改进的二视图随机森林
2022-01-18夏笑秋陈松灿
夏笑秋,陈松灿,2+
1.南京航空航天大学 计算机科学与技术学院,南京210016
2.南京航空航天大学 模式分析与机器智能工信部重点实验室,南京210016
由Breiman 在2001 年首次提出的随机森林(random forest,RF)已成为应用最广的集成学习算法之一。RF 通过利用随机重采样和结点随机分裂策略构建出多棵决策树,进而通过投票得到最终分类结果。由于其具有高精度、好的可解释性、低的过拟合风险及良好的容噪能力等优点,已在包括计算机视觉和数据挖掘等众多领域取得了极大成功,同时也激发众多后继者对RF 的广泛研究,发展出了诸如动态RF、深度森林等RF 变体。
尽管如此,现有的RF 及其变体几乎全聚焦于单视图学习场景,针对二视图或多视图的RF 构建却很少。现实中很多分类问题本质上是多视图的,因为单视图数据通常并不能描述出数据信息的全貌,数据特征往往需要从多个方面进行刻画,相互补充。例如一张图片可由其纹理特征、形状特征和颜色特征来共同表示,即形成了一组多视图数据。充分利用来自不同视图的互补信息可以带来泛化性能的提高,并已推动了多视图学习的广泛展开。
然而,当前结合RF 的二视图或多视图工作仅有两个,其一是用于行人检测的多视图RF,另一个是研究放射性组的基于差异的多视图RF。两者提出的方法都是先为各个视图生成各自的RF,然后在决策(或后程)阶段才融合视图信息。显然,这些方法并未全程利用到决策树/RF 的层次结构,在各层次的各结点处进行视图间的信息交互,这无疑是对信息资源的一种浪费。为了克服这一不足,本文在二视图场景下,提出了一种改进的二视图RF(improved two-view random forest,ITVRF),考虑将视图交互信息融入到决策树的全程构建阶段,充分利用决策树/RF 的层次特征逐层进行特征交互,以实现视图数据的全程融合。为此,需要解决以下两个问题:
(1)如何在决策树的构建阶段逐层融合二视图数据?
(2)如何将融合后的数据用于分类?
针对第一个问题,可通过诸如经典的典型相关分析(canonical correlation analysis,CCA)来解决。CCA 是研究视图间相关性的一种有效方法。具体而言,对于一组给定的二视图数据,CCA 旨在获得一组基向量使视图间的相关性最大。作为一类经典的二视图数据处理方法,CCA 自然也可用于信息融合。常见的特征融合方法分为并行和串行两种。在决策树的全程构建阶段进行视图融合是ITVRF 能够取得优越性能的关键。
针对第二个问题,ITVRF 考虑利用样本的类信息来进行分类。将数据投影到线性判别分析(linear discriminant analysis,LDA)对应的判别向量上,使得类内样本尽可能紧凑,类间样本尽可能分离。对于投影后的样本,利用不纯度测量方法计算出当前最佳分割数据空间的超平面,在超平面创建的每个分区中生成一个子树。依此递归进行,最终得到一棵二视图决策树。对样本判别信息的全程利用是导致ITVRF 产生良好分类效果的另一个原因。
值得一提的是,ITVRF 先利用CCA 融合视图信息,再用LDA 进行样本投影,这要求先后计算一对CCA 向量和LDA 向量,增加了算法的复杂性,导致很大程度的低效性。幸运的是,早期所提出的增强组合特征判别性的CCA(combined-feature-discriminability enhanced canonical correlation analysis,CECCA)提供了将两步合为一步的办法。CECCA 是一种监督型降维方法,弥补了CCA 抽取出的特征未必具有良好判别性这一不足。通过直接将数据投影到一组兼顾视图间相关性和判别性的向量上,CECCA 可以一步解决上述两个问题,为ITVRF 提供了效率保证。
1 相关知识介绍
1.1 随机森林
随机森林(RF)是Breiman 提出的由一组决策树{(,θ),=1,2,…,}组成的分类器,其中θ是相互独立且同分布的随机向量,表示RF 中决策树的个数,RF 最终由所有决策树投票决定输入向量的最终分类结果。
RF 的生成步骤如下:
(1)利用bootstrap 重采样法有放回地随机抽取个自助样本集,每个样本集的容量都与原始训练集相同。
(2)设有个特征,在每棵决策树的每个结点随机抽取个特征(<)。通过不纯度测量,在个特征中选择最具分类能力的特征进行结点分裂。
(3)在个样本集上分别构建决策树,每棵树都最大限度地自由生长,即不进行剪枝处理。
(4)RF 的最终预测结果通过多数投票法得到。
1.2 典型相关分析
典型相关分析(CCA)是研究两组变量相关关系的多元统计方法,在二视图学习中,CCA 早已广泛应用于特征提取和信息融合。
给出一组二视图数据集{(x,y)}∈R×R,其中x和y分别来自两个不同的视图。令

