自适应插值与特征压缩的小样本数据分类研究
2022-01-22孙永明
孙永明,杨 进
上海理工大学理学院,上海 200093
目前,人工智能的迅速发展产生了海量数据,高维且类型复杂的大数据导致预测效率低,结果不准确[1-2],尤其是多分类问题[3]。集成学习在解决这个问题上得到了很快的发展,应用较广泛的有GBDT(gradient boosting dart tree)[4]、XGDT(extreme gradient boosting dart tree)[5]。对比随机森林与GBDT,XGDT 防止过拟合,对数据拟合度更高。然而,XGDT 对非均衡数据分类时,仍会存在对少数类样本学习不足,预测不准确的问题。并且它以决策树为基学习器,容易受到高维冗余特征的干扰,对于划分多的特征也会过拟合。研究XGDT 算法对于高维不均衡小样本的分类问题十分必要。
对于非平衡样本分类主要研究为:加入代价损失函数与集成学习;构造新的分类评判标准;对数据重采样。如SMOTE(synthetic minority ove sampling technique)[6]、BorderlineSMOTE[7]、ADASYN(adaptive synthetic sampling approach)[8]过采样;Tomek link[9]、ENN(edit nearest neighbor)[10]欠采样等。SMOTE 插值对于稀疏的少数类样本难以被学习到。ADASYN插值以每个少数类样本为中心,在周围生成新样本,容易生成噪声数据。基于过采样、欠采样的缺点,很多学者提出了综合采样,取得了良好的效果。如SMOTEENN、SMOTETomek。有学者将采样与集成算法结合研究大数据分类问题,如SMOTEBoost、SMOTEBagging。大部分学者研究将过采样与集成算法结合,易造成算法学习到过采样的噪声数据,影响分类效果,且易过拟合。文献[2]提出BSL(borderline SMOTE and tomeklink)综合采样与随机森林结合的方法,改善了少数类样本的分布,取得了良好的分类效果。
特征压缩对于研究机器学习与数据挖掘十分重要[11]。经典的特征压缩法有Filter、Wrapper、Embedding。Filter简单高效,有Relief、ReliefF[12]等;Wrapper 准确但费时,有LVW(las vegas wrapper)[13];Embedding 有LARS(least angle regresion)[14]。基于启发式算法的思想,文献[15]提出一种大数据下压缩特征的遗传算法。文献[16]改进了森林优化特征选择算法。启发式算法复杂,用时久,不适用于高维大数据。因此,结合Filter、Wrapper方法与集成算法压缩特征成为一种新的思想[17]。文献[18]提出一种结合信息增益率与随机森林压缩特征的方法。文献[19]提出一种结合互信息、邻域和SBS(sequential backward selection)的特征压缩法。根据互信息、邻域判别指数,用随机森林的准确率作为评价指标,利用SBS 压缩特征。但是,随机森林容易学习到噪声数据,造成过拟合。SBS 方法的时间成本高,降维结果不理想。文献[20]提出一种XGBoost 与PCC(pearson correlation coefficient)相结合的特征压缩法。目前,研究XGDT 算法的特征压缩问题较少。很少有人将XGDT与Filter、Wrapper结合来研究特征压缩问题。
本文针对小样本数据的高维不均衡以及算法XGDT在大数据背景下研究不足的问题,构造了一种基于插值与特征压缩的分类方法ASE-RFXT。首先构造ASE 采样方法。改进ADASYN 的插值中心,计算每个少数类样本近邻内同类样本的中心作为插值中心,保持了数据原有信息,减少了自适应插值引入的噪声,结合ENN降采样方法,从而减少错误数据对分类的影响。其次构造了综合ReliefF与XGDT的特征压缩法RFXT,提出改进ReliefF 的统计量与XGDT 的特征平均信息增益对特征进行并行加权的方法,使得对特征重要性的评估更全面准确;利用PCC过滤低权重的相关特征,去除冗余信息,以集成算法XGDT的分类精度为评价指标,对特征空间进行SFS寻优。最后,将方法ASE-RFXT在UCI数据集上进行实验,从采样、特征压缩、分类三方面与常用方法进行对比,结果显示具有一定的优势。
1 算法
1.1 ASE综合采样
ASE方法结合了ADASYN与ENN的优点。ADASYN以每个少数类样本为中心,在近邻的同类之间随机插值。由于有些少数类数据可能是噪声数据,也可能处于分类边界处,如果进行大量插值容易引入更多噪声,如果直接删除可能会导致信息丢失。因此,改进ADASYN的插值中心,计算少数类样本k近邻中同类样本的中心,以此中心为插值中心,生成新样本。同时将中心点与近邻同类样本的距离所乘的随机数范围改为[0,0.7],使得生成的样本更加靠近类别中心点。这样减少了插值数据受异常数据的影响,减少生成噪声的可能,保持了数据原有信息。
设少数类样本数目ms,多数类样本数目ml,xi为任意的少数类样本,则总共需要合成的少数类样本数G=(ml-ms)×β,β为平衡程度。设xi的k近邻中多数类样本数为Δi,则xi附近需要合成的少数类样本数目为:

依据中心点xim进行插值,随机选择在xi的k近邻内的一个同类样本xzi,生成随机数λ∈[0,0.7],则生成新样本:

尽管对ADASYN 方法进行了改进,减少了噪声数据的引入,然而,仍然不可避免存在一些错误样本(包括原数据)。利用ENN降采样,将每个样本的k近邻内超过k2 的样本是异类的数据视为噪声数据,进行删除,减少学习器受错误样本的影响,提高了分类精度。
算法1 ASE-Sampling

1.2 RFXT特征选择与分类
RFXT 算法是一种结合ReliefF 和XGDT 的特征压缩法。主要思想是改进ReliefF 计算特征权重的统计量,并结合XGDT 的平均信息增益对特征并行加权,运用PCC删除与低权重特征相关性强的特征,降低特征冗余度。以XGDT分类器的分类准确率为评价指标,利用SFS 技术搜索特征,直到准确率不再增加,从而得到最优特征子集及其准确率。
XGDT算法用损失函数与正则项作为目标函数:
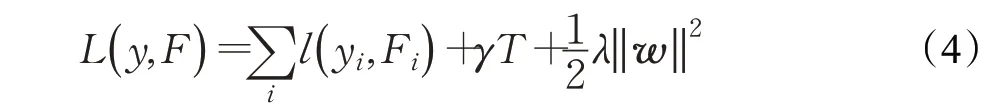
其中Fi是预测值,设类别数为K,则损失函数为:

将特征j在所有树中的分裂次数设为FScore,则XGDT 计算特征j的权重为j在所有树中的平均增益gj(加权方法记为X)为:

设xi的类别个数为k,xim,xih,l分别表示xi的同类样本与异类样本;c(c=k-1)表示与xi不同类别的那些类,设pl为第c类样本在数中所占比例;特征j的权重统计量公式为(记为R权重统计量):

考虑到不同的特征数值大小差异,公式(9)会导致数值大的特征权重偏大。定义新的距离公式为:

此外,R统计量只考虑与最近单个样本之间的距离,权重易受最近邻的影响。因此,本文计算样本与所有同类样本以及所有异类样本之间距离的平均值,来衡量特征权重,减少了特征权重受单个近邻值的影响,使得权重评估更加精确。记RE统计量为:

运用两种特征加权方法,分别将RM与RE统计量计算的特征权重δj和XGDT的增益gj相结合,对特征进行并行加权。先标准化δj与gj,再计算δj与gj的平均值作为最终的特征权重wj=(δj+gj) 2。并行加权考虑了不同类别特征之间的距离也考虑了特征对分类的贡献,减少了噪声对特征权重的影响,使得最终的特征权重更具有鲁棒性。将RM与XGDT结合的加权方法记为XRM,将RE与XGDT记为XRE。
本文整个算法分为三部分:对数据进行采样、对数据进行特征选择与分类。算法流程图如图1所示。

