基于强化学习的六足机器人动态避障研究*
2022-01-21董星宇唐开强傅汇乔留沧海
董星宇, 唐开强, 傅汇乔, 留沧海, 蒋 刚
(1.西南科技大学 制造科学与工程学院,四川 绵阳 621000;2.南京大学 工程管理学院 控制与系统工程系,江苏 南京 210093;3.制造过程测试技术省部共建教育部重点实验室,四川 绵阳 621000;4.成都理工大学 核技术与自动化工程学院,四川 成都 610059)
0 引 言
地震救援机器人需要在非结构环境下实现救援搜索任务,六足机器人在复杂环境下行走高效,且具有较好的稳定性,是未来救援机器人的一大选择[1]。地震救援环境复杂,且震后易发生余震,救援环境由静态变为动态,机器人需要拥有动态避障能力。传统的移动机器人动态避障常用人工势场法、快速扩展随机树和动态窗口法等方法[2~4]。但是传统的动态避障方法,移动机器人需要依赖地图信息,不能在未知、动态、复杂环境下通过自身的传感器与环境交互进行避障决策。
近年来,由于深度学习(deep learning,DL)与强化学习(reinforcement learning,RL)得到国内外专家的广泛研究,涌现出大量基于深度强化学习(deep reinforcement learning,DRL)的机器人避障的研究成果。文献[5]提出对无人驾驶船舶在未知环境干扰下的深度强化学习避障算法。文献[6]提出了一种基于深度增强学习的AGV移动机器人,创建了一个移动机器人避障和导航模型。但传统深度强化学习即深度Q学习网络(deep Q-learning network,DQN)易出现收敛速度慢,算法偏差变大,难以收敛到最优动作状态值,而降低机器人动态避障的效果。
在不依靠环境信息的情况下,本文研究将六足机器人上的激光测距仪采集距离数据作为双重深度强化学习即双重DQN(double DQN,DDQN)的输入项,将速度与行进方向作为单片机控制输出,将每个时刻采集的传感器数据整合作为马尔可夫状态空间。结合传统DQN与双重深度强化学习DDQN算法相对比,对六足机器人进行训练、测试、验证。
1 双重深度强化学习算法
1.1 六足机器人运动建模
相对于传统的轮式和履带式机器人,六足机器人对复杂地形的适应能力更强但结构设计和步态规划却较为复杂。实验通过运动学逆解得到机器人腿部股、髋和膝三个关节角度,建立笛卡尔坐标系进行足端轨迹规划,控制舵机联合转动使六足机器人移动。
六足机器人的三足步态即通过控制机身一侧的前足、后足与另一侧的中足在运动时交替处于支撑相和摆动相[7]。图1为六足机器人在各步态下行进周期的稳定性表现,角度波动范围越小,机器人行走稳定性越好。图1(a)为三足步态,图1(b)为四足步态,图1(c)为五足步态,由图分析可知三足步态相较于另外两种步态虽然稳定性较小但其具有运动效率高,控制简单等优点。因本次实验环境不涉及较为复杂的多结构路面,故采用三足步态作为六足机器人的输出动作步态。