分别表示两个视图。CCA 旨在寻找一组投影方向w∈R和w∈R,使得样本集和在投影空间的相关性最大。可以通过优化如下函数获得:

分别为样本集的自协方差矩阵和互协方差矩阵。
CCA 寻找的投影向量w和w可以通过求解如下问题获得:

在得到w和w后,对样本对(,)进行特征组合。常用的组合方法有两种,并行组合

和串行组合

在进行分类任务时,可利用上述信息融合方法得到组合属性特征,再将该组合特征作为输入用于预测。
1.3 线性判别分析
线性判别分析(LDA)是一种有监督的降维技术,其目标是寻找一个有效的投影方向,使得数据投影后类内散度尽可能小,类间散度尽可能大。
假设有一组样本集=[,,…,x]∈R,LDA的目标函数定义为:


式中,μ为第类样本的均值向量;为的类间散布矩阵;为类内散布矩阵。
LDA 的解为:

2 改进的二视图随机森林
如前分析,现有的针对二视图场景的RF 构建都是先为各个视图生成对应的RF,再通过各个RF 投票决定最终预测结果。这些方法的弊端是在后程的决策阶段才利用了视图间的互补信息。本文提出的ITVRF 方法弥补了这一不足。ITVRF 中的每棵决策树都独立生成,且在树的构建阶段全程进行了视图间的信息交互。本章将详细介绍ITVRF的实现过程。
2.1 融合视图数据
假设{(x,y)}∈R×R为一组二视图样本集,令数据矩阵
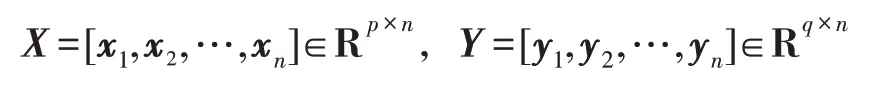

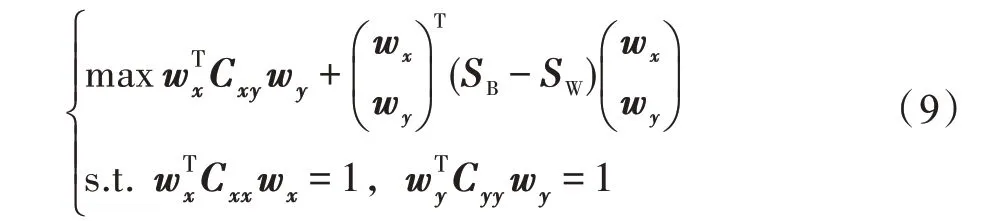
其中,C、C和C的定义同式(2),和分别表示并行组合样本集[,]的类间散布矩阵和类内散布矩阵。目标向量可通过求解如下广义特征值问题而获得:

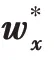
2.2 构建二视图决策树

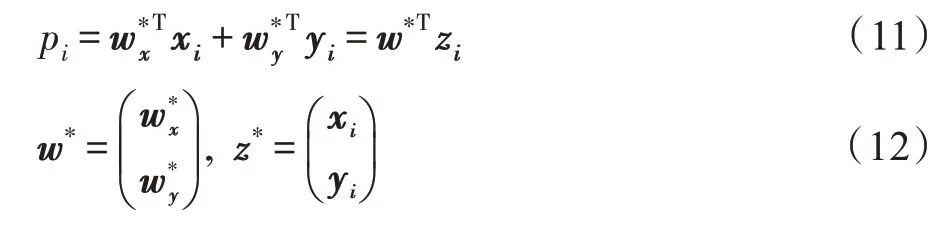
p可看作并行样本对z在上的投影。而后排序所有p,形成-1 个s 分割点q=(p+ p)/2。经过分割点q且与正交的超平面为当前划分数据空间的候选超平面。每个超平面将当前的数据空间划分为和两个分区:

