结合学生行为模式分析的成绩早期预警研究
2022-01-22张明焱
张明焱,杜 旭,李 浩
华中师范大学国家数字化学习工程技术研究中心,武汉 430079
在线学习已成为当今教育系统中必不可少的学习方式,通过分析学生的在线学习行为以支持相关的教学决策或触发相应的教学干预[1-2]吸引了大量的研究工作[3]。该研究领域也被称为学习分析(learning analysis)。早期预警(early warning)是学习分析领域中的一个热门主题[4]。早期预警通过构建预测模型在学期较早阶段预测学生的最终成绩,以识别出尽可能多的不及格风险(简称at-risk)学生,方便教师在学期结束前采取干预措施,最终降低学生不及格的比例[5]。但仅识别出at-risk学生无法帮助教师采取有针对性的干预措施。已有的研究表明,识别关键预测因子,找出造成at-risk的因素对于教师采取针对性的教学干预措施意义重大[6-7]。因此,早期预警的核心问题是:(1)提高at-risk学生的识别率;(2)确定合适的干预时间点;(3)提供有效的干预信息。
国内外学者都对早期预警进行了研究。Wang 等人[8]利用改进的Apriori算法对学生成绩数据进行分析,找出数据中隐藏的课程关联规则,然后将这些规则应用于学生成绩预警,及时找出可能出现不及格的课程,并对部分学生给出警示,加强学习监督。Akçapınar等人[9]使用学生阅读电子书的数据和机器学习模型预测学生最终成绩。为了确定采取干预措施所需的最佳模型和最佳时间点,使用13 种算法以及不同周的课程数据进行预测,并对比了结果。Howard 等人[10]通过分析本科生的评估数据和个人信息数据建立早期预警模型,并重点研究干预的最佳时间。其结论表明,最佳干预时间是在课程中期,且学生需要改变学习策略以适应新的课程要求。然而,已有的研究多数基于累积行为频率作为预测变量。Hung 等人[11]指出累积行为频率存在一些问题。如未能考虑到不同学生学习行为模式之间的差异,忽略了多种行为模式可导致课程不及格,未能考虑到课程活动的要求会随课程进展发生变化等问题。因此at-risk学生的预测结果还有进一步提升的空间。
学生的学习模式决定了其学习表现。学习模式被定义为“学习者通常采用的连贯的学习活动,包括他们对学习的信念和学习动机”。通过分析学习模式能够解释造成学习表现差异的原因,进一步区分不同学习表现的群体[12],因而提高不及格学生的识别率。在学习管理系统(learning management system,LMS)中,学生的行为是最易收集的,且已被广泛应用于描述学生在LMS中学习模式的变量,这些变量构成了学生的行为模式。已有的研究采用各种行为的累积次数描述学生的行为模式。这种方法虽代表了模式的宏观特征,却无法进一步区分累积频率相似但频率分布不同的学生,而他们具有不同的学习表现[11]。学习生行为的时间序列数据包含学习过程信息,即学习者在不同课程时期的行为分布,它描述了学生微观行为模式,能够进一步区分不同类型的群体。
