深度学习下的快速SAR图像目标检测
2022-01-13王春平韩子硕
王春平, 韩子硕, 付 强
(陆军工程大学 石家庄校区,河北 石家庄 050003)
合成孔径雷达(Synthetic aperture radar, SAR)是一种主动式微波成像传感器,可以全天候、全天时地执行遥感监视任务,其多极化和高分辨率成像模式,为对地监测提供了大量可利用数据[1]。目标检测作为SAR的一项前沿技术,已被广泛应用于战场态势监测、军事目标搜索、水上目标检测和城市交通管控等多个军事及民用领域。
由于SAR独特的成像机制和复杂的电磁波散射过程,导致所成图像中的地物存在几何畸变和阴影,且充斥着大量的相干斑噪声,使得传统的目标检测算法[2-4]收效甚微。近年来,随着深度学习算法的崛起,许多优异的目标检测模型[5-7]脱颖而出。然而,当将其应用于SAR图像目标检测时,检测性能往往会急剧下降。究其原因,一是受相干斑噪声和复杂环境影响,许多目标特征淹没于背景当中,导致目标视觉线索匮乏;二是地物成像畸变和诸多假目标干扰检测器判断,导致虚警和漏警;三是目标特性及其分布多变,给检测任务带来巨大挑战。显然,增强目标的显著性特征和优化检测器的判别能力是提高网络性能的有效途径。此外,提高检测效率也是至关重要的。大多数现有的深度学习网络模型通常需要一组具有预定尺寸和纵横比的锚框,然后借助真实目标将其回归至所需位置,再通过非极大值抑制(Non-maxima suppression, NMS)消除对同一目标的重复检测。尽管此类基于锚框的检测算法已经取得巨大成功,但这种思想不仅需要根据不同的应用背景手动设定合适的锚框参数,而且还需要枚举所有可能的目标位置,大量的锚框冗余令检测器耗时耗力,也限制了其通用性。
无锚框模型通过直接预测目标关键点和相关元素(如分类概率、目标置信度等)实现目标检测。CornerNet[8]通过预测目标框的左上角和右下角两个关键点得到预测边框,ExtremeNet[9]通过预测目标的中心点以及4个顶点共5个关键点实现目标检测。然而,这两种算法都需要增设一个分组模块将预测的众多关键点分配给所属目标,这无疑降低了检测速度。CenterNet[10]将目标建模成单个中心点,并回归所有其他坐标参数(如目标宽度、高度和分类概率等)完成目标检测任务,其摒弃了关键点分组,提高了检测效率。在此基础上,BBAVectorst[11]通过预测目标的中心点以及对应的10维参数向量实现旋转目标定向检测,但由于预测参数较多,其检测速度也不够理想。