其中,代表两个分区中相对较纯的一个。利用不纯度测量方法(如信息增益准则)选出所有中样本信息最纯的一个,将其对应的分割点q记作。经过的候选超平面是所求的最佳超平面。对每个分区重复上述操作生成子树,直到满足决策树的停止生长条件为止。二视图决策树的生长过程详见算法1。
生成二视图决策树
输入:={(,),(,),…,(x,y)} 为一个二视图数据集,_为叶子结点的最小样本数。
输出:二视图决策树。


2.3 构建二视图随机森林
利用bootstrap 重采样技术随机抽取个自助样本集,在每个样本集上分别构建决策树,每棵决策树不受限制自由生长。ITVRF 由按上述方法生成的棵决策树组成。
在预测阶段,输入一个二视图样本对(,),ITVRF的最终预测结果由森林中的所有决策树投票共同决定:

其中,(∙)为指示函数,h是ITVRF 中的单个决策树分类器。
3 实验与结果分析
3.1 数据集

表1 UCI数据集统计信息Table 1 Statistics for UCI datasets
此外,还在3 个真实多视图数据集SPECTF、机器人执行故障数据集和Microsoft Research Cambridge v1(MSRC-v1)上对ITVRF进行了性能评估。SPECTF数据集包含两组与不同受试者应激状态和静息对应的图像特征,可被视为一组维度均为22 的二视图。机器人执行故障数据集描述了机器人在故障检测后的力和扭矩对应的两组特征,维度均为45,可被视为一组二视图数据。该数据集被划分为5 个学习任务,具体信息见表2。MSRC-v1 数据集共有240 幅图像,可分为8 类。本文选取了7 类作为实验数据。这些类是树、建筑、飞机、牛、脸、汽车和自行车,每个类有30 个图像。从每幅图像中提取4 个特征作为4 个视图,即颜色矩、方向梯度直方图、局部二进制模式和中间特征。结合不同特征,可以得到两个二视图数据集,具体信息如表3 所示。

