loss.Due to the hard-annotated data for supervised learning,Radenovićet al.[19] proposes to leverage geometry of 3D model from structure-from-motion(SfM) for triplet learning in an automated manner.But SfM is off-line and costly,so it is not possible for end-to-end training.Instead we employ an unsupervised triplet training technique adapted to the DIFL framework [63] so that domain-invariant and scene-specific representation can be trained in an unsupervised and end-to-end way efficiently.
III.FORMULATION OF DOMAIN-INVARIANT FEATURE LEARNING
A.Problem Assumptions
Our approach to long-term visual place localization and recognition is modeled in the setting of multi-domain unsupervised image-to-image translation,where all query and database images are captured from multiple identical sequences across environments.Images in different environmental conditions belong to corresponding domains respectively.Let the total number of domains be denoted asNand two different domains are randomly sampled from{1,...,N}for each translation iteration,e.g.,i,j∈{1,...,N},i≠j.Letxi∈Xiandxj∈Xjrepresent images from these two domains.For the multi-domain image-to-image translation task [38],the goal is to find all conditional distributionsp(xi|xj),∀i≠j,i,j∈{1,...,N}with known marginal distribution ofp(xi),p(xj),and translated conditional distributionp(xj→i|xj),p(xi→j|xi).Since different domains correspond to different environmental conditions,we suppose the conditional distributionp(xi|xj) is monomodal and deterministic compared to multimodal distribution across only two domains in [40].AsNincreases to infinity and becomes continuous,the multi-domain translation model covers more domains and can be regarded as a generalized multi-modal translation with limited domains.
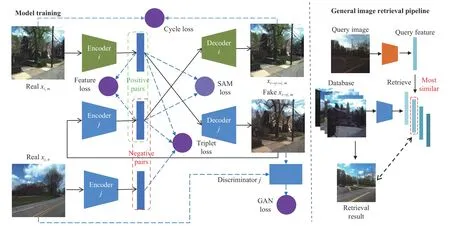
Fig.2.The architecture overview for model training from domain i to j and general image retrieval pipeline while testing.The involved losses include GAN loss,cycle loss and feature loss,SAM loss,and triplet loss.Note that SAM loss are only used for fine model and the encoder,decoder and discriminator are specific for each domain.
Like the shared-latent-space assumption in the recent unsupervised image-to-image translation methods [39],[40],the content representationcis shared across different domains while the style latent variablesibelongs to each specific domain.For the image joint distribution in one domainxi∈Xi,it is generated from the prior distribution of content and style,xi=Gi(si,c),and the content and style are independent of each other.Since the condition distributionp(xi|xj)is deterministic,the style variable is only embodied in the latent generator of the specific domain,i.e.,Under such assumptions,our method could be regarded as implicitly partially-shared,although only content latent code is explicitly found across multiple domains with corresponding generators.Following the previous work [40],we further assume that the domain-specific decoder functions for shared content code,are deterministic and their inverse encoder functions exist,whereAnd our goal of domain-invariant representation learning is to find the underlying decodersand encodersfor all the environmental domains through neural networks,so that the domain-invariant latent codeccould be extracted for any given image samplexithroughc=The overview architecture based on the assumption is shown in Fig.2,of which the details are introduced in the Sections III and IV.
B.Model Architecture
We adopt the multi-domain image-to-image translation architecture [38],which is an expansion of CycleGAN [44]from two domains to multiple domains.The generator networks in the framework are decoupled into domainspecific pairs of encodersand decodersfor any domaini.The encoder are the first half of the generator while the decoder is the second half for each domain.For image translation across multiple domains,the encoders and decoders can be randomly combined like manipulation of blocks.The discriminatorsDiare also domain-specific for domainiand optimized in adversarial training as well.The detailed architectures of encoder,decoder,and discriminator for each domain is the same as ComboGAN [38].Note that[63] applies the ComboGAN architecture for image retrieval with feature consistency loss,resulting in an effective selfsupervised retrieval-based localization method.However,in this section we further formulate the architecture in a probabilistic framework,combining the multi-domain image translation and domain-invariant representation learning.
For images in similar sequences under different environments,first suppose domaini,jar e selected randomlyxi,xjand images are denoted as .The basic framework DIFL is shown as Fig.3,including GAN loss,cycle consistency loss and feature consistency loss.For the image translation pass from domainito domainj,the latent feature is fir st encoded by encoderand then decoded by decoder.The translated image goes back through encoderand decoderto find the cycle consistency loss (1) [44].Also,the translated image goes through the discriminatorDjto find adversarial loss (2) [41].The pass from domainjto domainiis similar.
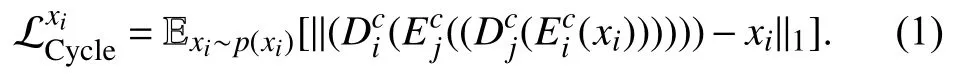
The adversarial loss (2) makes the translated imagexi→jindistinguishable from the real imagexjand the distribution of translated images close to the distribution of real images.
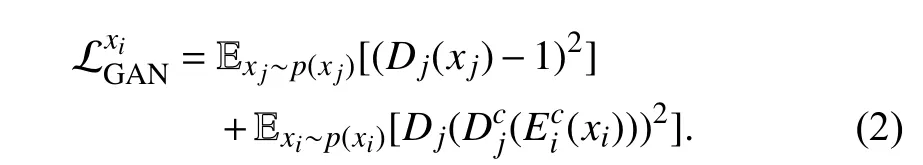
The cycle consistency loss (1) originates from CycleGAN[44],which has been proved to infer deterministic translation[40] and is suitable for representation learning through image translation among multiple domains.For the pure multidomain image translation task,i.e.,ComboGAN [38],the total ComboGAN loss only contains adversarial loss and cycle consistency loss.
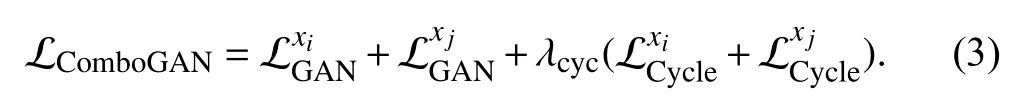
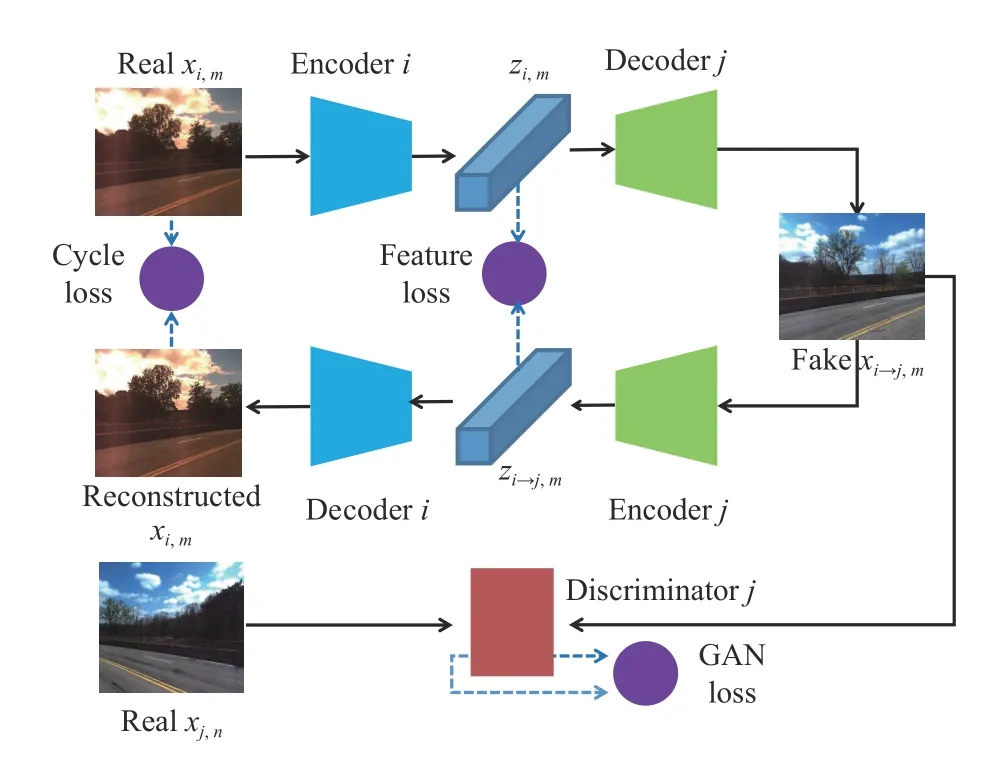
Fig.3.Network architecture for image translation from domain i to j.Constraint by GAN loss,cycle loss,and feature loss,the latent feature code is the domain-invariant representation.The discriminator D j results in GAN loss through adversarial training,given the real image of domain j and the translated image from domain i to j.