为了进一步提高at-risk学生的识别率,可对学生的行为模式数据进行特征处理。多项研究表明,使用自动编码器(autoencoder)对原始数据进行特征压缩和噪声消除可以改善模型的性能(例如Zhao 等人[13]的研究)。autoencoder 也已被用于教育领域的研究。例如,Du 等人[14]提出了一个基于变分自编码器(LVAE)和深度神经网络(DNN)的集成框架(LVAEPre),以解决教育数据集的高度不平衡问题。Li 等人[15]提出了基于autoencoder的复合特征模型,该模型结合学习数据中的多重特征来推断学生未来两周的行为。由于学生的行为模式可以用时间序列数据表示,结合能够处理序列数据的长短期记忆(long short-term memory,LSTM)单元构建自动编码器(LSTM-autoencoder)可以对学生行为模式数据进行特征提取和去噪,进而提高模型预测效果。
在线学习中,学生的最终成绩取决于课程各个阶段的学习活动,而不同阶段的学习活动对最终成绩的影响存在差异。对学习者的时间序列数据进行分析,可以回溯学习者过程,发现影响学习成绩的关键因子。注意力机制能够计算出输入变量相对输出结果的权重,采用注意力机制分析学生行为模式,可以得到不同课程阶段中各种行为对最终成绩的影响程度。教师可根据这些信息进一步分析at-risk学生在学习过程中存在的得失,进而采取个性化的干预措施。如针对性监督、辅助或改变后期的教学策略等。
本文提出一种通过深度学习模型对微观行为模式进行分析以实现学习成绩早期预警的方法-结合LSTMautoencoder 特征处理和注意力权重计算的at-risk 学生早期预警模型(LSTM-autoencoder and attention based early warning model,LAA)。该方法采用LSTM-autoencoder对学生行为的时间序列数据进行特征提取和去噪,通过注意力机制计算出不同学期周次、不同行为对最终成绩的影响权重,并识别出at-risk学生和最早干预时间点。该方法不仅可以提高at-risk学生的召回率,提前教学干预时间,还可帮助教师进行精准的个性化教学干预。
1 基于微观行为模式分析的早期预警
1.1 基于LSTM-autoencoder 的学生行为时间序列特征处理
Autoencoder在序列数据的特征提取方面获得了广泛的应用。其编码器部分能够对输入序列数据进行维度压缩,解码器能从压缩数据中恢复信息。整个训练过程要求能够尽可能多的恢复原始数据中的信息,实现数据特征提取和去噪。
学生的行为模式具有前后关联性,即前一段时间的学习行为会对后一段时间的学习行为产生影响。本文采用能够记忆序列因果信息的LSTM 神经元搭建autoencoder。根据LSTM网络结构,每个LSTM神经元都包含输入门(it)、遗忘门(ft)和输出门(Ot)。输入门控制输入信息,遗忘门控制哪些信息应当被舍弃,输出门控制神经元的输出。各个门的计算公式如下:
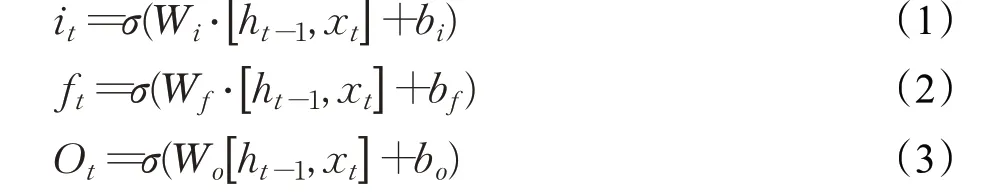
ht表示t时刻神经元的输出,ht-1表示前一时刻单元的输出。LSTM当前状态Ct计算如下:
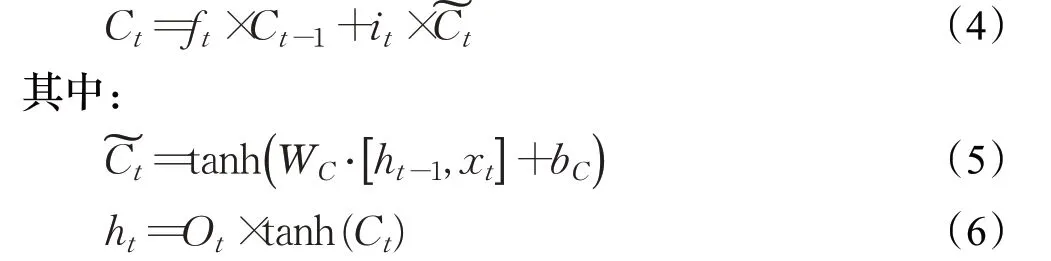
本文通过LSTM-autoencoder 提取学习者时间序列数据中的前后学习行为关联信息,并增强数据特征,以提高学习成绩预测的结果。为了简化实验同时提高预测准确率,autoencoder的编码和解码部分都采用单层的LSTM 神经元。LSTM-autoencoder 模型架构如图1 所示。训练过程可以描述为[16]:
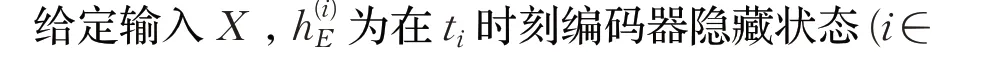

本文中,LSTM-autoencoder的输入数据为学生行为的时间序列数据。输入数据形状为S(students)×M(时间步)×N(行为),经过编码器处理成S(students)×M(时间步)×1(编码)的数据,最终解码器输出S(students)×M(时间步)×N(恢复的行为)数据。整个训练过程结束后,学生的行为模式信息被保存在解码器恢复出的序列数据中。
1.2 基于注意力机制的关键预测因子计算
本文采用Raffel 等人[17]的研究中提出的用于解决LSTM问题的前馈注意力网络架构进行关键预测因子分析,计算各类学习行为对最终成绩的影响权重和不同学期周次对成绩的影响权重。该注意力模块如图2所示。
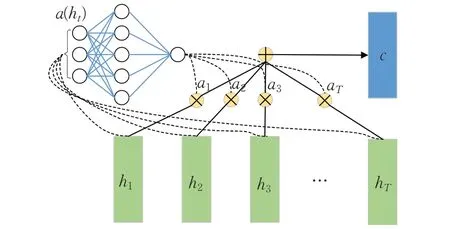
图2 注意力计算模块Fig.2 Attention calculation module
对于一般的注意力模块,其隐层状态计算公式为:

T为输入序列的时间步长,αtj是状态hj在每个时间步t计算的权重。这些上下文向量被用于计算新的状态序列s,其中st取决于st-1,ct和模型在t-1 时的输出。权重αtj计算公式如下:
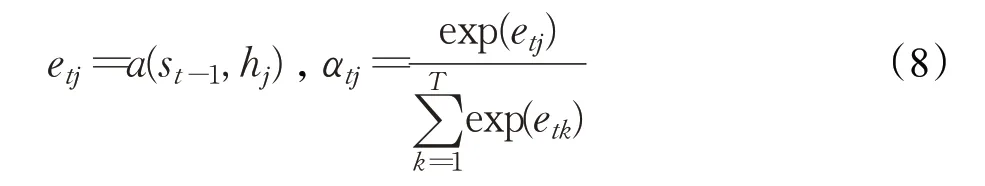
其中,a是一个通过学习得到的函数,可以考虑为给定hj的值和先前状态st-1来计算hj的层级重要性值。这个公式使得新的状态序列s可以更直接地获取整个状态序列h。
对上述隐层状态计算方法进行简化,使其可以用于从整个序列中产生单维向量c,方法如下:
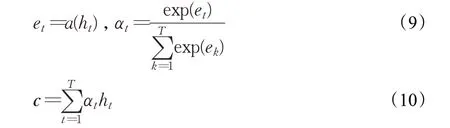
a仍然是一个可学得的函数,但现在仅取决于ht。在这种表述中,可以将注意力视为通过计算状态序列h的自适应加权平均值来生成输入序列的固定长度嵌入c。由于计算可以完全并行化,该方法会带来较大的效率提升。
1.3 基于行为时间序列特征处理和关键预测因子计算的早期预警
本文提出的结合LSTM-autoencoder 特征处理和注意力权重计算的at-risk 学生早期预警模型(LAA)架构如图3所示。