基于以上分析,针对SAR图像目标检测困难以及锚框机制所引起的计算冗余和应用场景受限问题,提出了一种基于无锚框机制的中心点、尺度和旋转角度预测网络(Center, scale and angle prediction network, CSAP-Net)。CSAP-Net将目标检测转化为中心点估计问题,然后在中心点位置直接预测目标的其他坐标参数,如宽度、高度、旋转角度等,其具有快速准确的特点,可以高效完成多场景、多类型SAR图像目标定向检测。
1 算法设计
CSAP-Net为无锚框单阶段网络模型,以ResNet-101的为主干网络,并利用U型跳跃连接和注意力模块提取输入图像极具表征能力的高分辨率语义特征图,检测层输出用于估计中心点的热力图(Heatmap)、计算中心点偏移量(Center offset)的特征图和边框参数(Box param)特征图,三者联合完成目标定向检测。训练过程中,通过优化损失函数来增强边框约束,并利用“翻转+剪切”的数据增强技术扩增训练数据集以提升模型检测性能。图1展示了该网络的基本框架。
1.1 特征提取
CSAP-Net的特征提取网络是一个U型结构,以ResNet-101为主干,ResNet-101的网络结构如表1所示。为了得到特征更加丰富的预测特征层,将主干网络残差模块Ⅴ的输出经上采样后与残差模块IV的输出进行跳跃连接,并利用基于注意力机制的特征层级联(Attention-based concatenation, AC)策略将两者特征进行融合。同理,将融合后的特征图与残差模块III的输出进行连接融合。最后,共经3次上采样和3个AC后得到高分辨率语义特征图。融合过程中的上采样用于统一两层特征图的尺寸大小,跳跃连接可以将网络深层特征与浅层特征结合起来,共享高层语义特征和浅层细节信息,AC模块将网络注意力聚焦于信息量较大的区域,抑制无关区域。

