基于批损失的跨模态检索
2022-01-11徐清振
刘 爽, 乔 晗, 徐清振
(华南师范大学计算机学院, 广州 510631)
跨模态检索的目标是实现不同模态数据的检索[1],即采用一种模态的数据来检索另一种模态的数据. 近年来,随着各种模态数据的海量增长,跨模态检索引起了学术界和工业界的兴趣. 由于不同模态的数据存在异构鸿沟,如何直接度量不同模态数据的相似性成为跨模态检索的挑战.
常用的弥补异构鸿沟的方法是表征学习,其目标是寻找一个公共表征空间,不同模态的数据在此空间中能够直接度量. 学习这样的公共表征空间存在大量的方法[2-7],例如,具有代表性的典型相关性分析(CCA)[2]、多标签的典型性相关分析(MCCA)[3]和多视图辨别分析(MvDA)[4]等. 然而,这些方法难以表示数据的复杂关系. 受到深度神经网络应用于单模态检索的启发,大量的基于深度学习的跨模态检索方法[1,8-12]利用网络的非线性能力来学习公共表征空间.
现有的表征学习可分为基于二进制的表征学习和基于实值的表征学习. 基于二进制的表征学习通常将不同模态的数据映射到公共的二进制汉明空间,其检索速度快,但精度低[13]. 基于实值的表征学习包含无监督的方法、成对的方法和监督的方法. 其中:无监督的方法利用不同模态数据的相关性来学习公共表征空间,典型的方法有深度典型相关分析(DCCA)[8]和深度典型相关自编码(DCCAE)[9]. 成对的方法通过构造样本对来挖掘跨模态样本的信息,典型的方法包含跨媒体多重深度神经网络(CMDN)[10]和跨模态相关学习(CCL)[11]. 监督的方法利用类别标签来学习更有辨别性的公共表征空间,如:KAN等[4]提出了多视图辨别分析(MvDA)方法,通过联合求解多个线性变换实现有辨别性的公共表征空间;WANG等[1]基于监督的方法提出了对抗学习的方法(ACMR);PENG和QI[14]提出跨模态生成对抗网络(CM-GANs)来建模跨模态的联合分布. 然而,现有的成对或三元组的方法构造了高度冗余且信息量少的样本对,不利于公共表征空间的学习.
针对以上问题,本文提出了基于批损失的跨模态检索方法(BLCMR),从模态内和模态间2个维度进行优化. 具体而言,为了保持模态内不同类别样本的可分性,引入线性投影器来预测样本的类别,利用交叉熵函数来计算模态内的分类损失;为了减小相同类别跨模态的样本的差异性,基于样本相似性的迭代方法修正预测的类别标签,并采用批损失函数计算相同类别样本的相似性. 最后,在3个公开的数据集上进行对比实验、消融实验和可视化实验,分析BLCMR方法的检索性能.
1 BLCMR方法
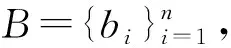
由于不同模态的数据具有不同的统计特性而无法直接比较,因此,本文将不同模态的数据投影到公共表征空间. 在此公共表征空间,不同模态的数据可以直接度量. BLCMR方法的目标是学习这样的公共表征空间,即学习最优的映射函数f(ui;ωui)和f(ti;ωti). 在公共表征空间中,图像和文本分别被映射为pi=f(ui;ωui)d和qi=f(ti;ωti)d,所有实例的图像表征矩阵、文本表征矩阵、标签表征矩阵分别表示为P=(p1,p2,…,pn)Tn×d、Q=(q1,q2,…,qn)Tn×d、S=(sic)n×mn×m. 图像表征矩阵和文本表征矩阵拼接得到矩阵E=(p1,p2,…,pn,q1,q2,…,qn)T2n×d,记为E=(e1,e2,…,ei,…,e2n)T2n×d.
下面给出BLCMR方法的总体框架和目标函数.
