基于DBLSTM-DCNN的骨导和气导语音转换
2022-01-21储有亮
储有亮,李 梁
(重庆理工大学,重庆 400054)
0 引 言
语音是人与人之间最常见的信息交互方式,但是很容易受到周围噪声的干扰而造成信息的丢失,怎样在强噪声等嘈杂环境下进行无碍的语音信息交互,对于业界来说是一个亟需突破的研究课题。骨导语音对噪声具有很强的抗干扰性[1],这是由于骨导语音是使用高灵敏振动传感器收集人在说话时发声部位产生的振动信号得到的。这使得骨导语音在广场、码头甚至战场等强噪声的环境下有着较好的应用前景。
骨传导传感器(Bone-Conduction Microphone,BCM)通过采集人说话时由声带产生的激励信号并由人体内部骨骼以及相关组织传递到皮肤表面的震动,将其通过一系列的转换最终采集到骨导语音[2]。这与通过气导麦克风(Air-Conduction Microphone,ACM)采集到的气导语音有很大的不同。BCM语音由于其独特的采集方式,因此对来自周围环境中通过空气传播而产生的噪声具有非常好的强抗噪性。但由于人体的骨骼具有低通性,这导致BCM语音的高频信号损失严重,一般超过2.5 kHz的高频信号会严重损失,同时由于BCM语音没有经过口腔、鼻腔等调音区域进行调音,造成摩擦音、爆破音、清音等辅音音节的缺失,致使BCM语音听上去比较沉闷、语音清晰度也无法令人满意[3],因此BCM语音在实际应用上难以推广。
通过转换语音谱包络、倒谱系数、线谱频率等语音特征达到转换目的是现今主流的BCM语音转ACM语音的转换方法。例如文献[4]中利用四层全连接层建立BCM语音倒谱系数到ACM语音倒谱系数的映射关系;文献[5]出于稳定性的考虑,选择线谱频率(Linear Spectral Frequency,LSF)作为转换特征,并且采用递归神经网络来完成LSF的特征转换;文献[6]通过深度神经网络,实现LSF从BCM语音特征到ACM语音特征之间的映射;文献[7]首先通过K-means算法将喉振传感器(Throat Microphone,TM)语音的美尔广义倒谱系数(Mel Generalized cepstral coefficients,MGC)分为若干类,然后再对每类 MGC分别构建多层前馈神经网络来实现MGC特征的映射,以此来提升转换语音的效果;文献[3]则利用(Speech Transformation And Representation Using Adaptive Interpolation of Weighted Spectrum,STRAIGHT)模型[8]将语音分解为基音周期、谱包络特征与非周期成份这三种特征,利用高斯混合模型(Gaussian Mixture Model,GMM)建立非声呢语(Non-Audible Murmur,NAM)与ACM语音之间的特征映射关系。