表1 ResNet-101的网络结构
AC模块共有两路输入,一路是待上采样的特征图,即ResNet-101残差模块V或前一个AC模块的输出,另一路是由残差模块II~IV输出的高分辨率特征图。假设ResNet-101残差模块II~V的输出分别为F2~F5,则3个AC模块的输出Ai(i∈[2,3,4)可表示为
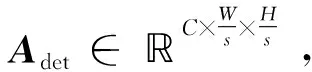
1.2 中心点预测
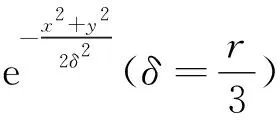

图2 真实目标中心点设置
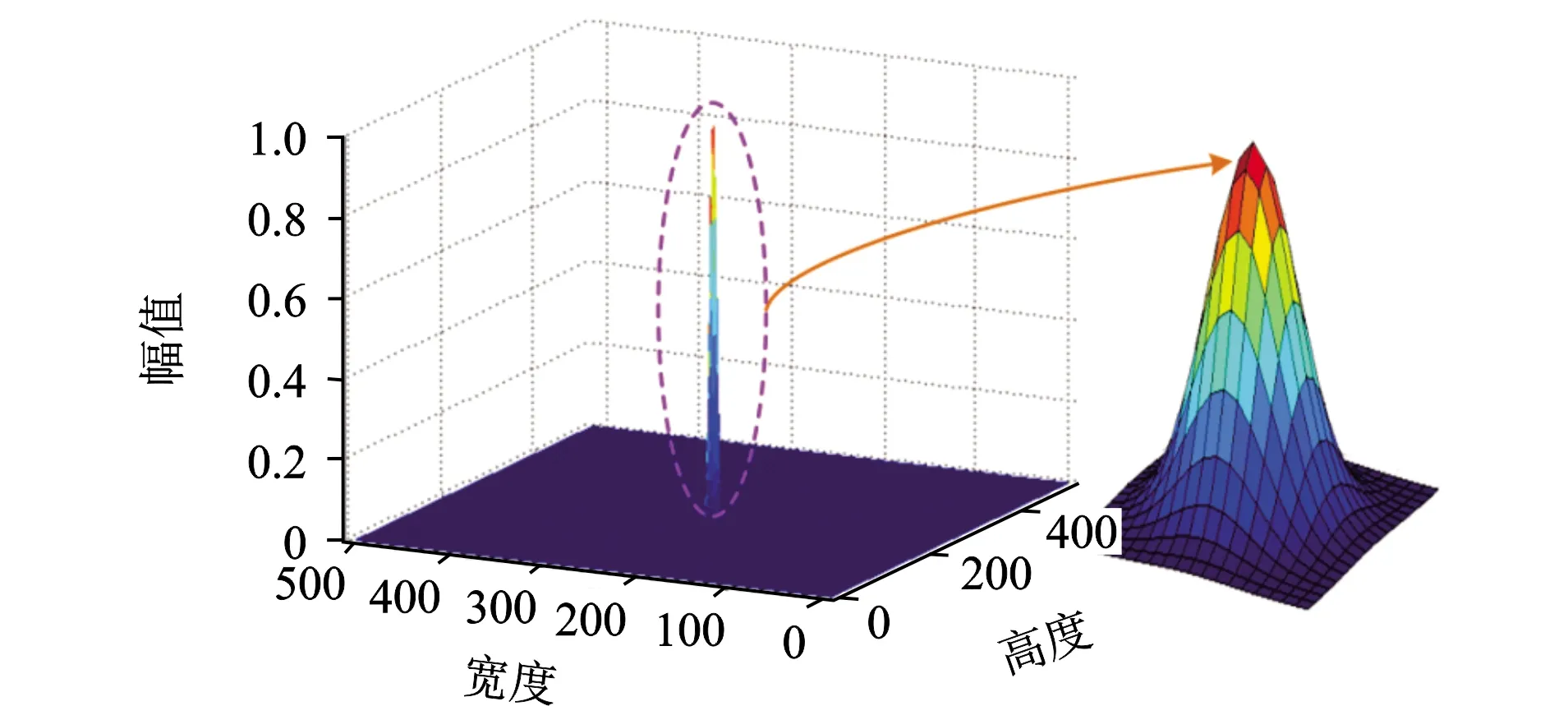
图3 中心点周围负样本的惩罚衰减量
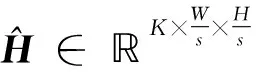
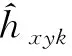
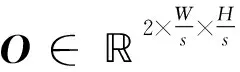
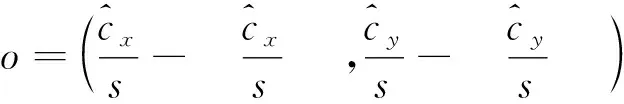
(3)
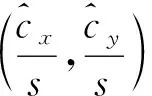
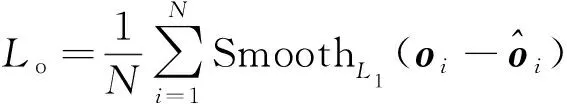
(4)
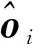
1.3 目标坐标参数预测
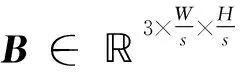
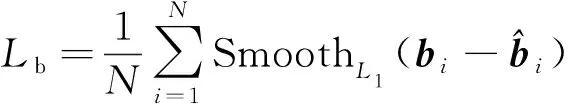
(5)
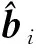
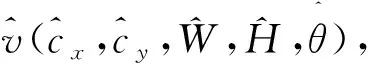

(6)
Ltotal=Lh+Lo+Lb+LGIoU
(7)

图4 不同边框重叠情况时的平滑L1损失、IoU和GIoU损失
2 实验设置及评估
2.1 数据集
为了验证所提算法的有效性,实验中使用了MSTAR数据集和SSDD数据集,其中前者为公开的军事车辆数据集,后者为舰船数据集。
