面向不平衡样本的高校学生资助等级分类模型
2022-01-21郭佳君杨波朱剑林朱连淼余辉
郭佳君,杨波,朱剑林,朱连淼,余辉
(中南民族大学 计算机科学学院,武汉 430074)
学生资助是教育领域中一项不可或缺的重要工作.我国相关政府部门非常重视贫困生的问题.《2020年中国学生资助发展报告》指出,2020年全国累计资助学生14617.50万人次,增幅38.02%,资助资金2408.20亿元,增幅13.27%[1].但由于传统助学金评定方式存在贫困生认定依据片面、部分困难学生隐瞒不报、助学金分配名额不合理等问题,高校难以主动识别贫困学生.本文针对高校学生资助的问题,基于数据挖掘技术分析学生的在校行为,量化学生的人格特征,在高校学生资助样本不平衡的情况下实现精准资助,为高校学生资助工作提供参考.
1 相关工作
目前数据挖掘技术广泛应用于教育领域中.CHUI等人提出一种改进的基于条件生成对抗网络的深度支持向量机算法,为解决样本数据量较小的问题,结合CGAN,InfoGAN,ACGAN提出ICGAN生成更多训练数据,同时采用DSVM进行学生成绩的预测[2];郭鹏等人优化了K-means算法,去除离群点后基于样本分布密度选取初始聚类中心,采用改进的K-means算法对学生成绩离散化;后引入兴趣度,通过考虑兴趣度阈值的方式优化Apriori算法;通过挖掘分析得到课程之间的相关性以及不同课程的重要程度,进一步指导个性化教学工作[3].
在教育数据挖掘领域,有关学生资助的研究主要集中在我国,依据我国的资助政策,许多研究学者提出将大数据技术应用到高校精准资助工作中[4-5].
针对判断贫困生的特征指标,GUAN等人通过学生的校园卡使用行为、互联网使用行为和数字轨迹提取特征,结合学生之间的相关性和标签之间的相关性,预测学生应获得的助学金组合[6];针对校园卡中学生数据的异常情况,李克华提出改进的离群点检测算法识别噪声数据,然后提出面向学生轨迹序列的频繁模式挖掘方法提取特征,放入基于置信度融合的助学金预测模型中预测[7];针对用于助学金预测的算法模型,MA等人提出Apriori平衡算法,通过提出的平衡支持度对贫困生进行关联规则挖掘,然后使用半监督的K-means算法识别贫困生[8].
虽然当前方法在高校贫困生评定过程中取得了一定的成果,但仍存在特征维度单一的局限性.本文提出假设,除消费水平外,学生的人格特征与其经济状况存在一定的相关性.罗伏生等人的调查研究显示,贫困生的大五人格中的社交性、利他性和道德性与SCL-90总分呈负相关,适应性与除恐怖因子和躯体化外的其他因子呈正相关[9].宋传颖的研究表明,在卡特尔16型人格上,贫困生的独立性、聪慧性、敢为性、稳定性上得分较低,而在怀疑性、忧虑性和自律性上得分较高[10].本文结合大五人格理论与卡特尔16型人格量化学生人格特征.
同时上述相关工作忽略学生受资助情况不平衡的问题.根据《学生资助资金管理办法》,本专科生国家助学金资助面约为普通高校全日制本专科在校生总数的20%[11].按照受资助等级情况对学生进行分类,整体样本呈不平衡分布状态.因此本文在模型设计中融入解决数据不平衡的算法.
针对当前研究的不足,本文从特征维度和类别失衡两个方面进行改进,技术路线如图1所示.原始数据预处理后进入特征工程,其中将量化后的人格作为一部分特征以丰富特征维度.采用重采样的方式进行失衡处理以解决数据分布不平衡的问题.失衡处理结束后基于上下文信息构建模型,最后通过测试集进行模型的评估.