文献[9]借助深层双向长短期记忆网络(Deep Bidirectional Long and Short Term Memory Network,BLSTM)建立对数频谱(Logarithmic Spectrum)之间的映射关系。文献[10]在同为非正常音的耳语音中使用深层卷积神经网络建立谱包络特征、基音周期和非周期成分之间的转换关系,有效地提高了耳语音转换的效果。文献[11]使用WaveNet声码器来实现骨导语音和气导语音之间的语音特征转换。
以上介绍的转换算法虽然可以较好地提高和改善BCM语音的转换效果,但特征维数较低,因此导致频谱的细节信息不能很好地恢复。同时,对频域维度上隐藏信息的提取没有足够地重视,因此转换效果并不是很清晰,尚未达人耳可以清晰识别的程度。本文提出了一种基于特定说话人(某一固定说话人)的骨导语音转换算法,该算法利用深度双向长短期记忆-深度卷积神经网络(Deep Bidirectional Long and Short Term Memory-Deep Convolutional Neural Network,DBLSTM-DCNN)模型直接建模BCM语音和ACM语音,通过WORLD模块[12]提取出谱包络、非周期性成分和基频之间的映射关系,最终再通过WORLD模块合成出转换语音。实验结果表明,使用本论文提到的方法所转换的ACM语音在语音质量感知评价(Perceptual Evaluation of Speech Quality,PESQ)[13]、短时客观可懂度(Short-Time Objective Intelligibility,STOI)[14]和对数谱距离(Log-spectral distance,LSD)[15]等客观评价指标上均有较好的表现。
1 语音转换模型
1.1 骨导语音转换模型
训练阶段如图1所示,先使用WORLD模块分别提取BCM语音以及ACM语音的谱包络BCM_sp与ACM_sp(spectral envelope,sp)[16]、非周期成份BCM_ap与ACM_ap(Aperiodic component,ap)[17]和基频(f0)[18]BCM_f0与ACM_f0这三种语音特征。本文从第8帧(初始帧通常为静音帧)开始,取语音特征的当前帧及其前后各7帧(共15帧)作为DBLSTMDCNN的输入。分别使用BCM语音与ACM语音的谱包络、非周期成分和基频建立BCM谱包络与ACM语音谱包络映射模型(DBLSTM-DCNN_sp)、BCM语音非周期成份与ACM语音非周期成份的映射模型(DBLSTM-DCNN_ap)以及BCM语音基频与ACM语音基频的映射模型(DBLSTM-DCNN_f0)。
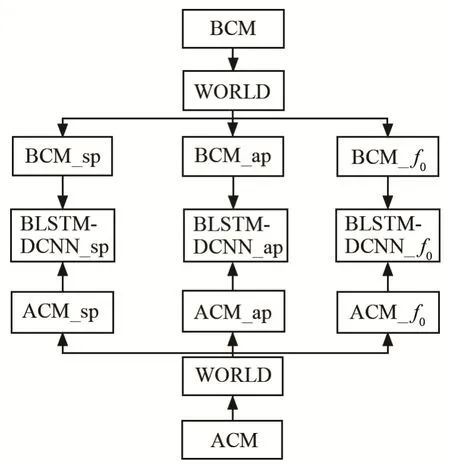
图1 基于DBLSTM-DCNN转换网络的训练阶段语音处理Fig.1 Speech processing in the training phase based on DBLSTM-DCNN conversion network
