面向位置服务的K-Vretr隐私保护方法
2022-01-21唐朝生李鹏飞王成杰申自浩
唐朝生,李鹏飞,王 辉,王成杰,申自浩
(河南理工大学 计算机科学与技术学院,河南 焦作 454000)
1 引 言
得益于移动终端设备的多样性以及定位服务系统的迅猛发展,我们的生活发生了巨大变革,人们足不出户便可以获得想要的服务[1].穿衣有淘宝、吃饭有美团、住宿有飞猪、旅游有携程,人们能够通过各式各样的APP来随时随地获取服务[2],这一切都源自于基于位置的服务(Location Based Services,LBS)的迅猛发展.据统计,全球LBS和实时定位系统的市场占有率从2015年的113.6亿增加到2020年的549.5亿美元,年复合增长率为37.1%.
基于位置服务[3,4]是指基于移动设备的位置信息以及通信网络的信息传递,为移动用户提供各种各样的增值服务.随着人们对服务的需求增加,位置服务提供商(Location Service Providers,LSP)可能会为了自己的利益而将用户的隐私泄露给不法分子,威胁到用户的财产甚至人身安全[5].因此,在给用户提供便捷服务的同时保证用户的隐私安全成为一个亟待解决的问题[6].
2 相关工作
在面向位置服务的隐私保护[7]方面,基于K匿名[8,9]的空间泛化技术一直是学者们研究的热点.其核心思想是将用户的真实位置泛化,保证匿名区域(Anonymous Spatial Region,ASR)内至少包含K-1个用户,使得LSP无法从K个用户中区分出真实用户[10].现阶段基于K匿名的隐私保护技术也有较多研究.例如,贾俊杰等人[11]基于K匿名思想提出一种可抵制相似性攻击的(p,k,d)-匿名模型,采用基于距离的度量方法划分等价类,减少隐私保护中信息的损失.袁健等人[12]提出了K-Differential-Privacy隐私保护模型,采用噪声匿名组的思想,克服了现有算法对隐私预算过度依赖的弊端.郭敏等人[13]基于K匿名机制提出了r匿名的概念,引入一种时间混淆技术,在有限的计算成本下,增加了查询结果的正确性.Zheng等人[14]提出了一种基于K匿名模型的离群值剔除聚类算法,该算法通过以匿名组为中心代替用户位置的思想优化了用户在匿名组中的分布,但形成的ASR往往大于实际需要.Wang等人[15]结合差分隐私和K匿名的概念提出DPkA(Differe-ntially Private k-anonymity)方法,并给出了实现方式,但是匿名效率不高,在用户查询次数频繁的情况下容易受到连续查询攻击.文献[16]提出了一种基于层次分析法的K匿名算法,该方法在聚类过程中,总是选择距离最小的记录进行添加,并根据K值对聚类进行单独控制,实现等价类的均衡划分,但是当在用户密集的地方形成的K匿名区域较小时,攻击者依旧可以推断出用户的大致位置,安全性不高.
由上述研究方案可知,在生成ASR的过程中,在避免ASR受到攻击导致用户隐私泄露的同时,匿名效率与安全性能之间总是得不到很好的平衡.另一方面,现有的研究方法[17]大都将重心放在了位置隐私保护方面,忽略了用户的查询隐私保护.攻击者有很大的概率可根据用户查询内容推断出用户的敏感信息造成隐私泄露,甚至不能不考虑很多攻击者就来自于LSP内部人员.所以最好的方法就是用户在获取服务的同时不对外暴露任何信息.
针对以上问题,本文研究内容及所作贡献如下:
1)提出一种基于K匿名机制的K-Vretr(K-Voronoi retrieval)隐私保护方法.采用可信第三方架构,在减轻客户端与服务端负载压力的同时从位置和查询两个方面有效保护了用户的隐私.
2)针对匿名过程中构造ASR效率不高或安全度不够的问题,采用基于Voronoi图模型的K匿名随机位置隐藏方法,保证ASR安全性的同时满足了位置l-多样性,使得用户被攻击者识别的概率低于1/K.