表2 机器人执行故障数据集Table 2 Robot execution failures dataset

表3 从MSRC-v1 数据集中选择的二视图数据集信息Table 3 Two-view dataset information selected from MSRC-v1 datasets
3.2 实验设计
为了对每个方法进行公平比较,实验中所有RF参数都设成相同,即RF 中决策树个数均为10,每棵决策树的最大深度均不设限制,即不进行任何剪枝处理,叶子结点的最小样本数_均为2,决策树均选择信息增益准则作为不纯度准则。本实验重复10 次,选取平均值来比较各个方法的性能。评价标准采用AUC。实验仿真的参数详见表4。
表4 实验仿真参数Table 4 Experimental simulation parameters
引言部分提到,现有的TVRF 都是先为每个视图生成对应的RF,在决策阶段再进行融合,其中基于差异的TVRF将RF 作为生成差异矩阵的中间载体,再融合差异矩阵作为输入生成新的RF,而ITVRF 也同样可以计算出对应的差异矩阵并进行后续工作。本文着重研究的是最基本的RF 二视图数据融合方法,而非对已有的二视图RF 模型进行改造,故此处不对ITVRF 和已有的TVRF 方法进行基于差异矩阵处理后的比较。
为了全面比较和解释ITVRF 的性能,本文也专门针对fisherRF 设计了一个拓展的二视图fisher 随机森林(TV_fisherRF)。TV_fisherRF 的实现思路是,针对每个视图生成对应的fisherRF,最终预测结果由每个fisherRF 分别投票决定,其中,fisherRF 是指由若干fisher 决策树组成的RF。由于ITVRF 中的决策树和fisher 决策树都利用了样本的判别信息进行分类,TV_fisherRF 特别作为TVRF 和ITVRF 性能的中间比较方法。
3.3 实验结果比较
表5 为ITVRF 与现有的二视图RF 的比较结果,表6 为ITVRF 与现有多视图算法MLRA 的比较结果。通过分析可得出如下结论:
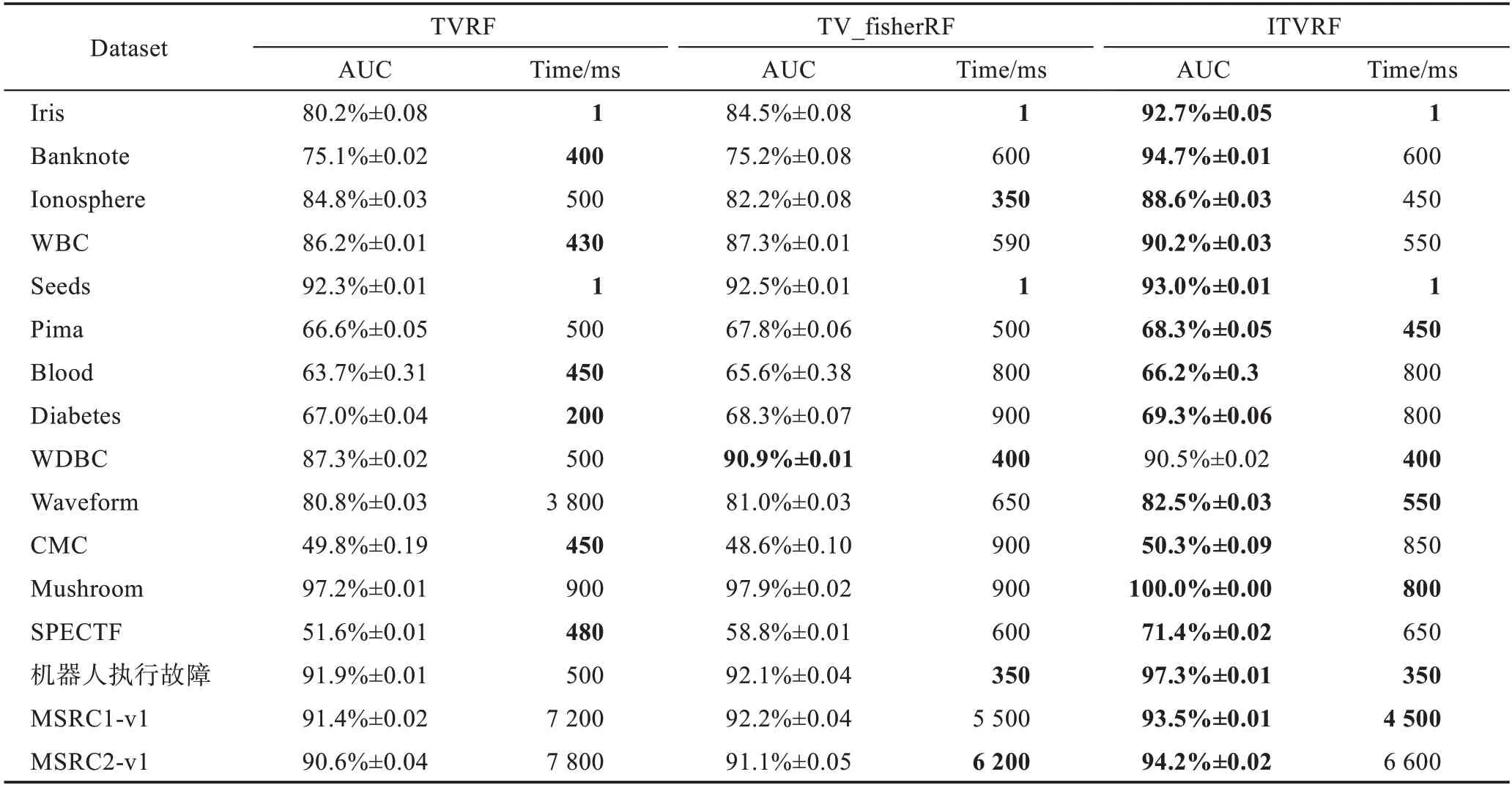
表5 AUC 值和运行时间Table 5 AUC value and running time