转换阶段如图2所示,首先利用WORLD模块从待转换的BCM语音中提取BCM_sp、BCM_ap和BCM_f0这三种语音特征,再分别输入到之前训练好的语音特征映射模型DBLSTM-DCNN_sp、DBLSTM-DCNN_ap和DBLSTM-DCNN_f0中,然后得到预测的ACM语音谱包络、非周期成分与基频这三种语音特征,并将其输入到WORLD模块合成转换后的正常语音。
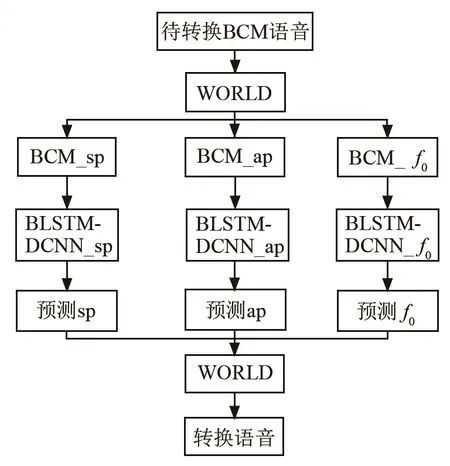
图2 基于DBLSTM-DCNN转换网络的转换阶段语音处理Fig.2 Speech processing in the transformation phase based on DBLSTM-DCNN conversion on network
1.2 DBLSTM-DCNN语音特征映射模型
虽然传统的递归神经网络(Recurrent Neural Network,RNN)算法可以记录之前产生的历史信息,并借此对语音信号的上下文信息进行建模,但是传统的RNN算法在训练过程中由于梯度的爆发和消失问题而难以学习长时间的依赖关系。基于这些问题,有学者提出了很多适合语音建模的RNN结构,在其中最著名的就是长短期记忆网络(Long and short term memory networks,LSTM)[19]。LSTM单元通过引入特殊的门(输入门,输出门和遗忘门)来促进信息在网络中的流动和存储,从而缓解了梯度问题。BLSTM是在LSTM基础上引入了双向的概念,不仅考虑语音信号的上文信息(即前向信息)对当前语音帧的影响,还要考虑下文信息(即后向信息)对当前语音帧的影响,因此BLSTM在时间维度上存在正向和反向两个方向的信息传递过程,这样可以更加容易地学习到上下文学习是如何对当前语音帧产生影响的。
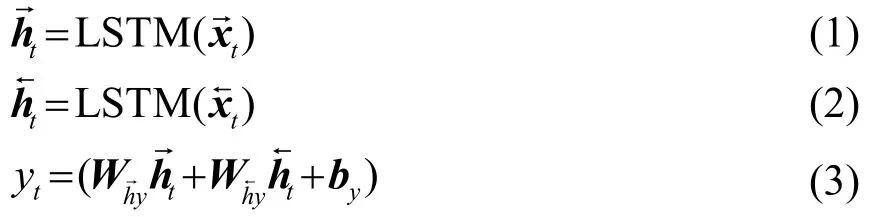
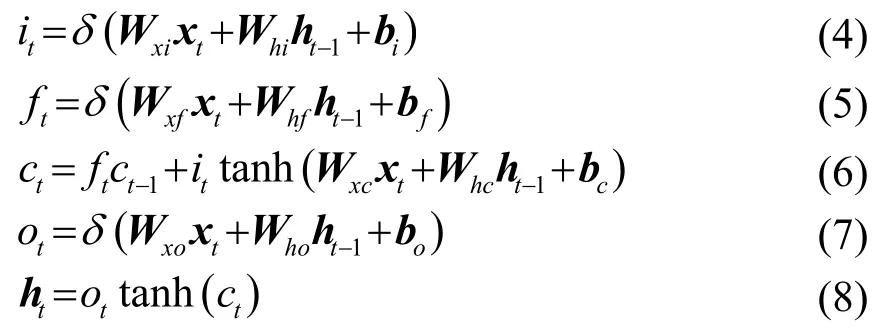
式中:it、ft、ct、ot分别为输入门、遗忘门、记忆单元状态和输出门,δ代表sigmoid函数。如图4所示,通过叠加多个BLSTM隐藏层来构建DBLSTM体系结构,其中。
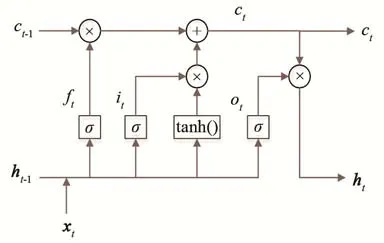
图3 LSTM模块Fig.3 LSTM module
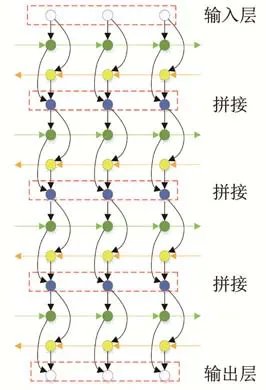
图4 BLSTM模块Fig.4 BLSTMmodule
