BERT 辅助金融领域人物关系图谱构建
2022-01-18张纯鹏辜希武李瑞轩李玉华
张纯鹏,辜希武,李瑞轩,李玉华,刘 伟
华中科技大学 计算机科学与技术学院,武汉430074
信息化时代下,金融行业的各个公司、监管机构每天都会在互联网上发布大量的公告,将公告中的人员实体以及相关属性提取出来,发现人员之间的隐含关系,以结构化的形式描述金融行业中与人物相关的概念、实体及其关系,构建金融领域人物关系图谱,能够对金融活动进行深度分析,可以帮助金融从业人员进行合作伙伴选择、人事任命等关键决策,对促进金融活动的顺利完成具有重要意义。另外,伴随着我国经济的快速发展,金融活动的日益频繁,经济犯罪也越来越难以发现与监管,通过构建金融行业人物关系图谱,可以发现金融从业人员的校友、同事等社会关系,对预警潜在的金融活动风险,打击经济犯罪活动也具有重要意义。构建金融领域人物关系图谱关键是从非结构化的金融公告中抽取出人员相关的实体、属性以及事件,主要涉及到命名实体识别、关系抽取、事件抽取等子任务。
近年来,随着计算能力的不断提升,基于神经网络的深度学习技术逐渐成为了命名实体识别的主流方法。基于神经网络的方法将命名实体识别视作序列标注任务,搭建多层的神经网络模型,将文本中的单词或者字符表示为词向量,作为模型输入,通过神经网络模型对单词或字符进行分类,抽取文本中的命名实体。常见的神经网络包括卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural networks,RNN)等。Huang 等人提出了多种基于长短时记忆网络(long short-term memory,LSTM)的序列标记模型,通过对比实验表明双向LSTM 连接条件随机场(conditional random field,CRF)模型可以达到较好的命名实体识别效果;Strubell 等人将空洞卷积(dilated convolutions)用于命名实体识别,加大感受野,提高了模型的训练和预测速度;预训练语言模型可以从大量无标注文本中学到潜在的语义信息,为下游的自然语言处理任务提供更好的特征表示。BERT预训练语言模型在11 项自然语言处理任务上均取得了最好成绩,将BERT 应用于命名实体识别任务能取得更好的效果。
实体关系抽取指的是在实体识别的基础上,从非结构化文本中抽取出预先定义的实体关系。传统的关系抽取是在一句话中发现实体之间的关系,大都没有对关系的属性做进一步的抽取,且无法发现金融公告中跨文档的人员之间的关系。人员作为一个实体,往往包含若干实体属性(如出生日期、性别等),人员属性的提取将人员与实体属性建立关系,可以看作关系提取的一种特殊形式。目前从非结构化人员文本中提取结构化人员属性的研究较少,Dib 等人使用描述人物的Wikipedia 数据作为语料输入,通过分析句子依赖图,输出结构化的只包含任职经历的人物简历信息;Plum等人使用Wikipedia和Wikidata 作为数据源,提取满足特定要求的人员信息,但涉及的人员属性比较少。
非结构化的人员简历文本中通常包含多个任职事件与教育事件,如何不依赖触发词且准确地提取人员简历的多个任职事件与教育事件是一个值得研究的问题。现有的事件提取方法,通常是针对新闻等语料,大多依赖触发词来检测某种类型的事件,然后提取相关的事件参数,不适用于非结构化人员简历文本的情况。Zeng 等人提出可以通过事件中的关键参数来检测事件类型的存在,不依赖触发词检测事件并提取事件参数,但是无法解决非结构化人员简历这种具有多个任职事件和教育事件的特殊情况。
本文针对非结构化人员简历的特殊情况,通过研究一种填充层次化人员信息模板的方法,提取跨文档的人员之间的关系,在非结构化人员简历文本中不依赖触发词提取多个任职经历与教育经历事件,提出一种基于BERT 的中文金融领域人物关系图谱构建框架,实验表明所提出的方法可以有效地解决非结构化金融人员简历文本的信息提取问题,有效构建金融领域人物关系图谱。
1 相关基础
BERT 是谷歌提出的一种预训练语言模型,在11项自然语言处理任务上均取得了最好成绩,是近年来自然语言处理领域取得的重大的进展之一。
BERT 是基于Transformer的深度双向语言表征模型,利用Transformer 架构构造了一个多层双向的编码器(encoder)网络,基本结构如图1 所示,表示输入的句子中每个词的词向量,Trm 表示Transformer编码器,表示输入句子的每个单词的输出的词向量。