表6 ITVRF 与多视图算法MLRA 的AUC 值Table 6 AUC values of ITVRF and multi-view method MLRA
(1)相较于TVRF 和TV_fisherRF,ITVRF 的AUC值获得明显的提高。这是因为TVRF 和TV_fisherRF均在决策阶段才利用到了视图数据间的互补信息,而ITVRF 是在整个决策树的生成过程中都进行了信息融合。对信息的充分利用是ITVRF 取得更优性能的关键。
(2)TV_fisherRF的AUC值大多高于TVRF。TV_fisherRF 和TVRF 的不同之处在于TV_fisherRF 的基学习器是fisher 决策树,而fisher 决策树利用LDA 方法生成具有判别性的决策边界。由此可见ITVRF 的性能能够优于已有的TVRF 的另一个原因是CECCA方法生成的决策边界兼顾了样本的相关性和判别性,使其更加适合分类。
(3)对于特征数较少的样本集,如Iris、Banknote、Diabetes 等,ITVRF 的AUC 值显著高于TVRF 和TV_fisherRF。这是因为对于人工分割的二视图数据,视图之间的信息本身是互补的,这在特征数较少的样本中体现得尤为明显。现有的TVRF 在决策阶段才进行视图间的数据交互,导致了信息的严重欠利用。
(4)ITVRF 性能略优于多视图算法MLRA 性能。值得一提的是,ITVRF 聚焦于二视图RF 场景,主要关注的是如何实现在决策树生长过程中通过视图特征的逐层交互达到全程决策的融合,故ITVRF 更加关注与同类体系算法的比较。
3.4 参数分析
