消费者的信息属性价值感知对可追溯农产品偏好的影响分析
——以富士苹果为例
2022-01-17张心怡岳世茂刘瑞峰马恒运
张心怡,岳世茂,刘瑞峰,马恒运,梁 飞
〔1.加利福尼亚大学 圣地亚哥分校雷迪商学院,加利福尼亚 圣地亚哥CA92093;2.河南农业大学 经济与管理学院,河南 郑州 450046〕
一、引言
随着消费者对农产品质量安全要求提高,可追溯农产品商业模式已经出现。农产品质量安全不易观察且识别成本高,容易导致信息不对称问题,需要市场提供信息透明、质量安全有保障的农产品[1]。目前,可追溯体系通过在供应链上形成可靠且连续的信息流,监控产品流向,识别风险责任来源并实施问题产品召回机制,同时利用信号传递机制,为消费者提供更多的产品信息,满足消费者对农产品质量安全的需求,进而提高消费者信心[2-3]。完整的农产品可追溯体系不仅能够提供透明的可追溯信息,而且能够为消费者提供影响农产品价值的质量保证信息[4],例如,生产过程控制和认证等信息。因此,可追溯体系已经成为各国实施农产品质量安全管理的重要措施,同时,也是生产经营者实现农产品增值的营销工具[5]。国务院于2004年发布《关于进一步加强食品安全工作的决定》,明确表示开始建立农产品质量安全追溯制度。2010年以来,商务部开始分批选择试点城市建设肉菜流通追溯体系。2016年农业部提出《关于加快推进农产品质量安全追溯体系建设的意见》,并选择苹果、茶叶、猪肉、生鲜乳、大菱鲆等几类农产品统一开展追溯试点。然而,消费者对可追溯农产品的认知度仍很低,可追溯农产品的市场价值难以实现[6-7]。因此,了解消费者对信息属性价值的感知,研究其对可追溯农产品异质性偏好的影响,具有重要的现实意义。
可追溯农产品消费行为受到国内外学者广泛关注。早期研究将可追溯农产品整体作为消费者的决策对象,没有考虑农产品差异化问题[8-10]。基于Lancaster的消费者理论,可追溯农产品由多种信息属性构成,各种信息属性及属性水平组合的可追溯农产品具有多样性[11-12]。消费者在购买可追溯农产品时,通过综合权衡不同信息属性水平来做出决策。大量文献运用离散选择模型,研究消费者选择可追溯农产品的可能性与不同信息属性组合的关系[13-15]。根据可追溯农产品信息属性在消费者选择决策时的功能,Hobbs[16]将其分为事后可追溯信息和质量检测、安全认证、原产地、环境影响等事前质量保证信息。有些研究表明完整的可追溯信息更能够提高消费者效用[17-18]。但是,许多实证研究发现,可追溯信息为农产品获得的支付意愿并不高,消费者更愿意为包含质量保证信息的可追溯农产品支付更高溢价[19-21]。
可追溯农产品偏好受消费者特征影响且具有异质性。除了消费者社会统计特征,消费者对可追溯农产品的认知、态度、信任等心理统计特征,也显著影响可追溯农产品偏好和支付意愿[22-24]。然而,可追溯农产品效用判断的主要依据是信息属性满足消费者质量安全需要的程度,因此,研究信息属性价值感知这一消费者心理特征,是分析可追溯农产品偏好的关键。消费者之所以愿意购买某种信息属性组合的可追溯农产品,是因为该产品包含的信息组合具有较高的消费者感知价值,能够满足消费者的质量安全需求。从消费者感知的角度,信息属性价值包括预测价值和信心价值[25]。预测价值是指,消费者认为信息属性能够预测产品质量安全的程度,即消费者对信息属性的功能性态度。