1.1 BLCMR方法的总体框架
BLCMR方法的框架包括图像和文本2个网络模块(图1). 图像网络模块以图像为输入,经过特征提取模块来提取4 096维的图像特征,以此作为图像的原始高层语义表示,进行公共表征空间的学习,其中,特征提取模块采用ImageNet上预训练的VGG19Net的fc-7层来提取图像特征. 文本网络模块以文本为输入,经过特征提取模块获取300维的文本特征,以此作为文本的原始高层语义表示,进行公共表征空间的学习,其中,特征提取模块利用经过谷歌300W新闻语料库预训练的词向量模型[15]将每个输入的文本表征为k维的特征向量,接着,通过Sentence CNN[16]来提取文本特征. 提取的图像特征和文本特征分别接入3个全连接层进行公共表征空间的学习,为了确保能够学习统一的公共表征空间,本文共享最后一个全连接层的权重,并设置神经元的数量为1 024个.
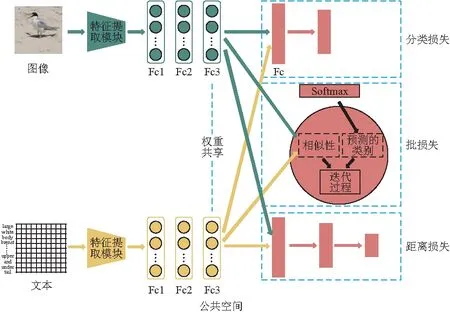
图1 BLCMR方法的总体框架
1.2 BLCMR方法的目标函数
BLCMR方法的目标是学习一个公共表征空间,在此空间中,相同语义类别的数据尽可能靠近,不同语义类别的数据尽可能远离. 因此,最小化标签空间的分类损失函数L1、批损失函数L2和图像文本对的距离损失函数L3,从而构造BLCMR方法的总损失函数:
L=αL1+L2+βL3,
其中,超参α、β分别决定了L1、L3对总损失函数的贡献.
1.2.1 标签空间的分类损失 为了保留公共表征空间中不同类别样本的区分性,本文引入线性分类器[17]来预测样本的类别. 该分类器以公共表征空间中的图像和文本为输入,输出样本数据的m维的类别标签. 本文利用下式来计算相同模态(图像和文本)的分类损失[17]:
(1)
1.2.2 批损失 深度度量学习的损失的计算经常利用基于嵌入距离的损失函数[18],较少采用分类损失函数. 对于分类网络而言,正确的分类很重要. 在分类网络中,尽管每个样本独立地分类,仍可能存在相同类别的样本分类正确、在公共表征空间却距离较远的情况. 因此,当以一批样本而不是单个样本为单位进行分类时,属于同一类别的图像和文本具有相似的嵌入,分类损失仍可用于深度度量学习[19]. 由此,本文利用批损失来保持相同类别跨模态样本的相似性,即基于批处理样本的相似性和网络的分类信息进行多次迭代来修正分类结果. 具体而言:首先,初始化分类结果;然后,基于跨模态样本的相似性矩阵来迭代地修正分类结果;最后,计算批损失.
(1)初始化分类矩阵和相似性矩阵.
①初始化softmax层输出的标签矩阵. 首先,获取softmax层输出的标签矩阵H(0)=(hic)2n×m2n×m,H(0)由图像标签矩阵HImg=n×m和文本标签矩阵HTxt=n×m纵向拼接而成. 然后,随机选取一些点作为锚点,利用锚点的独热(one-hot)标签来代替H(0)中的标签向量,通过利用样本真实的类别标签来代替预测标签,引导其他的样本正确分类. 锚点的one-hot标签在迭代过程中保持不变,不会直接影响损失函数.
②计算公共表征空间中跨模态批处理样本的相似性矩阵. 相似性矩阵R=(rij)2n×2n2n×2n由批量样本的相似性构成,样本的相似性是指图像与图像、图像与文本、文本与图像以及文本与文本的相似性. 本文利用皮尔逊相关系数rij度量样本的相似性,定义如下:
(2)
其中,ei、ej为公共表征空间中的图像、文本表征,Cov为协方差,Var为方差;当i=j时,rij=0.