3)在保护查询隐私方面,因LBS的特殊性及不可信性,故本文采用安全性相对较高的基于私有信息检索技术[18-21]的二次剩余假设模型,确保可信第三方服务器(Trusted Third Part server,TTPs)能从不可信的LBS中安全检索到想要的数据,有效防范了因LBS被攻击而造成的用户隐私泄露问题.
3 预备知识
3.1 系统架构
随着问题背景的深化和攻击模型的改变,位置隐私还将继续面临新的挑战,如LBS服务器容易遭受攻击,在不可完全信任LBS运营商的前提下,造成敏感属性泄露的风险是客观存在的.为保证用户隐私与服务质量,本方法引入TTPs,由用户端、TTPs以及LBS服务器构成可信第三方中心架构,如图1所示.在K-Vretr隐私保护方法中,TTPs与LBS服务器共同维护一份信息点集合.用户端将服务请求信息发送至TTPs,TTPs根据用户服务请求信息及自身缓存的信息点生成Voronoi图,按既定规则去选择K-1个其他V块中的虚拟用户与当前用户的虚假位置组成用户匿名集发送给LBS服务器.得到用户匿名集之后,LBS服务器根据用户目标信息点与K个用户之间的邻近关系生成关系矩阵.此后,TTPs从关系矩阵中检索目标信息并返回给用户,这是一次完整的服务请求.在整个隐私保护过程中,以TTPs作为总载体,完成了数据的集中化,只要保证TTPs的安全即可满足用户对隐私安全的要求.
3.2 相关定义
定义1.信息点(Point Of Information,POI):地理信息系统术语,泛指一切可以抽象为点的地理对象.例如生活中随处可见的医院、超市、健身房,甚至一个路灯等.POI的定义如下:
POI(Des,Cat,Coo,Cla)
(1)
其中,Des代表POI的唯一名称标识;Cat代表POI的类别;Coo代表POI的位置信息;Cla代表POI所属的分类,宏观分为1级类和2级类.POI的引入是为了增强对用户位置的查询和描述能力,并提高查询效率.

图1 通信模型Fig.1 Communication model
定义2.Voronoi图.设集合D={D1,D2,D3,…,Dn}为平面上n个POI的集合,满足
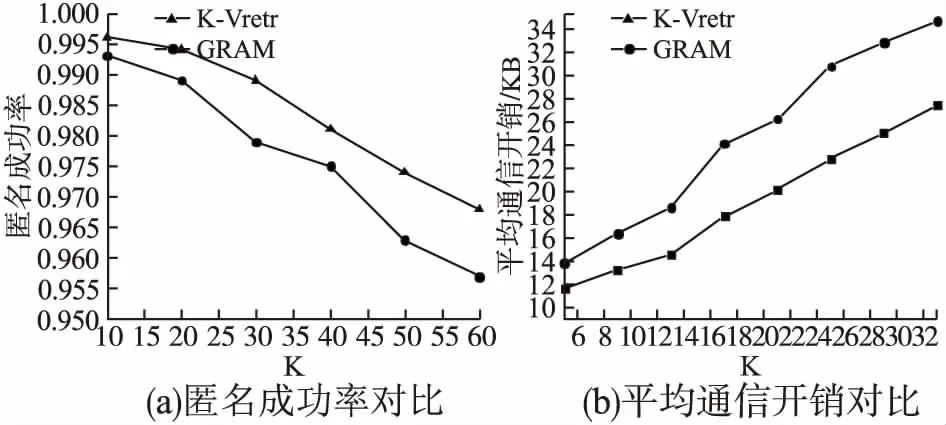
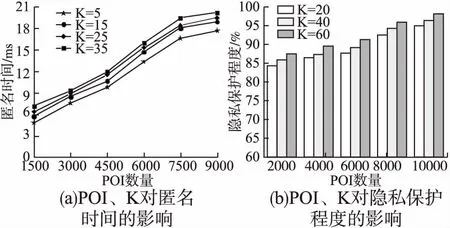
∀Di,Dj∈D,Eve∈Vi|S(Eve,Di) (2) 则为Voronoi图.其中,S(Eve,Dj)为点Eve到点Dj的欧式距离;Vi为Voronoi图中任意单个多边形,称为V块;Eve为V块中任意一点.如图2所示. 图2 Voronoi图中的V块Fig.2 Block V in Voronoi diagram Voronoi图的特点是每个V块中有一个焦点Dj;每个V块内点到该焦点距离小于到其它V块内焦点的距离,如S(Eve,D1) 定义3.用户端请求: R(IDu,Pe,Cat,Utime,d) (3) 其中,字段IDu代表用户的唯一标识号;字段Pe代表用户端发起请求时的位置;Cat代表POI类别;Utime代表用户发送请求时的时间点;d代表一个大的奇素数. 定义4.用户匿名集: Users(IDc,Cat,Ctime,X,P) (4) 其中,IDc表示用户匿名集的唯一标识号;Cat表示用户匿名集的POI类别;Ctime表示用户匿名集发出的时间;用户私有信息X=(x1,x2,…,xu,…,xK)中有K-1个模d的二次剩余和一个模d的二次非剩余xu;位置集合P={P1,P2,…,Pu,…,PK}表示用户匿名集中K个用户的位置,Pu表示真实用户所属V块中的随机虚假位置.位置参数P需要满足: ∃Pi∈Vi,∀Pj∉Vi,i≠j (5) 其中,参数Vi表示Voronoi图中V块.