基于深度随机森林的商品类超短文本分类研究
2022-01-13牛振东石鹏飞朱一凡张思凡
牛振东, 石鹏飞, 朱一凡, 张思凡
(北京理工大学 计算机学院,北京 100081)
短文本常指不超过200个字的文本,其主要特点是离散、即时产生以及用语新颖、噪声较多[1-17]. 短文本的处理难点,追本溯源是在于文本对象特征(即语言)本身所固有的多义性,即存在一词多义 (polysemy)和一义多词(synonymy)的特点,而短文自身所具有的特征稀疏性和上下文缺失的情况,造成了语义难以明辨,理解偏差无法消解,最终形成短文本底层特征和高层语义之间巨大的语义鸿沟[2]. 为了破解这样的难题,相关学者借助传统的文本分类方法如SVM[3]、BAYES[4]、KNN[5]等,通过降低其离散性、减少噪声特征、特征扩展等手法来实现短文本的有效分类. 而超短文本[6]比短文本更短,指的是文本只由几个字、词组成,字、词之间没有任何的相关关系,也无法构成任何有效的语义,文本包含的信息都集中在字、词本身. 另外,超短文本数据一般没有辅助标签信息,并且长度在20个字以内,如海关类数据中的商品名称:电热水壶、舒肤佳养肤香皂等. 这些商品名称数据不仅长度较短,而且不带有任何辅助标签信息[7].
随着短信、在线社区、微博客的兴起,网络超短文本已初具规模,其发展趋势已不可逆转. 特别是针对以即时消息、在线聊天记录、BBS 标题、手机短消息、微博交互、博客评论、新闻评论等为代表的超短文本信息 ,由于手持输入设备和移动交流方式的限定,不可能进行长篇累牍的交流. 另外,在日常文本自动处理中,也遇到越来越多的超短文本处理需求. 然而,由于超短文本相较于一般短文本存在更加明显的文本特征稀疏性和上下文缺失的情况,导致降低离散性等方法对其分类几乎没有效果,如何找出有效的处理方法成为了网络信息数据中超短文本分类领域亟需解决的新课题[8-9].
除了互联网数据,超短文本作为一种常见的语言表达形式也出现在生活的各个方面. 作为其中的一个重要代表,商品名称需要在蕴含企业品牌、用途、特色等信息的同时尽可能减少自身长度,造成了单位文本下信息量激增的现象. 加之俚语等因素的出现,导致基于计算机的自动化商品名称分类具有挑战性[10]. 例如,中国海关2018年12月份共计检验检疫出入境货物79.815 6万批次,进出口货运量37 835万吨,2018年累计进口货运量287 643万吨,海关机构需要将各种申报过关的货物按其类别进行分类,从而确定关税、统计进口货物分布情况,以便进行之后更深入的数据挖掘. 然而,通过人工审查进行商品分类需要非常大的人力成本及很多的工作量,且往往由于货物名目繁杂,采用人工的手段进行分类的效率和长期准确率并不能得到保证. 因此需要考虑将这个问题视作文本分类问题,通过计算机辅助进行处理. 虽然经过多年来的研究,传统文本分类方法已经比较成熟,短文本的分类也有许多学者进行了研究并取得了一定的进展,但是申报货物名称是以超短文本的形式存在,文本上下文信息明显缺失,并且通常会没有辅助标签信息,这导致目前已存的文本分类方法对该类超短文本进行分类时,很难得出理想的效果.
针对上述问题,本文提出了一种超短文本分类框架,该方法利用外部广告语料知识库和百科知识库对超短文本进行了特征扩展以确定类别. 之后,本文实现了一个深度随机森林分类器,对于不能直接通过百科知识库确定类别的超短文本,利用广告语料知识库将其向量化,再使用深度随机森林分类模型进行分类. 此方法在以往方法基础上,使用了一个随机森林分类器,使得分类速度和准确性显著提高,满足了商品名称分类的实时性等要求.