图1 技术路线图Fig.1 Technology roadmap
2 人格特征量化
依据大五人格理论,将人格特征描述为5个方面,分别是:开放性(Openness to experience)、严谨性(Conscientiousness)、外向性(Extroversion)、宜人性(Agreeableness)、神经质(Neuroticism).本文选择更符合助学金评选标准的严谨性进行研究.DUDLEY等人将严谨性细分为4个狭义特征,分别是努力性(Achievement)、可 靠 性(Dependability)、有 序 性(Order)、谨慎性(Cautiousness)[12].由于努力性和有序性更能反映出学生的行为习惯,因此本文对严谨性中的努力性和有序性进行量化,努力性和有序性的量化方式参考曹奕提出的量化方法[13].在本文中,努力性通过学生进出图书馆总次数以及借书总数量进行量化,以反映学生的努力程度.有序性通过学生就餐以及淋浴行为的真实熵进行量化,以反映学生行为的规律性.信息熵可以衡量信息的不确定程度,而真实熵则可以结合事件的时间顺序特征.以下是具体步骤.
首先将一天的24个小时按照每半个小时进行划分,划分成48个时间段,分别以1,2,3,……表示.例如凌晨00:15被表示为1,凌晨01:20被表示为3.将学生每天的就餐和淋浴时间计算出其所在的时间段后分别组成一个序列,然后通过真实熵衡量其自律程度.真实熵的计算公式如下:
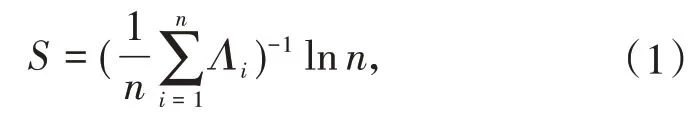
其中S表示真实熵,n表示序列的长度,Λi表示从i开始的、之前未出现过的最短子序列长度.例如,假设经过时间分区后,某学生某项行为的时间序列为[1,2,1,1],Λ的具体计算过程如图2所示.由图2计算得出Λ=[1,1,2,0],因此得到该学生真实熵的值约为1.3863.真实熵越小,表明学生的有序性越高.

图2 Λ计算过程图Fig.2 The calculation process diagram of Λ
依据卡特尔16型人格,本文选取更符合助学金评选标准的因素B聪慧性、因素G有恒性、因素Q3自律性进行量化.针对聪慧性,本文采用数据集中的学生成绩排名进行量化,由于学生所在学院不同、人数不同,因此将学生的排名根据公式(2)进行标准化处理:

x'表示标准化后的成绩排名,x表示数据集中的排名情况,xˉ表示平均值,σ表示标准差.针对有恒性,本文采用某时间段内学生按时吃早饭、午饭、晚饭,按时洗浴的频率进行量化.由于学生一餐内可能会有多次刷卡的记录,因此在数据处理的过程中只保留短时间内的第一次刷卡记录.Q3自律性与大五人格的有序性视为一致,不再单独量化Q3自律性.
3 LT-CFIN模型设计
3.1 CFIN模型原理
FENG等人提出的基于上下文感知的特征交互网 络(Context-aware Feature Interaction Network,CFIN)用于分析学生线上学习的行为活动,从而预测辍学率的问题[14].CFIN模型包括上下文平滑和基于注意力机制的特征交互两个部分,其中上下文平滑包括特征增强、特征嵌入和特征融合.使用MOOC中的用户信息和课程信息,结合注意力机制来学习不同活动的重要性,最后通过深度神经网络进行辍学率的预测.
3.2 LT-CFIN模型
CFIN模型能够较好预测线上学生的辍学率,但在长尾分布下分类性能不佳,本文基于CFIN模型针对助学金资助面小的特点,提出长尾分布下的基于上下文信息的特征交互网络模型LT-CFIN(Context⁃aware Feature Interaction Network for the Long-Tailed Problem).
3.2.1 样本重采样
在特征提取之后,首先通过BoderLine-SMOTE方法将样本数据进行重采样.BoderLine-SMOTE是使用处于边界的少数类样本进行新样本的合成[15].BoderLine-SMOTE将少数类样本分成safe、danger、noise三类,针对少数类样本来说,若样本周围有超过一半以上的样本为少数类的话就将其称为safe类;若样本周围有超过一半以上的样本是多数类的话,则将其称为danger类,也即边界上的类;若样本周围都是多数类的话,则将其称为noise类.BoderLine-SMOTE方法只针对danger类进行合成.生成新样本时,通过K近邻的方法选择少数类样本进行合成.BoderLine-SMOTE方法流程图如图3所示.以邻近样本属于多数类的比例为依据,创建danger类样本集合,并在该集合上合成新样本,进而组成样本数据进行后续实验.
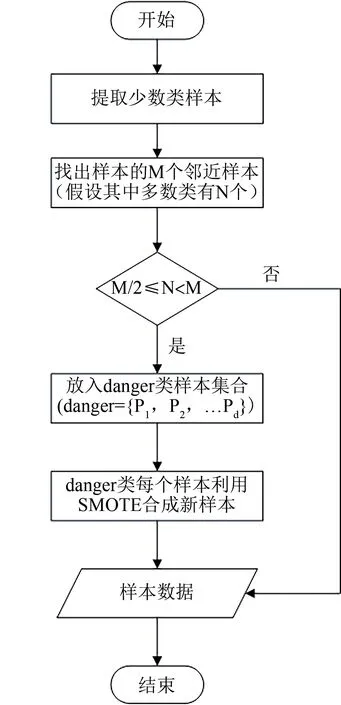
图3 BoderLine-SMOTE方法流程图Fig.3 Flow chart of BoderLine-SMOTE method
3.2.2 上下文平滑与注意力机制
在提取特征时,通过人格量化的方式进行了特征增强的过程,在上下文平滑的部分只采用特征嵌入与特征融合.每位学生的消费特征如公式(3)所示:

其中Vi表示不同的消费活动,i=1,2,…,m.通过特征嵌入和一维卷积神经网络将Vi转化成一个稠密向量V(i)d.基于注意力机制的特征交互的过程是首先将学生的人格特征以及所属学生类别等上下文信息特征放入嵌入层,再送入全连接层中得到稠密向量Vz.然后结合Vz和V(i)d计算注意力分数.注意力打分函数如公式(4)所示:
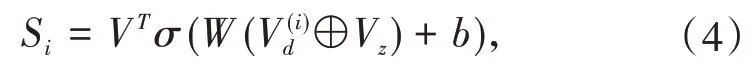
其中VT、W、b均为模型参数,σ(·)表示激活函数.通过公式(5)计算得到每个特征向量Vi的注意力分数αi:
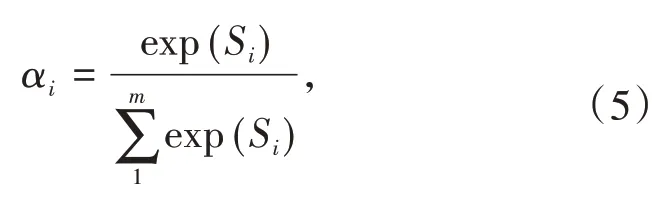
用加权平均的方式对输入信息进行汇总,根据att=得到权重和,之后输入L层的深度神经网络中进行训练得到预测值.
LT-CFIN模型训练图如图4所示.首先通过BoderLine-SMOTE进行数据重采样,重采样后将数据特征分为消费特征和上下文信息特征两部分,经过上下文平滑以及基于注意力机制的交互过程后,采用深度神经网络进行助学金等级的预测.
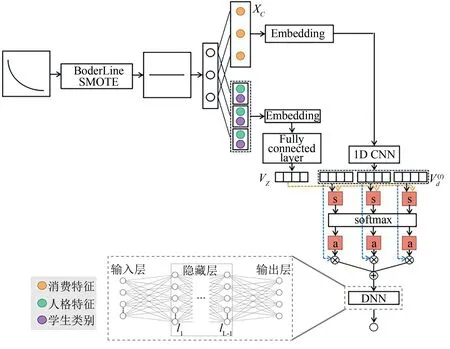
图4 LT-CFIN模型训练图Fig.4 Training diagram of LT-CFIN
3.3 性能评估
本模型针对不平衡数据集提出,选择AUC值作为评价指标.AUC是ROC曲线下的面积,同时考虑了分类器对各个类别的分类能力,即使样本不平衡,评价也较合理.AUC值越接近于1,表明分类器的效果越好.除此之外,选择打印混淆矩阵以直观地观察各类别的分类准确率.
4 实验与分析
4.1 数据集与问题描述
学生在校园内活动时,消费、图书馆和宿舍等一些场所进出都会被记录下来,并保存在校园卡数据中心,同时学生的成绩数据和受资助情况也分别被保存在学工部与资助中心.本文所采用的数据集为DataCastle官网提供的某高校2014、2015年的学生校园卡数据,该数据集已经过脱敏处理,数据内容包括书籍借阅数据、一卡通消费数据、寝室进出数据、图书馆进出数据、成绩数据以及受资助情况.数据集具体情况如表1所示.