图1 算法整体流程图Fig.1 Overall flow chart of algorithm
算法2 ASE-RFXT


1.3 复杂度分析
ASE-RFXT算法的时间复杂度主要由采样,特征加权,特征子集搜索构成。设样本数量为m,特征维数为n,ASE的时间复杂度仅与m有关为O(m)。RE与RM是通过计算不同类别样本之间的距离衡量特征权重,它的时间复杂度与m和n成线性关系,为O(m,n) 。设XGDT算法由深度为d的k棵树组成,则XGDT时间复杂度为k×O(mnd)。利用SFS搜索寻找最优特征子集,比较次数最多为n(n-1) 2,由于算法设置准确率不再增加为停止原则,因此,实际比较次数远小于n(n-1) 2。则算法ASE-RFXT总的时间复杂度为:

故它的时间复杂度在合理范围内,它的空间所占内存与样本和特征数成线性关系,也在合理范围内。
2 实验设计
2.1 实验数据
实验使用数据集Studentlife[21],它来源于智能手机传感器记录的人的日常行为数据。从中提取了79个特征,2 138条有标签的样本,特征提取方法参考文献[22]。此外,选取了UCI 数据集中常用分类数据集进行实验。对数据集类型为名词的特征进行Onehot 编码,对所有数据进行标准化,数据分布如表1所示。
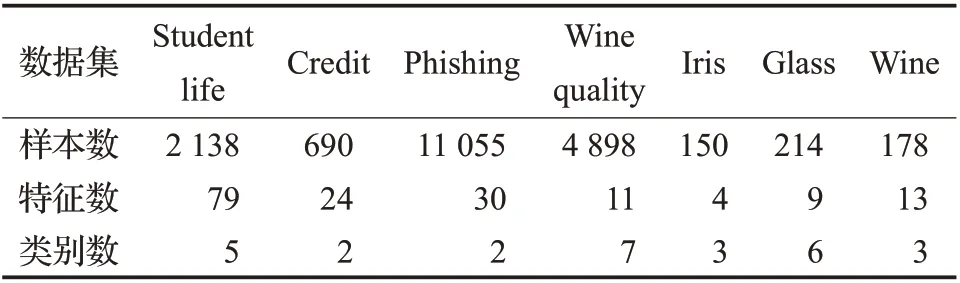
表1 所用数据集Table 1 Data sets used
2.2 评价指标
设分类器对样本的预测结果为ypred,对应样本的真实类别标签为ytrue。由于研究的数据集不均衡,因此,本文利用Accuracy、Precision、Recall、Fβ值作为分类器预测结果的评价指标(取β=0.5),计算公式为:

2.3 实验方案
本文是在2.20 Ghz CPU,8 GB RAM的Windows10,PyCharm 编程环境基于Scikit-learn 库进行的实验。在采样上,对数据进行无采样、BSL 采样、ASE 采样的对比;在特征加权上,对比了XGDT 增益(X),基于RM、RE,以及并行加权XRM、XRE的结果;对特征寻优,对比了GS(贪心搜索)、SFS、SBS结果,并对比了SFS搜索在各分类器上的结果。同时,对比了XGDT 与LVW 结合(记为XLVW),以及其他文献的特征选择法的结果。进行实验的分类器为极限梯度提升决策树(XGDT)、随机森林(SF)、支持向量机(SVM)、K近邻(KNN)、决策树(TREE)、多层感知机(MLP)。
分类器参数均在数据Studentlife上通过网格搜索与十折交叉验证结合的方式进行调节。首先将数据集Studentlife 按照3∶1 划分为训练集与测试集,然后利用网格搜索调节分类器的参数,对训练集进行十折交叉验证,同时记录验证集准确率,将验证集准确率最高时的参数保留下来。最终参数设置如表2所示。

