融合BERT词嵌入和注意力机制的中文文本分类
2022-01-21陈强越
孙 红,陈强越
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
随着信息技术的不断发展,互联网已经成为信息传递的主要媒介.如今,每天都会产生难以估量的文本信息,对这些信息进行分类,既方便运营商的管理,又使得普通大众能够有选择地阅读自己感兴趣的内容.如何对这些文本进行快速高效的分类,是文本分类研究的热点问题.
由于文本数量庞大,人工进行文本分类显然不可取.随着机器学习和深度学习的发展与应用,相关方法被越来越多的应用到文本分类中.
Kalchbrenner[1]提出了动态卷积神经网络模型(DCNN),使用k-max池化,并与卷积层交替的结构.Kim[2]提出了一个基于卷积神经网络(CNN)的文本分类模型,该模型通过word2vec获得输入的词向量,并将此作为卷积神经网络的输入.Johnson[3]等提出了一种新型的CNN结构DPCNN,可以有效提取文本中的远程关系特征,同时避免了复杂度的堆砌.Hochreiter[4]等基于循环神经网络[5](RNN),提出了长短时记忆网络(LSTM),弥补了传统循环神经网络梯度消失或梯度爆炸的问题.Chung[6]等在此基础上,提出GRU模型,提高了训练的效率.Joulin[7]等人提出了一种简单高效的文本分类器FastText,FastText将文本视为词袋,并使用n-gram作为附加功能来捕获词序信息.Devlin[8]等人提出了双向编码模型BERT(Bidirectional Encoder Represent-ation from Transformers),在大量语料训练基础上,同时考虑了词语在不同上下文的特殊表达,形成动态词向量的输出.杨[9]等人提出多特征融合的模型,从不同层面对文本特征进行提取.
上述方法对文本分类的贡献大多体现在优化词向量或者优化特征表达其中一方面,兼顾两者的方法大多结构复杂,分类耗时长.为了对文本进行分类,我们既要考虑合适的文本向量表达,又要精准地提取出文本的主要特征.为此,本文提出了一种用BERT训练词向量,用双向GRU网络进行高效的特征提取,同时融合注意力机制作为辅助特征嵌入的文本分类模型BBGA(BERT based Bidirectional GRU with Attention).实验证明,该方法能够相对快速并且精确地进行较大规模的文本分类任务.
2 相关工作
2.1 文本分类简述
文本分类是自然语言处理的经典问题之一,其主要目的是为目标语句分配标签.随着互联网的发展,文本的规模呈指数级上涨,自动文本分类逐步成为主流方法.自动文本分类方法可分为3类[10]:基于规则、基于机器学习和深度学习以及混合方法.基于规则的方法使用预先定义的各种规则来进行文本分类,例如“体育”这一类别会把所有包含“足球”、“篮球”或“排球”之类词语的文本纳入其中.基于规则的方法需要对待分类文本所属的领域有着深入的了解,这就抬高了这种方法的门槛.
近年来,机器学习,尤其是深度学习相关的方法开始在文本分类中流行起来.深度学习模型在学习文本特征时,能够发现一些难以定义的隐藏规则或模式.这类方法通常包含两个主要的步骤:1)构造合适的词向量来表示任务中输入的文本;2)选择合适的模型来训练提取文本特征,并通过这些特征进行文本分类.
2.2 词向量
词向量,顾名思义,就是将输入的单词或者词语用向量来表示.One-hot向量是最简单的词向量表示方法,这种向量的维度和词库的大小相等,通过在不同位置设定值1,其余位置设定0来达到唯一表示的目的.这种方法虽然简单,但是会导致维度灾难,而且无法表示一词多义,也无法表示出词与词之间的联系.
Word2vec通过词的上下文来得到目标词的向量表达,主要方法包括CBOW和Skip-gram,前者通过周围的词来预测中间词,后者则通过中间词来预测周围的词.
然而word2vec的表达与窗口大小密切相关,因为它只考虑窗口内的局部联系.为此,glove利用共现矩阵,把局部信息和整体内容都加以考虑.
尽管word2vec和glove在某种程度上提升了词向量的表达效果,但是它们都无法表示一词多义,这两个模型的词在不同语境中得到的向量是相同的.为了优化这一点,ElMo采用双向模型来预测单词.在正向模型中,使用前1-k个词去预测第k个词,在反向模型中,使用k后面的单词来预测第k个词.
BERT通过海量语料的训练,得到了一组适用性十分广泛的词向量,同时还能在具体任务中动态优化词向量,大幅提升了相关NLP任务的实验效果.
2.3 深度文本分类模型
使用深度学习方法进行文本分类已经是现在的主流方法,后来的深度学习模型大多是对一些主流模型(例如RNN和CNN)的优化,从而使其更适用于某一类的任务.Tai[11]等人发现传统的链式LSTM在NLP任务上的效果有限,提出了Tree-LSTM模型,从而学习到更加丰富的语义表示.Bieng[12]等人提出了TopicRNN模型,把潜在主题模型与RNN相结合,使用RNN获取局部的联系,同时使用主题模型获取全局的联系.Prusa[13]为了减少字符级文本学习的耗时,使用CNN进行文本的编码,可以在原始文本中更多的保留信息.Conneau[14]使用深层的CNN(VDCNN)进行文本分类,随着层数的不断增加,分类的效果会更好.与VDCNN类似,现有模型大多通过复杂度的增加来提高性能.
通过对已有方法的深入学习,也为了达到快速准确地进行文本分类的目标,本文提出了BBGA模型.该模型综合考虑了各种词向量表达的优劣,选择使用BERT模型训练输入文本的词向量,得到新的词向量之后,将其作为新的输入送到GRU网络进行文本特征的提取,同时考虑到文本上下文的联系,将GRU扩展为双向网络.最后引入注意力机制,使分类过程中各文本的权重分配更加合理.
3 系统框架
BBGA模型结构如图1所示,该模型的整体运作流程是:首先输入文本数据,利用BERT预训练模型,获得包含文本总体信息的动态词向量,接着将新的词向量输入到双层的GRU网络进行特征提取,捕捉文本的特征信息,最后引入注意力机制,得到输入文本的最终概率表达,从而达到文本分类的目的.

