BETES:一种中文长文档抽取式摘要方法
2022-01-21王宗辉李宝安吕学强游新冬
王宗辉,李宝安,吕学强,游新冬
1(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)2(北京信息科技大学 计算机学院,北京 100101)
1 引 言
随着互联网的快速发展,面对大量的文本信息,如新闻,文献,报告等,传统的阅读方式,需要人们自己阅读全篇,总结核心内容,效率低,成本高,如何快速、准确的获取长文本的概括主旨摘要是一个急需解决的问题.
Tas[1]等人指出文本摘要是将源文本压缩为缩小版本,以保留其信息内容和整体含义.胡侠[2]等人对于中文的摘要生成方法进行阐述,介绍了常见的几种摘要生成的方法.文本摘要方法可以分为抽取式摘要和生成式摘要,抽取式摘要方法包括根据单词和句子的特征从文档中选择高等级的句子,并将它们放在一起以生成摘要,句子的重要性取决于句子的统计和语言特征,生成式摘要用于理解给定文档中的主要概念,然后以清晰自然的语言表达这些概念.抽取式摘要和生成式摘要具有各自的优缺点.本文以抽取式摘要为研究对象.
抽取式摘要的优点,可以最大化地保证摘要内容来自于原文,抽取式摘要的任务对象非常适合科技文献,法律文书,医疗诊断书等文本载体,可以提高摘要内容的正确性,避免生成不准确甚至是错误的信息.然而,抽取式摘要也有一定的缺陷,抽取式摘要的对象是文本中的句子,当要抽取的数值确定时,会有正确的摘要句未被抽取,造成摘要内容的缺失,而被抽取的摘要内容也会有很大冗余.由于中文表达规则的宽泛性问题,一个句子所表达的内容并非都是重要的,并非都可以作为摘要组成部分的,以句子为单位的抽取模式摘要存在的冗余性问题较为严重,在一个句子中,可能只有部分内容应当被抽取,其他部分并不符合作为摘要.
除了抽取式摘要本身的缺陷,在中文长文本抽取式摘要研究方面面临更大的挑战,当前公开主流语料库文本和摘要长度不足,大多都是短文本,而中文长文本-摘要语料库数量不足.同时,在文本向量化方面,目前在摘要抽取领域还是使用Word2Vec和GloVe等早期的词向量模型,使用最新的Bert预训练模型对输入文本进行向量化,可以提高长文本语义的捕捉效果.最后,在摘要抽取模型方面,深度神经网络的快速发展,最新的模型应用到摘要抽取中可以提高摘要抽取的准确性.
针对抽取式摘要存在的问题以及中文长文本抽取式摘要的难点,本文主要有以下几点贡献:1)构建了一个中文科技文献长文本-摘要语料库;2)提出了一个中文基本篇章单元(Edu)解析模型,可以识别文本的基本篇章单元,作为抽取式摘要更细粒度的对象,降低摘要抽取的冗余度;3)通过Bert预训练模型对于中文长文本进行文本向量化,更好地捕捉文本的语义;4)基于Transformer神经网络,训练中文长文本的摘要抽取模型,提高摘要抽取的准确性.
2 相关工作
2.1 文本向量化
文本向量化是自然语言处理任务极其重要的工作,计算机无法对文本直接读取,向量化是将高维文本进行数字化,编码成低维向量.文本早期的向量化方法是基于统计的方法,例如One-hot编码、TF-IDF、N-Gram,这些早期的编码方式,代价成本高,特征表示是离散的,稀疏的,向量的维数过高,且不能表示一词多义.为了提高模型的精度,降低成本,谷歌在2013年提出了Word2Vec,它是目前最常用的词嵌入模型之一.基于Word2Vec文本向量化的表示是应用比较成熟,比较广泛的方法,王雪霏[3]利用Word2Vec进行中文自动摘要抽取,较之前的方法维度更少,速度更快,通用性更强.除了Word2Vec,GloVe也是一种常见的词向量模型,GloVe可以被看作是更换了目标函数和权重函数的全局Word2Vec,它更容易并行化,速度更快,容易在大规模语料上训练.
虽然Word2Vec和Glove效果很好,但是无法针对特定任务做动态优化,对于长文本很难获取上下文特征,Kenton[4]等人提出了Bert,Bert预训练模型的出现,可以很好的解决这个问题,更加高效地捕捉更长距离的依赖,可以更好的进行上下文表示,因此,利用Bert进行文本向量化可以更好地捕捉文本的语义,进而应用在下游任务中具有更好的效果.