(2)考虑到相似样本的类别应相同,本文利用相似性矩阵对标签矩阵H(0)进行迭代修正.
首先,定义支持矩阵为:
(3)
其中,第i个元素gic反映了当前批量样本对第i个样本属于类别c的支持,gic越大,表明第i个样本属于类别c的可能性越大.
然后,对于初始的标签矩阵H(0),利用下式进行迭代修正:
(4)
其中,分母为归一化因子,保证修正后的矩阵每行之和为1. 这可以看作进化博弈论中的多种群复制动态模型[20],相当于非线性松弛过程[21-22].gic越大,则hic越大,样本属于类别c的可能性越大.
最后,为了用矩阵简化表示,式(4)可以改写为:
(5)
其中,1为m维的全一的向量,⊙为哈达玛矩阵乘积.
(3)当迭代过程达到最大次数时,本文利用本质为交叉熵损失函数的批损失函数来计算样本的分类错误:
(6)
其中,si为样本的真实标签,ha、hb分别为图像、文本的预测标签. 损失越小,同一类别的跨模态样本嵌入到一起的可能性越大,减少了跨模态样本的差异.
1.2.3 图像文本对的距离损失 为了减小跨模态差异,本文最小化公共表征空间中的图像文本对之间的距离,损失函数如下:
(7)
2 实验结果与分析
为了验证BLCMR方法的有效性,首先,在Wikipedia[23]、Pascal Sentence[24]和NUS-WIDE-10k[25]3个公开的数据集上,将BLCMR方法与13种经典的方法进行对比实验;然后,在3个数据集上,对BLCMR方法进行消融实验;最后,在Wikipedia数据集上进行BLCMR方法的可视化实验.
2.1 实验配置
2.1.1 数据集的划分 首先,遵循FENG等[26]的规则,将Wikipedia、Pascal Sentence和NUS-WIDE-10k数据集划分为训练集和测试集(表1).
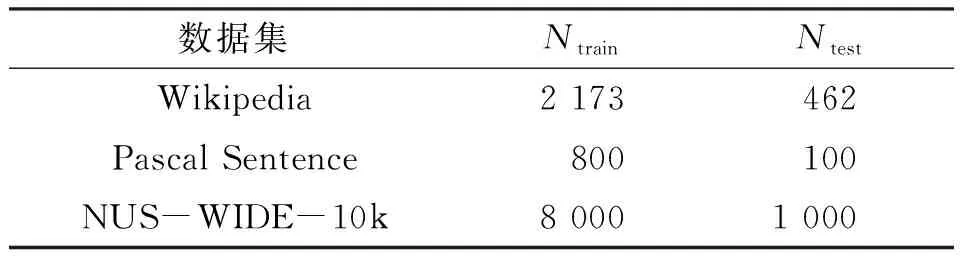
表1 数据集的划分Table 1 The partitioning of datasets
2.1.2 参数设置 对于批量样本,本文设置批处理数据B中实例数n=100,Wikipedia、Pascal Sentence、NUS-WIDE-10k数据集的类别数分别为mwiki=10、mpascal=20、mnus=10,每类的实例数分别为hwiki=10、hpascal=5、hnus=10. 实验过程中,本文提取4 096维的图像特征和300维的文本特征,选定超参α=1和β=0.1,同时,采用Adam优化器[27]进行梯度优化.
2.1.3 评估指标 mAP指标[28]表示检索结果的平均精度均值,是跨模态检索的典型的评价指标,因此,本文采用该指标来评估检索的性能. 考虑到跨模态检索包含图像和文本的相互检索:图像检索文本和文本检索图像,本文采用图像检索文本的mAP(Img2Txt)、文本检索图像的mAP(Txt2Img)和平均检索的mAP(Avg)来评估跨模态检索的性能,其中,Avg为图像和文本相互检索的mAP的均值.
