可见光-近红外光谱的矽卡岩型铁矿反演模型
2022-01-12毛亚纯付艳华赵占国丁瑞波
毛亚纯,温 健*,付艳华,曹 旺,赵占国,丁瑞波
1.东北大学资源与土木工程学院,辽宁 沈阳 110819 2.东北大学江河建筑学院,辽宁 沈阳 110819 3.中国黄金集团,北京 100000
引 言
铁矿是我国经济发展的重要矿产资源,其中矽卡岩型铁矿是我国重要的铁矿床类型之一,其储量约占全国铁矿床总储量的11%,矿石类型以磁铁矿为主[1]。传统的矿石品位检定方法以化学分析法为主,检测方法较为准确,但由于成本昂贵、检定周期较长,无法实现矿石品位的即时原位测定[2],相对配矿流程均存在滞后效应,因此难以有效降低矿石开采的损失贫化率。如今,如何做到低成本,快速、准确确定铁矿品位及合理、高效开采铁矿已成为铁矿开采中亟待解决的关键问题。高光谱遥感由于其高分辨率、波谱连续、信息丰富[3],已被广泛应用于植被指数反演、土壤含盐量反演、重金属品位反演等领域[4-6]。
由于原始高光谱数据存在数据冗余、信噪比低等问题,严重影响其特征分析的准确性和建模反演精度,为此大量学者在高光谱数据的预处理、及降维处理等方面进行了的研究[7-8],这些方法均有效降低了高光谱数据的冗余度,快速准确地提取出有效的光谱信息,达到提升预测精度降低误差的目标。同时国内外很多学者也对数据处理以及建模方法进行了大量的研究。