表1 数据集描述Tab.1 Data set description
本文的研究目的是发现潜在的贫困生.在形式上,定义一组学生U={u1,u2,……,uN},N为学生总数.每位学生un的行为特征均包含消费行为相关特征XC(un)与上下文信息XZ(un),其中上下文信息包括学生的人格特征以及所属学生类别.根据上述相关特征学习函数f,预测每位学生资助档次y(un).数据集中学生受资助金额分别为0元、1000元、1500元、2000元,本文将其资助档次分别定义为第0档,第1档,第2档,第3档,因此y(un)∈(0,1,2,3).本问题可形式化描述为:

图5表示资助档次的分布情况,其中第0档资助类别占比86%,而第3档仅占3%,样本数据严重不平衡.因此本文所解决的问题是一个不平衡样本下的多分类问题.

图5 资助档次分布Fig.5 Funding level distribution
4.2 数据预处理
在数据集中存在完全相同的两条或多条数据,首先对数据集进行去重操作.
数据集中缺失值的处理均在去重操作之后,具体处理方式如表2所示.

表2 缺失值处理方式Tab.2 Processing methods of missing values
在一卡通消费数据中,消费类型除“POS消费”外,还包括“圈存转账”、“卡充值”、“卡挂失”等17种消费类型,本文只研究消费类型是“POS消费”的消费数据,因此消费方式的缺失率基于消费类型为“POS消费”的数据.寝室进出数据、成绩数据和受资助情况均未出现缺失值.
4.3 特征构建
本文所采用特征为消费行为相关特征XC(un)和上下文信息XZ(un).
消费行为相关特征XC(un)的构建方法如下.将消费记录分为生活、学习和其他三个类别.根据学生的id和消费类别,统计每位学生在各类别上消费金额的总和、最大值、最小值、平均值以及中位数.除此之外,对每位学生的消费金额和余额分别做各维度统计和消费总次数统计.消费行为相关特征及其含义如表3所示.