图1 BBGA模型结构图Fig.1 Model structure of BBGA
3.1 BERT词嵌入
BERT作为一种预训练语言模型,是在海量语料中训练得到的,既可以直接进行文本分类任务的训练,也可以将其作为词向量嵌入层输入到其他训练模型,本文选择后者.BERT模型的结构图如图2所示.
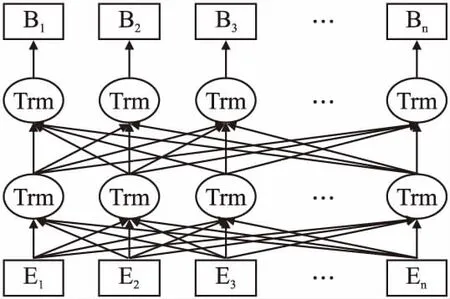
图2 BERT结构图Fig.2 Model of BERT
输入的向量不仅包含当前文本的词向量,还有表示词在文本中位置的位置向量,以及词所在句子的分段向量.3个向量求和之后,分别加上CLS和SEP作为一个文本开头与结尾的标志.
3.2 循环神经网络与BiGRU
为了综合考虑文本上下文之间的联系,开始出现一些尝试使用RNN处理文本数据的方法.基于RNN的模型将文本处理成一个较长的序列,但是,在更新网络参数的反向传播过程中,容易出现梯度弥散的问题.为了克服RNN存在的缺点,许多基于RNN的变体模型被提出.其中长短时记忆模型(LSTM)是RNN众多变体中最为流行的一个,它由输入门、记忆单元、遗忘门和输出门4个主要部分组成,通过对输入向量的“记忆”与“遗忘”,保留了文本中的重要特征,剔除了相对无用的内容.
但是,随着文本数量的增多,由于参数多、各个门之间的计算相对复杂,LSTM进行网络训练耗时长的问题逐渐暴露.同时,LSTM还会产生过拟合的现象.为了解决LSTM存在的弊端,一种更为简单的基于RNN的神经网络模型GRU被提出,其模型结构如图3所示.