1 国内外研究现状
对于传统的商品名称分类,在海关、工商等法律和监管领域,手工分类是这些部门日常的工作内容. 因此,相应部门一般均制定了系统的商品类别标签[11-12]. 在自动化分类领域,SONG[13]使用了传统的数据库存储方式,每当出现新的商品名称时检索与该名称相似的已有名称,并将该相似名称的商品类别作为推荐的结果. 这种方式仍然没有解决缺乏先验知识和无相似结果的情况下的“冷启动”问题. 刘德建等[14]提出了将商品名称进行分词,并依据基于词法的模型实现相似度比较. 该方法能够比单纯的单文本匹配提供更加细致的检索,但是超短文本自身的特性会导致分词的过程准确率堪忧,从而再次引出缺乏先验知识等一系列问题.
不同于传统文本具有较为完整的上下文,短文本主要具有离散性高、特征稀疏、噪声较多等特点,这些特点阻碍了传统文本分类方法在短文本上的应用. 因此,针对短文本的这些特点,以往的研究主要从以下3个方面进行:①降低短文本的离散性;②优化训练样本特征;③扩展短文本特征.
1.1 降低短文本离散性
郭东亮等[15]首先通过Word2vec的Skip-gram模型获取短文特征,接着送入CNNs中进一步提取高层次特征,最后通过K-max池化操作后放入Softmax分类器得出分类模型;WANG等[16]提出,通过不同大小的词窗口进行上下文词嵌入,从而计算出短文本中的多尺度语义单元的向量表示,然后挑选语义单元中足够近的词表示构成文本扩展矩阵,最后通过CNN进行分类;CHEN等[17]构建相关主题文本数据库,利用LDA主题模型产生相应的隐含主题矩阵,对于待分类文本首先抽取特征向量,使用主题矩阵重新对各分量赋予权重,之后再计算两个文本之间的相似度;杨萌萌等[18]针对传统向量空间模型在短文本分类中维数高和短文本特征稀疏问题,分别提出了基于LDA模型主题分布相似度分类方法和基于LDA主题-词分布矩阵的主题分布向量改进方法,降低了相似度计算维度,融合了一定语义特征.
1.2 优化训练样本特征
黄贤英等[19]针对KNN短文本分类算法存在的扩充内容导致的短文本分类效率降低的问题,通过卡方统计提取某一类别中与该类别特征更加相似的训练样本,将训练空间拆分细化,提高训练样本的质量,减少KNN短文本分类算法比较文本数,从而提高效率;KALCHBRENNER等[20]提出动态卷积神经网络,不依赖于句法解析树,而是利用动态K-Max池化操作提取全局特征;Sun选出最能代表短文本语义的词语作为查询,使用搜索引擎查找出较少的最匹配查询的且具有类别标签的文本,然后选择出现次数最多的类别作为此短文本的类别,从而实现分类[1-21].
1.3 扩展短文本特征
ZHANG等[22]提出一种利用包含了待分类文本外部数据库,采用LDA进行主题模型的训练,抽取文本主题,然后将主题整合入文本从而实现对文本进行扩充的方法. 利用扩充后的文本训练出的向量进行分类,使得错误率显著减少;ZHANG和WU[23]在2016年提出一种基于N-Gram模型的特征扩展方法,在连续的词序列中抽取特征扩展库,然后通过短文本中的特征计算出不在文本中的词的出现概率,从而实现特征的扩展,之后使用贝叶斯分类器进行分类;LIU等[24]使用Word2vec方法构建了基于维基百科的相关语义概念集,然后利用此集合去扩充短文本的特征,从而实现短文本的分类;BOLLEGALA等[25]把短文本包含的词作为查询输入搜索引擎,利用返回的网页数及文本片段来计算两个查询词之间的相似度分数,然后利用支持向量机对相似度分数进行整合,从而进行语义相似度的度量.