图1 BERT 模型结构Fig.1 BERT model structure
BERT 模型的输入词向量由三部分相加得到,这三部分分别是词表征(token embedding)、段表征(segment embedding)、位置表征(position embedding)。词表征表示当前词初始词向量,通常是查表获得;段表征表示当前词属于哪个句子;位置表征表示当前词在句子中的位置索引。另外,句子的原始输入需要添加[CLS]和[SEP]标签,[CLS]添加在开头,可以用来表征整个句子;[SEP]标签用于分隔两个句子,表示句子结尾。
BERT 预训练过程包含两个不同的预训练任务,分别是掩盖语言模型(masked language model)和下一句预测(next sentence prediction)任务。掩盖语言模型通过将某些词统一替换为标识符[MASK]的方式随机遮盖一些词,然后通过被遮盖的词的上下文信息来预测这些被遮盖的词,这样每个词的向量表示能够综合参考上下文信息。下一句预测指的是预测某个句子是否是另一个句子的下一句。这样便将句子之间的关系引入了模型,使得模型可以获取句子之间的语义信息。
BERT 模型完成预训练后,通过微调重新训练的方式,调整预训练过程中的模型参数,使得模型更适用于下游任务,从而获得更好的效果。针对句子级别的分类任务,取第一个标签[CLS]的输出向量表示作为句子表示;对于字符级别的分类任务,取所有字符的最后层transformer 输出,送到softmax 层做分类即可。
2 金融领域人物关系图谱构建框架
利用BERT 预训练语言模型构建金融领域人物关系图谱,使用如图2 所示人物关系图谱构建框架。该框架分为三部分:第一部分为人员属性实体抽取,该部分使用BERT 模型从金融人员简历文本中抽取出生日期、任职单位等人员属性实体;第二部分为人员属性关联,该部分通过定义并填充人员模板,将人员属性名与人员属性值关联起来,将相关的人员属性值关联起来,构成任职事件或教育事件;第三部分为人物关系图谱构建,该部分利用人员模板发现人员之间的关系,定义人物关系图谱存储模型,利用图数据库存储人物关系图谱。

图2 金融领域人物关系图谱构建框架Fig.2 Construction framework of financial personal relationship graphs
2.1 基于BERT 的人员属性实体抽取
使用BERT 模型对非结构化简历文本中的人员属性实体进行抽取。模型由输入层和24 个隐藏层构成,最后一个隐藏层的输出即为对应的每个字符的向量表示,利用每个字符的向量表示,进行人员属性实体的分类。将字符的向量编码输入到线性分类器中,再经过softmax 操作,得到每个字符对应每个人员属性标签的概率分布,选出对应最大概率值的人员属性标签,作为当前字符的最终人员属性标签分类。得到所有字符的模型预测人员属性分类后,对预测结果进行处理,得到非结构化人员简历文本中的人员属性实体。
2.2 基于BERT 的人员属性关联
使用BERT 模型抽取出的人员属性(如出生日期、人员职位、任职公司等)可能有多个候选值,需要确定某些人员属性名唯一对应的人员属性值,从而将人员属性名与人员属性值关联起来。另外,某些人员属性值之间有关联关系,有关联关系的人员属性值构成了某个事件实例,比如任职时间、离职时间、任职单位、任职部门、职位等属性值就构成了任职事件实例,需要将相关属性值正确关联组合,识别筛选出正确的事件实例。通过BERT-Template 方法填充人员模板解决人员属性关联任务。人员模板由固定的键值(key-value)对组成,存储为JSON 文件格式,以结构化的形式描述人员实体,记录人员的属性信息。人员模板的键用来标识人员的属性,通常用字符串来表示;人员模板的值与某个键对应,可以是数组也可以是具体的值。将值为数组的键称为人员模板的多值属性,将值不是数组的键称为人员模板的单值属性。人员模板的单值属性将人员属性与人员属性实体关联起来,对于人员模板单值属性,采用了一定的策略进行填充,通常选取单值属性对应的出现次数最多的人员属性实体进行填充。人员模板的多值属性记录了事件实例列表,将事件涉及的人员属性实体关联起来。
完成人员属性关联任务最核心的是建立人员多值属性实体之间的关联。通过BERT-Template 方法填充人员模板多值属性,完成人员多值属性实体之间的关联,该方法通过获取事件实例向量,对事件实例的真实性进行分类判断,从而不依赖触发词提取人员的多个教育经历与任职经历事件。事件实例分类的模型架构如图3 所示。在模型的输入层,将包含事件实例的句子输入到训练好的BERT 预训练模型中,获取BERT 模型最后一个隐藏层的输出,该隐藏层的输出就是句子中每个字符的向量表示,通过人员属性实体包含的字符在句子中的索引,将属性实体中所有字符的向量进行组合,可以获得人员属性实体对应的字符向量组。