图3 GRU结构图Fig.3 Model of GRU
GRU主要由更新门和重置门组成,其中更新门用于决策上一时刻隐层状态对当前层的影响,更新门中的值越大,说明上一时刻对当前层的影响越大.更新门的计算方法如公式(1)所示:
rt=σ(Wrxt+Wrht-1+br)
(1)
重置门用于剔除上一时刻的无效信息,重置门的值越小,剔除的无效信息就越多.重置门的计算方法如公式(2)所示:
zt=σ(Wzxt+Wzht-1+bz)
(2)
当前状态的计算方法如公式(3)和公式(4)所示:
(3)
(4)

通过GRU,我们既能很好的捕获文本的总体特征,又能减少计算量,达到高效训练的效果.但是,在单层的GRU网络中,状态的传播也是单向的,为了充分利用文本上下文的关系,我们建立了双向的GRU网络,双向GRU网络的结构模型如图4所示.
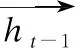

图4 双向GRU结构图Fig.4 Model of bidirectional GRU
(5)

3.3 注意力机制
注意力机制是深度学习中极为重要的核心技术之一,已经被广泛地应用在模式识别和自然语言处理相关领域.注意力机制模仿了人类视觉的注意力,人类在观察事物时,总是会把注意力重点放在关键区域,从而获得视野内的重要信息,同时忽略非重要区域,提高我们视觉信息处理的效率.
对于本文的文本分类任务而言,每条文本数据的类别,通常由其中的关键词和关键语句决定,引入注意力机制的目的在于提升分类过程中这些关键词的权重,同时降低非关键词的权重,从而获得更好的分类效果.
4 实验结果与分析
4.1 实验数据集和评价指标
本文使用的数据集是清华NLP组提供的THUCNews新文文本分类的数据集,从中抽取了10万条新闻数据,包含经 济、房产、股票、教育、科学、社会、时政、体育、游戏和娱乐,数据分布情况如表1所示.同时,将数据集按照8∶1∶1划分训练集、测试集和验证集.其中,训练集八万条,测试集和验证集各1万条.
表1 THUCNews实验数据集分布情况
Table 1 Distribution of THUCNews data set
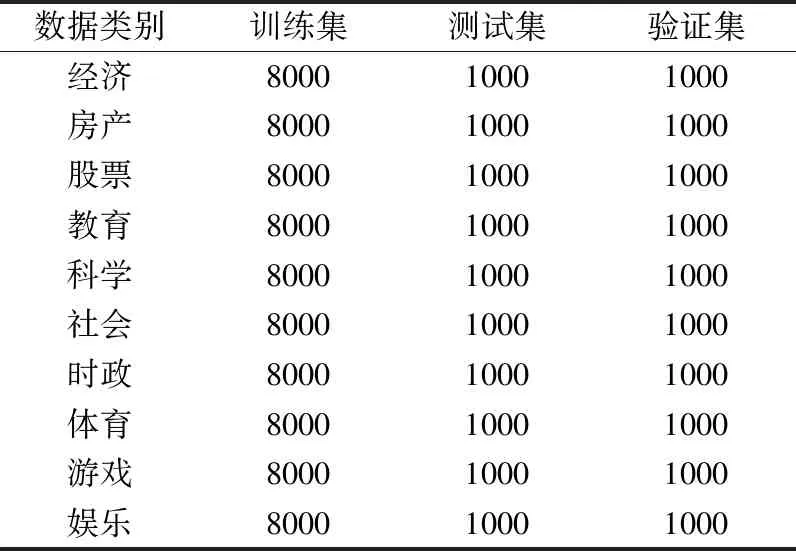
数据类别训练集测试集验证集经济800010001000房产800010001000股票800010001000教育800010001000科学800010001000社会800010001000时政800010001000体育800010001000游戏800010001000娱乐800010001000
本文分别采用准确率(Precision)、召回率(Recall)和F1-Score作为测评指标,对BBGA模型的分类性能进行评价.
准确率是一个统计测量,其计算公式如(6)所示,本实验中用于对特征提取的效果验证以及F1-Score的计算.
(6)
召回率Recall用于计算F1-Score,其计算如公式(7)所示:
(7)
F1-Score是衡量分类器分类准确性的指标,其计算如公式(8)所示:
(8)
4.2 模型与参数设置
本文中的实验基于pytorch框架,用于训练的GPU是Quadro RTX 6000,模型参数设置如表2所示.
表2 模型参数
Table 2 Parameters of the model

参数数值词向量维度768BiGRU维度(768,2)Dropout值0.2学习率1e-5优化器AdamAttention维度64
实验中其他对比模型的参数设置都参考了经典的模型,例如Kim等人对于CNN的实验工作,Lai等人对于RNN的实验工作.
4.3 实验结果与分析
为了验证将BERT作为嵌入层来训练词向量的有效性,本文首先选择TextCNN、TextRNN、DPCNN和FastText作为对比实验的模型,与BERT_CNN和BERT_RNN的实验结果相比较,试验结果如表3所示.
表3 第1组实验结果
Table 3 First group of results