信心价值是消费者有信心能够在多大程度上正确感知和判断信息属性,即消费者对信息属性易用性的认知。Olson等[26]认为,信息属性同时具有高的预测价值和信心价值时,被消费者选择用于质量判断的概率更高。Grunert[27]对比几种信息属性的偏好发现,即便一些信息属性的预测价值很高,但仍可能由于其难以验证,或需要具有专业知识和专业技能经验,理论上对消费者偏好具有正向影响,但作用可能并不显著。而信心价值对信息属性偏好具有显著正向影响。
可追溯农产品异质性偏好及其影响因素,目前主要利用离散选择模型进行实证检验。早期文献采用二元logit或多元logit模型,研究选择可追溯农产品(属性)的概率与消费者的特征变量之间的关系。这些模型以消费者同质性为假设前提,无法考察影响因素在不同消费者选择行为中的异质性作用。综合考虑产品属性和消费者特征对产品选择的影响,混合logit模型被引入可追溯农产品选择行为研究。而且大量实证研究发现,考虑消费者异质性的模型拟合更好,消费者对可追溯农产品偏好具有异质性[28]。对于异质性原因的研究,许多文献运用随机参数logit模型,虽然能够估算出信息属性对每个消费者的效用分值,结果却无法直接揭示异质性原因,不能为市场细分刻画消费者群体特点[29]。而利用潜类别logit模型,能够对不同偏好类型下的信息属性效用分值和影响因素变量进行联合估计,并以概率形式给出各类别消费者分布。从而有助于分析不同消费群体对可追溯农产品信息属性的需求差异,识别每类消费者的特征,影响可追溯农产品的市场细分和市场绩效,所以更具有实际意义[30]。
综上所述,为进一步分析可追溯农产品偏好异质性及原因,区别于以往研究,本文创新之处表现在以下两方面:第一,与关注可追溯畜禽产品的大量已有研究不同,本文考察消费者对可追溯水果(富士苹果)的偏好。理论上,不同农产品的风险特点不同,信息属性的效用不同。而且水果在农产品生产和消费中所占的比重逐渐增大。因此,研究可追溯水果将有助于扩展可追溯农产品偏好的研究与应用领域。第二,本文在考虑消费者社会统计特征和水果消费特征的基础上,引入信息属性价值感知变量,分析可追溯水果异质性偏好的原因。因此,本文以可追溯富士苹果为例,运用潜类别模型,估计信息属性组合可追溯农产品的异质性偏好,并分析信息属性价值感知对偏好异质性的影响,进而揭示不同偏好群体特征和支付意愿,明确不同信息组合可能带来的经济利益。为可追溯农产品信息属性的选择和市场细分提供更有效的决策参考。
二、信息属性设置和实验设计
苹果是我国北方生产和消费的主要水果。2019年苹果种植面积和产量分别占国内水果产业的16.12%和15.49%(1)国家统计局农村社会经济调查司.中国农村统计年鉴2020[M].北京:中国统计出版社,2020(11):173-175.,是仅次于南方柑桔的第二大水果产业。2019年水果人均消费量为51.4千克,仅次于粮食和蔬菜的人均消费量(2)国家统计局.中国统计年鉴2020[M].北京:中国统计出版社,2020(9):172.。其中,苹果人均消费量大约占水果人均消费量三分之二(3)新浪财经.13亿中国人每年能吃掉多少苹果 产销平衡点在哪?[EB/OL].http://finance.sina.com.cn/money/future/agri/2018-11-19/doc-ihmutuec1603058.shtml.。