基于RGB-D图像弱监督学习的3D人体姿态估计*
2022-01-21申琼鑫
申琼鑫, 杨 涛, 徐 胜
(福州大学 物理与信息工程学院,福建 福州 350116)
0 引 言
人体姿态估计是对图像或视频数据中的人的关节点位置进行检测并还原的过程。根据估计结果的数据维度的不同分为2D人体姿态估计和3D人体姿态估计。目前,2D人体姿态估计技术获得了较大进展[1]。Toshev A等人[2]首次提出了人体关键点解决方案,使用级联形式的卷积神经网络(convolutional neural network,CNN)完成更准确的姿态估计。现在大多数的3D人体姿态估计都是在2D姿态估计的基础上完成的。Wang K等人[3]提出长短期记忆( long short-term memory,LSTM)网络架构,利用自顶向下的反馈机制,从而达到优化关节点的目的。Bogo F等人[4]提出自监督校正机制,其本质是利用了同一个姿态的二维特征和三维特征的一致性。上述研究从不同的方向上去优化关节点的位置,在效果上都取得了不同程度的提升,但基本上采用的的都是强监督学习模型,其需要大量的带标签的数据。
本文提出一种基于RGB-D图像的弱监督学习模型实现3D人体姿态估计的方法。采用一种端到端的弱监督模型,解决数据标签不足的问题,并在弱监督模型中对生成的2D热图进行积分回归,克服基于热图估计的方法中所存在的缺陷,同时改善3D回归网络模块,以实现减少网络运算量,降低训练时间的目的。
1 3D人体姿态估计的实现原理与方法
本文所使用的网络整体实现具体框架如图1所示。1)将深度图像或者彩色图像作为网络输入;2)图像数据通过2D姿态估计模块生成热图,即H2d;3)将热图进行积分回归,生成对应的关节坐标J2d;4)将关节点坐标作为3D回归模块的输入,回归出3D关节坐标H3d,最终实现3D人体姿态估计。
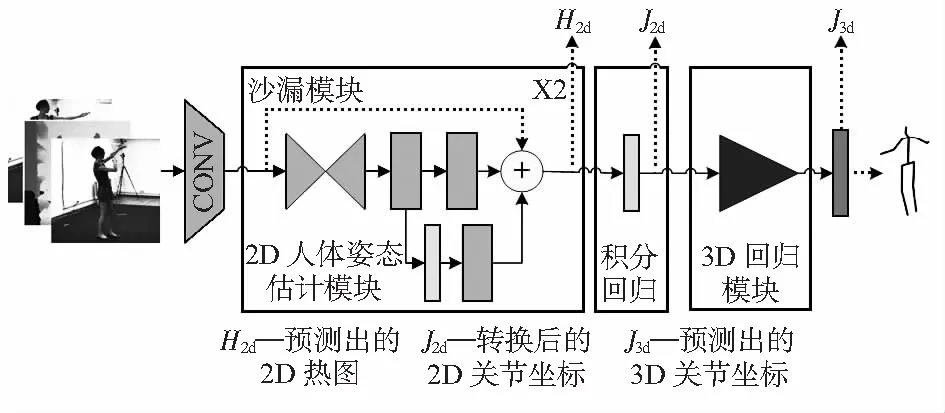
图1 3D人体姿态估计弱监督网络模型
2D姿态估计网络模块采用了沙漏结构作为该部分的主体网络[5],通过重复自下而上,自上而下推理的机制,重新评估整个图像的初始估计和特征。整个沙漏结构不改变特征的尺度,只改变特征的深度,并且采用中继监督训练方式,因此,在堆叠网络结构时不会出现梯度爆炸的问题。并在网络中加入积分回归操作[6],基于热图回归的方式虽然表示方便且容易组合其它深层特征图,但其存在着固有的缺陷,考虑到直接监督坐标的效果不如监督热图,需要将两者结合起来。因此,可以通过将热图转换成关节点坐标,从而避免这些缺点。使用积分回归的优点在于积分函数是可微的,允许端到端训练并且输出是连续的。