Chudnovsky等基于偏最小二乘法多元分析,证明了仅通过沉积物粉尘的可见光-近红外高光谱数据即可对其进行准确预测[9];高伟等以铁矿粉的高光谱数据为数据源,建立了多种反演模型,其中SFIM-RFR模型预测结果误差最小,证明了基于高光谱数据预测铁矿粉中全铁品位的可行性和有效性[10];陈俊英等建立了SNV-SR-ELM模型,对高光谱反演水质模型的优化以及污水水质的快速监测和综合评价提供了有效途径[11]。虽然国内外学者对高光谱数据处理及建模方法的研究已经取得了一定的进展,但目前基于矽卡岩型铁矿高光谱数据的研究相对较少。
以红岭矽卡岩型铁矿的化学分析与光谱测试数据为数据源,并对其进行数据预处理及降维多种组合算法处理,同时以随机森林算法和极限学习机算法两种算法为建模方法建立矿石铁品位的定量反演模型。结果表明,经MSC处理及PCA降维后的数据基于ELM算法(MSC-PCA-ELM)建立的定量反演模型效果最优,其中决定系数R2为0.99、均方根误差RMSE为0.005 7、平均相对误差MRE为2.0%,由此可见利用该方法可准确快速反演矽卡岩型铁矿的品位,为我国矽卡岩型铁矿品位的快速原位分析提供了有效手段。
1 实验部分
1.1 研究区与矿石采样
红岭铅锌矿位于我国内蒙古赤峰市,主要开采铁、锌矿体,是以铁、铅、锌为主的矽卡岩型多金属矿床。2019年6月在内蒙古赤峰红岭矿区采集了井下矽卡岩型铁矿样本。为保证所采集的样本具有代表性、多样性及建模的普适性,故采取矿区均匀抽样的方式采集了相应的矽卡岩型铁矿样本,如图1(a)所示。
为使所建模型在井下具有实际应用性,因此对矽卡岩型铁矿样本进行了钻孔、取芯及切块处理,最终制成共225件块状样本,如图1(b)和(c)所示。

图1 实验样品Fig.1 Experimental samples
