医疗大数据平台设计与实现
2022-01-14李志军高荣鑫
刘 丹,李志军,高荣鑫
(吉林大学通信工程学院,长春130012)
0 引 言
天文学、医学等领域每天产生的数据已达到EB(Exabyte)字节以上[1-2],这些海量数据的收集、存储和处理问题亟待解决。分布式技术不仅能缩短数据处理时间,还能使多个用户同时使用。Hadoop框架是应用最广泛的开源分布式计算框架,其对计算机硬件要求不高,可靠性强,容错率高,扩展性好,理论上该系统可以布置在成百上千台的低成本计算机上。目前,针对医疗大数据面临的问题和挑战,各种实用性强的医疗大数据平台架构方案被提出[3-6],但医疗大数据平台网站的建设和相应功能的实现还没得到有效解决。
笔者开发了采用搭建Hadoop计算机集群方式实现的Hadoop平台,其功能包括:针对大量已知的医疗数据的存储、下载以及数据的共享,并为不同权限的用户给予不同的功能选项;用分析处理数据效率较高的Python脚本完成对数据的可视化展示。
1 平台总体方案设计
平台的设计从实用性与功能性的角度出发,采用分布式文件系统解决大量医疗数据文件的存储问题,以搭建网站平台的方式实现数据文件的共享、下载和可视化展示。
该平台包含两个核心部分:一部分是基于Hadoop搭建的分布式文件系统,另一部分是基于Tomcat服务器搭建的网站平台,使用Hadoop Web API将二者连结起来(见图1)。本平台既拥有可靠存储大量数据文件的优势,又拥有网站平台的轻量化以及功能多样化的优势。其中分布式文件系统可运行在普通的多台计算机中,而用于运行网站的服务器主机则需满足有较高的网络配置以及较大内存、硬盘等性能要求。
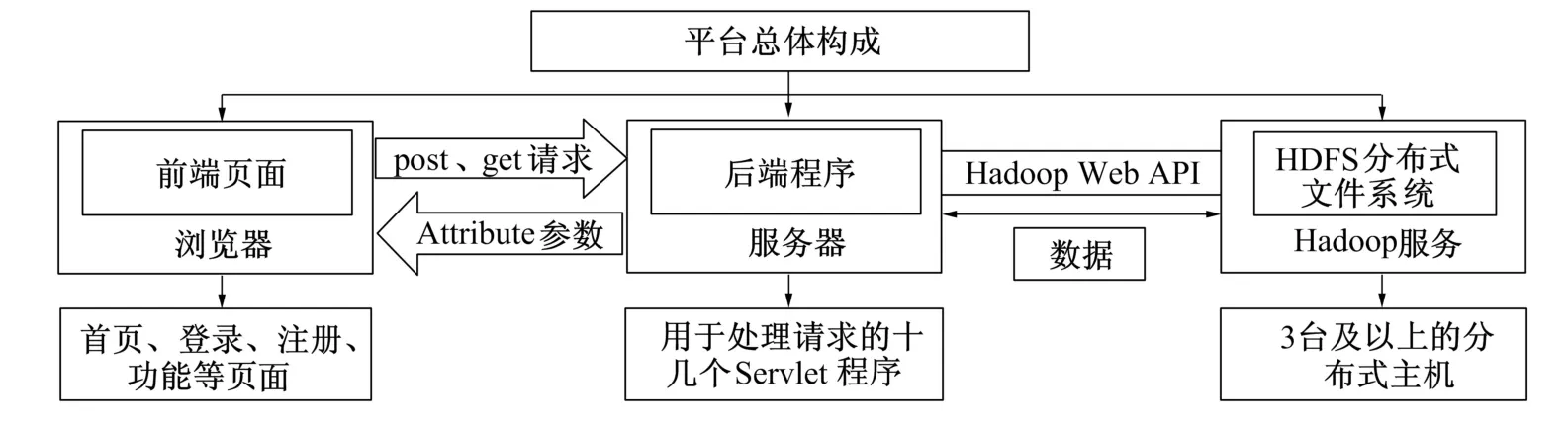
图1 医疗大数据平台总体架构示意图Fig.1 General architecture of medical big data platform
2 Hadoop分布式文件系统开发
2.1 分布式文件系统HDFS
分布式文件系统(HDFS:Hadoop Distributed File System)是Hadoop系统基本核心架构之一,主要由主节点和数据节点两部分构成[7-9]。主节点(NameNode)负责提供元数据服务,针对整个文件系统的存储空间、文件名称和路径、文件分块信息、备份信息及其存储位置进行管理,并对外部用户访问整个系统中的文件资源、文件操作进行控制。系统中通常存在多个数据节点(DataNode),数据节点的功能除了对已经分块的数据进行存储外,数据节点还可以接收主节点的指令,包括对数据块的创建、复制、删除和读取等命令。
2.2 分布式协调服务框架Zookeeper
此框架主要用于解决平台的数据管理以及系统一致性问题,同时也是Hadoop的重要组件。主要功能包括:数据的发布和订阅,资源的ID分配,分布式系统调度,用分布式锁以保证不同系统访问同一资源的一致性,分布式工作汇报,心跳检测,分布式队列。此框架的计算机集群是一个基于主从架构的高可用集群,包含领导者(Leader)和学习者(Learner)两部分,学习者又包含追随者(Follower)和观察者(Observer)。领导者负责检测和维护心跳机制,追随者可以直接处理读请求,拥有投票权,观察者的功能与追随者类似,但无投票权。此框架还有一个选举机制,在整个服务器启动或领导者宕机时,由各部分投票选举出领导者。
2.3 分布式文件系统的API编写