以此限定TTPs在把用户匿名集发送给LBS服务器时的用户位置一定是从不同V块中随机挑选出来的. 在隐私保护流程开始之前,LBS服务器将基于同类别POI构建的Voronoi图同步保存在TTPs和LBS服务器中.如算法1所示,以POI为基点,利用Delaunay三角剖分算法生成三角网,再找出三角网内每一个三角形的外接圆圆心,最后连接相邻圆心构建出Voronoi图模型.如图3所示,每一个多边形代表一个V块,每个V块的焦点为POI.当隐私保护流程开始之后,TTPs接收用户查询请求,依据用户端请求R中POI类别Cat划分出相应的Voronoi图. 图3 Voronoi图模型(POI=100)Fig.3 Voronoi diagram model(POI=100) 算法1.基于POI的Voronoi构建 根据定义2中集合D={D1,D2,D3,…,Dn}中所有的n个同类POI,将其位置信息Coo插入POIlist. 输入:POIlist 输出:以信息点为焦点的Voronoi图 1.initialize thetrianglelist 2.initialize theedgebuffer 3.determine the supertriangle 4.add supertriangle vertices to the end of thePOIlist 5.add the supertriangle to thetrianglelist 6.for eachPOIlist 7. for eachtrianglelist 8. calculate the triangle circumcircle center and radius 9. if the point lies in the triangle circumcircle then 10. add the three triangle edges to theedgebuffer 11. remove the triangle from thetrianglelist 12. endif 13. endfor 14. delete all doubly specified edges from theedgebufferthis leaves the edges of the enclosing polygon only 15. add to thetrianglelistall triangle formed between the point and the edges of the enclosing polygon 16.endfor 17.remove any triangles from thetrianglelistthat use the supertriangle vertices 18.remove the supertriangle vertices from thePOIlist 19.connectand get Voronoi 20.end 如算法1所示,输入POI集合,通过三角剖分算法,得到以POI为焦点的Voronoi图.其中,算法1-2行初始化三角形表trianglelist与边缓冲器edgebuffer;第3行确定大的超级三角形;第4行分别将超级三角形的3个顶点坐标插入到POI表POIlist,此处的POIlist是将POI的经纬度转换为屏幕坐标后的;第5行将超级三角形添加到trianglelist中;算法6-16行分别遍历POIlist、trianglelist,然后计算三角形的外接圆圆心和半径,如果POIlist中点位于三角形外接圆上,那么将三角形的3条边添加入edgebuffer,然后从trianglelist中删去此三角形,最后从edgebuffer中删除所有双重指定的边,仅留下封闭多边形的边并向trianglelist中添加点和封闭多边形之间形成的所有三角形;第17-18行从trianglelist中删除以超级三角形顶点为顶点的三角形并将超级三角形的顶点从POIlist中删除,得到Delaunay三角网;第19行连接所有三角形的外接圆圆心得到以同类POI为焦点的Voronoi图. 