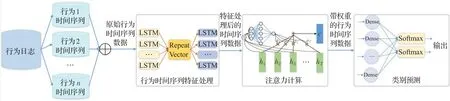
图3 LAA早期预警模型Fig.3 LAA early warning model
原始行为数据经过预处理和编码,构造成N个行为的时间序列数据;采用LSTM-autoencoder对时间序列数据进行处理,实现行为模式信息的特征提取和去噪;注意力层对解码器的输出数据进行权重计算。后层神经元通过Dense层和Softmax神经元实现成绩预测。本文提出的模型具体思路如下所示。
模型LAA早期预警模型:
输入:训练数据X;数据时间步T,特征维数F;自动编码器层数L,训练周期数E,批量大小B;注意力模块层数L′。
输出:学生成绩类别C,特征权重Wf,时间步权重Wt。
步骤:
1.对数据进行归一化处理,计算编码层的激活输出,编码器将F维特征压缩成1维;
2.自动编码器中间层将编码层的输出复制到T个时间步上;
3.解码器将中间层的数据重构成与输入层相同的维度,得到特征恢复后的数据;
4.注意力层利用公式(9)和(10)计算重构数据各个特征对目标变量的影响权重Wf(或各时间步对目标变量的影响权重Wt);
5.通过反向传播算法计算整个序列上的误差,并更新网络参数。
6.重复步骤1~5,直到反向传播算法停止更新参数,输出类别C(0或1),训练完成。
本文提出的模型计算量分析如下。整个模型的计算量取决于时间步T和特征维数F。编码器将F维特征压缩到1维;解码器的输出维度与编码器输入维度相同,且都由T和F决定。注意力模块在计算特征权重Wf时,计算量由F决定,在计算时间步权重Wt时,计算量由T决定。学生的课程周期通常不会超过20 周,因此时间步T≤20,属于短序列;在线学习平台中学生行为类别多数为个位数,即F≤10;为了简化模型架构同时保证性能,编码器和解码器部分都采用单层的LSTM。因此,本文提出的模型具有低复杂度、计算快的特点。
2 实验及结果
2.1 实验数据
数据收集自美国一所学校2015—2016 年完全在线的课程,包含476门课程,4 607名学生,课程持续16周,总计3 625 619条日志。这些数据记录了学生在线学习的所有行为,本文将这些学习行为分为以下五类:
(1)访问资源(Content,1 249 738 条记录):所有与浏览课程资料相关的行为。
(2)参与评估(Assessment,1 019 901条记录):所有与课程评估相关的行为。
(3)查看分数(CheckGrade,277 513 条记录):查看课程评估成绩、作业成绩等信息的行为(此行为在已有的文献中被识别为早期预警关键因子)。
(4)参与交互(Interaction,1 029 900 条记录):所有与线上互动有关的行为,包括同伴互动或师生互动。
(5)其他行为(Others,48 567 条记录):不属于上述类别的其他次要行为。