MSTAR数据集由美国国防高级研究计划局和空间实验室发布。该数据集由X波段、HH极化方式、高分辨率聚束式星载合成孔径雷达采集得到,共包括10类典型军事目标在0~360°不同姿态角下的静止切片图像和100幅场景图(图像尺寸为1 784像素×1 478像素)。为了获得大场景SAR图像下的军事车辆样本,利用合成的方法制作包含BMP2、BTR70和T72三类目标的大场景SAR图像。首先,建立包含100个场景的背景库和包含1 283个目标的目标库,其中587个目标的SAR入射角为15°、696个目标的SAR入射角为17°。然后,每次选取一幅背景图像和若干个目标合成一幅场景图,共合成340幅大场景SAR图像,图5给出了合成示例。其中,包含2 730个目标(SAR入射角为15°)的300幅场景图用于模型训练,其余包含696个目标(SAR入射角为17°)的40幅场景图用于测试。训练过程中,一幅场景图将被分割成一系列尺寸为400×400的子图像(重叠率为20%)。在此基础之上,对原始的SAR入射角为15°的587个目标切片周围的像素进行随机填充,以匹配子图像的大小,并为每个切片选择两个扩展图像作为扩展数据集。数据集的详细信息见表2。
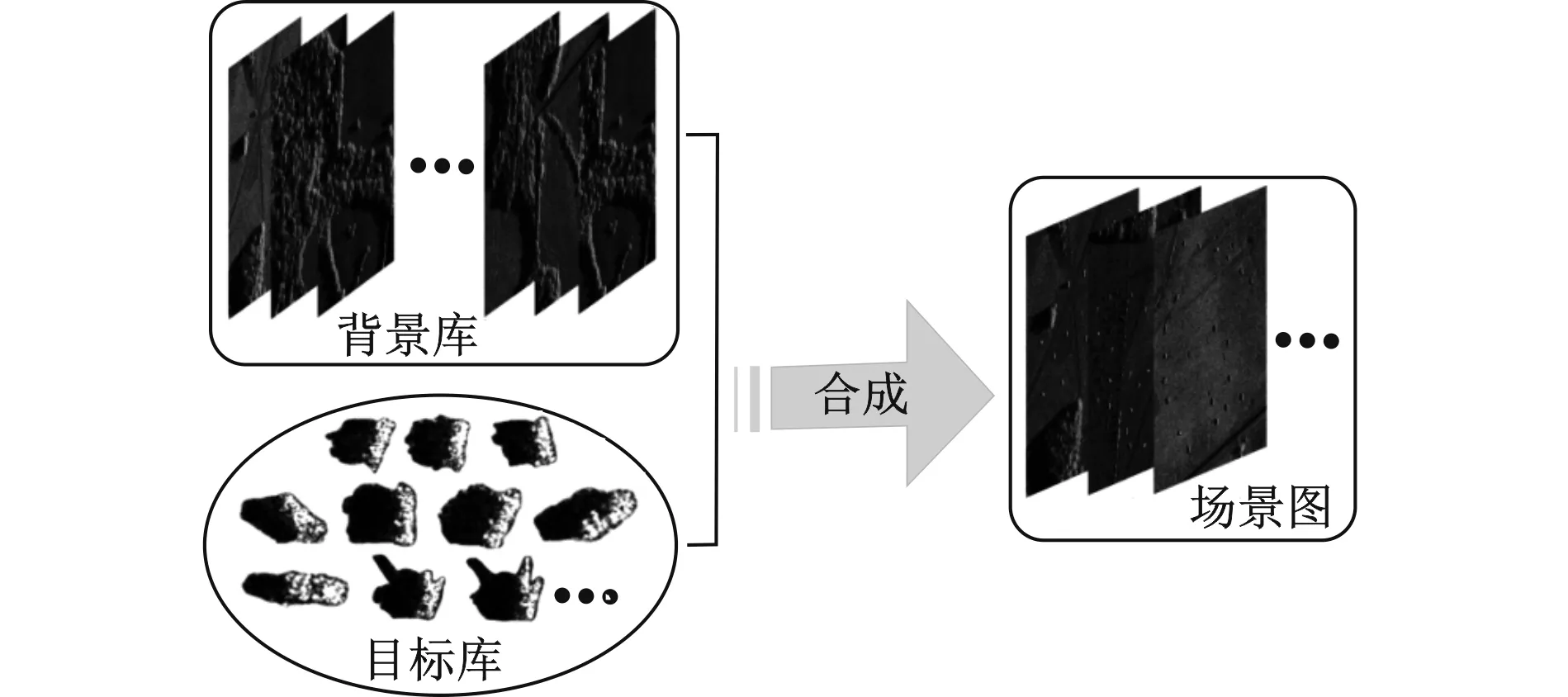
图5 大场景SAR图像合成示例
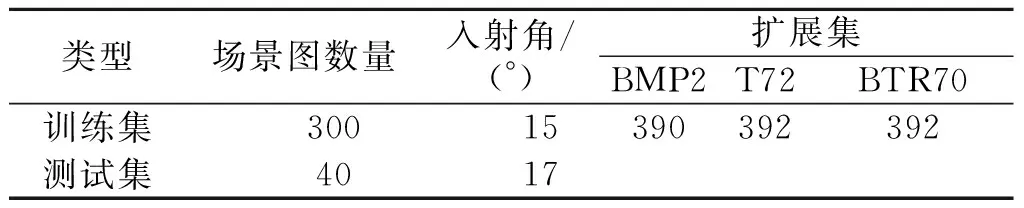
表2 MSTAR数据集详细信息
SSDD数据集包含由Radarsat-2、TerraSAR-X和Sentinel-1 SAR卫星收集的总共1 160幅SAR图像,含有2 456个尺度变化范围较大的舰船目标,场景类型包含港口、岛礁、远海区域等,适合验证检测算法对不同大小目标的检测能力以及对不同背景的适应能力。该数据集中图像的分辨率和尺寸均不固定,样例如图6所示, 详细信息如表3所示。

图6 SSDD数据集样例

表3 SSDD数据集详细信息
2.2 实验设置
本文所有实验均在配置为E5-2630v4 CPU,NVIDIA GTX-1080Ti GPU (11 GB显存),64 GB RAM的图像工作站上进行,以深度学习框架Tensorflow为编译工具完成。