算法1的算法复杂度计算共分为4部分.第1部分为构造Delaunay三角网,复杂度为O(n2);第2部分计算三角形外接圆圆心,复杂度为O(n);第3部分寻找三角形三边相邻的三角形,复杂度为3O(n);第4部分画出Voronoi图,复杂度为O(n).因此生成以同类POI为焦点的Voronoi图的算法复杂度为O(n2)+O(n)+3O(n)+O(n)=O(n2). 4.1.1 TTPs对用户端请求R的处理 当TTPs收到用户请求R时,首先根据R中的用户唯一标识号IDu判断此次请求是否由同一用户再次发起.如果是第一次发起,TTPs则按照既定规则生成用户匿名集发送给LBS服务器;如果不是第1次发起,TTPs则根据最新的用户请求R中的两次位置Pe进行计算,当最新的用户位置Pe已经离开上一次所属V块时,就重新生成用户匿名集发送给LBS服务器.及时更新用户匿名集可以有效防止联合攻击和位置推断攻击.如果用户多次发来的位置Pe均属于同一V块,那么TTPs将根据用户每次查询请求R的发送时间Utime形成一个时间序列集合Utime={t1,t2,…,tn},计算出γ值. (6) 设TTPs正常负载值为∂,当∂≥γ时,TTPs重新生成用户匿名集发送给LBS服务器;反之,直接发送上一次生成的用户匿名集.这种方式在某种程度上减轻了TTPs的负载压力,同时在服务器负载较低时,高频率的更新用户匿名集可以有效抵抗连续查询攻击和关联攻击,增强匿名性. 4.1.2 TTPs对用户匿名集Users的生成规则 TTPs收到用户请求R后依据标识号IDu保存下R中所有信息.根据R中的用户真实位置Pe与其邻近POI生成同类POI的Voronoi图;然后从其所属的V块中随机选择一个虚假位置点替代用户的真实位置,并在此Voronoi图中以全随机方式从不同V块中挑选K-1个虚假位置点,生成共K个分别属于不同V块的虚假用户,组成用户匿名集发送至LBS服务器.其中,用户请求R中的POI类别Cat与用户匿名集Users中的Cat相同. Voronoi图模型的应用将连续的匿名空间分割成离散的V块,相较于传统K匿名生成的匿名空间,达到了分割空间的作用.这样做的好处:1)随机分割空间的方法会增强匿名性,保护ASR的安全;2)在使用虚假位置代替用户真实位置的同时不会影响服务质量;3)有效规避掉了基于添加噪声的隐私保护方法中因噪声位置不实际所带来的隐私泄露风险. 在难解的二次剩余假设问题模型的私有信息检索协议中,将服务器数据库中数据定义为关系矩阵,TTPs的检索目标是矩阵中二进制位中的一位数据,用户端根据自己所持有的私有信息向服务器发起查询,当LBS服务器收到查询信息后,对矩阵中每一行元素进行规则运算得到查询结果然后返回给用户端,完成一次检索. LBS服务器接收到用户匿名集Users以后,根据POI类别Cat与位置集合P生成关系矩阵,这个关系矩阵中包含n个POI与K个用户的位置邻近关系. 定义5.二次剩余:设大的奇素数d>1,a∈Z且1≤a≤d,(a,d)=1,对于二次同余式y2≡a(modd),若存在y∈Z满足此式,那么称a是模d的二次剩余,否则称为二次非剩余. 定义6.d为大的奇素数,(a,d)=1,由二次剩余理论模型中的欧拉判别条件有 1)a是模d的二次剩余的充要条件为: (7) 2)a是模d的二次非剩余的充要条件为: (8) 定义7.LBS服务器中生成的关系矩阵为 (9) 其中,aij∈{0,1},aij的值代表关系矩阵中第i个POI与私有信息X中第j个用户的邻近关系;1代表邻近,0代表疏远;n代表POI数量;K为用户匿名集中用户数量. 