Hadoop平台基于Java语言开发,HDFS文件系统的操作基于Java编程实现,笔者使用版本为2018.2.2的编程软件IntelliJ IDEA。首先新建一个Maven工程,然后在src文件夹中的main文件夹中新建一个类,之后导入编写Hadoop API需要的依赖,其写法如下所示。需要导入的依赖名分别为:组名org.apache.hadoop,项目名hadoop-common、hadoop-client、hadoop-hdfs、hadoop-mapreduce-client-core,版本均为2.7.5;组名junit和项目名junit,版本为RELEASE。将依赖导入完成后,便可以进行代码的编写。


上传功能的代码中定义了一个有返回值的静态函数以方便使用时调用,函数名为HdfsUploadFiles,调用此函数时需要传入3个参数:1)HdfsPort为HDFS文件系统的IP地址和端口号(“hdfs:∥192.168.1.1:8020”);2)LocalFilePath是将要上传的文件在本地文件系统中的路径:(D:/Lenovo/test.txt);3)HdfsFilePath为用户想要上传到HDFS文件系统的目录(“/text”),“/”代表HDFS文件系统的根目录,按此方法填写路径,文件将上传到HDFS文件系统的text文件夹下,假如文件系统中没有此文件夹,系统将会自动创建此文件夹。在程序执行成功后将会返回true。
文件下载代码的函数名为HdfsDownloadFile,调用此函数同样需要3个参数。假如HDFS中不存在字符串中包含的文件,系统会输出错误信息,此外通过此函数下载文件时,在文件下载目录还会生成一个后缀为.crc的校验文件,执行成功后返回true。
文件删除代码用于删除HDFS文件系统上的文件,函数名为DeletHdfsFile,调用此函数需要传入HDFS端口号和HDFS上的文件路径,在删除成功后函数返回true。
创建文件夹代码用于在HDFS文件系统中创建文件夹,并且可递归创建,函数名为MkdirHdfs,调用此函数需要传入HDFS端口号以及想要在HDFS上创建的文件夹的路径,在创建成功后函数返回true。
用浏览文件代码可以浏览HDFS目录下所有文件及文件夹,同时将这些路径用“!”连接成字符串,以便之后将字符串解析成文件路径。
为方便对以上各函数的调用,使用软件将本工程导出为jar包,称之为HDFS API包。对于HDFS文件系统的操作均可通过调用该jar包中的方法实现。
3 Web服务器
本项目中所使用的服务器为汤姆猫服务器(Tomcat),该服务器具有以下特点[10-11]:占用各种资源都很小,部署及使用十分方便;支持Servlet和JSP(Java Server Pages);既能提供静态资源的访问服务,又能提供动态技术的服务;安全性较高,外部通过网络无法直接访问到后台代码内容;兼容性较好,许多制作Web项目的软件都为该服务器提供接口,并且可在软件内直接运行,十分方便高效。
为实现一个动态的网站,常用的技术包括Servlet和JSP两种。Servlet技术是在服务器上用Java编写并运行的程序,编写程序时需要导入所需接口的JAR包。客户端的用户请求信息通过服务器,发送给servlet程序,程序运行后得到结果,经服务器再发回给客户端;JSP技术指的是以.jsp为结尾的一类文件,在该文件中既可使用超文本标记语言(HTML:HyperText Markup Language),同时也能加入Java语言所编写的代码,本质上也是一种Servlet程序[12]。JSP文件必须运行在服务器上才能被解析为网页显示出来,不同于HTML文件,直接使用浏览器打开是无法显示JSP文件所想要显示的内容的。通过MVC(Model View Controller)模式[13]可使Servlet和JSP技术结合,Servlet实现控制与模型部分,JSP实现结果展示部分。
3.1 创建动态网页
从Tomcat官网上下载最新的8.0.5版本服务器,下载完成后解压在一定位置。配置好所需的服务器后就可以开始创建动态网页工程了。