表2 重要参数设置Table 2 Important parameters setting
3 实验结果
3.1 综合采样结果
对BSL 与ASE 采样方法中的近邻个数k设置为5。对数据集Studentlife、Credit、Phishing、Winequality 进行无采样(No),BSL与ASE综合采样结果如图2所示。利用ASE 方法采样后的数据分类准确率是最高的。这说明,提出的ASE方法可以提高不均衡数据分类准确率,与分类器的结合效果更佳。在Studentlife、Winequality多分类数据集上,对比结果较明显,说明ASE方法对多分类问题更敏感。
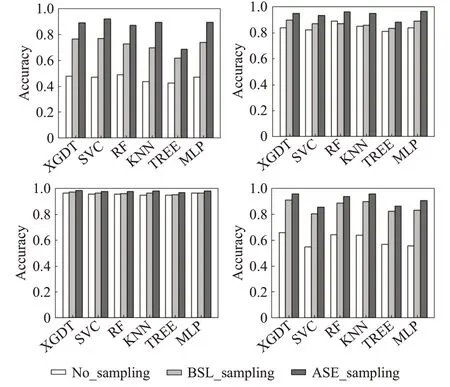
图2 采样前后分类效果Fig.2 Classification effects before and after sampling
3.2 特征选择结果
由于KNN分类器方便高效,基于Wrapper的特征选择算法中,很多文献采用KNN作为评价指标[23-24]。然而,它的准确率并不高。本文以XGDT 的准确率为评价指标,并对比了不同分类器为评价指标压缩特征空间后的特征个数(SF)与分类准确率(Acc)。实验在Studentlife数据上进行,采用SFS搜索,结果如表3所示。表3中,SF与Acc表示在XRM、XRE特征加权法下不同分类器选择的特征个数与对应的准确。可以看出,在XRM与XRE的并行加权下,以SVM分类精度为评价指标搜索的特征子集的分类准确率最高,分别为90.3%、90.9%。基于KNN的分类准确率最低,分别为68.5%、67.6%。但是,基于SVM进行搜索的最优特征子集的个数最多,这说明它的特征压缩效果最差。而本文基于XGDT 搜索的特征子集的分类准确率低于基于SVM的1.8个百分点、1.3个百分点,但选择的最优特征子集的特征个数分别为13、16远少于SVM的30、27。因此,综合考虑准确率与选择的特征个数,本文方法在准确率较高的情况下也可以有效降低特征维度,针对高维数据具有更高的实用价值。

表3 基于不同评价指标的特征选择效果Table 3 Effectiveness of feature selection based on different evaluation indicators
如表4对比了对不同数据集并行加权后,按照权重排序,以XGDT 分类结果为评价指标,利用GS、SFS、SBS 三种策略压缩特征空间的效果。实验对比了最终搜索的特征子集数(SF)与分类精度(Acc)。从表4 看出,GS 方法在Studentlife、Credit、Phishing 数据集上,搜索的特征个数最少,但准确率最低。在其他数据集上,特征个数不是最少的情况下,准确率也很低。这说明GS方法容易陷入局优;SBS方法,在所有数据集上的准确率都是最高的,但是它选择的特征个数较多,特征压缩效果不理想。在Student life、Phishing数据集上,用SFS搜索的精度分别比SBS 略低0.7 个百分点与1.6 个百分点,但搜索的特征个数分别为16、16,远小于SBS的76、22;在数据Credit 上,SFS 与SBS 的精度相同,但SFS 选择的特征个数为3,明显低于SBS选择的9。对比GS与SBS方法,SFS方法可以在达到较高的分类精度下选择较少的特征。

表4 不同搜索方式的分类结果Table 4 Classification results for different search methods
如表5 对比了BSL、ASE 采样后,不同特征压缩法的特征个数(SF)与分类精度(Acc)。可以看出,对于Studentlife、Phishing,在BSL 采样下,基于XRE 并行加权的准确率是最高的,分别为75.9%、86.2%。它选择的特征个数分别为17、18。基于XRM的准确率稍低,分别为74.2%、95.0%,但它的特征个数较少,分别为12、17。对于Studentlife、Credit、Phishing,在ASE 采样下,基于XRE 的准确率最高,分别为89.6%、95.2%、97.1%,它的特征个数也较少,分别为16、3、16。基于XRM的准确率稍低,分别为88.5%、92.9%、95.5%,但它的特征个数非常少,分别为13、2、11。所有特征选择法在ASE采样下的准确率都比在BSL 下高,且ASE 与XRE 结合的方法在对数据运用的特征个数更少情况下,达到较高准确率。XLVW 的特征个数是根据其他算法的特征个数进行设置的。各方法中,XRE 并行加权的准确率最高,XRM的降维效果相对较好。