以上方法对于200字以下的短文本,取得了一定的效果,也促进了短文本分类的发展,但这些方法也有其自身的局限性. 降低短文本的离散性只对于内部存在一定语义关系的短文本有较好的效果,通过这种方法可以挖掘出文本之中的概念间的相互关系,提高分类的精确性,但是对于离散度很高的、文本涉及的概念之间完全没有相关性的,这种方法很难有所发挥. 精心选择文本特征可以有效降低噪声对短文本的影响,提高特征提取的质量,但它并没有解决短文本特征稀疏的问题. 扩展短文本特征有效地将短文本扩展为相关的较长的文本,使得可以利用成熟的文本分类方法对短文本进行处理、分类,但其依然存在两个问题,分别是速度较慢和分类器性能较低. 在分类模型方面,近年来随着计算设备的运算与处理性能的不断增加,出现了越来越多的多分类器组合和堆叠的集成学习方法. 2017年,南京大学周志华等[26]提出了将随机森林等分类器作为元素首次构建出了层级模式的集成学习方法,并将其命名为深度随机森林(gcForest),该模型在文本情感分析、低维度特征、手势识别及面部识别等多个有监督学习任务中在准确性和训练时间上均取得了良好的结果.
在超短文本领域,YANG等[27]于2018年提出了基于协同过滤方法的超短文本分类模型. 该模型虽然能够在一定程度上通过协同过滤模型解决税务领域的超短文本分类问题,但是需要待分类数据拥有商家填写的预判类别,从而构造用户-项目矩阵,对发票上的物品类别进行推荐,最终判断商家填写的发票信息是否有误. 本文主要在扩展短文本特征方面进行研究,针对速度和分类器的分类性能两个方面,采用“分流”策略进行分类:利用基础知识库训练一个深度随机森林分类器,对于知识库中存在的知识,直接确定类别;对于知识库中不包含的知识,采用Word2vec工具对扩展后的特征进行向量化,然后用深度随机森林分类器进行快速准确地分类.
2 基于搜索引擎扩展知识和深度随机森林的超短文本分类方法
2.1 超短文本分类框架
如图1所示,所提出的分类框架依赖了外部知识库. 首先,根据数据定义出相应的商品类别,并对类别名称进行扩展;之后在网络上收集的大规模广告语料库作为知识库,主要用于对超短文本进行向量化;接着从商品名的数据中抽取出一定量的样本,向量化后作为训练集训练出一个分类器,并设置分类器的扩展集以对分类器进行更新. 在对商品名进行分类时,先将其作为查询输入到百科知识库,抽取类别信息,如果成功查询到相关的百科信息,则可利用实体和关系抽取工具抽取其分类信息,并将该次的类别结果其加入分类器扩展集;若没有查询到相关百科信息,则将该文本输入到搜索引擎及外部的广告语料库等外部知识库以将其向量化,再利用分类器进行分类,确定分类结果. 其中,当分类器扩展集大小与分类器的训练集大小相同时,就将扩展集中的样本加入训练集,重新训练分类器,直到训练集达到设定的上限.