Since every domain owns a set of encoder,decoder,and discriminator,the total architecture is complicated and can be modeled through a probabilistic graph if all the encoders and decoders are regarded as conditional probability distribution.Supposing the optimality of ComboGAN loss (3) is reached,the complex forward propagation during training can be simplified and the representation embedding can be analyzed.
Without loss of generality,imagexi,m,xj,nare selected from image sequencesxi,xj,i≠j,wherem,nrepresent the places of the shared image sequences and only related to the content of images.According to the assumptions in Section III-A,m,nrepresent the shared domain-invariant content latent codecacross different domains.For the translation from imagexi,mto domainj,we have
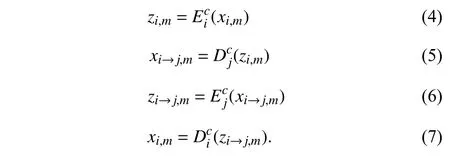
The latent codezi,mimplies the relationship of domainiand the content of imagemfrom (4).Due to the adversarial loss(2),the translated imagexi→j,mhas the same di stribution as imagexj,n,i.e.,xi→j,m,xj,n~p(xj).For the rec onstructed image from (7),the cycle consistency loss (1) limits it to the original image .xi,m
From (4) and (5),we have
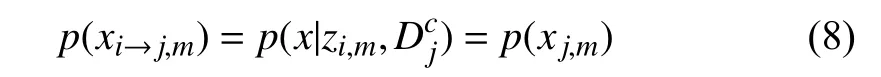
which indicatesxi→j,mandiare independent if theoptimality of adversarial loss (2) is reached,andzi→j,mandiare also independent from (6).Similarly,zi,mandjare independent for anyj≠i.Combining (5),(6) and (4),(7),we can find the relationship betweenzi,mandzi→j,mand the weak form of inverse constraint on encoders and decoders below:
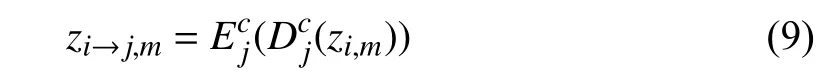
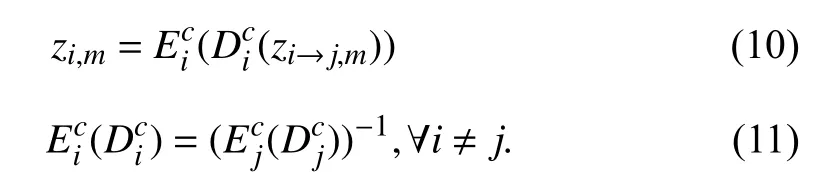
When the optimality of original ComboGAN loss (3) is reached,for anyi≠j,the latent codezi,mandzi→j,mare not related tojandi,respectively,which is consistent with the proposition that cycle consistency loss cannot infer sharedlatent learning in [39].Consequently,the representation embeddings are not domain-invariant and not appropriate for image retrieval,and the underlying inverse encoders and decoders have not been found through the vanilla ComboGAN image translation model.
C.Feature Consistency Loss
To obtain the shared-latent feature across different domains,unlike [39],we use an additional loss exerted on the latent space called the feature consistency loss as proposed in [63].Under the above assumptions,for imagexifrom domainiit is formulated as
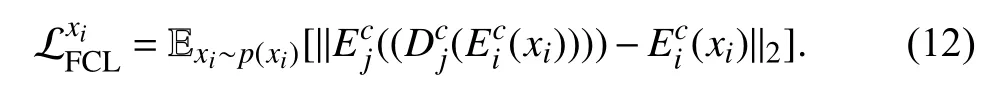
As a result,the domain-invariant feature [63] can be extracted by combining all the weighted losses together
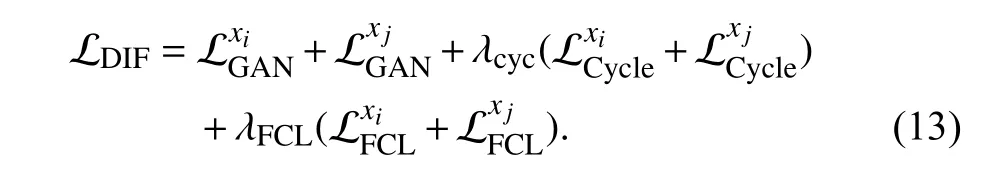
Here gives the theoretical analysis for FCL.Supposing the optimality of the DIF loss (13) is reached,(4)–(11) are still satisfied.Additionally,because of the feature consistency loss(12),based on (4),(6),(10),we have

Sincezi→j,mandiare independent (as discussed in the previous section),zi,mandiare independent for any domainifrom (14),which indicates that the latent feature is wellshared across multiple domains and represents the content latent code given any image from any domain.Furthermore,the trained encoders and decoders are inverse and the goal of finding underlying encodersand decodersis reached according to Section III-A.So it is appropriate to use the content latent code for image representation across different environmental conditions.
IV.COARSE-TO-FINE RETRIEVAL-BASED LOCALIZATION
A.Gradient-Weighted Similarity Activation Mapping Loss
The original domain-invariant feature (13) cannot excavate the context or localizing information of the content latent feature map;as a result the performance of place recognition under high accuracy is limited.To this end,we propose a novel gradient-weighted similarity activation mapping loss for shared-latent feature to fully discover the weighted similar area for high-accuracy retrieval.
Inspired by CAM [20],Grad-CAM [21],and Grad-CAM++[22] in visual explanation for classification with convolutional neural networks,we assume that the place recognition task can be regarded as an extension of image multi-classification with infinite target classes,where each database image represents a single target class for each query image during the retrieval process.Then,for each query image,the similarity to each database image is treated as the score before softmax or probability for multi-classification task and the one with the largest similarity is the retrieved result,which is similar to the classification result with the largest probability.