2.2 基本篇章单元识别
对于基本篇章单元,国内外很多学者给出了自己的定义,不同的理论看法并不完全相同,而汉语在语法和表达上更为复杂和丰富,当前并未完全定义出汉语的基本篇章单元表达方式,本文认为,比较准确的定义是李艳翠[5]在文中指出,基本篇章单元可以称为句子的字句,通常是以逗号、分号、句号等标点结尾,每一个字句至少有一个谓语,表达一个命题,并且是独立的,不作为其他字句的结构,字句之间发生命题关系.
语篇分析中的基本篇章单元的识别是自然语言处理中一个基础且重要的研究方向,基本篇章单元的识别大致分为两种方法,第一种是通过自然语言学的知识,分析篇章和句式结构,确定基本篇章单元的表达形式,通过制定规则进而识别,例如,李艳翠通过分析逗号和基本篇章单元之间的表达关系,进而实现汉语基本篇章单元的自动识别,Xue[6]等人提出一种逗号分类和歧义消除的方法,以达到句子的切分,进而得到句子中子句,即句子的话语基本单元.另外,为了进一步提高识别的准确性,目前主流的方法,是通过标注汉语篇章话题结构语料库(CDTC)语料库,通过深度学习训练自动识别模型,例如,葛海柱[7]等基于汉语的主述位,通过LSTM深度学习模型来识别基本篇章单元,Kong[8]等采用“连接驱动的依赖树”方案的端到端中文语篇解析模型,来获取基本篇章单元,这些深度学习方法,虽然提高了识别准确度,但是,需要标注大量的语料库,人力和时间成本较大,不利于在其他领域直接灵活使用.
2.3 抽取式摘要方法
对于抽取式摘要的方法,Moratanch[9]等人提出提取摘要技术包括从原始手稿中选择重要的句子,段落等,并将它们串联成较短的形式.句子的重要性严重依赖句子的统计和语言特征.抽取式摘要的方法,在方法类型上大致分为两类,无监督方法和有监督方法.在无监督方法中,Lin[10]提出了一种基于图算法思想的方法,为要汇总的文档建立了语义图,然后将摘要提取公式化为优化语义图上定义的子模块函数.Erkan[11]介绍了一种基于随机图的方法来计算自然语言处理中文本单元的相对重要性,提出了一种新的方法LexRank,它基于句子图形表示中的特征向量中心性概念来计算句子重要性,进而对句子抽取.除了基于图算法思想的无监督方法,Sankara[12]使用Wikipedia来获取每个句子的概念,建立概念矢量或图形模型来描述概念与句子之间的关系,应用排名算法进行评分句子,根据句子的排名分数生成摘要.另外吴佳伟[13]提出了一种基于Bigram关键词语义扩充的事件摘要方法用于文本摘要的抽取.无监督方法应用在摘要抽取工作上,方法简单,摘要句抽取快速,不受语料库的限制.然而,受制于没有正确摘要句的参考,抽取算法是根据人工规则或者文章的特点来制定,因此,摘要句抽取不准确,抽取方法应用不灵活.
随着机器学习,深度学习等有监督的方法的发展,有监督的方法在摘要生成方面应用越来越多,有监督的方法大致可以分为3种,基于条件随机场方法、机器学习方法、神经网络方法.早期,Batcha[14]提出了一种基于条件随机场(CRF)的ATS,它可以识别和提取正确的特征,使用一种可训练的监督方法进行摘要生成.Neto[15]等人基于可训练机器学习算法的应用提出一个摘要程序,首先统计文本中某些元素的频率,之后从文本的简化论证结构中提取,该算法可以直接从原始文本中提取的一组摘要.孟令阁[16]等人以SVM和MMR摘要提取算法为基础,针对当前的会议围绕某个主题进行讨论、交流的特点,以主题关键词为依据进行打分,选取评分靠前的句子作为摘要.机器学习方法应用在摘要抽取工作上,可以根据语料库的特点,自动学到抽取特征,摘要句抽取更准确,任务细化更具体,但是,机器学习也有它自身的缺点,当数据量较大时,机器学习算法效率较低,当数据多样化时,抽取方法的灵活性低,无法根据复杂的数据,形成更好的抽取方法.