卷积神经网络(Convolutional Neural Networks,CNN)是一种包含卷积计算的前馈神经网络。在CNN的卷积层中,当前层的每个神经元都与前一层中对应位置相同的神经元作为中心的相邻区域的多个神经元相连(相邻区域大小等于卷积核的大小),在将连续的相邻若干帧语音特征作为输入送到CNN网络时,下一个卷积层的输入是由上一层某一区域内的点通过卷积、池化等一些运算计算得到。由于上一层内的点同时包含了输入语音特征的频域信息与时域信息,因此使用卷积层可以提取出相邻帧在频域与时域上的相关性,二维卷积核计算公式为[20]
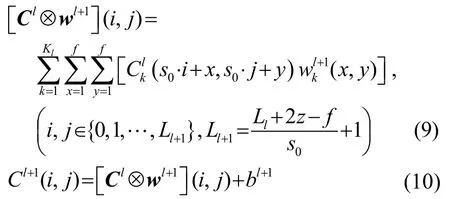
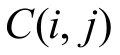
为了去除冗余信息,经过卷积层提取的特征信息通常会再连接池化层来进行特征选择和信息过滤。池化层以压缩特征为代价保留图像背景信息与纹理信息[20],通常采用均值池化法或最大池化法。由于最大池化法可以更大程度保留纹理信息,因此在语音增强[21]和语音识别[22]等领域大都采用最大池化法。本文同样也选择最大池化。DCNN层最后的输出最终将通过三层全连接层,全连接层的激活函数选择RelU函数。
本文提出的DBLSTM-DCNN语音特征映射模型图如图5所示,其整体分为DBLSTM层与DCNN层前后两个部分。DBLSTM层借助BLSTM能够保存上下信息的特性,用来提取和保存相邻帧之间隐藏信息。DCNN层则利用卷积神经网络(Convolutional Neural Network,CNN)可以提取相邻区域局部特征的功能来学习出相邻频域之间的隐藏信息。
本文首先将连续的15帧(前后各7帧)语音特征(谱包络、非周期成分与基频)输入到由4层BLSTM构成的DBLSTM层中,借助BLSTM提取和存储上下文之间隐藏的时域相关性。DBLSTM层之后连接由4层CNN组成DCNN层,利用CNN能够提取局部特征的特性来学习相邻频域之间的联系,DCNN层之后的输出最终将通过三层全连接层。全连接层作用主要有两点,一是对提取到的特征进行降维,二是增加非线性拟合程度。DBLSTM-DCNN模型的输入是上下文连续的15帧语音特征(前后各7帧),最终得到的输出是估计的第8帧语音特征。通过实验也表明该模型能够较好地实现BCM与ACM语音之间的语音特征映射。
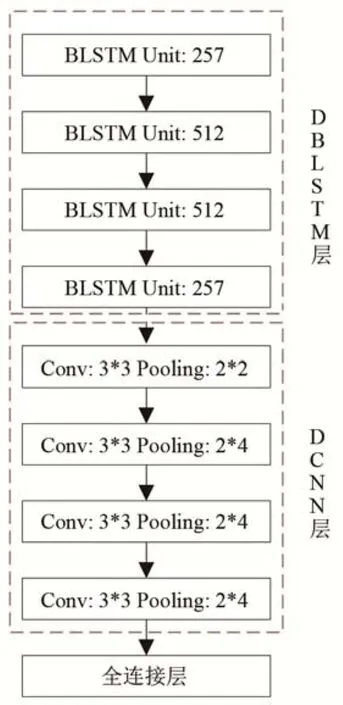
图5 DBLSTM-DCNN模块Fig.5 DBLSTM-DCNN module
2 仿真实验及结果分析
由于当前没有公开可用的数据库,本文录制了通过高灵敏振动传感器、信号放大器以及相关软件得到的BCM语音与由普通麦克风采集的ACM语音的平行语音数据库。该数据库的录音语料来源于北京语言大学创办的BCC语料库中精心挑选的包含体育、艺术、生活等方面的500条具有代表性的语句。选择年龄在20~24岁之间的两名男性与两名女性作为说话人完成录制,说话人使用标准普通话进行录制。录制的语音采样率为32 kHz,并采用16 bit量化。每名说话人录制320句从语料库中抽取的语句,每句话时长约2~3 s,同时要求吐字清晰且语气没有明显波动,其中300句作为训练集,20句作为测试集,并要求彼此之间没有重复的语料。