Ideally,suppose the identical content latent feature maps from domaini,j,zi,m,zj,m,have the shape ofn×h×w,where identical contentmis omitted for brevity.First the mean value of the cosine similarity on the height and width dimension is calculated below:
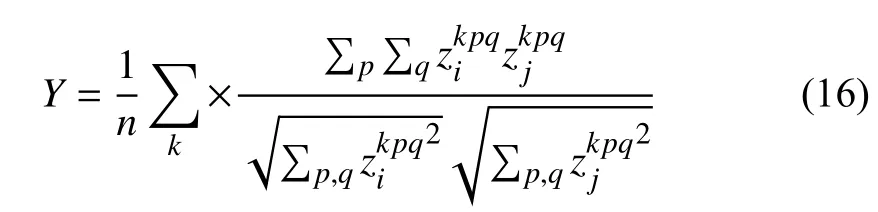
Yis the score of similarity betweenziandzj.Following the definition of Grad-CAM [21],we have the similarity activation weight and map:

Equations (17) and (18) are the mathematic formulation of the proposed Grad-SAM,where the activation map is aggregated by each gradient-weighted feature map,retaining the localizing information of the deep feature map.In order to only input the positively-activated areas for training,we exert aReLUfunction to obtain the final activation mapLi,jorLj,i.
Particularly,as shown in Fig.4,inside the unsupervised DIFL architecture,the content latent codeszi,m,zj,nare shared from the same distribution butzi,m≠zj,nfor the unpairedm≠n.The similarity activation mapLi,m,Li→j,mcould be visualized by resizing to the original size in Fig.4.According to FCL loss (12),zi,mandzi→j,mtend to be identical,which means that the calculation of similarity between them is meaningful and so is the SAM loss.Therefore,the selfsupervised Grad-SAM loss for domainicould be formulated below based on (16)–(18):
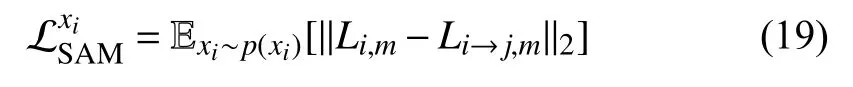
wherezi,mandzi→j,mare substituted intoziandzjin (16)–(18)andLi,mandLi→j,mare short forLi,j,mandLi→j,i,mderived from(17) and (18).
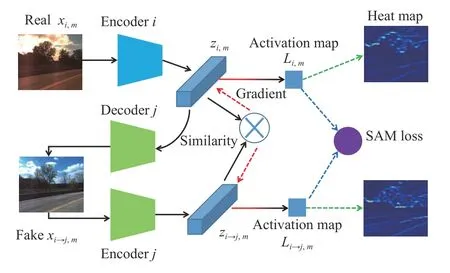
Fig.4.The illustration of one branch of SAM loss from domain i to j.The real image in domain i is first translated to fake image in domain j,and the gradient of similarity w.r.t.each other could be calculated,denoted as red dashed lines.And then the activation map is the sum of feature map weighted by the gradient,shown as color-gradient line from red to black,and SAM loss could be calculated in a self-supervised manner.Note that the notation of Li,m and L i→j,m here are short for L i,j,m and L i→j,i,m derived from (17) and (18).
B.Adaptive Triplet Loss
Though the domain-invariant feature learning is obtained through feature consistency loss (12) and Grad-SAM loss (19)is for further finer retrieval with salient localizing information on the latent feature map,it is difficult to distinguish different latent content codes using domain-invariant features without explicit metric learning.As the distance of the latent features with the same content is decreasing due to feature consistency loss (12) and Grad-SAM loss (19),the distance of latent features for different contents may be forced to diminish as well,resulting in mismatched retrievals for test images in long-term visual localization.
Toward this end,we propose a novel adaptive triplet loss based on feature consistency loss (12) and Grad-SAM loss(19) to improve the contrastive learning of the latent representation inside the self-supervised DIFL framework.Suppose unpaired imagesxi,m,xj,nare selected from domaini,j,i≠j,wherem,nrepresent the content of images.Note that for the purpose of unsupervised training pipelines,one of the selected image is horizontally flipped while the other is not so thatm≠nis assured for the negative pair.The operation of flipping only one of the input images is random and also functions as data augmentation due to the fact that the flipped images follow the distribution of original images.Details could be found in Section V-A.For the self-supervised contrastive learning,the positively paired samples are not given but generated from the framework in (4)–(6) and(16)–(18),i.e.,zi,m,zi→j,mandLi,m,Li→j,m.For the negatively paired samples,for the sake of the fact that the images under the same environmental condition tend to be closer than ones under different conditions,the stricter constraint is implemented for negative pairs with the translated image and the other real image,which are under the same environment but different places,i.e.,zi→j,m,zj,nandLi→j,m,Lj,n.
Moreover,in order to improve the efficiency of the triplet loss for representation learning during the late iterations,the negative pair with the least distance between the original and the translated one is automatically selected as the hard negative pairfrom a group of random negative candidates Zj,nor Lj,n,shown as (20) and (21).The adaptive triplet loss is calculated through these hard negative pairs without any supervision or extra priority information.
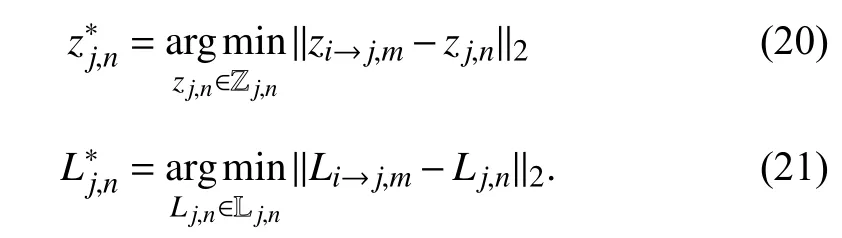
We adopt the basic form of triplet loss from [15],but themargindepends on the feature consistency loss (12) or Grad-SAM loss (19),which adapts to the representation learning of(12) or (19).The illustrations of the adaptive triplet loss for FCL and SAM are shown in Figs.5 and 6.The adaptive triplet loss for FCL and Grad-SAM for domainiis shown below:
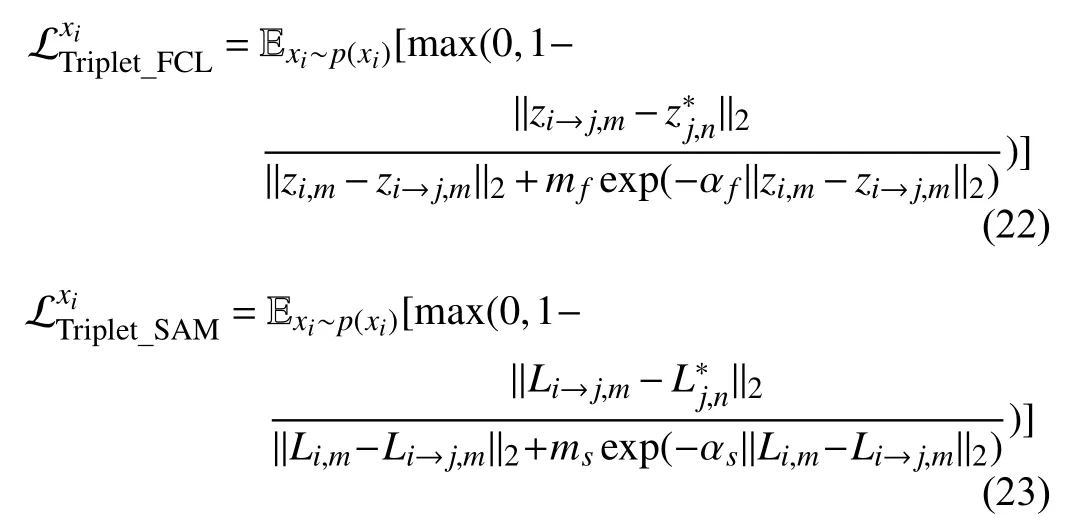
where hyperparametersmf,msare themargin,which is the value that the distance of negative pairs exceeds the distance of self-generated positive pairs when the image translation is well trained,i.e.,p(xi→j,m)=p(xj,m).However constantmarginhas an influence on the joint model training with FCL or Grad-SAM loss,so we propose the self-adaptive term,which is the exponent function of negative FCL loss or Grad-SAM loss weighted by αfor αs.