近几年,神经网络的深度学习方法已经成为文本摘要的主流方法,伴随着神经网络的发展,摘要生成的方法也在快速更新迭代.RNN是神经网络中的典型代表,Nallapati[17]等人介绍了SummaRuNNer,这是一种基于循环神经网络(RNN)的序列模型,用于文档的摘要提取,并显示与常规技术相比,其性能更好.除了循环神经网络,将图像领域的卷积神经网络应用在摘要生成方向上,例如,Wang[18]提出了一种深度学习方法,通过将主题信息纳入卷积序列到序列(ConvS2S)模型中并使用自关键序列训练(SCST)进行优化来解决自动摘要任务.基于LSTM在处理序列数据长距离依赖关系的优越性,Jadhav A[19]提出了一种新的用于提取摘要的神经序列到序列模型SWAP-NET,实现自动摘要获取,提升了文本摘要的质量.到后来,Vaswani[20]提出了Attention机制,基于此思想的Transformer神经网络最初应用在机器翻译任务中,取得了非常好的效果,当前,基于Transformer神经网络的中文摘要任务应用并不广泛,随着神经网络的快速发展,自然语言处理工作应该紧密跟随最新的神经网络,通过最新的神经网络,应用在特定任务上以达到更好的效果.
3 中文长文档抽取式摘要方法(BETES)
针对中文长文本的摘要抽取中存在的问题,为了提高摘要句抽取的准确性,降低抽取摘要的冗余,提出了一种BETES方法,该方法主要有3部分组成:
文本向量化部分:对输入文本进行预处理,进行分句、分词、标识符插入等操作,使用中文Bert预处理模型,对文本进行向量化.
基本篇章识别部分:设计一个基于规则的基本篇章单元识别模型,针对中文科技文献长文本,可以实现自动识别文本的基本篇章单元.
摘要抽取模型:设计一个基于Transformer的神经网络抽取模型,可以将上述生成的基本篇章单元自动抽取,然后对抽取后基本篇章单元进行融合,生成最终的摘要.
BETES方法的整体框架如图1所示,各个部分的内容将在后续小节中详细阐述.

图1 BETES方法整体框架图Fig.1 Overall frame diagram of BETES method
3.1 文本向量生成模型
对于中文长文本数据,根据Bert预训练模型的思想,需要进行3部分编码,即词嵌入,区间段嵌入,位置嵌入,将3部分的文本编码相加,最终得到整个篇章中的句子编码,文本向量生成模型结构图如图2所示.
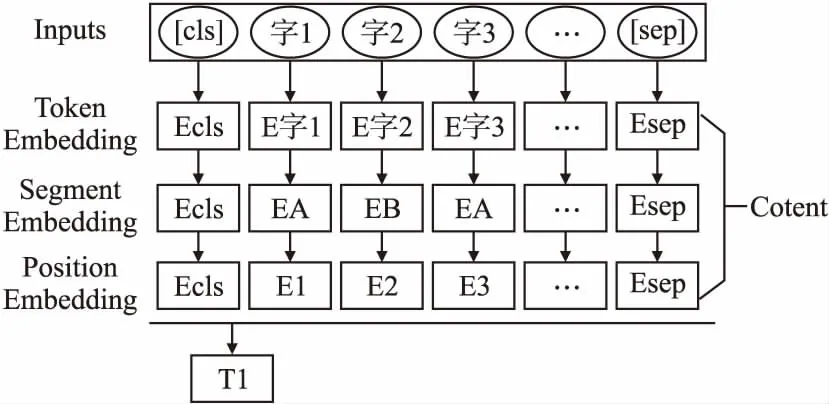
图2 文本向量生成模型Fig.2 Text vector generation model
对于一篇文本D={S1,S2,…,Si},有i个句子,首先,将输入文本通过两个特殊标记进行预处理,对每个句子之前插入一个[CLS]标识,在原始Bert中[CLS]用来从一个句子或一对句子中聚合特征,在每个句子后面插入一个[SEP]标识,通过多个这样的标识,可以表示一篇文本的顺序特征,然后对文本进行分词预处理,采用StanfordNLP工具包对文本进行分词.通过3部分的工作完成中文长文本的向量化表示:
1)首先定义Vt为文本的字符嵌入,通过Bert预处理模型进行编码,对每个字符进行嵌入;
2)定义Vs为文本的区间嵌入,使用区间嵌入来区分文本中的多个句子,当句子编号i为奇数时,将句子Si定义为EA,与之对应,当句子编号i为偶数时,句子Si定义为EB;
3)定义Vn为文本的位置嵌入,对分词后的文本,共有n个字符,定义[E[注]w_zh092@163.com,E2,…,En]表示每个字符的顺序.