定义8.函数 g(ω,θ)=xωaθω (10) (11) 定义10.d为大的奇素数,(a,d)=1,勒让德符号定义如下: (12) y2≡a(modd),y2≡b(modd) (13) 由公式(12)可得: (14) 由公式(7)、公式(14)可得: (15) (16) (17) 由公式(15)-公式(17)可得: (18) 又因为定义10中勒让德符号取值范围为±1,且d为大的奇素数,故有: (19) 由公式(12)、公式(19)可知,当d为大的奇素数,且a、b都与d互素时,若a、b均为模d的二次剩余,则ab也为模d的二次剩余;同理,若a、b中一个为模d的二次剩余,一个为模d的二次非剩余,则ab为模d的二次非剩余.当TTPs收到返回的结果集M后,已知私有信息X中二次非剩余xu,令ζ=i,1≤i≤n,由定义8和公式(11)即可得到要查询的用户与第i个POI的邻近关系: 1)当f(i)为模d的二次非剩余时,说明g(u,i)=xu·aiu=xu,即aiu=1,即要查询的用户与第i个POI邻近; 2)当f(i)仍为模d的二次剩余时,说明g(u,i)=xu·aiu=1,即aiu=0,即要查询的用户与第i个POI疏远. TTPs通过私有信息检索关系矩阵得到结果集M即可得到用户与各个POI的邻近关系,确定邻近关系之后便可对用户进行下一步指引. 主流的基于独立架构的隐私保护策略是将处理过的数据信息发送至LBS服务器,以保证用户的隐私信息不会泄露,但是当用户对服务质量要求较高时,LBS服务器只能根据客户端发送来的处理过的数据提供服务,服务质量是有损失的.应用二次剩余假设模型解决了因网络环境的复杂、用户行为的不确定等因素而造成的信息损失等问题. 传统的K匿名隐私保护方法中,用户的隐私保护程度与服务质量受K值的影响.当K取值越大,用户的隐私保护程度越高,服务质量越低;当K取值越小,用户的服务质量越高,但用户很容易遭受链接攻击而导致隐私泄露.所以选取一个可以平衡用户服务质量与隐私保护程度的K值,是传统K匿名隐私保护方法的关键. 在K-Vretr方法中,K值的选取略有不同.K取值越大,用户匿名集越大,用户的隐私保护程度越高,但因为应用二次剩余理论模型来保护查询隐私,用户的每次查询都需要遍历整个关系矩阵,使得用户的请求服务效率会受影响;K取值越小,用户匿名集越小,关系矩阵的遍历速度更快,提供给用户的服务质量将会更高.所以用户的隐私保护程度、请求服务效率和服务器的计算负载都与K的取值有关.随着计算机行业的快速发展,计算机的运算能力得到显著增强,已足够应付K取较大值的计算量,但如果当K取非常大的值或用户查询请求并发量特别高时,服务器仍然可能会因为计算能力不足而宕机或计算时长过长而导致此次查询失败. 此处假设计算机的计算能力无限.已知定义5中a、b,当a为模d的二次剩余时,a当且仅当取数列公式(20)中一项: (20) 取模d的绝对值最小的简化剩余系: (21) 因为(-α)2=α2,所以a取值变为数列公式(22)中一项: (22) (23) 在K-Vretr方法中,以地理信息系统中POI数据为基点,将不同类的POI利用Delaunay三角剖分算法生成Voronoi图.考虑现实生活中POI数据的更新并不频繁,所以采用以牺牲存储空间来减少服务器计算开销的策略,将这些以不同种类POI进行划分的Voronoi图提前存储在TTPs中,且在对POI数据进行更新时,只需要对相应POI类别生成的Voronoi图进行重新计算即可,大大减少了TTPs的计算开销.