因此,苹果质量安全出现问题,势必引起消费者高度关注,产生大规模影响。事实上,受到果品质量安全问题影响,近年来国内苹果销售已经面临滞缓压力[31-32]。为了增强消费者信心,2016年苹果成为中国市场上最早实行可追溯的水果之一[33]。因此,提高消费者对可追溯苹果质量安全信息属性的辨识度和认可度,是提高苹果消费信心,增强苹果市场竞争力的关键。本研究以可追溯苹果为例,同时,为排除品种偏好差异性的影响,选取可追溯富士苹果作为具体研究对象。
1.信息属性设置
对于可追溯产品而言,信息属性是产品具有的满足消费者质量安全需求的特性。同一信息属性的具体层次,即不同取值是可追溯产品效用差异的来源。根据可追溯农产品信息属性的现有研究,将可追溯富士苹果信息属性设置为:可追溯信息、认证信息、原产地信息和价格信息四种。同时,依据以下因素,为每个信息属性选取4个水平(见表1)。

表1 可追溯富士苹果的信息属性与属性层次设置
可追溯信息是可追溯苹果的基本信息属性。为了控制农产品安全风险,保障监管者和生产经营者实施监管和问题产品召回,农产品可追溯信息应该记录供应链全部环节信息,构建全程可追溯体系,实现可追溯信息传递的有效性。但在收入、信息识别能力和时间等约束条件下,消费者对可追溯信息的需求存在差异。了解消费者对信息追溯环节的需求,才能提高信息供给的有效性。因此,按照苹果供应链将可追溯信息分为无可追溯信息、包含种植环节信息、包含种植和流通环节信息以及包含种植、流通和销售环节信息4个层次。
认证信息借助其独立性和权威性向消费者传递产品质量安全信息[34]。认证农产品市场上,认证信息的差别不仅表现为政府与私人两种不同的认证主体,认证机构也具有来源国效应[35]。一些研究发现,中国消费者对欧盟有机标识的支付意愿远高于对中国有机标识的支付意愿。消费者对不同主体认证产品的偏好具有异质性。为了考察不同主体认证信息的消费者偏好,将认证信息分为无认证信息、政府认证、国内第三方机构认证和国际第三方机构认证4个层次。
原产地信息是消费者进行质量安全评价的重要线索。产品质量与产地所在区域的安全规制环境、行业标准和社会诚信程度等密切相关,而且水果的优劣品质还与产地的自然环境高度相关[36]。产地信息包含了口感、外观和新鲜度等感官属性信息,消费者通过消费体验能够进行验证,是水果购买决策过程中重要的事前质量保证信息。山东、陕西和新疆3个原产地是我国富士苹果的优势主产区,3个产地苹果的甜度、硬度和果汁密度等品质信息差别显著。因此,将原产地信息分为无原产地、山东、陕西和新疆4个层次。
为了测度信息属性价值,价格属性设定是选择实验方法的关键。通过实地走访大型超市、集贸市场、水果专卖店和农贸市场发现,6个被调查城市的苹果平均价格约为6元/500g。同时,借鉴郑风田等[7]的调查结果,可追溯苹果的支付意愿为1.85元/500g。因此,以6元/500g为基础价格等距上浮2元/500g,将富士苹果价格属性分为4个层次:6元/500g、8元/500g、10元/500g和12元/500g。
2.实验设计
本文采用选择实验测度可追溯苹果的偏好和支付意愿。选择实验方法具有经济学理论基础,能够提供更多消费者偏好信息,但保证实验结果的效度是选择实验应用的主要问题[37-38]。