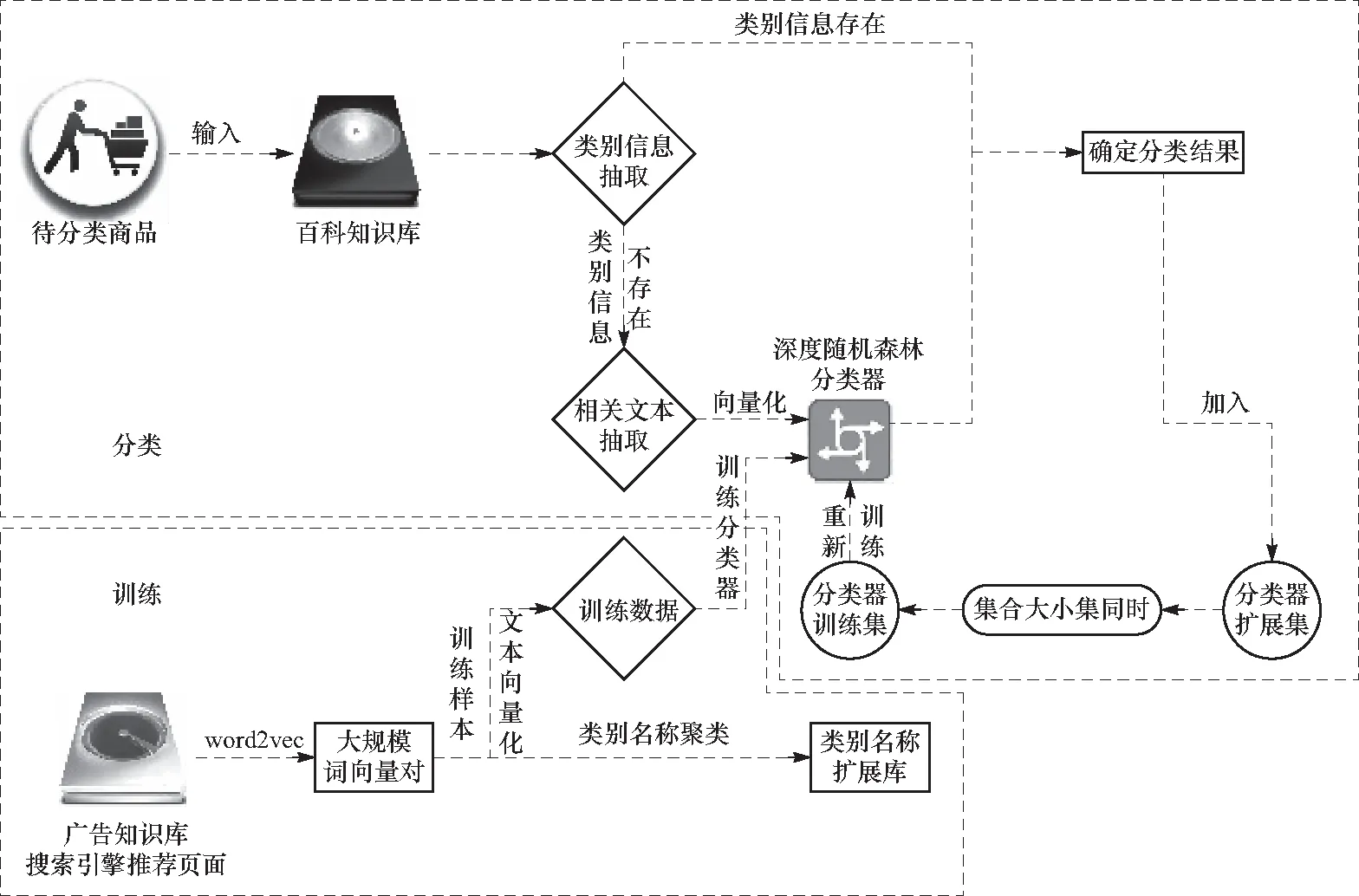
图1 超短文本分类框架Fig.1 Classification framework of ultra-short text
2.2 通过Word2vec进行大规模词-向量对预训练
Word2vec是2013年Google开源的一款工具,它的核心是神经网络的方法,采用CBOW和Skip-Gram两种模型,以文本集作为输入,通过训练生成每个词对应的词向量,保证具有相近语义的词,映射到向量空间中,向量之间的距离也相对较小.
Word2vec的CBOW模型利用某个词的上下文去预测当前词,Skip-gram模型恰好相反,利用当前词去预测它的上下文. 这两种模型的训练过程类似,在此只介绍CBOW的训练过程. CBOW是一种神经网络模型,它的输入层是当前词w的上下文中的2c个词向量,而隐含层向量Xw是这2c个词向量的累加和. 输出层是以训练语料库中出现过的词作叶子结点,以各词在语料库中出现的次数作为权值构造出的一棵Huffman树. 在这棵Huffman树中,叶子结点共N(=|D|)个,分别对应词典D中的词,非叶子结点共N-1个. 通过随机梯度上升算法对Xw的结果进行预测,使得p(w|context(w))值最大化,context(w)指词的上下文中的2c个词. 当神经网络训练完成时,即可求出所有词的词向量[28].