表3 消费行为相关特征及其含义Tab.3 Characteristics and implications of consumption behavior
上下文信息XZ(un)的构建方法如下.上下文信息包括学生的人格特征及所属学生群体.人格特征依据第二部分人格量化的方法进行构建.对于所属学生群体,本文根据学生学习类平均消费金额、生活类平均消费金额、其他类平均消费金额、努力性、有序性这些特征,采用K-means聚类方法对学生进行聚类,得到学生所属群体.聚类结果雷达图如图6所示,高校学生被分为4个类别.根据图6对每类学生进行分析,分析结果如表4所示.
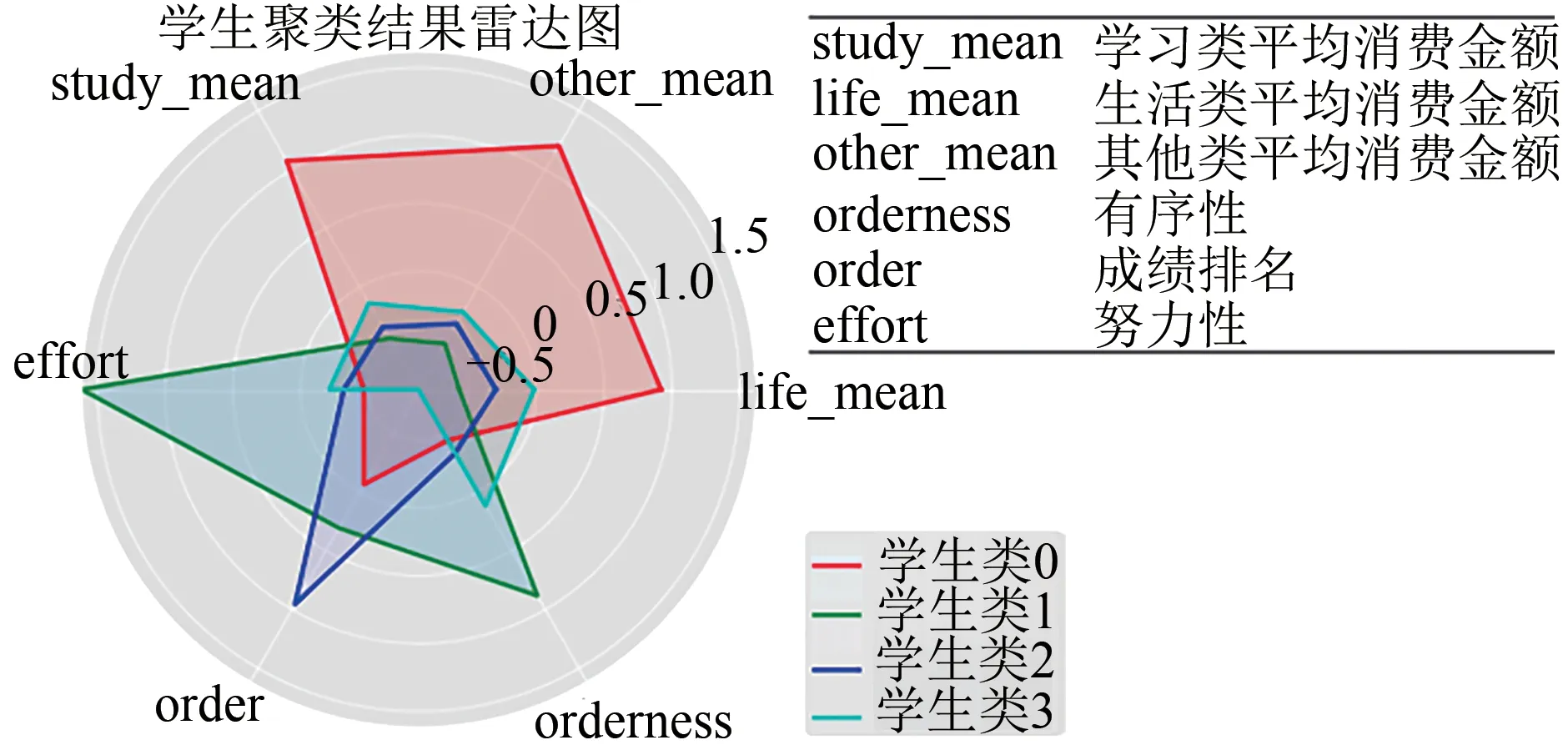
图6 学生聚类结果雷达图Fig.6 Student clustering results radar diagram

表4 各类学生分析描述Tab.4 Analytical description of the student categories
从表4可以得到,类别为1的学生群体,消费水平较低,且综合素质比较好,但成绩较差,可能有一部分原因来自家庭的压力,因此在相应资助时应该多关注学生类别为1的群体.而类别为0的学生群体,整体消费水平较高,因此考虑不需要得到资助.
上下文信息相关特征及其含义如表5所示.共包括12个特征,特征范围涵盖学生的生活习惯、努力程度、成绩排名以及学生所属类别.