为了降低实验过程中可能出现的信息处理偏差,保证实验结果效度,采用以下方法进行实验设计。首先,基于已选的各信息属性及层次,采用正交设计方案设定产品轮廓,构造选择集。根据已设置的4个苹果信息属性,以及每个属性包含的4个层次,如果按照全因子设计,最终将产生4×4×4×4=256个苹果轮廓。任意2个苹果轮廓随机配对,将产生256×256=65536组选择集。虽然全因子设计可以保证产品构造无信息损失,但会造成消费者的认知负担和选择偏差。因此,实验根据正交性和属性层次平衡原则,即正交设计方案,最终产生120个选择集,设计10个不同版本问卷,每个版本包含12个选择集(如图1)。第二,每个选择集中加入一个“不买”选项。一方面,更符合真实决策情境。另一方面,对比选择集中可选的苹果轮廓,消费者可以根据真实偏好选择不买,降低由强制选择造成的偏差。第三,引入“廉价磋商”(cheap talk)法,降低假想型偏差[39-40]。在实验正式开始前,提示消费者在虚拟市场和真实市场情况下支付意愿可能存在差异,请消费者在完成实验任务时综合考虑个人预算约束等因素。
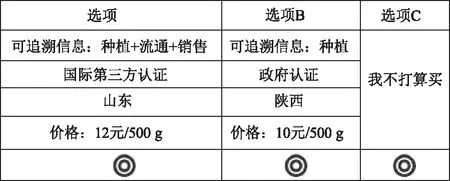
图1 实验选择集样例
三、数据来源、样本特征与计量模型
1.数据来源
本文实验于2017年7月—10月在中国北京、上海、广州、西安、济南和哈尔滨等6个城市进行。选择这6个城市进行实验调查的原因:首先,保证样本差异性。6个城市在经济社会发展水平和区域位置上存在差异;其次,为了提高实验的有效性,样本消费者需要对可追溯农产品具有一定了解和认知。目前可追溯农产品主要在城市销售,而且这6个城市是国家级或省级食品追溯体系建设城市,所以样本城市相对具备可追溯农产品偏好的研究条件。
2.样本特征
表2列示了样本消费者社会统计特征和苹果消费特征。总样本中,消费者性别比例基本相同,男性消费者占比50.72%略高于女性。消费者年龄、受教育程度和家庭月收入分布分别以25~34岁、13~16年和10000~19999元为主体。总体上,消费者对苹果具有较高的质量安全感知度。感觉比较安全和非常安全的消费者占比分别为39.15%和1.29%,47.51%消费者认为苹果质量安全状况一般。作为日常消费水果,苹果购买频率较高。每周购买1次苹果的样本消费者最多,占比36.28%。其次,分别是每周购买2~3次和两周购买1次的消费者,分别占25.67%和17.21%。
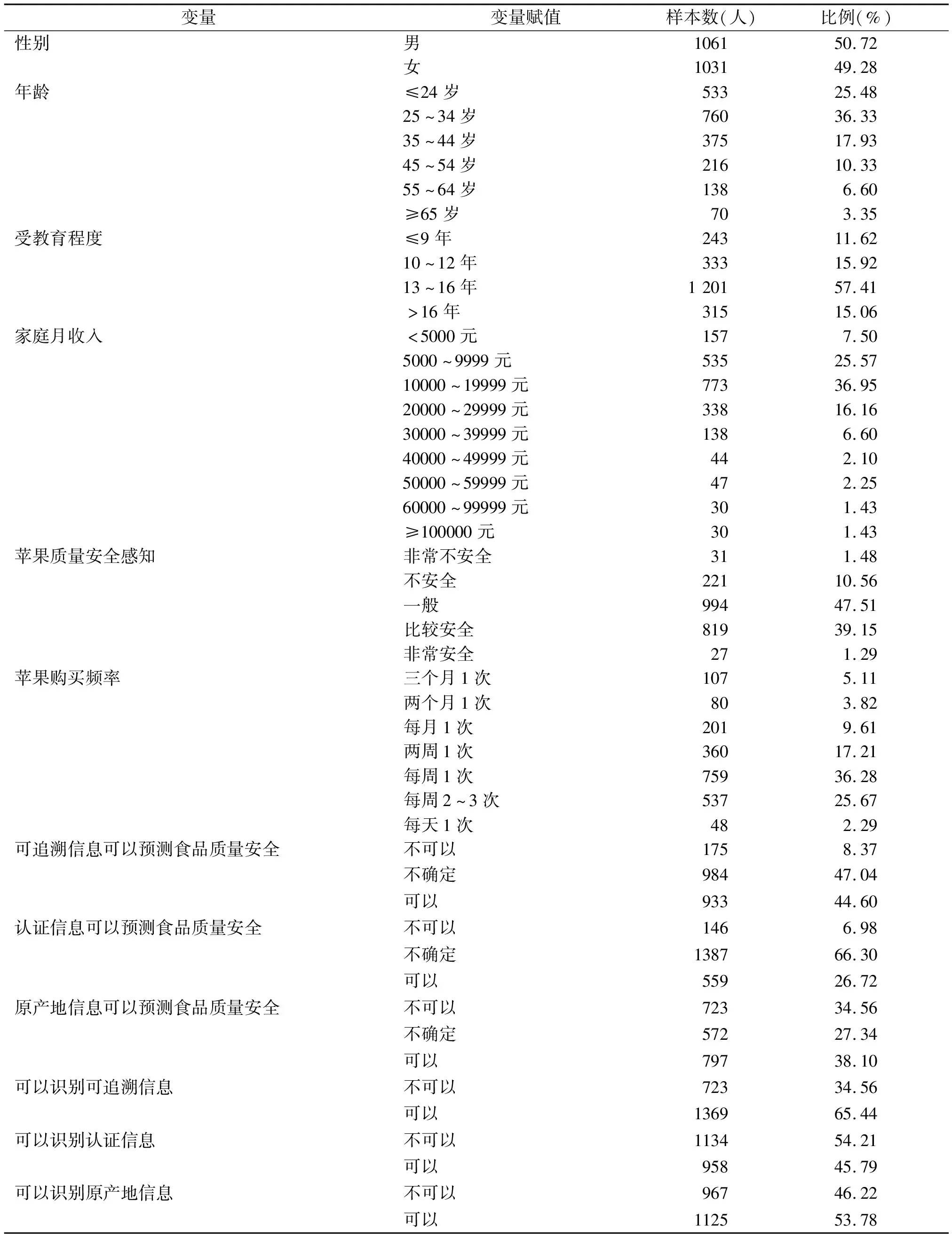
表2 样本消费者基本特征
同时,表2显示样本消费者对3种信息属性预测价值的感知较为一致,而对不同信息属性信心价值的认知则存在差异。对3种信息属性的功能性持肯定态度的消费者占比均高于持否定态度的消费者占比。对于可追溯信息和认证信息的预测价值,持不确定态度的消费者占比最高,分别为47.04%和66.30%。虽然对原产地信息预测价值持不确定态度的消费者占比最低,但持不认可态度的消费者占比远远高于不认可其它两种信息的消费者占比。可以识别可追溯信息和原产地信息的消费者比例分别为65.44%和53.78%,均高于表示不能识别的消费者占比。45.79%消费者认为能够识别认证信息,低于表示无法识别的消费者占比。
3.计量模型
根据Lancaster消费者理论,产品的效用来自产品所具有的属性组合。令Unit为消费者n在t情境下从M个选择集中选择苹果信息属性i所获得的效用,根据McFadden的随机效用理论,总效用Unit由两部分构成:
Unit=βxnit+εnit
(1)
其中,βxnit为效用确定项,xnit表示可追溯苹果的第i个信息属性,β是属性效用权重向量,表示消费者偏好具有同质性。εnit为随机项,当εnit独立且服从极值分布时,(1)式为条件logit模型(Conditional Logit)的效用函数。根据效用最大化原则,消费者n在t情境下选择苹果信息属性i的选择概率函数可以表示为:

(2)
可追溯苹果信息属性选择实验中,消费者n连续在T=12个情境中进行决策,选择信息属性i的联合概率函数为:
(3)
考虑到消费者偏好同质性假设不符合现实,各属性效用权重向量β并非固定,而是服从某种分布。通过对β的不同取值进行积分,可以将信息属性偏好异质性概率表示为:

(4)
(4)式称为混合Logit模型(Mixed Logit)的概率函数。其中,f(β)是β的概率密度函数。基于f(β)的不同假设形式,混合Logit模型能够非常灵活地模拟任何随机效用模型[41]。当f(β)为连续型分布时,消费者偏好具有个体异质性。而假设f(β)服从离散型分布,消费者的异质性偏好则具有群体性特点,有利于市场细分。假设消费者分为C个不同类别,各类别中消费者具有同质性,可以构造潜类别logit模型(Latent Class Logit),估计消费者偏好群体异质性。在假定消费者类别的前提下,消费者n选择属性i的概率为:
(5)
其中,βc为c类消费者群体对应属性系数的列向量,Lni(βc)为消费者n属于类别c的情况下选择属性i的先验概率,Hnc表示消费者n属于类别c的先验概率,可表示为:
(6)
(7)
由(7)式可以计算出所有消费者属于类别c的概率:

(8)
同时,由(7)式和(8)式可知,消费者类别概率由信息属性效用参数和消费者特征变量参数联合估计。通过对比分析两类参数估计值,就能发现消费者偏好异质性的原因。为了分析可追溯苹果偏好异质性的特点和原因,本文将同时考虑消费者社会统计特征、苹果消费特征和信息属性价值感知变量。其中消费者社会统计特征变量包括消费者性别、家庭收入和受教育程度。苹果购买特征包括苹果质量安全感知和购买频率。信息属性价值感知变量包括:信息属性的预测价值和信心价值。信息属性预测价值是指消费者对可追溯信息、认证信息和原产地信息增强食品质量安全的功能性态度。信息属性信心价值包括消费者分别对3种信息属性识别能力的认知。
四、估计结果及分析
1.潜类别logit模型的拟合与类别选择
通过逐一增加类别数目,检验潜类别logit模型与数据的拟合性,并确定最优类别数(表3)。为了选择适合模型的最优类别数,可以采用Akaike信息准则指标(AIC)、Akaike似然比指数(ρ2)和Bayesian信息准则指标(BIC)作为判断准则[42-43]。与Akaike似然比指数ρ2相反,AIC和BIC指标取值越小,潜类别模型拟合度越好。比较表3中模型拟合指标发现,随着潜类别数增加,ρ2从0.12增加到0.18,AIC值和BIC值持续下降。然而当类别从3类增加为4类时,3个指标变化程度都达到最大,模型拟合性获得最大程度改善,表明潜类别数为4时对模型拟合程度改进最大,是最佳的类别数。因此本文将消费者分为4类,分析可追溯苹果信息属性偏好异质性。
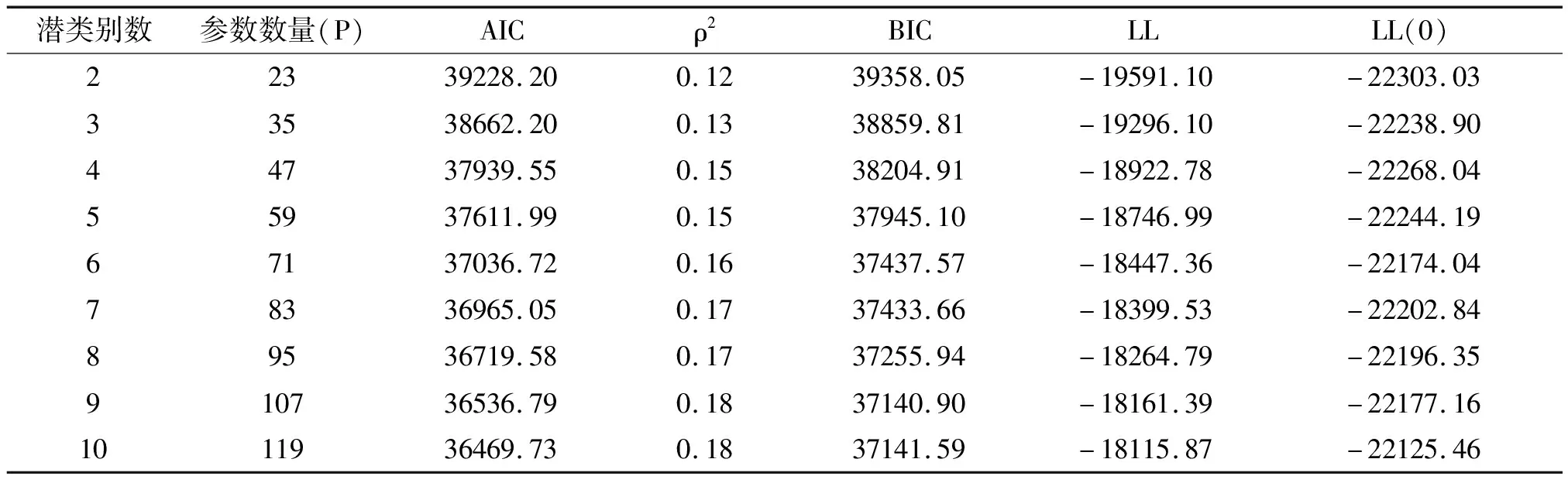