2.2 对比实验
在 3个数据集上,将BLCMR方法与13种算法进行对比,其中包括 5种传统的方法(CCA[2]、MCCA[3]、MvDA[4]、MvDA-VC[5]和JRL方法[6])和8种基于深度学习的方法(DCCA[8]、DCCAE[9]、CMDN[10]、CCL[11]、BDTR[28]、ACMR[1]、GSS-SL[12]和CM-GANs方法[14]).
由对比结果(表2)可知:(1)在Wikipedia、Pascal Sentence、NUS-WIDE-10k数据集上,BLCMR方法的Img2Txt与Txt2Img的差值分别为0.028、0.004、0.024,表明Avg能更好地反映检索结果. (2)BLCMR方法的整体检索效果在14种算法中是较好的. 其中,在Wikipedia数据集上,BLCMR方法的Avg虽然仅在14种算法中排第二(0.493),但比CM-GANs方法的仅低0.001,且BLCMR方法在Pascal Sentence数据集上的Avg比CM-GANs方法的高0.085;在Pascal Sentence数据集上,BLCMR方法的Avg最高(0.689),比并列第二的MCCA、DCCA方法的高0.012;在NUS-WIDE-10k数据集上,BLCMR方法的Avg最高(0.594),比并列第二的JRL、ACMR方法的高0.002. (3)在Wikipedia、Pascal Sentence、NUS-WIDE-10k数据集上,BLCMR方法的Avg比ACMR方法的分别高0.038、0.028、0.002,结果表明BLCMR方法优于ACMR方法.
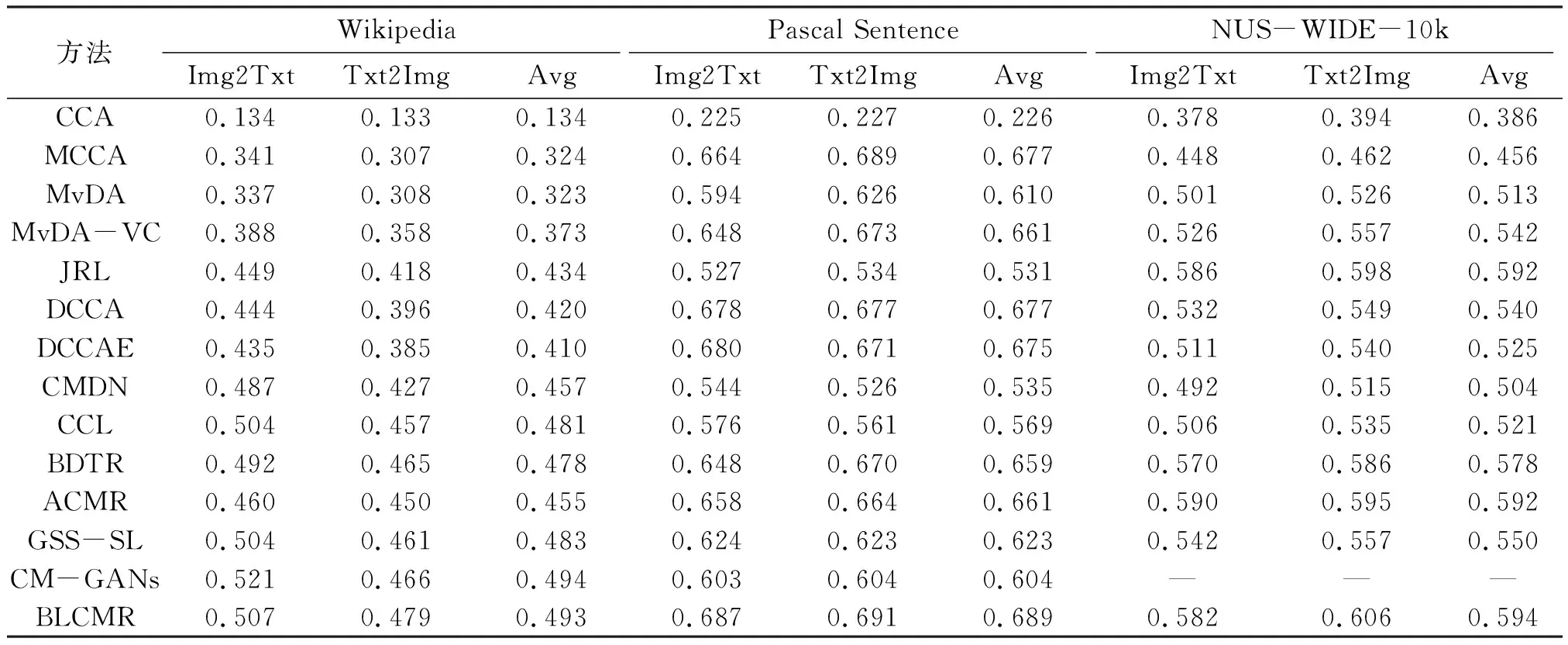
表2 跨模态检索的性能Table 2 The performance of cross-modal retrieval