最后,通过[CLS]和[SEP]来区分每个句子的位置,每个句子向量表示为Ti=[VtVsVn],i∈D,这样就完成了文本的向量化工作.
3.2 基本篇章单元识别模型
当前对于文本基本篇章单元的识别,是通过标注语料库,训练深度学习识别模型,使用模型识别基本篇章单元.基于深度学习的方法虽然会提高识别的准确率,但会消耗大量的人力和时间成本.经过综合考虑,本文的对象是中文长文本科技文献,在语言描述和句式句法上相对比较固定,本文的目的是快速获取文本的基本篇章单元,灵活地整合到整个摘要抽取框架中,因此,针对当前工作的实际需求,提出一个基本篇章单元的快速识别模型,流程图如图3所示.
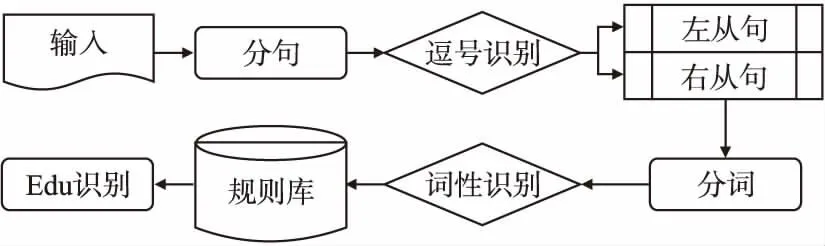
图3 Edu识别模型Fig.3 Edu recognition model
中文长文本基本篇章单元识别流程如下:
1)对于输入文本,使用Berkeley NLP工具,以中文常见的整句标点为界限,如句号,问号,感叹号等,对文本进行分句,得到文本整句.
2)根据逗号从句原则,对整句进一步分句,以逗号为界限,得到整句的字句,同时,对每个字句区分左右,并标记为左从句和右从句.
3)对得到的子句,使用Jieba分词工具对每个子句进行分词.
4)对分词后的字句,使用Jieba词性识别工具,对每个词进行词性识别.
5)以逗号为标志点分割的字句,并不是都可以作为基本篇章单元,因此,需要规则进行判定,针对中文科技文献的句式表达,参考Jin[21]等人总结的从句分割规则,用Python语言实现了这些规则,制定了一个基本篇章单元识别规则库(部分规则如表1所示),通过规则匹配对子句进行识别,最终得到一个句子的基本篇章单元.
表1 基本篇章单元识别规则
Table 1 Edu recognition rules

序号规 则1从句出现动词2从句出现单词‘的’、‘地’、‘得’3从句的最后一个单词是‘时间’4从句出现单词‘把’、‘被’5从句出现介词6从句的第一个单词是代词7…(注1:规则库的规则并未全部列出,详细规则可以通过联系方式获得)
基本篇章单元的算法流程如下:
算法1.Edus Discriminate
Input:Text
Output:Edus
1.functionDiscriminateEdus(Text)
2. Sentens[]= Berkeley_Parser(Text)
3. S = Sentens[S1,S2,…,Sn]
4.fori = 1 to ndo
5. Seg_L or Seg_R = Berkeley_Parser[i]
6. Words_L[]= Jieba_Cut(Seg_L)
7. Words_R[]= Jieba_Cut(Seg_R)
8.forj = 1 to l;k = 1 to rdo
9. Words_L_tag = Jieba_PosTag(Words_L[j])
10. Words_R_tag = Jieba_PosTag(Words_R[k])
11.IfWords_L[]or Words_R[]in RULES then
12. Seg_L or Seg_R is Edu
13.else
14. Seg_L or Seg_R is Edu
15.endif
16.endfor
17.endfor
18.returnEdus
3.3 摘要句抽取模型
抽取式摘要的工作,通常被认为是对原始文本的句子进行分数排名,选取分数排名最高的句子组合,作为最终的摘要,通过上文的工作,本文的对象是更细粒度的基本篇章单元的抽取,因此本文的模型是抽取分数排名较高的基本篇章单元,这在原理和方法上与摘要句的抽取是相通的.