1.2 矿石铁品位与光谱测定
使用美国SVC HR-1024便携式地物光谱仪采集光谱,波段范围350~2 500 nm,通道数为1 024,最小积分时间为1 s。在观测角度等条件保持不变的情况下,分别以太阳光和卤素灯光作为光源的测试结果基本一致。但考虑到井下应用将以卤素灯作为光源,因此以卤素灯作为测试光源,并在夜间封闭环境条件下对样本进行了测试,测试时使样本观测面保持水平,光谱仪镜头垂直于样品观测面,采样积分时间设置为2 s,每个样品重复测试2次,视场角为4°。为避免光谱测试出现的偶然性,取两次反射率平均值作为该矿石的实际反射光谱数据。在实验过程中,每隔10~15 min进行一次白板测定。
光谱采集完毕后,为了进一步降低噪声的干扰,采用Savitzky Golay法对原始光谱数据进行了平滑处理[12],图2是225个块状矽卡岩型铁矿样本的光谱曲线。
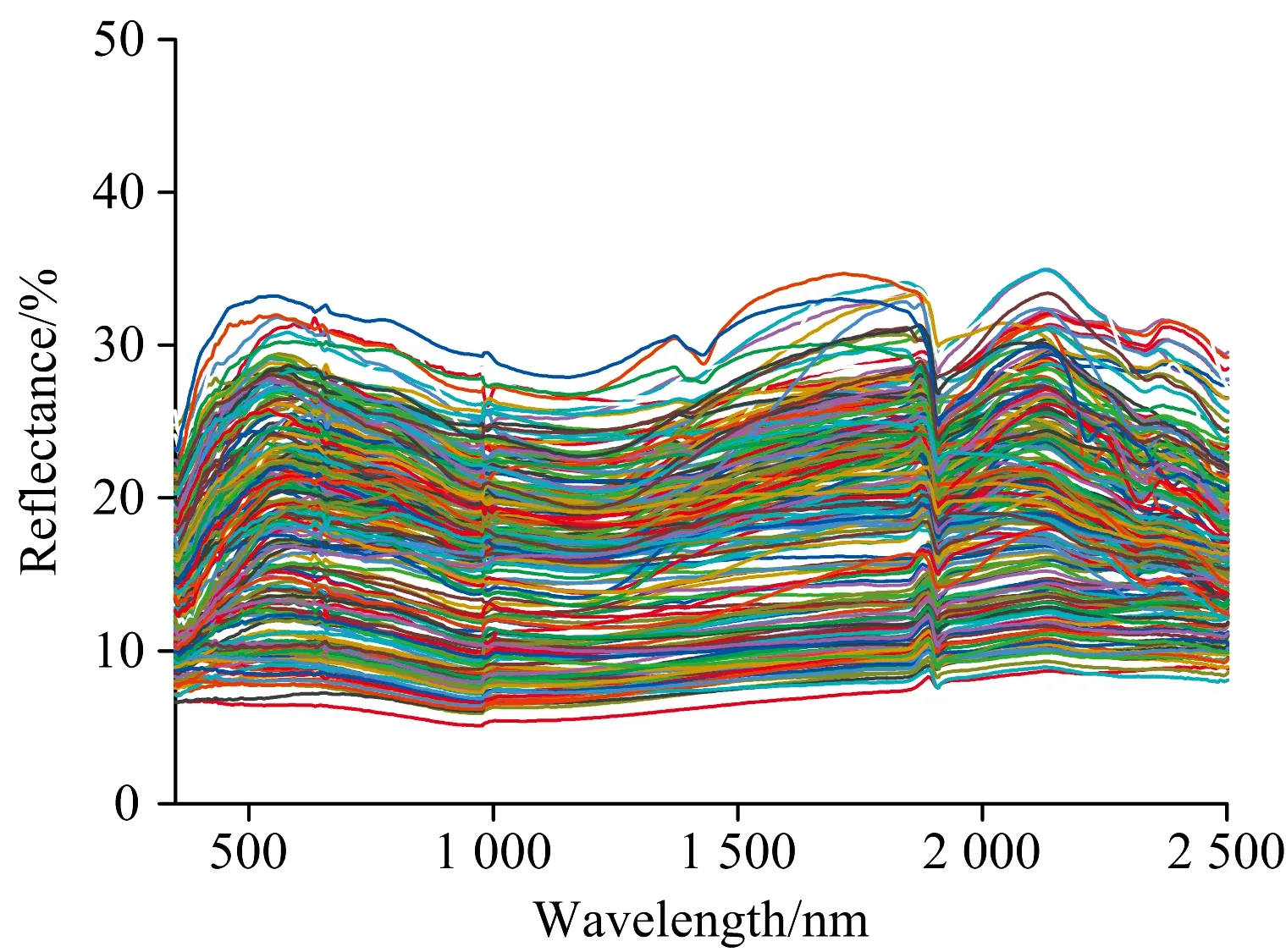
图2 样品可见光-近红外光谱曲线Fig.2 Visible and near infrared spectra of samples
光谱特征如下:
(1)样品的光谱反射率大部分在10%~30%之间。
(2)在400~550 nm反射率为上升趋势,一部分曲线上升趋势显著,斜率较大,另一部分曲线上升趋势缓慢,斜率较小,且在550 nm附近出现波峰。
(3)在550~1 180 nm反射率下降,其中在870 nm附近出现微弱波谷。
对上述现象进行分析发现,在350~550 nm间的光谱差异与样本铁品位有一定相关性,斜率小的样本普遍铁品位均值高于斜率大的样本铁品位均值。