本文使用在网络上收集到的与各种商品名相关的广告语料,包括商品名称及对此商品的描述来构建广告语料库,该语料库的来源主要有两个方面:①网络上的语料库中下载相应的商品名;②找到的最新的商品广告语加入语料库. 本文通过对广告语料库进行处理,使用Word2vec模型,获得大规模的词-向量对
2.3 训练深度随机森林分类器
利用数据及其所属的商品类别,本文定义了10个商品类别. 使用所获取的海关商品名实验数据,包括品目号及其所对应的各种商品名称构建商品名语料库. 接着从商品名语料库中,每一类商品抽取30条,共300条,手动标记商品分类,并将其在百科中的包含商品类别的语句所在的段落p,利用上一步中生成的词-向量对加权平均,对段落进行向量化,作为训练语料库T. 然后利用深度随机森林模型,训练出一个深度随机森林分类器. 设置一个扩展语料库E,用于对训练数据进行扩展.
2.4 利用K-Means对类别名称进行扩展
K-Means算法是一种聚类算法,其是根据样本之间的相似度,采用距离作为相似性的评价指标,将相似的样本自动聚集为一个簇,从而实现聚类的过程. 利用该算法,本文将广告语料库中的词向量进行了聚类,进而得到语义上与10个商品类别相近的词语,从而可以对商品类别的名称进行扩展[29].
从商品名语料库中,对各个类别的商品描述进行总结. 以品目号6902为例:“6902:耐火砖、块、瓦及类似耐火陶瓷建材制品,但硅质化石粉及类似硅土制的除外”,先将此描述总结为“建筑材料”,即品目号6902 对应的所有商品属于分类“建筑材料”. 然后对此分类名进行扩展,在广告语料库中寻找与“建筑材料”含义最接近的词作为扩展名. 寻找方法为:先将广告语料库中的词全部用Word2vec向量化,然后利用K-Means算法进行聚类,找出与“建筑材料”最相近的词作为其扩展名. 一般地,均采用此种方法对预定义的类别名称进行扩展:利用第 2 步中得到的大规模词向量对,采取K-Means算法进行聚类,从而得到每一类商品名的最相关5个描述词,Ci(i=1,2,…,10)表示每一类的描述词集合. 扩展结果如表1所示.

表1 类别名称扩展表Tab.1 Category name extension table
2.5 通过深度随机森林分类器进行分类
深度随机森林是一种深度集成学习方法. 它是针对深度神经网络的几个不足之处:①需要的训练数据量大,难以应用在小规模数据集上;②参数调节困难;③训练时间长等而提出的新的深度学习方法.
深度随机森林以随机森林作为基分类器,分为多层Fi(i=1,2,…,N),每一层分别设置两个完全随机森林和两个随机森林. 其中,完全随机森林包括500棵完全随机树,完全随机树的结点是随机地在特征空间中抽取某一特征而生成的;随机森林包括500棵随机树,随机树的结点是随机地在特征空间中抽取个特征(d为输入特征的长度),然后选取其中Gini系数最大的特征而生成的. 每一层Fi(i=2,3,…,N)的输入特征向量是原始特征向量再拼接前一层Fi-1(i=2,3,…,N)的输出向量. 第一层的输入是原始的特征向量R= {r1,r2,…,rn}.