图1 六足机器人行进步态特征
1.2 强化学习
强化学习为一种标记延迟的监督学习,六足机器人在某t时刻感知的环境状态为st,通过策略采取动作at达到另一状态st+1,由环境反馈获得交互动作的奖惩回报rt,与环境交互的整个过程表现为马尔科夫决策序列过程,整体可以表示为(st,at,rt,st+1)[8]。
经典的强化学习Q-learning算法通过当前状态和动作决策进行不断试错,其目标是使总折扣回报最大化[9]。然而,传统的Q-learning算法对输入变量的复杂性非常敏感。当离散的值函数面对高维或连续的状态空间时,必然会大大增加计算时间,并导致难以收敛,甚至引发维数灾难[10]。
2015年,Silver D提出了一种基于卷积神经网络(con-volutional neural network,CNN)的深度强化学习算法DQN,它是由多层神经网络组成的深度强化学习,作为替代传统离散值函数的一种解决方案。神经网络强大的适应能力使得逼近动作值函数成为可能。并且通过使用深度强化学习,将状态变量为矩阵形式的大量输入替换为一个连续变化的函数值,从而解决了维数灾难的问题[11,12]。
1.3 DDQN算法
虽然基于DQN的策略在一些机器人动态避障的问题上得到了成功的应用,但是在选择行动和评价价值函数时使用相同的网络存在一定缺陷,这可能导致对结果的过度乐观估计[13]。为了避免这种情况产生,使用一种双重深度强化学习算法,其与传统DQN结构类似,同样具有两个相同结构的Q网络。但与其不同,DDQN通过解耦目标Q值动作的选择和目标Q值的计算来消除过度估计的问题和使用经验回放来避免训练数据的相关性[14]。通过实际动作价值Q网络在现实中训练参数,迭代C次后将权重复制更新到目标动作价值Q网络中以降低过估计对训练结果的影响。DDQN的目标值可以定义如下
Qtagret=r+γQ(s′,argmaxaQ(s′,a|w)|w′)
(1)
式中γ为折扣因子,w为Q现实中网络结构权重,w′为Q估计中网络结构权重,s′为下一时刻感知的环境状态,a为选择的动作,r为奖惩回报值。DDQN模型示意如图2所示。

图2 DDQN模型
2 机器人运动决策模型
2.1 数据预处理
为了提高训练的收敛速度,保证训练后的模型具有较好的效果,将机器人与环境交互得到的输入数据进行降维化处理[15],通过传感器距离数据集输入来避免高维深度信息带来的收敛速度较慢和计算复杂的问题。将六足机器人不能够跨越的地方看作障碍物,满足六足机器人运动学参数要求的路况作为可通过的路径。
通过激光测距仪和超声波传感器采集距离数据集,得到机器人在行进过程中与局部障碍物距离的数据矩阵,机器人行进速度为vrot,采集下一组数据集间隔时间为t,根据公式可判断出障碍物运动速度vbar
(2)
式中xt为机器人距障碍物在t时刻的距离,sbar为障碍物运动状态值,设立相对速度的阈值为3 cm/s,当vbar>3时标定障碍物运动状态为动态障碍物,令sbar=1;反之标定为静态障碍物,令sbar=0。通过加速度传感器进行惯性导航,来确定机器人在行进过程中的位置,以此来判断机器人是否到达目的地。当数据集出现异常值即出现不正常数据时,此时通过运动学的方式控制机器人的运动。数据集正常情况时,将数据集、障碍物运动状态值和障碍物运动速度作为机器人的状态,进行双重深度强化学习训练网络参数。
六足机器人的动态避障算法主要运用卷积神经网络对机器人在局部环境中,如图3中坐标轴对应的四个方向特征提取障碍物的距离和速度数据。