光谱测试结束后,将全部实验样品进行了研磨化验处理,以确定各个样品的铁品位。由化验结果得出,样本铁品位在6.75%~66%之间,平均品位为27.84%。
2 结果与讨论
2.1 光谱数据预处理
由于原始高光谱数据存在数据冗余、信噪比低等问题,为了增强光谱信息,突出光谱特征,提高信噪比,采用倒数对数、多元散射校正两种预处理方法。
(1)倒数对数法
倒数对数法不仅可以有效增强光谱在可见光波段的差异,还可以有效的减弱因测试时光照条件变换所引起的乘性因素的影响。倒数对数法计算公式如式(1)所示
(1)
式(1)中,θ为平滑后的原始光谱数据,θ′为经倒数对数处理后的光谱数据。图3是225个块状矽卡岩型铁矿样本经过倒数对数处理后的光谱曲线。
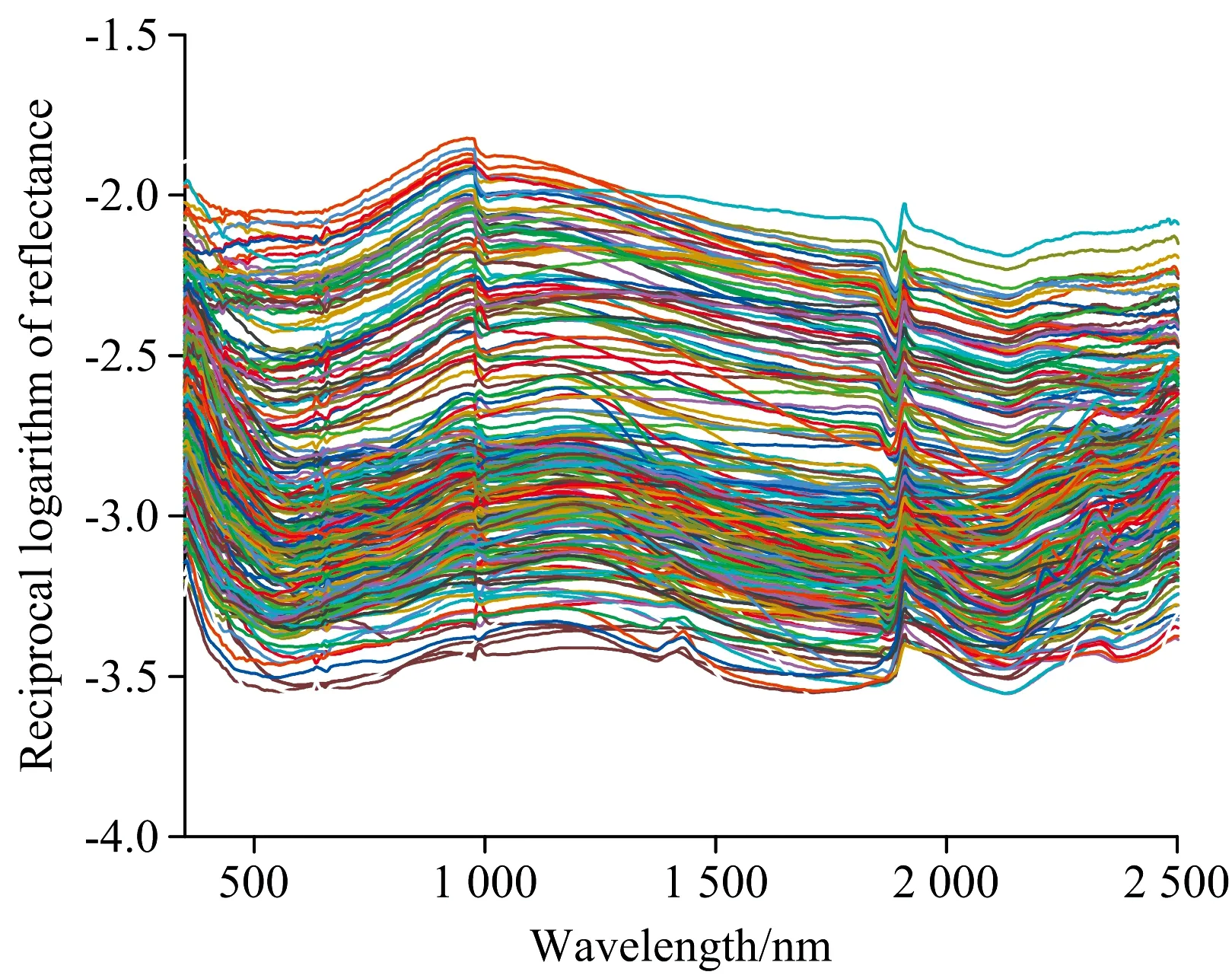
图3 倒数对数处理后的光谱曲线Fig.3 Spectral curves after reciprocal logarithm processing
(2)多元散射校正
多元散射校正处理可有效降低因散射对光谱数据的影响,在一定程度上增强特征波段的有效信息[13]。该算法的具体实现过程为:首先由式(2)计算样本的平均光谱作为标准光谱,然后将各种原始光谱与标准光谱作一元回归,如式(3)所示,最后由式(4)计算多元散射校正后的光谱数据。
(2)
(3)
(4)
式中,A为i×w维定标光谱矩阵,i为样品数,w为光谱采集时所用波段数,lm和Bm分别表示经平滑处理后的原始光谱数据和平均光谱数据作为一元线性回归后的相对偏移系数和平移量。图4是225个块状矽卡岩型铁矿样本经过多元散射校正处理后的光谱曲线。