若是分类结果可能有m种情况,对于第i层,每个随机树的输出为一个m维的向量D= {d1,d2,…,dm},向量的各个维度的值di(i=1,2,…,m),代表D属于各个类别的可能性. 每个随机森林的输出,是将森林中包含的500棵随机数分别生成的500个m维向量进行加权平均,生成4个新的m维向量Di= {di1,di2,…,dim}(i=1,2,3,4),向量的各个维度的值代表原始特征属于每一类别的概率. 而每一层的输出,是将这一层4个随机森林的输出Di(i=1,2,3,4)与原始特征向量R进行拼接,使得原始的特征向量R增长为Ra={r1,r2,…,rn,d11,d12,…,d1m,…d41,…,d4m}再作为下一层的输入. 最后一层的输出,是将当层的4个随机森林的输出结果进行加权平均,取数值最大的维度所代表的类别作为特征R的最终类别[28].
对于新的商品名n,先将其作为查询输入百度百科及维基百科,抽取首段文本Tn,进行分词、去除停用词处理后,将其中的词与预先定义的十类商品的描述词进行匹配,若商品名n与描述词集合Ci匹配成功,则将此商品划分为ci类. 若新的商品名n匹配失败,则需要直接获取扩充文本Tn. 获取方法如下:若百度百科及维基百科中有此商品n的词条,则取首段文本作为Tn;否则,抽取搜索引擎返回的首个结果的切片作为Tn. 得到扩充文本Tn之后,利用第2步中得到的词-向量对进行向量化得到向量L. 将向量L利用深度随机森林模型进行分类,得到类别ci. 上述步骤得到新商品名的类别后,将商品名n,类别ci,首段文本Tn保存入扩展语料库. 当扩展语料库与训练语料库大小相等时,将扩展语料库中的样本加入训练语料库,重新训练随机森林分类器,直到训练语料库中的样本数超出某个阈值,阈值设置为100 000.0.
3 实 验
3.1 数 据
本文所采用的实验数据为深圳海关2017年4月—5月过关商品的部分登记情况,根据原数据总共选取10个类别,将每一张报表中的内容作为一条数据信息,其中商品名称作为超短文本分类数据,总共包含93 686条信息. 训练样本的详细分类信息见表2.

表2 训练样本分布表Tab.2 Distribution table of training samples
3.2 预处理
对于海关商品领域数据,在进行超短文本分类操作之前,预处理往往是必要的. 首先,海关商品数据中存在很多垃圾数据,例如:商品名称仅仅只写了一个字的错误数据;商品名称中包含非法字符的数据;商品名称写成了商品的其他属性值的数据等. 具体样例如表3所示.

表3 垃圾数据样例Tab.3 Samples of garbage data
其次,对数据集中相对较长的商品名称根据词典进行分词处理,例如:“兰蔻柔皙清透防晒露”,根据分词处理结果为:“兰蔻/柔皙/清透/防晒露”. 在分词处理过程中,结合停用词表,去除不需要的停用词.
最后,对于相似度高的商品名称,可以进行合并处理. 例如:“奥利奥夹心饼干”、“奥利奥巧心结”、“奥利奥原味的夹心饼干”这3个商品名称经过去垃圾、分词以及去停用词操作后,再通过计算相似度得出他们之间具有很高的相似度值,因此,可以将这3个商品名称记录成单个名称进行处理.
3.3 结 果
本文实验采用准确率(Precision)、召回率(Recall)和F1值对分类结果进行评价. 具体评估方法为,对于测试集的分类结果,若采用此方法得到的分类与预先标记的类别完全相同时,则认为此条分类正确,否则认为分类错误. 准确率和召回率的计算方法如下.
式中:li代表类别为i且被分到i类别中的文本数;mi代表类别i的总文本数;ni代表测试集中真实类别为i的总文本数.
与此同时,也进行了相应的对比实验,在该数据集上分别采用KNN和决策树方法进行了实验,计算出了相应的准确率和召回率,实验结果如表4所示.