对于3D回归模块所采用的结构如图2所示,其包含线性(linear)层、批归一化(batch normalization,BN)、ReLU(rectified linear units)层、Dropout层,称之为Block[7]。用于得到最后的3D关节点坐标。可以看到这部分网络使用线性层进行运算,因此,能够大幅减少网络运算复杂度,节约运算成本,并且对于网络超参数的训练也比较容易。根据实际情况可以选择级联多个Block作为回归模块。
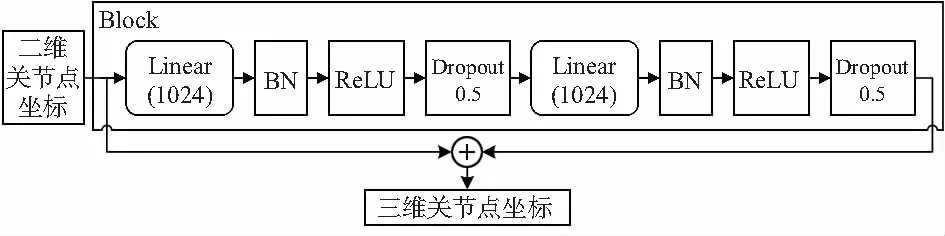
图2 3D回归模块单元示意
2 功能模块设计
2.1 概 述
本文目标是对于给定的彩色图或者深度图能够估计出其对应的3D人体姿势J3d。本文提出的网络框架包括2D姿态估计网络和深度回归模块。
2.2 2D姿态估计模块
本文采用沙漏结构作为2D姿态估计模块,用于预测人体各个关键点的位置。考虑到运算的规模和速度,选择使用2个沙漏结构构成轻量级的2D估计模块。该网络输出的是一组包含J(J=16)个关节点的低分辨率热图。2D模块的输入是经过预处理后的数据,图像分辨率为256×256,热图输出的分辨率为64×64。训练2D模块所使用的损失函数为
(1)
2.3 姿势积分回归
针对2D姿态检测模块输出的热图进行关节坐标转换,对于提升估计网络模型的性能是很有必要的,因为热图进行转换成关节坐标之后,后续网络不会再要求热图保持更高的分辨率,因此能够大幅减少后续网络的运算复杂度。对2D热图进行积分,关节被估计为热图中所有位置的积分,并根据概率加权求和做归一化。由于积分是没有参数的,因此在计算和存储方面带来的开销很小。转换公式分别为
(2)
(3)
式中Jk为转换后的关节点,Hk为热图,k为正则化的热图,Ω为Hk的域。
2.4 三维回归模块
回归模块的主要任务获取各个关节的深度信息。此模块镶嵌在2D姿态估计的后面,因此在进行端到端的训练时,会充分利用权重共享功能。并且可以通过实验确定构成3D回归网络所需要的Block数目。3D回归网络训练的Loss函数为
(4)
式中xi为通过2D检测器或照相机标定的二维关节坐标,yi为预测的各关节的三维坐标,N为关节点数目。
3 实验与结果分析
3.1 实验数据集
本文的实验数据集包括RGB数据集MPII[8]、Human 3.6M[9]和深度数据集ITOP[10]、K2HGD[11]。使用MPII中的2万张图像进行训练;使用Human 3.6M中的5万张图像进行训练,1 000张作为测试;ITOP包含3D关节标签的深度图,但其数据量不充足且不准确,因此将其纠错后作为测试样本;使用K2HGD中的1万张图作为训练样本。由于深度图和彩色图包含的信息不一样,不能直接进行混合训练,因此将彩色图数据进行灰度处理,从而减少数据信息不同造成的干扰。
3.2 实验细节和评价标准