由于要建立骨导语音转正常音的模型首先需要不包含噪声的气导语音作为目标训练集,将同步录制骨导语音转换成气导语音。除此之外骨导语音是通过高灵敏振动传感器采集人说话时在喉头部位的振动,再通过信号放大器、数据采集卡和EM9118B虚拟仪器对信号进行收集,最后在通过Matlab软件将其转换成对应骨导语音。可见骨导语音的采集与周围环境有无噪声没有关系。因此本文实验并未涉及在强噪声环境下的语音转换实验。
2.1 实验参数设置
实验中为每名说话人训练一个语音转换模型。训练语句有300句,测试语句20句。训练数据和测试数据均被下采样到16 kHz。在本文中设定帧长为32 ms,帧移为10 ms,语音在进行FFT变换时点数设置为512,故谱包络与非周期性成份特征长度为257维。该实验使用15帧作为特征窗口(前后各7帧),时间步长也设置为15帧,因此在特征映射模块中的BLSTM层的隐藏层中存储有来自上下文的15帧信息。BLSTM层中每一层的隐藏单元数如表1所示,其中隐藏层激活单元为RelU。而包含15帧上下文信息的BLSTM层输出序列在传递到DCNN层中,借助CNN能够提取局部特征的功能,最终输出中间帧的预测特征。DCNN中每层的卷积核大小都为3*3,池化层大小如表1所示。该实验中mini-batch设置为128,并且将均方误差(Mean Squared Error,MSE)作为损失函数来训练网络。初始学习率设置为 0.001,如果连续两轮损失没有减小,学习率将减少50%。
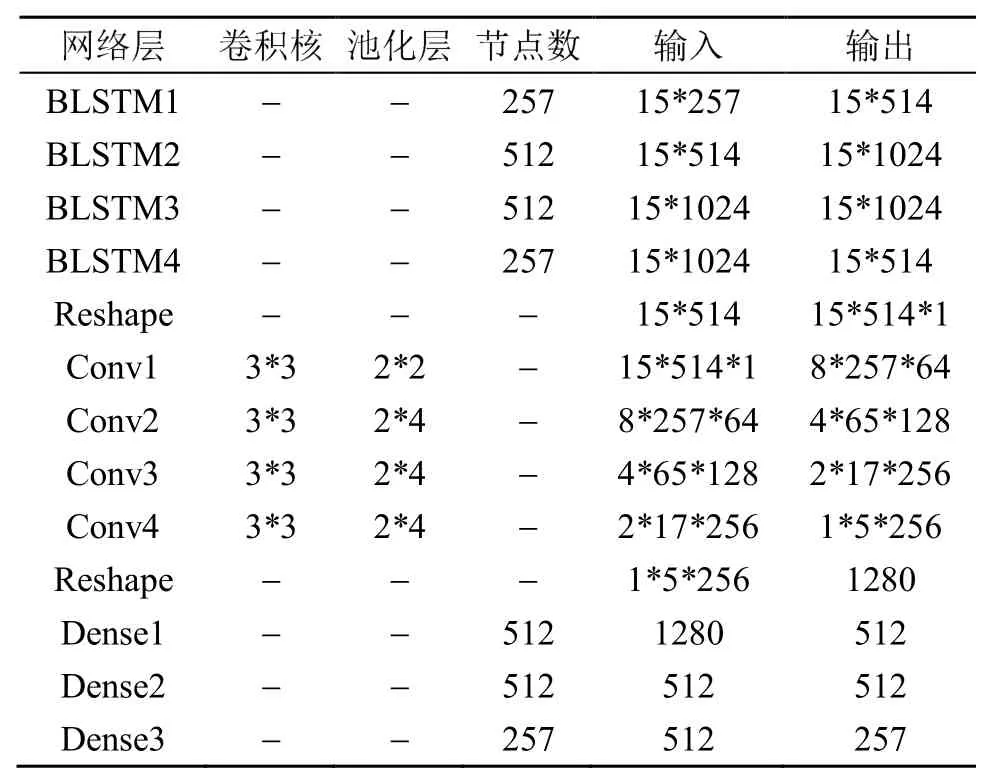
表1 DBLSTM-DCNN模型参数设置表Table 1 Parameter setting of DBLSTM-DCNN model
2.2 评价指标以及实验结果分析
本文采用语音质量感知评价 PESQ,短时客观可懂度STOI和对数谱距离LSD这三个指标来客观评估语音质量。PESQ分数衡量整体语音质量(−0.5~4.5,分数越高越好),STOI分数衡量语音清晰度(0~1,分数越高越高),而LSD衡量两个信号之间的对数频谱距离(分数越低越好)。
在平均主观意见分(Mean Opinion Score,MOS)[23]测试中,听众被要求使用5分制评分,分值为0~5,对应的PESQ评分范围为−0.5~4.5。4名志愿者(2男、2女)参与了这项测试。进行平均意见评分(MOS)测试,获得主观评价。
本文的对比实验BLSTM模型来自文献[9]提出的转换模型。使用4层连续的BLSTM来实现BCM语音的转换。4层BLSTM隐藏单元的数量为[257,512,512,257],激活函数设置为RelU,同时为了提高模型的非线性拟合能力以及防止过拟合,每层隐藏层之后都添加有dropout值为0.7的dropout层。而本文的另一个对比实验模型是深度神经网络(Deep Neural Network,DNN),一个包含3个隐藏层的DNN模型。该模型的网络结构为[514,512,512,512,257],并采用ReLU函数作为隐藏层的激活函数,同时为了提高泛化能力,在每层隐藏层之后加入dropout值为0.7的dropout层。