网络接收视野固定为608×608,则预测特征图尺寸为152×152。训练过程中,利用基于ImageNet数据集训练的ResNet-101预训练模型初始化网络参数,并采用“翻转+裁剪”的数据增强技术扩增训练数据集,提升模型的鲁棒性。MSTAR数据集训练80轮次,SSDD数据集训练50轮次,并采用初始学习率为1.25×10-4的Adam优化器优化损失函数。
2.3 消融实验分析
CSAP-Net借助旋转检测(Rotation detection, RD)技术、基于注意力机制的特征层级联策略(AC)和GIoU损失(LGIoU)实现了不同应用场景下的目标定向检测。为了探究以上3种功能策略对检测结果的影响,分别在MSTAR大场景数据集和SSDD数据集上进行了6组实验,各组实验的检测结果如表4所示,其中“√”表示采用某项策略,而“×”表示不采用某项策略,AP表示平均准确率,mAP表示均值平均精度,两者用于衡量模型的检测精度,FPS(帧/s)表示检测器每秒处理的图像数量,用于衡量模型的检测速度。
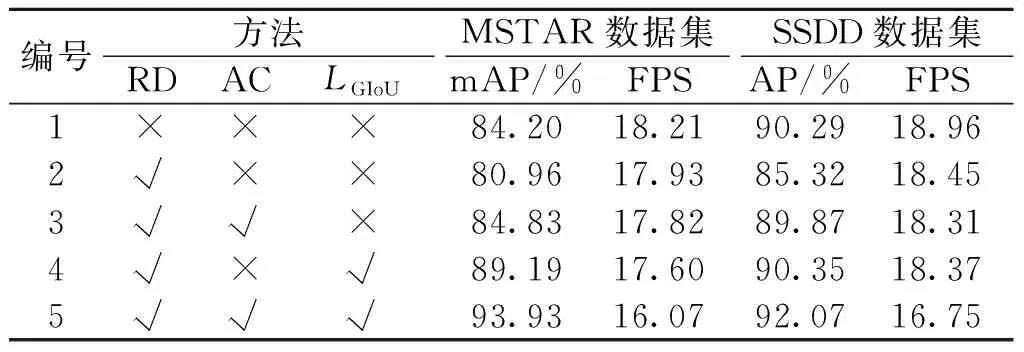
表4 CSAP-Net采用不同功能策略模块的检测结果
由表4可知,实验1未附加任何策略,相当于一个以ResNet-101的U型网络结构为特征提取网络的CenterNet无锚框检测模型,在MSTAR数据集上的mAP值达到了84.20%,检测速度为18.21 FPS,在SSDD数据集上的AP值达到了90.29%,检测速度为18.96 FPS。实验2在实验1的基础上引入了旋转角度θ,实现了对任意向目标的旋转检测。如图7所示,尽管θ能够指示目标的朝向信息,为观测者提供更多的可依据判定信息,然而由于预测边框与真实边框之间的IoU对θ十分敏感,而实验2的检测模型对θ的约束力又略有不足,致使检测性能有所下降,相较于实验1,在两个数据集上的检测精度分别降低了3.24%、5.97%。在实验2基础上,实验3将基于注意力机制的特征层级联策略引入检测模型中,构建信息丰富的高分辨率语义特征图,为目标预测提供强力支撑,相较于前者,在两个数据集上的检测精度分别提升了3.87%、4.55%。