图3 避障建模效果
在实际情况下障碍物并非质点,为保证六足机器人在行进过程中能感知障碍和具有实际避障能力,四个方向的取值角度为80°,间隔20°取值一次,即一个方向取值个数为5次,如图3(a)所示。其避免因数据取值过少而导致六足机器人避障失败。机器人机身全长为lhex,安全距离系数为ε,则机器人有效移动的安全距离为
dsafe=ε·lhex/sin40°
(3)
故当d0°≥dsafe或d80°>dsafe时,机器人可进行避障后的有效动作,否则视为机器人还未成功躲避障碍。
六足机器人攀爬台阶的能力是通过机身底部两个不同放置方式的超声波传感器判定,如图3(b)所示。当倾斜30°放置的超声波和同方向激光测距仪检测的距离无较大改变,而水平放置的超声波检测到障碍物则执行向上攀爬动作;当水平放置的超声波和激光测距仪检测距离无较大改变,倾斜30°放置的超声波检测距离突变,则执行向下攀爬动作。台阶高度位置应处于机器人底盘高度和激光测距仪放置高度之间。
2.2 DDQN模型
强化学习模型所建立的神经网络设计为一层输入层,四层隐藏层和一层输出层,网络输出为各个动作对应的Q值,选择对应最大Q值的动作和环境相交互。样本池采用优先级抽样,样本的时序差分误差越TDerr大,其训练价值越高,被选中概率增加。DDQN策略的逼近器采用卷积神经网络,其模型的优化目标函数L(ω)为
TDerr=Qtagret-Q(s,a|ω)
(4)
L(ω)=E[(TDerr)2]
(5)
本文通过运用增量式ε-greedy探索和利用策略。在成功到达一定终点次数前,为保证探索率足够,设置εmax∈(0,1),成功到达目标次数N(suc)和增量Δε,由式(6)每回合更新ε值
ε=ε+ln(N(suc)+2)·Δεandε≤εmax
(6)
由取值[0,1]的随机数rand()与ε值比较,在当前时刻选择最优动作和探索未知状态进行平衡,加快神经网络模型收敛的速度,该策略定义为

(7)
2.3 动态避障行为与奖惩函数
由于DDQN与DQN方法都具有高维输入低维输出的特点,故六足机器人的执行动作设计为11个离散性动作的输出。如表1所示。

表1 执行动作设计
六足机器人通过控制舵机转速和轨迹断点数协同调节行进速度,舵机运行误差积累增加而导致偏航角发生改变。偏航角越大机器人行走偏移量越大,图4表示出机器人在三足步态下行走路程为120 cm时,3种代表性的不同行进速度下偏航角随时间的变化。
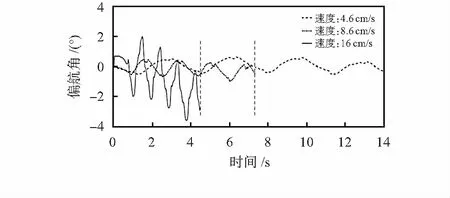
图4 不同行进速度下偏航角对比
由图4可知,为保证在速度和偏航角之间相对平衡,六足机器人在执行攀爬动作时为寻求机身稳定,采用行进速度为4.6 cm/s;而速度为8.6 cm/s比速度为4.6 cm/s时的偏航角误差改变量较小,速度却提高了进一倍,因此在无障碍和静态障碍物时,六足机器人以8.6 cm/s的速度行走;而当六足机器人在应对动态障碍物时,为保证躲避速度的要求,使机器人在满足能够承受最大偏航角误差下以速度为16 cm/s行走。
通过目标任务主次级分层制定奖励函数避免奖励稀疏,主任务为到达目标位置给予较大奖励;次级任务为静态、动态避障和快速抵达目标位置。定义机器人对障碍物最短距离为disrot。当disrot<0.2 m时,视为一次碰撞,给予惩罚值。根据机器人与目标位置的相对距离disFin进行奖励塑形,取0.4做为惩罚因子,相对距离越小惩罚值越小同时机器人停止不动给予惩罚。应对动态障碍时,防止因动态障碍物未完全驶离而导致机器人复碰撞情况产生,如图5所示。