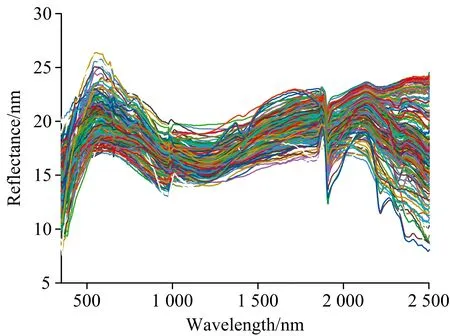
图4 多元散射校正后的光谱曲线Fig.4 Multivariate scatter corrected spectral curves
2.2 降维处理
(1)遗传算法
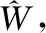
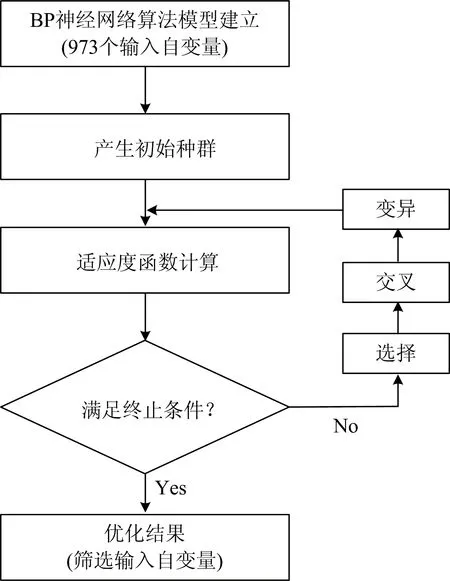
图5 遗传算法选择最优波段流程图Fig.5 Flow chart of genetic algorithm to select the optimal band
(5)
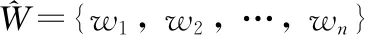
未经处理的数据、经倒数对数变换后的数据和经多元散射校正变换后的数据经遗传算法处理后,维度由973维分别降至477维、489维和509维。
(2)主成分分析法
主成分分析(principle component analysis,PCA)是一种线性数据降维分析方法,其主要思想是通过线性变换提取原始数据的中的主要特征,在减少数据冗余的同时保留原始数据的绝大有用信息,从而解决特征维数过高的问题,即用压缩后尽可能少的信息来代替原有的信息[14]。步骤如下:
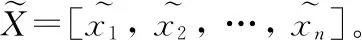
(6)
(7)