实验4在实验2的基础上,将GIoU损失加入总损失当中,增强检测器对目标位置参数尤其是旋转角度θ的约束,两个数据集上的检测精度分别提升了8.32%、5.03%。实验5的检测模型即为CSAP-Net,在两个数据集上的检测精度达到了最优,分别为93.93%、92.07%,且保持了16 FPS以上的检测速度,达到了精度与速度的最佳均衡。

图7 水平边框和旋转边框检测效果
2.4 与其他算法比较
为了验证CSAP-Net在众多检测模型中的优越性,将其与SSD[12]、R2CNN[13]、Faster RCNN++[14]、RRPN[15]、YOLOv3[7]、LRTDet[16]、R-DFPN[17]、CenterNet[10]、BBAVectors[11]等9种检测模型进行比较。各种方法在MSTAR和SSDD数据集上的检测结果定量比较如表5所示。
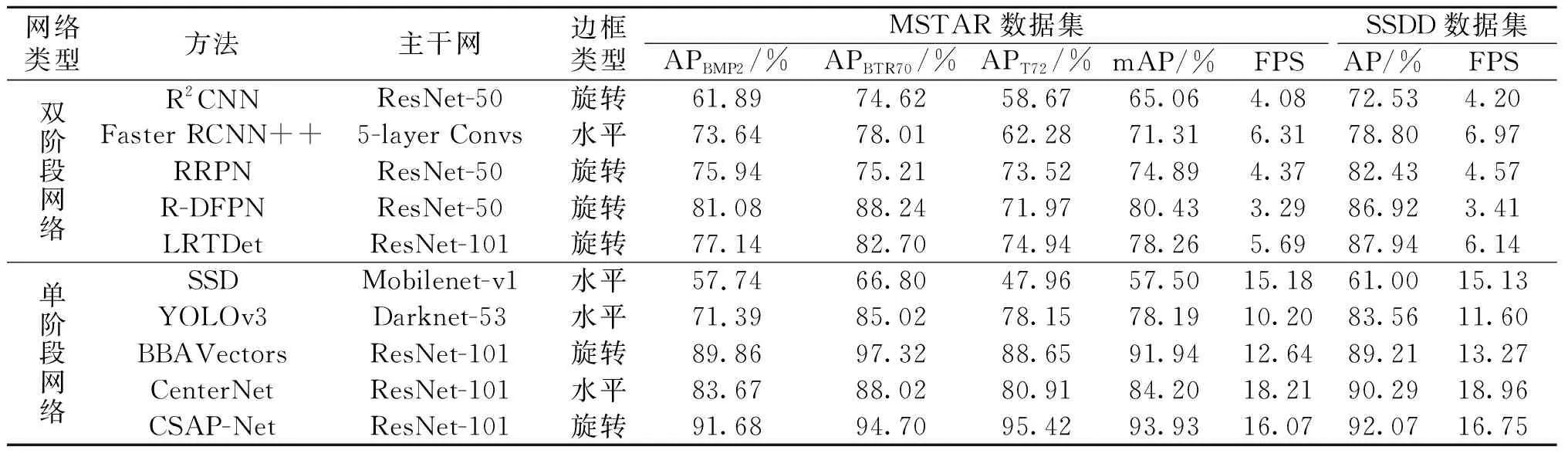
表5 不同算法的检测结果比较
分析表5检测结果,Faster RCNN++虽然采用了多层融合策略,在一定程度上综合了高层语义信息和浅层细粒度特征,但主干网络由5层卷积堆叠而成,其泛化能力不足以处理复杂的SAR图像环境,导致检测效果不理想。但由于其结构简单,检测速度优于其他双阶段网络。R2CNN和RRPN均以ResNet-50作为主干网络,并通过旋转角度因子实现任意朝向目标的定向检测,但两者对目标特征的刻画能力有限,在MSTAR和SSDD数据集上的检测精度均低于83%。相较于前三者,R-DFPN与LRTDet在两个数据集上的表现有所改善,但两者均以复杂的模型结构来换取性能的提升,从精度-速度效能以及检测效率的角度来看,这是非常不明智的。SSD和YOLOv3作为应用最为广泛的单阶段网络,检测速度比双阶段网络有了大幅提高。然而,由于Mobilenet-v1削弱了SSD的泛化能力,致使其在两个数据集上检测效果较差,mAP(或AP)仅达57.50%和61.00%。YOLOv3以Darknet-53为主干网络,且采用多层预测模式,有益于多尺度目标检测,在MSTAR上的mAP为78.19%、检测速度为10.20 FPS,在SSDD上的AP为83.56%、检测速度为11.60 FPS。