Combining with the adaptive triplet loss (22) or (23),in the beginning of the whole model training,the exponential adaptive term is close to 0 so the triplet loss term does not affect the FCL (12) or Grad-SAM (19).But as the training process goes by,the triplet loss would dominate the model training since the exponential adaptive term becomes larger and closer to 1.
C.Coarse-to-Fine Image Retrieval Pipeline
Different applications have different requirements for coarse-or high-precision localization,e.g.,loop closure and relocalization in SLAM and 3D reconstruction.As shown in the Section III-C,the feature consistency loss together with the cycle consistency loss and GAN loss in image-to-image translation contribute to the domain-invariant representation learning architecture,where the latent feature is independent of the multiple environmental domains so that the feature could be used for image representation and retrieval across different environments.While the Grad-SAM loss in Section IV-A is incorporated to the basic architecture for the purpose of learning salient area and attentive information from the original latent feature,which is important to the highprecision retrieval.The adaptive triplet loss in Section IV-B can balance the self-supervised representation learning and feature consistency loss,which improves the retrieval results through ablation studies in Section V-D.
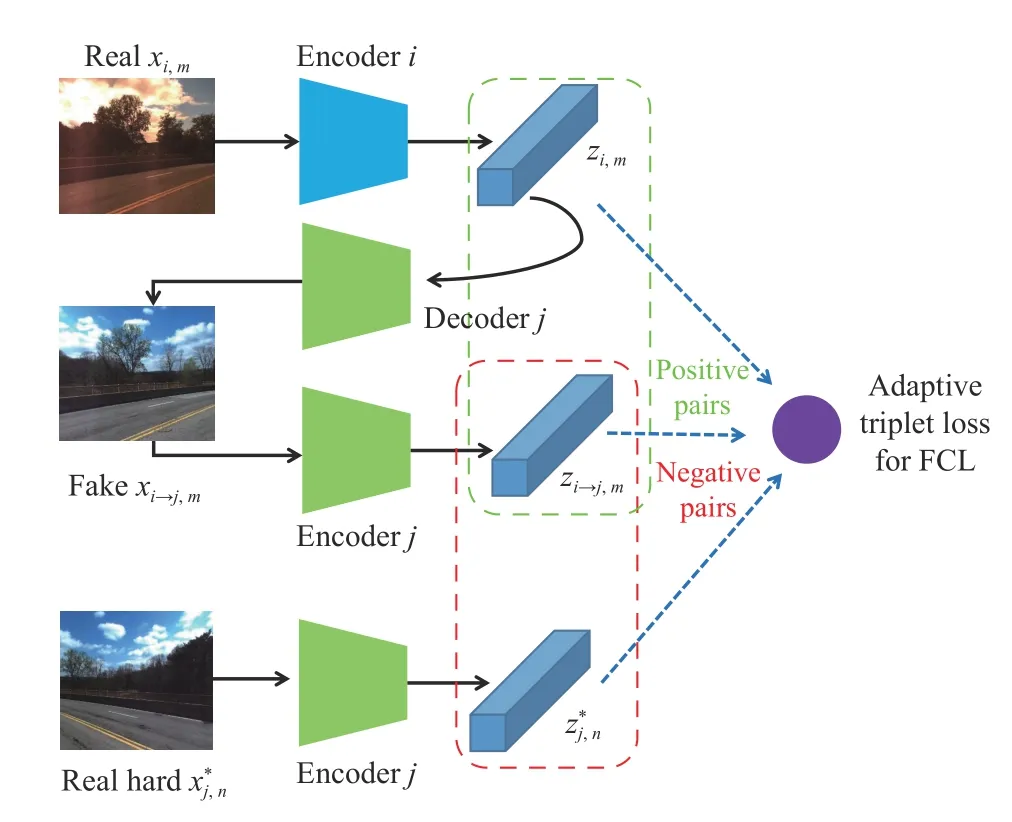
Fig.5.The illustration of one-branch adaptive triplet loss for FCL from domain i to j.The inputs of the loss are the encoded latent features from real images in domain i,j and the translated image i →j,resulting in the negative pairs with the red dashed box and the positive pairs with the green dashed box.Note that positive pairs only differ in the environment while the place is the only difference for the negative pairs.
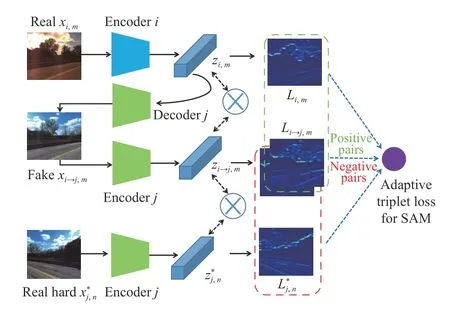
Fig.6.The illustration of one-branch adaptive triplet loss for Grad-SAM from domain i to j.The inputs of the loss are the similarity activation maps from real images in domain i,j and the translated image i →j.The negative pairs are bounded with the red dashed box while the positive pairs are bounded with the green dashed box.Note that the activation maps in domaini from two pairs are slightly different.
For the image retrieval,we adopt the coarse-to-fine strategy to fully leverage the models with different training settings for different specific purposes.The DIFL model with FCL (12)and triplet loss (22) aims to find the database retrieval for the query image using general domain-invariant features and results in better performance of localization within larger error thresholds,shown in Section V-D,which gives a good initialrange of retrieved candidates and can be used as a coarse retrieval.

TABLE IABLATION STUDY ON DIFFERENT STRATEGIES AND LOSS TERMS
The total loss for coarse-retrieval model training is shown below:
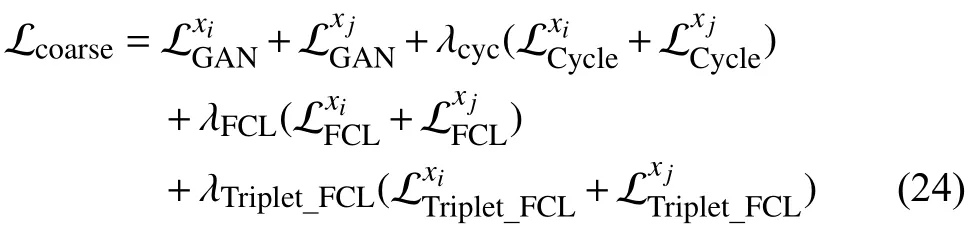
where λcyc,λFCL,and λTriplet_FCLare the hyperparameters to weigh different loss terms.
Furthermore,to obtain the finer retrieval results,we incorporate the Grad-SAM (19) with its triplet loss (23) into the coarse-retrieval model,which fully digs out the localizing information of feature map and promotes the high-accuracy retrieval across different conditions shown in Table I.However,according to Section V-D,the accuracy of lowprecision localization for fine-retrieval model is lower than the coarse-retrieval model,which shows the initial necessity of the coarse retrieval.The total loss for the finer model training is shown below:

where λcyc,λFCL,λSAM,λTriplet_SAM,and λTriplet_FCLare the hyperparameters for each loss term.