表3 潜类别logit模型拟合性检验结果
2.模型估计结果
为了保证模型稳健性并进一步验证潜类别模型拟合程度,表4分别列出了条件logit模型、混合logit模型和潜类别logit模型的估计结果。3个模型的显著性水平和系数估计值的符号基本一致。而且根据Log Likelihood和BIC估计,考虑个体异质性偏好的混合logit模型比条件logit模型具有显著改进,而考虑群体异质性偏好的潜类别logit模型的拟合程度最好。由此,验证了消费者偏好具有群体异质性的假设。

表4 3种logit模型估计结果
为了进一步考察信息属性偏好异质性及其影响因素,将消费者特征引入潜类别logit模型,估计结果见表5。根据表5上半部分类别概率和信息属性偏好估计结果,可以将消费者分为价格敏感型、认证偏好型、原产地偏好型和信息怀疑型4个类别,潜类别概率分别为31.8%、31.3%、19.7%和17.2%。任意消费者属于价格敏感型的概率最高,他们对于包含信息属性的可追溯苹果价格非常敏感。其次分别是更加偏好认证信息和原产地信息的消费者。还有17.2%消费者不愿意购买实验提供的信息属性组合的可追溯苹果。根据表5下半部分偏好类别协变量估计结果,以价格敏感型消费者为参照,进一步分析消费者偏好异质性特点和影响因素。
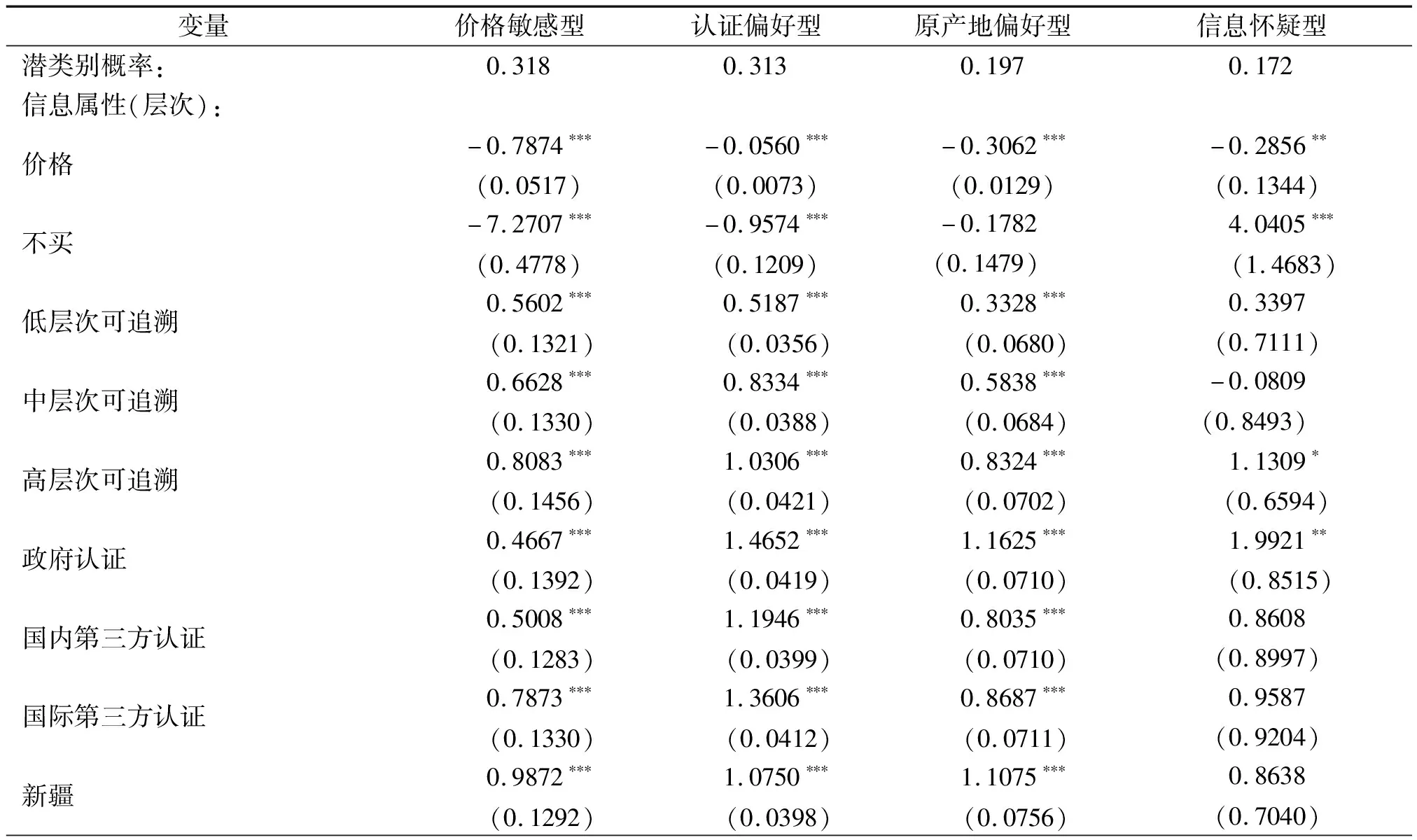
表5 加入消费者特征的潜类别logit模型估计结果
首先,受价格约束影响最大,价格敏感型消费者显著偏好3种信息属性,但程度最低。价格属性和不买选项的估计系数在1%水平上显著为负,且相较于其他3类消费者,两个系数估计值的绝对值最大,表明对于价格敏感型消费者而言,价格和不买的负效用最强;同时与其他消费者相比,价格敏感型消费者对各信息属性的偏好程度较低。因此,在不买对该消费群体具有最大负效用的情况下,对价格最敏感,可能最终导致他们显著偏好各信息属性但程度不高。在所有质量安全信息属性层次中,价格敏感型消费者认为原产地陕西的效用最高。
其次,认证偏好型消费者显著偏好3种信息属性,且最偏好认证信息。价格的估计系数显著为负,说明价格增加会降低认证偏好型消费者效用。但与其他类型消费者相比,价格属性的估计系数绝对值最小,表明认证偏好型消费者受到价格约束的程度最小。认证信息和原产地信息的信心价值估计系数分别在5%和1%水平上显著为正。因此,与价格敏感型消费者相比,认证偏好型消费者能够识别认证信息和原产地信息。而且,根据偏好类别协变量估计结果还可以发现,他们更可能认为苹果质量不安全,且具有较高的家庭收入和教育程度。
第三,对原产地偏好型消费者而言,3种信息属性都具有显著正效用,其中原产地信息的效用最高。原产地偏好型消费者偏好各层次原产地信息,且最偏好原产地陕西。原产地信息信心价值的系数估计值在1%水平上显著为正。表明与价格敏感型消费者相比,原产地信息更容易被原产地偏好型消费者识别,更能够提高其效用值,从而最受该群体偏好。与价格敏感型消费者相比,认为苹果质量不安全的女性高收入消费者更可能成为原产地偏好型消费者。