制作网页使用软件Eclipse,版本:4.4.2。首先在软件中新建一个动态网页工程,该软件会自动创建该工程所需要的文件路径以及依赖等相关资源。在WebContent文件夹下主要存放有关HTML和JSP页面相关内容的资源文件。Java代码放在src文件夹下,根据Java代码实现的功能类别不同可以创建不同的文件夹,以便于后期的调整和维护。
新建Servlet程序只需在新建的文件夹上点击右键,在New选项中可以找到Servelt选项,在新建时根据需求选择使用doGet方法或doPost方法。
要完成文件浏览功能,不需要前端页面向后端程序传入参数,利用HDFS API包即可完成读取文件目录。代码导入后,就可以直接在代码中调用各种函数,在程序中调用函数并传入参数,会返回一个包含所有文件路径的字符串,对字符串进行简单的处理,便可将文件路径直接打印在前端页面进行展示。
对完成文件下载功能的Servlet程序,只需接收来自前端或其他程序的一个字符串变量,该字符串变量所包含的是文件在HDFS文件系统上的路径信息,便可以直接从HDFS文件系统将文件下载到服务器,之后文件再由服务器传输到客户端浏览器,浏览器便会自动接收文件并进行下载。
本项目中使用的前端框架主要为Bootstrap,包含各种快捷可用的网页页面设计,极大节省了设计制作前端页面所需的时间。与此同时,制作的前端网页包含部分验证功能以降低后端代码的复杂度,比如在前端动态验证用户注册的用户名是否存在,已存在则不可用,无法提交注册信息,此功能主要由JavaScript语言编写的脚本完成。HTML用于编辑网页的主要内容;CSS用于对主要内容编辑动画或其他视觉效果;JavaScript用于实现辅助功能。
3.2 数据可视化模块
本项目中数据可视化的实现主要过程:首先由Java程序运行python脚本进行文件数据分析,传出参数,由Java程序接收,经过转发将参数传递给前端,最后,通过前端插件echarts进行数据可视化展示。对python脚本的编写,需要读取并进行可视化展示的是Excel文件,使用Pandas库读取Excel文件中的内容,使用一定方法进行统计从而得出需要的表格信息,最后将数据通过插件显示。
3.3 其他功能模块的实现
本平台还设计了其他功能模块以便于功能的扩展。比如常用软件的下载模块:可将常用的功能软件放在服务器中,用户通过网页便可以直接下载并使用该程序;本平台还提供python脚本的运行环境,故可以在网站直接命令服务器主机运行指定的python程序并将结果返回给浏览器页面,使用服务器的计算资源而不占用客户端的资源。另外,该模块还提供了按照条件筛选数据的网页程序,该程序使用了Streamlit库,用于给出python程序一个可视化的网页,不同于其他Web工程,此程序在运行时只占用一个端口,不需要运行在网络服务器中,直接将数据展示在网页上,不需要配置路由等信息。
4 系统的安装和测试
Linux系统是安装Hadoop平台的最佳选择。由于实验室条件下可利用的计算机资源有限,故选择在1台计算机(后面称为试验机)上安装3台虚拟机模拟多台计算机的情况。
4.1 虚拟机的安装
测试计算机系统为Windows 10家庭中文版,系统版本号1909。第1步,安装VMware;第2步,安装Linux系统:下载CentOS的镜像文件,使用CentOS 6.5的64位版本。本实验中,试验机的内存为16 GByte,所以给每台虚拟机的运行内存设置为1~4 GByte。将已经安装好的虚拟机再复制两份,给这3台虚拟机分别命名node01、node02以及node03。
4.2 配置Linux环境