在隐私保护过程中,利用Voronoi图进行分割区间,TTPs需要遍历一遍POI与用户的临近关系,复杂度为O(n),虽然计算开销呈线性上升,但是结合之前对POI的种类划分,已极大降低了查找基数,在保证安全的前提下提高了TTPs的计算效率,减少了计算开销.在对用户的虚假位置选取时,计算开销与K值的取值有关,因为Voronoi图的特性,不需要进行最近邻计算,虽然计算开销会随着K值的增加而增长,但整体不会产生过大变化. 在K-Vretr方法中,根据不同种类POI划分的Voronoi图由LBS与TTPs共同维护,LBS接受用户匿名集数据包,响应着用户请求,因此通信开销的大小关系着LBS处理用户请求的速度,尤其在面对多用户、高并发的情况时,LBS的吞吐量直接影响着用户的服务质量.在形成匿名集的过程中通信开销随着匿名集规模的增加而增大,由于本文采用二次剩余假设模型,LBS接受到用户匿名集生成关系矩阵后,虽然关系矩阵中记录着n个POI与K个用户的邻近关系,但是TTPs并不需要索引出所有的邻近关系,只需从中检索一条用户与POI的邻近关系即可,这从一定程度上降低了通信开销,也保证了通信开销整体并不会随着用户匿名集规模的增长而大幅提高. 随着使用LBS服务的用户人群增长,不法分子针对用户隐私的攻击手段也愈加丰富,本节将对K-Vretr方法在面临各种攻击手段时的安全性进行分析. 基于地理位置信息的攻击主要是因为隐私保护技术的不全面,导致生成的ASR中落入了许多不现实的虚假位置.当不法分子发现虚假位置大量分布在类似湖泊、断崖之中时,可以很容易排除这些位置,加大了用户真实位置泄漏的概率.K-Vretr方法基于现实中POI生成的ASR可以抵抗这种攻击手段,因为现实中的POI位置不会处于湖泊、断崖之中,且基于POI生成的V块中假如包含有类似湖泊之类时,K-Vretr方法也只会在该区域中分布一个虚假位置,避免大量无效虚假位置的产生,对用户真实位置泄漏概率的影响几乎为零. 基于用户信息背景知识的攻击是指攻击者在已经掌握了用户的基本信息,例如兴趣爱好、生活习惯等基础上对用户发起的隐私攻击.K-Vretr方法在对用户发起的请求服务应答时,每次都会对用户请求进行Voronoi图划分,且用户请求类型不同,生成的Voronoi图也会不同,在整个隐私保护过程中,用户的基本信息从未暴露,攻击者无法推断出用户的请求服务信息,K-Vretr方法能很好的抵抗此类攻击. 连续多查询攻击是指当用户一段时间内连续请求服务时,攻击者结合用户当前的移动速度及生成的ASR的结果推断出用户的下一次位置.K-Vretr中当用户进行连续查询时,TTPs每次都会对用户位置进行判定,用户每发起一次查询,就会根据新的V块重新生成新的虚假信息,每一次的虚假信息以及ASR的更新使得攻击者无法及时分析出用户的任何信息,因此K-Vretr方法在针对连续多查询的攻击时有着很好的效果,有效保护了用户的隐私安全. 监听攻击主要针对采用分布式点对点架构的隐私保护方法,在该架构中,用户通过P2P协议自发组成匿名组,攻击者可以冒充普通用户参与匿名组构建,如果攻击者在匿名组中监听组内用户请求,根据返回的结果进行分析就可以监听到用户的隐私信息.不同的是,K-Vretr方法采用可信第三方中心架构,以TTPs作为总载体,完成数据的集中化处理,各个用户在请求服务时互不通信、互不干扰,攻击者无法监听到其他用户的任何请求信息. 实验将本文所提出的K-Vretr方法与同样基于K匿名原理的隐私保护方法(GRAM)进行了多次详细的对比.GRAM[22]方法构建了满足(k,l)匿名性要求的保护图,在保护图中标识顶点,通过不断添加顶点与边的方式来满足用户隐私要求,缓解了隐私保护与服务质量的矛盾,与传统K匿名方法相比确实存在一定优势,但因为GRAM方法在添加顶点过程中并无法排除所有冗余边,使其在降低匿名效率的同时也存在一些缺点.