2.3 BLCMR方法的深入分析
2.3.1 消融实验 BLCMR方法的总损失函数包含标签空间的分类损失函数L1、批损失函数L2和图像文本对的距离损失函数L3. 为了探究各个部分对BLCMR方法的贡献,本文评估了L1、L2和L3单独作用的效果以及BLCMR方法作用的结果.
由消融实验结果(表3)可知:L1、L2和L3对BLCMR方法的检索性能都有贡献,且三者的联合作用高于单独作用;L1的贡献最高,说明L1考虑了数据类别的区分性,有效地提高了检索性能.

表3 BLCMR方法及其L1、L2和L3的检索性能Table 3 The retrieval performance of the BLCMR method and its L1, L2 and L3
2.3.2 收敛性实验 在Wikipedia数据集上进行总损失收敛性实验,由结果(图2)可知,总损失值随着学习步长的增大而持续减小,直到学习步长大约为2 000时,总损失值趋于稳定,表明本文采用的Adam随机梯度下降优化算法是有效的.
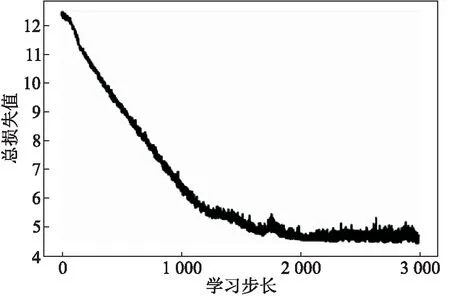
图2 Wikipedia数据集上总损失值的变化曲线
2.3.3 公共表征空间的可视化实验 为了直观地观察算法的效果,本文利用t-SNE[29]降维技术,在Wikipedia数据集上将图文初始化空间和学习的公共表征空间展示在二维坐标系上. 由初始的图像样本、文本样本以及图像和文本样本(图3A、B、C)可知,初始的图像、文本样本分布较稀疏,不利于图像和文本的检索. 由公共表征空间的图像表征、文本表征、图像和文本表征(图3D、E、F)可知,公共表征空间中的图像、文本样本间的距离近,说明BLCMR方法能够有效地减小跨模态样本之间的差异.