为了证明本文提出的DBLSTM-DCNN转换模型在骨导语音转气导语音的有效性,将本文所提方法与BLSTM模型进行比较,实验结果如表2所示,其中BCM指每名说话人的BCM语音与其ACM语音在不同评价指标下的对比结果,BLSTM与DBLSTM-DCNN表示使用2种转换算法转换后的语音与ACM语音的对比结果。其中说话人以M1、M2、F1、F2表示,M代表男性,F代表女性,M1即序号为1的男性。Avg是根据4名说话人在不同转换模型下的评价结果计算出来的平均值。
从表2可以看出,无论是DNN模型,BLSTM模型还是DBLSTM-DCNN模型,转换后的语音LSD都明显减小,说明DNN模型一定程度上可以学习到骨导语音的高频信息,BLSTM单元确实可以有效提取时域维度的隐藏特征,与DNN模型和BLSTM模型相比,DBLSTM-DCNN模型得到的转换语音LSD分别降低了15%和5.36%,表明同时考虑到时域维度与频域维度的DBLSTM-DCNN模型更适合BCM语音的转换。同时相比于DNN模型和BLSTM模型,DBLSTM-DCNN模型在PESQ上也有所改善,PESQ分别提高了22.66%和12.07%,表明该深度神经网络能够有效提高BCM语音的感知语音质量。且DBLSTM-DCNN模型的STOI相比 DNN模型和BLSTM模型分别提高了11.3%和6.01%,表明DBLSTM-DCNN模型转换得到的语音幅度谱更接近正常语音的幅度谱,且语音可懂度更高。表3给出了BLSTM模型与DBLSTM-DCNN模型转换后语音的MOS值。由表3可看出,DBLSTM-DCNN转换语音的MOS值比DNN和BLSTM方法分别提高了24.7%和18.91%,表明与BLSTM相比,DBLSTM-DCNN模型能够得到更高质量的转换语音。

表2 BCN,DNN,BLSTM与DBLSTM-DCNN模型的评测标准PESQ、STOI、LSD对比表Table 2 Comparison table of the evaluation criteria PESQ,STOI and LSD for BCN,DNN,BLSTMand DBLSTM-DCNN models
图4分别给出气导语音、骨导语音、BLSTM及DBLSTM-DCNN模型转换后语音的语谱图。图4(a)为气导语音的语谱图,说话人在发音时声带产生的激励信号会经过口腔、鼻腔、嘴唇等调音区,因此与其对应的摩擦音、爆破音、清音等辅音音节保存比较完整。从图4(b)中可以看出,骨导语音在高于3 kHz的部分几乎完全衰减,能量趋近为0。图4(a)在1.4~1.5 s的高频部分是辅音音节,辅音只有高频部分,没有低频部分。