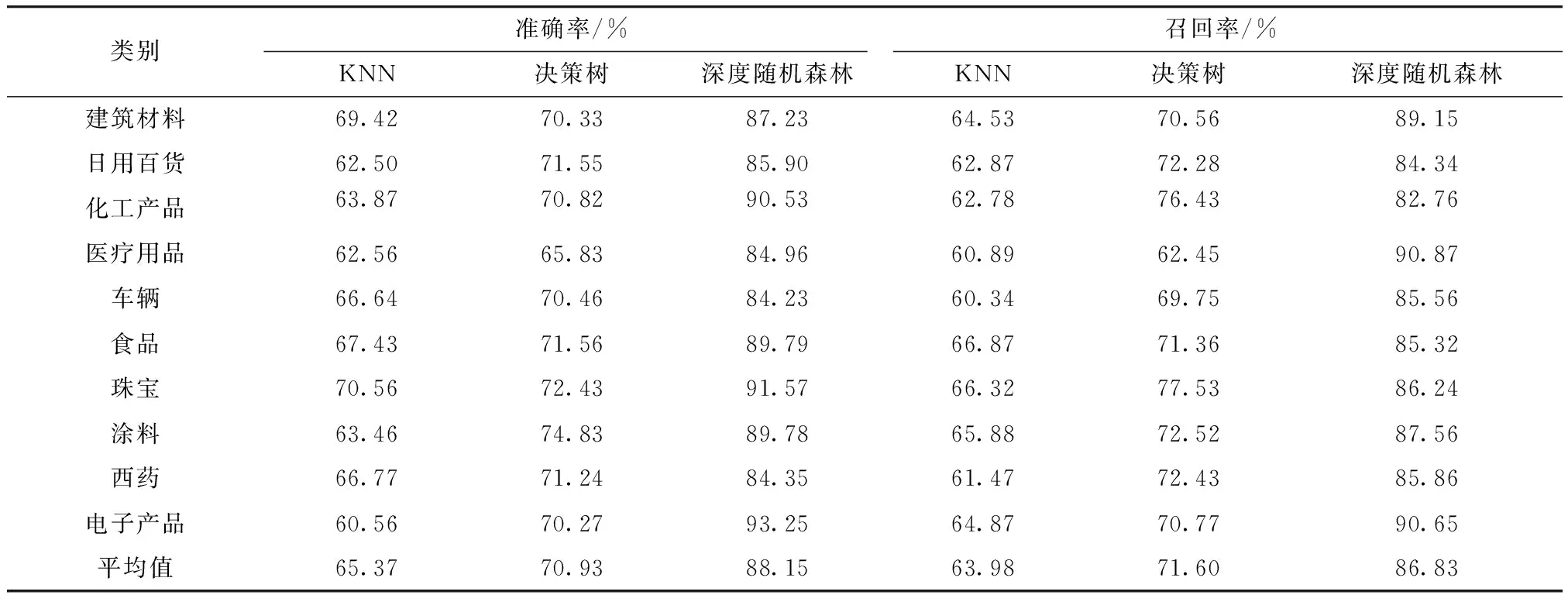
表4 分类方法实验结果对比Tab.4 Comparison of experimental results
此外,还对准确率和召回率进行了综合评估,分别计算出了各个方法的F1值,具体结果如图2所示.
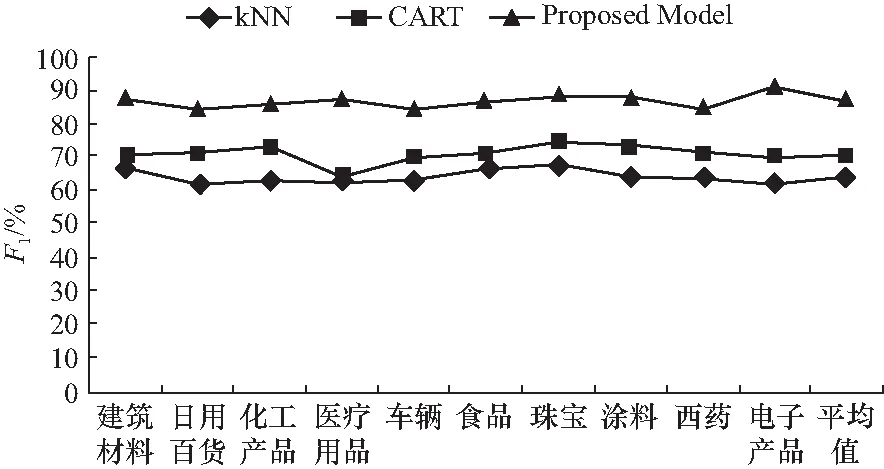
图2 F1值对比结果Fig.2 F1 value comparison results
实验结果显示在商品超短文本分类中,本文提出的超短文本分类方法,平均准确率达到了88.15%,平均召回率达到了86.83%. 与传统的KNN和决策树方法相比,平均准确率提高了22.78%和17.22%,平均召回率提高了22.85%和15.23%.