表5 上下文信息相关特征及其含义Tab.5 Context information related characteristics and their meanings
4.4 结果分析
本文所采用的操作系统为Windows 10,计算机内 存 为8 GB,处 理 器 为Intel(R)Core(TM)i5-9300H CPU@2.40 GHz,编程环境为Python 3.7.LTCFIN模型基于TensorFlow实现,采用线性整流函数(Rectified Linear Unit,ReLU)作为激活函数,并采用自适应距估计(Adaptive Moment Estimation,Adam)进行优化,epoch设置为300,学习率设为0.0001.
为全面验证LT-CFIN的有效性,本文设计了3组对比实验,分别进行模型对比验证、失衡处理对比验证以及人格量化对比验证.
4.4.1 模型对比验证
将 决 策 树(Decision Tree,DT)、随 机 森 林(Random Forest,RF)、逻辑回归(Logistic Regression,LR)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)作为对比模型,将所有特征作为模型的输入,并采用基于网格搜索和五折交叉验证进行各模型参数的调整.各模型的实验结果如表6所示.根据实验结果可以看出LT-CFIN模型在预测学生的助学金等级情况时有较好的表现,与对比模型相比,AUC值有3.24%~4.81%的提升,证明了本文提出的LT-CFIN模型的有效性.
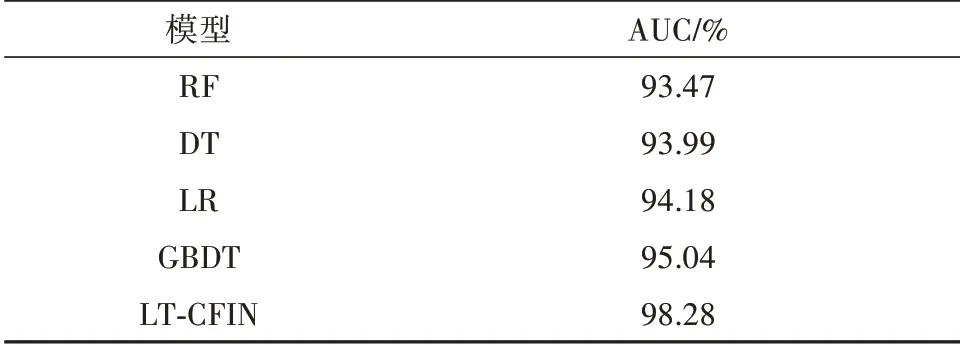
表6 不同模型实验结果对比Tab.6 Comparison of experimental results of different models
4.4.2 失衡处理对比验证
在不平衡数据集下,模型训练过程中会更多地关注数据样本较多的头部数据,但在现实生活中,高校资助部门需要更关注数量较少的贫困生.本文将LT-CFIN与未经过重采样处理的CFIN模型、采用SMOTE进行过采样后的CFIN模型、采用ADASYN进行过采样后的CFIN模型进行实验对比,实验结果见表7.可以看出未考虑数据不平衡的情况下,预测结果的AUC值为0.9158,通过使用SMOTE过采样方法,AUC值 达到0.9765,经 过ADASYN方 法 达到0.9768,但使用BoderLine-SMOTE仅对少数类的danger类过采样,AUC值比未经过处理的CFIN方法提升了6.7%.

表7 不同过采样方式下模型实验结果Tab.7 Experimental results under different over-sampling methods
由于本文更多关注学生获得助学金等级的情况,因此输出各类别的预测情况.图7(a)~(d)分别表示使用CFIN模型、SMOTE处理后的CFIN模型、ADASYN处理后的CFIN模型、LT-CFIN模型预测学生助学金的混淆矩阵结果图.其中混淆矩阵M第i行第j列的元素值M[i][j]表示真实类别为i的所有样本中被预测为类别j的样本比例.