第四,相比实验提供的3种信息属性组合的可追溯苹果,“不买”选项对信息怀疑型消费者而言,效用更高。在4类消费者中,只有信息怀疑型消费者“不买”选项的系数估计值为正,且显著性水平为1%。同时,该类消费者也显著偏好政府认证和高层次可追溯信息,表明对于信息怀疑型消费者而言,为了提高可追溯苹果的效用值,生产者仅需提供政府认证信息、高层次可追溯信息,或者两种信息组合。该类消费者信息属性预测价值的估计系数显著为负,所以定义为信息怀疑型消费者,表明不相信可追溯信息和认证信息能够预测食品质量安全的消费者更可能归入该群体。相比价格敏感型消费者,该类消费者更可能具有女性和高收入特征。信息怀疑型消费者对苹果质量安全感知较低,同时购买苹果的频率也较低。
整体而言,信息属性价值感知有助于解释可追溯苹果偏好群体异质性。第一,认证信息和原产地信息的信心价值有助于区分认证偏好型和原产地偏好型消费者,两类消费者分别对认证信息和原产地信息的偏好程度更高。第二,可追溯信息和认证信息的预测价值对于理解信息怀疑型消费者至关重要。他们不认为可追溯信息和认证信息可以预测可追溯苹果质量安全,不愿意购买实验提供的信息属性组合的可追溯苹果,仅显著偏好高层次可追溯信息和政府认证信息。第三,原产地信息预测价值和可追溯信息信心价值的作用不显著。可能的原因是,原产地信息被认为是农产品最重要的质量安全线索,向消费者传递农产品口感、新鲜和人文社会环境等多种安全品质信息,满足不同消费者需求,所以原产地信息预测质量安全的功能性对消费者偏好异质性的影响可能并不显著。另外,与认证信息和原产地信息具有事前质量保证作用不同,可追溯信息具有事后追溯特点。所以能否识别可追溯信息,不会显著影响消费者在购买决策前做出质量安全判断,对于消费者偏好差异不具有显著解释力。
表6显示了95%的置信区间的信息属性支付意愿估计的平均值。观察表6估计结果可以发现,信息怀疑型消费者认为选择“不买”选项的效用最大,而且该类消费者对各信息属性支付意愿的估计值均不显著。因此,针对价格敏感型、认证偏好型和原产地偏好型消费者,进一步分析其支付意愿估计结果。

表6 各类型消费者的信息属性支付意愿估计结果
第一,对这3类消费者而言,认证信息和原产地信息的溢价水平整体均高于可追溯信息。其中,价格敏感型和原产地偏好型消费者对原产地陕西具有最高支付意愿,溢价水平分别为1.47元/500克和4.27元/500克。政府认证是认证偏好型消费者支付意愿最高的信息属性,溢价水平为26.14元/500克。因此,这一估计结果说明,质量保证信息具有更强的增值作用,政府和生产经营者可以通过添加认证信息和原产地信息,提高可追溯苹果的市场价值。
第二,对这3类消费者而言,3种信息属性具体层次的溢价水平排序各有特点。这3类消费者对高层次可追溯信息的支付意愿最高,其次是中层次和低层次可追溯信息,说明消费者越来越重视苹果供应链各环节信息。这3类消费者对认证属性3个层次支付意愿的排序不完全相同,消费者一致愿意为国际第三方认证支付高于国内第三方认证的溢价水平,但第三方认证和政府认证溢价水平的排序不同。根据本研究调查数据,对政府食品安全监管持不信任(43.79%)和不确定态度(47.61%)的消费者占比高达91.4%,仅有8.6%消费者持信任态度。说明近年来中国不断爆发的食品安全事件,降低了消费者对政府监管和国内认证的信心,但提高了消费者对新兴的国际第三方认证的预期。这3类消费者对原产地各层次信息支付意愿排序完全不同。可能是由于不同原产地意味着口感、硬度、甜度等品质属性不同,消费者对这些品质属性偏好各异。因此,可追溯信息属性各层次溢价水平排序具有一致性,不利于市场细分。而生产经营者可以根据认证信息,尤其是原产地信息属性不同层次溢价水平排序的差异性,根据细分市场特征,供给满足市场需求的信息属性层次组合可追溯苹果。