本文对学生的原始日志数据进行清洗后,计算每周各个行为的频率,每个学生的记录最终生成16(周)×5(行为)的时间序列数据。同时,计算每周所有行为的总频率,每个学生的记录最终生成16(周)×1(总频率)的时间序列数据。其中,每周总频率等于每周5种行为频率之和。
对于学生的成绩数据,以60 分为标准将学生划分成及格(≥60 分,标记为类别0)和不及格(<60 分,标记为类别1)两类。其中,及格(以下简称success)学生为3 673人(占比79.73%),不及格(at-risk)学生为934人(占比20.27%)。
为了深入分析LAA 对不同类型学生的识别能力,本文分别对success 学生和at-risk 学生的时间序列数据进行聚类,探索这两类学生中存在的行为模式。时间序列聚类可以比较学生行为模式的相似性,将具有相似模式的学生分为同一个群,将具有不同模式的学生分为不同的群。为了提高时间序列聚类效果,本文在聚类前对学生的时间序列数据进行了特征处理。结果表明,该数据集中存在3种success学习行为模式和3种at-risk学习行为模式。各群人数分布如表1所示。
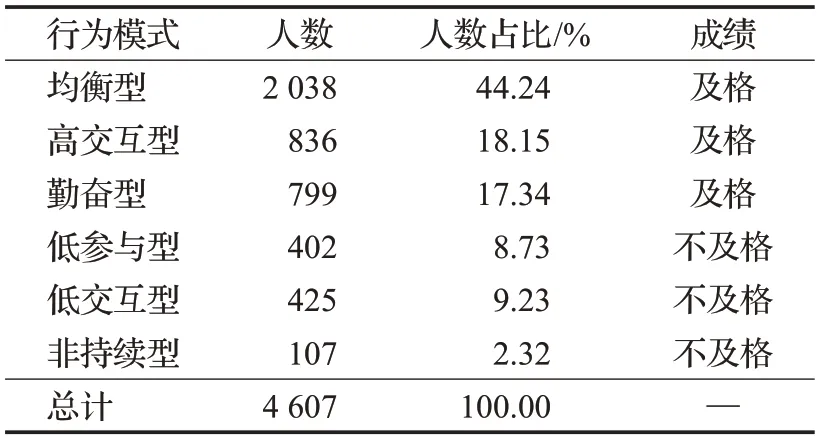
表1 success学生和at-risk学生的行为模式Table 1 Patterns of success and at-risk students
3 种success 学生的典型行为模式如图4(a)、(b)、(c)所示,具体描述如下:
(1)均衡型(success cluster 1)。该群学生3种主要行为(访问资源、参与评估和参与交互)比例接近,且保持稳定的高行为频率(例如图4(a)学生A 的行为模式)。已有的研究表明,具有稳定且持续参与水平的学生能够获得更高的学习表现。
(2)高交互型(success cluster 2)。该群学生的交互频率远高于其他行为,他们主要通过论坛讨论完成课程学习(例如图4(b)学生B 的行为模式)。已有的研究表明,高水平的交互行为有助于提高学习表现。
(3)勤奋型(success cluster 3)。该群学生三种主要行为比例接近,在学期开始的行为频率远高于其他群,且整个学期维持相对稳定的参与水平(例如图4(c)学生C的行为模式)。通常高参与度意味着高的学习动机,能够促进学习效果。
3种at-risk学生的典型行为模式如图4(d)、(e)、(f)所示,具体描述如下:
(1)低参与型(at-risk cluster 1)。该群学生几乎不参与学习活动,属于因参与度过低而表现不好的学生(例如,图4(d)学生D的行为模式)。低参与是最常见且最易被识别的at-risk类型之一[18],教师无需通过模型而直接使用数据可视化方法就能识别该群体。
(2)低交互型(at-risk cluster 2)。该群学生的交互行为频率随着课程的进展越来越低(例如图4(e)学生E的行为模式),表明其在学习过程中并不重视与教师或同学交流。低交互容易导致学生对知识点缺乏理解和掌握[19],造成低学习表现。