表5 不同特征选择的效果Table 5 Effects of different feature choices
如表6,对比了基于XRM 与XRE 构造的特征选择法、FSIGR[20]方法、文献[15]方法的结果。文献[15]是基于遗传算法,由于原文未具体说明种群个数与迭代次数等参数。本文多次调参,选择较优参数,设置种群个数为30,迭代100 次,交叉与变异率均为0.2,记录迭代最优的10个特征子集的特征个数平均值和在XGDT上准确率的平均值。对于FSIGR方法,本文采用网格搜索对参数调优,选择基尼系数为分裂策略,设置生成350 棵深度为13 的树。可以看出,在Glass、Credit 上,基于XRE 的准确率最高,分别为93.16%、95.16%,特征选择的特征个数为4、3,少于FSIGR的7、14;虽然在Phishing上的准确率97.15%,低于FSIGR 的97.4%,但选择的特征个数16 少于FSIGR 的23;在Wine、Iris 上的准确率略低于文献[15],但选择的特征个数较少。因此,提出的并行加权的特征选择法对高维数据的分类具有一定效果。

表6 不同特征选择算法的分类结果对比Table 6 Comparison of classification results of different feature selection algorithms
3.3 分类结果
如图3,对比了Studentlife 数据运用BSL、ASE 采样与XRM、XRE 构造的特征选择法,在分类器上的Accuracy、Precision、Recall、Fβ值。可以看出,ASE 与XRE的结合在各分类器上的Accuracy、Precision、Recall、Fβ值都是最高的。说明将ASE 与XRE 的特征压缩法结合,对解决高维不平衡数据具有良好的效果,且在XGDT分类器上的准确率高于其余的分类器,验证了给出的ASE-RFXT 方法与XGDT 分类器结合能够很好地解决高维不平衡数据的分类问题。
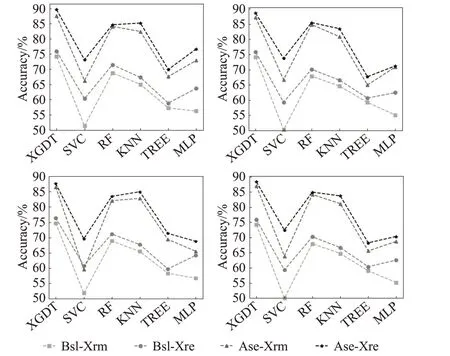
图3 不同采样与不同特征选择方法结合的分类效果Fig.3 Classification effects of combining different samplings and different feature selection methods
4 结论
针对高维不平衡小样本数据的分类效率低、准确率低的问题,本文构造了一种方法ASE-RFXT。提出了一种改进的自适应插值法并结合ENN降采样构造ASE综合采样法,改善了不均衡样本的分布,提高了分类准确率。通过改进ReliefF 特征加权法,提出了一种将ReliefF 与XGDT 结合对特征并行加权的REXT 特征选择法,压缩了特征空间,减少了信息冗余度,在不损失分类准确率的前提下提高了分类效率。从多个数据集的实验对比中得出,构造的ASE-RFXT 方法,对不平衡高维数据、特征冗余数据的分类具有较好的效果。今后的研究展望:(1)对自适应采样增加条件设置,可以根据高斯模型选择采样比例,检验采样后的数据是否符合正态分布;(2)不同特征加权方法效果不一样,根据需要进行选择;(3)可以将双向搜索方法运用于梯度提升决策树的特征选择中。