对于文本的摘要句进行抽取,主流方法是深度学习方法,通过训练神经网络模型对句子自动抽取,例如,沈向东[22]提出了一种新颖的端到端神经网络框架,用于文本摘要自动抽取,Zhou[23]等的提出了一种新颖的端到端神经网络框架,用于提取文档摘要.可以看出,当前常见的方法,无论是LSTM还是GRU,大多还是以循环神经网络作为基线.在机器翻译领域,Transformer神经网络的优越性已经得到充分的验证,针对英文数据集,基于Transformer的神经网络也用于文本摘要任务中,效果提升明显.因此,对于中文长文本,本文提出一个基于Transformer的神经网络抽取模型,对上文生成的基本篇章单元进行抽取,最终生成摘要.
本文的抽取模型是3层Transformer叠加,每个Transformer是一种全Attention机制的Seq2Seq模型,它的结构是由Encoder和Decoder组成.下面将介绍如何使用Transformer实现基本篇章单元的抽取模型,结构图如图4所示.
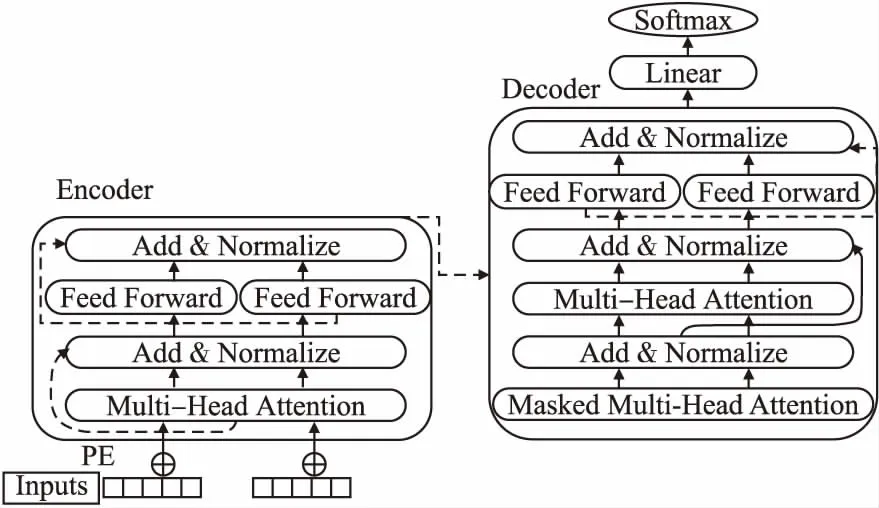
图4 抽取模型图Fig.4 Extraction model
Transformer是由6个编码器和6个解码器组成,其中Encoder结构图如图4左边所示,输入对象是一个长文本,根据Transformer模型的输入,使用公式(1)-公式(3)对输入文本Ti进行PositionalEncodings(PE):
Pi=PE(Ti)
(1)
PE(pos,2i)=sin((pos/10000^(2i/dmodel)))
(2)
PE(pos,2i+1)=cos((pos/10000^(2i/dmodel)))
(3)
对于编码器的输入向量Xi,公式(4)将InputsEncodings和PositionalEncodings组成编码器的输入向量:
Xi=[Ti,Pi]
(4)
初始化3个矩阵WQ,Wk,WV,使用公式(5)分别和Xi相乘,得到Q,K,V:
Q=Xi×WQ;W=Xi×Wk;V=Xi×WV
(5)
对当前输入状态使用公式(6),计算Attention:

(6)
使用多头注意力机制进一步计算MultiHeadAttention则是通过公式(7)、公式(8)对h个不同的线性变换对Q,K,V进行投影,最后将不同的Attention结果拼接起来.
(7)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(8)
接着对MultiHead的输出Z进行一次相加归一化计算,再经过一个前馈网络,对输出Z通过公式(9)计算:
FFN(Z)=max(0,ZW1+b1)W2+b2
(9)
最后再进行一次相加归一化计算,这样整个Encoder层就完成了.
对于Decoder层,如图4右边所示,结构和Encoder层相同,只是在最前面一层加上MaskedMultiHeadAttention,对于Decoder中的第一个多头注意力子层,需要添加Masking,确保预测位置i的时候仅仅依赖于i位置小于的输出,确保预测第i个位置时不会接触到未来的信息.
在Decoder结束后,使用一个线性层做输出,通过公式(10)做分类,判断当前输入文本是否应该被抽取.
Y=Softmax(Xi)
(10)
其中,1代表抽取,0代表不抽取.