接下来研究ITVRF 中二视图决策树的个数、最大深度和叶子结点最小样本数_对性能的影响。
图1(a)和图1(b)分别表示在决策树个数取不同值时,部分手工分割二视图数据集和真实数据集上的AUC 值,其中的取值范围为{10,25,50,75,100}。从实验结果可以看出,随着决策树个数的增多,ITVRF 性能越好。
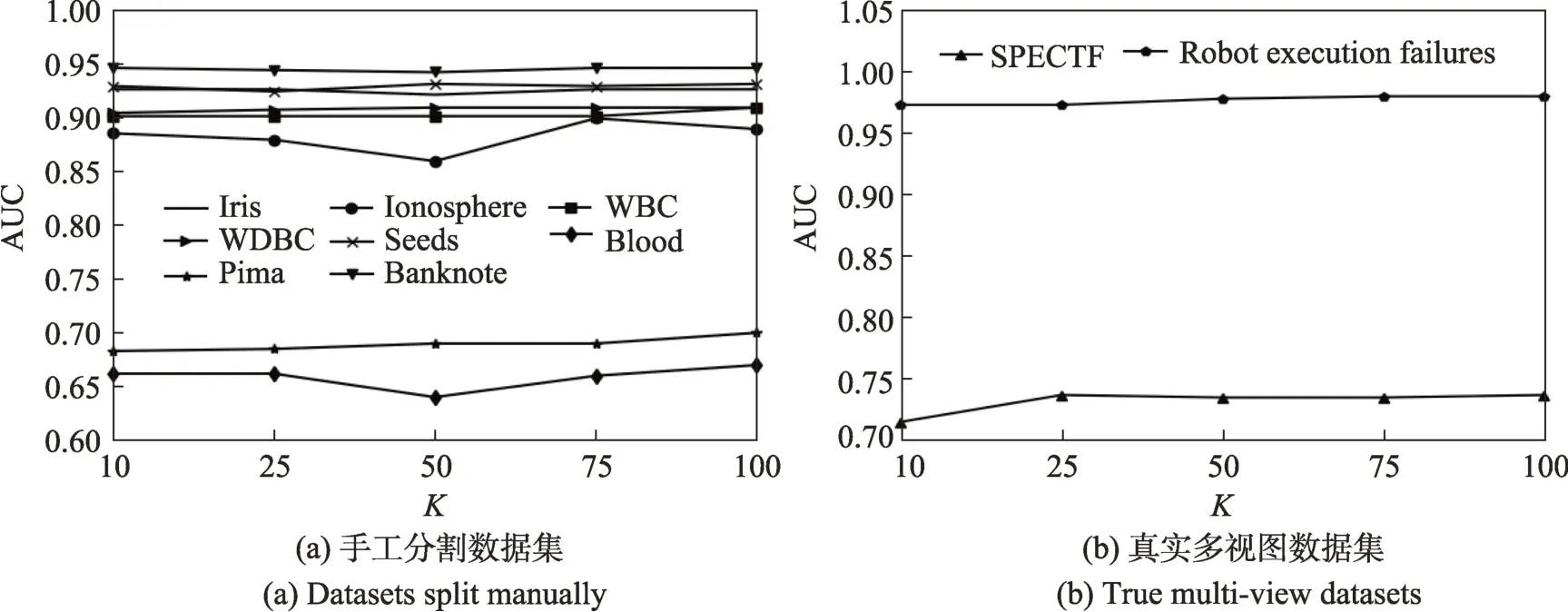
图1 不同K 值下的AUC 值Fig.1 AUC value with different values of K
图2(a)和图2(b)表示不同下ITVRF 在部分手工分割二视图数据集和真实数据集上的AUC值。的取值范围为{2,5,8,10,},其中表示所有决策树都生长到最大深度,即不进行任何剪枝处理。分析实验结果可以得到,随着的增大,AUC 值会随之增大。但若任ITVRF 完全自由生长,决策树可能会出现过拟合进而影响性能。
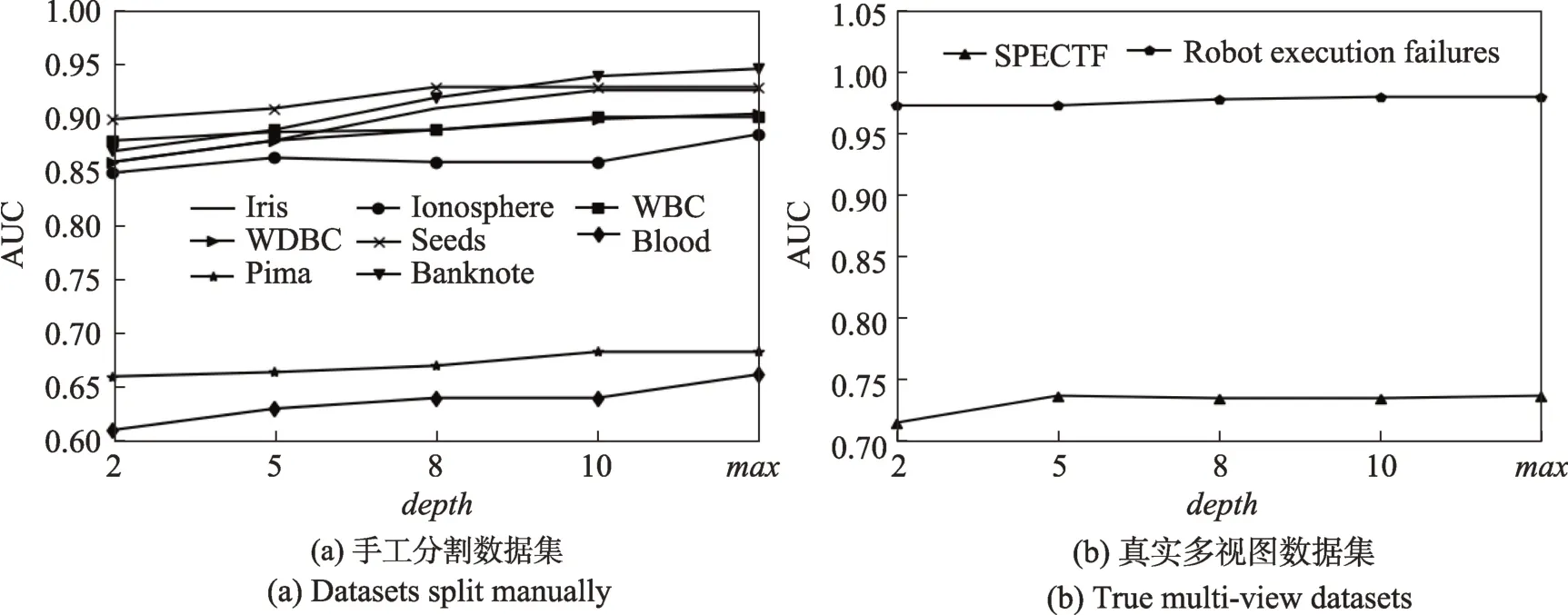
图2 不同depth 值下的AUC 值Fig.2 AUC value with different values of depth
不同_下ITVRF 在部分手工分割二视图数据集和真实数据集上的AUC值见图3(a)和图3(b)。_的取值范围为{2,4,6,8,10}。从图中可以看出,_值对ITVRF的性能无明显影响。
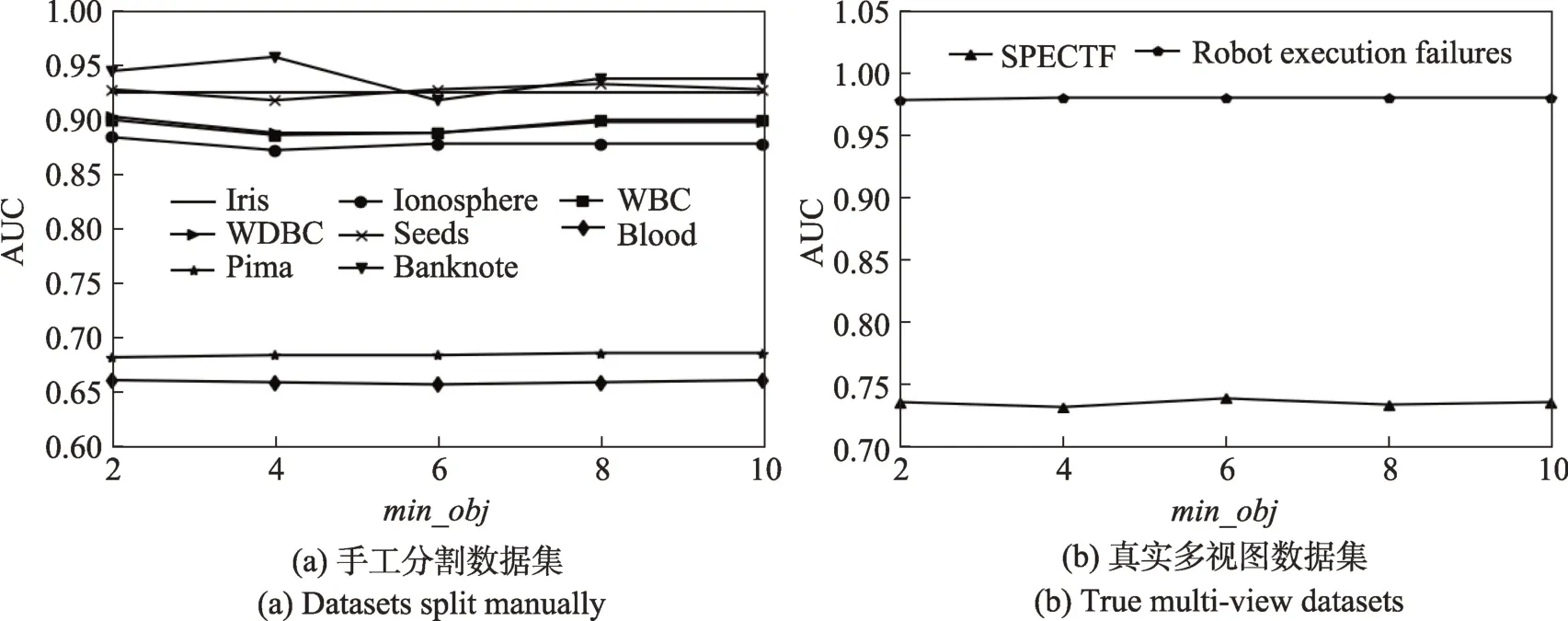
图3 不同min_obj 值下的AUC 值Fig.3 AUC value with different values of min_obj