(3)非持续型(at-risk cluster 3)。该类型学生具有不稳定的参与频率,且各种行为频率的相对大小也多次发生变化(例如,图4(f)学生F的行为模式)。该群学生参与频率的下降体现了其学习动机的减退[20]。
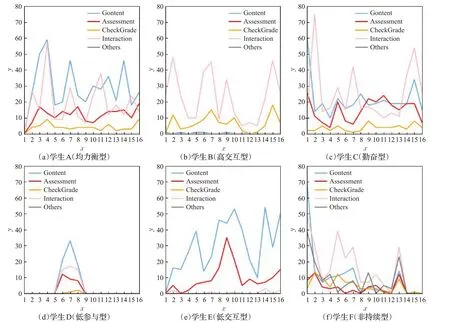
图4 及格(success)和不及格(at-risk)学生的行为模式Fig.4 Patterns of success and at-risk students
2.2 实验结果
本文设置两个基线模型与LAA进行早期预警预测比较,分别是:
(1)基线模型1。总频率行为序列(total frequency of behavior series)+RNN 模型(TFB)。总频率序列是学习者每周行为之和的序列数据,表征学习者的宏观行为模式。使用循环神经网络(RNN)作为预测模型。
(2)基线模型2。原始行为序列(original behavior series)+RNN模型(OB)。原始行为序列是学习者每周5种行为频率序列,包含学习者微观行为模式的原始信息。使用循环神经网络(RNN)作为预测模型。
(3)LAA 模型。对学习者微观行为模式原始信息进行特征处理和权重计算后实现成绩预测。
本文采用准确率和召回率作为评价指标,用以比较3个模型的早期预警性能。对于早期预警,其目的是在学期较早阶段通过模型识别尽可能多的at-risk学生,因而召回率是比准确率更重要的评价指标[21-23]。
2.2.1 早期预警比较
本文使用3种模型在每周进行了成绩预测。表2仅列出每隔一周预测成绩得到的准确率和召回率。所有结果都是取五折交叉验证平均值。结果表明,LAA在各周都取得了与基线模型相似的准确率和更高的召回率。
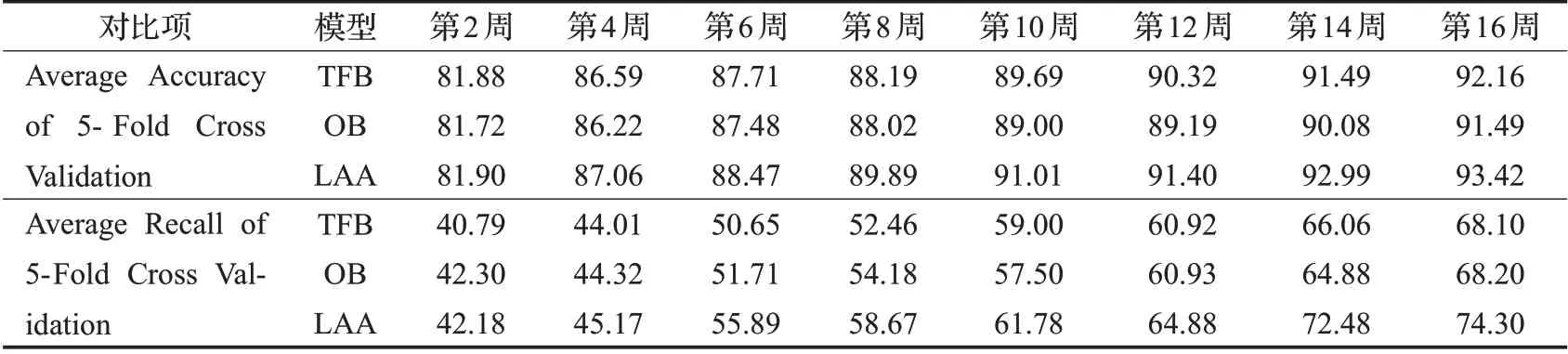
表2 早期预警预测结果比较Table 2 Comparison of early warning prediction results%
在已有的研究中,识别出较多(如50%以上)的at-risk 学生的时间点被确定为最佳干预时间。LAA 模型在第5周(5/16周,未在表中列出)可识别50.54%以上的at-risk 学生,比基线模型提前一周。因此,教师可在第5周对LAA模型筛选出的at-risk学生开展教学干预。
表3列出了3种模型识别的at-risk学生行为模式类型和人数。LAA识别出最多的低交互型和非持续型学生。
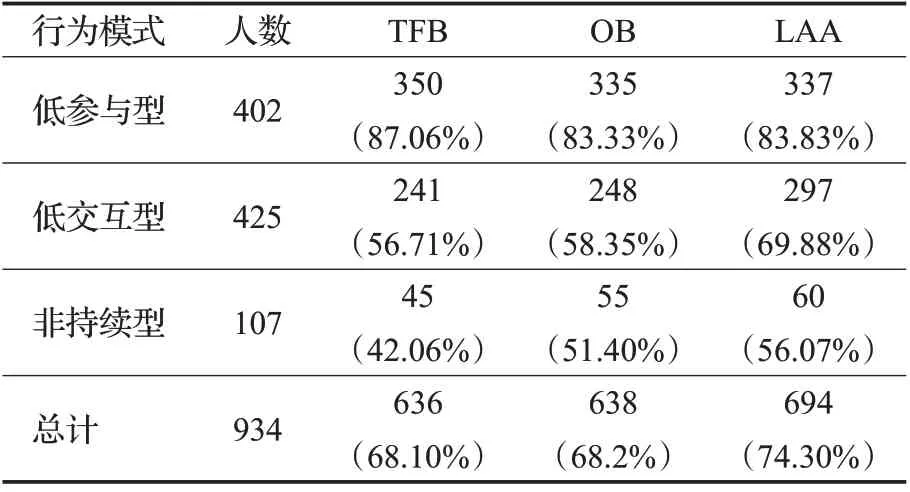
表3 模型对3种at-risk学生的识别结果Table 3 Identification results of three kinds of at-risk pattern students