4 实 验
针对中文长文本,首先建立了一个中文长文本-摘要数据集,对于实验的设置,在三个维度上,设置了九组对比实验,在评测指标上,选择ROUGE评测指标,证明了提出的BETES方法的有效性.
4.1 数据集
在中文文本自动摘要领域,文本-摘要数据集比较少,目前主流的数据集有两个,分别是哈工大LCSTS新浪微博短文本新闻摘要数据集和NLPCC(2015、2017、2018)中文新闻摘要数据集,除了上述主流的公开语料库外,还有一些其他语料库,例如,教育新闻自动摘要语料库、娱乐新闻文本摘要语料库、中文科学文献数据集(CSL)等.然而,在这些常见语料库中,原文本和生成的摘要长度都较短,对3个语料库的数据长度统计分析,如表2所示.
表2 语料库长度统计
Table 2 Corpus length statistics

数据集文本平均长度摘要长度LCSTS11214NLPCC2017103645CSL23520
由表2可以看出,当前主流的文本摘要数据集,文本和摘要的长度都很短,即使是NLPCC的数据集,长度只能是中篇文本,中文长文本摘要数据集目前处于缺失状态,符合一定长度要求的文本比较难获取,手动构建过程比较困难,会消耗大量人力和物力.针对中文长文本摘要语料库的不足的情况,本文构建了一个的中文长文本-摘要数据集,数据集的构建过程如下.
首先,在人工智能领域,选取了10个方向,数据来源为知网和万方文献网站,通过手动和自动相结合方法,获得中文长文科技文献,进而构建文本-摘要语料库.
构建科技文献的摘要,摘要句的表达有着特定的表达方式,使用温浩[24]总结出的科技文献创新点语句的表达方式,提取出能够构建摘要的句子,同时将文献的原始摘要作为参考,将提取出来的句子和原始摘要进行筛选组合,并辅以人工过滤筛选,构建科技文献的摘要.
构建的中文长文本-摘要数据集,经过筛选和处理,有3208篇科技文献,经过统计分析,数据集的文本平均长度为3802,摘要平均长度为145.本文使用的语料库公开在注[注]https://drive.google.com/file/d/1tfml9zC37WoTRfaNL6efjrrmcRbMizmq/view?usp=sharing.
4.2 对比实验
通过上文介绍的方法,本文在3个维度上进行对比实验,首先是文本向量化方法上的对比,其次是应用基本篇章单元方法的对比,最后是模型方法上的对比.
文本向量化实验:本文选择当前主流的中文文本向量化的方式,Word2Vec和GloVe词向量模型,来验证本文提出的文本向量化方法的有效性,Word2Vec和GloVe都采用中文维基百科的预训练模型,词向量设置为300维,对比实验采用BERT-Base-Chinese中文预训练模型.在抽取模型选择上,为了节省训练成本,本文只选取了简单的线性分类器进行训练,通过二元分类,进而抽取摘要句.
抽取模型对比实验:在模型的对比实验上,本文选择主流的摘要抽取模型方法,设置了4组对比实验,分别是:
1)强化学习抽取模型,使用Narayan[25]等提出的一种新颖的抽取方法,首先使用Glove对文本向量化表示,然后将句子选取概念化为对句子打分,通过强化学习目标来全局优化ROUGE评估指标,选取分数最高的句子.
2)双向LSTM神经网络抽取模型,以Bi-LSTM作为神经网络进行抽取模型训练也是当前主流的一种抽取式摘要的方法,本文使用Xiao[26]在论文中提出的Bi-LSTM摘要句抽取方法,使用Glove进行文本向量化,Bi-LSTM搭建神经网络进行训练,对文本进行摘要句的抽取.
3)Bi-LSTM+Attention抽取模型,在实验3的基础上,保持文本向量化相同,同时在LSTM的基础上加入Attention机制,这是当前在NLP领域比较常见的神经网络模型.
4)BETES模型方法是采用Bert进行文本向量化,使用Beet+Transformer抽取模型,为了实验的严谨性,排除Bert文本向量化带来的影响,仅对比在模型上的差距,使用Bert+Bi-LSTM,对原文Glove文本向量化替换为Bert文本向量化,这样就保证了在同一维度上的公平性.