第三,3类消费者愿意为信息属性支付的溢价水平具有明显差异。价格敏感型消费者对各属性层次的支付意愿最低。认证偏好型消费者愿意为各属性层次支付的溢价水平最高,且明显高于真实购买中消费者愿意支付的价格水平。可能的原因包括:一方面,本文运用选择实验方法研究消费者支付意愿。为了降低选择性偏差,尽管我们采用广泛认可的“廉价磋商”法,并设置更接近真实的产品轮廓和选择情境,但与其它陈述性偏好方法一样,估计结果依然会存在选择性偏差。另一方面,根据认证偏好型消费者分布特征可知,与价格敏感型消费者相比,该类消费者对认证信息和原产地信息具有较高的信心价值。而且受到价格属性影响最小,所以支付意愿也相应更高。
五、结论与启示
本文利用选择实验法,在对6个城市2092个消费者调查的基础上,通过潜类别logit模型,估计消费者对可追溯信息、认证信息和原产地信息组合的可追溯富士苹果的异质性偏好和支付意愿。并从消费者社会统计特征、苹果消费特征和信息属性价值感知角度,进一步分析可追溯富士苹果偏好异质性的群体特征和原因,得出如下研究结论:
第一,按照类别概率从高到低的顺序,消费者分为价格敏感型、认证偏好型、原产地偏好型和信息怀疑型4类群体。受价格强烈显著影响,价格敏感型消费者对信息属性组合的可追溯富士苹果购买意愿最强,但支付水平最低。认证偏好型消费者,受价格约束的程度最低,愿意为各层次信息属性支付的溢价水平最高。其次为原产地偏好型消费者。信息怀疑型消费者对3种信息属性组合的可追溯苹果没有购买意愿,对各信息属性的支付意愿不显著。
第二,消费者社会统计特征、苹果消费特征以及信息属性价值感知能够解释消费者的异质性偏好。与价格敏感型消费者相比,认证偏好型消费者更可能是受教育程度较高的高收入者。而且该类消费者认为苹果的质量安全状况较差,更能够识别认证信息和原产地信息。认为原产地信息具有最高信心价值的消费者属于原产地偏好型消费者的概率更大,而且该群体更可能是家庭收入较高的女性消费者。怀疑可追溯信息和认证信息功能性的消费者更可能成为信息怀疑型消费者。该消费群体也以家庭收入较高的女性消费者为主,但购买苹果频率较低,且仅偏好政府认证和高层次可追溯信息。
第三,与可追溯信息相比,认证信息和原产地信息的溢价水平较高。其中,原产地陕西是原产地偏好型和价格敏感型消费者支付意愿最高的信息属性。认证偏好型消费者愿意为政府认证支付最高溢价。高层次可追溯信息是所有消费者愿意支付最高溢价水平的可追溯信息。
因此,根据以上研究结论,为更好满足可追溯水果的市场需求,可以采用可追溯信息和质量保证信息组合,同时需要考虑消费者偏好异质性特点。首先,生产经营者既要考虑消费者对高层次可追溯信息的共同需求,也可以利用认证信息和原产地信息具体层次的异质性偏好,提供满足不同消费群体需求的可追溯水果。其次,由于多种信息属性组合必然导致可追溯水果价格上升,考虑消费者支付意愿,探索不同的追溯标识,比如标签说明、合格证明、包装说明等,降低信息传递、显示和识别的成本和价格,满足更多消费者需求。第三,政府通过完善规制环境,培养市场主体诚信意识,并加强对可追溯水果的宣传,提高消费者对可追溯水果信息属性的预测价值和信心价值,可追溯水果才能获得更多消费者认可和信任,提高水果市场竞争力。