图7 不同过采样方式下模型混淆矩阵结果图Fig.7 Results of confusion matrix under different oversampling methods
由图7可知,不平衡数据集下,CFIN模型将大部分样本预测为第一类,即未获得助学金,这样会导致准确率虽然较高,但在实际应用中存在较大误差的情况.经过数据重采样后,模型对原始数据集中的头部数据和尾部数据关注度相当,因此对实际应用也更具有参考价值.而LT-CFIN模型基于的BodelLine-SMOTE方法会解决SMOTE导致的生成样本重叠的问题,而且相对于ADASYN方法不易受离群点的影响.
4.4.3 人格量化对比验证
为证明学生人格特征对助学金预测的影响,本文进行了消融实验,只将有关消费信息的特征作为模型输入.表8表示将仅包含消费信息的特征作为输入和加入人格量化信息的特征作为输入的实验结果.
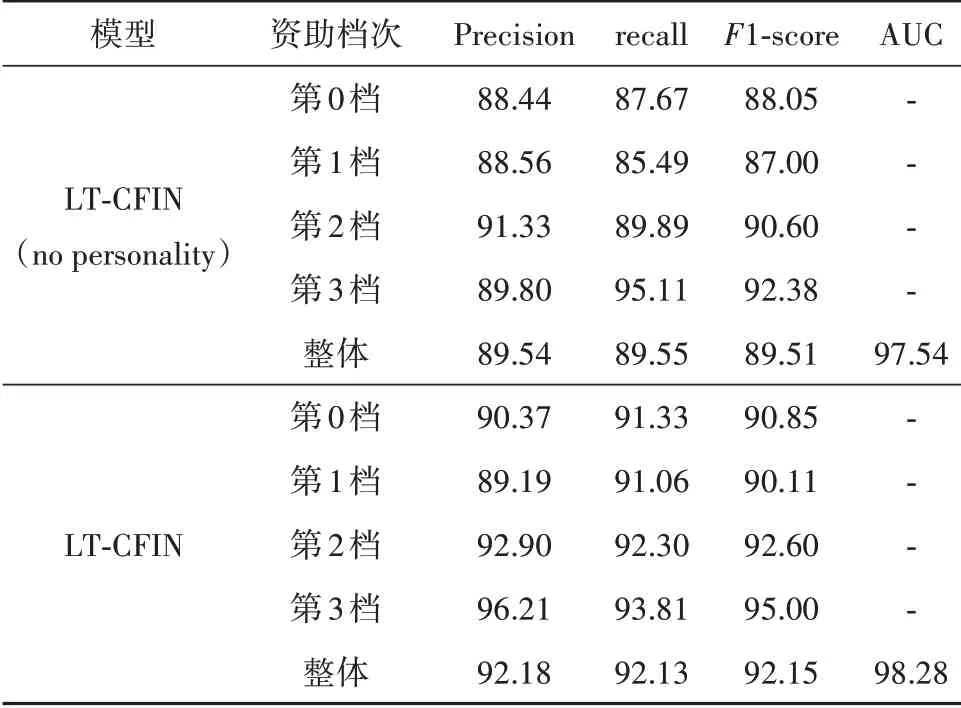
表8 人格量化前后实验结果 %Tab.8 Experimental results before and after personality quantification
由表8可以看出,通过对学生的人格特征进行量化,输入模型后,模型的预测效果有一定的提升,AUC值提升了0.74%,在各类别上,F1值提升幅度从2%至3.11%,实验结果验证了人格量化的有效性.
5 总结
由于学生助学金评定过程中存在主观的判断,本文基于数据挖掘技术预测潜在的贫困生,可为助学金的评定工作提供一定的参考.除考虑学生的经济状况外,量化学生的人格特征以反映学生的综合素质,从定量的角度为贫困生认定指标提供参考;结合学生的消费行为以及上下文信息,构建分类模型,实现对高校学生助学金等级的分类.实验结果表明:本文提出的LFCFIN模型可以有效掌握学生的经济情况,给出贫困生认定的建议,为进一步补充和完善贫困生的认定标准提供参考,同时能提高贫困生管理工作的效率.