累积贡献率设置为99%,以累计贡献率为依据,计算最终维度。如图6(a,b,c)所示,横坐标为依次各主成分,纵坐标为各主成分贡献率,未经处理的数据、经倒数对数变换后的数据和经多元散射校正变换后的数据利用PCA算法处理后维度由973维分别降至3维、3维和7维。
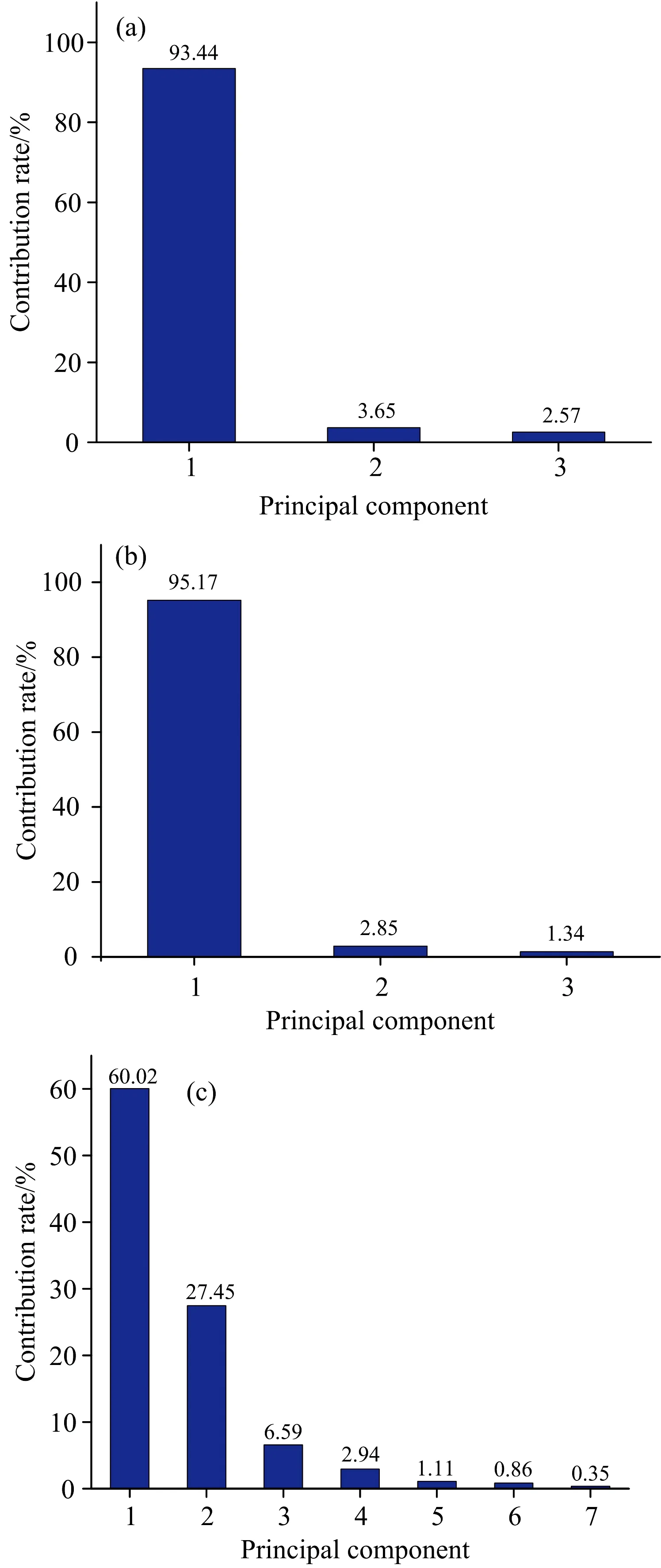
图6 主成分分析结果Fig.6 Principal component analysis results
2.3 模型建立与验证
随机森林(random forests,RF)是由Leo Breiman提出的一种基于统计学的非线性组合智能机器学习算法。对于回归问题,RF模型通过多次bootstrap抽样获得随机样本,然后通过学习样本特征分别建立相应的决策树,最后基于投票和平均的方法输出多个不同功能决策树的最终结果。在算法模型建立过程中,设置决策树的数量为500。
极限学习机(extreme learning machine,ELM),是黄广赋等依据广义逆矩阵理论提出的一种性能优良的单隐含层前馈神经网络模型。它不仅具有较强的非线性拟合能力,还因较其他算法模型速度更快、精度更高、参数调整简单而被广泛应用于多个领域。ELM在执行过程中随机产生输入层和隐含层间的连接权值及隐含层的神经元的阈值且在训练中无需调整,可以获得最优解[15]。模型建立过程中将隐含层节点数设置为30。
模型的稳定性、精确度、可信度分别由决定系数R2、均方根误差RMSE以及平均相对误差MRE来检验。