方法精确率召回率F1值TextCNN0.89140.89120.8911TextRNN0.89180.89110.8909FastText0.90520.90540.9052DPCNN0.89180.89130.8912BERT_CNN0.93520.93520.9352BERT_RNN0.93330.93330.9333
可以看出,将BERT作为嵌入层训练词向量,可以有效的优化输入文本的向量表达,从而获得更好的训练效果.相比于TextCNN,BERT_CNN的F1值上升了4.41%,相比于TextRNN,BERT_RNN的F1值上升了4.24%.
接着,为了验证本文提出的BBGA模型在进行文本分类任务时的有效性,选择上述实验中表现相对优秀的BERT_CNN和BERT_RNN模型作比较,同时,选择了纯粹的BERT模型来做对比,实验结果如表4所示.
表4 第2组实验结果
Table 4 Second group of results
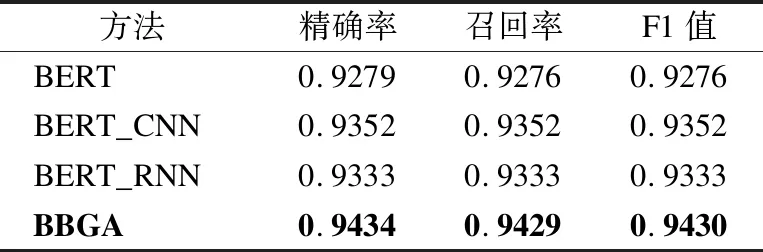
方法精确率召回率F1值BERT0.92790.92760.9276BERT_CNN0.93520.93520.9352BERT_RNN0.93330.93330.9333BBGA0.94340.94290.9430
从表4中的结果可以看出,相比于BERT词嵌入后只接一层训练网络,本文提出的BBGA模型,有效的优化了分类时的相对权重,提高了文本分类的精度.同时,可以看出,虽然纯粹的BERT在许多任务中都有不俗的表现,但是效果是有限的,将其训练的结果作为进一步的词向量,可以达到更好的效果.
接着,为了分析本文的BBGA模型在每个类别分类上的准确率,同时也为后续的优化工作做准备,我们挑选了具有代表性的BERT_CNN模型和FastText模型作为对比实验,实验结果如图5所示.

图5 各类别分类精度对比Fig.5 Comparison of classification accuracy of each category
可以看出,BBGA模型不仅在每个具体的分类任务中的效果优于其他模型,同时每个分类任务的准确率都超过了90%,某些特征明显的类别,例如体育和教育,精度更是达到了98.14%和96.48%.
最后,为了验证BBGA模型的分类效率,我们对比了几个深度学习模型达到收敛所需的时间,在学习率统一设置为1e-5的条件下,实验结果如表5所示.
表5 收敛速度对比
Table 5 Comparison of convergence rates

模型收敛耗时BERT8min12sBERT_CNN12min37sBERT_RNN15min19sBBGA13min35s
从表5中的结果可以看出,RNN由于无法进行并行计算,收敛速度相比于RNN较慢,但是BBGA模型采用的神经网络结构相对简单,收敛速度要快于传统的RNN模型,同时相比于BERT_CNN耗时稍长一点,这是RNN相关模型特点决定的.尽管如此,BBGA模型还是在保证较高精确度的同时,一定程度上减少了耗时,达到了高效准确地进行大规模文本分类的效果.
5 结 论
我们正处于信息极速增长的时代,对于文本分类任务而言,准确率和效率都是极为重要的衡量指标.传统方法虽然速度快,但是准确率普遍偏低,深度学习方法通过对模型的改进提高了准确率,混合方法以耗时为代价进一步提高了准确率.为此,本文提出了BBGA模型,旨在保证较高分类精度的前提下,尽可能减少文本分类的耗时.
首先对比了几种常用的词向量表示方法,选择了以大量语料的训练为基础得到的动态词向量模型BERT.接着,为了保证文本提升特征提取的质量和速度,使用GRU网络,并加入正反两层网络,充分捕捉文本的上下文联系.最后加入了注意力机制,用于调整分类时的权重比例.
实验表明,在THUCNews数据集下,BBGA模型的性能完全优于TextCNN、TextRNN、DPCNN和FastText,而相对于BERT、BERT_CNN和BERT_RNN,也有着优秀的表现.
但是,本文的工作还存在优化的空间,例如进一步优化词向量的表示,优化神经网络的结构等,从而更加快速准确地进行更大规模的文本分类.