图3 事件分类模型架构图Fig.3 Structure diagram of event classification model
在模型的融合层,使用每个属性实体对应的字符向量组生成事件实例向量。事件实例向量的生成方式如式(1)、式(2)所示。

式中,表示最终的事件实例向量,V表示事件中的人员属性实体向量,ev表示人员属性实体的字符向量组,MaxPooling 表示最大池化操作,⊕表示向量的拼接操作。首先,对人员属性实体的字符向量组进行最大池化操作(MaxPooling),获取到向量组中向量的每一维的最大值,然后将每一维的最大值组合成新的向量,作为人员属性实体向量,记为V;对当前事件实例所有的人员属性实体的字符向量组进行最大池化操作,就得到了当前事件实例所有的人员属性实体向量{,,…,V,…,V},将所有的人员属性实体向量进行拼接操作,得到最终的事件实例向量。
最后是模型的输出层,在输出层将事件实例向量送入到全连接网络进行分类,判断是否是真实的事件实例。
2.3 人物关系图谱构建
人员模板中包含了单值人员属性以及多值人员属性构成的事件实例列表。可以利用层次化的人员模板,发现人员实体之间的关系。
人员模板的某一个多值属性可以记为={,,…,e,…,e|≥0},其中e表示人员多值属性,记为e={,,…,t,…,t|≥2},其中t为人员属性值。人员模板与人员模板中的同一种多值属性分别记为_、_,人员模板与中的某种人员属性实体分别记为t、t,如果满足{t=t|(t∈e∈_)∧(t∈e∈_)}≠∅,则可以认为人员模板与人员模板在人员多值属性e上存在共现关系,即人员与人员具有某种关系。当e为毕业院校时,认为人员与具有校友关系(alumnus);当e为任职单位时,认为人员与人员具有同事关系(colleague)。
将人员实体映射为Neo4j 图数据库中的Person节点,将人员的单值属性及其对应的人员属性实体映射为Neo4j 图数据库中的Person 节点的属性键值对,将人员实体之间的同事关系和校友关系映射为Neo4j图数据库中的边。
定义好人物关系图谱在图数据库中的数据模型后,将人员模板中的信息以及3.3 节发现的人物关系,存储到Neo4j数据库中。
3 实验与分析
3.1 实验数据集
目前在中文金融领域尚无公开的人员简历文本数据集,本文从网络上爬取了上市公司年报、招股说明书以及公司官网上的文档,获取了金融公告中的非结构化人员简历文本信息,并通过人工标注的方式,对非结构化人员简历文本信息,进行人员属性实体相关的BIO(B-begin,I-inside,O-outside)标注,人员属性实体标注数据集的基本信息如表1 所示。

表1 人员属性实体标注数据集信息Table 1 Information of personnel attribute entity labeling dataset
通过人工的方式构筑层次化的人员模板,邀请多位金融领域专家对生成的数据集进行校对修改,保证了数据集准确性。人工构建的层次化人员模板数据集的基本信息如表2 所示。

表2 层次化人员模板数据集信息Table 2 Information of hierarchical personnel templates dataset
3.2 超参数设置
本文使用albert_large_zh 为基础模型,该模型由24 个Transformer 编码器构成,每个Transformer 编码器包含16 个注意力头,词向量的维度为1 024。
在微调训练阶段,本文设置批处理大小32,对应的学习率设置为2E-5,预热率为0.1,句子的最大长度设置为128,对数据集迭代6 次,在一块RTX2080Ti上使用adam 优化器训练。
3.3 人员属性实体抽取实验与结果分析
本文使用查准率()、查全率()和1 值作为人员属性实体抽取的评价指标,分别与基于启发式规则的方法、经典的BiLSTM-CRF方法进行对比。基于启发式规则的方法,通过人工编写一些模板或正则表达式,对文本中的属性实体进行抽取。人员属性实体抽取实验结果如表3 所示。