Once the coarse and fine models are trained,the test pipeline contains coarse retrieval and finer retrieval.The 6-DoF poses of database images are given while the goal is to find the poses of query images.We first pre-encode each database image under the reference environment into feature maps through coarse model off line,forming the database of coarse features.While testing,for every query image,we extract the feature map using coarse encoder of the corresponding domain and retrieve thetop-Nmost similar ones from pre-encoded coarse features in the database.TheNcandidates are then encoded through the fine model to find the secondary feature maps,and the query image is also encoded through the fine model to find the query feature.The most similar one in theNcandidates is retrieved as the final result for localization.Although the coarse-to-fine strategy may not get the most similar retrieval globally in some cases,it will increase the accuracy within coarse error in Section V-D compared to the only single fine model,which is beneficial to the application of pose regression for relocalization.It may also benefit from the filtered coarse candidates in some cases,as in Table I,to improve medium-precision results.The 6-DoF pose of query image is the same as the finally-retrieved one in the database.
V.ExPERIMENTAL RESULTS
We conduct a series of experiments on CMU-Seasons dataset and validate the effectiveness of coarse-to-fine pipelines with the proposed FCL loss,Grad-SAM loss and adaptive triplet loss.With the model only trained on the urban parts of the CMU seasons dataset in an unsupervised manner,we compare our results with several image-based localization baselines on the untrained suburban and park parts of the CMU-Seasons dataset and RobotCar-Seasons dataset,showing the advantage under scenes with massive vegetation and robustness to huge illumination change.To prove the practical validity and applicability for mobile robotics,we have also conducted real-site field experiments under different environments with more angles using a mobile robot with camera and RTK-GPS.We conduct these experiments on two NVIDIA 2080Ti cards with 64 G RAM on Ubuntu 18.04 system.Our source code and pre-trained models are available on https://github.com/HanjiangHu/DISAM.
A.Experimental Setup
The first series of experiments are conducted on the CMUSeasons dataset [9],which is derived from the CMU Visual Localization [75] dataset.It was recorded by a vehicle with left-side and right-side cameras over a year along a route roughly 9 kilometers long in Pittsburgh,U.S.The environmental change of seasons,illumination,and especially foliage is very challenging on this dataset.Reference [9] benchmarks the dataset and presents the groudtruth of camera pose only for the reference database images,adding new categories and area divisions of the original dataset as well.There are 31 250 images in 7 slices for urban area,13 736 images in 3 slices for suburban area,and 30 349 images in 7 slices for park area.Each area has only one reference and eleven query environmental conditions.The condition of database isSunny+No Foliage,and conditions of query images could be any weather intersected with vegetation condition,e.g.,Overcast+Mixed Foliage.Since the images in the training dataset contain both left-side and right-side ones,the operation of flipping horizontally is reasonable and acceptable for the unsupervised generation of negative pairs and data augmentation,as introduced in Section IV-B.
The second series of experiments are conducted on RobotCar-Seasons dataset [9] derived from Oxford RobotCar dataset [76].The images were captured with three Point Grey Grasshopper2 cameras on the left,rear,and right of the vehicle along a 10 km route under changing weather,season,and illumination across a year in Oxford,U.K.It contains 6 95 4 triplets for database images under overcast condition,3 100 triplets for day-time query images under 7 conditions,and 878 triplets for night-time images under 2 conditions.In the experiment we only test rear images with the pre-trained model on the urban part of CMU-Seasons dataset to validate the generalization ability of our approach.Considering that not all conditions of RoborCar datasets have exactly corresponding conditions in CMU-Seasons,we choose the pre-trained models under the conditions with the most similar descriptions and dates from CMU-Seasons dataset for all the conditions in RobotCar dataset listed in Table II.Note that for the conditions which are not included in CMU-Seasons,we usethe pre-trained models under the reference condition instead,Overcast+Mixed Foliage,for the sake of fairness.
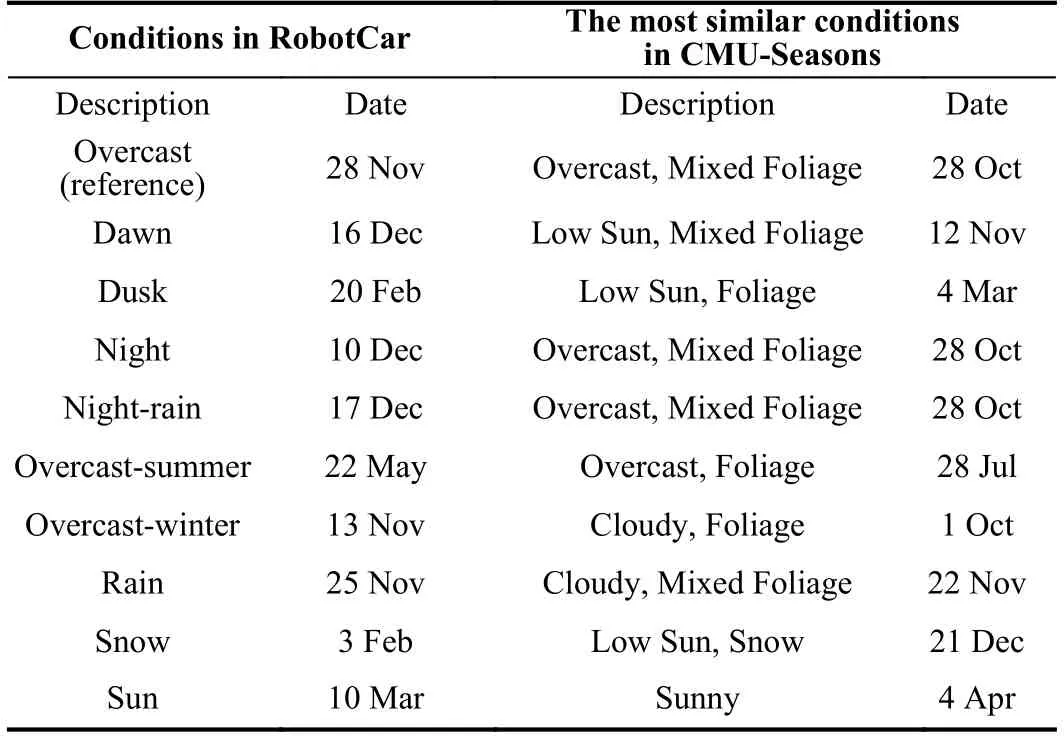
TABLE IICONDITION CORRESPONDENCE FOR ROBORCAR DATASET
The images are scaled to 286×286 and cropped to 256×256randomly while training but directly scaled to 256×256while testing,leading to a feature map with the shape of 256×64×64.We follow the protocol introduced in[9] which is the percentage of correctly-localized query images.Since we only focus on high and medium precision,the pose error thresholds are (0.25 m,2°) and (0.5 m,5°) while coarse-precision (low-precision) (5 m,10°) is omitted for the purpose of high-precision localization except for the ablation study.We choose several image-based localization methods FAB-MAP [74],DIFL-FCL [63],NetVLAD [4],and Dense-VLAD [6],which are the best image-based localization methods.
B.Evaluation on CMU-Seasons Dataset
Following the transfer learning strategy for DIFL in [63],we fine-tune the pre-trained models in [63] at epoch 300 which are trained only with cycle consistency loss and GAN loss under all the images from the CMU-Seasons dataset for pure image translation task.Then,for the representation learning task,the model is fine-tuned with images from Urban areas in an unsupervised manner,without paired images across conditions.After adding the other loss terms in (24) or(25),we continue to train until epoch 600,with a learning rate linearly decreasing from 0.000 2 to 0.Then the model is trained in the same manner until epoch 1 200 with split 300 epochs.In order to speed up and stabilize the training process with triplet loss,we use the random negative pairs from epoch 300 to epoch 600 for the fundamental representation learning and adopt the hard negative pairs from epoch 600,as shown in Section IV-B.We choose the hard negative pair from 10 pairs of negative samples for each iteration.