基本篇章单元对比实验:除了上述文本向量化的对比实验,为了验证本文提出的BETES方法,以基本篇章单元作为更细粒度的抽取对象,在抽取式摘要任务中的有效性.在实验4的基础上,采用Bert进行文本向量化表示,通过基本篇章单元识别算法,获取文本的基本篇章单元,采用基于Transformer的神经网络抽取模型,以验证文本提出的BETES方法的最终效果.
4.3 实验过程
实验均在PyTorch 1.4.0环境上,采用4块TeslaV100 GPU并行训练,对比实验的方法详细介绍如下.
对比实验1中,采用简单的机器学习方法,只设置一个线性分类器,选择SoftMax分类器,在文本向量化之后,通过分类对句子进行分类,识别是否可以被选择为摘要句.
对比实验2中,由于原文数据集是英文,在文本向量化上,本文统一使用Glove词向量模型,词向量设置为200维,批次大小为20,每一批次训练20轮,学习率为0.001,损失函数采用文中提出的基于强化学习的损失函数.
对比实验3中,采用双向LSTM,其中,LSTM中隐藏单元数为300,每次训练数据的批次大小为128,学习率为0.0001,采用二元交叉熵损失函数,每个批次经过50轮的训练,多层感知机的最后一层为100维,最后通过1维线性层,计算句子被抽取的最大概率.
对比实验4中,Bert模型中dropout为0.1,隐藏层单元数为768,隐藏层数为12,采用glue激活函数,神经网络为两层transformer,学习率为0.002,经过10000步的训练,在最后一层为1维线性层,得出句子被抽取的概率.
在基本篇章单元对比实验中,实验过程在对比实验4的基础上,通过本文提出的基本篇章单元识别模型,识别基本篇章单元,然后作为输入,利用Bert+Transformer的抽取方法,实现基本篇章单元的抽取,将抽取后的基本篇章单元根据标点和抽取顺序融合为最终的摘要.
4.4 实验结果及评测
本文的评测指标,使用ROUGE作为本文实验结果的评测指标,ROUGE是Lin[27]在2004年提出的一种准对摘要生成任务的一种评测方法,现在已经成为应用最广泛的评测指标,分别计算ROUGE-1,ROUGE-2和ROUGE-L的F1值,来评测各个对比实验的结果,实验的结果如表3所示.
表3 实验结果
Table 3 Experimental result
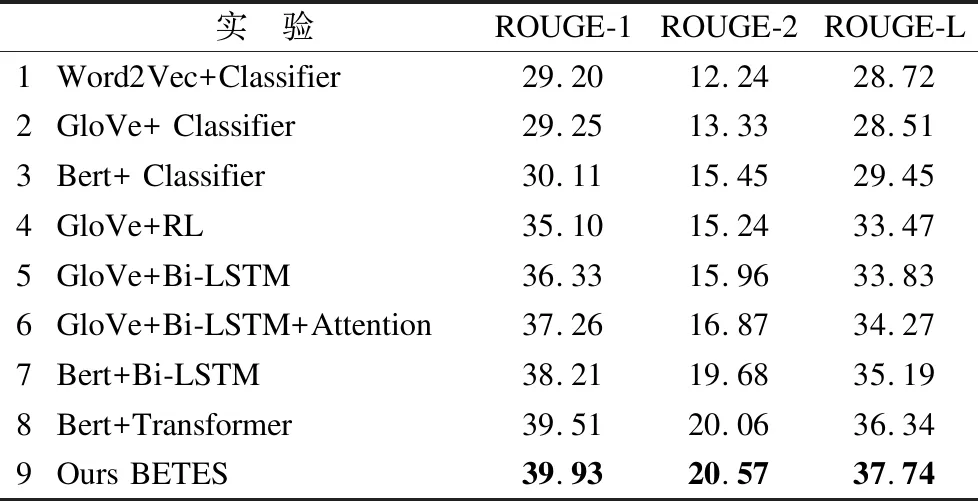
实 验ROUGE-1ROUGE-2ROUGE-L1Word2Vec+Classifier29.2012.2428.722GloVe+ Classifier29.2513.3328.513Bert+ Classifier30.1115.4529.454GloVe+RL35.1015.2433.475GloVe+Bi-LSTM36.3315.9633.836GloVe+Bi-LSTM+Atten-tion37.2616.8734.277Bert+Bi-LSTM38.2119.6835.198Bert+Transformer39.5120.0636.349Ours BETES39.9320.5737.74
进一步,为了更直接的对比各个实验的结果,对各个对比实验的结果的柱状图如图5所示.