选择169个样品为训练样本和56个样品为测试样本分别建立随机森林算法模型和极限学习机算法模型。表1和表2分别为未经处理的数据以及对数据进行不同预处理后使用随机森林算法和极限学习机算法建模的结果。
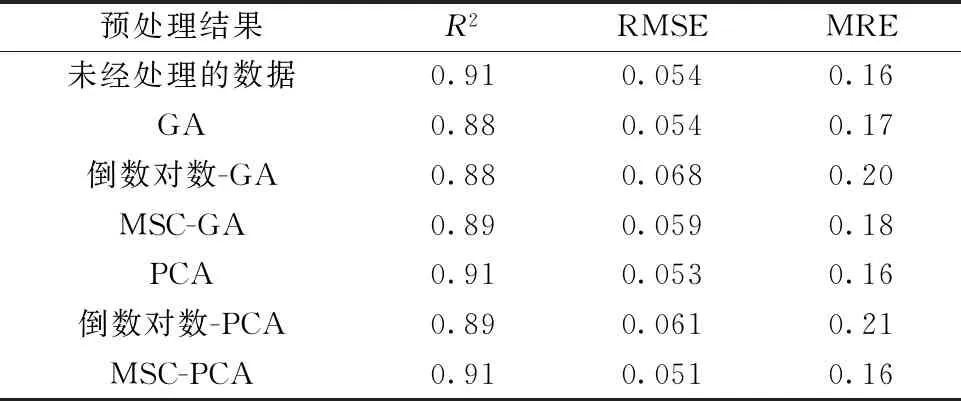
表1 RF反演模型反演结果评价Table 1 Assessment of RF inversion results
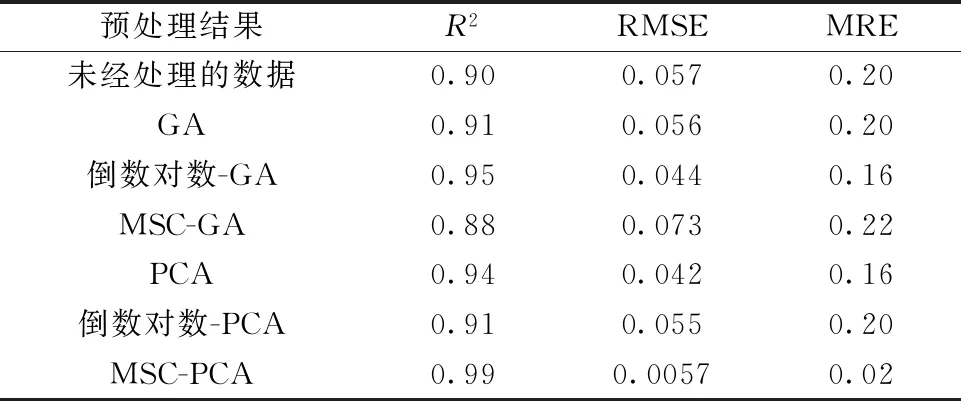
表2 ELM反演模型反演结果评价Table 2 Assessment of ELM inversion results
综合两个表中的数据,利用经MSC处理、PCA降维后的数据基于ELM算法建立的品位定量反演模型效果最优。如图7所示,经该方法处理后使用ELM预测的预测值和真实值作拟合曲线,预测值与真实值的决定系数达到0.99,均方根误差为0.005 7,平均相对误差为2.0%,与未经处理的数据建立的模型相比较,有较大的提升,预测效果更为精确。
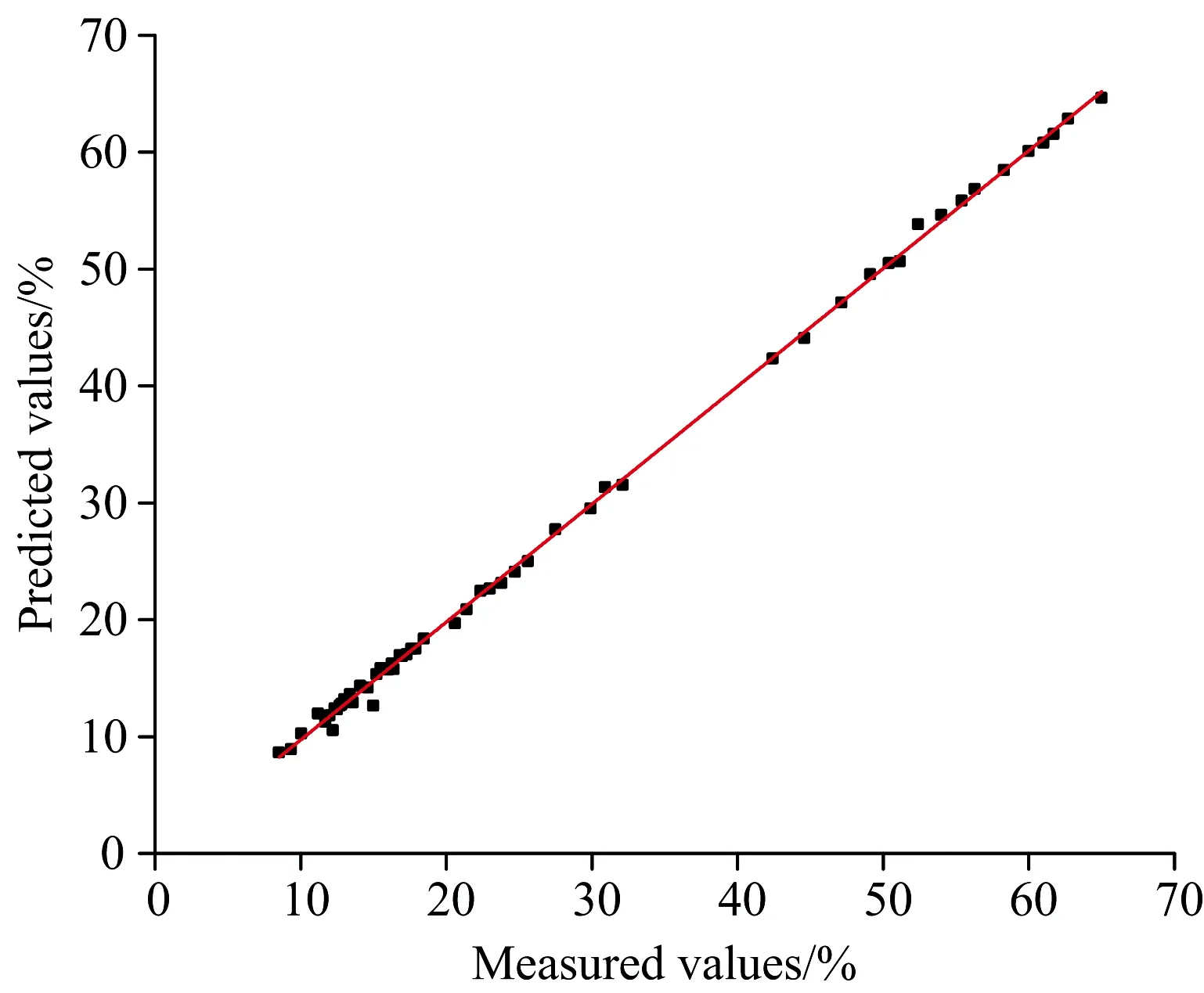
图7 预测值与真实值差异图Fig.7 The difference between the predicated value and the true value
综合分析上述不同方法处理之后的结果,其中经MSC处理、PCA降维后的数据基于ELM算法建立的品位定量反演模型效果最优。未经处理的数据可能受到设备的局限性以及实验环境的影响,产生基线平移偏移等现象,对建模造成负面影响,而通过MSC处理之后的数据能很大程度上消除这种影响,突出光谱特征信息的同时降低信噪比,有助于反演模型的精度提升,而遗传算法在路径寻优上具有偶然性,且容易收敛到局部最优解,因此满足不了精度要求。