图4(a)中辅音音节保存完整,而骨导语音缺少高频成分,可见图4(b)中摩擦音、爆破音、清音等辅音音节丢失较为严重。从图4(c)中可以看出,通过BLSTM模型转换的语音在高频部分虽然频谱有所恢复,但是频谱的声纹信息的细节与ACM语音相比仍有一些差别,这是由于BLSTM仅仅利用相邻时域的相关性进行建模,没有考虑到骨导语音在高频区域的特殊性,无法对骨导语音的相邻频域进行频域相关性的建模,转换语音在高频部分的预测效果也因此有所瑕疵。而从对比图4(d)中可以看出,虽然DNN能够一定程度上对骨导语音的高频区域进行建模,但是仅仅是包含部分能量,无法对频谱细节进行映射,这是由于DNN不能对频域与时域相关性进行很好的提取。对比图4(a)、图4(c)、图4(d)和图4(e)可以发现,采用本文方法转换的气导语音和目标气导语音在频谱结构上拥有更高的相似度,比如在1.5~1.8 s之间,高频部分声纹信息比较清晰与完整、层次分明,而且低频部分的频谱细节也较为相似。同时,从语谱图4(a)~4(e)中1.4~1.5s之间的高频区域可以看出,图4(c)和4(e)都能较好的恢复骨导语音的辅音音节,其中4(e)的辅音部分与4(a)更为接近。在 1.4~1.5 s之间,摩擦音、爆破音、清音等辅音音节恢复效果较好,可见使用本文方法转换的语音更加接近气导语音,表明本文方法转换的语音优于DNN模型和BLSTM模型转换的语音。

表3 DNN,BLSTM与DBLSTM-DCNN模型转换后的语音MOS值对比Table 3 Comparison of voice MOS values after speech conversion by DNN,BLSTMand DBLSTMDCNN models
3 结 论
语音信号具有很强的时域与频域相关性。相比于传统的GMM和BLSTM等专注于上下文信息(时域信息)的语音转换算法,本文提出了一种基于DBLSTM-DCNN的依赖于说话者的BCM语音转换模型。该模型利用DBLSTM层来收集时域信息并保存,再通过DCNN层来提取频域特征,最终达到同时考虑时域与频域相关性的效果。
DBLSTM-DCNN模型的语音转换是通过WORLD声码器先提取出来的谱包络、非周期性成分和基频三种特征,再分别利用DBLSTMDCNN_sp、DBLSTM-DCNN_ap和DBLSTMDCNN_f0模型实现上述三种特征转换,最终由预测出来的三种气导语音特征合成出转换语音。客观和主观的评估结果表明,BCM语音质量均有所提高。本文提出的DBLSTM-DCNN模型在一台拥有GTX 1080Ti显卡的电脑上进行实验需要花费60 h左右的时间。未来的研究工作包括优化模型进而缩减实验时间,将更高级的模型(如添加注意力机制)以缩小生成的骨导语音高频成分与气导语音高频成分数据分布间的差异,在BCM转换中引入多模态特征(人在说话时唇部视觉信息也包含语音信息)。