For the coarse-retrieval model training,the weight hyperparameter are maximumly set as λcyc=10,λFCL=0.1,and λTriplet_FCL=1,which are all linearly increasing from 0 as the training process goes by to balance the multi-task framework.Similarly for the fine-retrieval model training,we set λcyc=10,λFCL=0.1,λSAM=1000,λTriplet_SAM=1,and λTriplet_FCL=1with a similar training strategy.The fine model consists of the metrics of bothL2 andcosine similarityfor FCL terms while onlyL2 metric is used in the coarse model for FCL terms.For the adaptive triplet loss,we setmf=5,αf=2 in triplet FCL loss (22) andms=0.1,αs=1000 in triplet SAM loss (23).And during the two-stage retrieval,the number of coarse candidatestop-Nis set to be 3,which makes it both efficient and effective.In the two-stage retrieval pipeline,we use the mean value of thecosine similarityon the height and width dimension as the metric during the coarse retrieval,as shown in (16).For the fine retrieval,we use the normalcosine similarityfor the flatten secondary features due to the salient information in the feature map.
Our final result is compared with baselines shown as Table III,which shows that ours outperforms baseline methods for highand medium-precision localization,(0.25 m,2°) and(0.5 m,5°),in park and suburban area,which shows powerful generalization ability because the model is only trained on theurban area.The medium-precision localization in the urban area is affected by numerous dynamic objects.We further compare the performance on different foliage categories from[9],FoliageandMixed Foliagewith the reference database underNo Foliage,which is the most challenging problem for this dataset.The results are shown in Table IV,from which we can see that our result is better than baselines under different conditions of foliage for the localization with medium and high precision.To investigate the performance under different weather conditions,we compare the models with baselines on theOvercast,Cloudy,andLow Sunconditions with the reference database underSunnyin Table V,which covers almost all the weather conditions.It could be seen that our results present the best medium-and highaccuracy results on most of the weather conditions.TheCloudyweather contains plenty of clouds in the sky,which provides some noise in the activation map for fine retrieval with reference to the clear sky underSunny,which could be regarded as a kind of dynamic objects.
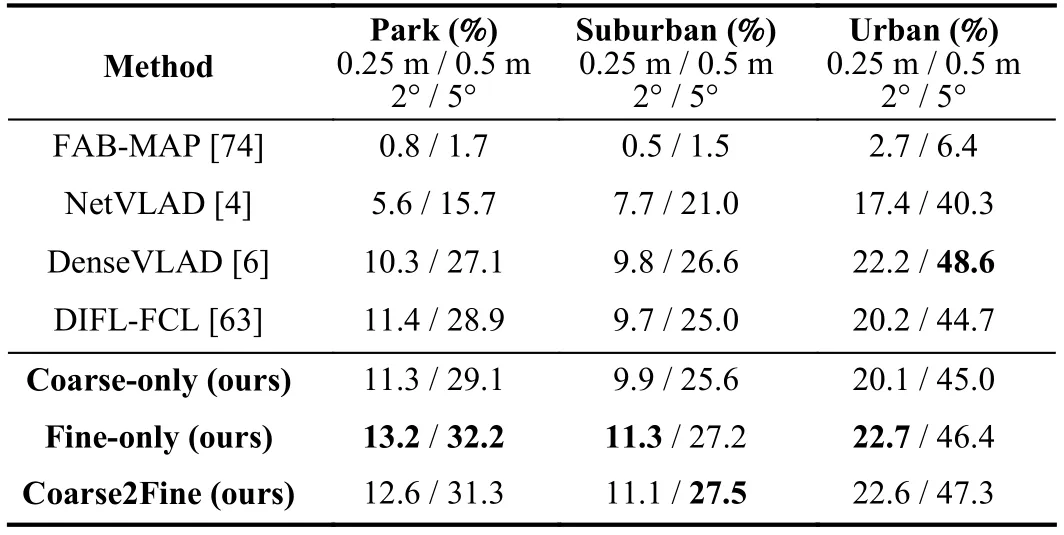
TABLE IIIRESULTS COMPARISON TO BASELINES ON CMU-SEASONS DATASET
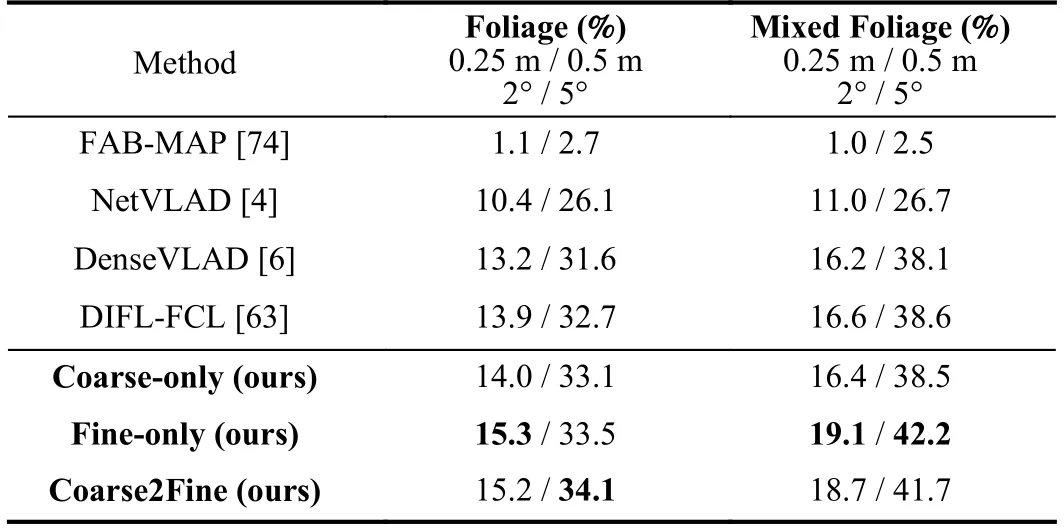
TABLE IVCOMPARISON WITH BASELINES ON FOLIAGE CONDITION REFERENCE IS NO FOLIAGE
From the results of different areas,vegetation,and weather,it can be seen that the finer retrieval boosts the results of coarse retrieval.Moreover,the coarse-to-fine retrieval strategy gives better performance than the fine-only method in some cases,showing the significance and effectiveness for highand medium-precision localization of the two-stage strategy.The reasonable explanation for the good performance under different foliage and weather conditions lies in that the latent content code is robust and invariant for changing vegetation and illumination.All the results (including ours) are from theofficial benchmark website of long-term visual localization[9].Some results of fine-retrieval are shown in Fig.7,where the activation maps give the localizing information of feature maps and the salient areas mostly exist around the edges or adjacent parts of different instance patches due to the gradient-based activation.