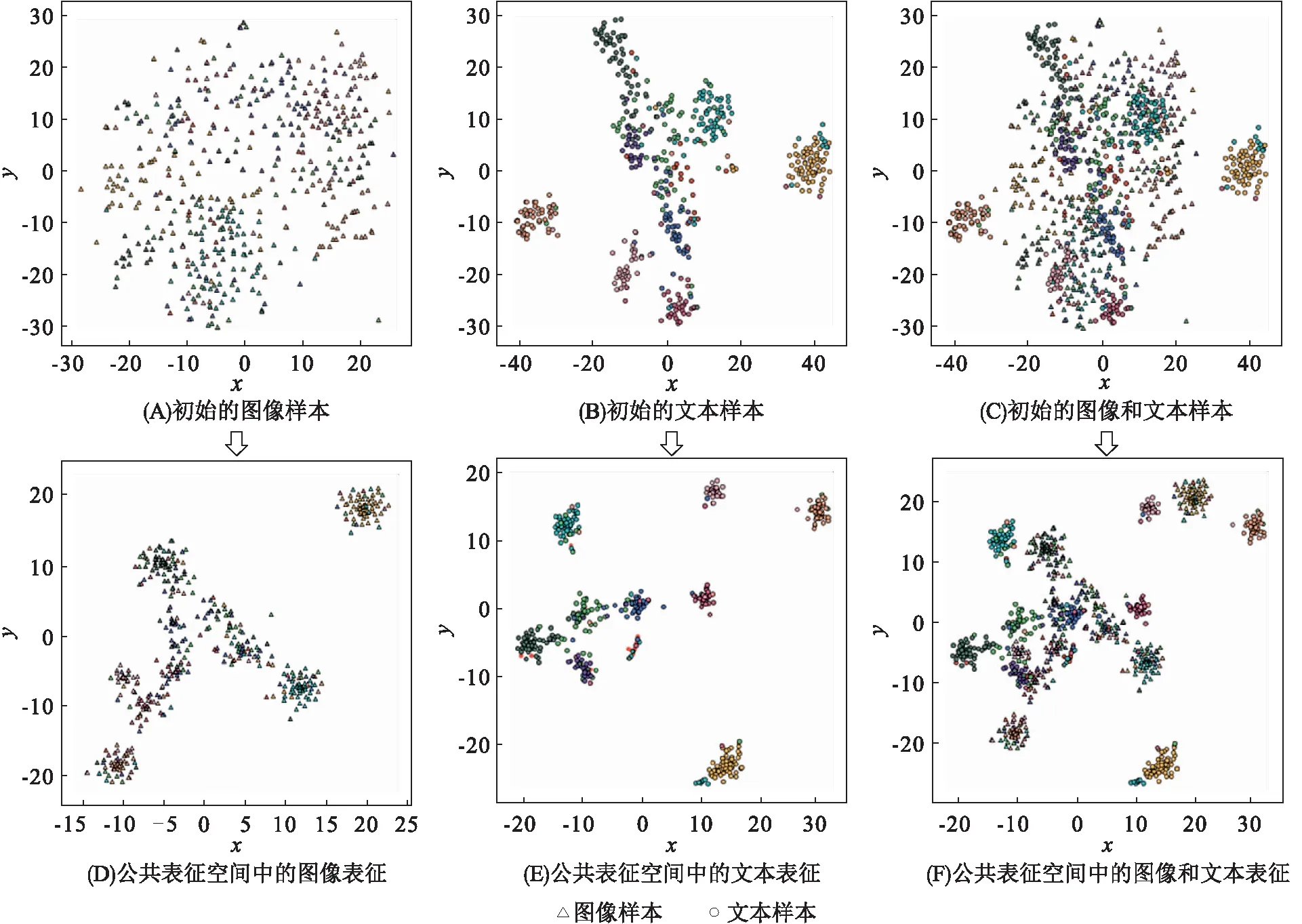
图3 Wikipedia数据集上的图像、文本样本的可视化
3 小结
针对现有的基于成对或三元组约束的方法构造了高度冗余且信息量少的样本对的问题,本文提出基于批损失的跨模态检索方法(BLCMR):引入批损失,考虑了批量样本的相似性,有效地保持了跨模态样本的不变性;为了区分模态内样本的语义类别信息,修正了分类结果,从而减少了分类错误. BLCMR方法与13种经典的方法在3个数据集上的实验结果表明:BLCMR方法能够提升最终的检索精度,减小跨模态样本之间的嵌入距离,其中,标签空间的分类损失函数、批损失函数和图像文本对的距离损失函数对BLCMR方法的检索性能有不同程度的贡献;Wikipedia数据集上的图像、文本样本的可视化结果直观地表明BLCMR方法能够减小跨模态样本之间的差异.
在下一步的工作中,将探索模态间的优化方案,改进跨模态样本的度量方法,以提高检索精度.