表3 人员属性实体抽取实验结果Table 3 Experimental results of personnel attribute entity extraction
由表3 可以看出,基于BERT 的人员属性实体提取方法与基于BiLSTM-CRF 的方法在查准率、查全率以及1 值三个评价指标上均超过了0.900 0。相对于基于BiLSTM-CRF 的方法,基于BERT 的人员属性实体提取方法在查准率、查全率以及1 值三个评价指标上,均取得了最优的效果。基于启发式规则的方法依赖于人工编写规则,而规则很难覆盖所有的情况,查准率、查全率与1 值和另外两种方法相比,效果最差。
3.4 人员属性关联方法实验与结果分析
从非结构化的文本中抽取出人员属性实体后,通过BERT-Template 方法构造层次化的人员模板,从而完成人员属性关联。将训练数据按照9∶1 的比例划分为训练集与测试集,使用训练集进行8 000 次迭代训练,训练过程中使用测试集测试模型。将BiLSTM-CRF 模型替换BERT 模型作为对比实验,教育经历事件实例与任职经历事件实例最终分类的结果评价指标如表4 所示,其中正确率()的计算方式如式(3)所示,其中表示被正确分类为某一类的样本数,表示将其他类的样本错误地分类成当前类样本的样本数,表示将当前类样本错误地分类成其他类样本的样本数,表示将负类预测为负类数的数量。

表4 事件分类结果Table 4 Event classification results

在任职经历和教育经历事件真假分类上,BERTTemplate 方法比BiLSTM-CRF 方法的1 值分别高了0.03 与0.03。综合来看,BERT-Template方法更优。
3.5 人物关系图谱构建评估
得到层次化的人员模板后,对人员模板之间的同事关系以及校友关系进行发现和抽取。使用抽取到的人员关系与人员模板信息构建知识图谱,存储到Neo4j 图数据库中。分别使用人工启发式规则、BERT-Template 方法和BiLSTM-CRF 方法构建的层次化人员模板进行人物关系的发现和抽取,与人工构建的准确的层次化人员模板进行人员关系发现和抽取得到的结果进行对比。对比结果如表5 所示。
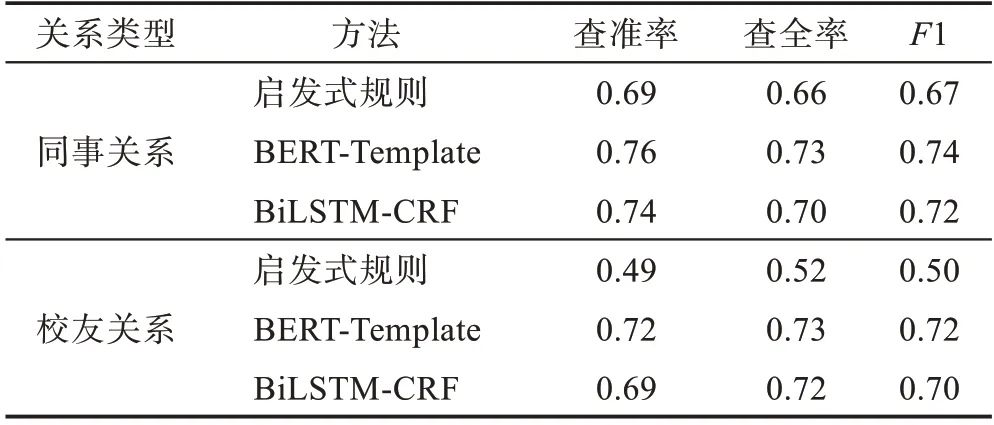
表5 人员实体关系发现与抽取实验结果Table 5 Experiment results of personnel entity relationship discovery and extraction
表5 中通过BERT-Template 方法,在基于BERT预训练模型构建的层次化人员模板的基础上进行人物关系的发现和抽取,与BiLSTM-CRF 方法相比,在同事关系与校友关系上,查准率分别提升了0.02 与0.03,1 值均提升了0.02;与启发式规则方法相比,在同事关系与校友关系上,查准率分别提升了0.07 与0.23,1 值分别提升了0.07 与0.22。综合来看,BERT-Template方法能取得较好的效果。
4 结束语
本文研究中文金融领域人物关系图谱构建方法,提出一种金融领域人物关系图谱构建框架,旨在解决现有的人员简历信息抽取方法存在的分散文本中的人物属性及其关系的发现与提取问题、非结构化人员简历文本中人员属性的抽取以及关联问题。使用BERT 模型,准确抽取出人员属性实体,利用微调训练好的BERT 模型对事件实例向量分类,构造层次化的人员信息模板,解决人员属性关联问题,最终通过填充好的人员信息模板,更加方便准确地提取人员关系,构建人物关系图谱。实验表明了该金融领域人物关系图谱构建框架的有效性。本框架依赖于人工标注的数据集,下一步考虑使用弱监督学习的方法,进一步地扩充数据集,减少人工构建数据集的工作量。