通过实验结果看出,在文本向量化模型的选择上,在保证抽取方法一致性的情况下,Word2Vec和GloVe词向量模型效果差距很小,而使用Bert进行文本向量化的效果,会比使用Word2Vec和GloVe词向量模型有着明显的提高.在摘要句的抽取模型上,排除文本向量化的影响,使用Bert+Transformer作为摘要抽取模型,效果会优于当前主流的摘要抽取模型.最后一个对比实验,在确定最优的抽取模型后,使用基本篇章单元作为更细粒度的抽取对象时,摘要句的抽取效果会进一步提高,因此,证明了所提出的BETES方法的有效性.使用对比实验中得出的最优抽取模型Bert+Transformer对中文科技文献做抽取.同时,使用本文BETES方法作对比,实例对比结果如表4所示.
通过表4可以看出,在使用了最好的抽取模型Bert+Transformer对长文档进行摘要句抽取时,模型可以抽取句子数量是固定的,当数值较大时,会造成摘要的冗余,增大了模型的训练量,当数值较小时,可能未抽取到需要的句子,造成摘要句的缺失,影响最终摘要的准确性.而BETES方法以基本篇章单元作为更细粒度的抽取对象,在抽取句子过程中,很多冗余信息,不必要抽取,对基本篇章单元进行抽取,可以降低抽取的摘要的冗余度,实现对更多信息进行抽取,避免了最终摘要信息缺失,最终,证明了本文方法的有效性.
表4 实例结果对比
Table 4 Comparison of case results

参考摘要Bert+Transformer抽取模型BETES方法针对人脸识别技术难点问题,本文采用了新的改进型PCA和LDA融合算法的人脸图像识别方法.本文提出了改进型PCA和LDA融合算法人脸图像识别方法,有效地降低光照不均匀对人脸识别所造成的影响,从而拓展了PCA算法的应用条件.运用改进的PCA算法对训练图像降维,最后再对降维以后的特征采用LDA算法,训练出一个最具判别力的分类器,实验证明,本文提出的方法,对光照不均匀、表情变化的人脸具有一定的鲁棒性,具有很好的人脸识别性能,提高了其识别精度,其识别率高于传统的PCA算法.从识别曲线中可以看出,其改进的PCA和LDA融合算法,比传统的PCA算法识别率有了很大的提高.针对人脸识别技术难点问题,本文采用了新的改进型PCA和LDA融合算法的人脸图像识别方法.本文提出了改进型PCA和LDA融合算法人脸图像识别方法,有效地降低光照不均匀对人脸识别所造成的影响,从而拓展了PCA算法的应用条件.运用改进的PCA算法对训练图像降维,最后再对降维以后的特征采用LDA算法,训练出一个最具判别力的分类器,实验证明,本文提出的方法,对光照不均匀、表情变化的人脸具有一定的鲁棒性,具有很好的人脸识别性能,提高了其识别精度,其识别率高于传统的PCA算法.目前,在众多的人脸识别方法中其中以主成分分析法(PCA 算法)居多.虽然传统的PCA 算法在人脸识别中应用很广,但其也有自身的缺陷.针对人脸识别技术难点问题,本文采用了新的改进型PCA和LDA融合算法的人脸图像识别方法.实验证明,本文提出的方法具有很好的人脸识别性能,提高了其识别精度,优于传统的PCA算法,其效果令人满意.本文提出了改进型PCA和LDA融合算法人脸图像识别方法, 有效地降低光照不均匀对人脸识别所造成的影响,从而拓展了PCA算法的应用条件.运用改进的PCA算法对训练图像降维, 最后再对降维以后的特征采用LDA算法, 训练出一个最具判别力的分类器, 实验证明,本文提出的方法,对光照不均匀、表情变化的人脸具有一定的鲁棒性,具有很好的人脸识别性能,提高了其识别精度,其识别率高于传统的PCA算法.从识别曲线中可以看出, 其改进的PCA和LDA融合算法,比传统的PCA算法识别率有了很大的提高.
5 结 论
本文针对中文长文本抽取式摘要任务,构建了一个小型的中文长文本-摘要数据集,提出了一种BETES方法,利用Bert对中文长文本进行文本向量化,通过将文本解析成更细粒度的基本篇章单元,使用基于Transformer的神经网络抽取模型,对摘要句进行抽取,实验结果表明,BETES方法提高了摘要句抽取的准确性、降低了摘要的冗余度,优于当前主流的抽取式摘要方法.