图5 复碰撞情况示意
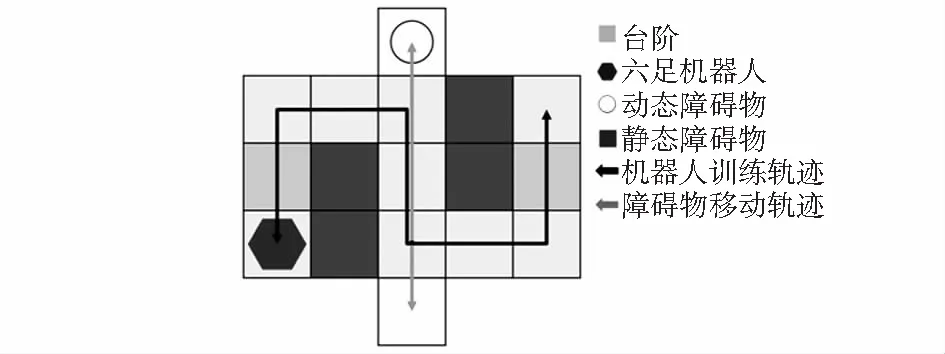
根据vbar和vrot估算出预计相撞时间为t0和预计躲避时间为t1。当t0>t1时,机器人躲避方向选择与障碍物移动方向一致时给予奖励;当t0 R=-(disFin)0.4+Rm(disrot,disFin|t0,t1) (8) 机器人移动平台为18个自由度的六足机器人,驱动硬件为单片机STM32F4。为解决运算速度的问题,电脑通过TensorFlow计算更新神经网络权重,根据策略决定执行的动作数据,通过ATK—HC05蓝牙模块与串口进行全双工通信,传输数据至单片机。机器人执行动作后将观测值反馈给电脑进行下一次更新,通过上下位机数据传输的方式避免单片机内存不足导致的计算速度缓慢,时延过大的问题。 通过在实验室搭建实验环境,为提高强化学习训练效率,本文采用对称式搭建尺寸大小为5.6 m×3 m的迷宫场景,机器人完成一次抵达终点任务后,目的地与起始位置交换;实验动态障碍物为四驱小车,小车沿移动轨迹以10 cm/s均速行进,每次行进到轨迹末端会等待3 s后再反向移动以此避免机器人很难避过小车抵达终点而导致损失函数难以收敛的情况;六足机器人训练轨迹和动态障碍物移动轨迹如图6所示,实际搭建的实验场景如图7所示。 图6 训练示意 图7 算法验证实验环境 本次实验设置两组相同网络模型参数的DQN和DDQN算法,网络模型训练参数:经验回放池样本数为12 000个,回合训练批量为60个,折扣回报系数为0.9,网络梯度动量为0.9,学习率为0.01,网络权重更新回合为100。令通信中的六足机器人在搭建好的迷宫内进行循环训练。在规定回合后机器人停止行动,对比两种算法的训练效果。 六足机器人的动态避障实验结果局部截图如图8所示,图8中(a)~(f)六种情况在全局环境下发生位置与图7中的标号相对应。 图8 六足机器人动态避障实验 在应对静态障碍物时,机器人通过策略选择常速动作稳定避开静态障碍物,如图8(a)所示;强化学习策略根据次级任务奖惩函数的设定,使机器人以最短回合数抵达终点,如图8(b)所示;应对动态障碍物时,机器人向旁侧闪避时间低于与小车相撞时间且旁侧无障碍物,则学习策略倾向于采取向旁侧躲避,等待小车完全驶离后再向前行进,以避免复碰撞的产生,如图8(c)所示;当机器人向旁侧闪避时间高于与小车相撞时间,学习策略大概率采取与小车运动方向同向移动, 如图8(d)所示;神经网络通过训练传感器采集得到的距离数据集,机器人成功对台阶进行攀爬,如图8所示。 图9为DQN与DDQN两种不同算法训练机器人动态避障后的结果对比。图9(a)可知,DDQN有效减少了平均状态动作值的过度乐观估计。图9(b)可以看出DDQN比DQN的损失函数收敛速度快。 图9 DQN与DDQN算法避障结果对比 针对移动机器人在智能决策控制下的动态避障问题,本文提出基于双重深度强化学习的六足机器人动态避障算法,与传统的深度强化学习方法进行比较,证明了双重深度强化学习在迭代训练收敛速度和防止算法结果偏差变大表现出更好的性能,六足机器人能够有效完成简单的动态避障任务。但本次实验的环境建模较小,只是针对性进行建模,故还不能应用于复杂的环境中,仍需要进一步研究。3 实验结果与分析
3.1 实验平台描述
3.2 实验过程设计

3.3 实验结果与分析


4 结 论