本文将通过实验分析K-Vretr与GRAM的区别及优劣.因为GRAM已经在安全、效率等方面与传统K匿名方法进行了数据实验,故本文将不在数据对比中加以赘述,而是在理论分析中进行说明. 所有的位置隐私保护方法初衷都是为了给用户提供一个安全的服务环境,在保证安全的同时进行不断优化迭代,兼顾实用性、可行性以及服务器的运算开销.本文将从以下3方面来阐明K-Vretr隐私保护技术的性能. 8.1.1 隐私保护度 1)位置隐私保护.基于K匿名机制的K-Vretr方法核心思想是TTPs通过LBS对用户目标POI的Voronoi图构建K匿名集,匿名集选取采用全随机方式从不同V块中选取,由于K匿名集中所有用户的位置均是虚假位置点,故LBS只知道用户处于V块中,用户的真实位置从未暴露,LBS只能利用Voronoi图的特性查询最近点. 2)查询隐私保护.TTPs通过私有信息检索与LBS服务器通信,因为攻击者无法区分私有信息中的二次剩余与二次非剩余,所以即便获取到用户私有信息X和关系矩阵F2n,也无法从中捕获到有价值的用户隐私数据,保证了用户查询隐私的安全. 8.1.2 服务可行性 基于K匿名机制的K-Vretr方法引用Voronoi图模型构建用户匿名集,Voronoi图是基于同类POI所构建的.每个V块中存在一个POI,POI越多,V块越多,关系矩阵就越大;同样的,当K取值增大时,关系矩阵也会增大,因此POI数量与K值的增加会导致服务查询时间变长.但是相较于传统K匿名方法,K-Vretr有着更高的安全性,且随着现阶段计算机运算能力的提升,基本保证了效率与安全性之间的平衡. 8.1.3 服务器开销 本方法中LBS服务器的作用是根据TTPs提供的用户匿名集与POI类别生成相应的关系矩阵,并且负责与TTPs进行通信.首先,LBS上存储着不同种类POI划分的Voronoi图,LBS的存储开销与POI有关;其次,每次发起服务请求时需要遍历LBS中的关系矩阵,所以K的取值也会影响服务器的运算开销.但是相较于传统私有信息检索技术,K-Vretr方法将Voronoi图提前缓存在本地的处理方式,以空间换取时间,对并发量要求较高时也不会造成网络堵塞. 实验采用北京市POI类别为餐饮服务的数据集来验证K-Vretr算法性能,数据来自高德地图的POI集,其中包含约10821个POI.算法采用Python3.8.3编程实现.环境配置为处理器Intel(R)Core(TM)i7-4710HQ CPU @ 2.50GHz(8 CPUs),~2.5GHz,内存4GB,显卡NVIDIA GeForce GTX 850M,操作系统Windows 10专业版.如图4所示,故宫博物馆为圆心,方圆5000米区域内,按比例缩小后POI的分布情况. 图4 基于真实数据集的POI分布图Fig.4 POI distribution map based on real data set 8.2.1 匿名空间与匿名时间的比较 如图5(a)所示,将K-Vretr方法中的POI数量固定,同时不断增大K值,随着匿名空间的面积变大,用户的隐私保护程度将会更高,但无论K取何值,K-Vretr的匿名空间面积始终大于GRAM,且随着K取值越来越大,两种方法相差的匿名空间面积也越大.如图5(b)所示,将POI数量与ASR固定,K-Vretr方法利用Voronoi图模型的特性,不需要通过最近距离的算法判定,LBS服务器存储当前POI划分下的Voronoi图,只在POI进行变更的时候才进行更新,而GRAM方法因为需要满足(k,l)机制的原因匿名时间则显著增加.由此可见,当增加匿名集规模时,2种方法的匿名时间会相差更大. 