3.5 算法复杂度分析
ITVRF 的运行时间见表5。可以看出在样本特征数较小时,TVRF 效率优于ITVRF。这是因为ITVRF 算法的步骤6 需要计算投影向量,时间复杂度为((+)3),其中和分别表示两个视图的特征数。
随着特征数的增大,ITVRF 比TVRF 的运行效率更高。因为TVRF 在结点分裂时需要在每个特征中依次搜索最优分割点,这无疑消耗了大量时间。而ITVRF 虽然计算了投影向量,训练时间略有增加,但无需在每个属性中搜索最优分割点。
可以看出,ITVRF 与现有的TVRF 实际应用成本相当。
4 总结与展望
多视图数据在现实世界中非常常见,从多视图数据中往往能够获取比单视图数据更有用的信息。然而RF 作为一类实现简单、性能优越的分类器,针对二视图或多视图的RF 构建却很少,且仅有的二视图RF 均未利用到RF 的层次结构。
本文在二视图场景下提出了一种改进的二视图RF 方法,在决策树生成过程中采用CCA 方法融合视图数据,将视图间的信息交互融入到决策树的全程构建之中,逐层实现视图间的互补信息在整个RF 生成过程中的利用。对比已有的TVRF,ITVRF 既全程融合了视图间的互补信息,又利用了数据的判别信息,分类准确率得到了显著的提高。
ITVRF 是在决策树构建阶段全程进行视图交互的一次成功尝试,因为使用了CCA 型设计,仅适合二视图场景,到多视图的推广需要另行设计,如将多集合CCA(multiset CCA)拓展到与本文相似的场景,或采用层次式两两判别CCA 设计,由于其中都涉及到非平凡的改造,将作为下一步的工作。