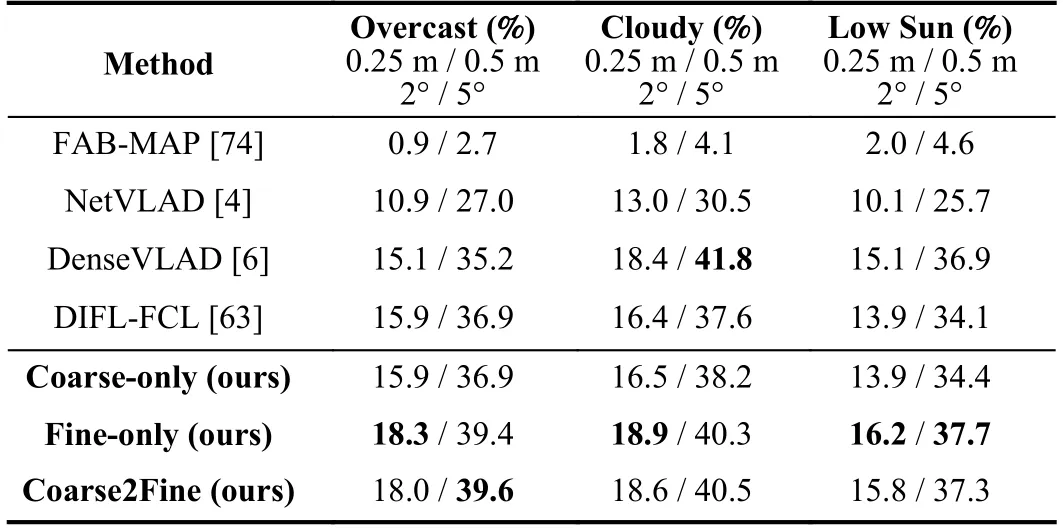
TABLE VCOMPARISON WITH BASELINES ON WEATHER CONDITION REFERENCE IS SUNNY
C.Evaluation on RobotCar Dataset
In order to further validate the generalization ability of our proposed method to the unseen scenarios,we directly use the pre-trained models on urban area of CMU-Seasons to test on the RobotCar dataset,according to the correspondent condition from CMU-Seasons for every query condition of RobotCar based on Table II.Considering the database images are much more than query images under each condition,the two-stage strategy is skipped for practicality and efficiency,only testing coarse-only and fine-only models.The metric for both coarse and fine retrieval is the mean value of thecosine similarityon the height and width dimension as shown in (16).
The comparison results are shown in Table VI,where we can see that our method outperforms other baseline methods under theNightandNight-rainconditions.Note that the model we use for the night-time retrieval is the same as the database because night-time images are not included in the training set,showing the effectiveness of the representation learning in the latent space form autoencoder-structured model.Since the images underNightandNight-rainconditions have too poor context or localizing information to find the correct similarity activation maps,the coarse model performs better than the finer model.
Our results under all theDayconditions are the best for high-precision performance,showing the powerful generalization ability in the unknown scenarios and environments through attaining satisfactory retrieval-based localization results.All the results (including ours) are also from the official benchmark website of long-term visual localization[9].Some day-time results are shown in Fig.8,including all the environments which have similar ones among pre-trained models on CMU-Seasons dataset.
D.Ablation Study

Fig.7.Results on CMU-Seasons dataset.For each set of images in (a) to (e),the top left is the query image while the top right is the database image under the condition of Sunny+No Foliage.The query images of set (a) to (e) are under the conditions of Low Sun+Mixed Foliage,Overcast+Mixed Foliage,Low Sun+Snow,Low Sun+Foliage and Sunny+Foliage,respectively.The visualizations of similarity activation maps are on the bottom row for all the query or database RGB images.
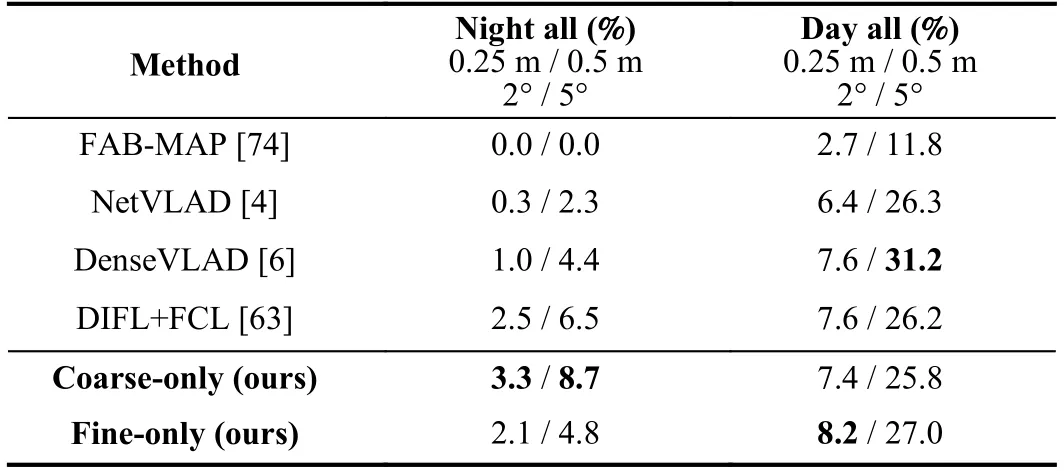
TABLE VIRESULTS COMPARISON TO BASELINES ON ROBOTCAR DATASET
For the further ablation study in Table I,we implement different strategies (Coarse-only,Fine-only,andCoarse-to-fine) and different loss terms (FCL,Triplet FCL,SAM,andTriplet SAM) during model training,and test them on CMUSeasons dataset.The only difference betweenCoarse-onlyandFine-onlylies in whether the model is trained withSAMor not,while coarse-to-fine strategy follows the two-stage strategy in Section IV-C.It could be seen thatCoarse-onlymodels perform the best in low-precision localization,which is suitable to provide the rough candidates for the upcoming finer retrieval.With the incorporation ofSAM-related loss,the medium-and high-precision accuracies increase while the low-precision one decreases.TheCoarse-to-finecombines the advantages ofCoarse-onlyandFine-onlytogether,improving the low-precision localization of fine models as well as the medium-and high-precision localization of coarse models simultaneously,which shows the effectiveness and significance of the two-stage strategy by overcoming both the weaknesses.Furthermore,because of the high-quality potential candidates provided byCoarse-onlymodel,some medium-precision results ofCoarse-to-fineon the last row perform the best and other results are extremely close the best ones,which shows the promising performance of the twostage strategy.
From the first two rows ofCoarse-onlyandFine-onlyin Table I,theFlipped Negativeand theHard Negativesamples are shown to be necessary and beneficial to the final results,especially for the flipping operation for data augmentation.On the third and fourth row,the DIFL with FCL performs better than vanilla ComboGAN (3),which indicates that FCL assists to extract the domain-invariant feature.Due to the effective self-supervised triplet loss with hard negative pairs,the performance withTriplet FCLorTriplet SAMis significantly improved compared with the results on the fourth or ninth row,respectively.To validate the effectiveness ofAdaptive Marginin triplet loss,we compare the results ofConstant MarginandAdaptive Margin,which show that the model with adaptive margin gives better results than that with constant margin for bothTriplet FCLandTriplet SAM.The last row inFine-onlystrategy shows the hybrid adaptive triplet losses of both FCL and SAM are beneficial to the fine retrieval.Note that the settings of training and testing for Table I are consistent internally,but are slightly different from the experimental settings in the [63] in many aspects,like training epochs,the metrics for retrieval,the choice of the pre-trained models for testing,etc.Also,the adaptive margin for triplet loss is partially influenced by the hard negative samples,because the less distance of negative pairs means relatively less margin to positive pairs which reduce the positive distance and the adaptive margin increases consequently.

Fig.8.Results on RobotCar dataset.For each set of images in (a) to (e),the top left is the day-time query image while the top right is the database image under the condition of Overcast.The query images of set (a) to (e) are under the conditions of Dawn,Overcast-summer,Overcast-winter,Snow and Sun,respectively.The visualizations of similarity activation maps are on the bottom row for all the query or database RGB images.