而主成分分析能最大程度的提取经过MSC处理之后光谱数据主要信息,因此经过该方法建立的模型反演结果精度最优。由于随机森林是一种集成算法,因此经过预处理的数据对其反演模型精度没有产生太大变化;而极限学习机算法,学习速度极快,泛化能力强,预测结果精确,但容易受到噪声以及无用信息的干扰,导致对未经处理的数据反演建模精度较低,而选择合适的预处理方法能很大程度消除负面影响。
经MSC处理、PCA降维后的光谱数据,以ELM为极限学习机模型对红岭矽卡岩型铁矿品味反演不仅能大幅度提升模型反演速度,而且满足高精度、高效率的品位反演需求。
3 结 论
以225个赤峰红岭矽卡岩型铁矿的化学分析与可见光-近红外光谱测试数据为数据源,深入研究了测试数据的预处理方法以及定量反演模型,结论如下:
(1)利用MSC算法对矽卡岩型铁矿光谱数据进行处理可有效降低散射对数据的影响。利用PCA算法对矽卡岩型铁矿光谱数据进行降维处理可有效降低原始数据冗余,提升建模速度。
(2)对于矽卡岩型铁矿,使用经MSC处理、PCA降维后的数据,以极限学习机为建模方法,反演结果最优。其中R2由0.94提升至0.99,MSE由0.042 0降低至0.005 7,MRE从16%降低至2%,预测精度较高。
针对矽卡岩型铁矿的原位快速品位分析提供了一种有效方法。但由于不同类型矿体的光谱测试结果会存在不同程度的差异,因此数据处理方法、所建模型精度也会不同,对此尚需开展进一步深入研究。