以上网络模型均为基于锚框的检测方法,由于大量的锚框和计算冗余,导致其检测速度较慢。CenterNet和BBAvectors是当前性能比较优异的无锚框检测模型,CenterNet在SSDD上的性能要优于BBAVectors,而后者在MSTAR上的表现更佳。BBAVectors通过直接预测一个包含12个参数的坐标向量实现目标定向检测,在两个数据集上的mAP(或AP)分别达91.94%、89.21%,但由于预测参数量的增大致使其检测速度略输于CenterNet。后者通过直接预测目标中心点、宽和高实现目标检测,在两个数据集上的mAP(或AP)分别达84.20%、90.29%,且检测速度均高于18 FPS。值得注意的是,CenterNet是水平框检测,而BBAVectors为旋转框检测(可提供目标朝向信息)。CSAP-Net通过引入旋转角度实现目标定向检测,并利用跳跃连接和注意力结构提取极具表征力的高分辨率语义特征,训练过程引入GIoU损失和“翻转+裁剪”的数据增强技术提升模型检测性能,在两个测试数据集上的mAP(或AP)分别达93.93%、92.07%,且保持了16 FPS以上的检测速度。相较于具有相同功能的BBAVectors,CSAP-Net不仅检测精度高,而且检测速度提升了3.4 FPS。图8展示了所提模型在不同应用背景下的目标检测可视化结果,说明所提方法可有效完成不同背景下的多尺度、多类型目标的定向检测任务。
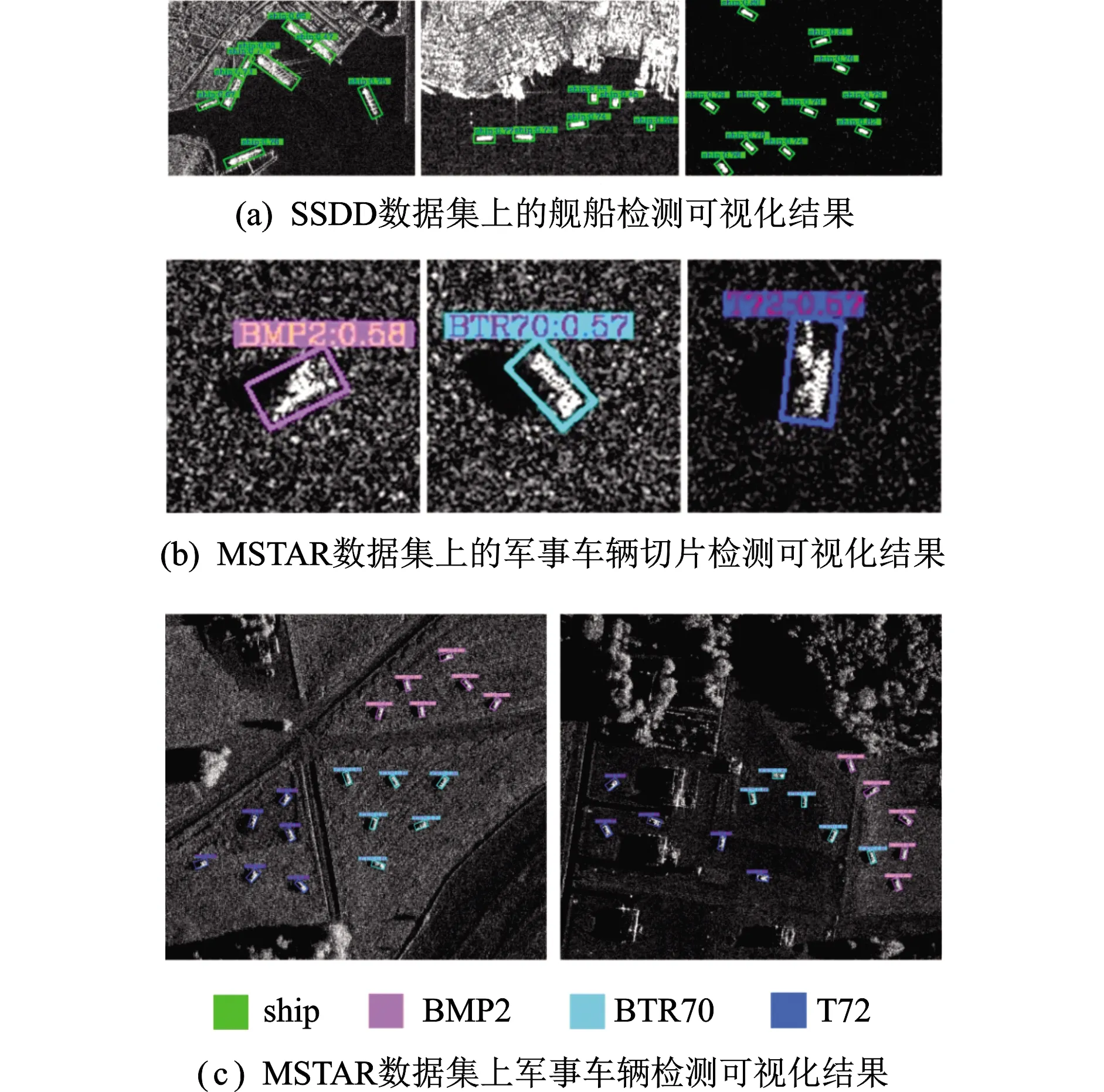
图8 联合模型在不同场景下的目标检测可视化结果
2.5 模型抗噪性分析
中心点预测是 CSAP-Net 的首要任务和关键,一旦中心点丢失,则会造成目标漏检。SAR图像中存在着大量的相干斑噪声,而且目标与背景的对比度较低,这无疑给检测器预测中心点带来很大挑战。因此分析检测模型的抗噪性能至关重要。下面,对CSAP-Net的抗噪性能进行验证,首先使用不同噪声比(Noise ratio)的椒盐噪声污染原始测试集中的样本,噪声比分别设置为2%、4%、8%、10% 和 12%,而后利用原数据集训练的检测模型对噪声污染的测试集进行目标检测,测试结果如图9所示。