E.Real-Site Experiment
For the real-site experiment,the dataset is collected through an AGV with ZED Stereo Camera and RTK-GPS,and mobile robot is shown as Fig.9(a).The routine we choose is around the Lawn besides the School Building on the campus,which is around 2 km and is shown in Fig.9(b).We collect different environments including the weather,daytime,and illumination changes,as classify them asSunny,Overcast,andNight,respectively.There are 12 typical places as key frames with 25 different angles of view point for challenging localization,marked in red circles in Fig.9(b),compensating the single perspective of driving scenes in both CMU-Seasons and Oxford RobotCar dataset.There are 300 images for each environment and some samples of the dataset are shown as Fig.10.The same places along the routes are mainly within the distance of 5 m,which acts as the 25 groundtruth images of place recognition from GPS data.

Fig.9.Image (a) shows the mobile robot used to collect dataset with RTKGPS and ZED Stereo Camera.Image (b) shows the routines of the dataset under changing environments,illustrated in different colored lines and the red circles indicate the 12 typical places for recognition and retrieval with different perspectives.
Since all three environments are during autumn,we use the CMU-Seasons pretrained models underLow Sun+Mixed FoliageforSunny,Overcast+Mixed FoliageforOvercast,andCloudy+Mixed FoliageforNightin the experiments.The three place recognition experiments are query images underSunnywith database underOvercast,query images underSunnywith database underNight,and query images underNightwith database underOvercast.

Fig.10.Dataset images for real-site experiment.Column (a) is Sunny,Column (b) is Overvast,and Column (c) is Night.The first and last two rows show the changing perspectives,which gives more image candidates for the typical places.
For each query image,we retrieve Top-Ncandidates (Nfrom 1 to 25) from the database and calculate average recall rate to demonstrate the performance of the coarse-only and fine-only methods.For the coarse-to-fine method,first the coarse-only model retrieves the Top-2Ncandidates (2Nfrom 2 to 50) and then the fine-only model retrieves finer Top-Ncandidates (Nfrom 1 to 25) from them,the average recall is calculated over all the query images.
As shown in the Fig.11,the results of three proposed methods are validated under three different retrieval environmental settings.From the results,it can be seen that the coarse-only method performs better than the fine-only method in the large-scale place recognition,which is consistent with the results of coarse precision on CMUSeasons in Table I.Besides,the coarse-to-fine strategy obviously improves the performance of both coarse-only and fine-only methods,which shows that the effectiveness and applicability of the two-stage method.The coarse-to-fine performance within top 5 recall is limited by the performance of fine model,which is improved as the number of database retrieval candidates (N) increases.
Since time consumption is important for place recognition in robotic applications,we have measured the time cost of three proposed methods in the real-site experiment.As shown in Table VII,the average time of inference is to extract the feature representation through encoder while the average time of retrieval is to retrieve top 25 out of 300 database candidates through brute-force searching in the real-site experiment.By comparing the three methods,it could be seen that although the inference time of coarse-to-fine is almost the sum of coarse-only and fine-only,the time consumption is short enough for representation extraction.For brute-force retrieval,the time of coarse-to-fine is a little bit larger than the coarseonly and fine-only methods because the second finer-retrieval stage only find top 25 out of 50 coarse candidates,which costs much less time.Note that the retrieval time cost could be significantly reduced through other ways of search,like KDtree instead of brute-force search,but these techniques are beyond the focus of this work so Table VII only gives relative time comparison of the three proposed strategies,validating the time-efficiency and effectiveness of the two-stage method.
VI.CONCLUSION
In this work,we have formulated a domain-invariant feature learning architecture for long-term retrieval-based localization with feature consistency loss (FCL).Then a novel loss based on gradient-weighted similarity activation map (Grad-SAM) is proposed for the improvement of high-precision performance.The adaptive triplet loss based on FCL loss or Grad-SAM loss is incorporated to the framework to form the coarse or fine retrieval methods,resulting in the coarse-to-fine testing pipeline.Our proposed method is also compared with several state-of-the-art image-based localization baselines on CMUSeasons and RobotCar-Seasons dataset,where our results outperform the baseline methods for image retrieval in medium-and high-precision localization in challenging environments.Real-site experiment validate the efficiency and effectiveness of the proposed further.However,there are a few concerns about our method that the performance under the dynamic scenes is weak compared to other image-based methods,which can be addressed by adding semantic information to enhance the robustness to dynamic objects in the future.Another concern lies in the unified model for robust visual localization where the front-end network collaborate with representation learning better.
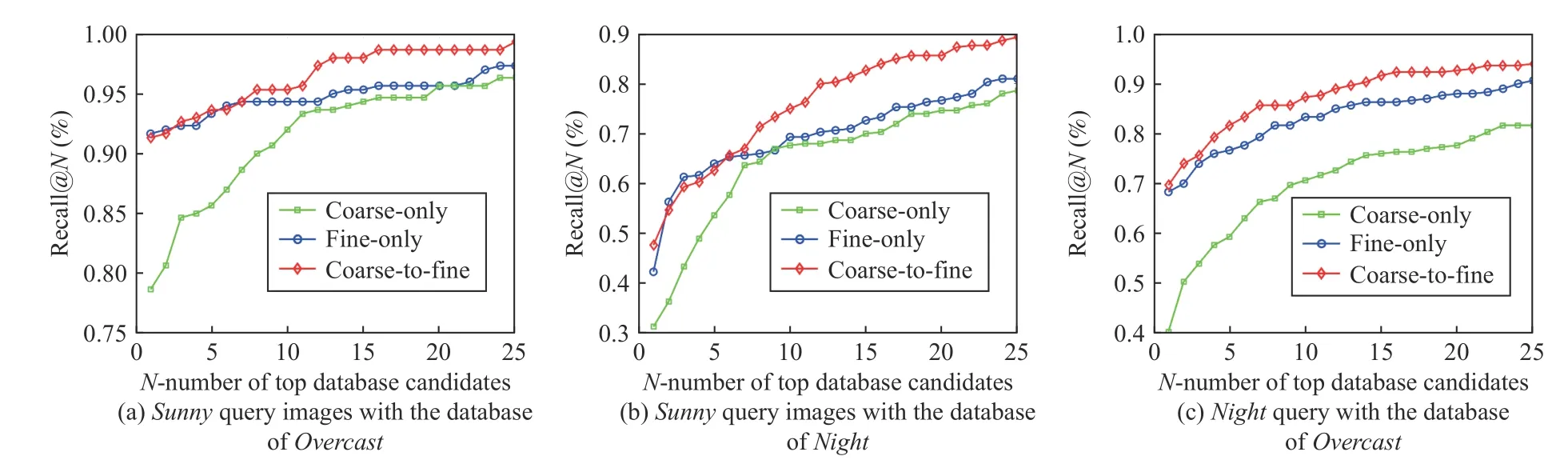
Fig.11.Results of the real site experiment.(a) is the result of Sunny query images with the database of Overcast;(b) is the result of Sunny query images with the database of Night;(c) is the result of Night query images with the database of Overcast.

TABLE VIITIME CONSUMPTION OF DIFFERENT METHODS
ACKNOWLEDGMENT
The authors would like to thank Zhijian Qiao from Department of Automation at Shanghai Jiao Tong University for his contribution to the real-site experiments including the collection of dataset and the comparison experiments.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Sampling Methods for Efficient Training of Graph Convolutional Networks:A Survey
- Fault Accommodation for a Class of Nonlinear Uncertain Systems With Event-Triggered Input
- Precise Agriculture:Effective Deep Learning Strategies to Detect Pest Insects
- Maximizing Convergence Speed for Second Order Consensus in Leaderless Multi-Agent Systems
- Exponential Set-Point Stabilization of Underactuated Vehicles Moving in Three-Dimensional Space
- An Adaptive Rapidly-Exploring Random Tree