本文使用Human 3.6M和ITOP数据作为测试样本,并将本文的方法与文献[7]进行对比实验,比较其精度、参数量、训练时间三个指标。本实验基于Torch平台,训练采用的学习率为0.001,batch-size的尺寸为16,分两个阶段进行训练,第一阶段仅使用2D标签数据训练2D网络,第二阶段使用3D标签数据集训练整个网络。实验使用NVIDIA GTX1060显卡,64位Ubuntu系统,Intel i5—7600CPU。使用平均精度(mean average precision,mAP)作为评价标准,通过计算网络预测得到的关节点坐标与真实标签的人体关节点坐标之间欧氏距离,当距离小于设定的阈值即认为估计正确。
3.3 实验结果与分析
为了更加科学地选择3D回归模块所用的堆叠模块Block的数目,对Block数目不同的模型分别在彩色图像Human 3.6M和深度图像ITOP上进行实验测试,并与文献[12]所提出的方法进行对比试验,分别将Human 3.6M和ITOP数据上的测试结果进行可视化如图3所示。

图3 3D姿态估计可视化结果
表1给出了ITOP数据集上各关节的预测精度。在表2中给出其对应的准确率、训练时间、参数数量三个指标。
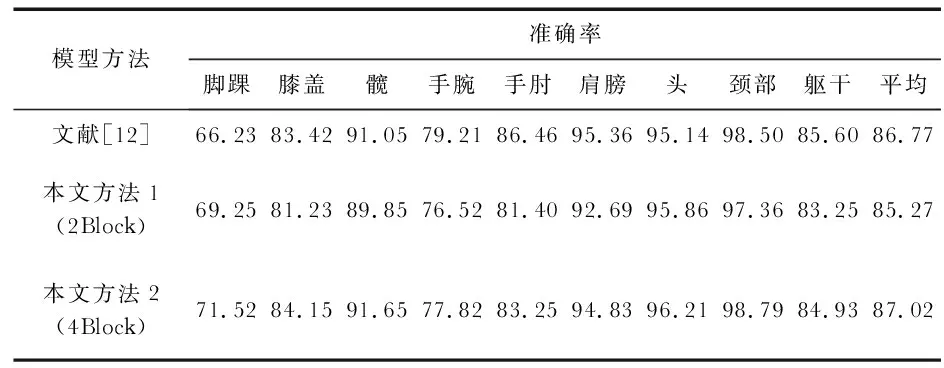
表1 模型在阈值为10 mm时的各关节精度 %
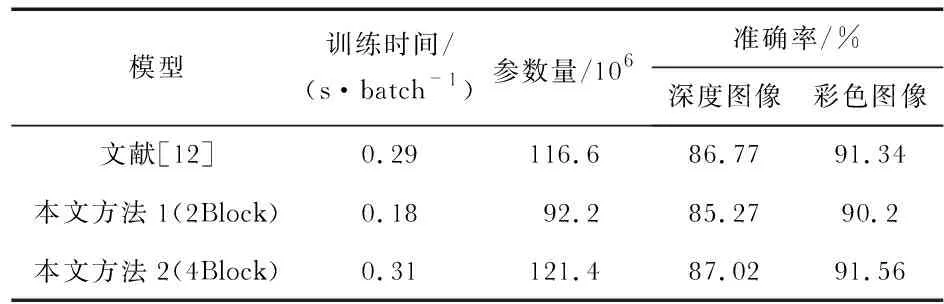
表2 模型性能比较
根据表2的结果可以看出,使用4个Block堆叠模块,其精确度确实增加了,但是其训练时间和参数量也增多了,考虑到网络的轻量性,选择2个Block堆叠模块的模型作为3D回归模块。实验结果表明:加入积分回归的思想,是有助于减少整个网络模型的参数量和训练时间的,相比于文献[12],本文方法参数量减少了20.9 %,训练时间减少了37.9 %,并且该模型同时适用于彩色图像和深度图像。但本文所提供的方法在精度上略有降低了,相比于文献[7],在深度图数据集上降低了约1.5 %,在彩色图上降低了1.14 %,其中的原因可能在于两个方面:1)网络模型训练规模太小,从而导致精度的下降;2)彩色图数据集的数量远大于深度图数据集,因而在深度图上损失了更多的精度。
4 结 论
本文提出了一种基于RGB-D数据的一种弱监督学习网络模型实现3D人体姿态估计的方法。方法的核心思想首先在于将基于热图回归的方式转换为基于关节点的回归;其次是将彩色数据与深度数据进行关联,使得该网络可以同时适用于彩色图和深度图。方法主要在降低训练时间和参数量两个方面做出了努力,并取得了一定的进步,但也损失了一部分估计精度。因此,后续还需要在轻量级网络的基础上往提高精度方面继续展开研究。