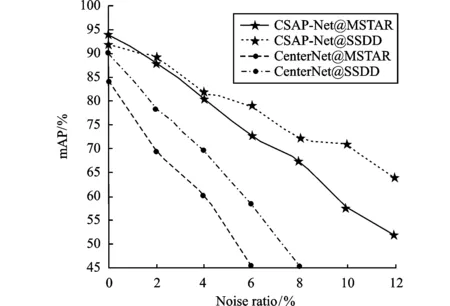
图9 CSAP-Net和CenterNet的检测性能与噪声比关系图
由图9可知,随着噪声比的增加,CSAP-Net和CenterNet都产生了不同程度的性能下降。当噪声比达到 6% 时,CSAP-Net 在两个数据集上的 mAP 值仍然可以保持在 70% 以上甚至接近 80%,而 CenterNet 的 mAP 值则下降到 60% 以下。此外,当噪声比达到 12% 时,CSAP-Net 的 mAP 值保持在 50% 以上,远远高于CenterNet。说明CSAP-Net对噪声有一定的抑制作用,验证了其抗噪声能力。结合2.3节中的消融实验分析可推断出,CSAP-Net的抗噪能力主要得益于3个方面:(1)注意力模块可以抑制背景、突显前景,引导检测器关注包含更多目标信息的区域,进而起到消除背景及噪声干扰的目的;(2)旋转定向检测标注的是目标最小外接矩形,减小了边框冗余,进一步降低了噪声干扰;(3)GIoU 损失增强了对回归边框的约束,使检测器更加稳健。比较CSAP-Net在SSDD和MSTAR上的抗噪表现不难发现,随着噪声比的增加,检测器性能在MSTAR数据集上的下降速度比SSDD数据集快。原因是在SSDD数据集中,目标和背景之间的对比度较高,令其能够承受一定程度的噪声污染。相反,在 MSTAR 数据集中,目标和背景的对比度本身并不占优,而噪声无疑会加剧这一劣势。
3 结论
针对锚框机制所引起的大量冗余计算和模型通用性受限问题,本文提出了一种单阶段无锚框深度学习框架CSAP-Net。该模型利用ResNet-101的U型结构和特别设计的注意力模块提取输入样本的高分辨率语义特征图,突显前景、抑制背景;在训练过程中引入GIoU损失消除旋转角度θ引起的IoU误差,弥补了平滑L1损失的不足,并采用“翻转+裁剪”的数据增强技术扩增训练集,提升模型检测能力,实现目标定向检测。CSAP-Net具有简单、快速、准确的特点。在SSDD和MSTAR数据集上的实验结果验证了所提方法对不同复杂背景下的多类型目标检测的有效性和通用性。