本文采用上述学校的2018年数据验证所提方法的泛化能力。该数据中的课程持续20 周,共7 592 977 条行为日志数据,参与者为7 701 名学生。其中,5 743 人及格,1 958人不及格。学生的行为日志被编码为7种类别的行为(访问资源、查看通知、完成作业、参与评估、参与交互、查看成绩和其他行为)。结果表明,LAA 在每个周都取得了最高的准确率和召回率。LAA 在第6 周(6/20周)可识别50%以上的at-risk学生;在第20周取得了最高的召回率(分别是:TFB-61.69%、OB-73.13%、LAA-79.73%)。
2.2.2 早期预警关键预测因子分析
通过注意力模块计算得到success 学生和at-risk 学生的各周次对最终成绩的影响权重如图5所示。R为atrisk 学生,S 为success 学生。学生R 权重最大的周是第10周,学生S权重最大的周是第13周。这表明不同学习表现的学生,学期各周次对成绩的影响程度有所差异。
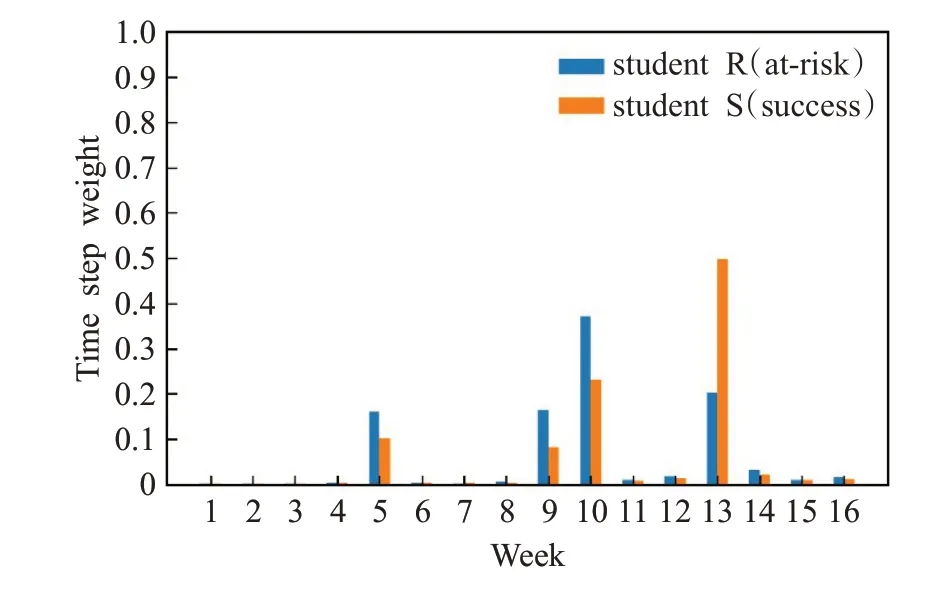
图5 At-risk和success学生的各周次权重Fig.5 Week weights of at-risk and success students
学生R 和学生S 的各种行为对最终成绩影响权重如图6所示。学生R的行为权重大小依次为:参与交互(Interaction)>查看成绩(CheckGrade)>访问资源(Content)>参与评估(Assessment)>其他行为(Others)。学生S 的行为权重大小依次为:访问资源(Content)>参与评估(Assessment)>其他行为(Others)>参与交互(Interaction)>查看成绩(CheckGrade)。可以看出,及格学生和不及格学生虽然有相同的行为类别,但是各类行为对学习结果的影响权重不同。
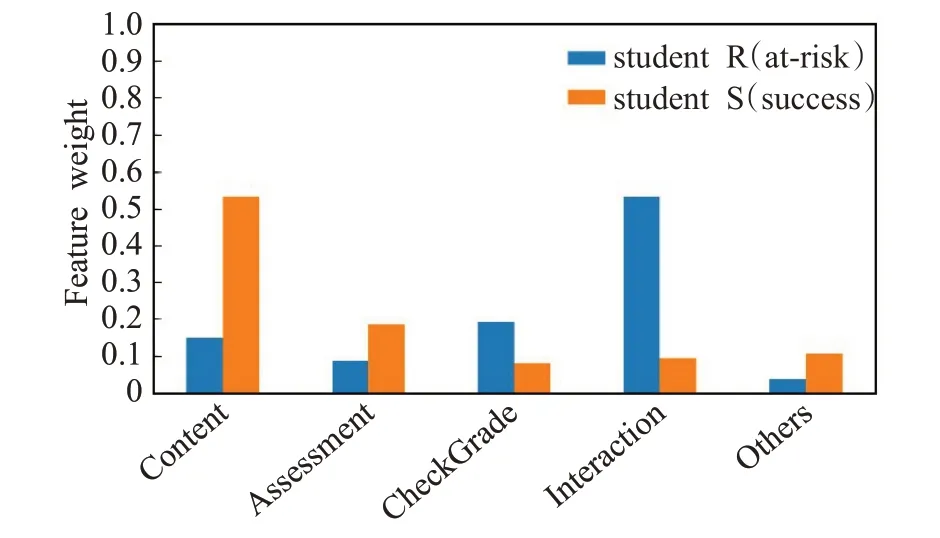
图6 At-risk和success学生的各类行为权重Fig.6 Behavior weights of at-risk and success students
在实际的教学活动中,教师按照课程大纲安排学生在特定阶段完成课程任务,参加指定的学习活动。LAA模型计算出关键周次和行为,可帮助教师对照标准课程设计来发现学生在某个阶段学习上存在的具体问题,进而采取干预措施。
3 结束语
本文提出的LAA 方法可在学期较早的阶段识别50%以上的at-risk学生,相比基线模型取得了相似的准确率和更高的召回率。该方法对识别低交互类型和非持续类型的at-risk学生具有明显优势,且可以将教学干预时间提前一周。LAA模型通过计算各周注意力权重和各种行为的注意力权重,挖掘出影响学习结果的最重要周次和行为类别,可以方便教师选回溯学习过程。教师可根据预测结果精准定位需要干预的群体,并根据影响at-risk 学生成绩的周次和行为权重,从课程设计、学习活动评估和学习监控等方面对学生进行个性化的教学干预。尽管LAA模型取得了比基线模型较高的召回率,如何进一步提高准确率是后续工作需要研究的内容。