配置Linux环境:首先查看Windows系统内所有正在运行的服务,确认与VMware相关的服务已经全部开启。其次,在VMware的虚拟网络编辑器中查看NAT(Network Address Translation)设置,确认VmNet网卡已经配置好IP地址以及DNS(Domain Name System)服务器。最后,按照集群规划分别配置3台虚拟机的环境。启动虚拟机,开机完成后在命令行完成以下修改操作:修改每台机器的MAC地址、IP地址、主机名和域名映射。
所有内容修改成功后重启Linux系统,将3台机器配置为关闭防火墙,禁止开机启动,关闭Selinux,设置虚拟机的免密登录,最后设置3台虚拟机的时钟同步。
4.3 给Linux安装Java环境和Zookeeper服务
配置环境。首先查看3台机器自带的Openjdk并卸载,将从Java官方网站下载的以.tar.gz为结尾的Java环境安装包,上传到虚拟机中并分别在3台虚拟机中解压缩,之后再分别给3台及其配置Java的环境变量。
配置好Java环境变量后,再给3台虚拟机安装MySQL数据库。将从Apache官网下载的以.tar.gz为结尾的zookeeper安装包,本实验中所下载版本为3.4.9版本,之后解压此压缩包,修改其中配置文件并且分别给3台虚拟机添加myid配置文件。
最后分别在3台虚拟机命令行启动Zookeeper服务,使用以下命令运行服务和查看状态:

4.4 安装配置Hadoop和服务器
将Hadoop安装包上传到虚拟机,之后解压并修改配置文件,配置hadoop相关的环境变量。在各个虚拟机上启动集群服务,命令行输入jps,Hadoop运行成功。在命令行输入“sbin/start-dfs.sh”,便可以成功启动HDFS文件系统。
下载Tomcat服务器的压缩版本,之后将其解压在工程指定文件夹。解压后,进入到其bin文件夹下,在此文件目录中打开Windows命令行窗口并运行startup文件启动服务器。
4.5 工程部署与测试
关于网站工程的部署,笔者通过eclipse软件将工程导出成以war为结尾的文件包,之后将此文件放入服务器文件目录的webapps文件夹。这种方式比较方便,可节省服务器存储空间。
由于从外部网络访问网站需要专有域名或公网IP,在实验室为方便测试,使用内网穿透工具,此工具将本地端口映射到外部网络可以访问的域名。实验中使用钉钉内网穿透工具,进入到ding.exe存在的目录,在此目录下打开命令行,输入命令:ding.exe-config=./ding.cfg-subdomain=mbdp 8080。
之后该软件便将本机8080端口映射到mbdp.vaiwan.com域名地址,此时在网络任意一台设备的浏览器中输入以上域名便可访问到本机对应端口所共享的内容。
经过运行与测试,该网站能成功运行并完成相关功能。其用户注册页面如图2所示;经过实际测试文件的上传与下载等功能均能正常使用,其上传与下载速度取决于当时所处的网络环境,文件下载和上传页面如图3、图4所示;导入大量的医疗数据,经统计后可输出图形化显示,如图5、图6所示。

图2 用户注册页面示意图Fig.2 Schematic diagram of user registration page

图3 文件下载页面Fig.3 File download page

图4 文件上传页面Fig.4 File upload page

图5 显示数据关系的条形图Fig.5 Bar chart of data relationships
图6 显示数据关系的饼形图Fig.6 Pie chart of data relationships
5 结 语
笔者使用Hadoop分布文件系统、Web服务器开发设计了针对医疗大数据的平台,给出了本平台的总体设计方案、网站服务器及相应软件安装配置方法。通过平台的搭建部署以及测试运行,实现了数据存储、下载、数据的可视化展示以及运行脚本完成对数据的统计与分析等功能。