从以上的评估结果可以看出,传统的KNN方法并不适用于超短文本的分类,因为超短文本特征过于稀疏,因此向量化的结果过于离散,很难进行准确的分类. 而决策树方法相对效果好一些,因为它通过最大熵尽可能地考虑了超短文本所包含的信息,但也由于特征稀疏,使得分类性能难以得到较高提升. 而采用“分流”策略的超短文本分类方法取得了最好的效果,因为它对超短文本进行扩展,充分挖掘了文本可能包含的语义,并使用深度随机森林这一分类器,充分考虑到了样本多样性.
更进一步地,实验将一些代表性的且在设计过程中考虑到超短文本情形的已有文本分类模型进行对比. 如表5所示,本文选取了Sun在文献[1]中所提出的联合TF.IDF.CLARITY作为特征提取方案并使用Maximum Entropy作为基分类器的方法,ZHANG等[22]所提出的利用基于百科数据的LDA方法扩展短文本后使用SVM进行分类的方法,以及YANG等[27]提出的基于协同过滤方法的超短文本分类模型作为对比. 出于实用性考虑,对比的方式不再以对于某一分类的精确率、召回率及F1进行比较,而是通过模型直接在十分类任务上的准确率(Accuracy)作为衡量标准. 在具体实现上,文献[1,22]均未给出官方的实现,故由本文根据论文中的描述加以实现,其中,文献[1]的查询词长度按照本文所设想的情形设定为1和3,文献[22]的语料使用的为中文维基百科离线数据集(https://download.wikipedia.org,原文为基于英文维基百科数据的实现). 表5表明,本模型所提出的模型能够取得比相关已有文献更好的准确率. 值得一提的是,在实验过程中,文献[1]的方法在类别从其报道的八分类扩展到十分类是准确率显著下降,同时,由于Query Length的长度的物理意义是作为分类特征的词语数,在这个参数偏小时才符合本文所设想的场景,其性能相较于针对超短文本分类模型显著下降.

表5 所提出模型与相关已有文献结果对比
通过对部分样例的进一步观察,可以发现,例如“活动隔离桩”和“砖浆料”等超短文本构成的商品名称由于没有百科信息的支持,出现了其他模型无法全部正确判断的情况. 而通过网页爬取获取的广告等较低质量但信息较为完备的语料库使得本文所提出的模型为该短文本提供了更好的分类性能.
4 结 论
本文提出了一种基于深度随机森林的商品类超短文本分类方法,采用“分流”的策略,在海关的商品名分类领域取得了良好的效果,证实了此方法的可行性. 下一步,可以深入研究此框架向其他领域扩展的可能性,以解决更为复杂的任务,例如,该技术对于俚语、俗语等高度依赖先验知识的超短文本的分析有着良好的应用前景,结合使用领域词法可以将某地域相关的俚语、俗语进行更加准确的情感计算[30]. 此外,基于该超短文本模式的推荐系统也值得进一步的研究[31]. 同时,在构建类别名称扩展库时,也存在着一些问题需要进一步研究和解决,如何实现知识库的自动更新也是将在以后着重讨论研究的方向. 对于超短文本自身的定义和建构同样需要进一步完善,其内涵也有待进一步挖掘.