8.2.2 匿名成功率与通信开销的比较 如图6(a)所示,将ASR固定,随着K值的不断增大,两种方法的匿名成功率虽整体都保持在一个较高水平,但K-Vretr方法的匿名成功率仍然高于GRAM方法.GRAM方法需要不断在基础图中加边来保护用户隐私,每一次加边都要重新计算,需要做K次整合,所以在匿名成功率上也会更低. 图5 匿名空间与匿名时间的对比Fig.5 Compare anonymous space and anonymous time 如图6(b)所示,随着K值增大两种方法的平均通信开销均有增加,K-Vretr方法的增加方式较为平缓,这是因为K值的增大使用户在进行请求服务时需要更多的位置信息来构造匿名区;GRAM方法在增加K值时,当K达到某个节点值就会在保护图上添加一个顶点对应添加l条边,所以GRAM算法的增加有平缓有跳跃.从结果来看,本方法在平均通信开销上要低于GRAM方法. 图6 匿名成功率与通信开销的对比Fig.6 Average communication overhead 8.2.3 POI、K取值的不同对K-Vretr方法的影响对比 如图7(a)所示,取POI数量分别为1500、3000、4500、6000、7500、9000,可以看到匿名时间随POI数量的增加而递增;同时,将POI值保持不变增加K的取值,匿名时间也会略微增加.虽然本方案的匿名时间会随着POI数量与K值的增加而递增,但整体匿名效率仍控制在较好水平.联系现实生活中当同类POI数量如此之多时,所覆盖面积已足够大,这样的匿名效率足够保证用户的服务质量,这也证明了本方法的优越性.如图7(b)所示,取POI数量分别为2000、4000、6000、8000、10000对隐私保护程度进行试验,从实验中可以看出,当K值相等时,POI数量越多,所生成的Voronoi图覆盖面积就越大,构造用户匿名集时分散性就更高,用户的隐私保护程度越高;当POI数量相等时,K值越大,用户的隐私保护程度也会越高,且整体隐私保护程度保持在较高水平. GRAM方法较于传统的隐私保护方法已经证明了他的优越性,实验结果表明,本文所提出的K-Vretr方法具有比 GRAM方法更好的安全性能与匿名效率.通过在LBS服务器上存储Voronoi图的方式,以空间换取时间,避免了因大量用户请求而导致服务堵塞的情况,进一步提升了用户的隐私安全度,增加了本方法的实用性. 图7 POI、K对本方案的影响对比Fig.7 Comparison of the influence of POI and K on this scheme 基于位置服务的隐私保护方法是目前广受关注的热点研究领域.本文提出一种基于K匿名机制的K-Vretr方法,该方法通过对Voronoi图模型和二次剩余假设模型的应用,使得用户被攻击者识破的概率低于1/K,保护了用户的查询隐私与位置隐私.下一步工作将针对大数据时代服务的高并发性,进一步提高用户的查询效率.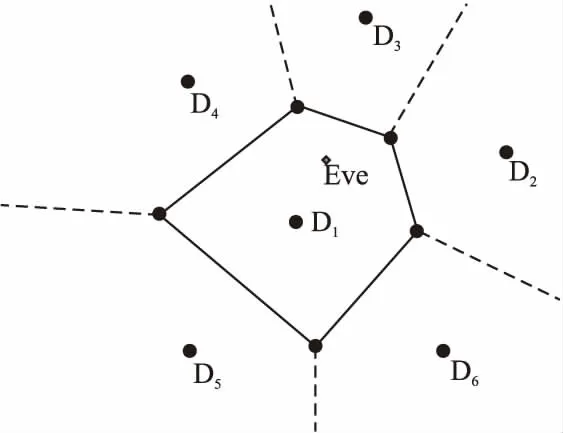
4 基于K匿名的K-Vretr隐私保护机制
4.1 基于Voronoi图模型的位置隐私保护过程
4.2 基于二次剩余假设模型的查询隐私保护过程


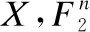

5 关于K-Vretr中K值的讨论



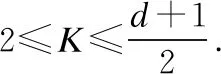
6 计算与通信开销分析
6.1 K-Vretr方法的计算开销分析
6.2 K-Vretr方法的通信开销分析
7 安全性分析
7.1 抵抗基于地理位置信息的攻击
7.2 抵抗基于用户背景知识的推理攻击
7.3 抵抗连续多查询攻击
7.4 抵抗攻击者的监听攻击
8 实 验
8.1 匿名方法分析
8.2 实验对比分析


9 结束语
